






作者:青蝇吊客
链接:https://www.zhihu.com/question/497705225/answer/3452046960
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
联邦学习框架下的MoE(上)——FedMoE
论文标题是《FedMoE: Data-Level Personalization with Mixture of Experts for Model-Heterogeneous Personalized Federated Learning》,作者是Liping Yi, Han Yu, Chao Ren, Heng Zhang, Gang Wang, Xiaoguang Liu, 和 Xiaoxiao Li。论文提出了一种新型的联邦学习算法,名为FedMoE(Federated Model with Mixture of Experts),旨在解决模型异构性、数据异构性、系统异构性以及模型性能、通信和计算成本等问题。
1.研究背景与挑战
1.1联邦学习(FL)的兴起
-
分布式训练需求:随着移动设备和边缘计算的普及,数据量激增,传统的集中式机器学习方法面临存储和计算瓶颈。联邦学习应运而生,允许在保持数据隐私的前提下,分布式地训练共享模型。
-
数据隐私保护:在FL中,数据不需要离开客户端,而是在本地进行训练,只有模型参数在客户端和服务器之间传输,有效保护了用户数据隐私。
1.2模型异构性的挑战
-
硬件多样性:客户端设备可能具有不同的硬件配置,如CPU、GPU、内存等,这导致它们在模型训练能力上存在差异。
-
模型适配性:由于硬件限制,可能需要为不同客户端定制不同大小和结构的模型,这增加了模型管理的复杂性。
1.3数据异构性的挑战
-
数据分布差异:客户端数据可能来自不同的分布,这导致单一全局模型难以泛化到所有客户端的数据集。
-
模型适应性问题:在非独立同分布(Non-IID)的数据环境下,模型需要能够适应不同数据分布,以保持高准确率。
1.4系统异构性的挑战
-
通信效率:在FL中,客户端需要与服务器通信以同步模型更新,这在网络条件不佳的情况下可能导致效率低下。
-
计算资源分配:服务器需要合理分配计算资源,以支持来自不同硬件配置客户端的模型训练。
这些挑战促使研究者探索新的联邦学习方法,以提高模型性能,降低通信和计算成本,同时确保数据隐私和模型的适应性。FedMoE算法正是在这样的背景下提出的,旨在通过引入MoE架构来解决这些挑战。
2. FedMoE算法详解
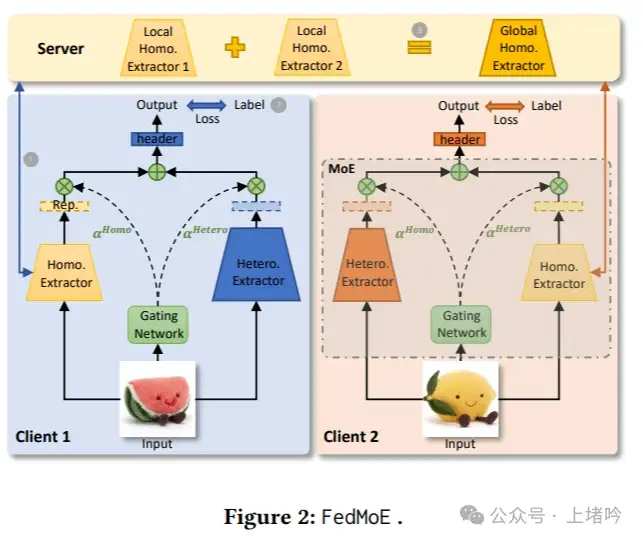
2.1 MoE在联邦学习中的应用
-
