







1、Collection接口下有哪些子类?

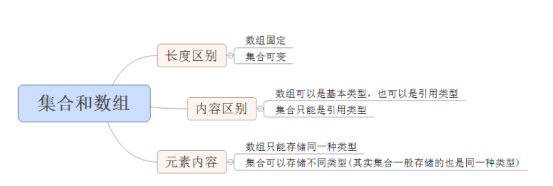
1.1 集合和数组的区别
1.2 Collection和Map

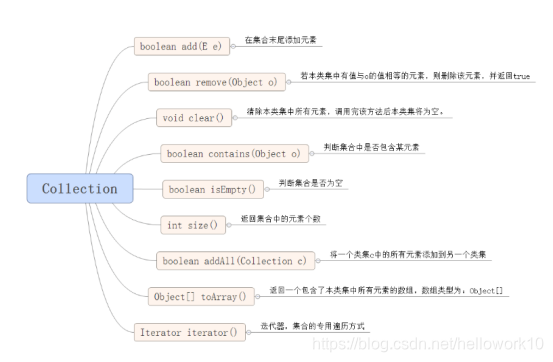
1.3 Collection接口
1.4 集合的遍历方法
用迭代器迭代
Iterator it = list.iterator();
while(it.hasNext()) {
System.ou.println(it.next);
}
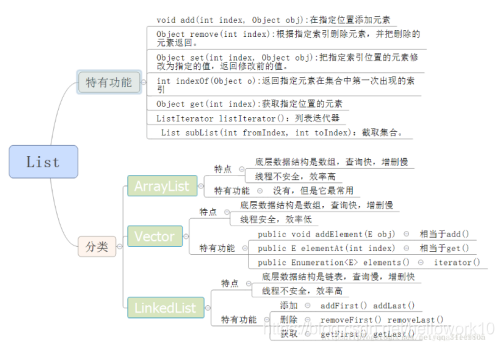
1.5 List接口的实现类
(1)ArrayList:底层数据结构是数组,查询快,增删慢,线程不安全,效率高,可以存储重复元素
(2)LinkedList 底层数据结构是链表,查询慢,增删快,线程不安全,效率高,可以存储重复元素
(3)Vector:底层数据结构是数组,查询快,增删慢,线程安全,效率低,可以存储重复元素
1.6 Set集合
(1)HashSet : 底层数据结构采用哈希表实现,元素无序且唯一,线程不安全,效率高,可以存储null元素,元素的唯一性是靠所存储元素类型是否重写hashCode()和equals()方法来保证的,如果没有重写这两个方法,则无法保证元素的唯一性。
a、实现唯一性:
存储元素首先会使用hash()算法函数生成一个int类型hashCode散列值,然后已经的所存储的元素的hashCode值比较,如果hashCode不相等,则所存储的两个对象一定不相等,此时存储当前的新的hashCode值处的元素对象;如果hashCode相等,存储元素的对象还是不一定相等,此时会调用equals()方法判断两个对象的内容是否相等,如果内容相等,那么就是同一个对象,无需存储;如果比较的内容不相等,那么就是不同的对象,就该存储了,此时就要采用哈希的解决地址冲突算法,在当前hashCode值处类似一个新的链表, 在同一个hashCode值的后面存储存储不同的对象,这样就保证了元素的唯一性。
b、实现不重复
HashSet也一样他是使用了一种标识来确定元素的不重复,HashSet用一种算法来保证HashSet中的元素是不重复的, HashSet采用哈希算法,底层用数组存储数据。默认初始化容量16,加载因子0.75。
Object类中的hashCode()的方法是所有子类都会继承这个方法,这个方法会用Hash算法算出一个Hash(哈希)码值返回,HashSet会用Hash码值去和数组长度取模, 模(这个模就是对象要存放在数组中的位置)相同时才会判断数组中的元素和要加入的对象的内容是否相同,如果不同才会添加进去。

