






RPG-DiffusionMaster:革新文本到图像生成的新方法
在人工智能和计算机视觉领域,文本到图像的生成一直是一个充满挑战的研究方向。随着扩散模型的出现,这一领域取得了突破性的进展。然而,现有的方法在处理涉及多个对象、多个属性和复杂关系的文本提示时仍面临诸多挑战。为了解决这些问题,研究人员提出了一种全新的训练无关的文本到图像生成/编辑框架——RPG(Recaption, Plan and Generate)。
RPG的核心理念
RPG的核心理念是利用多模态大语言模型(MLLM)强大的链式思考推理能力,来增强文本到图像扩散模型的组合能力。这种方法将生成复杂图像的过程分解为多个子区域内的简单生成任务,从而更好地处理复杂的文本提示。
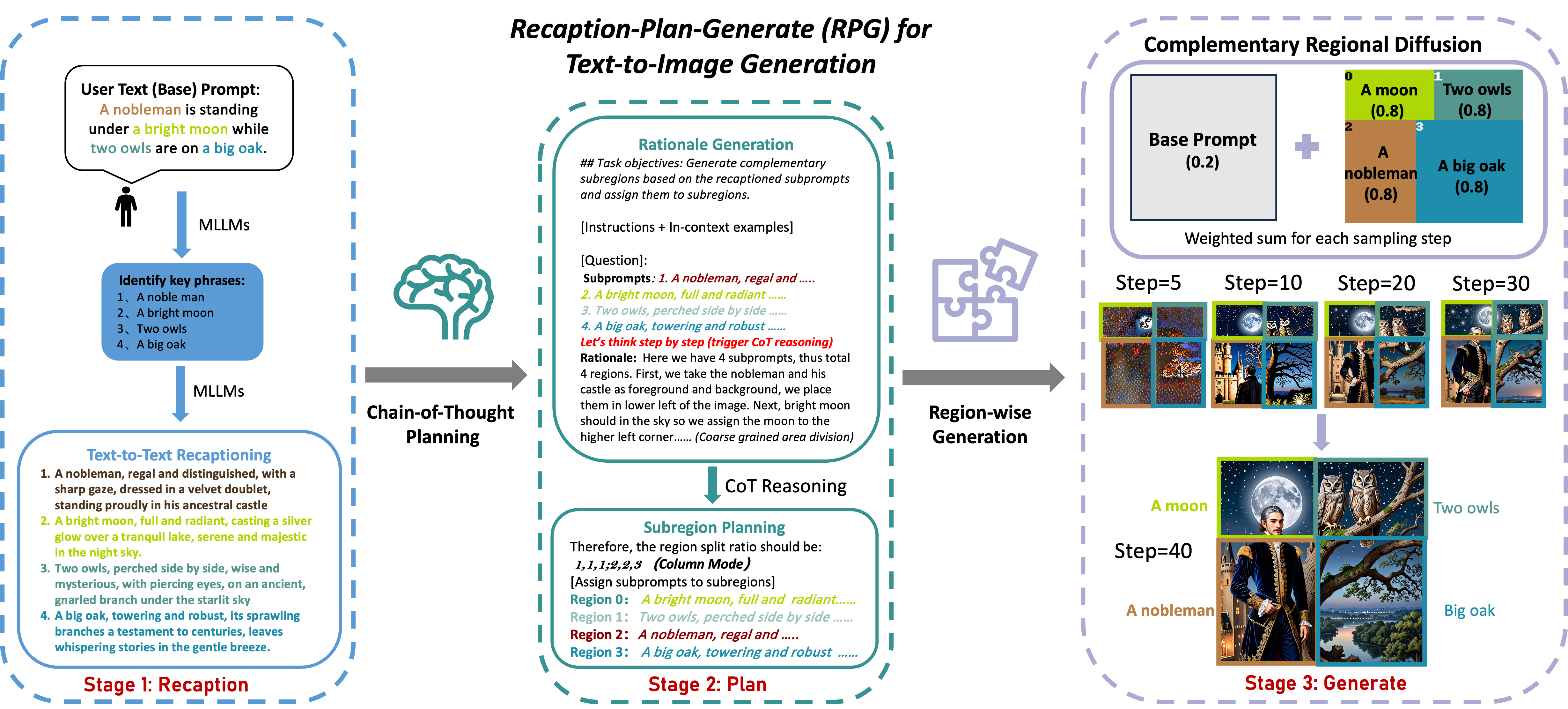
如上图所示,RPG框架主要包含以下几个关键组件:
-
MLLM全局规划器: 利用多模态大语言模型作为全局规划器,将复杂图像的生成过程分解为多个子区域的简单生成任务。
-
补充区域扩散: 提出了补充区域扩散技术,实现区域级的组合生成。
-
闭环整合: 将文本引导的图像生成和编辑在RPG框架内以闭环方式整合,从而增强泛化能力。
RPG的主要特点
-
训练无关: RPG是一个无需额外训练的框架,可以直接利用现有的预训练模型。
-
灵活性: 可以使用专有MLLM(如GPT-4、Gemini-Pro)或开源本地MLLM(如miniGPT-4)作为提示重述器和区域规划器。
-
兼容性: 可以与任意MLLM架构和扩散模型主干网络兼容。
-
高分辨率生成: 能够生成超高分辨率的图像。
RPG的工作流程
-
重述(Recaption): MLLM首先对输入的文本提示进行重述,提取关键信息并进行细化。
-
规划(Plan): MLLM根据重述后的提示,规划图像的整体布局和各个区域的内容。
-
生成(Generate): 利用补充区域扩散技术,根据规划生成各个子区域的图像内容,最后合成完整图像。
RPG的应用场景
RPG在多个场景下展现出了卓越的性能,尤其是在处理复杂文本提示时:
- 多人物复杂属性绑定
RPG能够精确地生成具有多个人物且每个人物都有复杂属性的图像。例如:

文本提示: "一个白色马尾辫的女孩穿着黑色连衣裙,正在与一个金色卷发的女孩在咖啡厅里聊天,后者穿着白色连衣裙。"
这个例子展示了RPG能够准确地捕捉和呈现多个人物的不同特征,包括发型、服装颜色等细节。
- 多对象复杂关系
RPG在处理涉及多个对象之间复杂关系的场景时也表现出色。比如:

文本提示: "一个绿色双马尾的女孩穿着橙色连衣裙坐在沙发上,左边是一个大窗户下的凌乱书桌,沙发右上方是一个生机勃勃的水族箱,写实风格。"
这个例子展示了RPG能够准确地布局和生成多个不同的对象,并保持它们之间的空间关系。
- 超高分辨率图像生成
RPG还能生成超高分辨率的图像,展现出惊人的细节和复杂性:

文本提示: "一幅美丽的景观,中间是一条河流。河的左侧是冬季的傍晚,有一座大冰山和一个小村庄,一些人在河上滑冰,另一些人在滑雪。河的右侧是夏季的早晨,有一座火山和一个小村庄,一些人在玩耍。"
这个例子展示了RPG能够在一幅图像中呈现截然不同的场景,并且在高分辨率下保持细节的清晰度。
RPG的技术实现
RPG的实现主要基于以下几个关键技术:
-
扩散模型: 使用了多种扩散模型作为基础,包括SDXL、SD v2.0/2.1、SD v1.4/1.5等。
-
多模态大语言模型: 可以使用GPT-4、Gemini-Pro等专有MLLM,也支持使用miniGPT-4等开源本地MLLM。
-
区域扩散管道: 提出了RegionalDiffusionPipeline和RegionalDiffusionXLPipeline,分别用于基础模型和SDXL模型。
-
参数优化: 引入了base_prompt和base_ratio等参数,用于优化生成效果。
RPG的优势与创新
-
提高组合能力: 通过MLLM的规划,RPG显著提高了处理复杂文本提示的能力。
-
灵活性和可扩展性: 支持多种MLLM和扩散模型,易于扩展和适应新的模型架构。
-
无需额外训练: 作为一种训练无关的方法,RPG可以直接利用现有的预训练模型,降低了使用门槛。
-
高质量图像生成: 在多类别对象组合和文本-图像语义对齐方面表现优异。
RPG的未来发展
RPG团队计划在未来进行以下改进和扩展:
- 更新Gradio演示,提供更直观的用户界面。
- 发布自我优化版RPG,进一步提高生成质量。
- 发布用于图像编辑的RPG版本,扩展应用场景。
- 发布集成ControlNet的RPG v3,增强对图像生成的控制能力。
- 发布支持diffusers的RPG v2,提高与主流框架的兼容性。
结论
RPG-DiffusionMaster作为一种创新的文本到图像生成框架,通过结合多模态大语言模型的推理能力和扩散模型的生成能力,成功解决了复杂文本提示下的图像生成问题。它不仅在多类别对象组合和文本-图像语义对齐方面表现出色,还具有良好的灵活性和可扩展性。随着进一步的发展和优化,RPG有望在计算机视觉和人工智能领域发挥更大的作用,为创意表达和内容创作提供强大的工具支持。
参考资料
- RPG-DiffusionMaster GitHub仓库
- Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs
- SDXL
- miniGPT-4
- diffusers库
通过深入了解RPG-DiffusionMaster,我们可以看到它为文本到图像生成领域带来了新的可能性。随着技术的不断发展,我们期待看到更多基于RPG的创新应用,为艺术创作、设计和视觉通信等领域带来革命性的变化。
文章链接:www.dongaigc.com/a/rpg-diffusion-master-control-text-to-image
https://www.dongaigc.com/a/rpg-diffusion-master-control-text-to-image


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









