






神经网络自动搜索研究概要
目标:快速了解硬件感知的神经网络NAS搜索
背景
-
由于需要将神经架构部署到资源受限的硬件上, 人们迫切地需要高效的架构
-
研究发现 FLOP 数并不总是反映实际的硬件效率
-
具有较低 FLOPs 的架构并不一定更快
-
人类设计的规则仍然存在产生次优架构的风险
-
NAS,Neural architecture search 能自动搜索具有最佳架构的神经网络.
-
NAS 的方法可以根据 3 个维度进行分类: 搜索空间、优化方法和性能评估策略.
-
NAS主要是搜索神经网络的拓扑结构
-
搜索空间定义了理论上可以表示的架构.
-
性能评估是指评估模型性能的过程, 通常来说 NAS 的目标是找到在新的数据上能得到良好的预测结果的架构
-
Network optimization is typically done manually with a great deal of in-depth understanding of the hardware platform since certain hardware characteristics (e.g., clock speed, number of logical processor cores, amount of RAM, architecture) will affect the optimization process.
-
weight-sharing approaches known as one-shot or supernetworks 用于减少计算开销
-
模型加速类别:

-
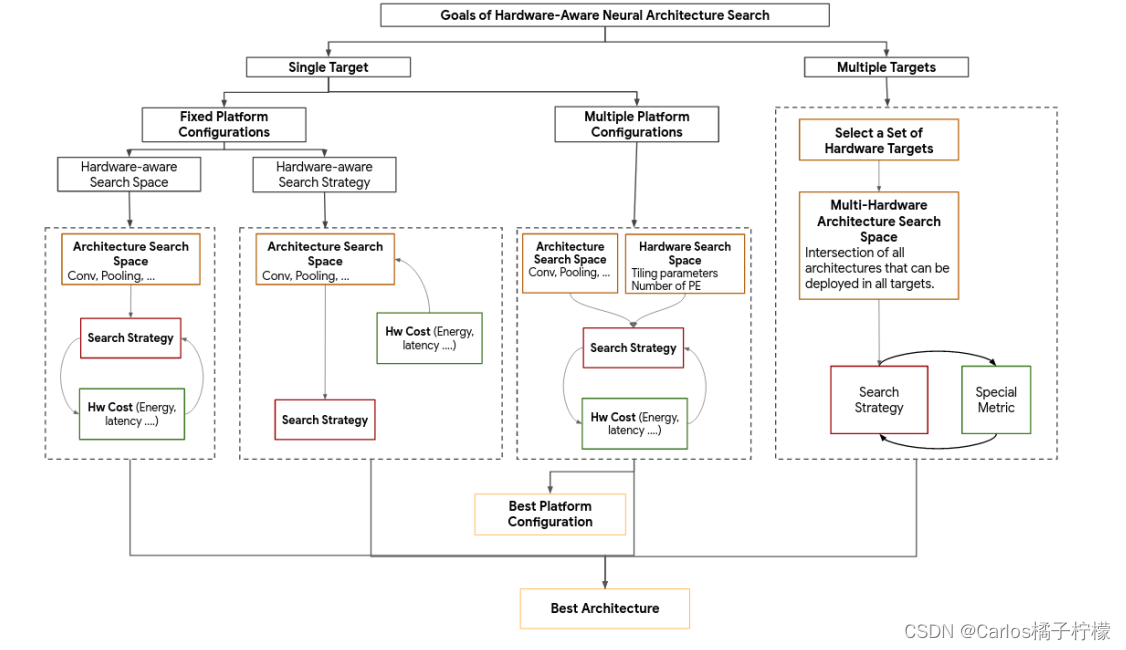
硬件感知的NAS搜索分类
-
硬件感知的搜索策略,选择在特定平台的最佳模型,包括精度和hardware cost metric (e.g., latency, memory usage, energy consumption)
-
硬件感知的搜索空间,先衡量搜索空间中的集合,去除一些不会在平台表现很好的结构,从以前积累的领域知识,在给定硬件平台上进行实验有助于缩小搜索空间
-
还有一种HW-NAS是仅搜索在特定平台最快的结构,后续对该结构进行fine-tunning
-
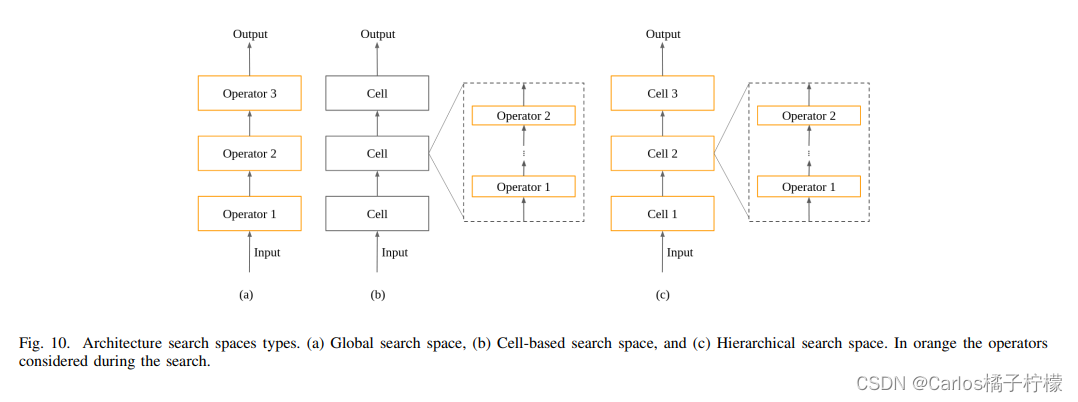
搜索空间类别:
-
基于cell的方法依赖于观察到的许多有效的手工结构是通过重复一组单元来设计的
研究现状
- NetAdapt 通过在损失函数中加入硬件感知的资源限制来使得搜索出的网络能适应不同的硬件
- 损失函数采用了直接的度量标准, 比如为移动 CPU 测量的延迟. 这些方法测量出每个算子的延迟然后建立预测模型, 并把延迟视为可微正则化损失加入搜索过程中
- 可变换神经网络架构搜索 (TAS) 通过调整网络的宽度和深度来取得更好的性能.
- TAS 首先通过应用可微 NAS 来降低模型的宽度和深度, 从而获得更为精简的模型
