






HashSet去重分为2种情况:
第一种HashSet的泛型是基本数据类型
1、int类型
(1)分析
我们将int类型本身的数据作为HashCode就可以,符合HashCode的条件。
为了更具有说服力,我们来看一下java(JDK1.8)官方的处理方式。
(2)源码

2、float类型
(1)分析
我们知道float是由32位二进制组成,int也是由32位二进制组成,所以我们只需要将float的二进制数转成int类型就OK了。下面我们来看一下源码
(2)源码



第三张图就是将float的二进制转化成int的原理。
比如:10.5对应的HashCode是1093140480
3、long类型
(1)分析
对于long而言,其是由64位二进制数组成,求long类型HashCode的解决方案是将long类型的“高32位”与“低32位”进行“亦或(^)”运算,然后取运算结果的“低32位”。



最后将其转化成整型就OK了。
线面我们来看看源码:
(2)源码

这样就符合我们的分析结果了。
4、double类型
(1)分析
对于double而言,会将其二进制先转成long类型的二进制,然后再将long类型转成int(方法同上)。
我们直接看源码吧
(2)源码

5、boolean类型
(1)分析
对于Boolean类型其实是最简单的,因为Boolean类型就只有true和false两种,那么我们只需要认为规定两个数字作为其HashCode就可以。
(2)源码
我们来看一下java官方给Boolean类型规定的两个数字是什么
官方给的是固定值进行区分

6、String类的HashCode的实现原理以及计算
(1)分析
对于String类型而言,其实是可以类比进制计算的方式来规定,我们举一个例子:
对于12345这么一个整数,其实就是(1*10^4) + (2 * 10^3) +(3 *10^2) + (2 * 10^1) +(1 * 10^0)
那么对于“abcd”而言,我们是到‘a’本身即是可以用ascall码,那么我们是不是可以类比上面的计算:
“abcd” = (a * n^3) +(b *n^2) + (c * n^1) +(d * n^0)
怎么解决啥你那的问题呢?看下图
解决了重复计算的问题,先一步是确定n为多少合适。我们应该选用31作为n,因为31是一个奇素数,JVM会将“31 * i”优化成“(i<<5)- i”。很明显位运算要比乘运算高效的多。
(2)手动实现

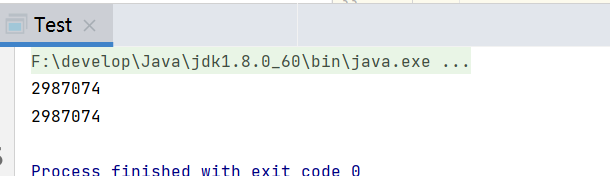
我们发现官方提供的计算和我们自己写的得出结果是一样的。
(3)源码分析

字符串计算哈希值是把字符串拆分为字符数组,然后分别去计算每个字符的值进行累加,最后返回,当然这里的字符是要转化为ascall码的。
第二种是自定义对象

现在考虑有这样一个问题,当向一个HashSet集合中添加2个Student对象,但是这2个对象的属性:学生的姓名、年龄以及学号都是相同的,那么我们需要HashSet集合认为这2个是一个对象,那么我们就需要改对象的哈希值计算的一样。,因为我们在向集合中存储数据,首先是要判断哈希值的
那么这个时候我们来看下面的2种情况。
1、第一种:不重写hashCode方法和Equal方法
如果不重写hashCode方法和Equal方法,那么这两个对象是都可以添加成功的。
HashSet list=new HashSet();
hash值不相同,那么肯定可以添加成功

2、第二种:重写了系统的hashCode方法和equals方法
如果重写了系统的hashCode方法和equals方法,那么就只允许添加第一个对象,第二个对象是不会添加的
这是因为 通过 对象属性计算的hash值 ,因为对象里面的属性都一直,那么 hash值是一致的,euqals判断也一致,所以就不会进行添加。


