






本次分享的是CVPR2025图像超分辨率的论文,作者在谷歌实习期间做出。
论文标题:The Power of Context: How Multimodality Improves Image Super-Resolution
论文地址:https://arxiv.org/pdf/2503.14503
研究动机
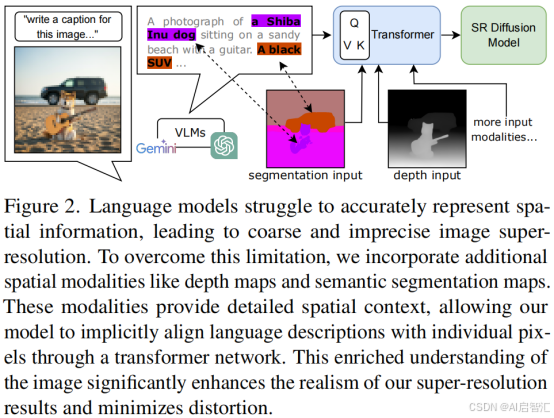
单图像超分辨率(SISR)需从低分辨率图像恢复高分辨率细节,但因信息丢失严重,传统方法依赖有限的图像先验(如边缘、纹理),导致结果存在模糊或过平滑问题。尽管生成模型(如扩散模型)提升了感知质量,但仅依赖文本提示易产生语义错位(如错误生成物体的纹理)和空间关系不准确的问题。
核心挑战:
- 文本模态难以描述局部空间关系(如"狮子的舌头不应有毛发")。
- 现有方法(如ControlNet)通过复制网络模块融合多模态,计算成本高且灵活性差。
- 高分类器无关指导(CFG)权重易导致幻觉(与输入不符的虚假细节)。
解决思路:
通过融合深度、分割、边缘、文本等多模态信息,利用互补的上下文线索约束生成过程,减少不确定性并提升细节保真度。
创新点
1.统一的多模态扩散架构
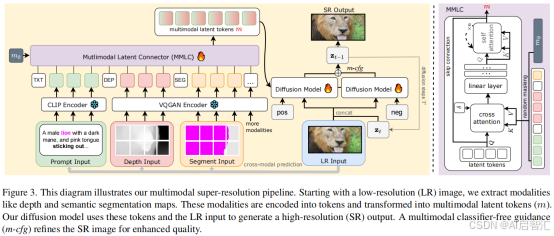
-多模态编码:通过VQGAN将深度、分割、边缘图量化为离散Token,与文本嵌入拼接,实现模态统一表示。
-多模态潜在连接器(MMLC):轻量级Transformer模块,通过交叉注意力将长Token序列压缩为固定长度(128)的潜在表示,降低计算复杂度(从O(M²)到O(MN))。
2.多模态分类器无关指导(Multimodal CFG)
-改进传统CFG公式,在负向生成过程中引入多模态条件,抑制文本提示的过度想象力。
3.模态控制的灵活性
-通过调节注意力温度(δ)独立控制各模态的贡献强度(如增强深度引导的虚化效果或分割引导的物体突出)。
-支持模态缺失的鲁棒生成:通过可学习的空模态Token(m∅)处理不可靠输入。
方法
整体结构:
统一的多模态扩散条件设定:
-基于VQGAN的多模态编码:256×256输入模态→16×16离散Token(VQGAN编码+Codebook量化),特征维度扩展至1024以对齐文本嵌入。
利用预训练的VQGAN图像标记器,将不同模态(如深度图、语义分割图、边缘图等)编码为统一的标记表示。实验发现,离散标记相较于连续标记能更好地保留模态信息,所以采用离散标记。每个256×256的输入模态被编码为16×16、特征维度为256的多模态标记序列,再通过大小为1024 的Codebook进行量化。为便于与文本嵌入连接,将多模态标记的特征维度填充至1024,形成 (256×3 + 77)×1024的多模态标记序列作为条件。

