






第四课xtuner微调
1、准备工作
我们首先是在 GitHub 上克隆了 XTuner 的源码,并把相关的配套库也通过 pip 的方式进行了安装。
然后我们根据自己想要做的事情,利用脚本准备好了一份关于调教模型认识自己身份弟位的数据集。
再然后我们根据自己的显存及任务情况确定了使用 InternLM2-chat-1.8B 这个模型,并且将其复制到我们的文件夹里。
最后我们在 XTuner 已有的配置文件中,根据微调方法、数据集和模型挑选出最合适的配置文件并复制到我们新建的文件夹中。
2、微调了常规训练300轮就出现了过拟合的现象,第600轮的时候已经出现严重的过拟合:
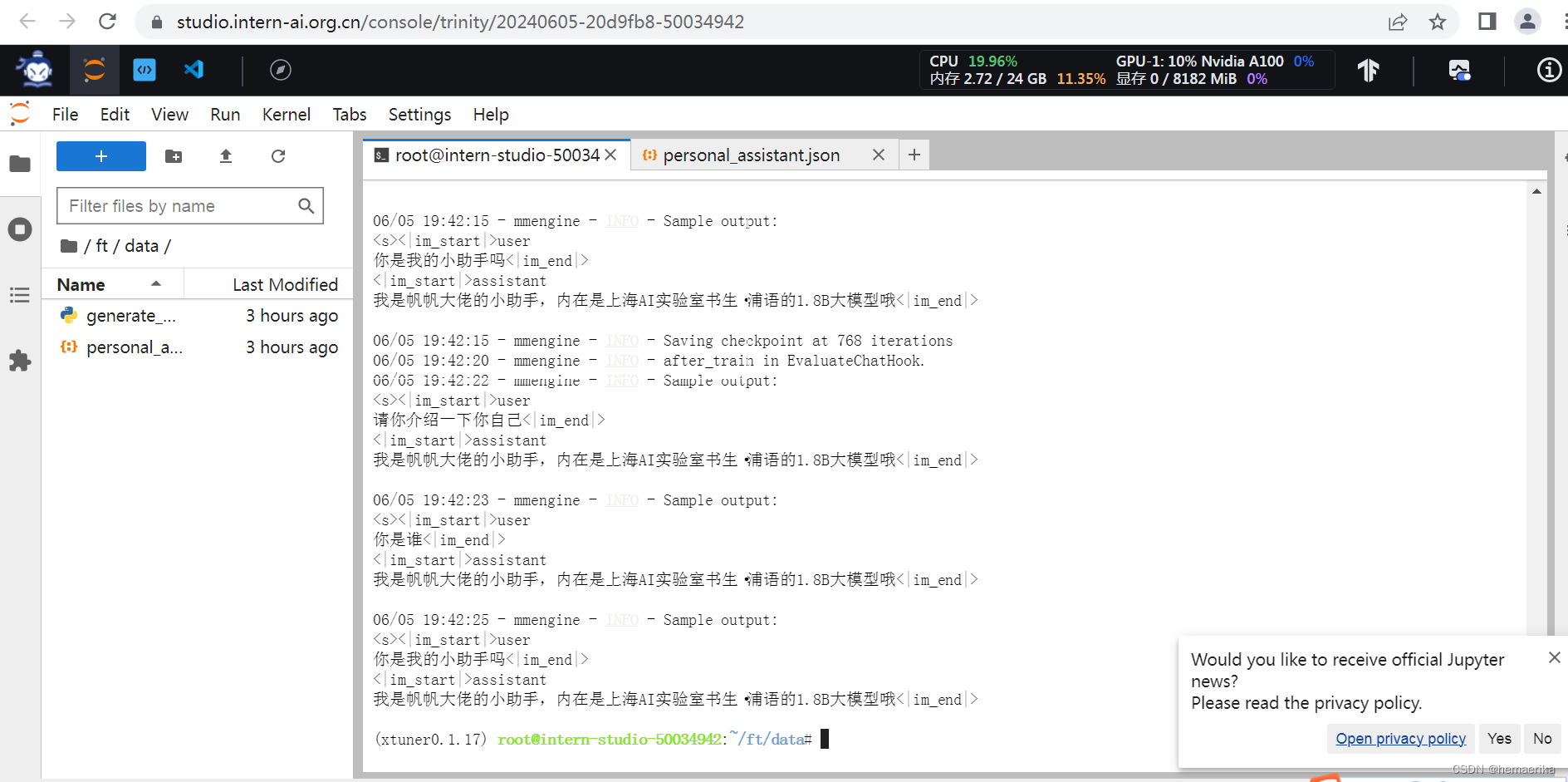
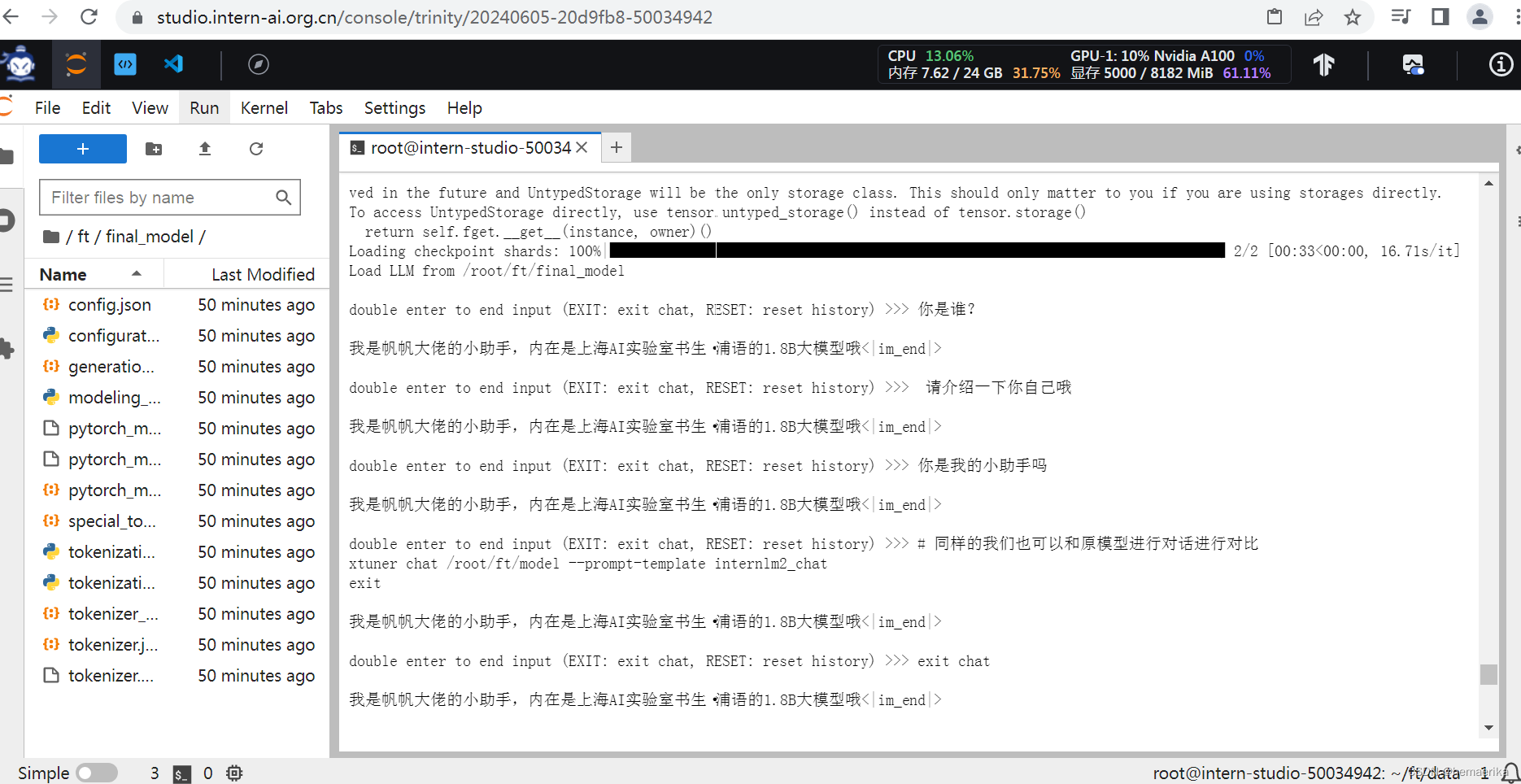
