









1 归一化
1.1 BN
BN(Batch Normalization)层的作用
(1)加速收敛
(2)控制过拟合,可以少用或不用Dropout和正则
(3)降低网络对初始化权重不敏感
(4)允许使用较大的学习率
BN层放在激活函数的前面,把送到激活函数的这个batch的数据变成均值为零,方差为1 的数据,这样激活函数尤其sigmoid函数梯度较大反向传播更有效。比如我网络中间某一层学习到特征数据本身就分布在S型激活函数的两侧,你强制把它给我归一化处理、标准差也限制在了1,把数据变换成分布于s函数的中间部分,这样就相当于我这一层网络所学习到的特征分布被你搞坏了,这可怎么办?于是文献使出了一招惊天地泣鬼神的招式:变换重构,引入了可学习参数γ、β,这就是算法关键之处,且γ、β反向传播可调参数。
归一化后的数据优点是易收敛,缺点是破坏了原始数据的分布,这种数据送入到下一层后,对于总的网络来说,不一定就易收敛了。所以在原始数据和归一化的数据两个极端,通过调整γ、β让网络找到最优的数据状态。快速达到降低loss的状态。

BN训练和测试时的参数是一样的嘛?
对于BN,在训练时,是对每一批的训练数据进行归一化,也即用每一批数据的均值和方差,BCHW的数据,其均值方差的shape是1C1*1
而在测试时,比如进行一个样本的预测,就并没有batch的概念,因此,这个时候用的均值和方差是全量训练数据的均值和方差,这个可以通过移动平均法求得。
对于BN,当一个模型训练完成之后,它的所有参数都确定了,包括均值和方差,gamma和bata。
import numpy as np
def Batchnorm(x, gamma, beta, bn_param):
# x_shape:[B, C, H, W]
running_mean = bn_param['running_mean']
running_var = bn_param['running_var']
results = 0.
eps = 1e-5
x_mean = np.mean(x, axis=(0, 2, 3), keepdims=True)
x_var = np.var(x, axis=(0, 2, 3), keepdims=True0)
x_normalized = (x - x_mean) / np.sqrt(x_var + eps)
results = gamma * x_normalized + beta
# 因为在测试时是单个图片测试,这里保留训练时的均值和方差,用在后面测试时用
running_mean = momentum * running_mean + (1 - momentum) * x_mean
running_var = momentum * running_var + (1 - momentum) * x_var
bn_param['running_mean'] = running_mean
bn_param['running_var'] = running_var
return results, bn_param
BN训练时为什么不用全量训练集的均值和方差呢?
因为用全量训练集的均值和方差容易过拟合,对于BN,其实就是对每一批数据进行归一化到一个相同的分布,而每一批数据的均值和方差会有一定的差别,而不是用固定的值,这个差别实际上能够增加模型的鲁棒性,也会在一定程度上减少过拟合。也正是因此,BN一般要求将训练集完全打乱,并用一个较大的batch值,否则,一个batch的数据无法较好得代表训练集的分布,会影响模型训练的效果。
1.2 IBN
IBN是将IN和BN结合。IN(Instance Normalization,对每个位置的数据进行单独归一化),通过将IN和BN的组合提出了IBN-Net,IN主要可以学习视觉表现变化的相关性,例如颜色,风格,真假等。而BN主要学习内容相关的信息,同时可以加速训练和学习到更加有区分性的特征

IN代码,NCWH的原始数据,其均值方差维度是WH。
x_mean = np.mean(x, axis=(2, 3), keepdims=True)
1.3 LN
又叫layer normalization层归一化,一般用在nlp中。LN的主要思想是:是在每一个样本(一个样本里的不同通道)上计算均值和方差,而不是 BN 那种在批方向计算均值和方差!
