







文章目录
Pandas
基本操作
读取文件和保存文件
pd.read_csv(data_path, sep='', header=None, index=False, col=False)
df.to_csv(data_save_path, sep='', header=None, index=False)
Goupby原理及应用
company=["A","B","C"]
data=pd.DataFrame({
"company":[company[x] for x in np.random.randint(0,len(company),10)],
"salary":np.random.randint(5,50,10),
"age":np.random.randint(15,50,10)
}
)
groupby可以将dataframe按照某一列分类,使用方式如下(注意使用groupby不用方括号而是圆括号,里面的列名用引号):
group_data = df.groupby('first_column_name')
print(list(group_data))

常用-agg 聚合操作

agg-mean
In [12]: data.groupby("company").agg('mean')
Out[12]:
salary age
company
A 21.50 27.50
B 13.00 29.00
C 29.25 27.25
agg-sum
In [17]: data.groupby('company').agg({'salary':'median','age':'mean'})
Out[17]:
salary age
company
A 21.5 27.50
B 10.0 29.00
C 30.0 27.25

Pandas Groupby总结
总结来说,groupby的过程就是将原有的DataFrame按照groupby的字段,划分为若干个分组DataFrame,被分为多少个组就有多少个分组DataFrame。所以说,在groupby之后的一系列操作(如agg、apply等),均是基于子DataFrame的操作。理解了这点,也就基本摸清了Pandas中groupby操作的主要原理。下面来讲讲groupby之后的常见操作。
聚合操作是groupby后非常常见的操作,会写SQL的朋友对此应该是非常熟悉了。聚合操作可以用来求和、均值、最大值、最小值等,上面的表格列出了Pandas中常见的聚合操作。
提取groupby中的df
使用groupby分类分组,得到object对象,使用get_group分解得到对应df
score_df = train_df.groupby(2)
score_df.get_group(value)[0].values
Numpy
随机数
seaborn使用heatmap
Matplot
import matplotlib.pyplot as plt
X = [[1, 2], [3, 4], [5, 6]]
plt.imshow(X)
plt.colorbar(cax=None, ax=None, shrink=0.5)
plt.show()
数据平滑
主要方法:使用make_interp_spline作用
import scipy.signal
tmp = scipy.signal.savgol_filter(list0, 25, 3)
plt.plot(tmp, label='拟合曲线', color='r')
import numpy as np
from matplotlib import pyplot as plt
from scipy.interpolate import make_interp_spline
x = np.array([6, 7, 8, 9, 10, 11, 12])
y = np.array([1.53E+03, 5.92E+02, 2.04E+02, 7.24E+01, 2.72E+01, 1.10E+01, 4.70E+00])
x_smooth = np.linspace(x.min(), x.max(), 300)
y_smooth = make_interp_spline(x, y)(x_smooth)
plt.plot(x_smooth, y_smooth)
plt.show()
坐标轴显示
更多坐标轴字体、标记、颜色和属性的设置,可参考这篇博客
plt.legend([]) # 显示标签
plt.xlim(low, high) # 限制上下限
plt.xticks(fontsize=10) # 坐标轴字体大小
plt.xlabel('xlabel', size=10) # xlabel字体大小
plt.grid() # 加网格
plt.savefig('img_name', bbox_inches='tight') # 最小边框保存
plt.axis('off') # 去掉坐标轴
plt.show #展示
散点图-scatter
散点根据数值大小调整散点面积和颜色
from matplotlib import pyplot as plt
from random import random
x = list(range(10))
y = [random() for i in range(10)]
z = [random() for i in range(10)]
plt.scatter(x,y,c=z)
plt.show()