- 尽可能选择那些硬件友好的通道数量组成硬件感知的搜索空间
- 已有的 TAS 方法 的搜索空间大多由一组等差比率和基础模型的层宽相乘得到. 例如, Resnet32 第一阶段的通道数量是 16, 比率可以从 (0.25, 0.50, 0.75, 1.0) 中选择, 那么它的搜索空间应为 (4, 8, 12, 16).如果有 N 个通道数量, 最高 L 层可供搜索, 那么搜索空间的大小为 O(N^L).
- GraphNAS 方法中, 搜索空间中的信息计算函数、聚合函数和激活函数是作者总结出的当前图神经网络领域中具有代表性的函数种类
- One popular way to mitigate the validation cost in one-shot networks is to train predictors for objectives such as inference time (a.k.a. latency) and accuracy from a training set with thousands of sampled architectures
- 虽然使用supernet进行oneshot训练可以减少训练网络的开销,但是子网络的验证需要大量时间
- 在使用NAS发现有前景的DNN架构后,可以通过找到微调策略的正确组合或通过从头开始完全重新训练子网络来实现特定性能范围的最先进性能
- one-shot predictor approach to reduce the validation cost overhead
- 对于oneshot的supernet网络搜索流程参照如下
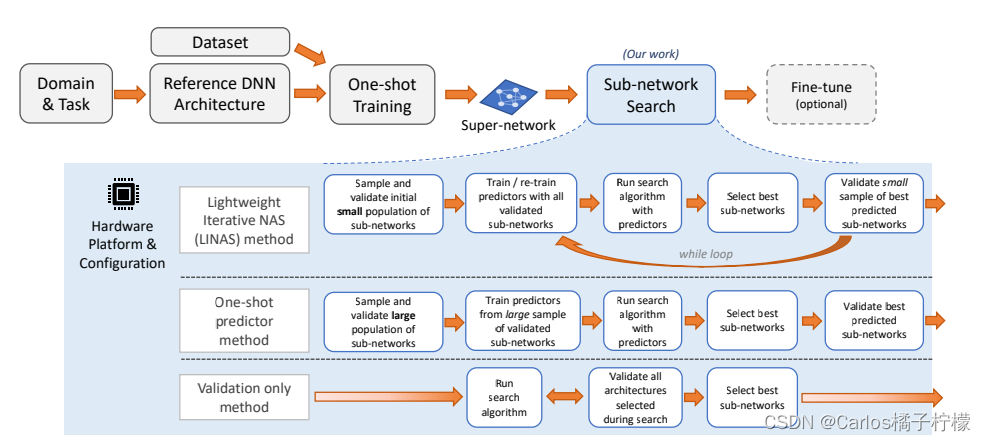
- BootstrapNAS discuss the sub-network search process for the quantized INT8 space in the Appendix
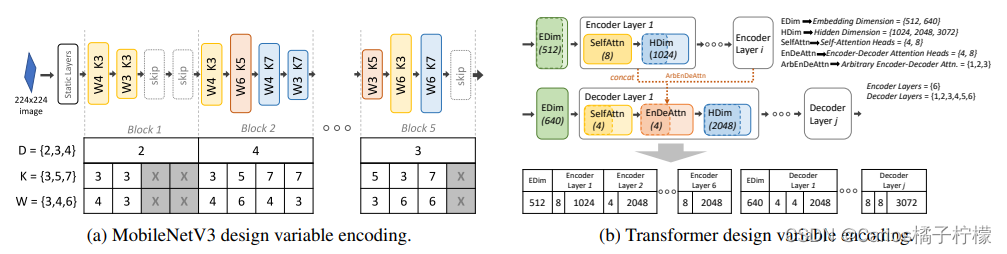
- 子网络需要有有相关的表示,就是对搜索空间进行编码,以方便表示supernet下的subnet
- 表现预测(Performance prediction):我们知道,NAS中最费时的是候选模型的训练,而训练的目的是为了评估该结构的精度。为了得到某个网络模型的精度又不花费太多时间训练,通常会找一些代理测度作为估计量。比如在少量数据集上、或是低分辨率上训练的模型精度,或是训练少量epoch后的模型精度。尽管这会普遍低估精度,但我们要的其实不是其绝对精度估计,而是不同网络间的相对值。换言之,只要能体现不同网络间的优劣关系,是不是绝对精准没啥关系。从另一个角度思考,有没有可能基于模型结构直接预测其准确率呢。论文《Progressive Neural Architecture Search》中的关键点之一是使用了一个代理模型来指导网络结构的搜索。