







论文标题:Eyes Tell the Truth: GazeVal Highlights Shortcomings of Generative AI in Medical Imaging
论文地址:https://arxiv.org/abs/2503.20967
导读:论文聚焦于医学影像合成数据质量评估问题。通过结合专家眼动追踪数据与放射学评估,构建 GazeVal 框架来评估合成医学图像质量,揭示了生成式 AI 在医学影像领域的不足,为合成数据的发展提供方向。
研究动机
机器学习和人工智能在医学影像领域发展迅速,合成数据对模型训练和增强至关重要。但目前评估合成图像质量主要依赖计算指标,与人类专家认知存在差异,导致合成图像虽数值上逼真,但缺乏临床真实性,影响 AI 医疗工具的可靠性和有效性。生成图像中存在的伪影、曝光异常、纹理和图案不一致等特征,会降低诊断准确性和模型性能。因此,需要一种方法来量化图像真实性并评估判别特征,探究放射科医生对合成图像真实性的关注情况。
创新点
提出 GazeVal 框架,将专家眼动追踪数据与直接放射学评估相结合,能更准确地评估合成医学图像的临床真实性。以往评估方法多依赖计算指标,未充分考虑人类感知,GazeVal 弥补了这一缺陷。将视觉图灵测试(VTT)应用于基于潜扩散模型(LDMs)的生成模型评估,此前 VTT 在 LDMs 评估方面尚未得到充分探索。通过多种评估指标,全面分析合成图像与真实图像的差异,以及放射科医生在不同任务中的注视行为,为理解人类和机器注意力提供新视角。
方法
整体框架:
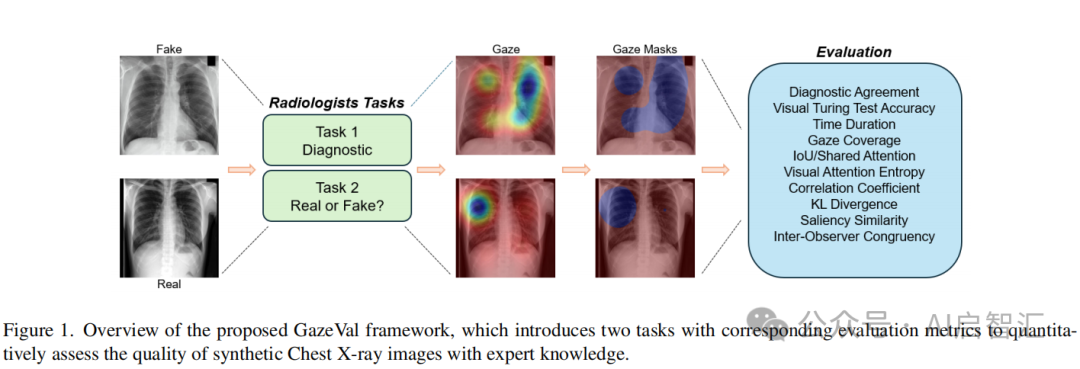
