







由于自己配了几遍,总结出了一些问题,然后现在写一遍最详细的过程,作为总结
第一步:把jdk和hadoop的压缩包导入虚拟机的目录下:/opt/softWare/jdk /opt/softWare/hadoop
第二步:解压 # tar -zxvf jdk-8u141-linux-x64.tar.gz
hadoop同理
第三步:配置环境变量
1. vi /etc/profile
2. 追加以下内容:
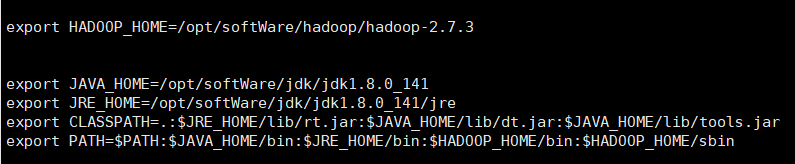
3. 刷新环境变量 source /etc/profile
4. 检测环境变量是否成功:java -version hadoop version
第四步:主机名与ip建立映射关系 vi /etc/hosts (有几台虚拟机,就添加几条映射)

第五步:修改hadoop的配置文件
1.配置文件的位置 /hadoop/hadoop-2.7.3/etc/hadoop
2.修改配置文件
(1)vi Hadoop-env.sh
第一页里面唯一没有被注释的这一行
第27行 export JAVA_HOME=/usr/java/jdk1.8.0_141
(2) vi core-site.xml
<!--制定HDFS的老大(NameNode)的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://zz01:9000</value>
</property>
<!--指定hadoop运行时产生文件的存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/zz/hadoop/tmp</value>
</property> (3)hdfs-site.xml
<!--指定HDFS副本的数量-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>(4)mapred-site.xml 只有 mapred-site.xml.template没有mapred-site.xml,需要复制一个
mv mapred-site.xml.template mapred-site.xml vi mapred-site.xml
<!--指定mr运行在yarn上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>(5) yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>zz01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>第六步:克隆(根据自己的需要克隆多台,配置的过程中,一定要快照保存,为了以后配错了可以不用重头再来)
第七步:修改克隆主机的ip (每台克隆机都需要修改)
1.查看克隆主机ip 和mac地址 ip add
2.修改mac地址,设置静态ip(也就是在第三步中的ip) vi /etc/sysconfig/network-scripts/ifcfg-ens33
第八步:修改主结点的slaves(位置在/hadoop/hadoop-2.7.3/etc/hadoop)
将里面的localhost删除,写上自己几台虚拟机的主机名
第九步:配置免密功能(每台虚拟机上都需要执行一遍)
1. cd ~/.ssh (看看有没有,有的话进入,没有直接进行第二步)
2.ssh-keygen -t rsa #全部输回车
3.把公钥拷贝到到要免密登录的机器上(以共有三台为例)
# ssh-copy-id 192.168.233.121
# ssh-copy-id 192.168.233.122
# ssh-copy-id 192.168.233.123
4.附加:
由于我在前三步的过程中,免密功能设置总是不好,所以我就执行了以下命令:
例如在第一台虚拟机(zz01)上执行这两条:ssh zz02 ssh zz03
ssh后面加上除了本机以外的主机名
第十步:格式化(注意:在格式化之前一定要记得快照保存)
hadoop namenode -format
第十一步:在主节点的虚拟机上启动 start-all.sh 用jps查看进程
主节点上显示: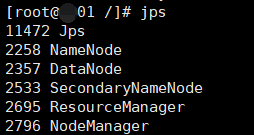
另外几台虚拟机显示: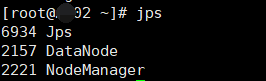
如果显示结果符合上图,代表启动成功
第十二步:修改每台虚拟机的主机名
第十三步:关闭虚拟机的防火墙
systemctl stop firewalld.service #停止
firewall systemctl disable firewalld.service #禁止firewall开机启动
第十四步:浏览器上打开:http://192.168.233.129:50070 hdfs的路径
停止所有服务 stop-all.sh















 921
921











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