具体来说,这个代理模型是个LSTM模型,输入为网络结构的变长字符串描述,输出预测的验证精度。也正是有个这个利器,使得它里边提出方法即使用看起来并不复杂的启发式搜索,也能达到很好的效果。还有一个思路就是基于学习曲线来预测,这基于一个直观认识,就是我们在训练时基本训练一段时间看各种指标曲线就能大体判断这个模型是否靠谱。学习曲线预测,一种直观的想法就是外插值,如论文《Speeding up Automatic Hyperparameter Optimization of Deep Neural Networks by Extrapolation of Learning Curves》中所讨论的。之后论文《Learning Curve Prediction with Bayesian Neural Networks》中使用Bayesian neural network对学习曲线进行建模与预测。当然实际的预测中,可以不局限于单一的特征,如在论文《Accelerating Neural Architecture Search using Performance Prediction》中,结合了网络结构信息,超参数信息和时序上的验证精度信息来进行预测,从而提高预测准确性。总得来说,表现预测由于其高效性,在NAS中起到越来越关键的作用。
- 基于梯度的方法(Gradient-based method):这是比较新的一类方法。前面提到的基于强化学习和进化算法的方法本质上都还是在离散空间中搜索,它们将目标函数看作黑盒。我们知道,如果搜索空间连续,目标函数可微,那基于梯度信息可以更有效地搜索。CMU和Google的学者在《DARTS: Differentiable Architecture Search》一文中提出DARTS方法。一个要搜索最优结构的cell,可以看作是包含N个有序结点的有向无环图。结点代表隐式表征(例如特征图),连接结点的的有向边代表算子操作。DARTS方法中最关键的trick是将候选操作使用softmax函数进行混合。这样就将搜索空间变成了连续空间,目标函数成为了可微函数。这样就可以用基于梯度的优化方法找寻最优结构了。搜索结束后,这些混合的操作会被权重最大的操作替代,形成最终的结果网络。另外,中科大和微软发表的论文《Neural Architecture Optimization》中提出另一种基于梯度的方法。它的做法是先将网络结构做嵌入(embedding)到一个连续的空间,这个空间中的每一个点对应一个网络结构。在这个空间上可以定义准确率的预测函数。以它为目标函数进行基于梯度的优化,找到更优网络结构的嵌入表征。优化完成后,再将这个嵌入表征映射回网络结构。这类方法的优点之一就是搜索效率高,对于CIFAR-10和PTB,结合一些像权重共享这样的加速手段,消耗可以少于1 GPU/天。