看源码我们也可以看出来,其中outputs的shape=(btz, seq_len, dim)
mean = K.mean(outputs, axis=-1, keepdims=True) #mean的shape(btz, seq_len, 1)
axis=-1表示的是对最后一维:dim这一维进行计算,同时keepdims=True表示保留当前维度shape数量,最终变成shape=(btz, seq_len, 1),作用是每个字只对自己归一化。
2 图像数据增强
像素级变换
- 模糊 高斯模糊、平均模糊、中值模糊、GlassBluer(毛玻璃效果)、MotionBlur、ElasticTransformation(扭曲平滑)
- 均衡化 CLAHE、AHE、HE
- 颜色空间变换 ChannelDropout(随机选择通道像素失活,和Dropout层类似) CoarseDropout区域随机失活(擦除/高亮) ChannelShuffle(颜色空间随机交换)
- 噪声 高斯噪声 椒盐噪声 camera sensor noise FrequencyNoiseAlpha:在频域中用随机指数对噪声映射进行加权,再转换到空间域。在不同图像中,随着指数值逐渐增大,依次出现平滑的大斑点、多云模式、重复出现的小斑块
- 颜色干扰 对比度、饱和度、亮度
- 增强 FancyPCA(检测图像中的所有边缘,将它们标记为黑白图像,再将结果与原始图像叠加) EdgeDetect、浮雕、锐化、Superpixel、黑白转置、雾化、雨化、阴影、雪、太阳耀斑
空间变换
crop Resize 旋转 Flip 仿射变换 弹性变换ElasticTransform Pad(常数、边界、反射) 网格畸变GridDistortion 光学畸变OpticalDistortion
多样本合成
cutmix:别的图片区域填充,无法保证语义信息,即拼接的不一定合理
mixup:将两幅图片按照一定比例,进行像素及混合(加权求和)
mosaic:对数据进行像素或空间变换增强后,进行拼接,组成新的图像,yolov4中有使用
随机擦除(数据集均值或特定value填充)
常用工具
torch.mmcv
torchvison.transorm
imgaug:github.com/aleju/imgaug
Albumentations:https://github.com/albumentations-team/albumentations
3 网络结构
inception
卷积网络为了提取高维特征,一般方式进行更深层卷积,但是随之带来网络变大的问题。Inception V1模块(借鉴network in network论文中mlpconv思想)提出可以使网络变宽,在保证模型质量的前提下,减少参数个数
nception结构,首先通过1x1卷积来降低通道数把信息聚集一下,再进行不同尺度的特征提取以及池化,得到多个尺度的信息,最后将特征进行叠加输出(官方说法:可以将稀疏矩阵聚类为较为密集的子矩阵来提高计算性能)
 对于上图中的(a)做出几点解释:
对于上图中的(a)做出几点解释:
a)采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
b)之所以卷积核大小采用1、3和5,主要是为了方便对齐;
c)文章说很多地方都表明pooling挺有效,所以Inception里面也嵌入了;
d)网络越到后面,特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,3x3和5x5卷积的比例也要增加。
总结:有点类似于bagging思想,n个弱分类器并行处理,最后加权投票
补充知识:
bagging算法:有放回的选取一批批的样本,训练n个弱分类器,与测时弱分类器再投票(分类问题)或取平均(回归问题)
boosting:Bagging算法可以并行处理,而Boosting的思想是一种迭代的方法,每一次训练的时候都更加关心分类错误的样例,给这些分类错误的样例增加更大的权重,下一次迭代的目标就是能够更容易辨别出上一轮分类错误的样例。最终将这些弱分类器进行加权相加。
bagging增加模型泛化性,boosting提高模型准确率。
mobileNet
通过把一个普通的3×3卷积,转换为一个3×3的可分离卷积 + 1×1卷积,减少计算量。Depthwise卷积不进行通道融合,只在通道内卷积,运算量小,再使用1×1卷积进行通道融合。
其实Depthwise卷积是group卷积的特殊形式,即group思想不向Depthwise卷积这么彻底,它是分组进行卷积通道融合,比如通道数为512,分成2个gourp的化,两个256分别进行普通的卷积,一定程度上也减小列计算量。
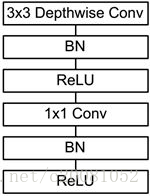
shuffleNet
可分离卷积是group卷积(降低参数量)的一种特殊方式,即group数等于channle数,但是单纯的group卷积会造成数据融合不好,几个独立的分支各预测各的,要使各个分支间有信息交流,就是讲各个channle进行重组打乱,有序的shuffle,这就是shufflenet
resNet
1、解决深度网络退化问题 2、不是直接学习目标特征,是学习差异,差异内容少,更好学
resNet基本结构,如下图,左图是基本的res结构,在18和34中都是这种res。右图是bottleNeck残差结构,目的一目了然,就是为了降低参数的数目
 bottleNeck详细图
bottleNeck详细图

各种resNet网络结构,一共五个卷积层,五次下采样,conv1只有一个卷积,卷积核是7×7

RepVGG
把res结构应用于VGG网络,同时训练时和推理时采用不同的网络结构,将卷积和BN融合,并且将11卷积和identity都转化为33卷积,提高计算效率。具体还要再详细总结!