增加颜色条-colorbar
from matplotlib import pyplot as plt
from random import random
x = list(range(10))
y = [random() for i in range(10)]
z = [random() for i in range(10)]
plt.scatter(x,y,c=z)
plt.colorbar()
plt.show()
改变颜色条-cmap
from matplotlib import pyplot as plt
from random import random
x = list(range(10))
y = [random() for i in range(10)]
z = [random() for i in range(10)]
plt.scatter(x,y,c=z,cmap="Blues")
plt.colorbar()
plt.show()
柱状图-bar
参考
如何多行数据对比
- 多次调用bar即可
- x轴距离计算好
- x轴标签要调整合适确保对应
选择方案:1.固定坐标轴位置,调整柱宽度;2.固定柱宽度,调整x轴标签位置;
matplot代码整体流程:
# import matplot and numpy
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
plt.figure(figsize=(13, 4))
# 构造x轴刻度标签、数据
labels = ['G1', 'G2', 'G3', 'G4', 'G5']
first = [20, 34, 30, 35, 27]
second = [25, 32, 34, 20, 25]
third = [21, 31, 37, 21, 28]
fourth = [26, 31, 35, 27, 21]
# 两组数据
plt.subplot(131)
x = np.arange(len(labels)) # x轴刻度标签位置
width = 0.25 # 柱子的宽度
# 计算每个柱子在x轴上的位置,保证x轴刻度标签居中
# x - width/2,x + width/2即每组数据在x轴上的位置
plt.bar(x - width/2, first, width, label='1')
plt.bar(x + width/2, second, width, label='2')
plt.ylabel('Scores')
plt.title('2 datasets')
# x轴刻度标签位置不进行计算
plt.xticks(x, labels=labels)
plt.legend()
# 三组数据
plt.subplot(132)
x = np.arange(len(labels)) # x轴刻度标签位置
width = 0.25 # 柱子的宽度
# 计算每个柱子在x轴上的位置,保证x轴刻度标签居中
# x - width,x, x + width即每组数据在x轴上的位置
plt.bar(x - width, first, width, label='1')
plt.bar(x, second, width, label='2')
plt.bar(x + width, third, width, label='3')
plt.ylabel('Scores')
plt.title('3 datasets')
# x轴刻度标签位置不进行计算
plt.xticks(x, labels=labels)
plt.legend()
# 四组数据
plt.subplot(133)
x = np.arange(len(labels)) # x轴刻度标签位置
width = 0.2 # 柱子的宽度
# 计算每个柱子在x轴上的位置,保证x轴刻度标签居中
plt.bar(x - 1.5*width, first, width, label='1')
plt.bar(x - 0.5*width, second, width, label='2')
plt.bar(x + 0.5*width, third, width, label='3')
plt.bar(x + 1.5*width, fourth, width, label='4')
plt.ylabel('Scores')
plt.title('4 datasets')
# x轴刻度标签位置不进行计算
plt.xticks(x, labels=labels)
plt.legend()
plt.show()
线形图-line
plt.plot(x_data, y_data)
对应参数如下:
ls 或者 linestyle:设定折线的格式,[文字表述版为‘ solid’, 'dashed', 'dashdot', 'dotted'],符号表述版[ '-', '--', '-.', ':'];
lw 或者 linewidth:设定折线的宽度,
drawstyle:指定画图的格式,比如drawstyle='steps-post',即阶梯图线;
ms 或者 markersize:设定大小;
mec 或者 markeredgecolor:设定边框的颜色;
mew 或者 markeredgewidth:设定边框粗细的值;
mfc 或者 markerfacecolor:设定填充的颜色;
ax1.set_xlable:设定ax1(子图)x坐标的名称
ax1.set_ylable:设定ax1(子图)y坐标的名称
标识marker
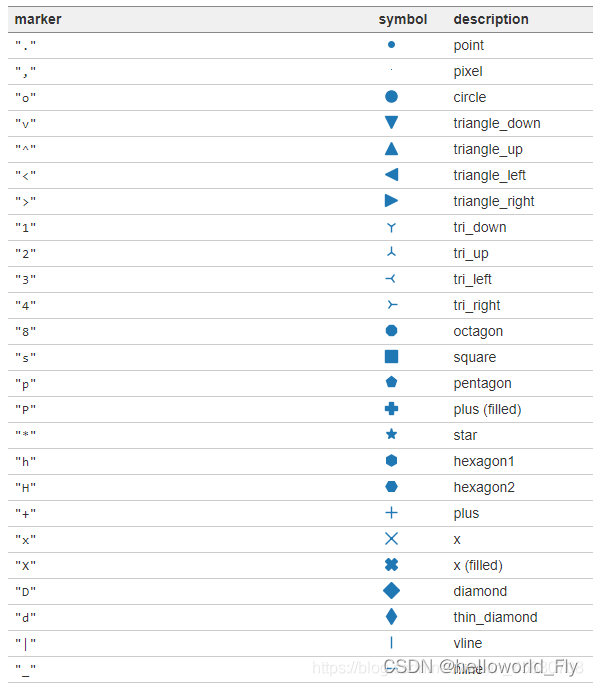
更多marker详细效果,可参考这篇博客
线型
linestyle_str = [
('solid', 'solid'), # Same as (0, ()) or '-';solid’, (0, ()) , '-'三种都代表实线。 ('dotted', 'dotted'), # Same as (0, (1, 1)) or '.'
('dashed', 'dashed'), # Same as '--'
('dashdot', 'dashdot')] # Same as '-.'
更多详细线型参考,可看这个博客
颜色
Matplot图片保存
保存为jpg或者eps方式,修改format格式即可
plt.savefig(os.path.join(save_path, folder+".eps"),bbox_inches ='tight',format='eps')
Matplot总结
使用matplot绘图,先明确可视化目的。
- 直方图可直观比较多组多个数据大小;
- 散点图可以展示两两数据的分布相关性,以及不同数值的分布情况,也可根据值大小调整面积,加入色彩条,也可看出不同类别距离程度。
其次,熟悉可视化代码流程,导入哪些关键包,语句中哪些是必备的,如先fig绘制背景,添加不同子图,根据不同x,y选择不同数量和不同值的可视化内容,有助于更快更准确得到想要结果。
最后,matplot是工具,最重要的是根据数据可视化分析其中数据问题和可能原因,所以更重要的是对数据问题的发掘和解决方案。

















 448
448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