- Google的论文《Learning Transferable Architectures for Scalable Image Recognition》提出NASNet ,它假设整体网络是由cell重复构建的,那搜索空间就缩小到对两类cell(normal cell和reduction cell)结构的搜索上,从而大大减小了搜索空间。
- 当前NAS工作主要聚焦于图像分类任务,并认为适用于图像分类的最佳模型,也能成为其他任务(如检测、分割等)的最佳Backbone。然而这一假设有失偏颇,容易导致迁移应用的次优化
- 2018年Berkeley和Facebook的论文《Mixed Precision Quantization of ConvNets via Differentiable Neural Architecture Search》将NAS(Neural architecture search)引入混合精度量化,提出一种Differentiable NAS(DNAS)框架。它根据给定的模型构建具有相同macro architecture的super net。在super net中,两个代表中间数据的节点中会有多个边。每个边代表不同的算子,比如分别对应不同bit-width的卷积。这些边由随机变量edge mask来控制。利用Gumbel Softmax,可以使目标函数对于该mask参数可微。这样,便可以利用常用的SGD进行优化。2019年Sony的论文《Differentiable Quantization of Deep Neural Network》前面有介绍,其中step-size和dynamic range是自动学习的,而bit-width是通过固定的规则从前面自动学习的参数得到的。
- OFA:最近基于 one-shot 的 NAS 首先训练大型的多分支网络。每次都从大型网络中提取一个子网,以直接评估近似精度。如此大的网络称为“once-for-all network”。由于深度神经网络中不同层的选择在很大程度上是独立的,因此一种流行的方法是为每一层设计多个选择(例如卷积核大小,扩展率等)。
- NAS 局限性:NAS 的搜索空间有很大的局限性,目前 NAS 算法仍然使用手工设计的结构和 blocks,NAS 仅仅是将这些 blocks 堆叠。NAS 还不能自行设计网络架构。NAS 的一个发展方向是更广泛的搜索空间,寻找真正有效率的架构,当然这也对搜索策略和性能评估策略提出更高的要求。
Transformer
- HAT 是一个基于HW-NAS寻找NLP transformer的NAS算法,他提出一个SuperTransformer。HTAS uses a gradient-based method to find the best width and depth for their transformable CNNs.
研究方法
搜索方法
- 文献对搜索算法进行了分类:
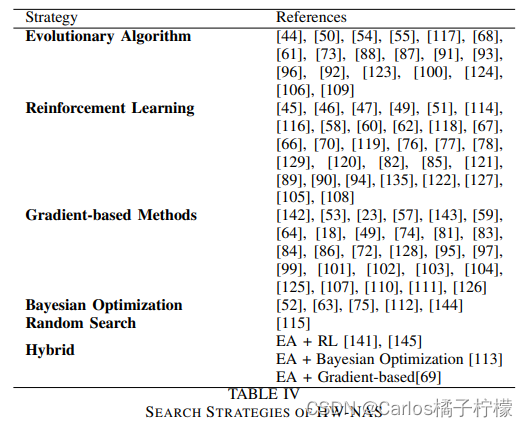