添加链接描述
mobileVit
Vit的轻量级模型,待学习
convNext
自从ViT(Vision Transformer)在CV领域大放异彩,越来越多的研究人员开始拥入Transformer的怀抱。回顾近一年,在CV领域发的文章绝大多数都是基于Transformer的,比如2021年ICCV 的best paper Swin Transformer,而卷积神经网络已经开始慢慢淡出舞台中央。卷积神经网络要被Transformer取代了吗?也许会在不久的将来。今年(2022)一月份,Facebook AI Research和UC Berkeley一起发表了一篇文章A ConvNet for the 2020s,在文章中提出了ConvNeXt纯卷积神经网络,它对标的是2021年非常火的Swin Transformer,通过一系列实验比对,在相同的FLOPs下,ConvNeXt相比Swin Transformer拥有更快的推理速度以及更高的准确率,在ImageNet 22K上ConvNeXt-XL达到了87.8%的准确率,参看下图(原文表12)。看来ConvNeXt的提出强行给卷积神经网络续了口命
self attention
attention机制,即注意力机制,为了解决以往的RNN,LSTM等模型对于长距离的上下文分析能力不足的问题。然而,自注意力机制,顾名思义,输出与输入自身有关。对于自注意力机制,最有名的就是在谷歌的transformer模型中所使用。

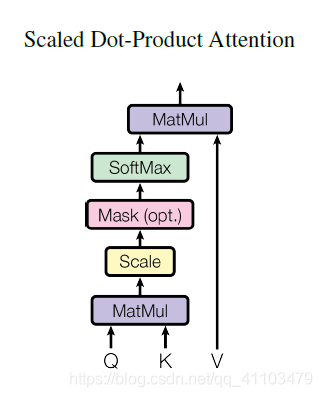
下面是pytorch实现,图像可用。返回值加了一个直连相加
class selfattention(nn.Module):
def __init__(self, in_channels):
super().__init__()
self.in_channels = in_channels
self.query = nn.Conv2d(in_channels, in_channels // 8, kernel_size = 1, stride = 1)
self.key = nn.Conv2d(in_channels, in_channels // 8, kernel_size = 1, stride = 1)
self.value = nn.Conv2d(in_channels, in_channels, kernel_size = 1, stride = 1)
self.gamma = nn.Parameter(torch.zeros(1)) #gamma为一个衰减参数,由torch.zero生成,nn.Parameter的作用是将其转化成为可以训练的参数.
self.softmax = nn.Softmax(dim = -1)
def forward(self, input):
batch_size, channels, height, width = input.shape
# input: B, C, H, W -> q: B, H * W, C // 8
q = self.query(input).view(batch_size, -1, height * width).permute(0, 2, 1)
#input: B, C, H, W -> k: B, C // 8, H * W
k = self.key(input).view(batch_size, -1, height * width)
#input: B, C, H, W -> v: B, C, H * W
v = self.value(input).view(batch_size, -1, height * width)
#q: B, H * W, C // 8 x k: B, C // 8, H * W -> attn_matrix: B, H * W, H * W
attn_matrix = torch.bmm(q, k) #torch.bmm进行tensor矩阵乘法,q与k相乘得到的值为attn_matrix.
attn_matrix = self.softmax(attn_matrix)#经过一个softmax进行缩放权重大小.