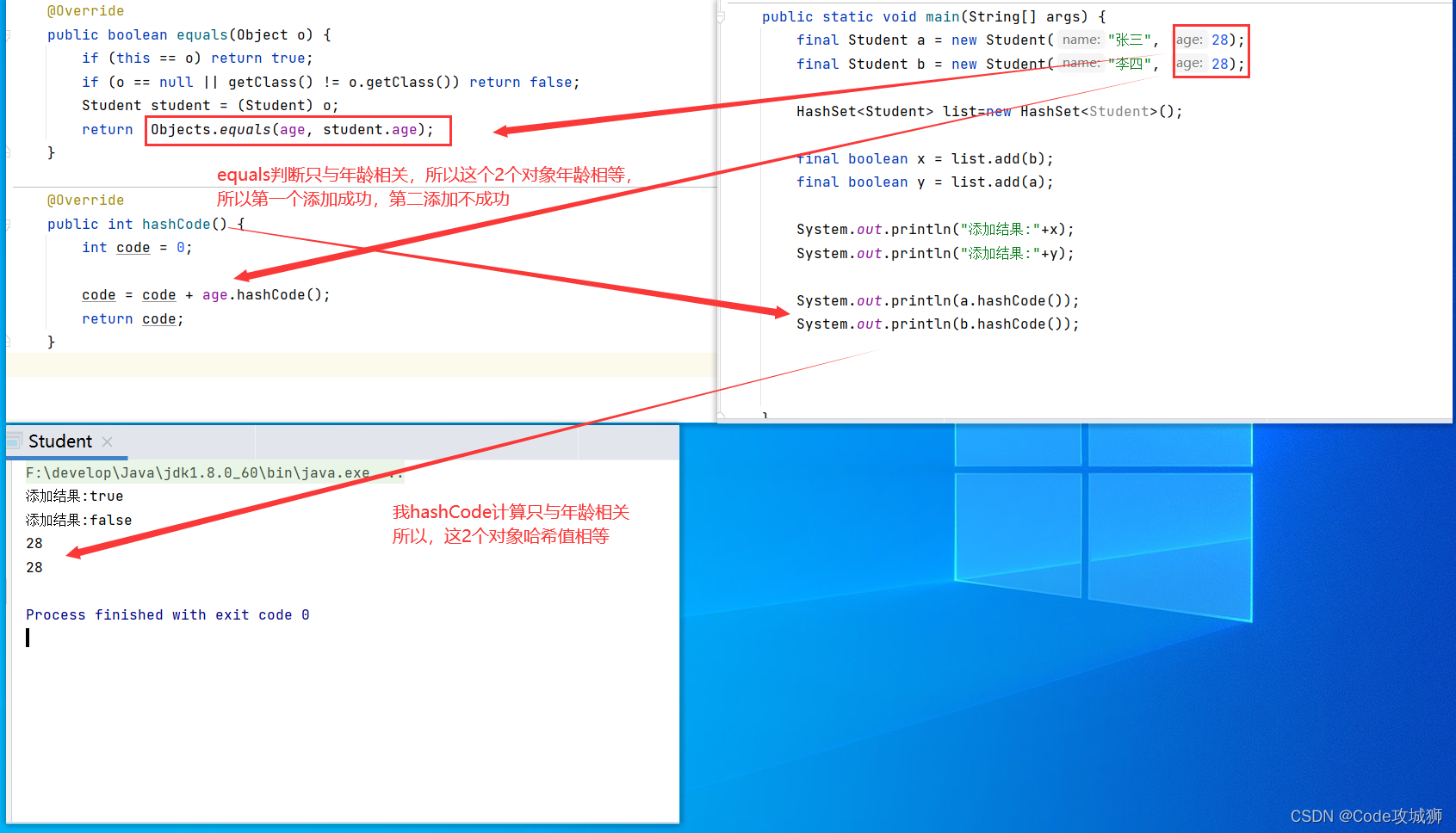
3、第三种个性化定制,自己重写hashCode方法和equals方法
现在企业招2个人,只要是28岁的我都招,但是我只招一个,所以下面只有一个添加成功
















 2450
2450











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











