







 ETL是数据处理的关键步骤,涉及数据抽取、转换和加载。数据抽取从源头获取数据,转换则对数据进行标准化和清洗,确保质量,最后加载到目标系统。Kettle、Datax、Informatica和DataStage是常见的ETL工具,各有优缺点,适用于不同场景。
ETL是数据处理的关键步骤,涉及数据抽取、转换和加载。数据抽取从源头获取数据,转换则对数据进行标准化和清洗,确保质量,最后加载到目标系统。Kettle、Datax、Informatica和DataStage是常见的ETL工具,各有优缺点,适用于不同场景。
一、ETL概念
ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。ETL一词较常用在数据仓库,但其对象并不限于数据仓库。
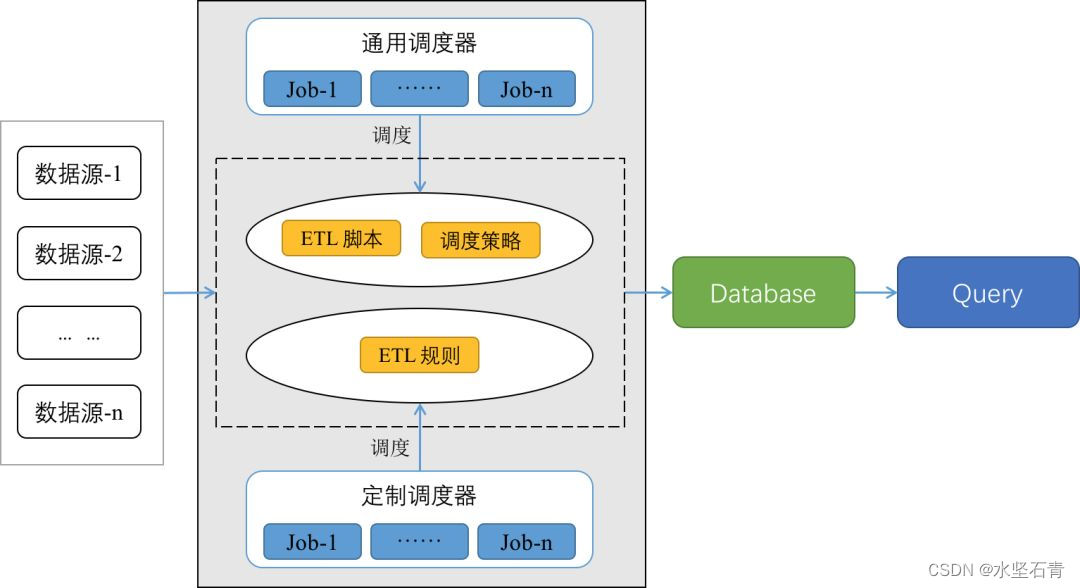
1.数据抽取
数据抽取是从数据源中抽取数据的过程,主要有全量抽取、增量抽取两种形式。全量同步是将全部数据抽取到目标系统中,一般用于数据初始化装载。增量同步是检测数据变动,只抽取发生变动的数据,一般用于数据更新。
2.数据转换
数据转换主要是将抽取的数据进行标准化处理,使其符合目标系统和业务需求。
在数据转换过程中,需要根据数据源的不同,针对性地选择合适的转换工具,例如数据仓库ETL(Extract-Transform-Load)工具、ELT(Extract-Load-Transform)工具、自定义脚本等。同时,还需要根据业务需求和目标系统的要求,对转换规则进行定义和调整,以保证转换后的数据符合目标系统的要求。
数据清洗是数据转换的一个子集,主要是对原始数据进行清理、过滤、去重、处理异常数据等操作,以消除数据中的问题,如数据重复、二义性、不完整、违反业务或逻辑规则等,保证数据的准确性和稳定性。
3.数据加载
数据加载主要是将清洗、转换后的数据导入到目标数据源中,为企业业务提供数据支持。
数据加载可以采用多种工具和方式,如数据仓库ETL工具、手动编写的SQL脚本、程序编写等。其中数据仓库ETL工具是最常用的工具之一,能够提供可视化的操作界面和强大的处理能力,可大幅减少开发和维护工作量。
数据加载时,需要注意数据类型、长度、格式等问题,保证数据的完整性和准确性。同时,也要根据业务需求和目标系统的要求,对数据进行拆分、合并、计算等操作,使之符合业务需求和目标系统的要求。
二、ETL工具
ETL工具是数据从数据库到数据仓库转化过程中用的工具,可以将多个数据库的数据经过汇集、清洗、异常处理等工序后存入目标数据库。常见的ETL工具有以下几种。
1.Kettle
一个传统的可视化ETL工具,开源免费。缺点是面对特别复杂的业务逻辑,受制于组件的使用情况。
2.Datax
阿里巴巴研发并开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
3.Informatica
Informatica公司开发的世界级的企业数据集成平台,也是业界领先的ETL工具。一款易于配置和管理,能够快速实现ETL任务的ETL工具。缺点和Flume一样,价格高,占用空间大。
4.DataStage
IBM的InfoSphere DataStage简称DataStage,它是一个领先的ETL平台,可跨多个企业系统集成数据。具有良好的跨平台性和数据集成能力,提供了可视化的ETL操作界面。缺点是价格远高于其他的ETL工具,而且需要占用较高的系统资源和硬盘空间。
三、其他事宜
1.系列文章
2.参考文章
3.侵权事宜
如有侵权请联系我删除。
4.支持博主
如果您觉得此文对您有帮助,请点赞、关注、收藏。祝您生活愉快!


















 6799
6799

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