out = torch.bmm(v, attn_matrix.permute(0, 2, 1)) #tensor.permute将矩阵的指定维进行换位.这里将1于2进行换位。
out = out.view(*input.shape)
return self.gamma * out + input
FasterNet
为了设计更快的神经网络,许多工作都集中在减少总浮点运算数量 (Floating-Point OPerations) 上。但是,FLOPs 和神经网络的延时 (Latency) 不一定遵循严格的一一对应关系,换句话,FLOPs 的减少不一定会导致类似水平的延迟 (Latency) 减少。这主要是由于每秒浮点运算数量 (Floating-Point OPerations per Second) 较低。
为了实现更快的网络,本文重新审视了流行的算子,并证明了较低的 FLOPS 主要是由于算子的频繁内存访问,尤其是 Depth-wise Convolution。
因此,本文提出了一种新的部分卷积 (Partial Convolution, PConv),通过同时减少冗余计算和内存访问,可以更有效地提取空间特征。在 PConv 的基础上,作者进一步提出了 FasterNet,一种新的神经网络家族,在各种设备上的运行速度远高于其他网络
常规的轻量化网络采用的办法是采用“深度可分离卷积 + 11 卷积”来替代普通卷积,深度可分离卷积减少了计算量,但是没有了通道间信息交互,因此后面会加上11卷积进行补偿。另一种办法是采用折中的group卷积。
内存访问分析
常规卷积的内存访问数量,这里假设输入输出通道都是c
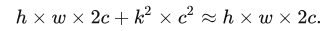
普通的卷积过程如下图,卷积核数量是cin * cout,对应上面的卷积核内存访问量。上式的h * w * 2c是指,input和output各从内存加载一次
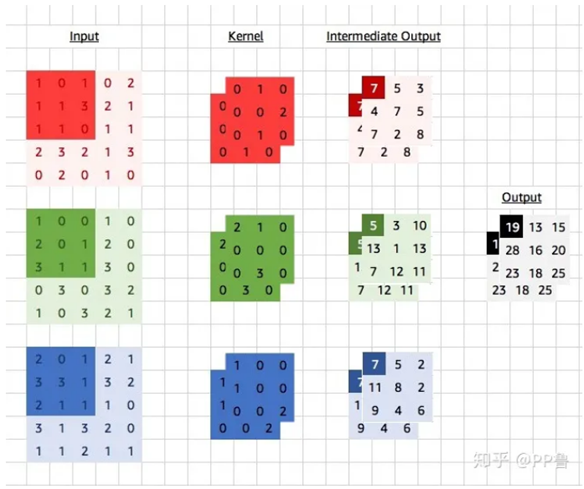
DWConv可分离卷积的内存访问数量如下,和普通卷积公式相同,但在实际应用中,可分离卷积的前后一般都会有1*1卷积,为了兼顾效果,会进行通道先升后降的操作,所以实际上DWConv访问内存数量会更高。再加上1 * 1卷积,以及附带的group、shuffle、concact等额外逻辑操作,这样实际的推理耗时比普通的卷积并没有节约很多,简言之,推理耗时并不是和flops成正比。
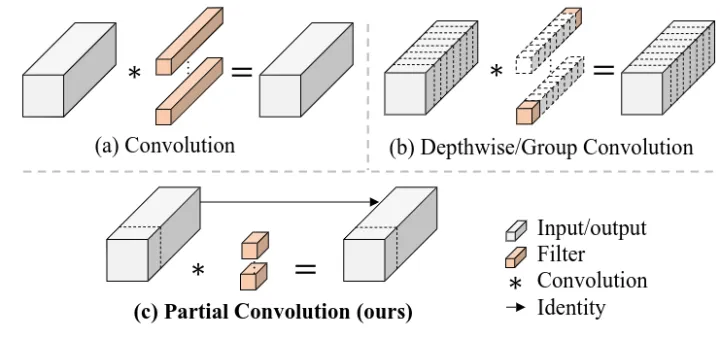
部分卷积 PConv 的设计
本文给出的解决方案部分卷积 (Partial Convolution, PConv) 的出发点是卷积神经网络特征的冗余性。如下图2所示是在预训练的 ResNet50 的中间层中可视化特征图,左上角的图像是输入,特征图在不同通道之间具有很高的相似性。

PConv 对部分输入通道应用常规的 Conv 来进行空间特征提取,而对其余通道保持不变。有点像 GhostNet,但是没有使用 GhostNet 中的 DWConv,而是依然保持着普通的卷积
实现代码如下:
import torch
import torch.nn as nn
from torch import Tensor
class PConv(nn.Module):
""" Partial convolution (PConv).
"""
def __init__(self,
dim: int,
n_div: int,
forward: str = "split_cat",
kernel_size: int = 3) -> None:
""" Construct a PConv layer.
:param dim: Number of input/output channels
:param n_div: Reciprocal of the partial ratio.
:param forward: Forward type, can be either 'split_cat' or 'slicing'.
:param kernel_size: Kernel size.
