









《从菜鸟到大师之路 Redis 篇》
(一):Redis 基础理论与安装配置
Nosql 数据库介绍
是一种 非关系型 数据库服务,它能 解决常规数据库的并发能力 ,比如 传统的数据库的IO与性能的瓶颈 ,同样它是关系型数据库的一个补充,有着比较好的高效率与高性能。专注于key-value查询的redis、memcached、ttserver。

解决以下问题
对数据库的高并发读写需求
大数据的高效存储和访问需求
高可扩展性和高可用性的需求
什么是 Redis
Redis 是一款 内存高速缓存 数据库。Redis全称为: Remote Dictionary Server(远程数据服务) ,使用C语言编写,Redis是一个key-value存储系统(键值存储系统),支持丰富的数据类型,如:String、list、set、zset、hash。
Redis是一种支持key-value等多种数据结构的存储系统。可用于缓存,事件发布或订阅,高速队列等场景。支持网络,提供字符串,哈希,列表,队列,集合结构直接存取,基于内存,可持久化。
官方资料
Redis官网:http://redis.io/
Redis官方文档:http://redis.io/documentation
Redis教程:http://www.w3cschool.cn/redis/redis-intro.html
Redis下载:http://redis.io/download
为什么要使用 Redis
一个产品的使用场景肯定是需要根据产品的特性,先列举一下
Redis的特点
读写性能优异
- Redis能读的速度是110000次/s,写的速度是81000次/s (测试条件见下一节)。
数据类型丰富
- Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
原子性
- Redis的所有操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行。
丰富的特性
- Redis支持 publish/subscribe, 通知, key 过期等特性。
持久化
- Redis支持RDB, AOF等持久化方式
发布订阅
- Redis支持发布/订阅模式
分布式
- Redis Cluster
所以,无论是运维还是开发、测试,对于 NoSQL 数据库之一的 Redis 也是必学知识体系之一。
下面是官方的bench-mark根据如下条件获得的性能测试(读的速度是110000次/s,写的速度是81000次/s)
- 测试完成了50个并发执行100000个请求。
- 设置和获取的值是一个256字节字符串。
- Linux box是运行Linux 2.6,这是X3320 Xeon 2.5 ghz。
- 文本执行使用loopback接口(127.0.0.1)。
Redis有哪些优缺点
优点
- 读写性能优异 , Redis能读的速度是110000次/s,写的速度是81000次/s。
- 支持数据持久化 ,支持AOF和RDB两种持久化方式。
- 支持事务 ,Redis的所有操作都是原子性的,同时Redis还支持对几个操作合并后的原子性执行。
- 数据结构丰富 ,除了支持string类型的value外还支持hash、set、zset、list等数据结构。
- 支持主从复制 ,主机会自动将数据同步到从机,可以进行读写分离。
缺点
- 数据库容量受到物理内存的限制,不能用作海量数据的高性能读写 ,因此Redis适合的场景主要 局限在较小数据量 的高性能操作和运算上。
- Redis 不具备自动容错和恢复功能 ,主机从机的宕机都会导致前端部分读写请求失败,需要等待机器重启或者手动切换前端的IP才能恢复。
- 主机宕机,宕机前有部分数据未能及时同步到从机,切换IP后还会引入数据不一致的问题 ,降低了系统的可用性。
- Redis 较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。 为避免这一问题,运维人员在系统上线时必须确保有足够的空间,这对资源造成了很大的浪费。
Redis的使用场景
redis 应用场景总结 redis 平时我们用到的地方蛮多的,下面就了解的应用场景做个总结:
热点数据的缓存
缓存是Redis最常见的应用场景,之所有这么使用,主要是因为Redis读写性能优异。而且逐渐有取代memcached,成为首选服务端缓存的组件。而且,Redis内部是支持事务的,在使用时候能有效保证数据的一致性。
有两种方式保存数据
作为缓存使用时,一般 有两种方式保存数据 :
方案一:读取前,先去读Redis,如果没有数据,读取数据库,将数据拉入Redis
实施起来简单,但是有两个需要注意的地方:
- 避免缓存击穿。(数据库没有就需要命中的数据,导致Redis一直没有数据,而一直命中数据库。)
- 数据的实时性相对会差一点。
方案二:插入数据时,同时写入Redis
- 数据实时性强,但是开发时不便于统一处理。
当然,两种方式根据实际情况来适用。如: 方案一适用于对于数据实时性要求不是特别高的场景。方案二适用于字典表、数据量不大的数据存储。
限时业务的运用
redis中可以使用 expire 命令设置一个键的生存时间,到时间后redis会删除它。利用这一特性可以 运用在限时的优惠活动信息、手机验证码 等业务场景。
计数器相关问题
redis由于 incrby 命令可以实现 原子性的递增 ,所以可以 运用于高并发的秒杀活动、分布式序列号的生成、具体业务还体现在比如限制一个手机号发多少条短信、一个接口一分钟限制多少请求、一个接口一天限制调用多少次 等等。
int类型,incr方法
例如: 文章的阅读量、微博点赞数、允许一定的延迟,先写入Redis再定时同步到数据库 。
分布式锁
这个主要利用redis的 setnx 命令进行,setnx:"set if not exists"就是如果不存在则成功设置缓存同时返回1,否则返回0 ,这个特性在很多后台中都有所运用,因为我们服务器是集群的,定时任务可能在两台机器上都会运行,所以在定时任务中首先 通过setnx设置一个lock, 如果成功设置则执行,如果没有成功设置,则表明该定时任务已执行。当然结合具体业务,我们可以给这个lock加一个过期时间,比如说30分钟执行一次的定时任务,那么这个过期时间设置为小于30分钟的一个时间就可以,这个与定时任务的周期以及定时任务执行消耗时间相关。
String 类型setnx方法,只有不存在时才能添加成功,返回true
public static boolean getLock(String key) {
Long flag = jedis.setnx(key, "1");
if (flag == 1) {
jedis.expire(key, 10);
}
return flag == 1;
}
public static void releaseLock(String key) {
jedis.del(key);
}
在分布式锁的场景中,主要用在比如秒杀系统等。
延时操作
比如 在订单生产后我们占用了库存,10分钟后去检验用户是否真正购买,如果没有购买将该单据设置无效,同时还原库存。 由于redis自2.8.0之后版本提供Keyspace Notifications功能,允许客户订阅Pub/Sub频道,以便以某种方式接收影响Redis数据集的事件。所以我们对于上面的需求就可以用以下解决方案,我们 在订单生产时,设置一个key,同时设置10分钟后过期, 我们在后台实现一个监听器,监听key的实效,监听到key失效时将后续逻辑加上。
当然我们也可以利用 rabbitmq、activemq 等消息中间件的 延迟队列服务 实现该需求。
排行榜相关问题
关系型数据库在排行榜方面查询速度普遍偏慢,所以可以借助redis的 SortedSet 进行热点数据的排序。
比如点赞排行榜,做一个SortedSet, 然后以用户的openid作为上面的username, 以用户的点赞数作为上面的score, 然后针对每个用户做一个hash, 通过zrangebyscore就可以按照点赞数获取排行榜,然后再根据username获取用户的hash信息,这个当时在实际运用中性能体验也蛮不错的。
点赞、好友等相互关系的存储
Redis 利用集合的一些命令,比如 求交集、并集、差集 等。
在微博应用中,每个用户关注的人存在一个集合中,就很容易实现求两个人的共同好友功能。
假如上面的微博ID是t1001,用户ID是u3001
用 like:t1001 来维护 t1001 这条微博的所有点赞用户
点赞了这条微博:sadd like:t1001 u3001
取消点赞:srem like:t1001 u3001
是否点赞:sismember like:t1001 u3001
点赞的所有用户:smembers like:t1001
点赞数:scard like:t1001
是不是比数据库简单多了。 7000字 Redis 超详细总结笔记 !建议收藏
简单队列
由于Redis有 list push和list pop 这样的命令,所以能够很方便的执行队列操作。
List提供了两个阻塞的弹出操作:blpop/brpop,可以设置超时时间
- blpop:blpop key1 timeout 移除并获取列表的第一个元素,如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
- brpop:brpop key1 timeout 移除并获取列表的最后一个元素,如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
上面的操作。其实就是java的阻塞队列。学习的东西越多。学习成本越低
队列:先进先除:rpush blpop,左头右尾,右边进入队列,左边出队列
栈:先进后出:rpush brpop
更多关于Redis的应用场景解析请参阅: Redis 16 大应用场景
Redis为什么这么快
1、 完全基于内存,绝大部分请求是纯粹的内存操作 ,非常快速。数据存在内存中,类似于 HashMap,HashMap 的优势就是查找和操作的时间复杂度都是O(1);
2、 数据结构简单,对数据操作也简单 ,Redis 中的数据结构是专门进行设计的;
3、 采用单线程 ,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
4、 使用多路 I/O 复用模型,非阻塞 IO ;
5、使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样, Redis 直接自己构建了 VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求;
Redis 为什么是单线程的?
- 代码更清晰,处理逻辑更简单;
- 不用考虑各种锁的问题,不存在加锁和释放锁的操作,没有因为可能出现死锁而导致的性能问题;
- 不存在多线程切换而消耗CPU;
- 无法发挥多核CPU的优势,但可以采用多开几个Redis实例来完善;
Redis真的是单线程的吗?
- Redis6.0之前是单线程的,Redis6.0之后开始支持多线程;
- Redis内部使用了基于epoll的多路复用,也可以多部署几个Redis服务器解决单线程的问题;
- Redis主要的性能瓶颈是内存和网络;
- 内存好说,加内存条就行了,而网络才是大麻烦,所以Redis6内存好说,加内存条就行了;
- 而网络才是大麻烦,所以Redis6.0引入了多线程的概念;
- Redis6.0在网络IO处理方面引入了多线程,如网络数据的读写和协议解析等,需要注意的是,执行命令的核心模块还是单线程的;
Redis 安装
Linux下安装Redis
下载安装
# 安装gcc
yum install gcc
# 下载redis wget下载或者直接去 http://redis.io/download 官网下载
wget http://download.redis.io/releases/redis-7.0.0.tar.gz
# 把下载好的redis解压
tar xzf redis-7.0.0.tar.gz
# 进入到解压好的redis-7.0.0.tar.gz目录下,进行编译与安装
cd redis-7.0.0.tar.gz
make
make install
修改配置文件
按需修改自己想要的redis配置。
# 编辑redis.conf配置文件
vim redis.conf
# Redis使用后台模式
daemonize yes
# 关闭保护模式
protected-mode no
# 注释以下内容开启远程访问
# bind 127.0.0.1
# 修改启动端口为6381
port 6381
启动Redis
# 启动并指定配置文件
src/redis‐server redis.conf(注意要使用后台启动,所以修改redis.conf里的daemonize改为yes)
# 验证启动是否成功
ps -ef|grep redis
# 进入redis客户端
src/redis-cli
redis-cli -h 192.168.239.131 -p 6379 (指定ip 端口连接redis)
# 退出客户端
quit
# 退出redis服务
pkill redis‐server
kill 进程号
src/redis‐cli shutdown
# 设置redis密码
config set requirepass 123456
# 验证密码
auth 123456
# 查看密码
config get requirepass
Windows 下安装 Redis
下载安装
下载地址:https://github.com/MicrosoftArchive/redis/tags
直接下载 Redis-x64-3.2.100.msi 版本即可,双击安装:

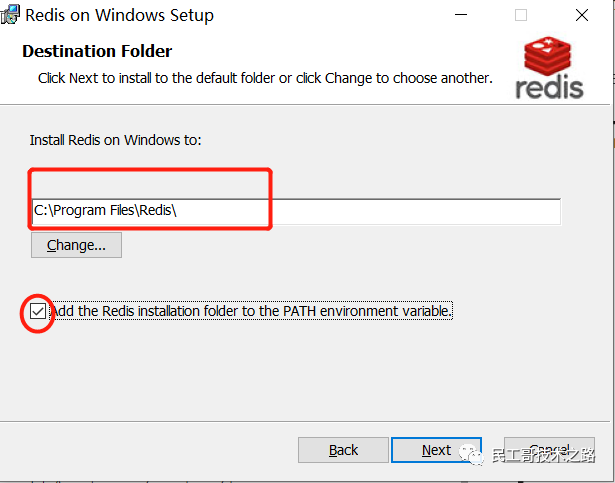
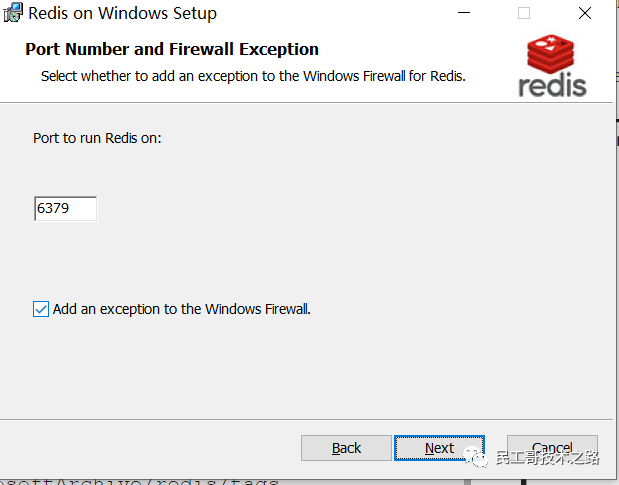
都选择默认即可,下一步、下一步安装就行了,非常的简单。

然后可以去连接一下,cmd窗口输入命令telnet 127.0.0.1 6379

正常连接,也可以正常操作
Redis.conf 详解
找到启动时指定的配置文件(redis.conf):
单位
# Redis configuration file example.
#
# Note that in order to read the configuration file, Redis must be
# started with the file path as first argument:
#
# ./redis-server /path/to/redis.conf
# Note on units: when memory size is needed, it is possible to specify
# it in the usual form of 1k 5GB 4M and so forth:
#
# 1k => 1000 bytes
# 1kb => 1024 bytes
# 1m => 1000000 bytes
# 1mb => 1024*1024 bytes
# 1g => 1000000000 bytes
# 1gb => 1024*1024*1024 bytes
#
# units are case insensitive so 1GB 1Gb 1gB are all the same.
配置文件中 unit 单位对大小写不敏感。
包含
################################## INCLUDES ###################################
# Include one or more other config files here. This is useful if you
# have a standard template that goes to all Redis servers but also need
# to customize a few per-server settings. Include files can include
# other files, so use this wisely.
#
# Notice option "include" won't be rewritten by command "CONFIG REWRITE"
# from admin or Redis Sentinel. Since Redis always uses the last processed
# line as value of a configuration directive, you'd better put includes
# at the beginning of this file to avoid overwriting config change at runtime.
#
# If instead you are interested in using includes to override configuration
# options, it is better to use include as the last line.
#
# include /path/to/local.conf
# include /path/to/other.conf
配置文件可以将多个配置文件合起来使用。
NETWORK 网络
bind 127.0.0.1 #绑定的 IP
protected-mode no #保护模式
port 6379 #端口设置
GENERAL 通用
daemonize yes # 以守护进程的方式运行,默认是 no ,我们需要自己开启为 yes
pidfile /var/run/redis_6379.pid # 如果是后台启动,我们需要指定一个pid 文件
# 日志级别
# Specify the server verbosity level.
# This can be one of:
# debug (a lot of information, useful for development/testing)
# verbose (many rarely useful info, but not a mess like the debug level)
# notice (moderately verbose, what you want in production probably)
# warning (only very important / critical messages are logged)
loglevel notice
logfile "" # 日志文件的位置
databases 16 # 数据库的数量,默认是 16
always-show-logo yes # 是否总是显示 LOGO
快照 SNAPSHOTTING
持久化, 在规定的时间内,执行了多少次操作则会持久化到文件 。
Redis 是内存数据库, 如果没有持久化,那么数据断电即失 。
################################ SNAPSHOTTING ################################
#
# Save the DB on disk:
#
# save <seconds> <changes>
#
# Will save the DB if both the given number of seconds and the given
# number of write operations against the DB occurred.
#
# In the example below the behaviour will be to save:
# after 900 sec (15 min) if at least 1 key changed
# after 300 sec (5 min) if at least 10 keys changed
# after 60 sec if at least 10000 keys changed
#
# Note: you can disable saving completely by commenting out all "save" lines.
#
# It is also possible to remove all the previously configured save
# points by adding a save directive with a single empty string argument
# like in the following example:
#
# save ""
# 如果 900s 内,至少有 1 个 key 进行了修改,进行持久化操作
save 900 1
# 如果 300s 内,至少有 10 个 key 进行了修改,进行持久化操作
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes # 如果持久化出错,是否还要继续工作
rdbcompression yes # 是否压缩 rdb 文件,需要消耗一些 cpu 资源
rdbchecksum yes # 保存 rdb 文件的时候,进行错误的检查校验
dir ./ # rdb 文件保存的目录
SECURITY 安全
可以 设置 Redis 的密码 ,默认是没有密码的。
[root@xxx bin]# redis-cli -p 6379
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> config get requirepass # 获取 redis 密码
1) "requirepass"
2) ""
127.0.0.1:6379> config set requirepass "123456" # 设置 redis 密码
OK
127.0.0.1:6379> ping
(error) NOAUTH Authentication required. # 发现所有的命令都没有权限了
127.0.0.1:6379> auth 123456 # 使用密码登录
OK
127.0.0.1:6379> config get requirepass
1) "requirepass"
2) "123456"
127.0.0.1:6379>
CLIENTS 限制
################################### CLIENTS ####################################