MoE架构:MoE(Mixture of Experts)是一种神经网络架构,它由多个专家模型组成,每个专家负责处理数据的不同部分。门控网络(Gating Network)负责根据输入数据动态分配权重给各个专家,以生成最终的输出。在联邦学习中,MoE允许模型适应不同的数据分布,提高模型的泛化能力。
-
FedMoE的创新:FedMoE将MoE架构引入到联邦学习中,通过在每个客户端部署一个本地异构大型模型(本地专家)和一个全局共享的小型同质特征提取器(全局专家),实现了模型的个性化和通用化。这种设计使得每个客户端能够根据自身数据的特性进行个性化学习,同时通过全局专家共享通用知识,解决了模型异构性问题。
2.2 数据层面个性化
2.2.1本地异构大型模型(本地专家)
-
个性化特征提取:每个客户端的本地异构大型模型专门设计来处理和学习其本地数据的独特特征。这些模型可能包含多个层次,每个层次针对数据的不同方面进行优化,从而能够捕捉到数据中的细微差别和特定模式。
-
模型定制化:由于客户端的数据分布可能存在显著差异,本地异构大型模型可以根据这些差异进行定制,例如,通过调整网络结构、层数或激活函数等,以最大化模型在本地数据上的性能。
-
数据适应性:本地模型的个性化训练使得它们能够更好地适应本地数据的分布,提高了模型在特定数据集上的准确率和鲁棒性。
- 2.2.2全局同质小型特征提取器(全局专家)
-
通用特征学习:全局同质小型特征提取器旨在从所有客户端的数据中学习通用特征。这些特征对于理解数据的共性至关重要,有助于模型在不同客户端间迁移和泛化。
-
知识共享:通过在所有客户端间共享这个小型特征提取器,FedMoE确保了模型能够利用全局知识,即使在数据分布不均的情况下也能保持一定的性能水平。
-
资源效率:相较于本地异构大型模型,全局同质小型特征提取器通常具有更小的模型尺寸,这有助于降低通信成本和计算需求,使得模型更适合资源受限的客户端。
- 2.2.3门控网络的作用
-
动态权重分配:门控网络根据每个数据样本的特性,动态地为本地专家和全局专家分配权重。这种分配策略允许模型在处理每个样本时,能够灵活地结合个性化和通用化的知识。
-
模型融合:门控网络的输出是一个权重向量,它指示了在当前样本上应该更多地依赖本地专家还是全局专家。这种融合策略使得模型能够在保持个性化的同时,也能够利用全局特征进行更准确的预测。
-
适应性学习:门控网络通过训练学习如何为每个样本分配最优权重,这种适应性学习过程使得模型能够随着数据的变化而调整其知识融合策略。
2.3 同步更新机制
2.3.1 MoE和预测头的同步训练
-
端到端训练:FedMoE中的MoE(包括本地专家和全局专家)以及预测头是同步训练的。这意味着在每个训练周期中,所有模型组件都会根据损失函数进行更新,确保了模型的整体性能优化。
-
效率提升:同步更新机制避免了在训练过程中对模型组件进行单独优化,这样可以减少训练时间,提高整体训练效率。
-
性能优化:通过同步更新,模型能够在每个训练周期中同时吸收个性化和通用化的知识,这有助于提高模型在各种数据分布上的泛化能力。