- 使用随机搜索策略的研究者 argue that it is more important to design the architecture search space for the targeted hardware platform than to complicate the search strategy and incorporate the hardware constraints in the objective function
- 使用梯度下降寻找最优结构必须确保损失函数可微,在许多这样的搜索策略中,作者使用了大网络。因此,损失函数必须相对于体系结构参数是可微分的。此外,我们需要检查硬件损失项是否可微分。现有的几种方法使离散变量上的梯度计算成为可能:Gumbel Softmax、Estimated Continuous Function、REINFORCE algorithm
模型评估加速方法
- Early Stopping 通常训练5个epoch来判断模型质量的近似值
- Hot start 搜索启发法不是从一个随机模型开始的,而是从一个有效的模型开始的,相当于从次优模型开始搜索
- Proxy datasets 在小数据集上训练搜索,但是在大数据集上精调
- Accuracy Prediction Models 基于网络具体实现和数据特征直接预测模型精度,例如将具体实现编码为向量输入MLP、RNN(LSTM)中预测精度
硬件损失评估方法
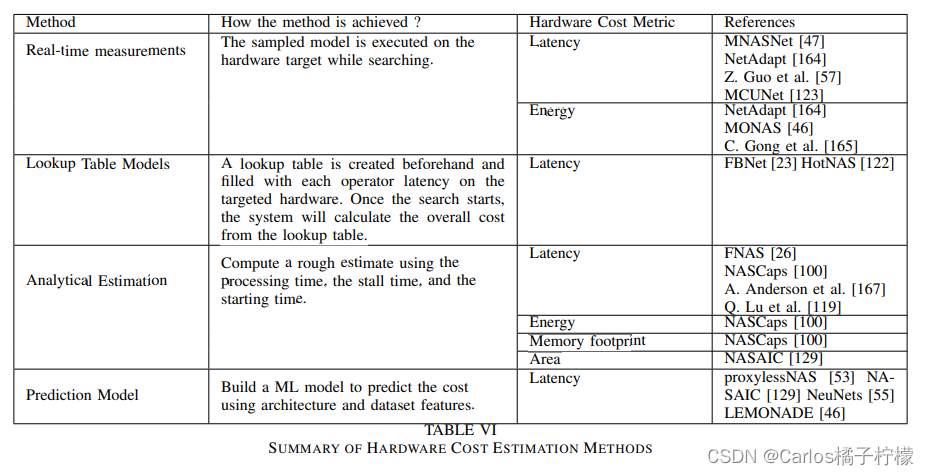
- FLOPs & Model Size
- Latency
- Energy Consumption
- Area :The goal is to get the smallest chip possible that could run the best model. The area of the circuit is also a good indicator of the static power consumption.
- Memory footprint:测评运行时的使用内存
搜索空间
- 搜索空间根据网络类型可以划分为链式架构空间、多分支架构空间、cell/block 构建的搜索空间。根据搜索空间覆盖范围可分为 macro(对整个网络架构进行搜索)和 micro(仅搜索 cell,根据 cell 扩展搜索空间)
- 链式架构空间包括(1)网络最大层数 n。(2)每一层的运算类型:池化、连接、卷积(depthwise separable convolutions,dilated convolutions、deconvolution)等类型。(3)运算相关的超参数:滤波器的大小、个数、 strides 等。(4)激活函数:tanh,relu,identity,sigmoid 等。
- 很多神经网络结构虽然很深,但会有基本的 cell/block,通过改变 cell/block 堆叠结构,一方面可以减少优化变量数目,另一方面相同的 cell/ block 可以在不同任务之间进行迁移