# Set the max number of connected clients at the same time. By default
# this limit is set to 10000 clients, however if the Redis server is not
# able to configure the process file limit to allow for the specified limit
# the max number of allowed clients is set to the current file limit
# minus 32 (as Redis reserves a few file descriptors for internal uses).
#
# Once the limit is reached Redis will close all the new connections sending
# an error 'max number of clients reached'.
#
# maxclients 10000 # 设置能链接上 redis 的最大客户端数量
# maxmemory <bytes> # redis 设置最大的内存容量
maxmemory-policy noeviction # 内存达到上限之后的处理策略
- noeviction:当内存使用达到阈值的时候,所有引起申请内存的命令会报错。
- allkeys-lru:在所有键中采用lru算法删除键,直到腾出足够内存为止。
- volatile-lru:在设置了过期时间的键中采用lru算法删除键,直到腾出足够内存为止。
- allkeys-random:在所有键中采用随机删除键,直到腾出足够内存为止。
- volatile-random:在设置了过期时间的键中随机删除键,直到腾出足够内存为止。
- volatile-ttl:在设置了过期时间的键空间中,具有更早过期时间的key优先移除。
APPEND ONLY 模式 AOF 配置
appendonly no # 默认是不开启 AOF 模式的,默认使用 rdb 方式持久化,大部分情况下,rdb 完全够用
appendfilename "appendonly.aof" # 持久化的文件的名字
# appendfsync always # 每次修改都会 sync 消耗性能
appendfsync everysec # 每秒执行一次 sync 可能会丢失这 1s 的数据。
# appendfsync no # 不执行 sync 这个时候操作系统自己同步数据,速度最快。
参考来源:
https://www.pdai.tech/md/db/nosql-redis/db-redis-overview.html
https://www.cnblogs.com/itzhouq/p/redis4.html
拓展
(二):Redis 9 种数据类型和应用场景
Redis 数据结构简介
Redis 基础文章非常多,关于 基础数据结构类型 ,我推荐你先看下官方网站内容,然后再看下面的小结。
首先对 redis 来说,所有的 key(键)都是字符串。我们在谈基础数据结构时,讨论的是存储值的数据类型,主要包括常见的5种数据类型,分别是:String、List、Set、Zset、Hash。
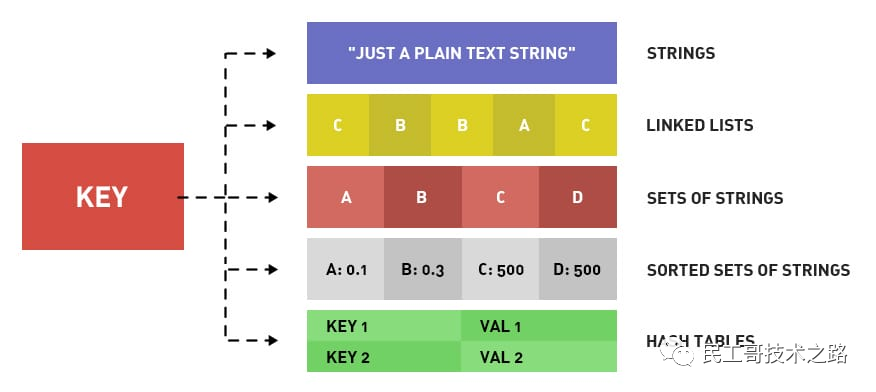
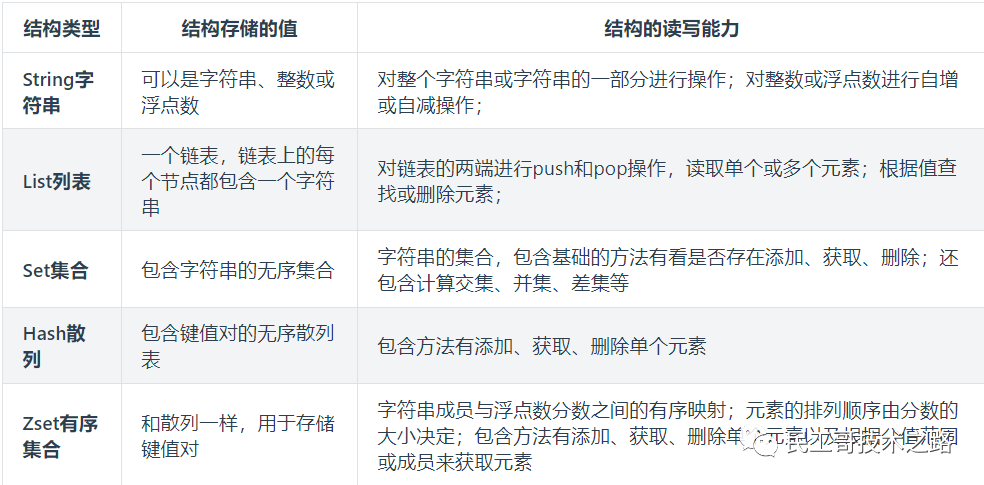
5 种基础数据类型
内容其实比较简单,我觉得理解的重点在于这个结构怎么用,能够用来做什么?所以我在梳理时,围绕图例,命令,执行和场景来阐述。
String 字符串
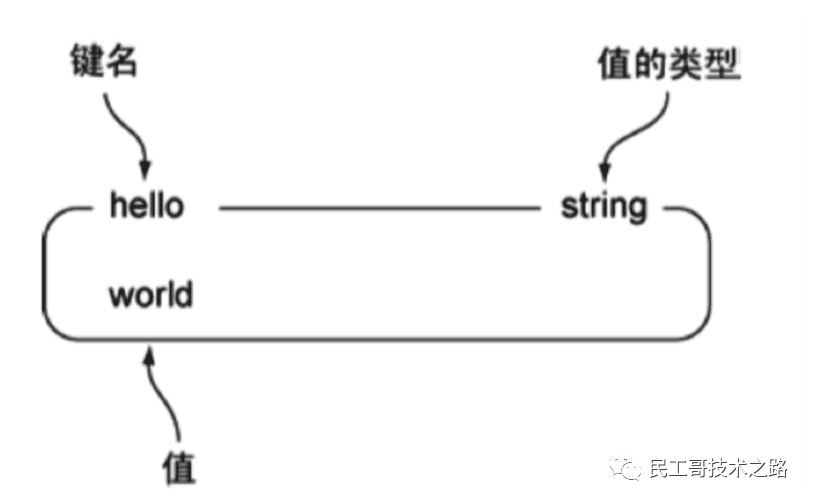
String是redis中最基本的数据类型,一个key对应一个value。
String 类型是 二进制安全的 ,意思是 redis 的 string 可以包含任何数据。如数字,字符串,jpg图片或者序列化的对象。
图例
下图是一个String类型的实例,其中键为hello,值为world图片
命令使用
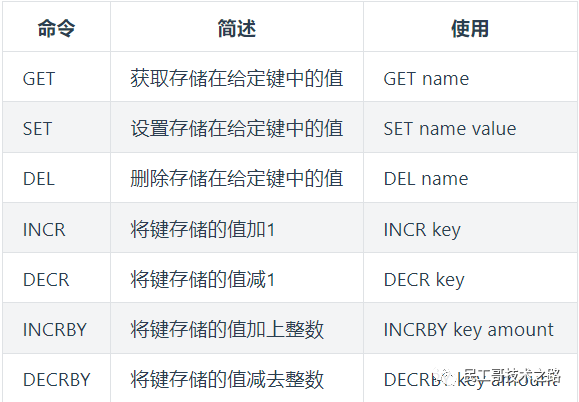
命令执行
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> get hello
"world"
127.0.0.1:6379> del hello
(integer) 1
127.0.0.1:6379> get hello
(nil)
127.0.0.1:6379> set counter 2
OK
127.0.0.1:6379> get counter
"2"
127.0.0.1:6379> incr counter
(integer) 3
127.0.0.1:6379> get counter
"3"
127.0.0.1:6379> incrby counter 100
(integer) 103
127.0.0.1:6379> get counter
"103"
127.0.0.1:6379> decr counter
(integer) 102
127.0.0.1:6379> get counter
"102"
实战场景
- 缓存 :经典使用场景,把常用信息,字符串,图片或者视频等信息放到redis中,redis 作为缓存层,mysql做持久化层,降低mysql的读写压力。
- 计数器 :redis是单线程模型,一个命令执行完才会执行下一个,同时数据可以一步落地到其他的数据源。
- session :常见方案spring session + redis实现session共享。
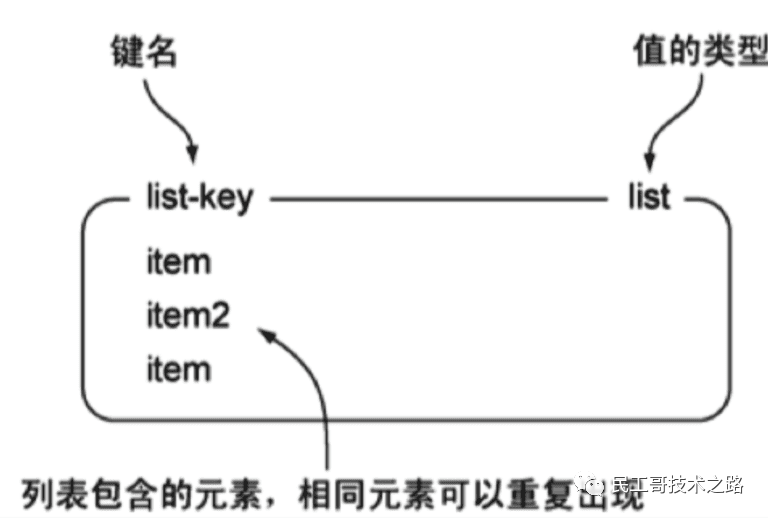
List列表
Redis 中的 List 其实就是 链表 (Redis 用 双端链表 实现 List )。
使用 List 结构,我们可以轻松地实现 最新消息排队功能 (比如新浪微博的TimeLine)。List 的另一个应用就是消息队列,可以利用List的 PUSH 操作,将任务存放在 List 中,然后工作线程再用 POP 操作将任务取出进行执行。
图例
命令使用
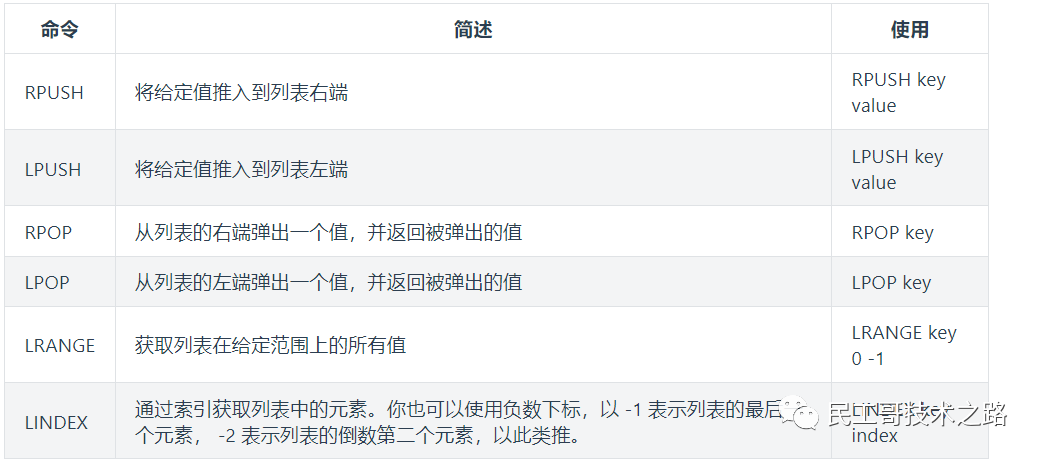
使用列表的技巧
- lpush+lpop=Stack(栈)
- lpush+rpop=Queue(队列)
- lpush+ltrim=Capped Collection(有限集合)
- lpush+brpop=Message Queue(消息队列)
命令执行
127.0.0.1:6379> lpush mylist 1 2 ll ls mem
(integer) 5
127.0.0.1:6379> lrange mylist 0 -1
1) "mem"
2) "ls"
3) "ll"
4) "2"
5) "1"
127.0.0.1:6379> lindex mylist -1
"1"
127.0.0.1:6379> lindex mylist 10 # index不在 mylist 的区间范围内
(nil)
实战场景
- 微博TimeLine : 有人发布微博,用lpush加入时间轴,展示新的列表信息。
- 消息队列
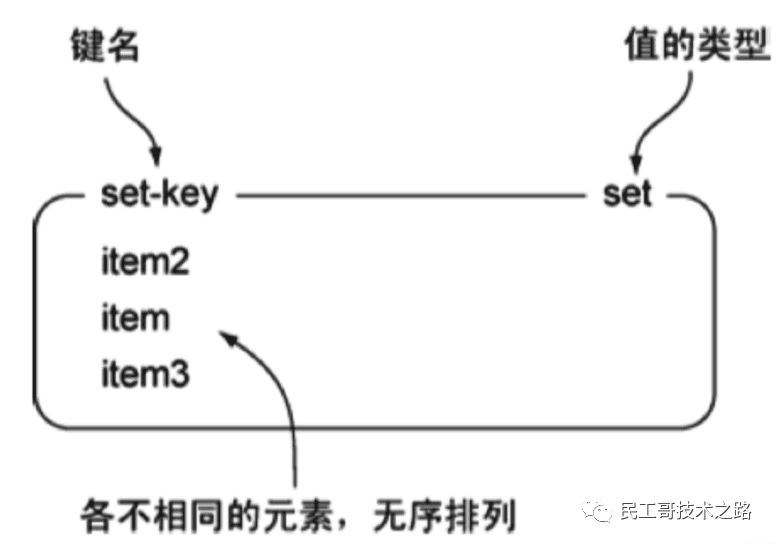
Set集合
Redis 的 Set 是 String 类型的 无序集合 。集合成员是唯一的,这就意味着 集合中不能出现重复的数据。
Redis 中集合是通过 哈希表 实现的,所以 添加,删除,查找的复杂度都是 O(1) 。
图例
命令使用
命令执行
127.0.0.1:6379> sadd myset hao hao1 xiaohao hao
(integer) 3
127.0.0.1:6379> smembers myset
1) "xiaohao"
2) "hao1"
3) "hao"
127.0.0.1:6379> sismember myset hao
(integer) 1
实战场景
- 标签(tag) ,给用户添加标签,或者用户给消息添加标签,这样有同一标签或者类似标签的可以给推荐关注的事或者关注的人。
- 点赞,或点踩,收藏等 ,可以放到set中实现
Hash散列
Redis hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表 ,hash 特别适合用于 存储对象 。
图例

命令使用
命令执行
127.0.0.1:6379> hset user name1 hao
(integer) 1
127.0.0.1:6379> hset user email1 hao@163.com
(integer) 1
127.0.0.1:6379> hgetall user
1) "name1"
2) "hao"
3) "email1"
4) "hao@163.com"
127.0.0.1:6379> hget user user
(nil)
127.0.0.1:6379> hget user name1
"hao"
127.0.0.1:6379> hset user name2 xiaohao
(integer) 1
127.0.0.1:6379> hset user email2 xiaohao@163.com
(integer) 1
127.0.0.1:6379> hgetall user
1) "name1"
2) "hao"
3) "email1"
4) "hao@163.com"
5) "name2"
6) "xiaohao"
7) "email2"
8) "xiaohao@163.com"
实战场景
- 缓存 :能直观,相比string更节省空间,的维护缓存信息,如用户信息,视频信息等。
Zset有序集合
Redis 有序集合和集合一样也是 string 类型元素的集合,且 不允许重复的成员 。 不同的是每个元素都会关联一个 double 类型的分数 。redis 正是通过分数来为集合中的成员进行从小到大的排序。
有序集合的成员是唯一的, 但分数(score)却可以重复。 有序集合是通过 两种数据结构 实现:
- 压缩列表(ziplist) : ziplist是为了提高存储效率而设计的一种特殊编码的双向链表。它可以存储字符串或者整数,存储整数时是采用整数的二进制而不是字符串形式存储。它能在O(1)的时间复杂度下完成list两端的push和pop操作。但是因为每次操作都需要重新分配ziplist的内存,所以实际复杂度和ziplist的内存使用量相关
- 跳跃表(zSkiplist) : 跳跃表的性能可以保证在查找,删除,添加等操作的时候在对数期望时间内完成,这个性能是可以和平衡树来相比较的,而且在实现方面比平衡树要优雅,这是采用跳跃表的主要原因。跳跃表的复杂度是O(log(n))。
图例

命令使用
命令执行
127.0.0.1:6379> zadd myscoreset 100 hao 90 xiaohao
(integer) 2
127.0.0.1:6379> ZRANGE myscoreset 0 -1
1) "xiaohao"
2) "hao"
127.0.0.1:6379> ZSCORE myscoreset hao
"100"
实战场景
- 排行榜 :有序集合经典使用场景。例如小说视频等网站需要对用户上传的小说视频做排行榜,榜单可以按照用户关注数,更新时间,字数等打分,做排行。
3 种特殊类型
Redis 除了上文中 5 种基础数据类型 ,还有 3 种特殊的数据类型 ,分别是 HyperLogLogs(基数统计), Bitmaps (位图) 和 geospatial (地理位置) 。
HyperLogLogs(基数统计)
Redis 2.8.9 版本更新了 Hyperloglog 数据结构!
什么是基数?
举个例子, A = {1, 2, 3, 4, 5}, B = {3, 5, 6, 7, 9};那么 基数(不重复的元素)= 1, 2, 4, 6, 7, 9 ;( 允许容错,即可以接受一定误差 )
HyperLogLogs 基数统计用来解决什么问题?
这个结构可以 非常省内存的去统计各种计数 ,比如 注册 IP 数、每日访问 IP 数、页面实时UV、在线用户数,共同好友数 等。
它的优势体现在哪?
一个大型的网站,每天 IP 比如有 100 万,粗算一个 IP 消耗 15 字节,那么 100 万个 IP 就是 15M。而 HyperLogLog 在 Redis 中每个键占用的内容都是 12K,理论存储近似接近 2^64 个值,不管存储的内容是什么,它一个基于基数估算的算法,只能比较准确的估算出基数,可以使用少量固定的内存去存储并识别集合中的唯一元素。而且这个估算的基数并不一定准确,是一个带有 0.81% 标准错误的近似值(对于可以接受一定容错的业务场景,比如IP数统计,UV 等,是可以忽略不计的)。
相关命令使用
127.0.0.1:6379> pfadd key1 a b c d e f g h i # 创建第一组元素
(integer) 1
127.0.0.1:6379> pfcount key1 # 统计元素的基数数量
(integer) 9
127.0.0.1:6379> pfadd key2 c j k l m e g a # 创建第二组元素
(integer) 1
127.0.0.1:6379> pfcount key2
(integer) 8
127.0.0.1:6379> pfmerge key3 key1 key2 # 合并两组:key1 key2 -> key3 并集
OK
127.0.0.1:6379> pfcount key3
(integer) 13
Bitmap (位存储)
Bitmap 即 位图数据结构 ,都是 操作二进制位 来进行记录,只有 0 和 1 两个状态。
用来解决什么问题?
比如: 两个状态统计用户信息,活跃,不活跃!登录,未登录!打卡,不打卡! 的,都可以使用 Bitmaps!
如果存储一年的打卡状态需要多少内存呢?365 天 = 365 bit 1字节 = 8bit 46 个字节左右!
相关命令使用
使用bitmap 来记录 周一到周日的打卡 !周一:1 周二:0 周三:0 周四:1 …
127.0.0.1:6379> setbit sign 0 1
(integer) 0
127.0.0.1:6379> setbit sign 1 1
(integer) 0
127.0.0.1:6379> setbit sign 2 0
(integer) 0
127.0.0.1:6379> setbit sign 3 1
(integer) 0
127.0.0.1:6379> setbit sign 4 0
(integer) 0
127.0.0.1:6379> setbit sign 5 0
(integer) 0
127.0.0.1:6379> setbit sign 6 1
(integer) 0
查看某一天是否有打卡!
127.0.0.1:6379> getbit sign 3
(integer) 1
127.0.0.1:6379> getbit sign 5
(integer) 0
统计操作,统计 打卡的天数!
127.0.0.1:6379> bitcount sign # 统计这周的打卡记录,就可以看到是否有全勤!
(integer) 3
geospatial (地理位置)
Redis 的 Geo 在 Redis 3.2 版本就推出了! 这个功能可以推算地理位置的信息: 两地之间的距离, 方圆几里的人
geoadd 添加地理位置
127.0.0.1:6379> geoadd china:city 118.76 32.04 manjing 112.55 37.86 taiyuan 123.43 41.80 shenyang
(integer) 3
127.0.0.1:6379> geoadd china:city 144.05 22.52 shengzhen 120.16 30.24 hangzhou 108.96 34.26 xian
(integer) 3
规则
两级无法直接添加,我们一般会下载城市数据(这个网址可以查询 GEO:http://www.jsons.cn/lngcode)!
- 有效的经度从-180度到180度。
- 有效的纬度从-85.05112878度到85.05112878度。
# 当坐标位置超出上述指定范围时,该命令将会返回一个错误。
127.0.0.1:6379> geoadd china:city 39.90 116.40 beijin
(error) ERR invalid longitude,latitude pair 39.900000,116.400000
geopos 获取指定的成员的经度和纬度
127.0.0.1:6379> geopos china:city taiyuan manjing
1) 1) "112.54999905824661255"
1) "37.86000073876942196"
2) 1) "118.75999957323074341"
1) "32.03999960287850968"
获得当前定位, 一定是一个坐标值!
geodist
如果不存在, 返回空。
单位如下:
- m
- km
- mi 英里
- ft 英尺
127.0.0.1:6379> geodist china:city taiyuan shenyang m
"1026439.1070"
127.0.0.1:6379> geodist china:city taiyuan shenyang km
"1026.4391"
georadius
附近的人 ==> 获得所有附近的人的地址, 定位, 通过半径来查询。
获得指定数量的人
127.0.0.1:6379> georadius china:city 110 30 1000 km 以 100,30 这个坐标为中心, 寻找半径为1000km的城市
1) "xian"
2) "hangzhou"
3) "manjing"
4) "taiyuan"
127.0.0.1:6379> georadius china:city 110 30 500 km
1) "xian"
127.0.0.1:6379> georadius china:city 110 30 500 km withdist
1) 1) "xian"
2) "483.8340"
127.0.0.1:6379> georadius china:city 110 30 1000 km withcoord withdist count 2
1) 1) "xian"
2) "483.8340"
3) 1) "108.96000176668167114"
2) "34.25999964418929977"
2) 1) "manjing"
2) "864.9816"
3) 1) "118.75999957323074341"
2) "32.03999960287850968"
参数:key 经度 纬度 半径 单位 [显示结果的经度和纬度] [显示结果的距离] [显示的结果的数量]
georadiusbymember
显示与指定成员一定半径范围内的其他成员
127.0.0.1:6379> georadiusbymember china:city taiyuan 1000 km
1) "manjing"
2) "taiyuan"
3) "xian"
127.0.0.1:6379> georadiusbymember china:city taiyuan 1000 km withcoord withdist count 2
1) 1) "taiyuan"
2) "0.0000"
3) 1) "112.54999905824661255"
2) "37.86000073876942196"
2) 1) "xian"
2) "514.2264"
3) 1) "108.96000176668167114"
2) "34.25999964418929977"
参数与 georadius 一样
geohash(较少使用)
该命令返回11个字符的hash字符串
127.0.0.1:6379> geohash china:city taiyuan shenyang
1) "ww8p3hhqmp0"
2) "wxrvb9qyxk0"
将二维的经纬度转换为一维的字符串, 如果两个字符串越接近, 则距离越近
底层
geo 底层的实现原理 实际上就是 Zset , 我们可以通过 Zset命令来操作 geo。
127.0.0.1:6379> type china:city
zset
查看全部元素 删除指定的元素
127.0.0.1:6379> zrange china:city 0 -1 withscores
1) "xian"
2) "4040115445396757"
3) "hangzhou"
4) "4054133997236782"
5) "manjing"
6) "4066006694128997"
7) "taiyuan"
8) "4068216047500484"
9) "shenyang"
1) "4072519231994779"
2) "shengzhen"
3) "4154606886655324"
127.0.0.1:6379> zrem china:city manjing
(integer) 1
127.0.0.1:6379> zrange china:city 0 -1
1) "xian"
2) "hangzhou"
3) "taiyuan"
4) "shenyang"
5) "shengzhen"
Stream 类型
为什么会设计Stream
Redis5.0 中还增加了一个数据结构 Stream,从字面上看是 流类型 ,但其实从功能上看,应该是 Redis 对消息队列(MQ,Message Queue)的完善实现 。
Reids 的消息队列
用过 Redis 做消息队列的都了解,基于 Reids 的消息队列实现有很多种,例如:
PUB/SUB,订阅/发布模式
- 但是发布订阅模式是无法持久化的,如果出现网络断开、Redis 宕机等,消息就会被丢弃;
基于List LPUSH+BRPOP 或者 基于Sorted-Set的实现
- 支持了持久化,但是不支持多播,分组消费等
设计一个消息队列需要考虑什么?
为什么上面的结构无法满足广泛的MQ场景? 这里便引出一个核心的问题:如果我们期望设计一种数据结构来实现消息队列,最重要的就是要理解设计一个消息队列需要考虑什么?初步的我们很容易想到
- 消息的生产
- 消息的消费
- 单播和多播(多对多)
- 阻塞和非阻塞读取
- 消息有序性
- 消息的持久化
其它还要考虑啥嗯?借助美团技术团队的一篇文章,消息队列设计精要中的图片
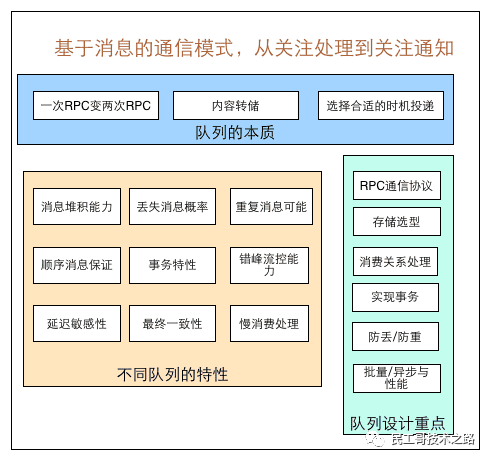
我们不妨看看Redis考虑了哪些设计?