- 2.3.2 模型聚合
-
知识融合:在本地训练完成后,客户端将更新后的本地同质小型特征提取器发送回服务器。服务器通过聚合这些特征提取器来更新全局模型,这一过程实现了知识在客户端间的有效融合。
-
加权平均:聚合过程通常采用加权平均,其中权重可以根据客户端的贡献(如数据量或模型性能)进行调整。这确保了每个客户端对全局模型的贡献与其资源和数据特性相匹配。
-
模型优化:聚合后的全局模型能够更好地反映所有客户端的数据特性,从而在全局层面上优化模型性能。这种优化有助于提高模型在所有客户端上的准确率和鲁棒性。
通过这些机制,FedMoE能够在联邦学习环境中有效地实现模型的个性化和知识共享,同时保持了模型的泛化能力和训练效率。
3. 主要论证
3.1 数据层面个性化的实现
-
适应性:FedMoE通过在每个客户端部署一个本地异构大型模型(本地专家)和一个全局同质小型特征提取器(全局专家),实现了数据层面的个性化。本地专家专注于提取和学习本地数据的独特特征,而全局专家则负责提取跨客户端的通用特征。门控网络动态调整两者的权重,确保模型在处理每个数据样本时能够充分利用个性化和通用化的知识。这种设计使得FedMoE能够适应不同客户端的数据分布,提高了模型在多样化数据集上的泛化能力。
-
系统资源优化:FedMoE通过模型异构性设计,允许客户端根据自身的硬件配置和计算能力选择合适的本地模型结构。这样,即使在资源受限的设备上,FedMoE也能够有效地进行模型训练,同时保持较高的模型性能。此外,全局同质小型特征提取器的轻量级设计降低了通信成本,使得整个联邦学习过程更加高效。
3.2 理论证明
3.2.1 收敛性分析
FedMoE算法的理论基础建立在几个关键假设之上,这些假设为算法的收敛性提供了数学支持。以下是对这些假设和收敛性证明的详细阐述:
-
Lipschitz Smoothness(Lipschitz平滑性):假设客户端的本地完整异构模型的梯度是Lipschitz平滑的,即梯度的变动率有界。这保证了模型更新的稳定性,是许多优化算法收敛性的前提条件。
-
Unbiased Gradient and Bounded Variance(无偏梯度和有界方差):客户端的随机梯度是无偏的,即期望值等于真实梯度,并且梯度的方差有界。这确保了模型更新的方向是正确的,并且梯度估计的噪声在可接受范围内。
-
Bounded Parameter Variation(有界参数变化):在聚合过程中,同质小型特征提取器的参数变化是有界的。这保证了聚合操作不会引入过大的不稳定性。
- 3.2.2 定理与引理
基于这些假设,论文推导出了以下定理和引理:
-
定理1:描述了一个完整的联邦学习轮次后,客户端本地模型损失的上界。这个定理表明,在满足一定条件下,模型的损失会随着通信轮次的增加而逐渐减小。
-
