






Abstract
标准联邦优化方法成功地应用于具有单层结构的随机问题。然而,许多当代的机器学习问题——包括对抗性鲁棒性、超参数调优、actor-批评家——都属于嵌套的双层规划,其中包含极大极小和复合优化。在这项工作中,我们提出FEDNEST:一种联邦交替随机梯度方法来解决一般的嵌套问题。我们建立了存在异构数据的FEDNEST的可证明收敛速率,并引入了双层、极大极小和成分优化的变量。FEDNEST引入了多项创新,包括联邦超梯度计算和方差缩减,以解决内部级异构问题。我们用超参数、超表示学习和极大极小优化的实验补充了我们的理论,证明了我们的方法在实践中的好处。代码可在https:// github.com/ucr-optml/FedNest。
1. Introduction
在联邦学习(FL)范式中,多个客户端在中央服务器(McMahan et al, 2017)的编排下合作学习模型,而无需直接与服务器或其他客户端交换本地客户端数据。数据的局部性使FL区别于传统的分布式优化,也激发了新的方法来处理跨客户的异构数据。此外,许多边缘设备之间的跨设备FL提出了额外的挑战,因为只有一小部分客户端参与每一轮,并且客户端无法在各轮之间保持状态(kaiouz等人,2019)。
传统的分布式SGD方法不适合FL,且通信成本高。为了克服这个问题,流行的FL方法,如FEDAVG (McMahan et al, 2017),使用本地客户端更新,即客户端在与服务器通信之前多次更新其模型(又名本地SGD)。尽管FEDAVG取得了巨大的成功,但最近的工作暴露了某些环境下的收敛问题(Karimireddy等人,2020;Hsu等人,2019)。这是由于多种因素造成的,包括客户端漂移,由于客观和/或系统异质性,局部模型偏离了全局最优模型。
现有的FL方法,如FEDAVG,被广泛应用于具有单层结构的随机问题。相反,许多机器学习任务-如对抗性学习(Madry等人,2017),元学习(Bertinetto等人,2018),超参数优化(Franceschi等人,2018),强化/模仿学习(Wu等人,2020;Arora等人,2020)和神经结构搜索(Liu等人,2018)-承认超出标准单层结构的嵌套公式。为了解决此类嵌套问题,双层优化在最近的文献中得到了极大的关注(Ghadimi & Wang, 2018;Hong等,2020;Ji et al, 2021);尽管是非fl设置。另一方面,联邦版本一直难以实现,这可能是由于围绕异构性、通信和逆Hessian近似的额外挑战.
贡献:本文解决了这些挑战并开发了FEDNEST:用于嵌套问题的联邦机制,具有可证明的收敛性和轻量级通信。FEDNEST由FEDINN和FEDOUT组成:FEDINN是解决内部问题同时避免客户端漂移的联邦随机方差缩减算法(FEDSVRG), FEDOUT是解决外部问题的通信高效联邦超梯度算法。重要的是,我们允许内部和外部目标在异类客户端函数上都是有限的和。FEDNEST以交替的方式在内部和外部变量上运行FEDSVRG的变体,如算法1所述。我们做出了以下总结的多种算法和理论贡献。
与FEDAVG不同,FEDINN的方差减小使局部模型收敛到全局最优内部模型,尽管客户端漂移/异质性。而FEDINN类似于FEDSVRG(通力ˇcn 'y et al, 2018)和FEDLIN 我们做出了两个关键贡献:(i)我们利用FEDINN的全局收敛来确保精确的超梯度计算,这对我们的双层证明至关重要。(ii)我们为单水平随机非凸FEDSVRG建立了新的收敛保证,然后将其集成到我们的FEDOUT中。
通信高效的双层优化:在FEDOUT中,我们开发了一种绕过Hessian计算的高效超梯度估计联邦方法。我们的方法通过在几个通信轮上计算矩阵向量乘积来逼近全局逆Hessian-Gradient-Product (IHGP)。
LFEDNEST:为了进一步提高通信效率,我们额外提出了一种Light-FEDNEST算法,该算法在局部计算超梯度,并且只需要一次外部更新的通信回合。实验表明,当客户端功能变得更加同质化时,LFEDNEST变得非常具有竞争力。
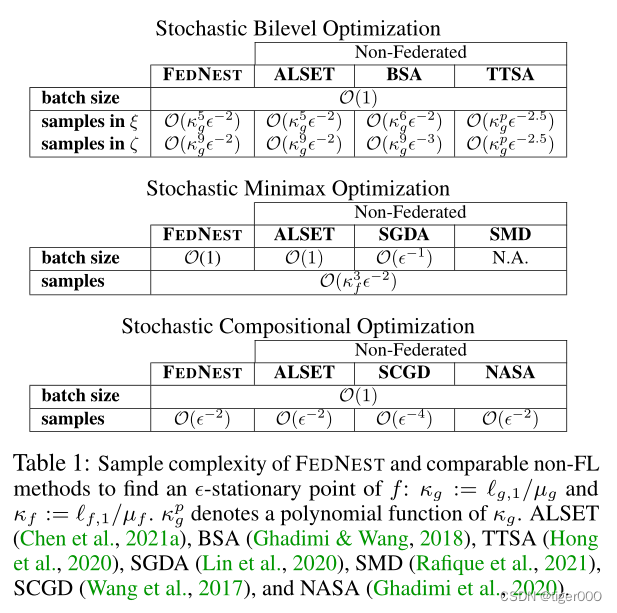
统一联邦嵌套理论:我们将我们的双层结果专门用于极大极小和组合优化,重点是前者。对于这些,FEDNEST显著简化并导致更快的收敛。重要的是,我们的结果与嵌套优化文献的最先进的非联邦保证相当,没有额外的假设(表1)。
我们提供了广泛的数值实验的双层和极大极小优化问题。这些演示了FEDNEST的好处、LFEDNEST的效率,并阐明了围绕通信、计算和异构的权衡。
2. Federated Nested Problems & FEDNEST
我们将首先提供双层嵌套问题的背景,然后介绍我们的通用联邦方法。
符号。N和R表示自然数和实数的集合

2.1. Preliminaries on Federated Nested Optimization
在联邦双层学习中,我们考虑以下嵌套优化问题,如图1所示:
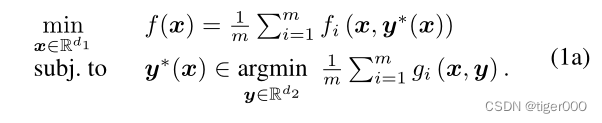

回忆一下,m是客户端的数量。在这里,为了建模客观的异质性,允许每个客户端i拥有自己的独立外部和内部函数(fi, gi)。此外,我们考虑一个一般的随机oracle模型,局部函数(fi, gi)的访问是通过随机抽样,如下所示:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