- 消息ID的序列化生成
- 消息遍历
- 消息的阻塞和非阻塞读取
- 消息的分组消费
- 未完成消息的处理
- 消息队列监控
- …
这也是我们需要理解Stream的点,但是结合上面的图,我们也应该理解 Redis Stream也是一种超轻量MQ并没有完全实现消息队列所有设计要点,这决定着它适用的场景。
Stream详解
经过梳理总结,我认为从以下几个大的方面去理解Stream是比较合适的,总结如下:
- Stream的结构设计
- 生产和消费
- 基本的增删查改
- 单一消费者的消费
- 消费组的消费
- 监控状态
Stream的结构
每个 Stream 都有唯一的名称,它就是 Redis 的 key,在我们首次使用 xadd 指令追加消息时自动创建。
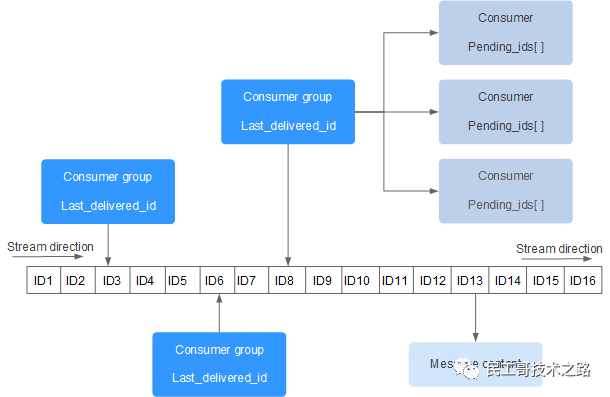
上图解析:
- Consumer Group :消费组 ,使用 XGROUP CREATE 命令创建,一个消费组有多个消费者(Consumer), 这些消费者之间是竞争关系。
- last_delivered_id :游标 ,每个消费组会有个游标 last_delivered_id,任意一个消费者读取了消息都会使游标 last_delivered_id 往前移动。
- pending_ids :消费者(Consumer)的状态变量 ,作用是维护消费者的未确认的 id。 pending_ids 记录了当前已经被客户端读取的消息,但是还没有 ack (Acknowledge character:确认字符)。如果客户端没有ack,这个变量里面的消息ID会越来越多,一旦某个消息被ack,它就开始减少。这个pending_ids变量在Redis官方被称之为PEL,也就是Pending Entries List,这是一个很核心的数据结构,它用来确保客户端至少消费了消息一次,而不会在网络传输的中途丢失了没处理。
此外我们 还需要理解两点 :
- 消息ID : 消息ID的形式是timestampInMillis-sequence,例如1527846880572-5,它表示当前的消息在毫米时间戳1527846880572时产生,并且是该毫秒内产生的第5条消息。消息ID可以由服务器自动生成,也可以由客户端自己指定,但是形式必须是整数-整数,而且必须是后面加入的消息的ID要大于前面的消息ID。
- 消息内容 : 消息内容就是键值对,形如hash结构的键值对,这没什么特别之处。
增删改查
消息队列相关命令:
XADD #添加消息到末尾
XTRIM # 对流进行修剪,限制长度
XDEL #删除消息
XLEN #获取流包含的元素数量,即消息长度
XRANGE #获取消息列表,会自动过滤已经删除的消息
XREVRANGE #反向获取消息列表,ID 从大到小
XREAD #以阻塞或非阻塞方式获取消息列表
# *号表示服务器自动生成ID,后面顺序跟着一堆key/value
127.0.0.1:6379> xadd codehole * name laoqian age 30 # 名字叫laoqian,年龄30岁
1527849609889-0 # 生成的消息ID
127.0.0.1:6379> xadd codehole * name xiaoyu age 29
1527849629172-0
127.0.0.1:6379> xadd codehole * name xiaoqian age 1
1527849637634-0
127.0.0.1:6379> xlen codehole
(integer) 3
127.0.0.1:6379> xrange codehole - + # -表示最小值, +表示最大值
127.0.0.1:6379> xrange codehole - +
1) 1) 1527849609889-0
1) 1) "name"
1) "laoqian"
2) "age"
3) "30"
2) 1) 1527849629172-0
1) 1) "name"
1) "xiaoyu"
2) "age"
3) "29"
3) 1) 1527849637634-0
1) 1) "name"
1) "xiaoqian"
2) "age"
3) "1"
127.0.0.1:6379> xrange codehole 1527849629172-0 + # 指定最小消息ID的列表
1) 1) 1527849629172-0
2) 1) "name"
2) "xiaoyu"
3) "age"
4) "29"
2) 1) 1527849637634-0
2) 1) "name"
2) "xiaoqian"
3) "age"
4) "1"
127.0.0.1:6379> xrange codehole - 1527849629172-0 # 指定最大消息ID的列表
1) 1) 1527849609889-0
2) 1) "name"
2) "laoqian"
3) "age"
4) "30"
2) 1) 1527849629172-0
2) 1) "name"
2) "xiaoyu"
3) "age"
4) "29"
127.0.0.1:6379> xdel codehole 1527849609889-0
(integer) 1
127.0.0.1:6379> xlen codehole # 长度不受影响
(integer) 3
127.0.0.1:6379> xrange codehole - + # 被删除的消息没了
1) 1) 1527849629172-0
2) 1) "name"
2) "xiaoyu"
3) "age"
4) "29"
2) 1) 1527849637634-0
2) 1) "name"
2) "xiaoqian"
3) "age"
4) "1"
127.0.0.1:6379> del codehole # 删除整个Stream
(integer) 1
独立消费
我们可以在不定义消费组的情况下进行Stream消息的独立消费,当Stream没有新消息时,甚至可以阻塞等待。 Redis设计了一个单独的消费指令 xread ,可以将Stream当成普通的消息队列(list)来使用。使用xread时,我们可以完全忽略消费组(Consumer Group)的存在,就好比Stream就是一个普通的列表(list)。
# 从Stream头部读取两条消息
127.0.0.1:6379> xread count 2 streams codehole 0-0
1) 1) "codehole"
2) 1) 1) 1527851486781-0
2) 1) "name"
2) "laoqian"
3) "age"
4) "30"
2) 1) 1527851493405-0
2) 1) "name"
2) "yurui"
3) "age"
4) "29"
# 从Stream尾部读取一条消息,毫无疑问,这里不会返回任何消息
127.0.0.1:6379> xread count 1 streams codehole $
(nil)
# 从尾部阻塞等待新消息到来,下面的指令会堵住,直到新消息到来
127.0.0.1:6379> xread block 0 count 1 streams codehole $
# 我们从新打开一个窗口,在这个窗口往Stream里塞消息
127.0.0.1:6379> xadd codehole * name youming age 60
1527852774092-0
# 再切换到前面的窗口,我们可以看到阻塞解除了,返回了新的消息内容
# 而且还显示了一个等待时间,这里我们等待了93s
127.0.0.1:6379> xread block 0 count 1 streams codehole $
1) 1) "codehole"
2) 1) 1) 1527852774092-0
2) 1) "name"
2) "youming"
3) "age"
4) "60"
(93.11s)
客户端如果想要使用xread进行顺序消费,一定要记住当前消费到哪里了,也就是返回的消息ID。 下次继续调用xread时,将上次返回的最后一个消息ID作为参数传递进去,就可以继续消费后续的消息。
block 0表示永远阻塞,直到消息到来,block 1000表示阻塞1s,如果1s内没有任何消息到来,就返回nil
127.0.0.1:6379> xread block 1000 count 1 streams codehole $
(nil)
(1.07s)
消费组消费
消费组消费图
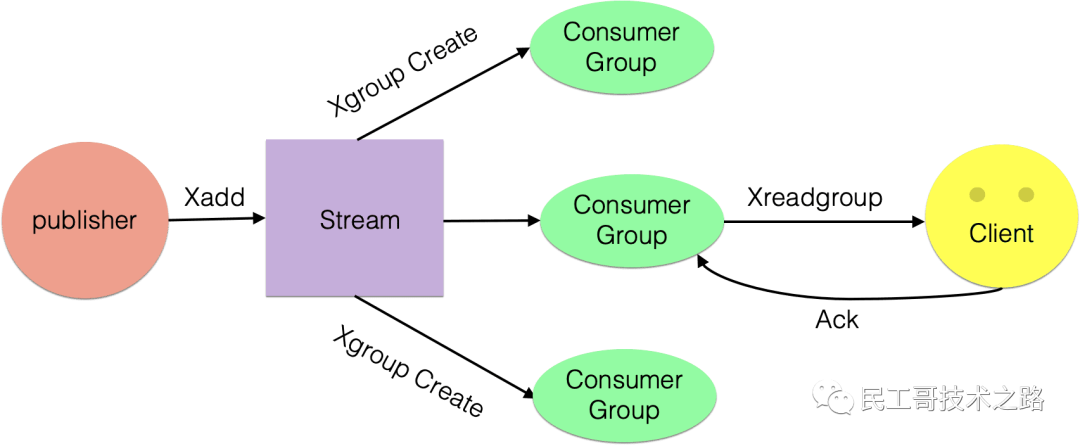
相关命令:
XGROUP CREATE #创建消费者组
XREADGROUP GROUP #读取消费者组中的消息
XACK - #将消息标记为"已处理"
XGROUP SETID #为消费者组设置新的最后递送消息ID
XGROUP DELCONSUMER #删除消费者
XGROUP DESTROY #删除消费者组
XPENDING #显示待处理消息的相关信息
XCLAIM #转移消息的归属权
XINFO #查看流和消费者组的相关信息;
XINFO GROUPS #打印消费者组的信息;
XINFO STREAM #打印流信息
创建消费组
Stream通过xgroup create指令创建消费组(Consumer Group),需要传递起始消息ID参数用来初始化last_delivered_id变量。
127.0.0.1:6379> xgroup create codehole cg1 0-0 # 表示从头开始消费
OK
# $表示从尾部开始消费,只接受新消息,当前Stream消息会全部忽略
127.0.0.1:6379> xgroup create codehole cg2 $
OK
127.0.0.1:6379> xinfo stream codehole # 获取Stream信息
1) length
2) (integer) 3 # 共3个消息
3) radix-tree-keys
4) (integer) 1
5) radix-tree-nodes
6) (integer) 2
7) groups
8) (integer) 2 # 两个消费组
9) first-entry # 第一个消息
10) 1) 1527851486781-0
2) 1) "name"
2) "laoqian"
3) "age"
4) "30"
11) last-entry # 最后一个消息
12) 1) 1527851498956-0
2) 1) "name"
2) "xiaoqian"
3) "age"
4) "1"
127.0.0.1:6379> xinfo groups codehole # 获取Stream的消费组信息
1) 1) name
2) "cg1"
3) consumers
4) (integer) 0 # 该消费组还没有消费者
5) pending
6) (integer) 0 # 该消费组没有正在处理的消息
2) 1) name
2) "cg2"
3) consumers # 该消费组还没有消费者
4) (integer) 0
5) pending
6) (integer) 0 # 该消费组没有正在处理的消息
消费组消费
Stream提供了xreadgroup指令可以进行消费组的组内消费,需要提供消费组名称、消费者名称和起始消息ID。它同xread一样,也可以阻塞等待新消息。读到新消息后,对应的消息ID就会进入消费者的PEL(正在处理的消息)结构里,客户端处理完毕后使用xack指令通知服务器,本条消息已经处理完毕,该消息ID就会从PEL中移除。
# >号表示从当前消费组的last_delivered_id后面开始读
# 每当消费者读取一条消息,last_delivered_id变量就会前进
127.0.0.1:6379> xreadgroup GROUP cg1 c1 count 1 streams codehole >
1) 1) "codehole"
2) 1) 1) 1527851486781-0
2) 1) "name"
2) "laoqian"
3) "age"
4) "30"
127.0.0.1:6379> xreadgroup GROUP cg1 c1 count 1 streams codehole >
1) 1) "codehole"
2) 1) 1) 1527851493405-0
2) 1) "name"
2) "yurui"
3) "age"
4) "29"
127.0.0.1:6379> xreadgroup GROUP cg1 c1 count 2 streams codehole >
1) 1) "codehole"
2) 1) 1) 1527851498956-0
2) 1) "name"
2) "xiaoqian"
3) "age"
4) "1"
2) 1) 1527852774092-0
2) 1) "name"
2) "youming"
3) "age"
4) "60"
# 再继续读取,就没有新消息了
127.0.0.1:6379> xreadgroup GROUP cg1 c1 count 1 streams codehole >
(nil)
# 那就阻塞等待吧
127.0.0.1:6379> xreadgroup GROUP cg1 c1 block 0 count 1 streams codehole >
# 开启另一个窗口,往里塞消息
127.0.0.1:6379> xadd codehole * name lanying age 61
1527854062442-0
# 回到前一个窗口,发现阻塞解除,收到新消息了
127.0.0.1:6379> xreadgroup GROUP cg1 c1 block 0 count 1 streams codehole >
1) 1) "codehole"
2) 1) 1) 1527854062442-0
2) 1) "name"
2) "lanying"
3) "age"
4) "61"
(36.54s)
127.0.0.1:6379> xinfo groups codehole # 观察消费组信息
1) 1) name
2) "cg1"
3) consumers
4) (integer) 1 # 一个消费者
5) pending
6) (integer) 5 # 共5条正在处理的信息还有没有ack
2) 1) name
2) "cg2"
3) consumers
4) (integer) 0 # 消费组cg2没有任何变化,因为前面我们一直在操纵cg1
5) pending
6) (integer) 0
# 如果同一个消费组有多个消费者,我们可以通过xinfo consumers指令观察每个消费者的状态
127.0.0.1:6379> xinfo consumers codehole cg1 # 目前还有1个消费者
1) 1) name
2) "c1"
3) pending
4) (integer) 5 # 共5条待处理消息
5) idle
6) (integer) 418715 # 空闲了多长时间ms没有读取消息了
# 接下来我们ack一条消息
127.0.0.1:6379> xack codehole cg1 1527851486781-0
(integer) 1
127.0.0.1:6379> xinfo consumers codehole cg1
1) 1) name
2) "c1"
3) pending
4) (integer) 4 # 变成了5条
5) idle
6) (integer) 668504
# 下面ack所有消息
127.0.0.1:6379> xack codehole cg1 1527851493405-0 1527851498956-0 1527852774092-0 1527854062442-0
(integer) 4
127.0.0.1:6379> xinfo consumers codehole cg1
1) 1) name
2) "c1"
3) pending
4) (integer) 0 # pel空了
5) idle
6) (integer) 745505
信息监控
Stream 提供了XINFO来实现对服务器信息的监控,可以查询:
查看队列信息
127.0.0.1:6379> Xinfo stream mq
1) "length"
2) (integer) 7
3) "radix-tree-keys"
4) (integer) 1
5) "radix-tree-nodes"
6) (integer) 2
7) "groups"
8) (integer) 1
9) "last-generated-id"
10) "1553585533795-9"
11) "first-entry"
12) 1) "1553585533795-3"
2) 1) "msg"
2) "4"
13) "last-entry"
14) 1) "1553585533795-9"
2) 1) "msg"
2) "10"
消费组信息
127.0.0.1:6379> Xinfo groups mq
1) 1) "name"
2) "mqGroup"
3) "consumers"
4) (integer) 3
5) "pending"
6) (integer) 3
7) "last-delivered-id"
8) "1553585533795-4"
消费者组成员信息
127.0.0.1:6379> XINFO CONSUMERS mq mqGroup
1) 1) "name"
2) "consumerA"
3) "pending"
4) (integer) 1
5) "idle"
6) (integer) 18949894
2) 1) "name"
2) "consumerB"
3) "pending"
4) (integer) 1
5) "idle"
6) (integer) 3092719
3) 1) "name"
2) "consumerC"
3) "pending"
4) (integer) 1
5) "idle"
6) (integer) 23683256
至此,消息队列的操作说明大体结束!
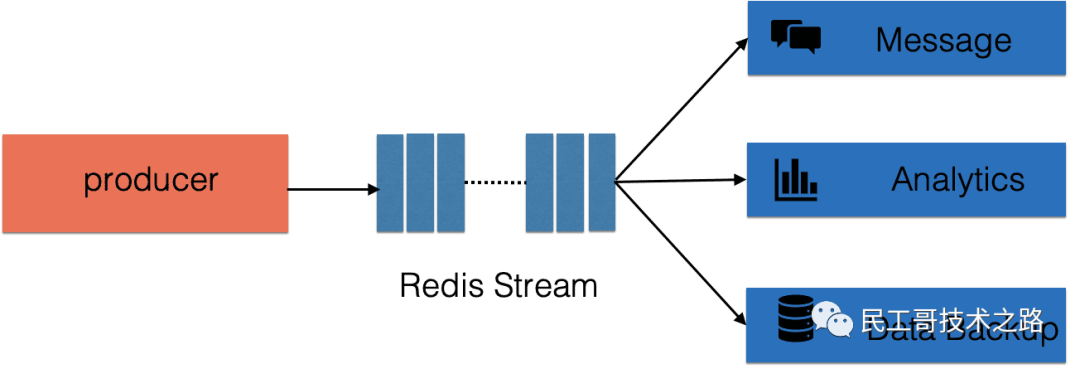
Stream用在什么样场景
可用作 即时通信,大数据分析,异地数据备份 等
客户端可以平滑扩展,提高处理能力
消息ID的设计是否考虑了时间回拨的问题?
在分布式算法 - ID算法设计中, 一个常见的问题就是时间回拨问题,那么Redis的消息ID设计中是否考虑到这个问题呢?
XADD生成的1553439850328-0,就是Redis生成的消息ID,由两部分组成:时间戳-序号。时间戳是毫秒级单位,是生成消息的Redis服务器时间,它是个64位整型(int64)。序号是在这个毫秒时间点内的消息序号,它也是个64位整型。
可以通过multi批处理,来验证序号的递增:
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> XADD memberMessage * msg one
QUEUED
127.0.0.1:6379> XADD memberMessage * msg two
QUEUED
127.0.0.1:6379> XADD memberMessage * msg three
QUEUED
127.0.0.1:6379> XADD memberMessage * msg four
QUEUED
127.0.0.1:6379> XADD memberMessage * msg five
QUEUED
127.0.0.1:6379> EXEC
1) "1553441006884-0"
2) "1553441006884-1"
3) "1553441006884-2"
4) "1553441006884-3"
5) "1553441006884-4"
由于一个redis命令的执行很快,所以可以看到在同一时间戳内,是通过序号递增来表示消息的。
为了保证消息是有序的,因此 Redis 生成的 ID 是单调递增有序的。由于 ID 中包含时间戳部分,为了避免服务器时间错误而带来的问题(例如服务器时间延后了),Redis 的每个 Stream 类型数据都维护一个 latest_generated_id属性,用于记录最后一个消息的ID。 若发现当前时间戳退后(小于latest_generated_id所记录的),则采用时间戳不变而序号递增的方案来作为新消息ID(这也是序号为什么使用int64的原因,保证有足够多的的序号),从而保证ID的单调递增性质。
强烈建议使用Redis的方案生成消息ID,因为这种时间戳+序号的单调递增的ID方案,几乎可以满足你全部的需求。但同时,记住ID是支持自定义的,别忘了!
消费者崩溃带来的会不会消息丢失问题?
为了解决组内消息读取但处理期间消费者崩溃带来的消息丢失问题 ,STREAM 设计了 Pending 列表,用于记录读取但并未处理完毕的消息。命令XPENDIING 用来获消费组或消费内消费者的未处理完毕的消息。演示如下:
127.0.0.1:6379> XPENDING mq mqGroup # mpGroup的Pending情况
1) (integer) 5 # 5个已读取但未处理的消息
2) "1553585533795-0" # 起始ID
3) "1553585533795-4" # 结束ID
4) 1) 1) "consumerA" # 消费者A有3个
2) "3"
2) 1) "consumerB" # 消费者B有1个
2) "1"
3) 1) "consumerC" # 消费者C有1个
2) "1"
127.0.0.1:6379> XPENDING mq mqGroup - + 10 # 使用 start end count 选项可以获取详细信息
1) 1) "1553585533795-0" # 消息ID
2) "consumerA" # 消费者
3) (integer) 1654355 # 从读取到现在经历了1654355ms,IDLE
4) (integer) 5 # 消息被读取了5次,delivery counter
2) 1) "1553585533795-1"
2) "consumerA"
3) (integer) 1654355
4) (integer) 4
# 共5个,余下3个省略 ...
127.0.0.1:6379> XPENDING mq mqGroup - + 10 consumerA # 在加上消费者参数,获取具体某个消费者的Pending列表
1) 1) "1553585533795-0"
2) "consumerA"
3) (integer) 1641083
4) (integer) 5
# 共3个,余下2个省略 ...
**** 每个Pending的消息有4个属性:
- 消息ID
- 所属消费者
- IDLE,已读取时长
- delivery counter,消息被读取次数
上面的结果我们可以看到,我们之前读取的消息,都被记录在Pending列表中,说明全部读到的消息都没有处理,仅仅是读取了。 那如何表示消费者处理完毕了消息呢?使用命令 XACK 完成告知消息处理完成 ,演示如下:
127.0.0.1:6379> XACK mq mqGroup 1553585533795-0 # 通知消息处理结束,用消息ID标识
(integer) 1
127.0.0.1:6379> XPENDING mq mqGroup # 再次查看Pending列表
1) (integer) 4 # 已读取但未处理的消息已经变为4个
2) "1553585533795-1"
3) "1553585533795-4"
4) 1) 1) "consumerA" # 消费者A,还有2个消息处理
2) "2"
2) 1) "consumerB"
2) "1"
3) 1) "consumerC"
2) "1"
127.0.0.1:6379>
有了这样一个Pending机制,就意味着在某个消费者读取消息但未处理后,消息是不会丢失的。等待消费者再次上线后,可以读取该Pending列表,就可以继续处理该消息了,保证消息的有序和不丢失。
消费者彻底宕机后如何转移给其它消费者处理?
还有一个问题,就是若某个消费者宕机之后,没有办法再上线了,那么就需要将该消费者Pending的消息,转义给其他的消费者处理,就是消息转移。
消息转移的操作时将某个消息转移到自己的Pending列表中。使用语法 XCLAIM 来实现,需要设置组、转移的目标消费者和消息ID,同时需要提供IDLE(已被读取时长),只有超过这个时长,才能被转移。演示如下:
# 当前属于消费者A的消息1553585533795-1,已经15907,787ms未处理了
127.0.0.1:6379> XPENDING mq mqGroup - + 10
1) 1) "1553585533795-1"
2) "consumerA"
3) (integer) 15907787
4) (integer) 4
# 转移超过3600s的消息1553585533795-1到消费者B的Pending列表
127.0.0.1:6379> XCLAIM mq mqGroup consumerB 3600000 1553585533795-1
1) 1) "1553585533795-1"
2) 1) "msg"
2) "2"
# 消息1553585533795-1已经转移到消费者B的Pending中。
127.0.0.1:6379> XPENDING mq mqGroup - + 10
1) 1) "1553585533795-1"
2) "consumerB"
3) (integer) 84404 # 注意IDLE,被重置了
4) (integer) 5 # 注意,读取次数也累加了1次
以上代码,完成了一次消息转移。转移除了要指定ID外,还需要指定IDLE,保证是长时间未处理的才被转移。被转移的消息的IDLE会被重置,用以保证不会被重复转移,以为可能会出现将过期的消息同时转移给多个消费者的并发操作,设置了IDLE,则可以避免后面的转移不会成功,因为IDLE不满足条件。例如下面的连续两条转移,第二条不会成功。
127.0.0.1:6379> XCLAIM mq mqGroup consumerB 3600000 1553585533795-1
127.0.0.1:6379> XCLAIM mq mqGroup consumerC 3600000 1553585533795-1
这就是消息转移。至此我们使用了一个 Pending 消息的 ID,所属消费者和IDLE 的属性,还有一个属性就是消息被读取次数,delivery counter,该属性的作用由于统计消息被读取的次数,包括被转移也算。这个属性主要用在判定是否为错误数据上。
坏消息问题,Dead Letter,死信问题
正如上面所说,如果某个消息,不能被消费者处理,也就是不能被XACK,这是要长时间处于Pending列表中,即使被反复的转移给各个消费者也是如此。此时该消息的delivery counter就会累加(上一节的例子可以看到),当累加到某个我们预设的临界值时,我们就认为是坏消息(也叫死信,DeadLetter,无法投递的消息),由于有了判定条件,我们将坏消息处理掉即可,删除即可。删除一个消息,使用XDEL语法,演示如下:
# 删除队列中的消息
127.0.0.1:6379> XDEL mq 1553585533795-1
(integer) 1
# 查看队列中再无此消息
127.0.0.1:6379> XRANGE mq - +
1) 1) "1553585533795-0"
2) 1) "msg"
2) "1"
2) 1) "1553585533795-2"
2) 1) "msg"
2) "3"
注意本例中,并没有删除 Pending 中的消息因此你查看Pending,消息还会在。可以执行 XACK 标识其处理完毕!
参考文章:
https://pdai.tech/md/db/nosql-redis/db-redis-data-type-stream.html
https://pdai.tech/md/db/nosql-redis/db-redis-data-type-special.html
(三):Redis 常用管理命令
redis set key
Redis SET 命令用于给键(key)设置值的。如果 key 已经存储其他值,SET 就覆写旧值。
语法结构如下:
set keyname 值
返回值:设置成功时,返回OK。
实例:
set freekey free;
结果:
redis get
Redis get命令用于获取键(key)中的值的。如果key不存在,返回 nil。
语法结构如下:
get keyname
返回值:返回keyname对应的值,如果key不存在,则返回nil。假如key中存的值不是字符串类型那么返回错误。
实例:
get freekey
结果:
redis -cli
Redis 命令是在redis 服务上执行的。那么要连接redis服务器需要一个redis客户端。Redis 客户端在我们之前下载的的 redis的安装包中。
我们要启动redis客户端,可以在DOS进入redis安装目录,然后通过执行redis -cli来启动客户端,该命令会连接本地的 redis 服务。如下图:
连接远程redis服务器
另起一个cmd,执行客户端连接到redis服务器,即服务端,进行测试,命令如下:
redis-cli.exe -h 127.0.0.1 -p 6379 -a 123456
其中127.0.01是redis的服务器地址,6379是端口,-a 123456是设置的密码。结果如下:
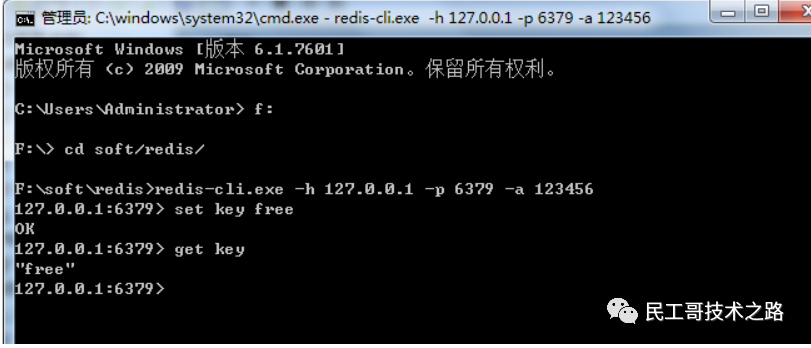
Redis setnx
Redis setnx命令也是用于设置key的值,但是它 和redis set命令有点不一样 。 只在key不存在的情况下, 给key设置,假如key已经存在,那么 redis setnx将啥都不做。
语法结构如下:
setnx keyname value
返回值:命令设置成功返回1,失败返回0。
实例:
setnx nxkey hello
结果:
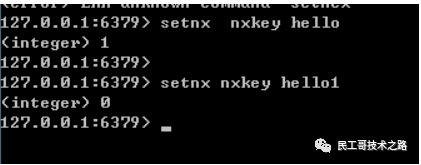
redis setex
redis setex命令也是用于设置key的值,但是它 和redis set命令有点不一样,它可以额外设置key值的生存周期。
语法结构如下
SETEX key seconds value
返回值:命令成功时返回 OK 。当 seconds 参数不合法时, 命令将返回一个错误。如果key已经存在那么覆盖旧值。
实例
SETEX setexkey 100 hello
–指的是设定setexkey键的生存周期为100秒。
ttl setexkey
–查看setexkey键的剩余时间。
结果:
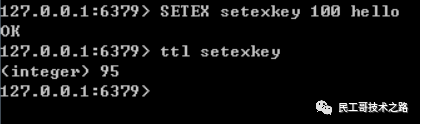
redis psetex
redis psetex命令:用于给redis设置key的值, 并且附带上值的生存时间,不同于setex命令,它设置值的生存时间为毫秒。
语法结构如下:
PSETEX key seconds value
返回值:命令成功时返回 OK 。当 seconds 参数不合法时, 命令将返回一个错误。如果key已经存在那么覆盖旧值。
实例:
PSETEX psetexkey 5000 free
–指的是设定setexkey键的生存周期为1000毫秒。
pttl psetexkey
–查看psetexkey键的剩余时间。
结果:
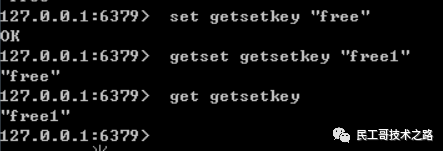
redis getset
redis getset命令:用于给redis设置key的新值,返回之前旧的key值。如果key值之前不存在,那会报错。
语法结构如下:
getset key value
实例:
–给key设置值
set getsetkey “free”
–给key设置新值
getset getsetkey “free1”
–获取key值
get getsetkey
结果:
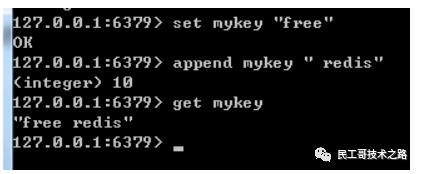
redis append
redis append 命令是 用于对redis字符串进行追加,当键值已经存在的情况下,在键值的末尾追加上提供的value值。
语法结构:
append key value
返回值:如果key存在并且是一个字符串,append命令会把value的值追加到原来的键值末尾,并返回现有的字符串长度。
如果key不存在,那么他就直接对key值进行赋值,和set key命令一样。
实例:
–给key设值
set mykey “free”
–在key值后面追加字符
append mykey " redis "
–获取key值
get mykey
结果:
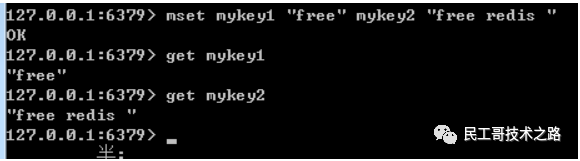
redis mset
redis mset命令用于给redis的键(key)赋值命令。 不同于redis set,它可以一次给多个键同时进行赋值。
语法结构:
mset key1 value1 key2 value2 …
返回值:总是返回OK。和redis set命令一样,当key值存在时,对其值进行覆盖。
实例:
–给key设值
mset mykey1 “free” mykey2 "free redis "
–获取键值
get mykey1
get mykey2
结果:
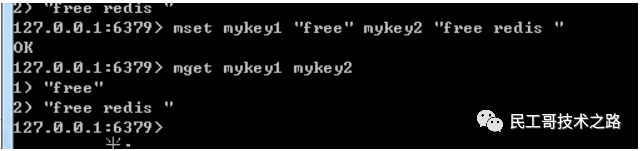
redis mget
redis mget命令 用于批量获取给定的多个键(key)的值,它是redis mset命令的逆过程。
语法结构:
redis mget key1 key2…
返回值:返回给定的一个或者多个键(key)的值。如果给定的键不存在,那么这个键返回的值将是nil。
实例:
–给key设值
mset mykey1 “free” mykey2 "free redis "
–获取键值
mget mykey1 mykey2
结果:
redis incr
redis incr命令 用于对数值类型的键(key)值进行加1操作,然后返回加1之后的数值。
语法结构:
redis incr key
返回值:
如果key值存在,并为数值类型,那么对其加1进行返回。
如果key值不存在,那么当做0处理,返回1。
如果key值不是数值类型,那么会返回错误。
实例:
–给key设值
set key 2
–给key加1
incr key
–获取key的值
get key
–对不是数值的执行incr结果
set key “free”
incr key
结果:

redis decr
redis decr命令 用于对数值类型的键(key)值进行递减操作(即减1操作),然后返回递减之后的结果值。
语法结构:
decr key
返回值:
如果key值存在,并为数值类型,那么对其递减1,然后返回结果值。
如果key值不存在,那么当做0处理,返回-1。
如果key值不是数值类型,那么会返回错误。
实例:
–给key设值
set key 2
–给key进行递减1
decr key
–获取key的值
get key
–对不是数值的执行decr结果
set key “free”
decr key
结果:
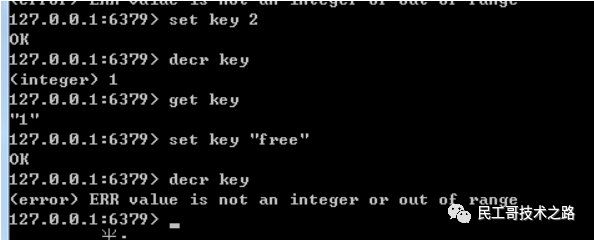
redis lindex key index
redis lindex key index命令主要 用于获取链表类型中指定下标的数据。
语法结构:
lindex key index
#返回链表类型key中下标为index的数据。index表示链表的下标,0表示链表头第一个元素,-1表示链表尾最后一个元素。
返回值:指定链表下标index的元素。如果index指定的下标大于链表的长度,就会报下标越界。
实例:
–给链表插入数据
rpush mylist10 “hello” “free” “redis” “hello”
–获取链表数据
lindex mylist10 0
lindex mylist10 1
lindex mylist10 -1
结果:
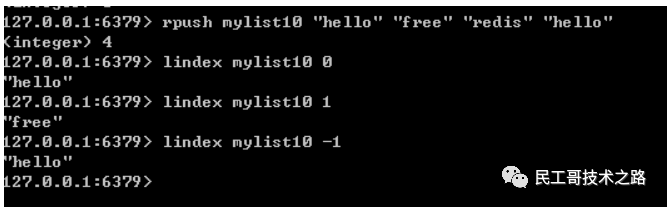
redis ltrim
redis ltrim命令主要 用于截取redis链表类型的指定下标区间内的元素,不在指定区间内的元素都会被删除。
语法结构:
ltrim key start end
key:#指定要截取的链表键。
start/end:#指定要截取的区间,start是开始,end是结尾。如ltrim key 0,1表示保留前两个元素,其它元素都删除掉。
start(end)都是表示链表的下标,链表下标是从0开始表示链表头,第一个元素。-1表示链表尾,最后一个元素。
返回值:命令执行成功返回OK,当key不是链表类型时,返回错误。下标区间不能超过链表的长度,会报下标越界错误。
实例:
–给链表插入数据
rpush mylist “hello” “free” “redis” “ok”
–截取中间两个元素
ltrim mylist 1 2
–查看截取后的链表元素
lrange mylist 0 -1
结果:
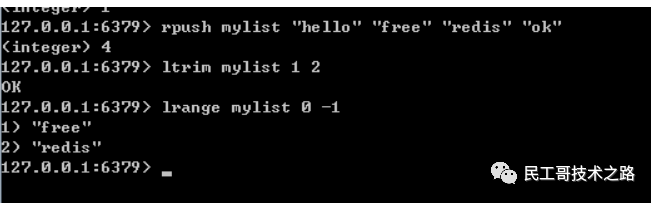
redis hget
redis hget命令主要用 获取redis哈希表中域(field)的值。
语法结构:
hget key field
获取哈希表key中域(field)的值。
返回值:正常返回给定域的值,如果给定的域不存在,那么返回nil错误。
实例:
–创建一个哈希表
hset myhash field1 “free”
–获取指定域的值
hget myhash field1
结果:
redis hdel
redis hdel命令 用于删除哈希表中指定的域(field),只可以批量移除多个域,不存在的域会被忽略。
语法结构:
hdel hash field field1 …
hash #指定哈希表的键,field是哈希表的域。
返回值:返回被成功移除域的数量,不存在的域不计算在内。
实例:
–创建一个哈希表
hset myhash field1 “free”
hset myhash field2 “redis”
–判断指定的域是否存在
hdel myhash field1 field2 field3
结果:
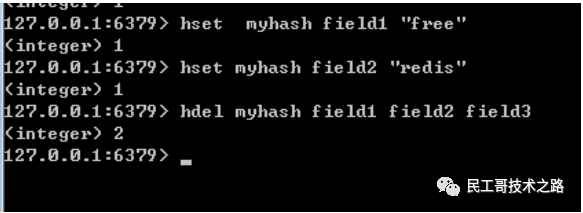
节选自:https://www.wenjiangs.com/doc/q3km1de9s1t7
(四):Redis 发布与订阅(pub/sub)
什么是发布订阅?