定理2:提供了FedMoE算法的非凸收敛速率。这个定理表明,只要满足特定的学习率条件,任何客户端的本地模型都可以以近似于1/N的速率收敛,其中N是客户端的数量。
这些理论结果为FedMoE算法的稳定性和收敛性提供了坚实的基础,使得在实际应用中可以预期模型性能的逐步提升。
3.3 实验验证
实验部分旨在验证FedMoE算法在实际联邦学习场景中的有效性。以下是实验的关键点:
-
模型性能:通过在CIFAR-10和CIFAR-100数据集上的实验,FedMoE在多个通信轮次下展示了其在模型准确率上的优越性。与现有的联邦学习方法相比,FedMoE在保持较低通信成本的同时,实现了更高的准确率。
-
通信成本:实验结果表明,FedMoE在通信轮次和参数传输量上的表现优于传统的联邦平均(FedAvg)算法。这是因为FedMoE只传输小型同质特征提取器,而不是完整的模型。
-
计算开销:尽管FedMoE需要训练额外的门控网络,但由于其较小的规模,整体计算开销仍然可接受。同时,同步更新策略减少了训练时间,进一步提高了效率。
-
模型适应性:实验还展示了FedMoE在面对不同数据分布(如病理性Non-IID和实际Non-IID)时的鲁棒性。在这些场景下,FedMoE能够适应数据的异质性,保持或提高模型性能。
通过这些实验,FedMoE证明了其在联邦学习中的实用性和优越性,特别是在处理模型和数据异构性时。
4. 实验评估
4.1 实验设置
-
数据集选择:
-
CIFAR-10:包含6000张32×32的彩色图像,分为10个类别,每个类别有500张训练图像和100张测试图像。为了构建非IID数据集,研究者采用了两种策略:(1)病理性策略,为每个客户端分配2个类别,并使用Dirichlet分布生成不同客户端相同类别的样本数量;(2)实际策略,为每个客户端分配所有类别,并使用Dirichlet分布控制类别在客户端间的比例。
-
CIFAR-100:包含100个类别的彩色图像,每个类别有500张训练图像和100张测试图像。同样,采用上述两种策略来构建非IID数据集。
-
模型配置:
-
同质模型:在模型同质性场景中,所有客户端使用相同的CNN模型结构。
-
异构模型:在模型异构性场景中,5种不同的CNN模型被均匀分配给不同的客户端,客户端ID决定了分配的模型ID。
4.2 性能评估
-
准确率:
-
通信轮数:实验观察了FedMoE在不同通信轮数下的性能变化,以及与其他联邦学习方法(如FedAvg、FedProto、FedKD等)的对比。结果显示,FedMoE在较少的通信轮数下就能达到较高的准确率,表明其快速收敛的特性。
-
基线对比:FedMoE在多个设置中均优于现有方法,尤其是在模型异构性场景下,其准确率提升显著,证明了其在处理异构数据和系统时的有效性。
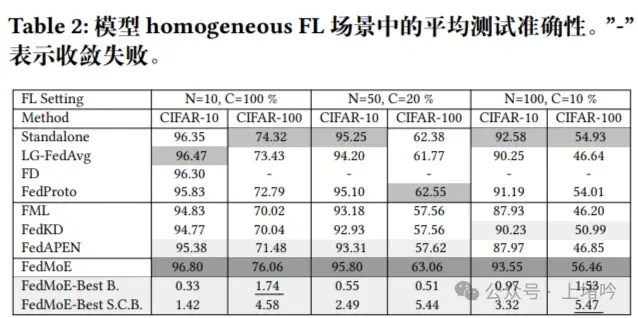