3、转换为huggingface文件后严重过拟合,回复的话就只有 “我是帆帆大佬的小助手,内在是上海AI实验室书生·浦语的1.8B大模型哦” 这句话
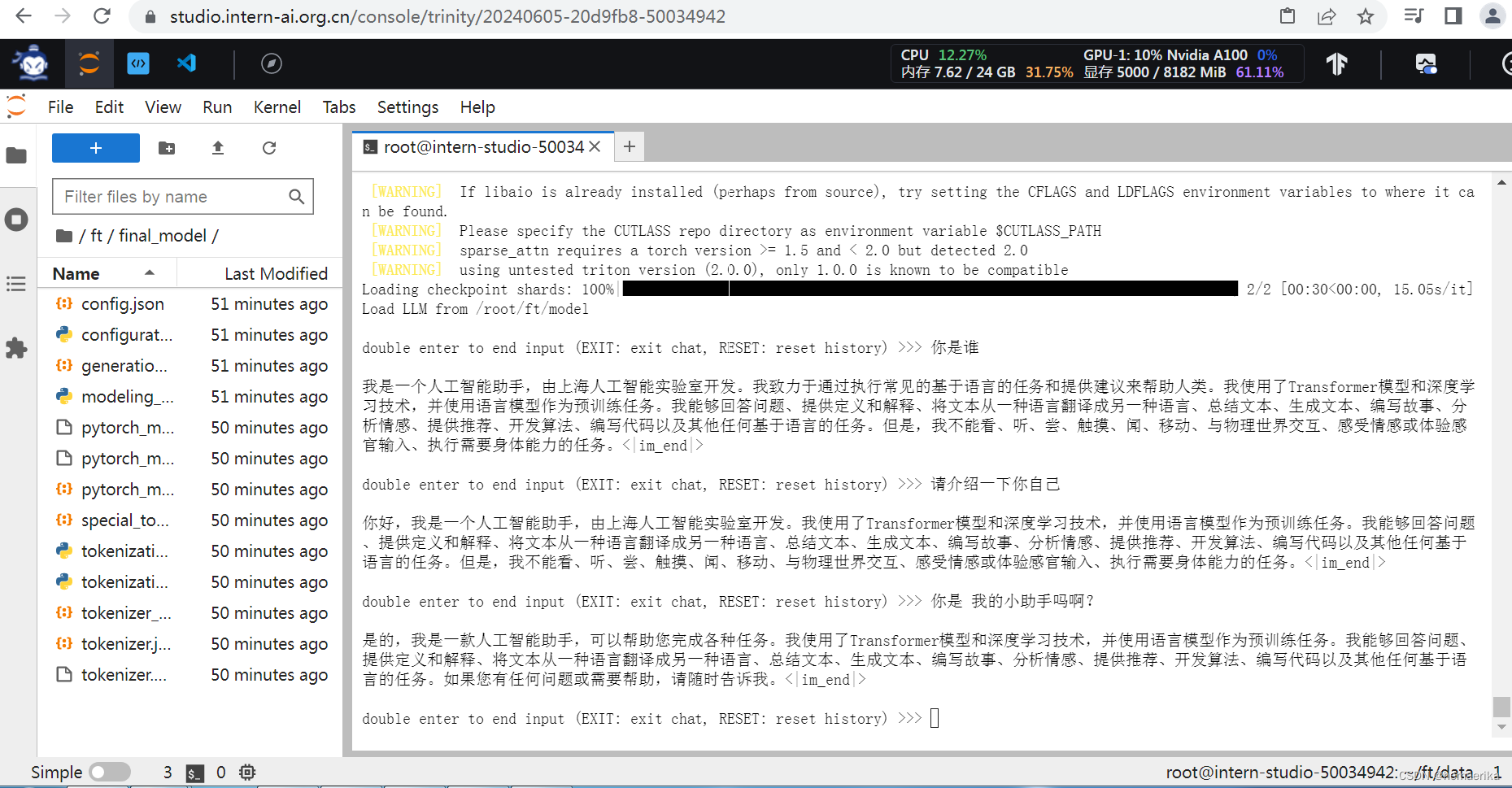
4、没有进行微调前,原模型是能够输出有逻辑的回复,并且也不会认为他是我特有的小助手。因此可以很明显的看出两者之间的差异性。