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。
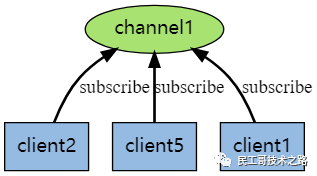
Redis 的 subscribe 命令可以 让客户端订阅任意数量的频道, 每当有新信息发送到被订阅的频道时, 信息就会被发送给所有订阅指定频道的客户端。
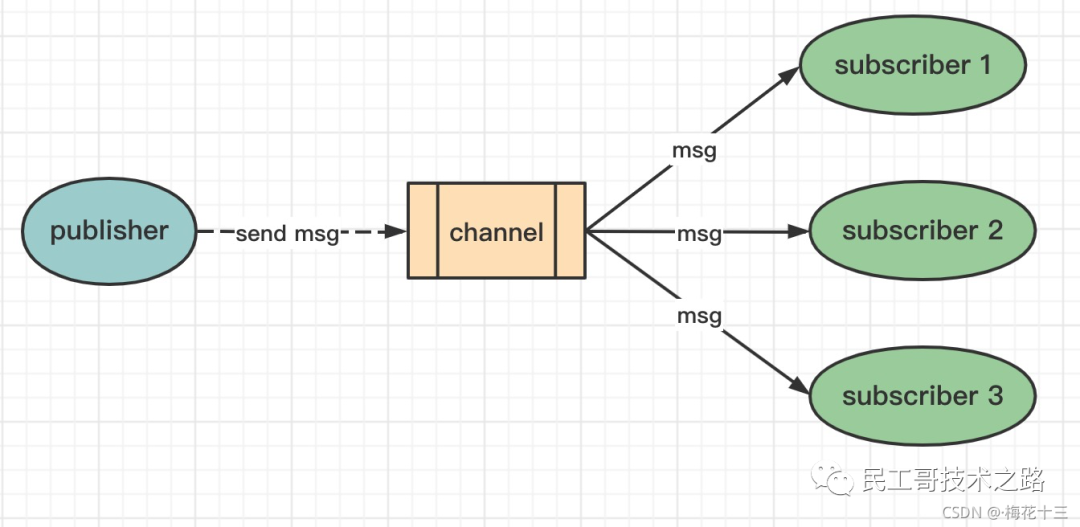
☛ 下图展示了频道 channel1 , 以及订阅这个频道的三个客户端 —— client2 、 client5 和 client1 之间的关系:
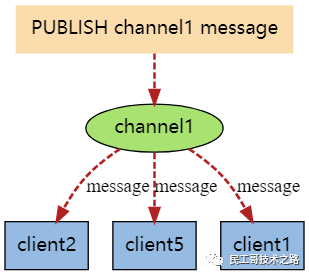
☛ 当有新消息通过 publish 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端:
为什么要用发布订阅?
熟悉消息中间件 的同学都知道,针对 消息订阅发布 功能,市面上很多大厂使用的是 kafka、RabbitMQ、ActiveMQ, RocketMQ 等这几种,redis的订阅发布功能跟这三者相比, 相对轻量,针对数据准确和安全性要求没有那么高可以直接使用,适用于小公司。
redis 的List数据类型结构提供了 blpop 、brpop 命令结合 rpush、lpush 命令可以实现消息队列机制,基于双端链表实现的发布与订阅功能
这种方式存在 两个局限性 :
- 不能支持一对多的消息分发。
- 如果生产者生成的速度远远大于消费者消费的速度,易堆积大量未消费的消息
◇ 双端队列图解 如下:

✦ 解析:双端队列模式只能有一个或多个消费者轮着去消费,却不能将消息同时发给其他消费者
◇ 发布/订阅模式图解如下 :
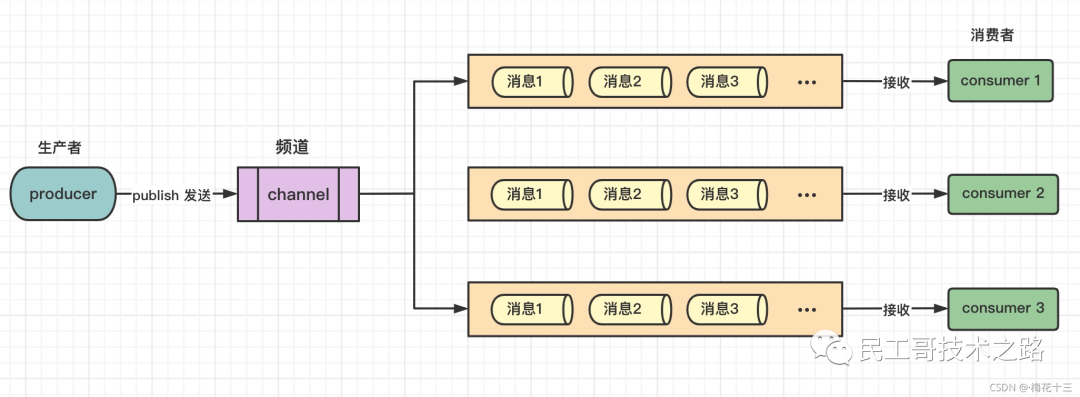
✦ 解析:redis订阅发布模式,生产者生产完消息通过频道分发消息,给订阅了该频道的所有消费
发布/订阅如何使用?
Redis 有两种发布/订阅模式 :
- 基于频道(Channel)的发布/订阅
- 基于模式(pattern)的发布/订阅
操作命令 如下
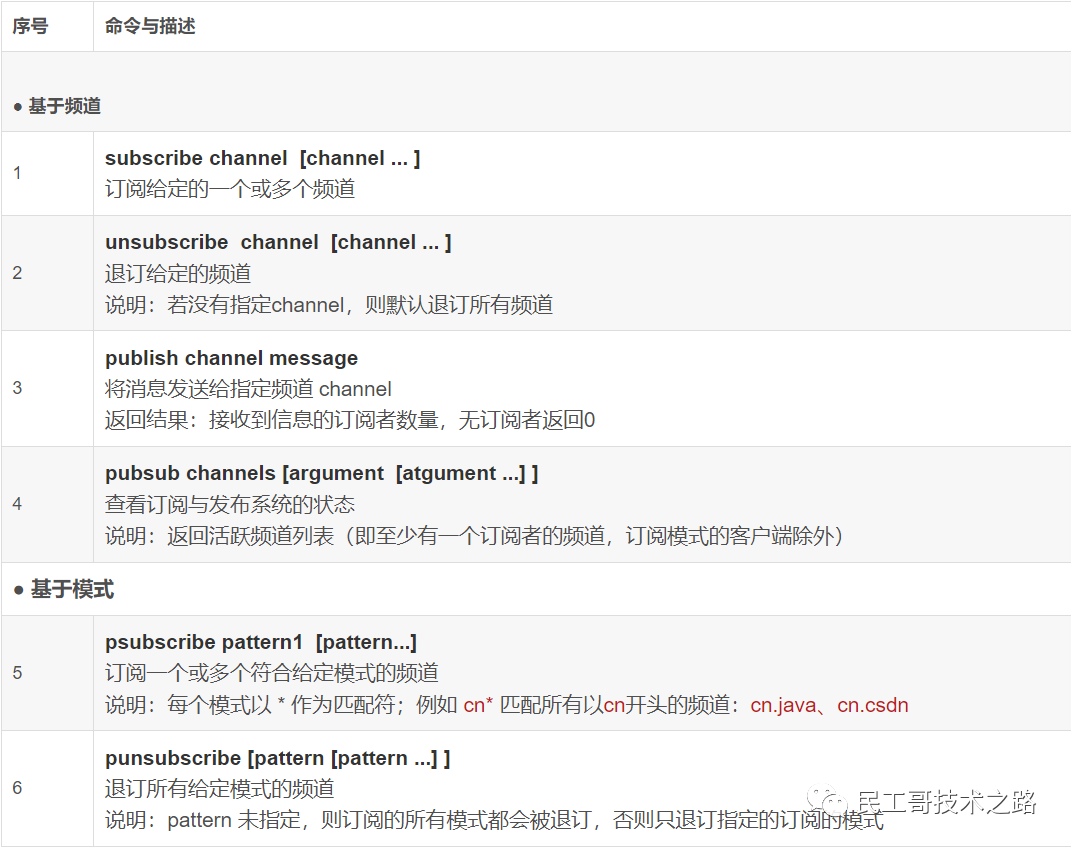
基于频道(Channel)的发布/订阅
“发布/订阅” 包含2种角色:发布者和订阅者。发布者可以向指定的频道(channel)发送消息;订阅者可以订阅一个或者多个频道(channel),所有订阅此频道的订阅者都会收到此消息。
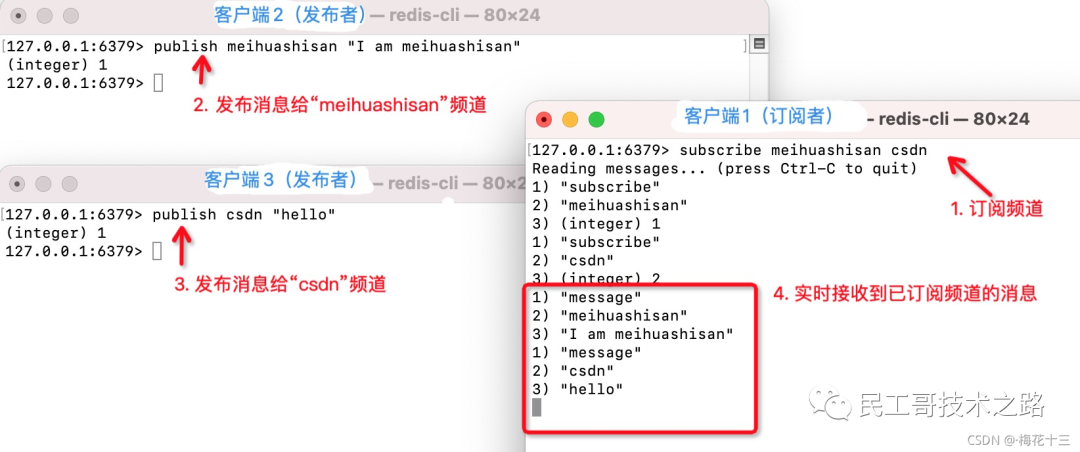
订阅者订阅频道 subscribe channel [channel …]
--------------------------客户端1(订阅者) :订阅频道 ---------------------
# 订阅 “meihuashisan” 和 “csdn” 频道(如果不存在则会创建频道)
127.0.0.1:6379> subscribe meihuashisan csdn
Reading messages... (press Ctrl-C to quit)
1) "subscribe" -- 返回值类型:表示订阅成功!
2) "meihuashisan" -- 订阅频道的名称
3) (integer) 1 -- 当前客户端已订阅频道的数量
1) "subscribe"
2) "csdn"
3) (integer) 2
#注意:订阅后,该客户端会一直监听消息,如果发送者有消息发给频道,这里会立刻接收到消息
发布者发布消息 publish channel message
-----------------------客户端2(发布者):发布消息给频道 -------------------
# 给“meihuashisan”这个频道 发送一条消息:“I am meihuashisan”
127.0.0.1:6379> publish meihuashisan "I am meihuashisan"
(integer) 1 # 接收到信息的订阅者数量,无订阅者返回0
客户端2(发布者)发布消息给频道后,此时我们再来观察 客户端1(订阅者)的客户端窗口变化:
--------------------------客户端1(订阅者) :订阅频道 -----------------
127.0.0.1:6379> subscribe meihuashisan csdn
Reading messages... (press Ctrl-C to quit)
1) "subscribe" -- 返回值类型:表示订阅成功!
2) "meihuashisan" -- 订阅频道的名称
3) (integer) 1 -- 当前客户端已订阅频道的数量
1) "subscribe"
2) "csdn"
3) (integer) 2
--------------------变化如下:(实时接收到了该频道的发布者的消息)------------
1) "message" -- 返回值类型:消息
2) "meihuashisan" -- 来源(从哪个频道发过来的)
3) "I am meihuashisan" -- 消息内容
命令操作图解 如下:
注意: 如果是先发布消息,再订阅频道,不会收到订阅之前就发布到该频道的消息!
注意:进入订阅状态的客户端,不能使用除了 subscribe、unsubscribe、psubscribe 和 punsubscribe 这四个属于"发布/订阅"之外的命令,否则会报错!
这里的客户端指的是 jedis、lettuce的客户端,redis-cli是无法退出订阅状态的!
实现原理
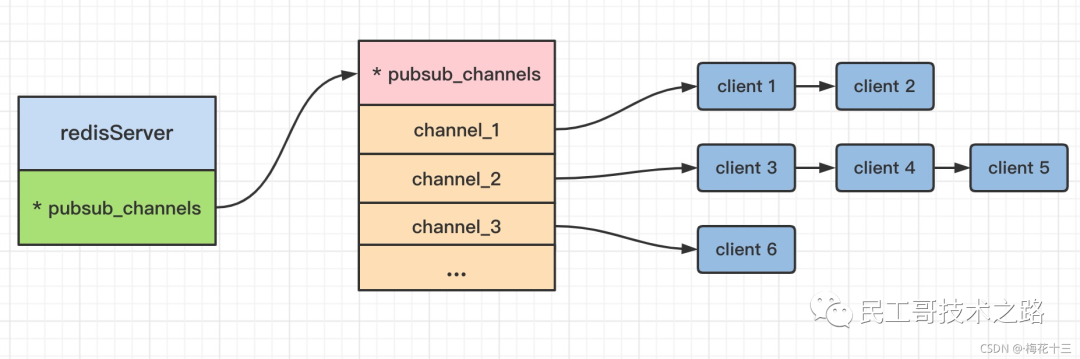
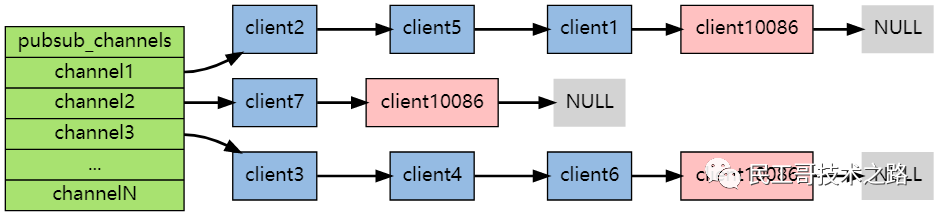
底层通过字典实现。pubsub_channels 是一个字典类型,保存订阅频道的信息:字典的key为订阅的频道, 字典的value是一个链表, 链表中保存了所有订阅该频道的客户端
struct redisServer {
/* General */
pid_t pid;
//省略百十行
// 将频道映射到已订阅客户端的列表(就是保存客户端和订阅的频道信息)
dict *pubsub_channels; /* Map channels to list of subscribed clients */
}
实现图如下:
-
频道订阅 :订阅频道时先检查字段内部是否存在;不存在则为当前频道创建一个字典且创建一个链表存储客户端id;否则直接将客户端id插入到链表中。
-
取消频道订阅 :取消时将客户端id从对应的链表中删除;如果删除之后链表已经是空链表了,则将会把这个频道从字典中删除。
-
发布 :首先根据 channel 定位到字典的键, 然后将信息发送给字典值链表中的所有客户端
基于模式(pattern)的发布/订阅
如果有某个/某些模式和该频道匹配,所有订阅这个/这些频道的客户端也同样会收到信息。
图解
下图展示了一个带有频道和模式的例子, 其中 com.ahead.* 频道匹配了 com.ahead.juc 频道和 com.ahead.thread 频道, 并且有不同的客户端分别订阅它们三个,如下图:
当有信息发送到com.ahead.thread 频道时, 信息除了发送给 client 4 和 client 5 之外, 还会发送给订阅 com.ahead.* 频道模式的 client x 和 client y
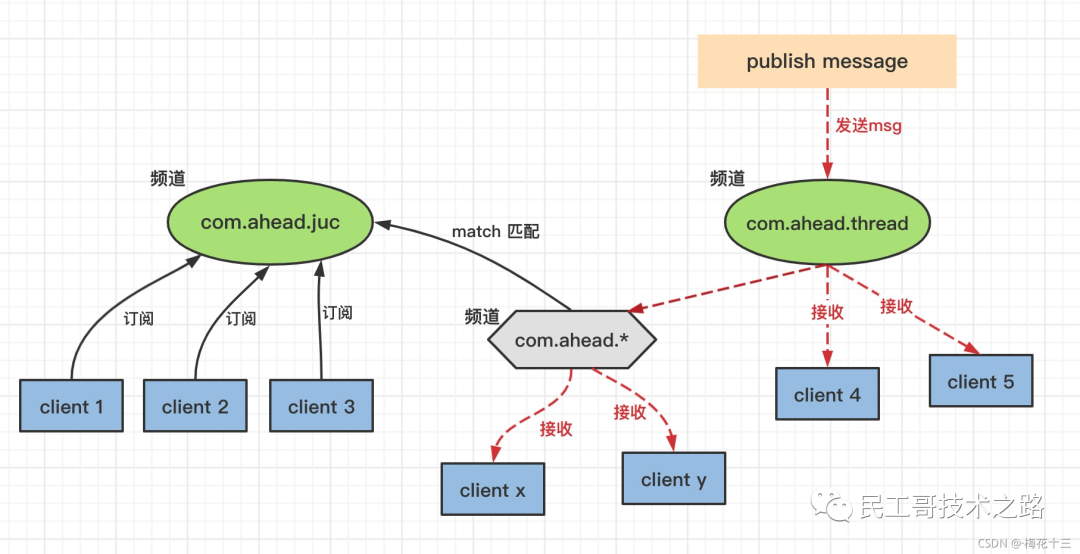
✦ 解析 :反之也是,如果当有消息发送给 com.ahead.juc 频道,消息发送给订阅了 juc 频道的客户端之外,还会发送给订阅了 com.ahead.* 频道的客户端: client x 、client y
通配符中?表示1个占位符,*表示任意个占位符(包括0),?*表示1个以上占位符。
订阅者订阅频道 psubscribe pattern [pattern …]
--------------------------客户端1(订阅者) :订阅频道 --------------------
# 1. ------------订阅 “a?” "com.*" 2种模式频道--------------
127.0.0.1:6379> psubscribe a? com.*
# 进入订阅状态后处于阻塞,可以按Ctrl+C键退出订阅状态
Reading messages... (press Ctrl-C to quit)
---------------订阅成功-------------------
1) "psubscribe" -- 返回值的类型:显示订阅成功
2) "a?" -- 订阅的模式
3) (integer) 1 -- 目前已订阅的模式的数量
1) "psubscribe"
2) "com.*"
3) (integer) 2
---------------接收消息 (已订阅 “a?” "com.*" 两种模式!)-----------------
# ---- 发布者第1条命令:publish ahead "hello"
结果:没有接收到消息,匹配失败,不满足 “a?” ,“?”表示一个占位符, a后面的head有4个占位符
# ---- 发布者第2条命令: publish aa "hello" (满足 “a?”)
1) "pmessage" -- 返回值的类型:信息
2) "a?" -- 信息匹配的模式:a?
3) "aa" -- 信息本身的目标频道:aa
4) "hello" -- 信息的内容:"hello"
# ---- 发布者第3条命令:publish com.juc "hello2"(满足 “com.*”, *表示任意个占位符)
1) "pmessage" -- 返回值的类型:信息
2) "com.*" -- 匹配模式:com.*
3) "com.juc" -- 实际频道:com.juc
4) "hello2" -- 信息:"hello2"
---- 发布者第4条命令:publish com. "hello3"(满足 “com.*”, *表示任意个占位符)
1) "pmessage" -- 返回值的类型:信息
2) "com.*" -- 匹配模式:com.*
3) "com." -- 实际频道:com.
4) "hello3" -- 信息:"hello3"
发布者发布消息 publish channel message
------------------------客户端2(发布者):发布消息给频道 ------------------
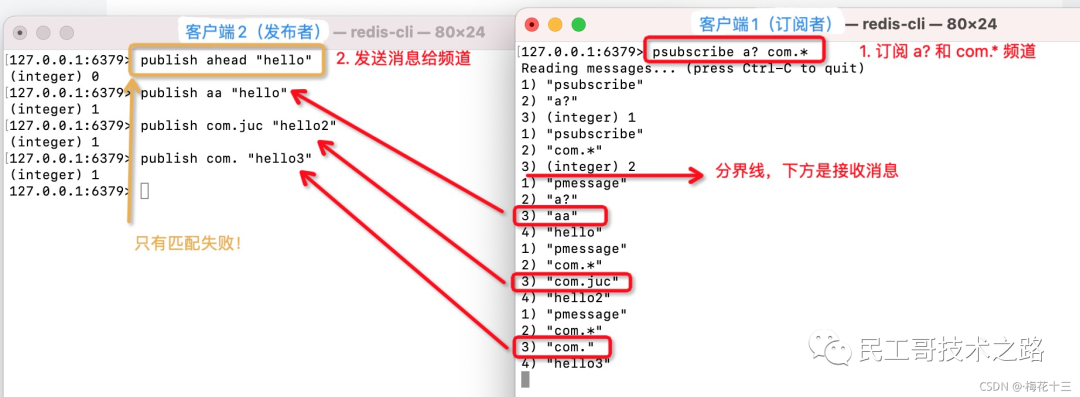
注意:订阅者已订阅 “a?” "com.*" 两种模式!
# 1. ahead 不符合“a?”模式,?表示1个占位符
127.0.0.1:6379> publish ahead "hello"
(integer) 0 -- 匹配失败,0:无订阅者
# 2. aa 符合“a?”模式,?表示1个占位符
127.0.0.1:6379> publish aa "hello"
(integer) 1
# 3. 符合“com.*”模式,*表示任意个占位符
127.0.0.1:6379> publish com.juc "hello2"
(integer) 1
# 4. 符合“com.*”模式,*表示任意个占位符
127.0.0.1:6379> publish com. "hello3"
(integer) 1
命令操作图解 如下:
实现原理
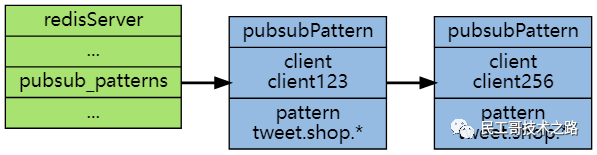
底层是pubsubPattern节点的链表。
struct redisServer {
//...
list *pubsub_patterns;
// ...