图1展示GazeVal框架的整体架构,该框架利用专家知识对合成胸部X光图像的质量进行定量评估。引入了两个任务,并配备了相应的评估指标。
诊断任务(Diagnostic Task):在这个任务中,放射科医生需要在不知道数据集中包含合成图像的情况下,对每张胸部 X 光图像进行诊断,通过口头描述他们观察到的任何病理或发现。这一任务主要用于自然地检测合成图像是否存在不现实或病理错误等质量问题。如果合成图像存在明显缺陷,放射科医生在诊断过程中可能会察觉到。
视觉图灵测试任务(Visual Turing Test):此时,放射科医生明确知晓数据集中同时包含真实和合成的胸部 X 光图像,他们的任务是判断每张图像是真实的还是合成的。与诊断任务不同,该任务直接引导医生考虑图像为合成的可能性,从而更直接地评估图像质量。之后会采用投票系统,让医生在不相互交流的情况下共同判断图像类型。
评估指标,诊断一致性(Diagnostic Agreement):指放射科医生的口头报告与原始图像报告(金标准)相符的病例百分比,反映了模型再现病理的能力。
评估指标,视觉图灵测试准确率(VTT Accuracy):即放射科医生正确识别图像类别(真实或合成)的病例百分比,该指标揭示了图像质量在欺骗放射科医生方面的表现。
其他指标:如观察时间(Time Duration)、注视覆盖范围(Gaze Coverage)、交并比(IoU/Shared Attention)、视觉注意力熵(Visual Attention Entropy)、相关系数(Correlation Coefficient)、KL 散度(KL Divergence)、显著相似性(Saliency Similarity)、观察者间一致性(Inter-Observer Congruency)等。这些指标从不同角度对合成图像和真实图像进行比较,全面评估合成图像的质量。