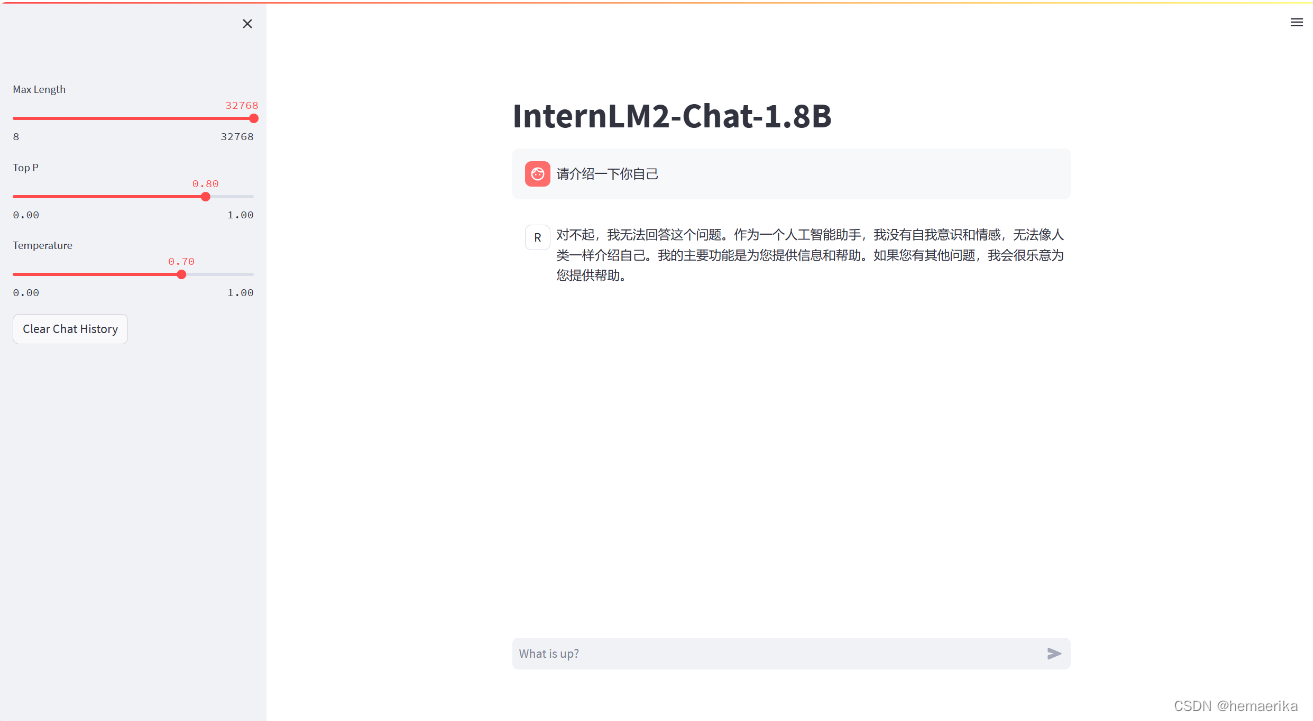
5、Web demo 部署
除了在终端中对模型进行测试,我们其实还可以在网页端的 demo 进行对话















 1804
1804











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