}
// 1303行订阅模式列表结构:
typedef struct pubsubPattern {
client *client; -- 订阅模式客户端
robj *pattern; -- 被订阅的模式
} pubsubPattern;
实现图 如下:
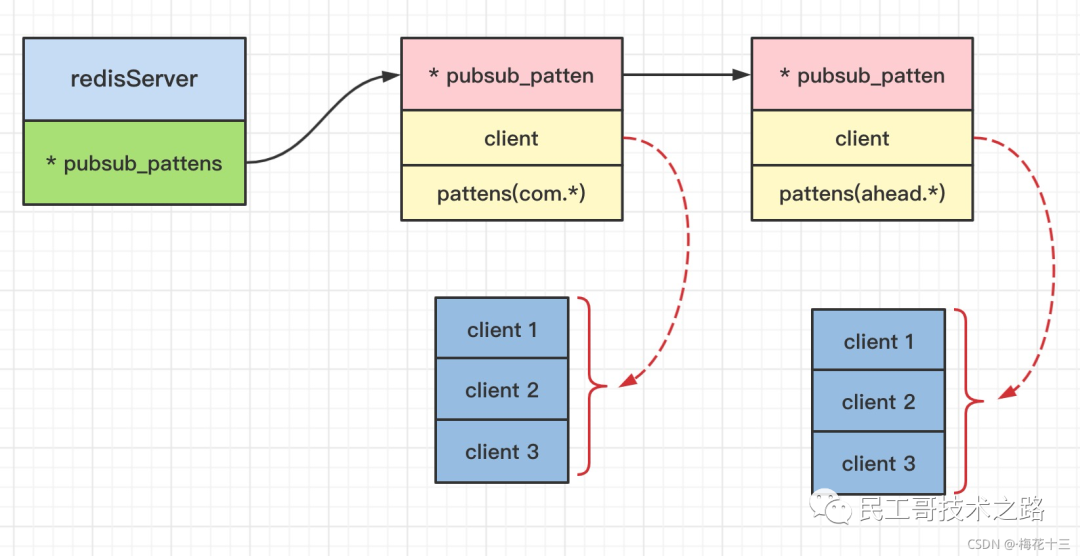
-
模式订阅 :新增一个pubsub_pattern数据结构添加到链表的最后尾部,同时保存客户端ID。
-
取消模式订阅 :从当前的链表pubsub_pattern结构中删除需要取消的pubsubPattern结构。
使用小结
订阅者(listener)负责订阅频道(channel);发送者(publisher)负责向频道发送二进制的字符串消息,然后频道收到消息时,推送给订阅者。
使用场景
- 电商中,用户下单成功之后向指定频道发送消息,下游业务订阅支付结果这个频道处理自己相关业务逻辑
- 粉丝关注功能
- 文章推送
使用注意
- 客户端需要及时消费和处理消息。
- 客户端订阅了channel之后,如果接收消息不及时,可能导致DCS实例消息堆积,当达到消息堆积阈值(默认值为32MB),或者达到某种程度(默认8MB)一段时间(默认为1分钟)后,服务器端会自动断开该客户端连接,避免导致内部内存耗尽。
- 客户端需要支持重连。
- 当连接断开之后,客户端需要使用subscribe或者psubscribe重新进行订阅,否则无法继续接收消息。
- 不建议用于消息可靠性要求高的场景中。
- Redis的pubsub不是一种可靠的消息系统。当出现客户端连接退出,或者极端情况下服务端发生主备切换时,未消费的消息会被丢弃。
深入理解
我们通过几个问题,来深入理解Redis的订阅发布机制
基于频道(Channel)的发布/订阅如何实现的?
底层是通过字典(图中的pubsub_channels)实现的 ,这个字典就用于保存订阅频道的信息:字典的键为正在被订阅的频道, 而字典的值则是一个链表, 链表中保存了所有订阅这个频道的客户端。
数据结构
比如说,在下图展示的这个 pubsub_channels 示例中, client2 、 client5 和 client1 就订阅了 channel1 , 而其他频道也分别被别的客户端所订阅:
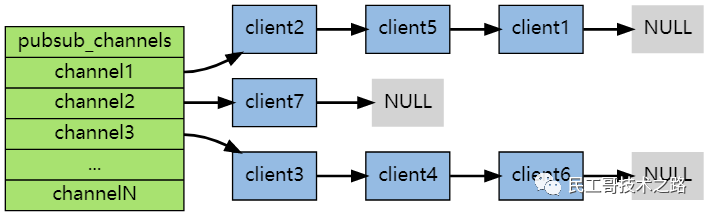
订阅
当客户端调用 SUBSCRIBE 命令时, 程序就将客户端和要订阅的频道在 pubsub_channels 字典中关联起来。
举个例子,如果客户端 client10086 执行命令 SUBSCRIBE channel1 channel2 channel3 ,那么前面展示的 pubsub_channels 将变成下面这个样子:
发布
当调用 PUBLISH channel message 命令, 程序首先根据 channel 定位到字典的键, 然后将信息发送给字典值链表中的所有客户端。
比如说,对于以下这个 pubsub_channels 实例, 如果某个客户端执行命令 PUBLISH channel1 “hello moto” ,那么 client2 、 client5 和 client1 三个客户端都将接收到 “hello moto” 信息:
退订
使用 UNSUBSCRIBE 命令可以退订指定的频道, 这个命令执行的是订阅的反操作:它从 pubsub_channels 字典的给定频道(键)中, 删除关于当前客户端的信息, 这样被退订频道的信息就不会再发送给这个客户端。
基于模式(Pattern)的发布/订阅如何实现的?
底层是pubsubPattern节点的链表。
数据结构
redisServer.pubsub_patterns 属性是一个链表,链表中保存着所有和模式相关的信息:
struct redisServer {
// ...
list *pubsub_patterns;
// ...
};
链表中的每个节点都包含一个 redis.h/pubsubPattern 结构:
typedef struct pubsubPattern {
redisClient *client;
robj *pattern;
} pubsubPattern;
client 属性保存着订阅模式的客户端,而 pattern 属性则保存着被订阅的模式。
每当调用 PSUBSCRIBE 命令订阅一个模式时, 程序就创建一个包含客户端信息和被订阅模式的 pubsubPattern 结构, 并将该结构添加到 redisServer.pubsub_patterns 链表中。
作为例子,下图展示了一个包含两个模式的 pubsub_patterns 链表, 其中 client123 和 client256 都正在订阅 tweet.shop.* 模式:
订阅
如果这时客户端 client10086 执行 PSUBSCRIBE broadcast.list.* , 那么 pubsub_patterns 链表将被更新成这样:

通过遍历整个 pubsub_patterns 链表,程序可以检查所有正在被订阅的模式,以及订阅这些模式的客户端。
发布
发送信息到模式的工作也是由 PUBLISH 命令进行的, 显然就是匹配模式获得Channels,然后再把消息发给客户端。
退订
使用 PUNSUBSCRIBE 命令可以退订指定的模式, 这个命令执行的是订阅模式的反操作:程序会删除 redisServer.pubsub_patterns 链表中, 所有和被退订模式相关联的 pubsubPattern 结构, 这样客户端就不会再收到和模式相匹配的频道发来的信息。
SpringBoot结合Redis发布/订阅实例?
最佳实践是通过RedisTemplate,关键代码如下:
// 发布
redisTemplate.convertAndSend("my_topic_name", "message_content");
// 配置订阅
RedisMessageListenerContainer container = new RedisMessageListenerContainer();
container.setConnectionFactory(connectionFactory);
container.addMessageListener(xxxMessageListenerAdapter, "my_topic_name");
总结
1、redis的订阅频道的信息是redis服务器进程自己维持在pubsub_channels链表字典当中。字典的KEY为被订阅的频道,值为订阅的客户端。
2、当发送者发送消息时,redis服务器遍历频道对应的所有客户端,然后将消息发送到所订阅的客户端上。
3、当有信息发送时,除了订阅该频道的客户端会收到消息,以及和订阅了匹配频道的客户端,其它客户端是收不到该信息的。
4、退订频道、退订模式和订阅频道、订阅模式是两组反操作。
应用场景
俗话说的好,知识学得好不好,还得看用到哪。反正笔者看到redis的发布与订阅的模式的特点后,第一时间想到的是可以用来做一个实时聊天系统,还可以用来做分布式架构中写的过程,利用redis的实时发布功能,把要写入的值及时快速的分发到各个写入程序当中,保证分布式架构中数据的完整一致性。再比如博客系统和自媒体平台中,粉丝关注功能,就比当我发布文章时,就可以及时推送文章到粉丝的客户端上。总而言之,应用的场景比较多,需要大家多思考,多交流。
参考来源:
https://blog.csdn.net/w15558056319/article/details/121490953 pdai.tech/md/db/nosql-redis/db-redis-x-pub-sub.html https://www.wenjiangs.com/doc/mt0ueji7b8sc
(五):Redis 事件机制详解
前言
Redis 采用事件驱动机制来处理大量的网络 IO。 它并没有使用 libevent 或者 libev 这样的成熟开源方案,而是自己实现一个非常简洁的事件驱动库 ae_event 。
什么是事件驱动?
所谓事件驱动,简单地说就是你点什么按钮(即产生什么事件),电脑执行什么操作(即调用什么函数) .当然事件不仅限于用户的操作. 事件驱动的核心自然是事件。
从事件角度说,事件驱动程序的 基本结构是由一个事件收集器、一个事件发送器和一个事件处理器组成。
- 事件收集器专门负责收集所有事件,包括来自用户的(如鼠标、键盘事件等)、来自硬件的(如时钟事件等)和来自软件的(如操作系统、应用程序本身等)。
- 事件发送器负责将收集器收集到的事件分发到目标对象中。
- 事件处理器做具体的事件响应工作。
事件驱动库的代码主要是在src/ae.c中实现的,其示用意如下所示。
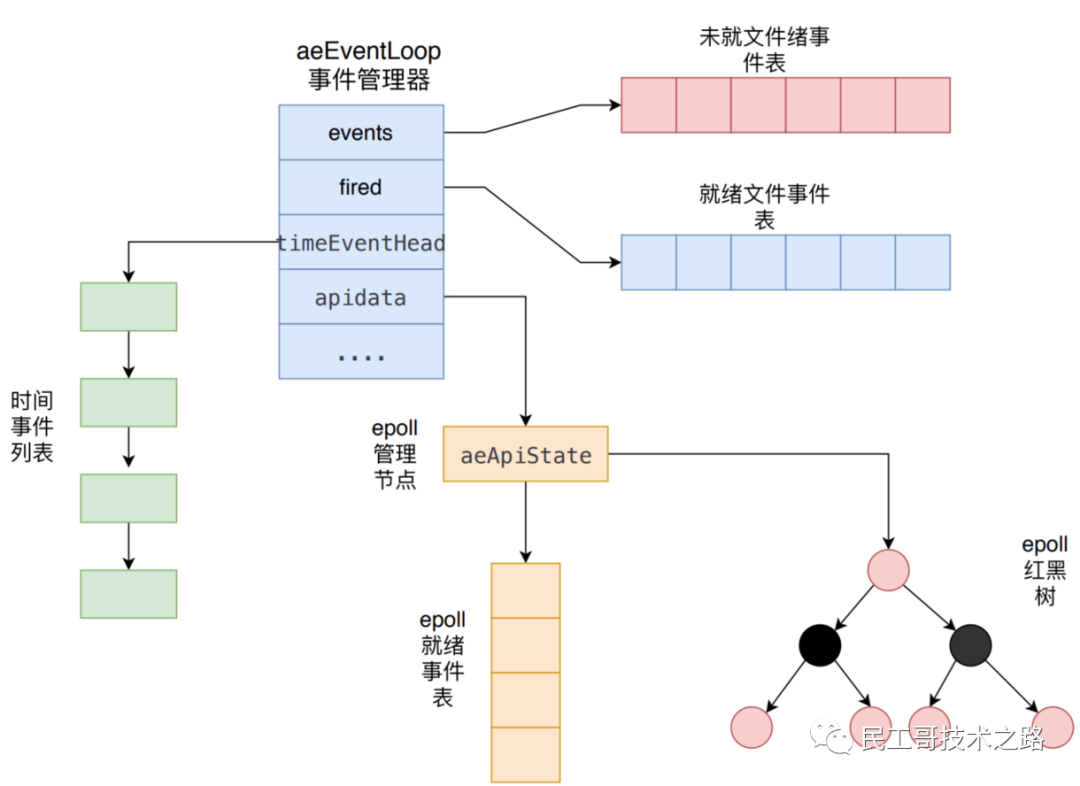
Redis 服务器就是一个事件驱动程序,服务器需要处理以下 两类事件 :
-
文件事件(file event) :Redis服务器通过套接字与客户端(或者其他Redis服务器)进行连接,而文件事件就是服务器对套接字操作的抽象,服务器与客户端(或者是其他服务器)通信会产生相应的文件事件,而服务器则通过监听并处理这些事件来完成一系列网络通信操作。
-
时间事件(time event) :Redis服务器中的一些操作需要在给定的时间点执行,而时间事件就是服务器对这类定时操作的抽象。
文件事件
Redis基于Reactor模式开发了自己的网络事件处理器:这个处理器被称为文件事件处理器(file event handler):
- 文件事件处理器使用I/O多路复用(multiplexing)程序来同时监听多个套接字,并且根据套接字目前执行的任务来为套接字关联不同的所时间处理器
- 当被监听的套接字准备好执行连接应答(accept),读取(read),写入(write),关闭(close)等操作时,与操作相对应的文件事件就会产生,这时文件处理器就会调用套接字之前关联好的事件处理器来处理这些事件
虽然文件事件处理器以单线程的方式运行,但通过使用I/O多路复用程序来监听多个套接字,文件时间处理器既能实现高性能的网络通信模型,又可以很好的与Redis服务器中的其他同样以单线程方式运行的模块进行对接,这就保持了Redis内部单线程设计的简单性。
文件事件处理器的构成
文件事件处理器主要有 四部分组成 ,他们分别是 套接字,I.O多路复用程序,文件事件分派器,以及事件处理程序 。
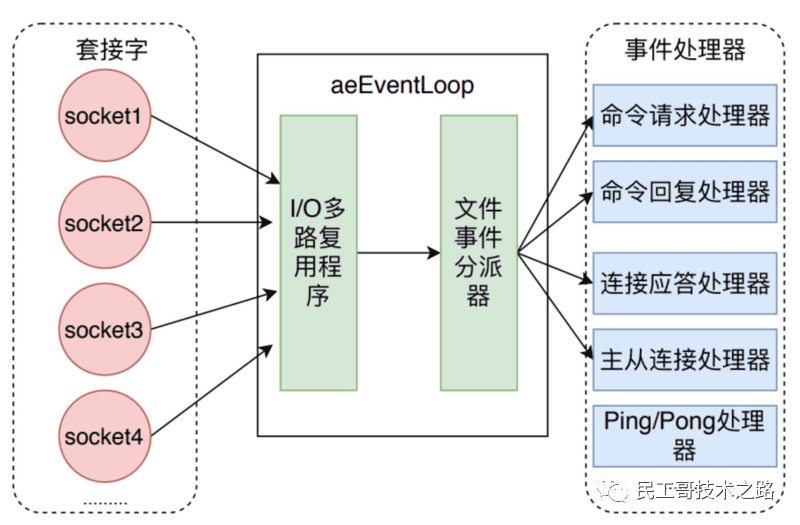
- 文件事件是对套接字操作的抽象,每当一个套接字准备好执行连接应答(accept),写入,读取,关闭等操作时,就会产生一个文件事件。因为一个服务器通常会连接多个套接字,所以多个文件事件可能会并发出现
- I/O多路复用程序负责监听多个套接字,并向文件事件分派器传送那些产生了事件的套接字
- 尽管多个文件事件可能会并发地产生地出现,但是I/O多路复用程序总是会将所有产生事件的套接字都会放到一个队列里面,然后通过这个队列,以有序(sequentially),同步(synchronously),每次一个套接字的方式向文件事件分派器传送套接字。当上一个套接字产生的事件被处理完毕后,I/O多路服用程序才会继续向文件事件分派器传送下一个套接字
- 文件事件分派器接受一个I/O多路复用程序传送来的套接字,并且根据套接字产生的事件的类型,调用相应的时间处理程序
I/O多路服用程序的实现
Redis的I/O多路复用程序的所有功能都是通过包装常见的select,epoll,evport和kqueue这些I/O多路复用函数库实现的,每个I/O多路复用函数库在Redis源码中都对应一个单独的文件。
下图就是基于多路复用的 Redis IO 模型。
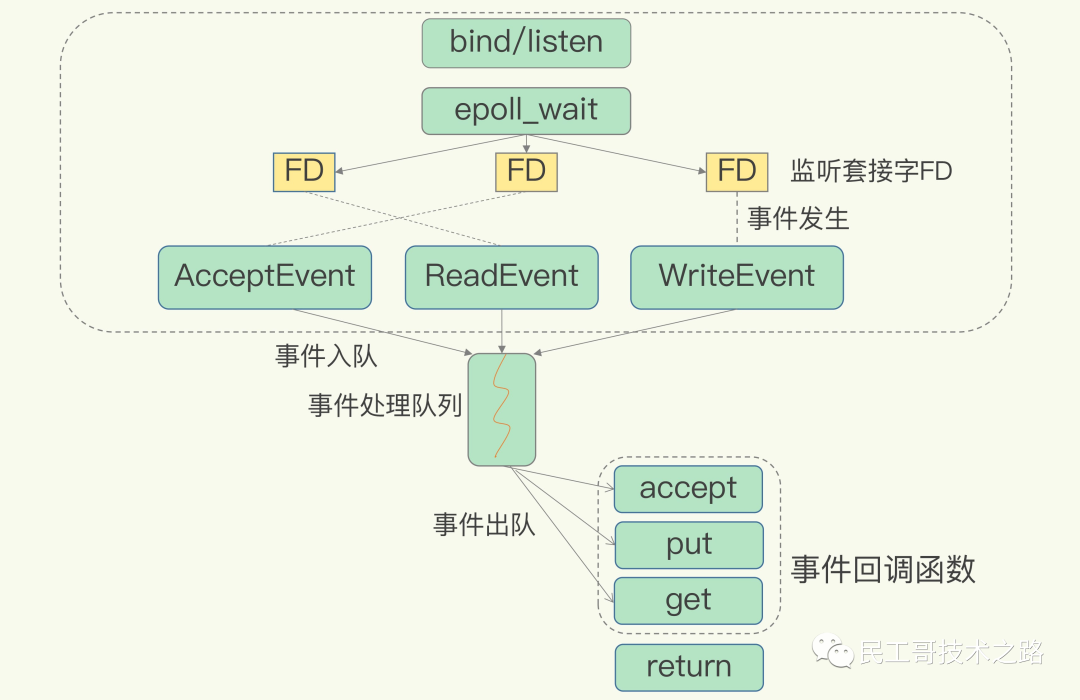
因为Redis为每个I/O多路复用函数库实现了相同的API,所以I/O多路复用程序的底层实现是可以互换的。

事件的类型
I/O多路复用程序可以监听多个套接字的READABLE事件和WRITEABLE事件,这两个事件和套接字操作之间的对应关系如下:
- 当套接字变得可读时(客户端对套接字执行write操作,或者执行close操作),或者有新的可应答(acceptable)套接字出现时(客户端对服务器的监听套接字主席那个connect操作),套接字产生READABLE事件
- 当套接字变得可写(客户端对套接字执行read操作),套接字产生WRITEABLE事件
I/O多路复用程序允许服务器同时监听套接字的READABLE事件和WRITEABLE事件,如果套接字同时产生这两种事件,那么文件事件分派器会优先处理READABLE事件,READABLE事件处理完之后,才会处理WRITEABLE事件。更多关于 Redis 学习的文章,请参阅:NoSQL 数据库系列之 Redis ,本系列持续更新中。
API
aeCreteFileEvent函数接受一个套接字描述符,一个事件类型,以及一个时间处理器作为参数,将套接字的给定事件加入到I/O多路复用程序的监听范围之内,并对事件和时间处理器进行关联。
aeDeleteFileEvent函数接受一个套接字描述符和监听事件类型作为参数,让I/O多路复用程序取消给定套接字的给定事件监听,并且取消事件和时间处理器之间的联系。
aeGetFileEvents函数接受一个套接字描述符,返回该套接字正在监听的事件类型:
- 如果套接字没有任务事件被监听,那么函数返回AE_NONE。
- 如果套接字的读事件正在被监听,那么函数返回AE_READABLE。
- 如果套接字的写事件正在被监听,那么函数返回AE_WRITABLE
- 如果套接字的读事件和写事件正在被监听,那么函数返回AE_READABLE|AE_WRITEABLE。
文件事件处理器
Redis为文件事件编写了多个处理器,这些事件处理器分别用于实现不同的网络通信需求:
- 为了对连接服务器的各个客户端进行应答,服务器要为监听套接字关联应答处理器。
- 为了接受客户端传来的命令请求,服务器要为客户端套接字关联命令请求处理器。
- 为了向客户端返回命令的执行结果,服务器要为客户端套接字关联命令回复处理器
- 当主服务器和从服务器进行复制操作时,朱从服务器都需要关联特别为复制功能编写的复制处理器
连接应答处理器
networking.c/accpetTcpHandler函数是Redis连接应答处理器,这个处理器用于对连接服务器监听套接字的客户端进行应答,具体实现为sys/socket.h/accpet函数的包装。
当Redis服务器进行初始化的时候,程序会将这个连接应答处理器和服务器监听套接字的AE_READABLE事件进行关联,当有客户端用sys/socketh/connect函数连接服务器监听套接字的时候,套接字就会产生AE_READABLE事件,引发连接应答处理器执行。
命令请求处理器
networking.c/readQueryFromClient函数是Redis命令处理器,这个命令处理器负责从套接字中读入客户端发送的命令请求内容,具体实现为unistd.h/read函数的包装。
当一个客户端通过连接应答处理器成功连接到服务器之后,服务器就会将客户端套接字的AE_READABLE事件和命令请求处理器关联起来,当客户端向服务器发送命令请求时,套接字就会产生AE_READABLE事件,引发命令请求处理器执行,并执行相应的套接字读入操作。
在客户端连接服务器的整个过程,服务器都会一直为客户端套接字的AE_READABLE事件关联命令请求处理器。
命令回复处理器
sendReplyToClient函数是Redis命令回复处理器,这个处理器负责将服务器执行命令后得到的回复命令通过套接字返回给客户端。
当服务器有命令回复需要传送给客户端时,服务器会将客户端套接字的AE_WRITEABLE事件和命令处理器关联起来,当客户端准备好接受服务器传回的命令回复时,就会产生AE_WRITABLE事件,引发命令回复处理器执行,并执行相应的套接字写入操作。
当命令回复处理器发送完毕后,服务器就会解除命令回复处理器与套接字得AE_WRITABLE事件之间的关联。更多关于 Redis 学习的文章,请参阅:NoSQL 数据库系列之 Redis,本系列持续更新中。
一次完整的客户端与服务器连接事件
当一个 Redis 服务器正在运作,那么这个服务器的舰艇套接字得 AE_READABLE事件应该正处于监听状态下,而事件所对应的处理器为连接应答处理器。
当 Redis 客户端向服务器发起连接,那么舰艇套接字将产生 AE_READABLE 事件,触发连接应答处理器执行。处理器会对客户端的连接应答请求进行应答,然后创建客户端套接字,以及客户端状态,并将客户端套接字的 AE_RAEDABLE事件与命令请求处理器进行关联,使得客户端可以主动向服务器发送命令请求。
之后,假设客户端向主服务器发送一个命令请求,那么客户端套接字将产生一个 AE_READABLE 事件,引发命令请求处理器执行,处理器读取客户端的命令内容,然后传给相关程序去执行。
执行命令将产生相应的命令回复,为了将这些命令回复传送给客户端,服务器会将客户端套接字的 AE_WRITABLE 事件与命令回复处理器进行关联。当客户端尝试读取命令回复的时候,客户端套接字将产生 AE_WRITABLE 事件,触发命令回复处理器执行,当命令回复处理器将命令回复全部写入套接字之后,服务器就会解除客户端套接字的 AE_WRITABLE 事件与命令回复处理器之间的关联。
时间事件
Redis 时间事件可以分为 两类 :
- 定时时间:让一段程序在指定的时间之后执行
- 周期性时间:让一段程序每隔指定时间就执行一次
一个时间事件主要有三个属性组成
- id:服务器为时间事件创建的全局唯一ID(标识号)。ID号按从小到大的顺序递增11,新事件的ID号比旧事件的ID号要大
- when:毫秒精度的UNIX时间戳,记录了时间事件到达时间
- timeProc:时间事件处理器,一个函数。当时间事件到达时,服务器就会调用相应的处理器来处理事件
一个定时事件是定时事件还是周期事件取决于时间事件处理器的返回值。
- 如果事件处理器返回ae.h/AE_NOMORE,那么这个事件为定时事件:该事件在到达一次之后就会被删除,之后不再到达
- 如果事件处理器返回一个非AE_NOMORE得整数值,那么这个事件为周期性事件:当一个时间事件到达之后,服务器会根据事件处理器返回的值,对时间事件的when属性进行更新,让这个事件在一段时间之后再次到达,并以这种方式一直更新并运行下去。
Redis中时间事件使用场景
时间事件的最主要应用是在redis服务器需要对自身的资源与配置进行定期的调度,从而确保服务器的长久运行。这些操作都是由serverCron函数实现。该函数做了以下操作。
1、更新redis服务器各类统计信息,包括时间,内存占用,数据库占用等
2、清理数据库中过期的key(过期删除)
3、关闭和清理连接失败的客户端
4、尝试进行aof个rdb的持久化操作(数据持久化)
5、如果服务器是主服务器,会定期将数据向从服务器做同步操作(主从复制)。
6、如果是集群模式,对集群定期进行同步和连接测试等操作(健康检查)。
Redis启动后,会定期执行serverCron函数,直到redis关闭为止,默认每秒执行10次,也就是100ms执行一次。
可以在redis配置文件(redis.conf)中的hz选项调整执行频率。
#redis执行任务的频率为1s除以hz, 一秒钟执行多少次
hz 10
实现
服务器将所有时间事件都放在一个无序链表中,每当时间事件执行器被运行时,它就遍历整个链表,查找所有已经达到的时间事件,并且调用相应的事件处理器
时间事件的链表为无序链表,指的不是链表不按ID排序,而是说该丽娜表不按when属性的大小排序。正因为链表没有按照when属性进行排序,所以当时间事件执行器运行时,它必须遍历链表中的所有时间事件,这样才能确保服务器中所有时间事件都被处理。更多关于 Redis 学习的文章,请参阅:NoSQL 数据库系列之 Redis ,本系列持续更新中。
时间事件的应用实例:serverCron函数
持续运行的Redis服务器需要定期对自身的资源和状态进行检查和调整,从而确保服务器可以长期,稳定的运行,这些定期操作有redis.c/serverCron函数负责执行,它的主要工作:
- 更新服务器的各类统计信息,比如时间,内存占用,数据库占用情况
- 清理数据库中的过期键值对
- 关闭和清理连接失效的客户端
- 尝试进行AOF或者RDB持久化操作
- 如果服务器时主服务器,那么对从服务器定期同步和连接测试
- 如果处于集群模式,那么对集群进行定期同步和连接测试
Redis服务器以周期性事件的方式运行serverCron函数,在服务器运行期间,每隔一段时间,serverCron就会执行一次,直到服务器关闭
事件的调度与执行
因为服务器中同时存在文件事件和时间事件,所以服务器必须对这两种事件进行调度,决定何时处理文件事件,何时处理时间事件,已经花费多少事件处理事件。
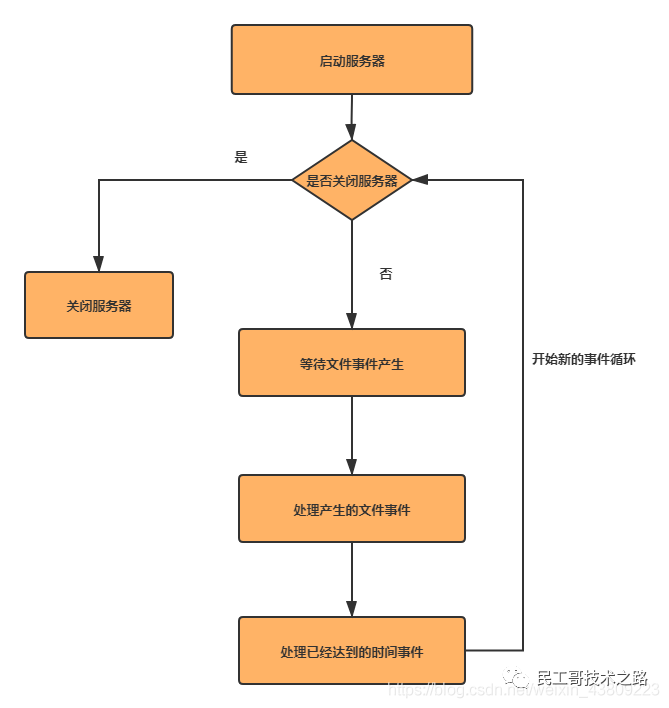
事件的调度和执行由ae.c/aeProcessEvents函数负责。将aeProcessEvents函数置于一个循环里面,加上初始化和清理函数,这就构成了Redis服务器的主函数,一下是该函数的伪代码:
def main():
#初始化服务器
init_server()
#一直处理事件,知道服务器关闭
while server_is_not_shutdown():
aeProcessEvents()
#服务器关闭,执行清理操作
clean_server()
从事件处理的角度,Redis服务器的运行流程可以用下图表示:
总结
Redis的高性能为什么是单线程也可以性能这么高。它的事件处理机制起着非常重要的一个作用。选用的模型为reactor模型。让单线程去做了多线程可以做的事情,并且还没有线程安全问题。
来源:
https://blog.csdn.net/weixin_43809223/article/details/109631305
(六):Redis 事务详解
什么是Redis事务
Redis 事务的 本质是一组命令的集合。事务支持一次执行多个命令,一个事务中所有命令都会被序列化。 在事务执行过程,会按照顺序串行化执行队列中的命令,其他客户端提交的命令请求不会插入到事务执行命令序列中。
总结说: redis 事务就是一次性、顺序性、排他性的执行一个队列中的一系列命令。
Redis事务相关命令和使用
MULTI、EXEC、DISCARD 和 WATCH 是 Redis 事务相关的命令。
- MULTI :开启事务,redis会将后续的命令逐个放入队列中,然后使用EXEC命令来原子化执行这个命令系列。
- EXEC:执行事务中的所有操作命令。
- DISCARD:取消事务,放弃执行事务块中的所有命令。
- WATCH:监视一个或多个key,如果事务在执行前,这个key(或多个key)被其他命令修改,则事务被中断,不会执行事务中的任何命令。
- UNWATCH:取消WATCH对所有key的监视。
标准的事务执行
给k1、k2分别赋值,在事务中修改k1、k2,执行事务后,查看k1、k2值都被修改。
127.0.0.1:6379> set k1 v1
OK
127.0.0.1:6379> set k2 v2
OK
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> set k1 11
QUEUED
127.0.0.1:6379> set k2 22
QUEUED
127.0.0.1:6379> EXEC
1) OK
2) OK
127.0.0.1:6379> get k1
"11"
127.0.0.1:6379> get k2
"22"
127.0.0.1:6379>
事务取消
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> set k1 33
QUEUED
127.0.0.1:6379> set k2 34
QUEUED
127.0.0.1:6379> DISCARD
OK
事务出现错误的处理
语法错误(编译器错误)
在开启事务后,修改k1值为11,k2值为22,但k2语法错误,最终导致事务提交失败, k1、k2保留原值。
127.0.0.1:6379> set k1 v1
OK
127.0.0.1:6379> set k2 v2
OK
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> set k1 11
QUEUED
127.0.0.1:6379> sets k2 22
(error) ERR unknown command `sets`, with args beginning with: `k2`, `22`,
127.0.0.1:6379> exec
(error) EXECABORT Transaction discarded because of previous errors.