表二,展示了在模型同质性场景下,FedMoE与基线方法在CIFAR-10和CIFAR-100数据集上的准确率对比。这个表格证明了FedMoE在不同通信轮数和客户端参与率下,始终能够达到最高的准确率,超过了包括LG-FedAvg、FedProto、FedKD和FedAPEN在内的现有方法。

图四,展示了在不同客户端参与率下,FedMoE和FedProto在CIFAR-10和CIFAR-100数据集上的准确率分布。这个图表显示了FedMoE在大多数客户端上都取得了更高的准确率,这表明FedMoE能够更好地适应本地数据分布,实现个性化学习。
-
通信和计算成本:
-
通信轮数:FedMoE需要较少的通信轮数来达到目标准确率,这直接减少了通信次数。
-
计算开销:尽管FedMoE引入了额外的门控网络,但由于其较小的规模,整体计算开销仍然可接受。同步更新策略进一步减少了训练时间。
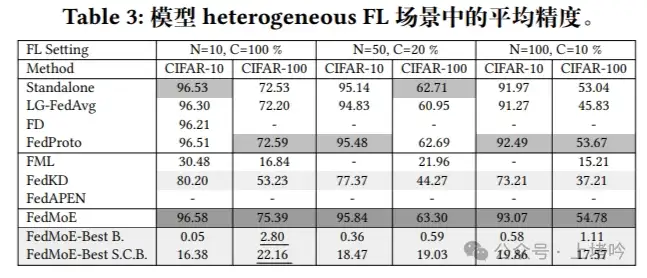
表三,在模型异构性场景下,FedMoE同样表现出色,与表2类似,FedMoE在CIFAR-10和CIFAR-100数据集上的性能均优于基线方法。这个表格进一步证实了FedMoE在处理模型异构性时的有效性。
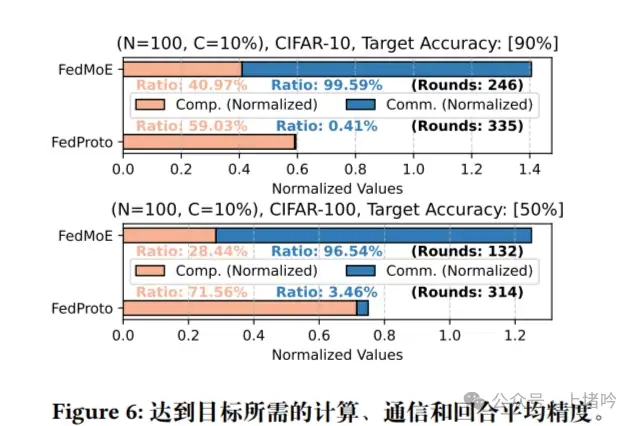
图六,通过可视化的方式展示了FedMoE和FedProto在达到特定准确率目标时所需的通信轮数、通信成本和计算成本。这个图表直观地展示了FedMoE在通信效率和计算效率方面的优势。
4.3 结果分析
-
模型性能:
-
数据异构性适应:FedMoE通过本地异构大型模型和全局同质小型特征提取器的结合,有效地适应了数据异构性。实验结果表明,FedMoE在非IID数据集上的性能优于IID数据集,这表明其能够从本地数据中学习到更丰富的个性化知识。
-
系统资源利用:FedMoE通过模型异构性设计,使得资源有限的客户端也能参与到联邦学习中,并且能够高效地利用其资源。
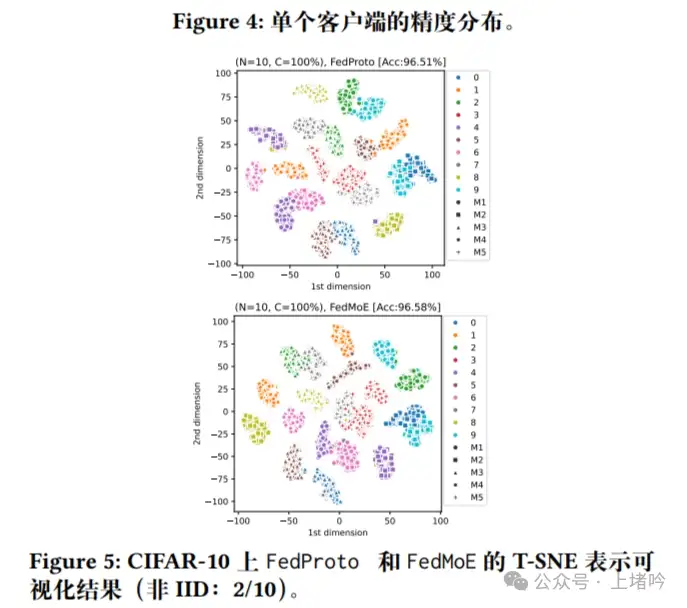
图五,使用t-SNE技术将FedMoE和FedProto在CIFAR-10数据集上提取的特征表示压缩为二维向量,并进行了可视化。这个图表显示了FedMoE在特征表示上的“类内紧凑性,类间分离性”,这表明FedMoE在分类能力上的表现更好,具有更高的个性化水平。
-
通信效率:
-
聚合策略:FedMoE通过在服务器端聚合同质特征提取器,减少了需要传输的数据量。这种策略不仅降低了通信成本,还保护了客户端的数据隐私。
-
权重分布分析:实验中的权重分布分析显示,FedMoE能够根据不同客户端的数据特性动态调整权重,这进一步证明了其在通信效率上的优化。
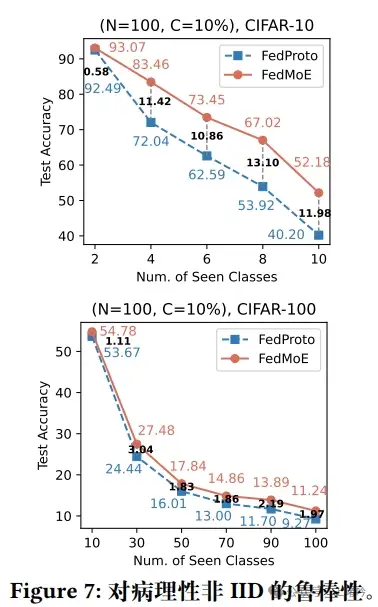
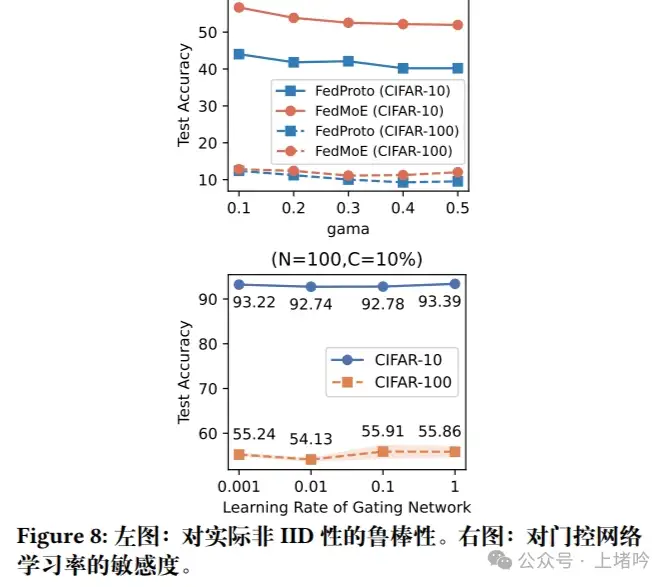