"""
super().__init__()
self.dim_conv = dim // n_div
self.dim_untouched = dim - self.dim_conv
self.conv = nn.Conv2d(
self.dim_conv,
self.dim_conv,
kernel_size,
stride=1,
padding=(kernel_size - 1) // 2,
bias=False
)
if forward == "slicing":
self.forward = self.forward_slicing
elif forward == "split_cat":
self.forward = self.forward_split_cat
else:
raise NotImplementedError
def forward_slicing(self, x: Tensor) -> Tensor:
""" Apply forward pass for inference. """
x[:, :self.dim_conv, :, :] = self.conv(x[:, :self.dim_conv, :, :])
return x
def forward_split_cat(self, x: Tensor) -> Tensor:
""" Apply forward pass for training. """
x1, x2 = torch.split(x, [self.dim_conv, self.dim_untouched], dim=1)
x1 = self.conv(x1)
x = torch.cat((x1, x2), 1)
return x
PConv运算代价分析
PConv内存访问量如下,cp是实际参与卷积的通道数量。实际应用中,cp一般取通道总数的1/4,因此总的内存访问量实际为原来的1/16
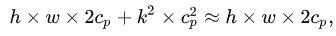
PConv的计算量
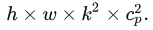
PConv 之后的 Point-Wise Convolution
为了充分有效地利用来自所有通道的信息,作者进一步在 PConv 之后增加了 Point-Wise Convolution (PWConv即1 * 1卷积)。如下图所示,在输入特征图上的有效感受野一起看起来像一个 T 型的 Conv,和常规 Conv 相比,它更关注中心位置。
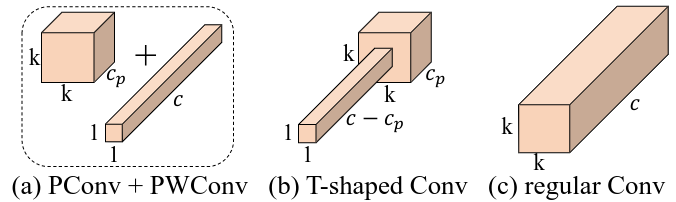
虽然 T 型的 Conv 可以直接实现,但将 T 型的 Conv 分解为 PConv 和 PWConv 更好,因为分解的过程利用了过滤器间冗余并进一步节省了 FLOPs
fasternet整体结构
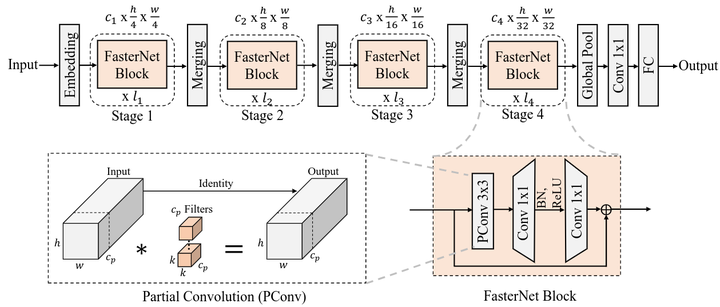
上图中的一个细节,Faster Block中,每个PConv后面都跟着两个1 * 1卷积,应该是为了进一步的对通道融合,也是充分利用同一层内不同通道之间相似性的策略。这里作者肯定也进行了试验,接了一个PWConv效果不够理想,进而又加了一层。其实加这个PWConv肯定和部分卷积Cp数量相关,极端情况,Cp等于C,也就退化成了普通卷积,因此也就无序PWConv了,如果Cp=0.9C,这样效果接近,最多加一层PWConv足够了,但是想要达到提速的效果,进需要使Cp尽可能的小,所以这里也是效果和速度的权衡。
上图的merger操作解释:对网络层进行合并模式{“sum”,“mul”,“concat”,“ave”,“cos”,“dot”},其中,sum和mul是对待合并层输出做一个简单的求和、乘积运算,因此要求待合并层输出shape要一致。concat是将待合并层输出沿着最后一个维度进行拼接,因此要求待合并层输出只有最后一个维度不同。
上图的Embedding层,可参考transformer网络中对图像的embedding操作,至于此处为何要添加embedding,个人理解只是实现了一个下采样?:Vit transformer
4 基础
数据集
训练集:用于训练模型,找出最佳的w和b
验证集:用以确定模型参数,选出最优模型。一般每个epoch后都进行验证,评估是否是最好模型
测试集:仅用于对训练好的最优函数进行性能评估。DL任务中,有时也设定测试频率,每多少个epoch评估一次
5 pytorch
一般有torch和torchvison两个模块,前者包含了tensor、nn、data、cuda、strorage等基础和常见的操作。torchvision则整合了一些常用的backbone模型、数据集、图像增强(transom)方法等
基本语法
上采样
'''从上到下,上采样(scale尺寸上采倍数)'''
inner_top_down = F.interpolate(last_inner, scale_factor=2, mode="nearest")
之前的技术为了增加特征图,采样反卷积等方法,单纯的想增加感受野可以使用空洞卷积,使卷积范围变大,但是卷积核大小不变
dataLoader
dataLoader是torch训练或测试的数据加载器,定义时要传入dataset、batch_size,batch_sampler、num_workers等参数,dataset一般是自己定义的数据集,batch_sampler是按照batch取数据的工具,可以顺序取,随机取等,一般直接使用torch定义好的sampler就行。