127.0.0.1:6379> get k1
"v1"
127.0.0.1:6379> get k2
"v2"
127.0.0.1:6379>
Redis类型错误(运行时错误)
在开启事务后,修改k1值为11,k2值为22,但将k2的类型作为List, 在运行时检测类型错误,最终导致事务提交失败,此时事务并没有回滚,而是跳过错误命令继续执行, 结果k1值改变、k2保留原值。
127.0.0.1:6379> set k1 v1
OK
127.0.0.1:6379> set k1 v2
OK
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> set k1 11
QUEUED
127.0.0.1:6379> lpush k2 22
QUEUED
127.0.0.1:6379> EXEC
1) OK
2) (error) WRONGTYPE Operation against a key holding the wrong kind of value
127.0.0.1:6379> get k1
"11"
127.0.0.1:6379> get k2
"v2"
127.0.0.1:6379>
CAS操作实现乐观锁
WATCH 命令可以为 Redis 事务提供 check-and-set (CAS)行为。
CAS? 乐观锁? Redis官方的例子帮你理解
被 WATCH 的键会被监视,并会发觉这些键是否被改动过了。如果有至少一个被监视的键在 EXEC 执行之前被修改了, 那么整个事务都会被取消, EXEC 返回nil-reply来表示事务已经失败。
举个例子, 假设我们需要原子性地为某个值进行增 1 操作(假设 INCR 不存在)。
首先我们可能会这样做:
val = GET mykey
val = val + 1
SET mykey $val
上面的这个实现在只有一个客户端的时候可以执行得很好。但是, 当多个客户端同时对同一个键进行这样的操作时, 就会产生竞争条件。举个例子, 如果客户端 A 和 B 都读取了键原来的值, 比如 10 , 那么两个客户端都会将键的值设为 11 , 但正确的结果应该是 12 才对。
有了 WATCH ,我们就可以轻松地解决这类问题了:
WATCH mykey
val = GET mykey
val = val + 1
MULTI
SET mykey $val
EXEC
使用上面的代码, 如果在 WATCH 执行之后, EXEC 执行之前, 有其他客户端修改了 mykey 的值, 那么当前客户端的事务就会失败。程序需要做的, 就是不断重试这个操作, 直到没有发生碰撞为止。
这种形式的锁被称作乐观锁 , 它是一种非常强大的锁机制。并且因为大多数情况下, 不同的客户端会访问不同的键, 碰撞的情况一般都很少, 所以通常并不需要进行重试。
watch是如何监视实现的呢?
Redis使用WATCH命令来决定事务是继续执行还是回滚,那就需要在MULTI之前使用WATCH来监控某些键值对,然后使用MULTI命令来开启事务,执行对数据结构操作的各种命令,此时这些命令入队列。
当使用EXEC执行事务时,首先会比对WATCH所监控的键值对,如果没发生改变,它会执行事务队列中的命令,提交事务;如果发生变化,将不会执行事务中的任何命令,同时事务回滚。当然无论是否回滚,Redis都会取消执行事务前的WATCH命令。
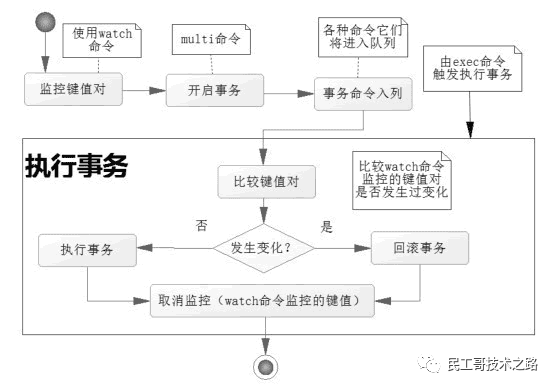
watch 命令实现监视
在事务开始前用WATCH监控k1,之后修改k1为11,说明事务开始前k1值被改变,MULTI开始事务,修改k1值为12,k2为22,执行EXEC,发回nil,说明事务回滚;查看下k1、k2的值都没有被事务中的命令所改变。
127.0.0.1:6379> set k1 v1
OK
127.0.0.1:6379> set k2 v2
OK
127.0.0.1:6379> WATCH k1
OK
127.0.0.1:6379> set k1 11
OK
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> set k1 12
QUEUED
127.0.0.1:6379> set k2 22
QUEUED
127.0.0.1:6379> EXEC
(nil)
127.0.0.1:6379> get k1
"11"
127.0.0.1:6379> get k2
"v2"
127.0.0.1:6379>
UNWATCH取消监视
127.0.0.1:6379> set k1 v1
OK
127.0.0.1:6379> set k2 v2
OK
127.0.0.1:6379> WATCH k1
OK
127.0.0.1:6379> set k1 11
OK
127.0.0.1:6379> UNWATCH
OK
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> set k1 12
QUEUED
127.0.0.1:6379> set k2 22
QUEUED
127.0.0.1:6379> exec
1) OK
2) OK
127.0.0.1:6379> get k1
"12"
127.0.0.1:6379> get k2
"22"
Redis事务执行步骤
通过上文命令执行,很显然 Redis事务执行是三个阶段 :
- 开启 :以MULTI开始一个事务
- 入队 :将多个命令入队到事务中,接到这些命令并不会立即执行,而是放到等待执行的事务队列里面
- 执行 :由EXEC命令触发事务
当一个客户端切换到事务状态之后, 服务器会根据这个客户端发来的不同命令执行不同的操作:
- 如果客户端发送的命令为 EXEC 、 DISCARD 、 WATCH 、 MULTI 四个命令的其中一个, 那么服务器立即执行这个命令。
- 与此相反, 如果客户端发送的命令是 EXEC 、 DISCARD 、 WATCH 、 MULTI 四个命令以外的其他命令, 那么服务器并不立即执行这个命令, 而是将这个命令放入一个事务队列里面, 然后向客户端返回 QUEUED 回复。

更深入的理解
我们再通过几个问题来深入理解Redis事务。
为什么 Redis 不支持回滚?
如果你有使用关系式数据库的经验,那么“ Redis 在事务失败时不进行回滚,而是继续执行余下的命令 ”这种做法可能会让你觉得有点奇怪。
以下是这种做法的优点:
- Redis 命令只会因为错误的语法而失败(并且这些问题不能在入队时发现),或是命令用在了错误类型的键上面:这也就是说,从实用性的角度来说,失败的命令是由编程错误造成的,而这些错误应该在开发的过程中被发现,而不应该出现在生产环境中。
- 因为不需要对回滚进行支持,所以 Redis 的内部可以保持简单且快速。
有种观点认为 Redis 处理事务的做法会产生 bug , 然而需要注意的是, 在通常情况下, 回滚并不能解决编程错误带来的问题 。举个例子, 如果你本来想通过 INCR 命令将键的值加上 1 , 却不小心加上了 2 , 又或者对错误类型的键执行了 INCR , 回滚是没有办法处理这些情况的。
如何理解Redis与事务的ACID?
一般来说, 事务有四个性质称为ACID,分别是原子性,一致性,隔离性和持久性 。这是基础,但是很多文章对Redis 是否支持ACID有一些异议,我觉的有必要梳理下:
原子性atomicity
首先通过上文知道 运行期的错误是不会回滚的,很多文章由此说Redis事务违背原子性的;而官方文档认为是遵从原子性的。
Redis官方文档给的理解是, Redis的事务是原子性的:所有的命令,要么全部执行,要么全部不执行。 而不是完全成功。
一致性consistency
redis事务可以保证命令失败的情况下得以回滚,数据能恢复到没有执行之前的样子,是保证一致性的,除非redis进程意外终结。
隔离性Isolation
redis事务是严格遵守隔离性的,原因是redis是单进程单线程模式(v6.0之前),可以保证命令执行过程中不会被其他客户端命令打断。
但是,Redis不像其它结构化数据库有隔离级别这种设计。
持久性Durability
redis事务是不保证持久性的 ,这是因为redis持久化策略中不管是RDB还是AOF都是异步执行的,不保证持久性是出于对性能的考虑。
Redis事务其它实现
-
基于Lua脚本,Redis可以保证脚本内的命令一次性、按顺序地执行,其同时也不提供事务运行错误的回滚,执行过程中如果部分命令运行错误,剩下的命令还是会继续运行完
-
基于中间标记变量,通过另外的标记变量来标识事务是否执行完成,读取数据时先读取该标记变量判断是否事务执行完成。但这样会需要额外写代码实现,比较繁琐
来源:https://www.pdai.tech/md/db/nosql-redis/db-redis-x-trans.html
(七):Redis 持久化(RDB和AOF)
Redis 持久化介绍
为了防止数据丢失以及服务重启时能够恢复数据,Redis支持数据的持久化,主要分为两种方式,分别是RDB和AOF; 当然实际场景下还会使用这两种的混合模式。
为什么需要持久化?
Redis是个基于内存的数据库。那服务一旦宕机,内存中的数据将全部丢失。通常的解决方案是从后端数据库恢复这些数据,但后端数据库有性能瓶颈,如果是大数据量的恢复:
1、会对数据库带来巨大的压力
2、数据库的性能不如Redis。导致程序响应慢
所以对Redis来说,实现数据的持久化,避免从后端数据库中恢复数据,是至关重要的。
Redis持久化有哪些方式呢?为什么我们需要重点学RDB和AOF?
从严格意义上说, Redis服务提供四种持久化存储方案:RDB、AOF、虚拟内存(VM)和 DISKSTORE。 虚拟内存(VM)方式,从Redis Version 2.4开始就被官方明确表示不再建议使用,Version 3.2版本中更找不到关于虚拟内存(VM)的任何配置范例,Redis的主要作者Salvatore Sanfilippo还专门写了一篇论文,来反思Redis对虚拟内存(VM)存储技术的支持问题。
至于DISKSTORE方式,是从Redis Version 2.8版本开始提出的一个存储设想,到目前为止Redis官方也没有在任何stable版本中明确建议使用这用方式。在Version 3.2版本中同样找不到对于这种存储方式的明确支持。从网络上能够收集到的各种资料来看,DISKSTORE方式和RDB方式还有着一些千丝万缕的联系,不过各位读者也知道,除了官方文档以外网络资料很多就是大抄。
最关键的是目前官方文档上能够看到的Redis对持久化存储的支持明确的就只有两种方案(https://redis.io/topics/persistence):RDB和AOF。所以本文也只会具体介绍这两种持久化存储方案的工作特定和配置要点。
RDB(Redis DataBase)持久化
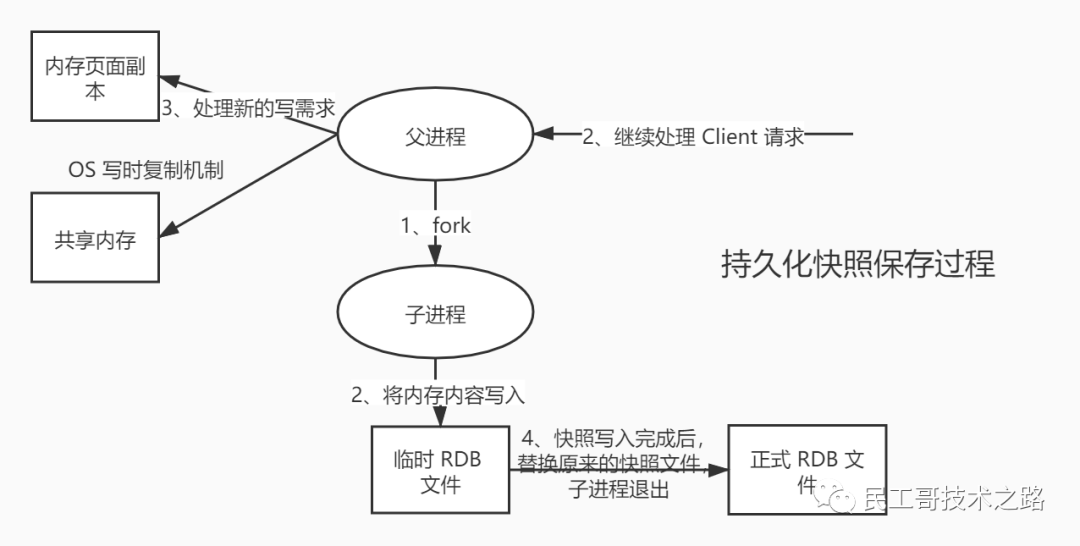
RDB 就是 Redis DataBase 的缩写,中文名为 快照/内存快照 , RDB持久化是把当前进程数据生成快照保存到磁盘上的过程,由于是某一时刻的快照,那么快照中的值要早于或者等于内存中的值。
Redis 会单独创建(fork)一个子进程进行持久化,会先将数据写入一个临时文件中,待持久化过程结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程不进行任何 IO 操作,这就确保的极高的性能。如果需要大规模的数据的恢复,且对数据恢复的完整性不是非常敏感,那 RDB 方式要比 AOF 方式更加高效。RDB 唯一的缺点是最后一次持久化的数据可能会丢失。
触发rdb持久化的方式有2种,分别是 手动触发 和 自动触发 。
手动触发
手动触发分别对应 save和bgsave命令
- save命令 :阻塞当前Redis服务器,直到RDB过程完成为止,对于内存 比较大的实例会造成长时间阻塞, 线上环境不建议使用
- bgsave命令 :Redis进程执行fork操作创建子进程,RDB持久化过程由子 进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短
bgsave流程图如下所示
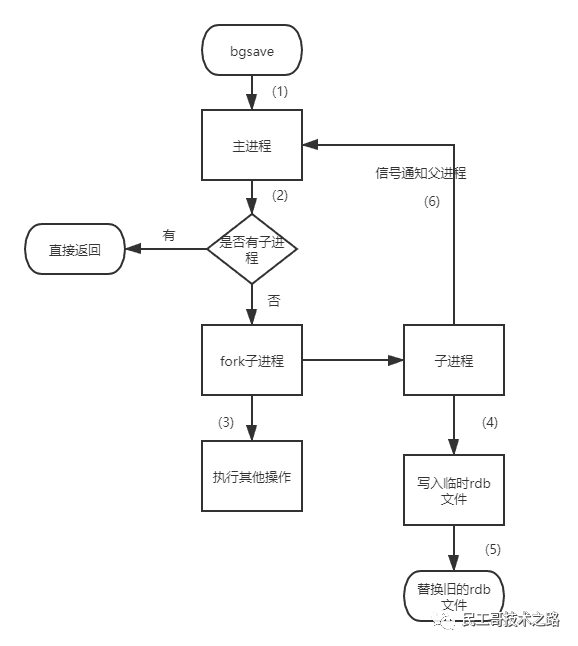
具体流程如下
- redis客户端执行bgsave命令或者自动触发bgsave命令;
- 主进程判断当前是否已经存在正在执行的子进程,如果存在,那么主进程直接返回;
- 如果不存在正在执行的子进程,那么就fork一个新的子进程进行持久化数据,fork过程是阻塞的,fork操作完成后主进程即可执行其他操作;
- 子进程先将数据写入到临时的rdb文件中,待快照数据写入完成后再原子替换旧的rdb文件;
- 同时发送信号给主进程,通知主进程rdb持久化完成,主进程更新相关的统计信息(info Persitence下的rdb_*相关选项)。
自动触发
在以下 4种情况时会自动触发 :
- redis.conf中配置save m n,即在m秒内有n次修改时,自动触发bgsave生成rdb文件;
- 主从复制时,从节点要从主节点进行全量复制时也会触发bgsave操作,生成当时的快照发送到从节点;
- 执行debug reload命令重新加载redis时也会触发bgsave操作;
- 默认情况下执行shutdown命令时,如果没有开启aof持久化,那么也会触发bgsave操作;
redis.conf中配置RDB
快照周期:内存快照虽然可以通过技术人员手动执行SAVE或BGSAVE命令来进行,但生产环境下多数情况都会设置其周期性执行条件。
Redis中默认的周期新设置
# 周期性执行条件的设置格式为
save <seconds> <changes>
# 默认的设置为:
save 900 1
save 300 10
save 60 10000
# 以下设置方式为关闭RDB快照功能
save ""
以上三项默认信息设置代表的意义是:
-
如果900秒内有1条Key信息发生变化,则进行快照;
-
如果300秒内有10条Key信息发生变化,则进行快照;
-
如果60秒内有10000条Key信息发生变化,则进行快照。读者可以按照这个规则,根据自己的实际请求压力进行设置调整。
其它相关配置
# 文件名称
dbfilename dump.rdb
# 文件保存路径
dir /home/work/app/redis/data/
# 如果持久化出错,主进程是否停止写入
stop-writes-on-bgsave-error yes
# 是否压缩
rdbcompression yes
# 导入时是否检查
rdbchecksum yes
-
dbfilename :RDB文件在磁盘上的名称。
-
dir :RDB文件的存储路径。默认设置为“./”,也就是Redis服务的主目录。
-
stop-writes-on-bgsave-error :上文提到的在快照进行过程中,主进程照样可以接受客户端的任何写操作的特性,是指在快照操作正常的情况下。如果快照操作出现异常(例如操作系统用户权限不够、磁盘空间写满等等)时,Redis就会禁止写操作。这个特性的主要目的是使运维人员在第一时间就发现Redis的运行错误,并进行解决。一些特定的场景下,您可能需要对这个特性进行配置,这时就可以调整这个参数项。该参数项默认情况下值为yes,如果要关闭这个特性,指定即使出现快照错误Redis一样允许写操作,则可以将该值更改为no。
-
rdbcompression :该属性将在字符串类型的数据被快照到磁盘文件时,启用LZF压缩算法。Redis官方的建议是请保持该选项设置为yes,因为“it’s almost always a win”。
-
rdbchecksum :从RDB快照功能的 version 5 版本开始,一个64位的CRC冗余校验编码会被放置在RDB文件的末尾,以便对整个RDB文件的完整性进行验证。这个功能大概会多损失10%左右的性能,但获得了更高的数据可靠性。所以如果您的 Redis 服务需要追求极致的性能,就可以将这个选项设置为no。更多关于 Redis 学习的文章,请参阅:NoSQL 数据库系列之 Redis ,本系列持续更新中。
RDB 更深入理解
我们通过几个实战问题来深入理解RDB
由于生产环境中我们为Redis开辟的内存区域都比较大(例如6GB),那么将内存中的数据同步到硬盘的过程可能就会持续比较长的时间,而实际情况是这段时间Redis服务一般都会收到数据写操作请求。 那么如何保证数据一致性呢?