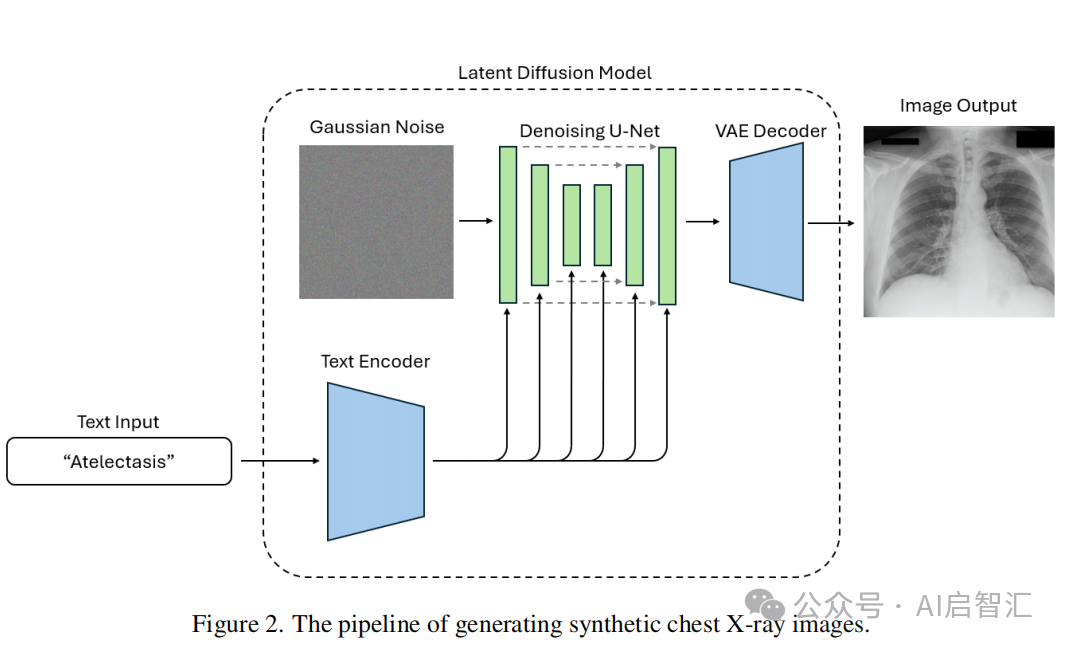
合成胸部 X 光图像生成:利用基于潜扩散模型(LDM)的RoentGen模型,依据MIMIC-CXR数据集中患者报告生成合成胸部X光图像,分辨率为 512x512,经过75步推理。生成后由独立放射科医生筛选,排除具有明显不真实特征的图像,随机选取 30 张用于实验。
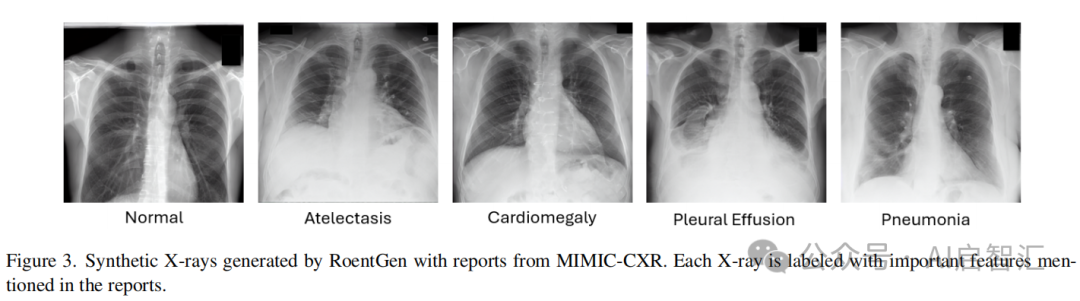
合成X光图像展示
GazeVal测试流程:设计诊断评估和视觉图灵测试(VTT)两个任务。诊断任务中,放射科医生在不知图像包含合成图像的情况下诊断胸部X光图像;VTT任务中,医生需判断图像是真实还是合成的。两个任务间隔约10天,减少图像曝光带来的偏差。
眼动追踪与分析:使用EyeLink 1000 Plus 设备以500Hz频率追踪眼动,通过13点校准确保准确性。引入注视掩膜技术,对原始注视数据进行处理,便于进行注视覆盖范围、交并比(IoU)等定量分析。
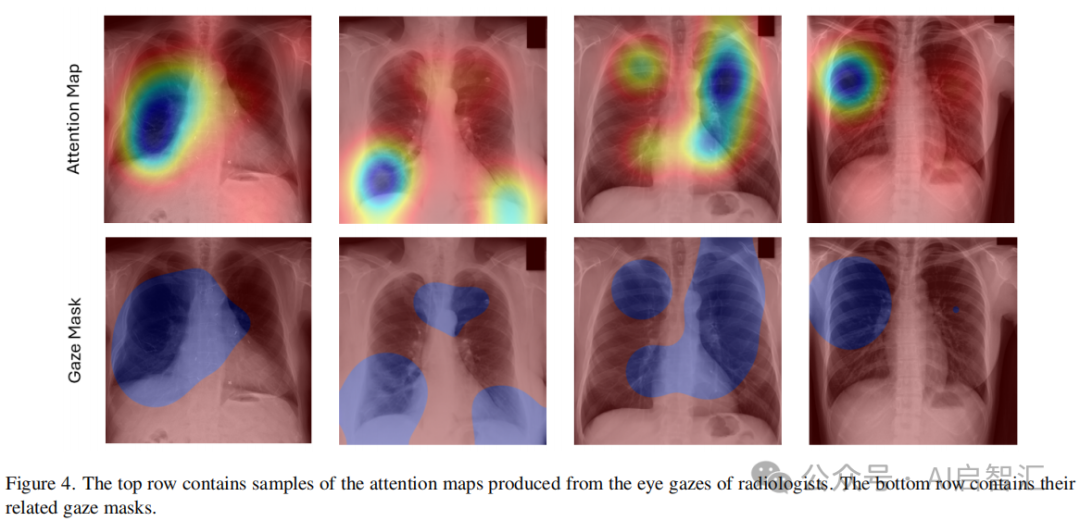
眼动数据处理(注视掩膜)
上图4展示从放射科医生眼动得到的注意力图及其对应的注视掩膜。原始眼动数据转化为视觉注意力图后,通过设定阈值得到注视掩膜。该掩膜虽可能包含医生未主动检查的区域,但能有效代表整体观察区域,便于进行定量测量,如计算注视覆盖范围、交并比等指标,以分析医生对真实和合成图像的注视模式差异,从而评估合成图像质量。
实验
实验设置:将30张生成图像和30张真实图像随机混合成60张图像的数据集,供16名不同专业和经验的放射科医生观察。实验过程中,图像显示在显示器中心,眼动仪置于显示器前 30cm,放射科医生与显示器距离校准为80cm。