自定义自己的数据集,需要继承torch的data.Dataset类,重定义以下三个函数
from torch.utils import data
import numpy as np
from PIL import Image
class face_dataset(data.Dataset):
def __init__(self):
self.file_path = './data/faces/'
f=open("final_train_tag_dict.txt","r")
self.label_dict=eval(f.read())
f.close()
def __getitem__(self,index):
label = list(self.label_dict.values())[index-1]
img_id = list(self.label_dict.keys())[index-1]
img_path = self.file_path+str(img_id)+".jpg"
img = np.array(Image.open(img_path))
return img,label
def __len__(self):
return len(self.label_dict)
https://zhuanlan.zhihu.com/p/105507334
有了自定义的数据集,接下来就可以在DataLoader使用了
train_dataset = TuplesDataset( #TuplesDataset是自定义的dataSet
name=args.training_dataset,
mode='train',
imsize=args.image_size,
nnum=args.neg_num,
qsize=args.query_size,
poolsize=args.pool_size,
transform=transform
)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=args.batch_size, shuffle=True,
num_workers=args.workers, pin_memory=True, sampler=None,
drop_last=True, collate_fn=collate_tuples
)
nn.module
nn.module自己有两个成员函数,train和eval(),这两个函数并不是真的训练和测试,而是设置成相关的模式,如设置成eval模式后,BN层会直接使用存储的均值方差进行推理等等。简单的训练过程如下:
# 实例化模型,loss,和优化器
model = Lr()
model.cuda()
#定义损失函数
criterion = nn.MSELoss()
#定义优化的方法为随机梯度下降,学习率为1e-3
optimizer = optim.SGD(model.parameters(), lr=1e-3)
# 3. 训练模型
for i in range(20000):
#这里的四个步骤是优化类的使用方法
out = model(x) # 3.1 获取预测值
loss = criterion(y, out) # 3.2 计算损失
optimizer.zero_grad() # 3.3 梯度归零
loss.backward() # 3.4 计算梯度
optimizer.step() # 3.5 更新梯度
if (i + 1) % 2000 == 0:
print('Epoch[{}/{}], loss: {:.6f}'.format(i, 30000, loss.data))
加载预训练模型的权重,如果某几层改动,匹配不上,可以不加载
model.load_state_dict({k.replace('module.', ''):v for k,v in torch.load('checkpoint.pt').items() if('seg.feat' not in k)}, strict=Flase)
nn层或操作
nn.embedding就是一个简单的查找表,存储固定字典和大小的嵌入。一中编码方式,类比二进制编码,只是里面的数字都是归一化了的,方便送入网络。这一层的weight就是所有的码表(N,L),N。
该模块通常用于存储词嵌入并使用索引检索它们。模块的输入是索引列表,输出是相应的词嵌入。
个人理解:
nn.embedding就是一个字典映射表,比如它的大小是128,0~127每个位置都存储着一个长度为3的数组,那么我们外部输入的值可以通过index (0~127)映射到每个对应的数组(应该是归一化的)上,所以不管外部的值是如何都能在该nn.embedding中找到对应的数组。想想哈希表,就很好理解了
import torch
import torch.nn as nn
embedding = nn.Embedding(10, 3) # an Embedding module containing 10 tensors of size 3
input = torch.LongTensor([[1,2,4,5],[4,3,2,9]]) # a batch of 2 samples of 4 indices each
e = embedding(input)
print(e)
输出如下,因为第一个参数(number_embeddings)是10,所以范围是0-9,如果input 中出现了10就是越界

tensor基本操作
回头参考这个链接自己再总结一遍
参考链接
tensor的GPU操作,不同设备上的tensor不能直接计算!
