







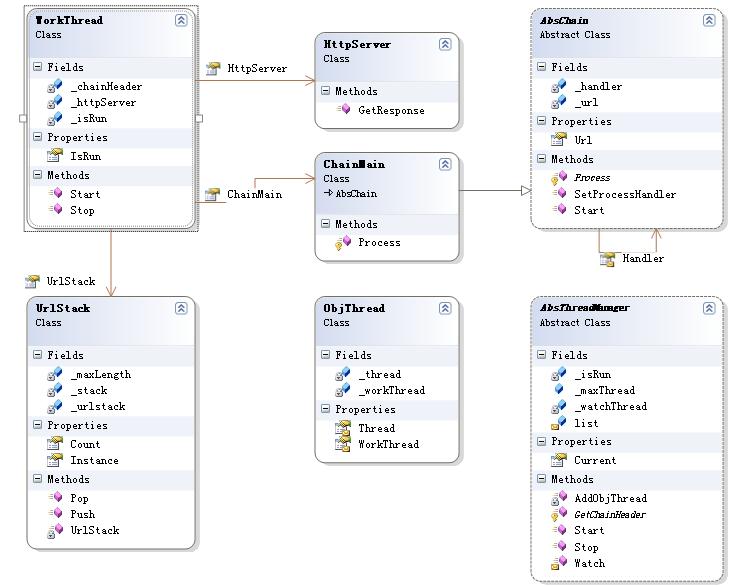
现在我们就开始利用Spilder程序集来构建一个简单的网络蜘蛛程序
数据库部分(本示例用的是SQL Server2005)
创建数据库SpiderDB
新增表:temp
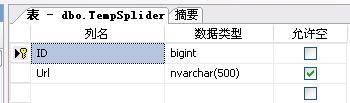
这个表是用来保存UrlStack中的URL值,当服务启动时UrlStack从这张表中装载URL,当服务退出时UrlStack中的Url将保存在这张表中.
新增表SpiderTable
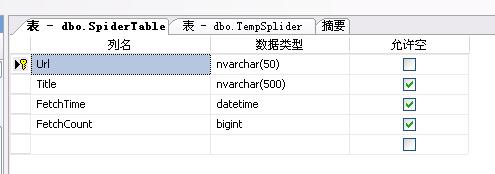
这张表用来将获取到的网页内容保存,在示例程序中我只从网页的HTML获取Title信息,并记录抓取时间,和被抓取次数
新增一个储存过程,用来添加抓取信息到SpiderTable中代码如下:
CREATE Procedure [dbo].[AddWeb]
@url nvarchar(500),
@title nvarchar(500)
as
if not exists(select Url from SpiderTable where Url=@url)
insert into SpiderTable(Url,Title) values(@url,@title)
else
update SpiderTable set FetchCount=FetchCount+1,Title=@title
where Url=@url
当URL已存在在表中则更新FetchCount的值
数据库部分完
未完,待续……















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