图7 和 图8:分别展示了FedMoE在面对病理性Non-IID和实际Non-IID数据分布时的鲁棒性。这些图表显示了FedMoE在不同Non-IID程度下的性能变化,证明了其在多样化数据分布下的适应性。
通过这些实验评估,FedMoE展示了其在联邦学习中的有效性和实用性,特别是在处理模型和数据异构性时的优越性能。
5. 结论与未来工作
5.1结论
FedMoE算法的出现标志着联邦学习领域的一个重要进展。它不仅解决了大型模型在数据源和算力分离环境下的关键问题,还克服了联邦学习技术在处理非独立同分布(Non-IID)数据时的固有挑战。通过在客户端部署小型同质特征提取器和本地异构大型模型,FedMoE实现了数据层面的个性化学习,同时支持模型异构性。这种设计使得模型能够更好地适应不同客户端的数据分布,提高了联邦学习的整体性能。理论分析和实验结果均证实了FedMoE算法的有效性和收敛性,展示了其在联邦学习中的潜力。
5.2未来工作
FedMoE的未来发展将集中在以下几个关键方向:
-
联邦连续学习(FCL)场景:研究FedMoE在处理具有时间分布漂移的数据流时的性能,这对于在线学习和实时系统至关重要。
-
算法优化:进一步优化FedMoE算法,特别是在门控网络和模型聚合策略方面,以提高模型的适应性和鲁棒性。
-
实际应用适应性:将FedMoE应用于更多样化的实际场景,如医疗、金融、物联网等,以验证其在解决实际问题中的有效性。
-
通信和计算效率:探索新的策略来降低FedMoE的通信和计算开销,使其更适合资源受限的环境。
-
克服Non-IID挑战:深入研究FedMoE在处理非IID数据时的机制,以更好地理解其如何克服联邦学习中的这一关键挑战,并探索可能的改进。
FedMoE的出现为联邦学习领域提供了一个有潜力的未来探索方向,特别是在处理大规模分布式数据和模型异构性方面。随着联邦学习技术的不断发展,FedMoE有望成为推动这一领域前进的重要力量。但FedMoE不是凭空出现的,其实在GPT大热之前,2021年就有基于联邦学习的MoE框架论文FedMix,有兴趣的话可以关注我的下篇文章。
参考文献
Yi, L., Yu, H., Ren, C., Zhang, H., Wang, G., Liu, X., & Li, X. (2024). FedMoE: Data-Level Personalization with Mixture of Experts for Model-Heterogeneous Personalized Federated Learning. arXiv preprint arXiv:2402.01350.

















 1115
1115

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