- 扩大全局搜索空间,搜索方法往往会优先选择较大的通道数与较低的层数
- 搜索策略,常见的搜索方法包括:随机搜索、贝叶斯优化、进化算法、强化学习、基于梯度的算法
- 像延迟、能耗与模型大小的限制可以通过强化学习中动作空间的构造来加以限制。因此,损失回报中只考虑准确率的降低就行
- 两个方面入手:
– 减少训练时间
– 基于小规模代理任务:使用和实际任务同类型但规模更小或分辨率更低的数据集进行结构搜索,在搜索过程中用神经结构在代理任务上的性能来估计它在实际任务上的性能,当搜索完成后再将神经结构迁移到实际任务上
– 减少卷积核数量
– 快速评估模型性能
– 基于训练曲线:将神经结构只训练少量的迭代次数并在训练过程中记录神经结构的性能曲线,通过已有的性能曲线来预测未来的性能并提前停止训练预期性能不好的神经结构
基于搜索出的网络结构:基于网络结构提取特征信息拟合模型性能
量化
- 最优的量化策略往往还是和硬件平台相关的
- CNN不同的层对量化的敏感度也是不一样的。因此在量化方法中,最好也可以对不同的层使用不同的bit-width
- 为每层找寻最优的bit-width是一个组合优化问题,其搜索空间是随着层数的增加指数增加的。
- 基于weight与activation的entropy来确定每层的bit-width。因为熵可以表示信息量,而熵越大表示信息量越大,直觉上也需要更多位数也表示
- 描述平坦的区域需要较少的位,要描述曲率很大的表面则需要较多的位
- 与weight和activation量化不同,梯度的量化主要用于训练,尤其是分布式训练。在传统的分布式训练中,通信的数据一大块是梯度的更新信息。因此,如果减少梯度,那就可以有效减少通信开销,从而提高训练速度。
- 量化是否一定能加速计算?回答是否定的,许多量化算法都无法带来实质性加速。引入一个概念:理论计算峰值。在高性能计算领域,这概念一般被定义为:单位时钟周期内能完成的计算个数乘上芯片频率。什么样的量化方法可以带来潜在、可落地的速度提升呢?我们总结需要满足两个条件:量化数值的计算在部署硬件上的峰值性能更高 。量化算法引入的额外计算(overhead)少 。
- 已知提速概率较大的量化方法主要有如下三类,
– 二值化,其可以用简单的位运算来同时计算大量的数。对比从nvdia gpu到x86平台,1bit计算分别有5到128倍的理论性能提升。且其只会引入一个额外的量化操作,该操作可以享受到SIMD(单指令多数据流)的加速收益。
– 线性量化,又可细分为非对称,对称几种。在nvdia gpu,x86和arm平台上,均支持8bit的计算,效率提升从1倍到16倍不等,其中tensor core甚至支持4bit计算,这也是非常有潜力的方向。由于线性量化引入的额外量化/反量化计算都是标准的向量操作,也可以使用SIMD进行加速,带来的额外计算耗时不大。有缩放因子S和偏移量Z。