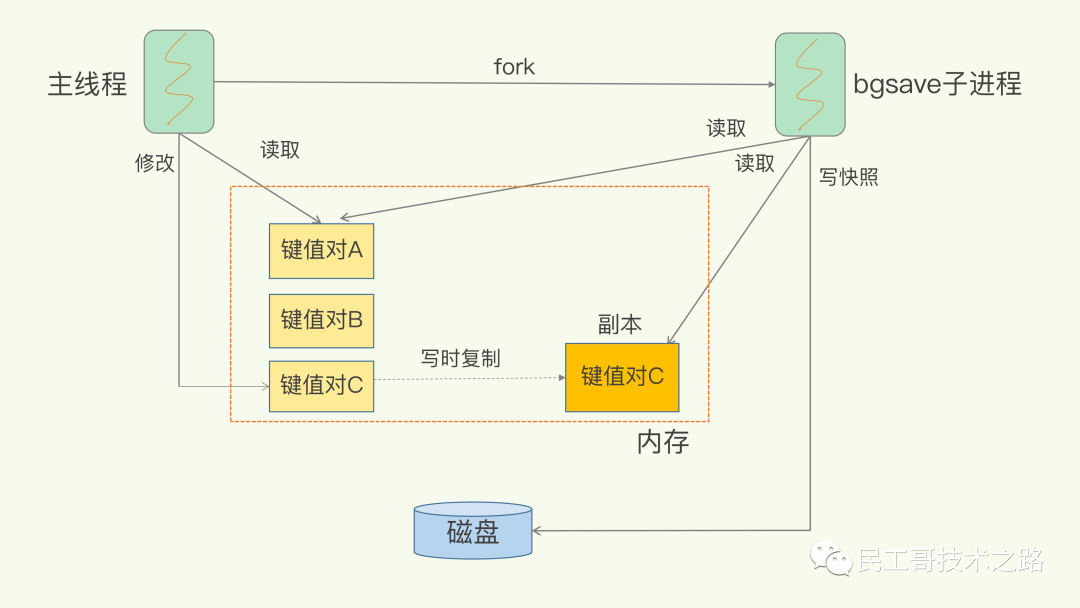
RDB中的核心思路是Copy-on-Write,来保证在进行快照操作的这段时间,需要压缩写入磁盘上的数据在内存中不会发生变化。在正常的快照操作中,一方面Redis主进程会fork一个新的快照进程专门来做这个事情,这样保证了Redis服务不会停止对客户端包括写请求在内的任何响应。另一方面这段时间发生的数据变化会以副本的方式存放在另一个新的内存区域,待快照操作结束后才会同步到原来的内存区域。
举个例子:如果主线程对这些数据也都是读操作(例如图中的键值对 A),那么,主线程和 bgsave 子进程相互不影响。但是,如果主线程要修改一块数据(例如图中的键值对 C),那么,这块数据就会被复制一份,生成该数据的副本。然后,bgsave 子进程会把这个副本数据写入 RDB 文件,而在这个过程中,主线程仍然可以直接修改原来的数据。
在进行快照操作的这段时间,如果发生服务崩溃怎么办?
很简单,在没有将数据全部写入到磁盘前,这次快照操作都不算成功。如果出现了服务崩溃的情况,将以上一次完整的RDB快照文件作为恢复内存数据的参考。也就是说,在快照操作过程中不能影响上一次的备份数据。Redis服务会在磁盘上创建一个临时文件进行数据操作,待操作成功后才会用这个临时文件替换掉上一次的备份。
可以每秒做一次快照吗?
对于快照来说,所谓“连拍”就是指连续地做快照。这样一来,快照的间隔时间变得很短,即使某一时刻发生宕机了,因为上一时刻快照刚执行,丢失的数据也不会太多。但是,这其中的快照间隔时间就很关键了。
如下图所示,我们先在 T0 时刻做了一次快照,然后又在 T0+t 时刻做了一次快照,在这期间,数据块 5 和 9 被修改了。如果在 t 这段时间内,机器宕机了,那么,只能按照 T0 时刻的快照进行恢复。此时,数据块 5 和 9 的修改值因为没有快照记录,就无法恢复了。
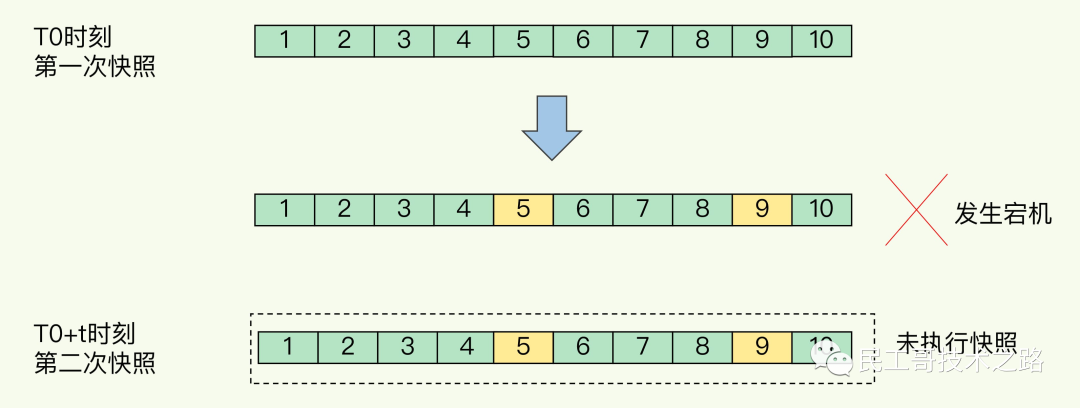
所以,要想尽可能恢复数据,t 值就要尽可能小,t 越小,就越像“连拍”。那么,t 值可以小到什么程度呢,比如说 是不是可以每秒做一次快照?毕竟,每次快照都是由 bgsave 子进程在后台执行,也不会阻塞主线程。
这种想法其实是错误的。虽然 bgsave 执行时不阻塞主线程,但是, 如果频繁地执行全量快照,也会带来两方面的开销:
- 一方面,频繁将全量数据写入磁盘,会给磁盘带来很大压力,多个快照竞争有限的磁盘带宽,前一个快照还没有做完,后一个又开始做了,容易造成恶性循环。
- 另一方面,bgsave 子进程需要通过 fork 操作从主线程创建出来。虽然,子进程在创建后不会再阻塞主线程,但是,fork 这个创建过程本身会阻塞主线程,而且主线程的内存越大,阻塞时间越长。如果频繁 fork 出 bgsave 子进程,这就会频繁阻塞主线程了。
那么,有什么其他好方法吗?此时,我们可以做 增量快照,就是指做了一次全量快照后,后续的快照只对修改的数据进行快照记录,这样可以避免每次全量快照的开销。 这个比较好理解。
但是它需要我们使用额外的元数据信息去记录哪些数据被修改了,这会带来额外的空间开销问题。那么,还有什么方法既能利用 RDB 的快速恢复,又能以较小的开销做到尽量少丢数据呢?且看后文中 4.0版本中引入的RDB和AOF的混合方式 。
RDB优缺点
优点
- RDB文件是某个时间节点的快照,默认使用LZF算法进行压缩,压缩后的文件体积远远小于内存大小,适用于备份、全量复制等场景;
- Redis加载RDB文件恢复数据要远远快于AOF方式;
缺点
- RDB方式实时性不够,无法做到秒级的持久化;
- 每次调用bgsave都需要fork子进程,fork子进程属于重量级操作,频繁执行成本较高;
- RDB文件是二进制的,没有可读性,AOF文件在了解其结构的情况下可以手动修改或者补全;
- 版本兼容RDB文件问题;
针对RDB不适合实时持久化的问题,Redis提供了AOF持久化方式来解决。
AOF(Append Only File)持久化
Redis是 “写后”日志,Redis先执行命令,把数据写入内存,然后才记录日志。 日志里记录的是Redis收到的每一条命令,这些命令是以文本形式保存。PS: 大多数的数据库采用的是写前日志(WAL),例如MySQL,通过写前日志和两阶段提交,实现数据和逻辑的一致性。
而AOF日志采用写后日志,即 先写内存,后写日志 。
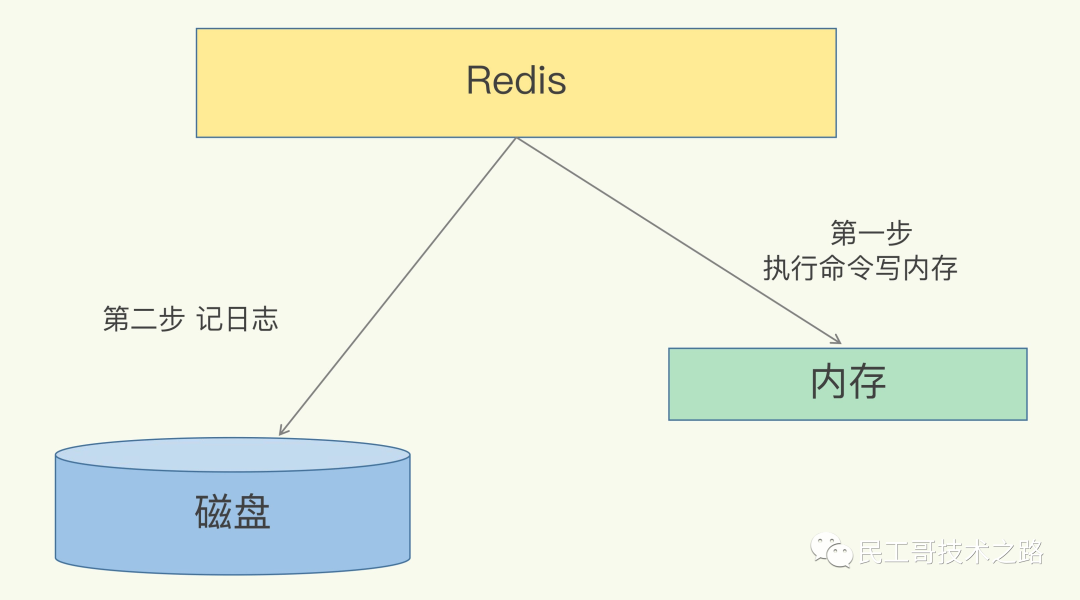
为什么采用写后日志?
Redis要求高性能,采用写日志有两方面好处:
- 避免额外的检查开销 :Redis 在向 AOF 里面记录日志的时候,并不会先去对这些命令进行语法检查。所以,如果先记日志再执行命令的话,日志中就有可能记录了错误的命令,Redis 在使用日志恢复数据时,就可能会出错。
- 不会阻塞当前的写操作
但这种方式存在 潜在风险 :
- 如果命令执行完成,写日志之前宕机了,会丢失数据。
- 主线程写磁盘压力大,导致写盘慢,阻塞后续操作。
如何实现AOF
AOF日志记录Redis的每个写命令,步骤分为: 命令追加(append)、文件写入(write)和文件同步(sync)。
- 命令追加 :当AOF持久化功能打开了,服务器在执行完一个写命令之后,会以协议格式将被执行的写命令追加到服务器的 aof_buf 缓冲区。
- 文件写入和同步 :关于何时将 aof_buf 缓冲区的内容写入AOF文件中,Redis提供了 三种写回策略:
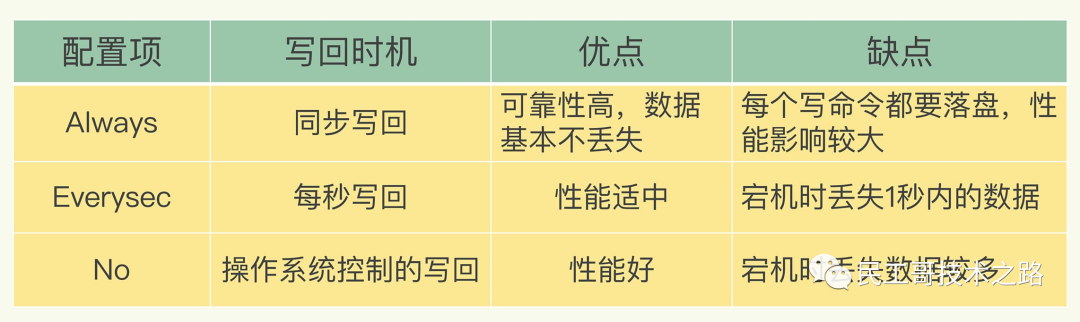
Always ,同步写回:每个写命令执行完,立马同步地将日志写回磁盘;
Everysec ,每秒写回:每个写命令执行完,只是先把日志写到AOF文件的内存缓冲区,每隔一秒把缓冲区中的内容写入磁盘;
No ,操作系统控制的写回:每个写命令执行完,只是先把日志写到AOF文件的内存缓冲区,由操作系统决定何时将缓冲区内容写回磁盘。
三种写回策略的优缺点
上面的三种写回策略体现了一个重要原则: **** trade-off,取舍,指在性能和可靠性保证之间做取舍。
关于AOF的同步策略是涉及到操作系统的 write 函数和 fsync 函数的,在《Redis设计与实现》中是这样说明的:
为了提高文件写入效率,在现代操作系统中,当用户调用write函数,将一些数据写入文件时,操作系统通常会将数据暂存到一个内存缓冲区里,当缓冲区的空间被填满或超过了指定时限后,才真正将缓冲区的数据写入到磁盘里。
这样的操作虽然提高了效率,但也为数据写入带来了安全问题:如果计算机停机,内存缓冲区中的数据会丢失。为此,系统提供了fsync、fdatasync同步函数,可以强制操作系统立刻将缓冲区中的数据写入到硬盘里,从而确保写入数据的安全性。
redis.conf中配置AOF
默认情况下,Redis是没有开启AOF的 ,可以通过配置redis.conf文件来开启AOF持久化,关于AOF的配置如下:
# appendonly参数开启AOF持久化
appendonly no
# AOF持久化的文件名,默认是appendonly.aof
appendfilename "appendonly.aof"
# AOF文件的保存位置和RDB文件的位置相同,都是通过dir参数设置的
dir ./
# 同步策略
# appendfsync always
appendfsync everysec
# appendfsync no
# aof重写期间是否同步
no-appendfsync-on-rewrite no
# 重写触发配置
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
# 加载aof出错如何处理
aof-load-truncated yes
# 文件重写策略
aof-rewrite-incremental-fsync yes
code here...
以下是Redis中关于AOF的主要配置信息:
appendonly #默认情况下AOF功能是关闭的,将该选项改为yes以便打开Redis的AOF功能。
appendfilename #这个参数项很好理解了,就是AOF文件的名字。
appendfsync #这个参数项是AOF功能最重要的设置项之一,主要用于设置“真正执行”操作命令向AOF文件中同步的策略。
什么叫“真正执行”呢?还记得Linux操作系统对磁盘设备的操作方式吗?为了保证操作系统中I/O队列的操作效率,应用程序提交的I/O操作请求一般是被放置在linux Page Cache中的,然后再由Linux操作系统中的策略自行决定正在写到磁盘上的时机。而Redis中有一个fsync()函数,可以将Page Cache中待写的数据真正写入到物理设备上,而缺点是频繁调用这个fsync()函数干预操作系统的既定策略,可能导致I/O卡顿的现象频繁 。
与上节对应,appendfsync参数项可以设置三个值,分别是:always、everysec、no,默认的值为everysec。
-
no-appendfsync-on-rewrite:always和everysec的设置会使真正的I/O操作高频度的出现,甚至会出现长时间的卡顿情况,这个问题出现在操作系统层面上,所有靠工作在操作系统之上的Redis是没法解决的。为了尽量缓解这个情况,Redis提供了这个设置项,保证在完成fsync函数调用时,不会将这段时间内发生的命令操作放入操作系统的Page Cache(这段时间Redis还在接受客户端的各种写操作命令)。
-
auto-aof-rewrite-percentage:上文说到在生产环境下,技术人员不可能随时随地使用“BGREWRITEAOF”命令去重写AOF文件。所以更多时候我们需要依靠Redis中对AOF文件的自动重写策略。Redis中对触发自动重写AOF文件的操作提供了两个设置:auto-aof-rewrite-percentage表示如果当前AOF文件的大小超过了上次重写后AOF文件的百分之多少后,就再次开始重写AOF文件。例如该参数值的默认设置值为100,意思就是如果AOF文件的大小超过上次AOF文件重写后的1倍,就启动重写操作。
-
auto-aof-rewrite-min-size:参考auto-aof-rewrite-percentage选项的介绍,auto-aof-rewrite-min-size设置项表示启动AOF文件重写操作的AOF文件最小大小。如果AOF文件大小低于这个值,则不会触发重写操作。注意,auto-aof-rewrite-percentage和auto-aof-rewrite-min-size只是用来控制Redis中自动对AOF文件进行重写的情况,如果是技术人员手动调用“BGREWRITEAOF”命令,则不受这两个限制条件左右。
深入理解AOF重写
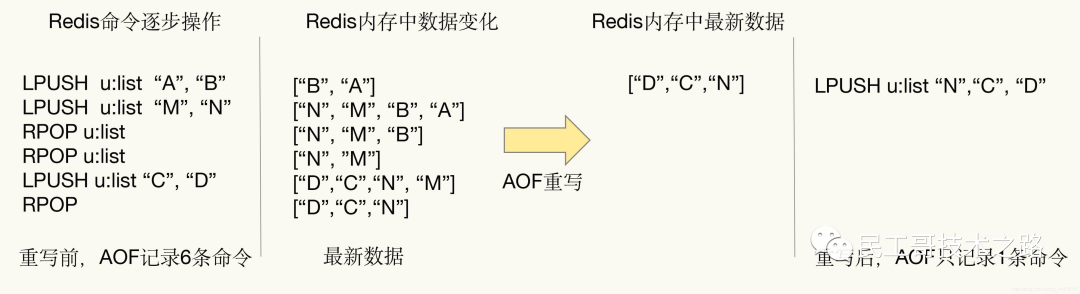
AOF会记录每个写命令到AOF文件,随着时间越来越长,AOF文件会变得越来越大。如果不加以控制,会对Redis服务器,甚至对操作系统造成影响,而且AOF文件越大,数据恢复也越慢。 为了解决AOF文件体积膨胀的问题,Redis提供AOF文件重写机制来对AOF文件进行“瘦身”。
图例解释AOF重写
Redis通过创建一个新的AOF文件来替换现有的AOF,新旧两个AOF文件保存的数据相同,但新AOF文件没有了冗余命令。
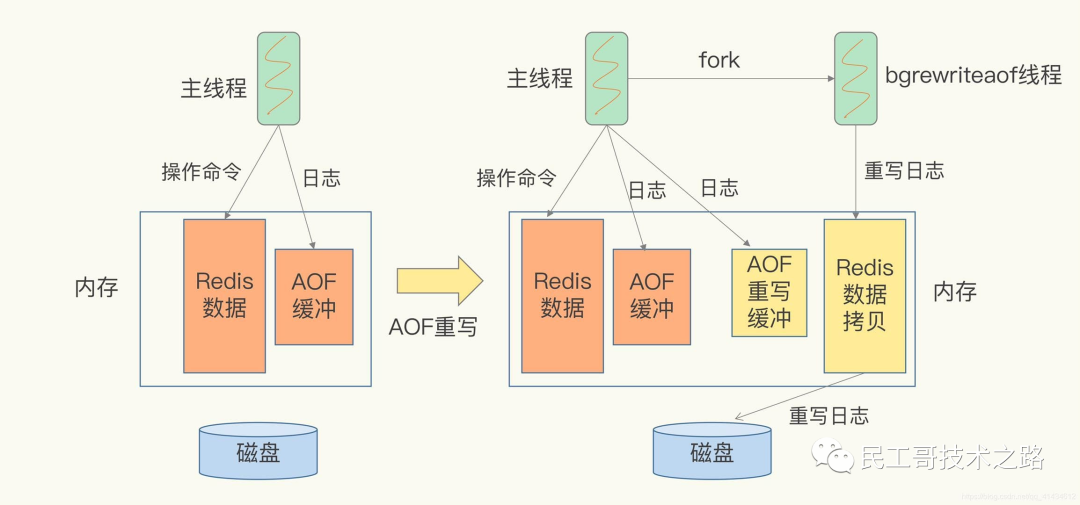
AOF重写会阻塞吗?
AOF重写过程是由后台进程bgrewriteaof来完成的。主线程fork出后台的bgrewriteaof子进程,fork会把主线程的内存拷贝一份给bgrewriteaof子进程,这里面就包含了数据库的最新数据。然后,bgrewriteaof子进程就可以在不影响主线程的情况下,逐一把拷贝的数据写成操作,记入重写日志。
所以aof在重写时,在fork进程时是会阻塞住主线程的。
AOF日志何时会重写?
有两个配置项控制AOF重写的触发:
-
auto-aof-rewrite-min-size :表示运行AOF重写时文件的最小大小,默认为64MB。
-
auto-aof-rewrite-percentage :这个值的计算方式是,当前aof文件大小和上一次重写后aof文件大小的差值,再除以上一次重写后aof文件大小。也就是当前aof文件比上一次重写后aof文件的增量大小,和上一次重写后aof文件大小的比值。
重写日志时,有新数据写入咋整?
重写过程总结为:“一个拷贝,两处日志”。在fork出子进程时的拷贝,以及在重写时,如果有新数据写入,主线程就会将命令记录到两个aof日志内存缓冲区中。如果AOF写回策略配置的是always,则直接将命令写回旧的日志文件,并且保存一份命令至AOF重写缓冲区,这些操作对新的日志文件是不存在影响的。(旧的日志文件:主线程使用的日志文件,新的日志文件:bgrewriteaof进程使用的日志文件)
而在bgrewriteaof子进程完成会日志文件的重写操作后,会提示主线程已经完成重写操作,主线程会将AOF重写缓冲中的命令追加到新的日志文件后面。这时候在高并发的情况下,AOF重写缓冲区积累可能会很大,这样就会造成阻塞,Redis后来通过Linux管道技术让aof重写期间就能同时进行回放,这样aof重写结束后只需回放少量剩余的数据即可。
最后通过修改文件名的方式,保证文件切换的原子性。
在AOF重写日志期间发生宕机的话,因为日志文件还没切换,所以恢复数据时,用的还是旧的日志文件。
总结操作:
- 主线程fork出子进程重写aof日志
- 子进程重写日志完成后,主线程追加aof日志缓冲
- 替换日志文件
温馨提示:这里的进程和线程的概念有点混乱。因为后台的bgreweiteaof进程就只有一个线程在操作,而主线程是Redis的操作进程,也是单独一个线程。这里想表达的是Redis主进程在fork出一个后台进程之后,后台进程的操作和主进程是没有任何关联的,也不会阻塞主线程。
主线程fork出子进程的是如何复制内存数据的?
fork采用操作系统提供的写时复制(copy on write)机制,就是为了避免一次性拷贝大量内存数据给子进程造成阻塞。fork子进程时,子进程时会拷贝父进程的页表,即虚实映射关系(虚拟内存和物理内存的映射索引表),而不会拷贝物理内存。这个拷贝会消耗大量cpu资源,并且拷贝完成前会阻塞主线程,阻塞时间取决于内存中的数据量,数据量越大,则内存页表越大。拷贝完成后,父子进程使用相同的内存地址空间。
但主进程是可以有数据写入的,这时候就会拷贝物理内存中的数据。如下图(进程1看做是主进程,进程2看做是子进程):
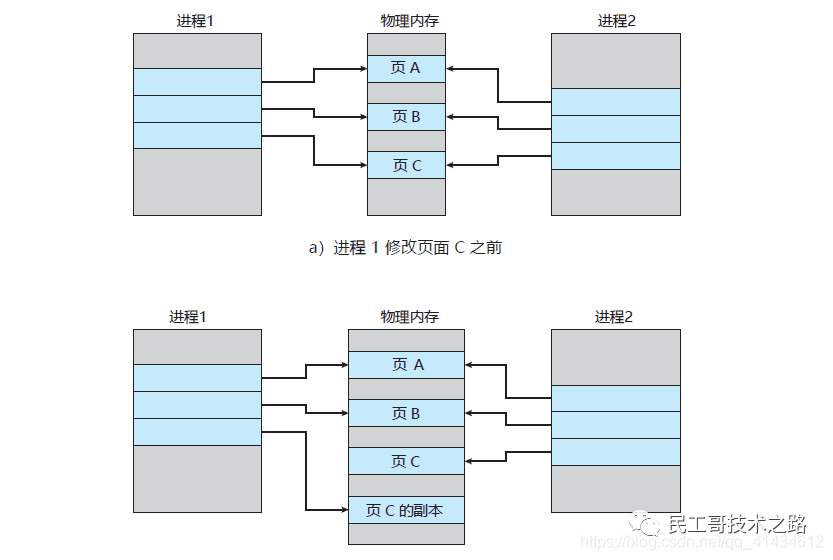
在主进程有数据写入时,而这个数据刚好在页c中,操作系统会创建这个页面的副本(页c的副本),即拷贝当前页的物理数据,将其映射到主进程中,而子进程还是使用原来的的页c。
在重写日志整个过程时,主线程有哪些地方会被阻塞?
- fork子进程时,需要拷贝虚拟页表,会对主线程阻塞。
- 主进程有bigkey写入时,操作系统会创建页面的副本,并拷贝原有的数据,会对主线程阻塞。
- 子进程重写日志完成后,主进程追加aof重写缓冲区时可能会对主线程阻塞。
为什么AOF重写不复用原AOF日志?
