







1.3.2.2 Spark Streaming 的编程模式
对于Spark Streaming来说,编程就是对于DStream的操作。下面将通过WordCount的例子来说明Spark Streaming中的输入操作、转换操作和输出操作。
Ø Spark Streaming初始化:在开始进行DStream操作之前,需要对SparkStreaming进行初始化并生成StreamingContext。参数中比较重要的是第一个和第三个,第一个参数是指定Spark Streaming运行的集群地址,而第三个参数是指定Spark Streaming运行时的batch窗口的大小。在这个例子中,将1秒的输入数据进行一次Spark Job处理。
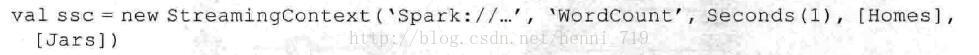
Ø Spark Streaming的输入操作:SparkStreaming已支持丰富的输入接口。接口大致分为两类:一类是磁盘输入,如以batch size作为时间间隔监控HDFS文件系统的某个目录,将目录中内容的变化作为Spark Streaming的输入;另一类就是网络流方式,目前支持Kafka、Flume、Twitter和TCP socket。在WordCount例子中,假定通过网络socket作为输入流,监听某个特定的端口,最后得出输入DStream(lines):
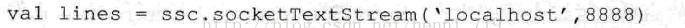
Ø Spark Streaming的转换操作:与Spark Streaming通过转换操作将一个或多个DStream转换成新的DStream。常用操作包括map、filter、flatmap和join,以及需要进行shuffle操作的groupByKey/reduceByKey等。在WordCount例子中,首先需要将DStream(lines)切分成单词,然后将相同单词的数量进行叠加,最终得到的wordCount就是每一个batch size(单词,数量)的中间结果。
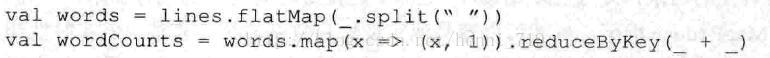
另外,Spark Streaming有特定的窗口操作,窗口操作涉及两个参数:一个是滑动窗口的宽度(Window Duration),另一个是窗口滑动的频率(SlideDuration)。这两个参数必须是batch size的倍数。例如,以过去5秒为一个输入窗口,每1秒统计一下WordCount,那么会将过去5秒的每1秒的WordCount都进行统计,然后进行叠加,得出这个窗口中的单词统计。
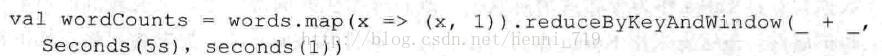
上面方法不够高效,如果以增量的方式来计算就更高效了。例如,计算t+4秒这个时刻过去5秒窗口的WordCount,那么可以将t+3时刻过去5秒的统计量加上[t+3,t+4]的统计量,再减去[t-2,t-1]的统计量(图1-49所示),这种方法可以复用中间3秒的统计量,提高了统计的效率。

Ø Spark Streaming的输出操作:对于输出操作,Spark提供了将数据打印到屏幕及输入到文件中的功能。在WordCount中将DStream wordCounts输入到HDFS文件中。
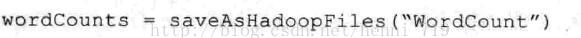
Ø Spark Streaming启动:经过上述操作,SparkStreaming还没有进行工作,需要调用start操作,Spark Streaming才开始监听相应的端口,然后收取数据,并进行统计。
















 7494
7494











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