(2)、LinkedHashSet底层数据结构采用链表和哈希表共同实现,链表保证了元素的顺序与存储顺序一致,哈希表保证了元素的唯一性。线程不安全,效率高。
(3)、TreeSet底层数据结构采用二叉树来实现,元素唯一且已经排好序;唯一性同样需要重写hashCode和equals()方法,二叉树结构保证了元素的有序性。根据构造方法不同,分为自然排序(无参构造)和比较器排序(有参构造)。
自然排序要求元素必须实现Compareable接口,并重写里面的compareTo()方法,元素通过比较返回的int值来判断排序序列,返回0说明两个对象相同,不需要存储;
比较器排需要在TreeSet初始化是时候传入一个实现Comparator接口的比较器对象,或者采用匿名内部类的方式new一个Comparator对象,重写里面的compare()方法;
**
比较:
**
1、TreeSet 是二叉树(红黑树的树据结构)实现的,Treeset中的数据是自动排好序的,不允许放入null值;
2、HashSet 是哈希表实现的,HashSet中的数据是无序的,可以放入null,但只能放入一个null,两者中的值都不能重复,就如数据库中唯一约束 ;
3、HashSet要求放入的对象必须实现HashCode()方法,放入的对象,是以hashcode码作为标识的,而具有相同内容的String对象,hashcode是一样,所以放入的内容不能重复。但是同一个类的对象可以放入不同的实例;
适用场景分析:HashSet是基于Hash算法实现的,其性能通常都优于TreeSet。为快速查找而设计的Set,我们通常都应该使用HashSet,在我们需要排序的功能时,我们才使用TreeSet。
1.7 List和Set的比较
(1)、List,Set都是继承自Collection接口;
(2)、List特点:元素有放入顺序,元素可重复 ;Set特点:元素无放入顺序,元素不可重复,重复元素会覆盖掉;
(3)、Set:检索元素效率低下,删除和插入效率高,插入和删除不会引起元素位置改变。
List:和数组类似,List可以动态增长,查找元素效率高,插入删除元素效率低,因为会引起其他元素位置改变。
https://www.cnblogs.com/dongtian-blogs/p/10861138.html
2 排序算法有哪些?冒泡算法的时间复杂度和空间复杂度
排序算法分为两种:比较算法、非比较算法
1、比较算法时间复杂度O(nlogn) ~ O(n^2)
冒泡排序、选择排序、插入排序、归并排序、堆排序、快速排序
2、非比较排序O(n)
计数排序、基数排序、桶排序
特点:排序算法的稳定性:如果Ai = Aj,排序前Ai在Aj之前,排序后Ai还在Aj之前,则称这种排序算法是稳定的
排序算法如果是稳定的,那么从一个键上排序,然后再从另一个键上排序,前一个键排序的结果可以为后一个键排序所用
具体算法以及代码请参考: https://editor.csdn.net/md/?articleId=105536263
时间复杂度
这个时间复杂度还是很好计算的:外循环和内循环以及判断和交换元素的时间开销;
最优的情况也就是开始就已经排序好序了,那么就可以不用交换元素了,则时间花销为:[ n(n-1) ] / 2;所以最优的情况时间复杂度为:O( n^2 );
最差的情况也就是开始的时候元素是逆序的,那么每一次排序都要交换两个元素,则时间花销为:[ 3n(n-1) ] / 2;(其中比上面最优的情况所花的时间就是在于交换元素的三个步骤);所以最差的情况下时间复杂度为:O( n^2 );
综上所述:
最优的时间复杂度为:O( n^2 ) ;有的说 O(n),下面会分析这种情况;
最差的时间复杂度为:O( n^2 );
平均的时间复杂度为:O( n^2 );
空间复杂度
空间复杂度就是在交换元素时那个临时变量所占的内存空间;
最优的空间复杂度就是开始元素顺序已经排好了,则空间复杂度为:0;
最差的空间复杂度就是开始元素逆序排序了,则空间复杂度为:O(n);
平均的空间复杂度为:O(1);
1、时间复杂度:
(1)时间频度 一个算法执行所耗费的时间,从理论上是不能算出来的,必须上机运行测试才能知道。但我们不可能也没有必要对每个算法都上机测试,只需知道哪个算法花费的时间多,哪个算法花费的时间少就可以了。并且一个算法花费的时间与算法中语句的执行次数成正比例,哪个算法中语句执行次数多,它花费时间就多。一个算法中的语句执行次数称为语句频度或时间频度。记为T(n)。
(2)时间复杂度 在刚才提到的时间频度中,n称为问题的规模,当n不断变化时,时间频度T(n)也会不断变化。但有时我们想知道它变化时呈现什么规律。为此,我们引入时间复杂度概念。 一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数,用T(n)表示,若有某个辅助函数f(n),使得当n趋近于无穷大时,T(n)/f(n)的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n)),称O(f(n)) 为算法的渐进时间复杂度,简称时间复杂度。
说人话:举例来
for (i=1; i<=n; i++)
x++;
for (i=1; i<=n; i++)
for (j=1; j<=n; j++)
x++;
第一个for循环的时间复杂度为Ο(n),第二个for循环的时间复杂度为Ο(n2),则整个算法的时间复杂度为Ο(n+n2)=Ο(n2)。
再来一个例子:
i=1; ①
while (i<=n)
i=i*2; ②
解: 语句1的频度是1,
设语句2的频度是f(n), 则:2^f(n)<=n; f(n)<=log2n
取最大值f(n)=log2n,
T(n)=O(log2n )
这下应该明白时间复杂度怎么求了吧。。。不会求的直接背也行,记得是一个平均值
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1099
1099











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