with torch.cuda.device(1):
# allocates a tensor on GPU 1
a = torch.tensor([1., 2.], device=cuda)
# transfers a tensor from CPU to GPU 1
b = torch.tensor([1., 2.]).cuda()
# a.device and b.device are device(type='cuda', index=1)
c = b * 2 #c和b在同一设备上
# extract query vectors,从网络里取出某一层(特征),先net.cuda()
qvecs = torch.zeros(net.meta['outputdim'], len(self.qidxs)).cuda()
for i, input in enumerate(loader):
qvecs[:, i] = net(input.cuda()).data.squeeze()
查看tensor的数据类型:tensor.dtype
类型转换:tensor.int() #将数据转换为int型
查看维度:tensor.shape
#维度交换,permute(),如下将网络输出的ncwh格式的tensor变为nwhc的维度
out = out_feature.permute(0, 2, 3, 1).detach().cpu().numpy()
其他
加载预训练参数
model = xxnet()
model_ckpt = torch.load("model path")
# 将pretrained_dict里不属于model_dict的键(可根据layer名字)剔除掉,strict=false表示非完全对应的加载
model.load_state_dict({k.rerlace('module.', ''): value for key, value in model_ckpt.items() if (k != 'layer name')},\
strict=false)
#可以这样保存,详细可参考torch官方
torch.save(model.state_dict(), 'resnet50_only_paramater.pth.tar', _use_new_zipfile_serialization=False)
冻结参数
# 冻结network1的全部参数和network2的部分参数
for name, parameter in network1.named_parameters():
parameter.requires_grad = False
for name, parameter in network2.named_parameters():
if 'key' in name:
parameter.requires_grad = False
# 另一种方法,直接在模型里冻结模块,更加实用
class MyNet(nn.Module):
def __init__(self):
super().__init__()
self.bb = resnet()
self.branch1 = branch1()
self.branch2 = branch2()
def forward(self, x):
x1 = self.bb(x)
def freeze(self):
for parameter in self.bb.parameters():
parameter.requires_grad = False
for parameter in self.branch1.parameters():
parameter.requires_grad = False
torch loss
BCELoss
二分类交叉熵,pre和gt维度相同,gt标签只有0和1,pre是经过了sigmoid之后的tensor。
另外还有一个BCEWithLogitsLoss,区别就是输入的pre可以是实数域,函数内部会进行sigmoid。
input = torch.tensor([[0.9,0.1,0.3], [0.4,0.8,0.2]], dtype=torch.float)
target = torch.tensor([[1,0,0], [0,1,0]], dtype=torch.float)
# 计算BCELoss
m = nn.Sigmoid()
loss = nn.BCELoss()
Bloss = loss(input, target)
print(Bloss)
corss_entropy
多分类交叉熵损失函数,也是内部实现了softmax,pre可以是实数。另外一个内部不嵌入softmax的是nll_loss
输入的gt和pre维度是不一样的,举个例子, 一个batch装3个样本,5个class,pre维度就是shape(3, 5),而gt要少一个维度shape(3)就可以,原因是gt里面存储的是0,1,2这样的标签值,而非one_hot数据。
import torch
import torch.nn.functional as F
logits = torch.randn(3, 5, requires_grad=True) # shape(3, 5)
>>>tensor([[ 1.5410, -0.2934, -2.1788, 0.5684, -1.0845],
[-1.3986, 0.4033, 0.8380, -0.7193, -0.4033],
[-0.5966, 0.1820, -0.8567, 1.1006, -1.0712]], requires_grad=True)
labels = torch.tensor([1, 0, 4])
loss = F.cross_entropy(logits, labels, reduction='none')
>>>tensor([2.3257, 3.0493, 2.7802], grad_fn=<NllLossBackward>)
# logsoftmax + nll_loss = cross_entropy
loss_nll = F.nll_loss(F.log_softmax(logits), labels, reduction='none')
>>>tensor([2.3257, 3.0493, 2.7802], grad_fn=<NllLossBackward>)
mmcv
mmcv作为一个基础库,主要提供了以下的功能模块:
- 统一可扩展的 io api
- 支持非常丰富的图像/视频处理算子