图 4 展示离散多模态标记在模态重建上相较于连续标记的优势
-多模态潜在连接器(MMLC)设计:随机初始化的潜在Token与多模态Token交叉注意力→自注意力整合信息→固定长度条件向量。
引入MMLC来解决跨注意力机制在处理多模态数据时计算复杂度高的问题。MMLC采用 Transformer架构,接收随机初始化的可学习潜在标记序列和多模态输入序列,输出与潜在标记序列等长的标记序列,作为扩散模型的条件。这样,扩散模型基于固定长度(实验中为 128)的潜在标记进行条件设定,显著降低了计算成本。而 MMLC 通过交叉注意力将复杂度从O(M²)到O(MN)。
多模态引导与控制:
-多模态无分类器引导(Multimodal Classifier-free Guidance):针对传统无分类器引导(CFG)在高引导尺度下易产生过多幻觉的问题,提出多模态引导策略。传统CFG通过公式:
![]()
进行引导去噪,但依赖文本提示的引导存在缺陷。多模态CFG则利用多模态潜在标记中的丰富信息,对正负生成过程都基于多模态潜在标记序列m进行条件设定,公式为:
![]()
,在感知质量和保持低分辨率输入语义内容之间取得更好的平衡。
-单模态引导缩放:多模态CFG虽能控制提示的整体影响,但无法单独控制每个模态。通过修改MMLC在交叉条件设定时的注意力温度\(\delta\)来实现对特定模态贡献的选择性放大或抑制。
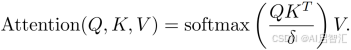
,较小的![]() 会增强注意力机制的条件作用。实验发现,将标准温度
会增强注意力机制的条件作用。实验发现,将标准温度![]() (
(![]() 为关键维度)在 [0.4, 10] 范围内缩放,可产生不同保真度的高质量结果,实现对超分辨率过程的精确控制。
为关键维度)在 [0.4, 10] 范围内缩放,可产生不同保真度的高质量结果,实现对超分辨率过程的精确控制。
训练策略
-数据构造:RealESRGAN退化模型生成低分辨率图像,结合DIV2K/LSDIR高分辨率数据。
-随机模态丢弃:训练时以10%概率独立替换各模态为m∅,增强模型鲁棒性。
推理流程
1.从低分辨率图像提取多模态:
- 文本(Gemini Flash生成文本描述)
- 深度(Depth Anything估计深度图)
- 分割(Mask2Former生成的语义分割掩码)
- 边缘(Canny检测边缘信息)
2.深度图、分割掩码和边缘信息通过预训练的VQGAN编码为标记序列,文本描述由预训练的CLIP编码器处理得到文本嵌入。低分辨率图像与从扩散模型采样的噪声潜在向量连接,为模型提供额外条件,最终生成高分辨率图像。
实验与结果
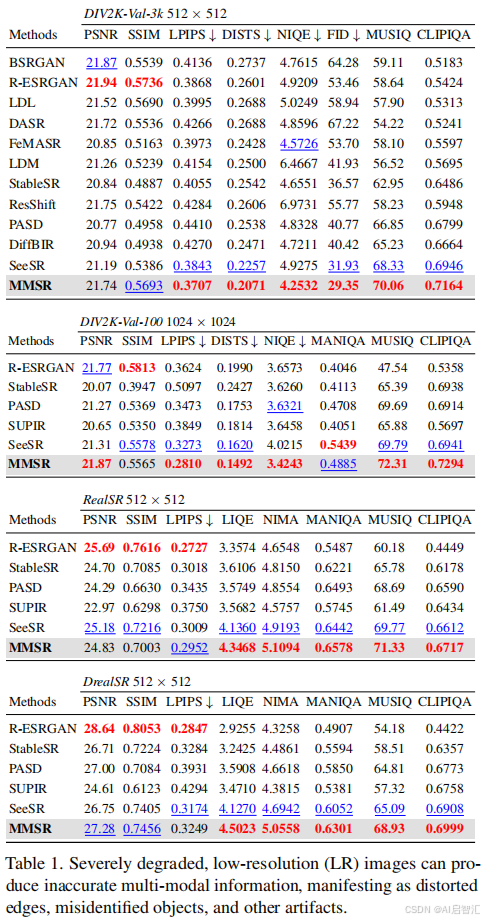
评估指标
-参考指标:LPIPS(感知相似性)、DISTS(结构保真度)、PSNR/SSIM
-无参考指标:NIQE(自然度)、MANIQA/MUSIQ/CLIPIQA(美学质量)
对比方法
BSRGAN、Real-ESRGAN、StableSR、PASD、SeeSR等主流生成式SISR方法。
主要结果
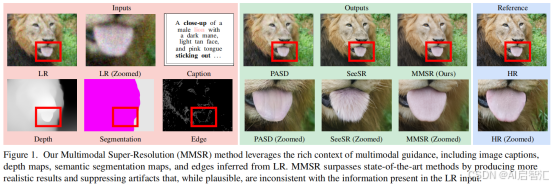
在感知质量(MUSIQ)和保真度(DISTS)上全面超越基线,尤其在复杂场景(如运动模糊)中细节恢复更准确。