评估指标:采用诊断一致性、VTT准确率、观察时间、注视覆盖范围、IoU、视觉注意力熵、相关系数(CC)、KL散度(KLD)、显著相似性(SS)、观察者间一致性(IOC)等指标评估合成图像质量。
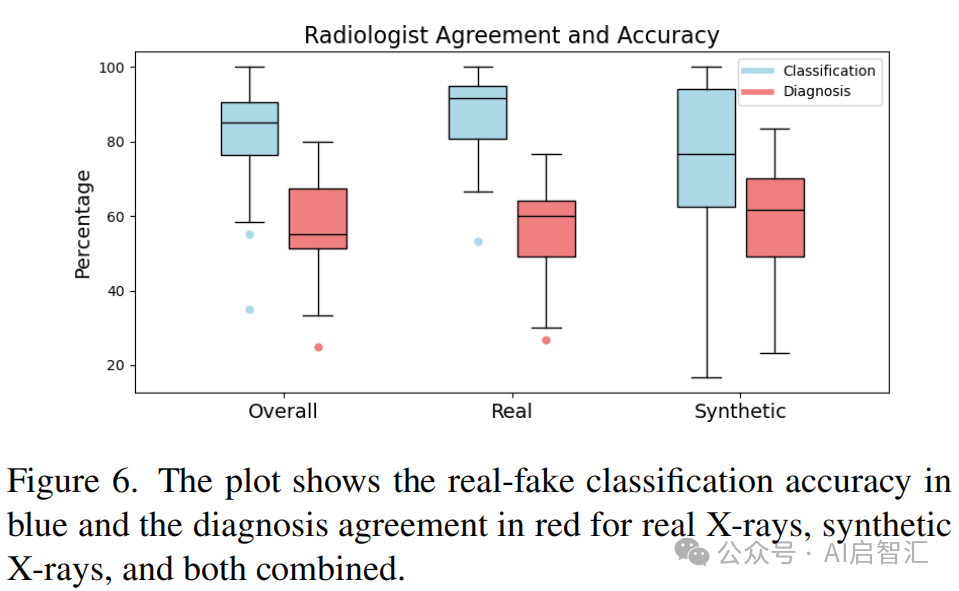
结果:合成 X 光片在疾病表现上与真实 X 光片相似,诊断一致性无显著差异,下图6 。
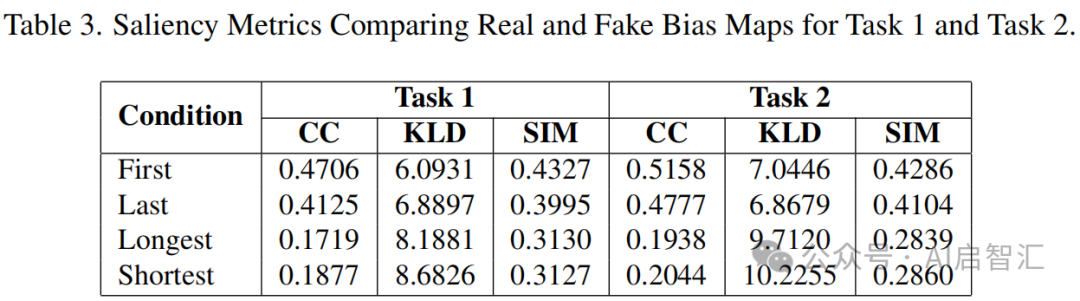
但在观察模式上,合成 X 光片与真实 X 光片存在差异,如最长和最短注视时间差异较大(表 3)
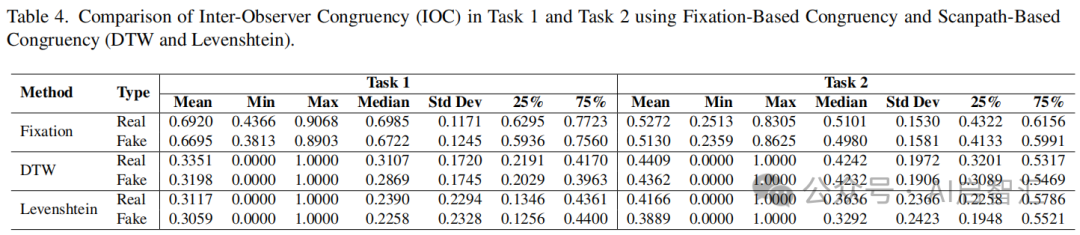
观察者间一致性在合成图像上较低(表 4)
放射科医生能准确区分真实和合成图像,协作投票后准确率高达 96.7%,见图6。
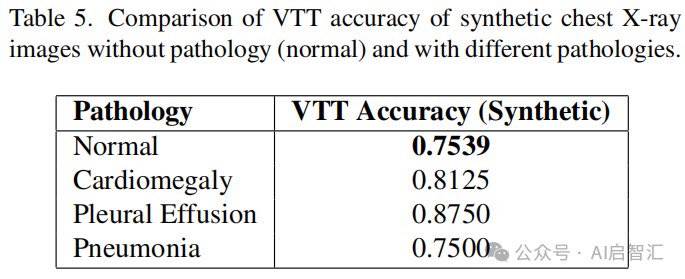
生成有病理发现的 X 光片比无病理的更具挑战性,表5。
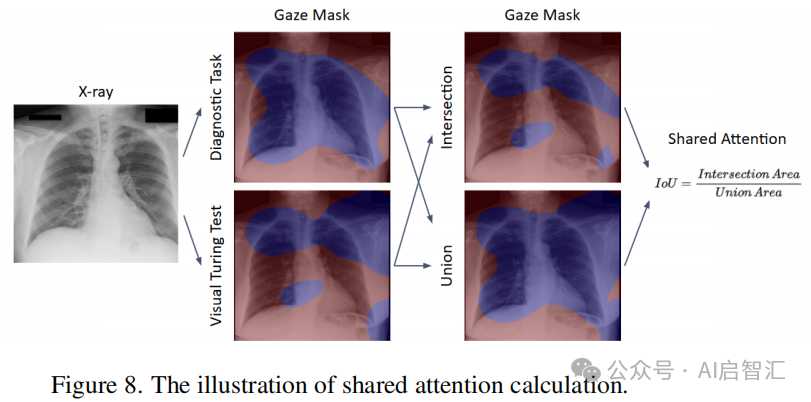
人类视觉注意力受任务影响,不同任务间注视模式差异明显,如下图8。
总结
该研究揭示了生成式AI在医学影像中的局限性(如骨骼结构、血管细节建模不足),并强调需结合人类专家认知优化评估标准,为未来开发更可靠的临床合成数据提供了重要方向。
以上仅供学习交流参考。
感谢阅读!可微信搜索公众号【AI启智汇】更多更及时获取AI分享。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