– 对数量化,一个比较特殊的量化方法。可以想象一下,两个同底的幂指数进行相乘,那么等价于其指数相加,降低了计算强度。同时加法也被转变为索引计算。但没有看到有在三大平台上实现对数量化的加速库,可能其实现的加速效果不明显。只有一些专用芯片上使用了对数量化。 - 量化属于浮点数向定点数转换的过程,由于浮点数的可表示数值间隙密度不同,导致零点附近的浮点数可表示数值很多,大约2^31个,约等于可表示数值量的一半。因此,越是靠近零点的浮点数表示越准确,越是远离原点的位置越有可能是噪声,并且网络的权重和激活大多分布在零点附近,因此适当的缩小量化域能提升量化精度几乎是必然的。
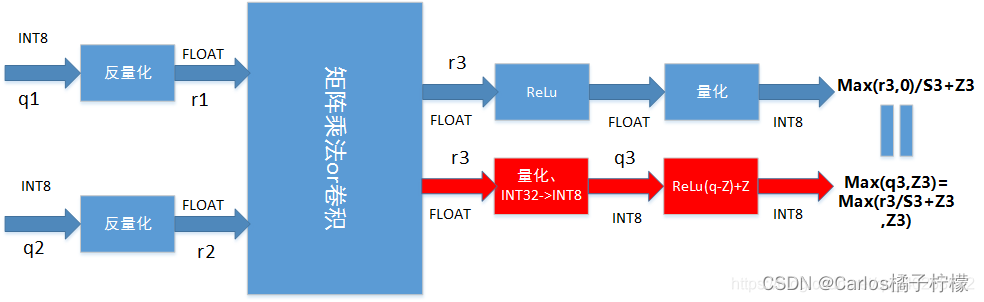
- Tensorrt使用权重饱和量化,激活值非饱和量化(阈值截断)以及KL散度进行模型量化;pytorch的静态量化是以zero_point为中心,用8位数Q代表input离中心有多远,scale为距离单位,即input ≈ zero_point + Q * scale;量化感知训练则如下图所示,梯度反向传播时对精度要求较高,因此训练时更新的是浮点型的权重,需要经过反量化->计算->量化的过程,如下图所示
- APQ(论文链接)提出:训练量化感知的准确性预测器,以快速获得量化模型的准确性,并将其提供给搜索引擎以选择最佳拟合。但是,训练此量化感知精度预测器需要收集大量量化的<model,precision>对,这涉及量化感知的微调,因此非常耗时。为了解决这一挑战,本文建议将知识从全精度(即fp32)精度预测器转移到量化感知(即int8)精度预测器。APQ 的核心思想是使用量化感知的精度预测器来加快搜索过程,预测器将模型体系结构和量化方案作为输入,并可以快速预测其准确性。代替微调修剪和量化的网络以获得准确性,本文使用由预测变量生成的估计准确性,可以以可忽略的成本获得该准确性(因为预测变量仅需要几个FC层)。
工业界应用
Tools
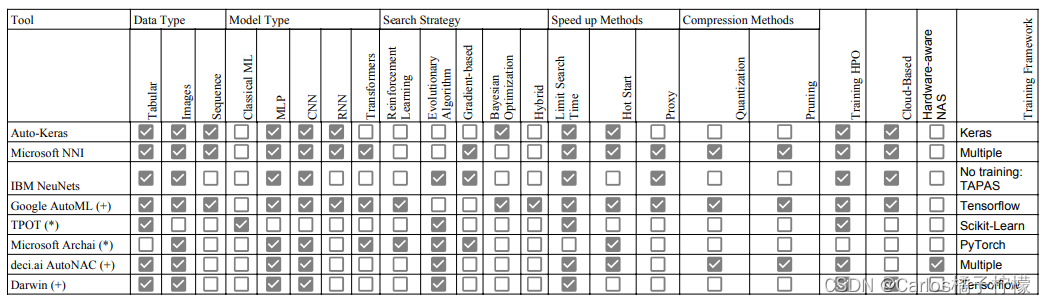
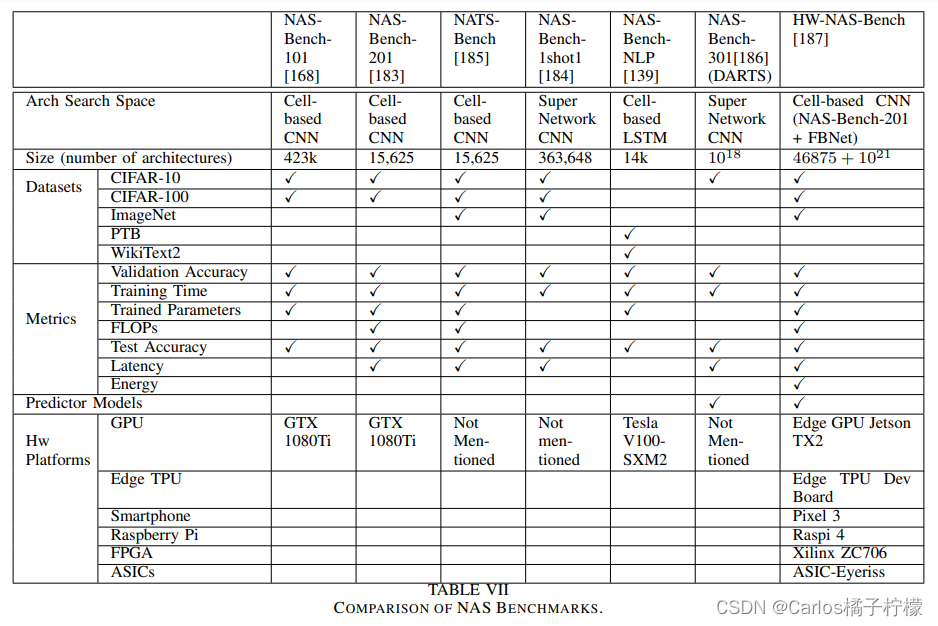
Benchmark
- 目的:
– 通过直接查询表格数据集,消除了生成搜索空间的开销。
– 在同一搜索空间上评估不同的搜索策略,这样可以对它们进行公平的比较。
– 提供精度预测模型和硬件成本模型使用的数据集。
– 通过提出包含硬件相关度量的数据集,向非硬件专家开放HW-NAS研究。这些度量通常是在对需要特定硬件知识的操作员和软件进行优化之后获得的。 - 总结
HW-NAS的限制
- 由于使用不同的搜索空间、不同的训练方法以及所需的大量计算资源,再现性是一个困难的步骤
- 针对图形分类任务的NAS搜索出的网络难以适应其他任务,需要重新搜索
- 针对一种硬件的网络如何适应其他硬件平台



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









