







写了一个只使用标准库函数的C程序,在其中用中文写了一些注释。在 Windows 7 中文版操作系统中,使用 Visual Studio 2010 中文版进行编译。为了测试 Visual Studio 2010 中文版对代码注释里中文的支持情况,使用 EditPlus,将 C 程序源文件转换成不同的编码方式,如下图:
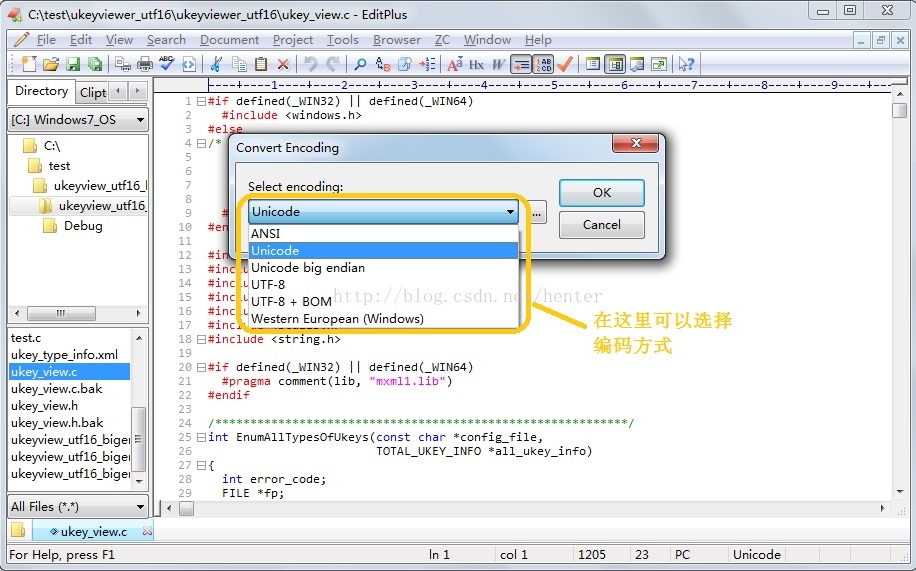
试验一下采用不同编码方式的 C 源文件在 VS 2010 中文版中显示和编译是否正常,结果如下:
| C源程序文件使用的编码 | 在VS 2010中源文件的显示情况 | 编译运行情况 |
|---|---|---|
| ANSI | 中文注释能正常显示,无乱码 | 能编译,运行正常 |
| Unicode | 中文注释能正常显示,无乱码 | 能编译,运行正常 |
| Unicode Big Endian | 中文注释能正常显示,无乱码 | 能编译,运行正常 |
| UTF-8 | 中文注释能正常显示,无乱码 | 编译报错,不能正确识别源代码 |
| UTF-8 with BOM | 中文注释能正常显示,无乱码 | 能编译,运行正常 |
由上表可以看出,除去采用不带 BOM 的 UTF-8 编码,VS 2010 中文版对于采用其他编码方式的源程序都能正确识别和编译。
---------------------------------------------------------------
再到 Linux 平台上看一下:
在 64 位 CentOS 6.8 上,将上面用到的采用不同编码方式 C 源文件使用 4.4.7 版本的 GCC 编译,结果如下:
| C源程序文件使用的编码 | 使用GCC编译运行情况 |
| ANSI | 能编译,运行正常 |
| UTF-8 | 能编译,运行正常 |
| UTF-8 with BOM | 能编译,运行正常 |
Linux对 Unicode 的支持不好,因此没有必要对采用 Unicode、Unicode Big Endian这两种编码方式的源文件做测试。
由此可见:如果中文字符只是出现在 C 程序的注释中,并且该程序需要在 Windows、Linux 两种平台上编译,源文件在采用 ANSI、带 BOM 的 UTF-8 这两种编码方式中的任意一种的情况下,都能够编译和运行。但是如果源文件使用 ANSI 编码保存,在 VS 2010 中编译时,会出现如下的警告:
warning C4819: 该文件包含不能在当前代码页(936)中表示的字符。请将该文件保存为 Unicode 格式以防止数据丢失
因此最好将源文件以带 BOM 的 UTF-8 编码方式保存。















 4320
4320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