- 图片/视频的标注文件可视化
- 常用的工具类例如 timer 和 progress bar 等等
- 上层框架需要的 hook 机制以及可以直接使用的 runner
- 高度灵活的 cfg 模式和注册器机制
- 高效高质量的 cuda op
MMCV核心组件——Config & Registry
基础了解,易懂
有时间再总结
注册是自己实线的类或函数,比如backbone、neck等等进行注册,然后可以动态调用,调用的时候,通过build传入参数(config),就可以返回自己需要的对象了,下面是一个小例子,模拟了网络模型的注册和调用过程。注意一下,我们打印Registry对象时,实际上打印的是self._module_dict中的values。
# 实例化一个注册器用来管理模型
MODELS = Registry('myModels')
# 方式1: 在类的创建过程中, 使用函数装饰器进行注册(推荐)
@MODELS.register_module()
class ResNet(object):
def __init__(self, depth):
self.depth = depth
print('Initialize ResNet{}'.format(depth))
# 方式2: 完成类的创建后, 再显式调用register_module进行注册(不推荐)
class FPN(object):
def __init__(self, in_channel):
self.in_channel= in_channel
print('Initialize FPN{}'.format(in_channel))
MODELS.register_module(name='FPN', module=FPN)
print(MODELS)
""" 打印结果为:
Registry(name=myModels, items={'ResNet': <class '__main__.ResNet'>, 'FPN': <class '__main__.FPN'>})
"""
# 配置参数, 一般cfg从配置文件中获取
backbone_cfg = dict(type='ResNet', depth=101)
neck_cfg = dict(type='FPN', in_channel=256)
# 实例化模型(将配置参数传给模型的构造函数), 得到实例化对象
my_backbone = MODELS.build(backbone_cfg)
my_neck = MODELS.build(neck_cfg)
print(my_backbone, my_neck)
""" 打印结果为:
Initialize ResNet101
Initialize FPN256
<__main__.ResNet object at 0x000001E68E99E198> <__main__.FPN object at 0x000001E695044B38>
"""
mmdetection
MMDetection是商汤和港中文大学针对目标检测任务推出的一个开源项目,它基于Pytorch实现了大量的目标检测算法,把数据集构建、模型搭建、训练策略等过程都封装成了一个个模块,通过模块调用的方式,我们能够以很少的代码量实现一个新算法,大大提高了代码复用率。
整个MMLab家族除了MMDetection,还包含针对目标跟踪任务的MMTracking,针对3D目标检测任务的MMDetection3D等开源项目,他们都是以Pytorch和MMCV以基础。Pytorch不需要过多介绍,MMCV是一个面向计算机视觉的基础库,最主要作用是提供了基于Pytorch的通用训练框架,比如我们常提到的Registry、Runner、Hook等功能都是在MMCV中支持的。另外,MMCV还提供了通用IO接口、多种CNN网络结构、高质量实现的常见CUDA算子,这里就不进一步展开了
使用流程
注册数据集:CustomDataset是MMDetection在原始的Dataset基础上的再次封装,其__getitem__()方法会根据训练和测试模式分别重定向到prepare_train_img()和prepare_test_img()函数。用户以继承CustomDataset类的方式构建自己的数据集时,需要重写load_annotations()和get_ann_info()函数,定义数据和标签的加载及遍历方式。完成数据集类的定义后,还需要使用DATASETS.register_module()进行模块注册。
注册模型:模型构建的方式和Pytorch类似,都是新建一个Module的子类然后重写forward()函数。唯一的区别在于MMDetection中需要继承BaseModule而不是Module,BaseModule是Module的子类,MMLab中的任何模型都必须继承此类。另外,MMDetection将一个完整的模型拆分为backbone、neck和head三部分进行管理,所以用户需要按照这种方式,将算法模型拆解成3个类,分别使用BACKBONES.register_module()、NECKS.register_module()和HEADS.register_module()完成模块注册。
构建配置文件:配置文件用于配置算法各个组件的运行参数,大体上可以包含四个部分:datasets、models、schedules和runtime。完成相应模块的定义和注册后,在配置文件中配置好相应的运行参数,然后MMDetection就会通过Registry类读取并解析配置文件,完成模块的实例化。另外,配置文件可以通过_base_字段实现继承功能,以提高代码复用率。
训练和验证:在完成各模块的代码实现、模块的注册、配置文件的编写后,就可以使用./tools/train.py和./tools/test.py对模型进行训练和验证,不需要用户编写额外的代码
注册机制
工具
HuggingFace
1.HuggingFace是什么
可以理解为对于AI开发者的GitHub,提供了模型、数据集(文本|图像|音频|视频)、类库(比如transformers |peft|accelerate)、教程等。
2.为什么需要HuggingFace
主要是HuggingFace把AI项目的研发流程标准化,即准备数据集、定义模型、训练和测试















 2078
2078











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