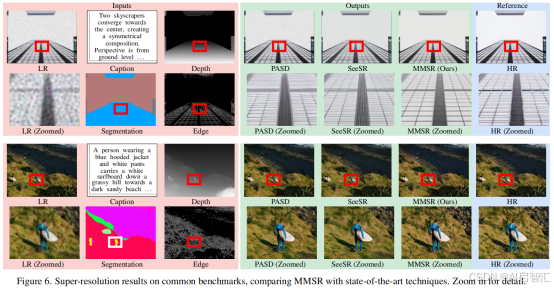
消融实验
- MMLC有效性:移除MMLC导致LPIPS从0.281升至0.393,生成出现深度错位(如树枝虚化错误)。
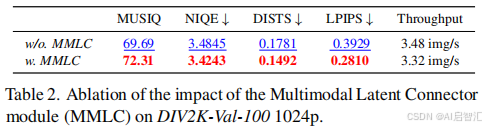
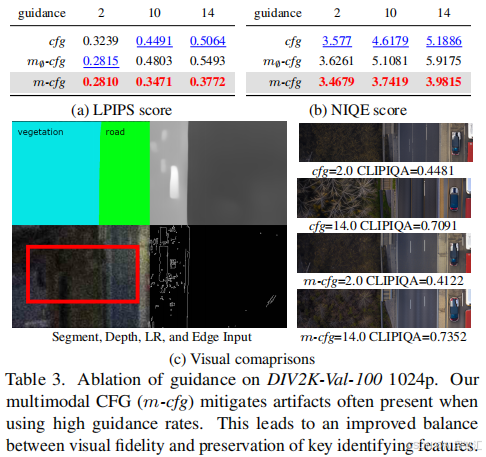

图7辅助表2看,从视觉层面
-探究模态贡献: 深度模态→提升背景虚化;分割模态→增强物体边缘;文本模态→补充语义细节
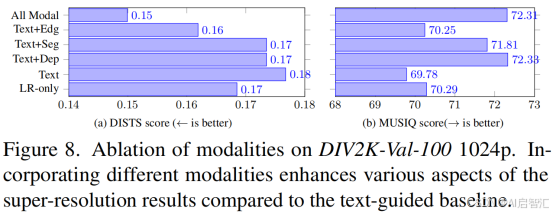
可控性验证
调节温度参数(δ)可定向调整输出特性:降低深度温度→背景虚化增强 ;提高边缘温度→锐利度下降;文本权重降低→减少无关纹理生成

总结
理论贡献:提出多模态条件熵降低理论,证明融合多模态可缩小解空间,提升生成确定性。
技术贡献:本文章是首个支持任意模态组合的轻量级扩散架构(MMLC)。同时改进CFG实现幻觉抑制与多模态解耦控制。
应用:为图像修复、虚拟现实等需高保真超分辨率的场景提供新工具。
局限与展望
当前限制:
-多模态提取依赖预训练模型(如Gemini),推理速度受限(0.34 img/s)。
-极端低质输入可能导致模态预测失效(需人工干预)。
未来方向:
-轻量化多模态提取模块(如蒸馏小型分割模型)。
-探索3D点云等新型模态的融合潜力。
可微信搜索公众号【AI启智汇】,获取最新AI分享,感谢阅读。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