两方面原因:
- 父子进程写同一个文件会产生竞争问题,影响父进程的性能。
- 如果AOF重写过程中失败了,相当于污染了原本的AOF文件,无法做恢复数据使用。
RDB和AOF混合方式(4.0版本)
Redis 4.0 中提出了一个混合使用 AOF 日志和内存快照的方法。简单来说,内存快照以一定的频率执行,在两次快照之间,使用 AOF 日志记录这期间的所有命令操作。
这样一来,快照不用很频繁地执行,这就避免了频繁 fork 对主线程的影响。而且,AOF 日志也只用记录两次快照间的操作,也就是说,不需要记录所有操作了,因此,就不会出现文件过大的情况了,也可以避免重写开销。
如下图所示,T1 和 T2 时刻的修改,用 AOF 日志记录,等到第二次做全量快照时,就可以清空 AOF 日志,因为此时的修改都已经记录到快照中了,恢复时就不再用日志了。
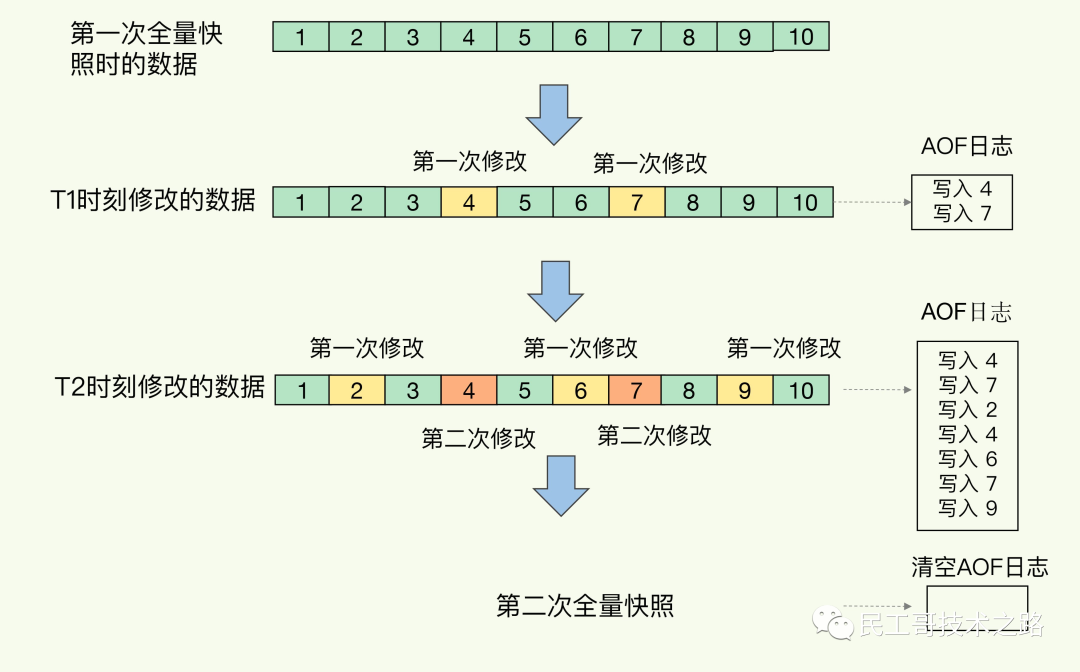
这个方法既能享受到 RDB 文件快速恢复的好处,又能享受到 AOF 只记录操作命令的简单优势, 实际环境中用的很多。
从持久化中恢复数据
数据的备份、持久化做完了,我们如何从这些持久化文件中恢复数据呢?如果一台服务器上有既有RDB文件,又有AOF文件,该加载谁呢?
其实想要从这些文件中恢复数据,只需要重新启动Redis即可。我们还是通过图来了解这个流程:
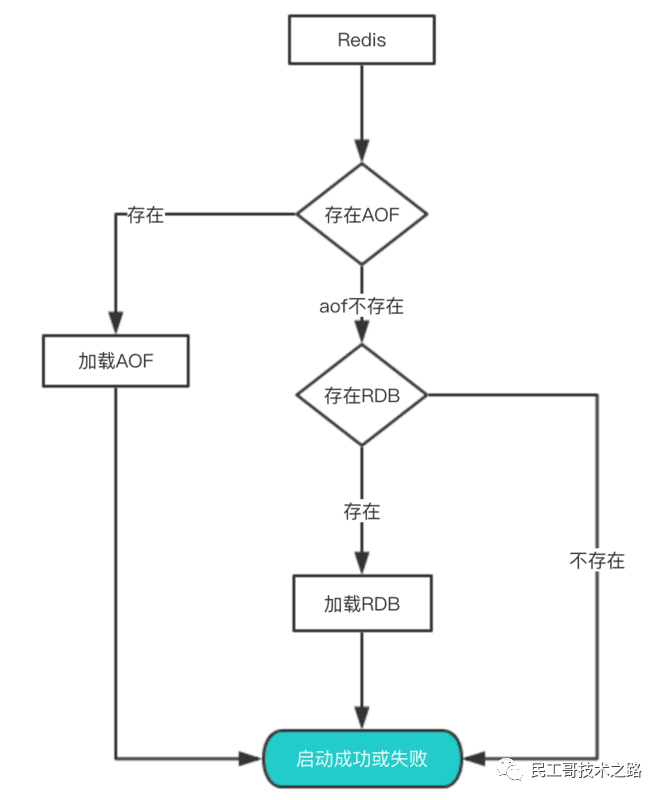
- redis重启时判断是否开启aof,如果开启了aof,那么就优先加载aof文件;
- 如果aof存在,那么就去加载aof文件,加载成功的话redis重启成功,如果aof文件加载失败,那么会打印日志表示启动失败,此时可以去修复aof文件后重新启动;
- 若aof文件不存在,那么redis就会转而去加载rdb文件,如果rdb文件不存在,redis直接启动成功;
- 如果rdb文件存在就会去加载rdb文件恢复数据,如加载失败则打印日志提示启动失败,如加载成功,那么redis重启成功,且使用rdb文件恢复数据;
那么为什么会优先加载AOF呢?因为AOF保存的数据更完整,通过上面的分析我们知道AOF基本上最多损失1s的数据。
性能与实践
通过上面的分析,我们都知道RDB的快照、AOF的重写都需要fork,这是一个重量级操作,会对Redis造成阻塞。因此为了不影响Redis主进程响应,我们需要尽可能降低阻塞。
- 降低fork的频率,比如可以手动来触发RDB生成快照、与AOF重写;
- 控制Redis最大使用内存,防止fork耗时过长;
- 使用更牛逼的硬件;
- 合理配置Linux的内存分配策略,避免因为物理内存不足导致fork失败。
在线上我们到底该怎么做?我提供一些自己的实践经验。
- 如果Redis中的数据并不是特别敏感或者可以通过其它方式重写生成数据,可以关闭持久化,如果丢失数据可以通过其它途径补回;
- 自己制定策略定期检查Redis的情况,然后可以手动触发备份、重写数据;
- 单机如果部署多个实例,要防止多个机器同时运行持久化、重写操作,防止出现内存、CPU、IO资源竞争,让持久化变为串行;
- 可以加入主从机器,利用一台从机器进行备份处理,其它机器正常响应客户端的命令;
- RDB持久化与AOF持久化可以同时存在,配合使用。
来源:https://www.pdai.tech/md/db/nosql-redis/db-redis-x-rdb-aof.html
(八):Redis 主从复制及数据恢复实践
概念
主从复制,是指将一台 Redis 服务器的数据,复制到其他的 Redis 服务器。前者称之为主节点(master/leader),后者称之为从节点(slave/flower);数据的复制都是单向的,只能从主节点到从节点。Master 以写为主,Slave 以读为主。
默认情况下,每台 Redis 服务器都是主节点。且一个主节点可以有多个从节点或者没有从节点,但是一个从节点只能有一个主节点。
主从复制的作用
1、数据冗余 :主从复制实现了数据的热备份,是持久化的之外的一种数据冗余方式。
2、故障恢复 :当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复。实际也是一种服务的冗余。
3、负载均衡 :在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写 Redis 数据时应用连接主节点,读 Redis 的时候应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个节点分担读负载,可以大大提高 Redis 服务器的并发量。
4、高可用(集群)的基石 :除了上述作用以外,主从复制还是哨兵模式和集群能够实施的基础,因此说主从复制是 Redis 高可用的基础。
一般来说,要将Redis 运用于工程项目中, 只使用一台 Redis 是万万不能的(可能会宕机),原因如下:
1、从结构上,单个 Redis 服务器会发生单点故障,并且一台服务器需要处理所有的请求负载,压力很大;
2、从容量上,单个 Redis 服务器内存容量有限,就算一台 Redis 服务器内存容量为 265G, 也不能将所有的内存用作 Redis 存储内存,一般来说, 单台 Redis最大使用内存不应该超过 20G。
电商网站上的商品,一般都是一次上传,无数次浏览的,说专业点就是“ 多读少写 ”。
对于这种场景,我们可以使用如下这种架构:
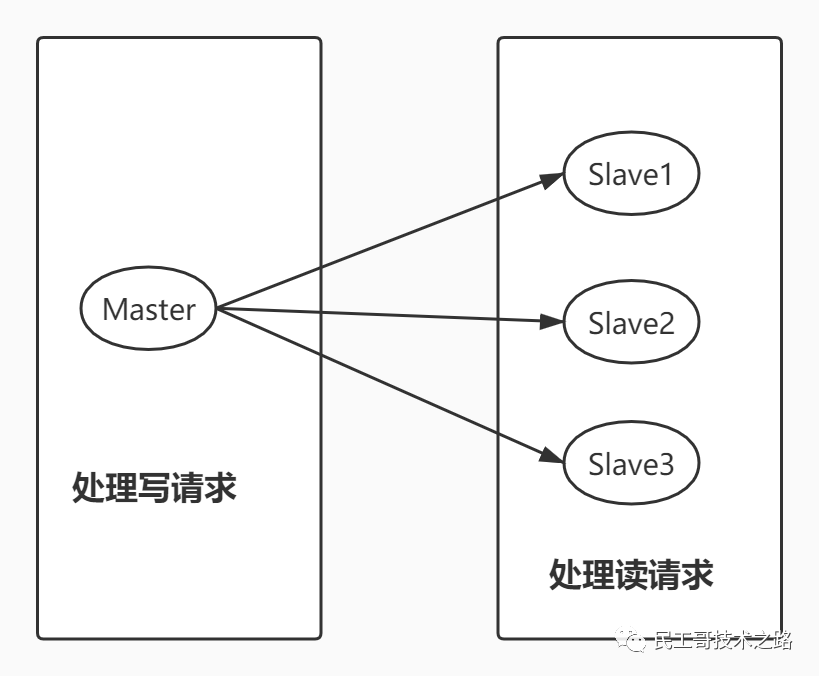
主从复制,读写分离 !80% 的情况下,都是在进行读操作。这种架构可以减少服务器压力,经常使用实际生产环境中, 最少是“一主二从”的配置 。真实环境中不可能使用单机 Redis。
主从复制原理
注意:在2.8版本之前只有全量复制,而2.8版本后有全量和增量复制:
- 全量(同步)复制 :比如第一次同步时
- 增量(同步)复制 :只会把主从库网络断连期间主库收到的命令,同步给从库
全量复制
当我们启动多个 Redis 实例的时候,它们相互之间就可以通过 replicaof(Redis 5.0 之前使用 slaveof)命令形成主库和从库的关系,之后会按照三个阶段完成数据的第一次同步。
确立主从关系
例如,现在有实例 1(ip:172.16.19.3)和实例 2(ip:172.16.19.5),我们在实例 2 上执行以下这个命令后,实例 2 就变成了实例 1 的从库,并从实例 1 上复制数据:
replicaof 172.16.19.3 6379
全量复制的三个阶段
你可以先看一下下面这张图,有个整体感知,接下来我再具体介绍。

第一阶段是主从库间建立连接、协商同步的过程 ,主要是为全量复制做准备。在这一步,从库和主库建立起连接,并告诉主库即将进行同步,主库确认回复后,主从库间就可以开始同步了。
具体来说,从库给主库发送 psync 命令,表示要进行数据同步,主库根据这个命令的参数来启动复制。psync 命令包含了主库的 runID 和复制进度 offset 两个参数。runID,是每个 Redis 实例启动时都会自动生成的一个随机 ID,用来唯一标记这个实例。当从库和主库第一次复制时,因为不知道主库的 runID,所以将 runID 设为“?”。offset,此时设为 -1,表示第一次复制。主库收到 psync 命令后,会用 FULLRESYNC 响应命令带上两个参数:主库 runID 和主库目前的复制进度 offset,返回给从库。从库收到响应后,会记录下这两个参数。这里有个地方需要注意,FULLRESYNC 响应表示第一次复制采用的全量复制,也就是说,主库会把当前所有的数据都复制给从库。更多关于 Redis 学习的文章,请参阅:NoSQL 数据库系列之 Redis ,本系列持续更新中。
第二阶段,主库将所有数据同步给从库。 从库收到数据后,在本地完成数据加载。这个过程依赖于内存快照生成的 RDB 文件。
具体来说,主库执行 bgsave 命令,生成 RDB 文件,接着将文件发给从库。从库接收到 RDB 文件后,会先清空当前数据库,然后加载 RDB 文件。这是因为从库在通过 replicaof 命令开始和主库同步前,可能保存了其他数据。为了避免之前数据的影响,从库需要先把当前数据库清空。在主库将数据同步给从库的过程中,主库不会被阻塞,仍然可以正常接收请求。否则,Redis 的服务就被中断了。但是,这些请求中的写操作并没有记录到刚刚生成的 RDB 文件中。为了保证主从库的数据一致性,主库会在内存中用专门的 replication buffer,记录 RDB 文件生成后收到的所有写操作。
第三个阶段,主库会把第二阶段执行过程中新收到的写命令,再发送给从库。 具体的操作是,当主库完成 RDB 文件发送后,就会把此时 replication buffer 中的修改操作发给从库,从库再重新执行这些操作。这样一来,主从库就实现同步了。
增量复制
在 Redis 2.8 版本引入了增量复制。
为什么会设计增量复制?
如果主从库在命令传播时出现了网络闪断,那么,从库就会和主库重新进行一次全量复制,开销非常大。 从 Redis 2.8 开始,网络断了之后,主从库会采用增量复制的方式继续同步。
增量复制的流程
你可以先看一下下面这张图,有个整体感知,接下来我再具体介绍。
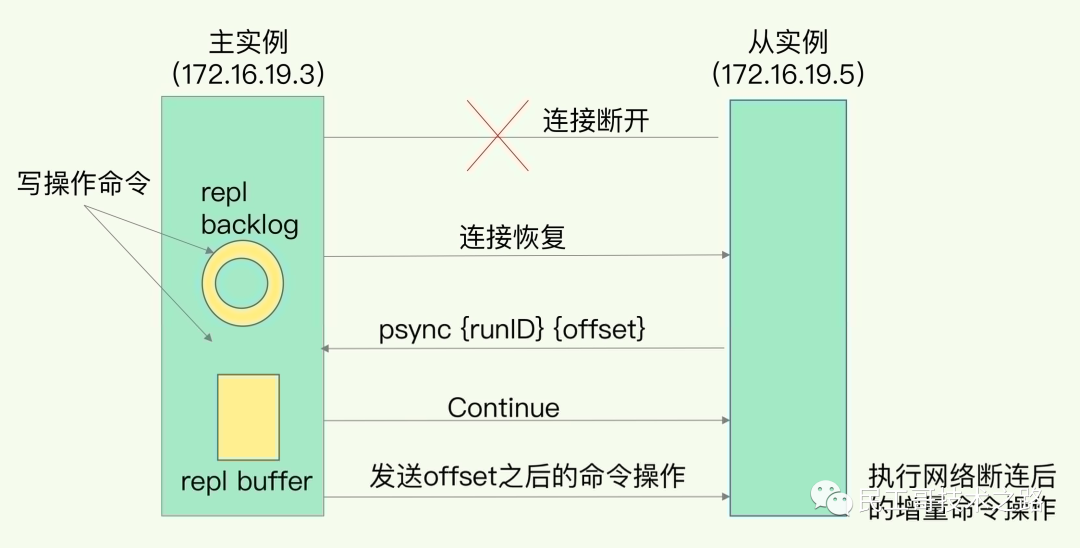
先看两个概念: replication buffer 和 repl_backlog_buffer
-
repl_backlog_buffer :它是为了从库断开之后,如何找到主从差异数据而设计的环形缓冲区,从而避免全量复制带来的性能开销。如果从库断开时间太久,repl_backlog_buffer环形缓冲区被主库的写命令覆盖了,那么从库连上主库后只能乖乖地进行一次全量复制,所以repl_backlog_buffer配置尽量大一些,可以降低主从断开后全量复制的概率。而在repl_backlog_buffer中找主从差异的数据后,如何发给从库呢?这就用到了replication buffer。
-
replication buffer :Redis和客户端通信也好,和从库通信也好,Redis都需要给分配一个 内存buffer进行数据交互,客户端是一个client,从库也是一个client,我们每个client连上Redis后,Redis都会分配一个client buffer,所有数据交互都是通过这个buffer进行的:Redis先把数据写到这个buffer中,然后再把buffer中的数据发到client socket中再通过网络发送出去,这样就完成了数据交互。所以主从在增量同步时,从库作为一个client,也会分配一个buffer,只不过这个buffer专门用来传播用户的写命令到从库,保证主从数据一致,我们通常把它叫做replication buffer。
如果在网络断开期间,repl_backlog_size环形缓冲区写满之后,从库是会丢失掉那部分被覆盖掉的数据,还是直接进行全量复制呢?
对于这个问题来说, 有两个关键点:
1.一个从库如果和主库断连时间过长,造成它在主库repl_backlog_buffer的slave_repl_offset位置上的数据已经被覆盖掉了,此时从库和主库间将进行全量复制。
2.每个从库会记录自己的slave_repl_offset,每个从库的复制进度也不一定相同。在和主库重连进行恢复时,从库会通过psync命令把自己记录的slave_repl_offset发给主库,主库会根据从库各自的复制进度,来决定这个从库可以进行增量复制,还是全量复制。
Redis 主从复制部署实践
环境配置
只配置从库,不用配置主库。
[root@xxx bin]# redis-cli -p 6379
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> info replication # 查看当前库的信息
# Replication
role:master # 角色
connected_slaves:0 # 当前没有从库
master_replid:2467dd9bd1c252ce80df280c925187b3417055ad
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6379>
复制 3 个配置文件,然后修改对应的信息
1、端口
2、pid 名称
3、log 文件名称
4、dump.rdb 名称
port 6381
pidfile /var/run/redis_6381.pid
logfile "6381.log"
dbfilename dump6381.rdb
修改完毕后,启动我们的 3 个 redis 服务器,可以通过进程信息查询。
[root@xxx ~]# ps -ef|grep redis
root 426 1 0 16:53 ? 00:00:00 redis-server *:6379
root 446 1 0 16:54 ? 00:00:00 redis-server *:6380
root 457 1 0 16:54 ? 00:00:00 redis-server *:6381
root 464 304 0 16:54 pts/3 00:00:00 grep --color=auto redis
一主二从环境
默认情况下,每台 Redis 服务器都是主节点,我们一般情况下,只用配置从机就好了。
主机:6379, 从机:6380 和 6381
配置的方式有两种:一种是直接使用命令配置,这种方式当 Redis 重启后配置会失效。另一种方式是使用配置文件。这里使用命令演示一下。
下面将80 和 81 两个配置为在从机。
127.0.0.1:6380> SLAVEOF 127.0.0.1 6379 # SLAVEOF host port
OK
127.0.0.1:6380> info replication
# Replication
role:slave # 角色已经是从机了
master_host:127.0.0.1 # 主节点地址
master_port:6379 # 主节点端口
master_link_status:up
master_last_io_seconds_ago:6
master_sync_in_progress:0
slave_repl_offset:0
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:907bcdf00c69d361ede43f4f6181004e2148efb7
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:0
127.0.0.1:6380>
配置好了之后,看主机:
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2 # 主节点下有两个从节点
slave0:ip=127.0.0.1,port=6380,state=online,offset=420,lag=1
slave1:ip=127.0.0.1,port=6381,state=online,offset=420,lag=1
master_replid:907bcdf00c69d361ede43f4f6181004e2148efb7
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:420
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:420
127.0.0.1:6379>
真实的主从配置应该是在配置文件中配置,这样才是永久的。这里使用命令是暂时的。
配置文件 redis.conf
################################# REPLICATION #################################
# Master-Replica replication. Use replicaof to make a Redis instance a copy of
# another Redis server. A few things to understand ASAP about Redis replication.
#
# +------------------+ +---------------+
# | Master | ---> | Replica |
# | (receive writes) | | (exact copy) |
# +------------------+ +---------------+
#
# 1) Redis replication is asynchronous, but you can configure a master to
# stop accepting writes if it appears to be not connected with at least
# a given number of replicas.
# 2) Redis replicas are able to perform a partial resynchronization with the
# master if the replication link is lost for a relatively small amount of
# time. You may want to configure the replication backlog size (see the next
# sections of this file) with a sensible value depending on your needs.
# 3) Replication is automatic and does not need user intervention. After a
# network partition replicas automatically try to reconnect to masters
# and resynchronize with them.
#
# replicaof <masterip> <masterport> # 这里配置
# If the master is password protected (using the "requirepass" configuration
# directive below) it is possible to tell the replica to authenticate before
# starting the replication synchronization process, otherwise the master will
# refuse the replica request.
#
# masterauth <master-password>
配置方式也是一样的。
几个问题
1、主机可以写,从机不能写只能读。主机中的所有信息和数据都会保存在从机中。如果从机尝试进行写操作就会报错。
127.0.0.1:6381> get k1 # k1的值是在主机中写入的,从机中可以读取到。
“v1”
127.0.0.1:6381> set k2 v2 # 从机尝试写操作,报错了
(error) READONLY You can’t write against a read only replica.
127.0.0.1:6381>
2、如果主机断开了,从机依然链接到主机,可以进行读操作,但是还是没有写操作。这个时候,主机如果恢复了,从机依然可以直接从主机同步信息。
3、使用命令行配置的主从机,如果从机重启了,就会变回主机。如果再通过命令变回从机的话,立马就可以从主机中获取值。这是复制原理决定的。
复制的两种模式
Slave 启动成功连接到 Master 后会发送一个 sync 同步命令。
Master 接收到命令后,启动后台的存盘进程,同时收集所有接收到的用于修改数据集的命令,在后台进程执行完毕后,master 将传送整个数据文件到 slave ,并完成一次完全同步。
但是只要重新连接 master ,一次完全同步(全量复制)将被自动执行。我们的数据一定可以在从机中看到。
这种模式的原理图:
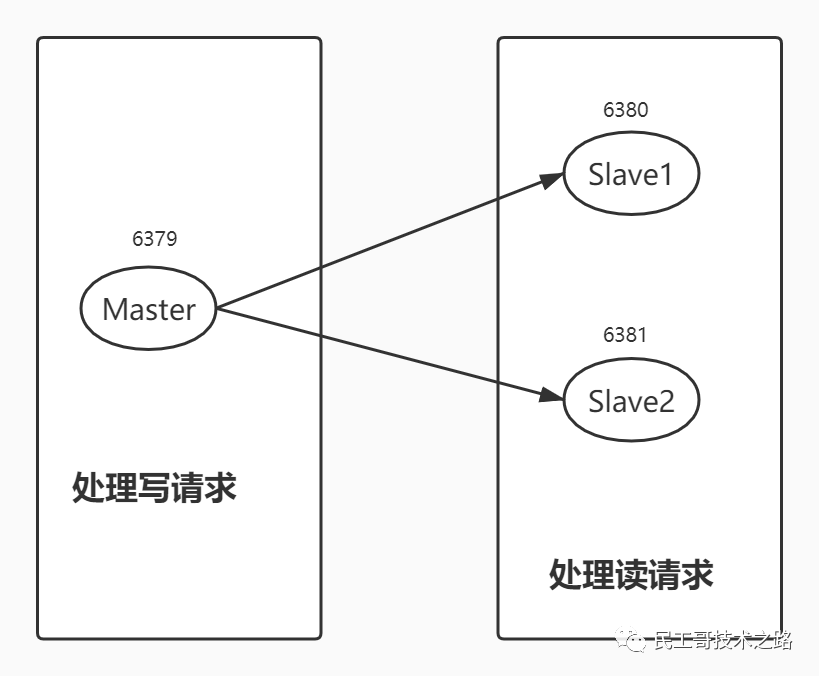
第二种模式
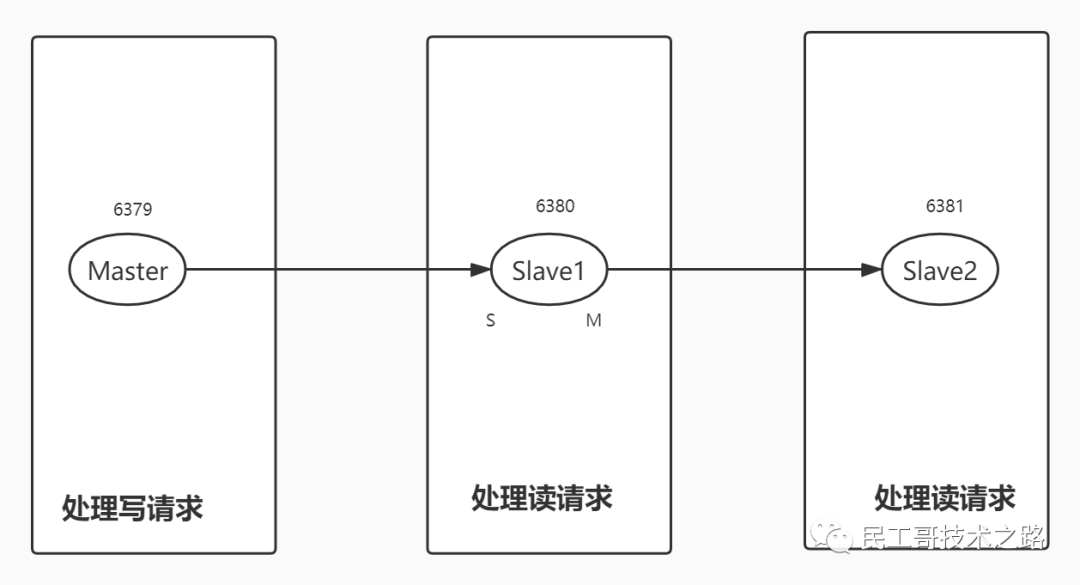
这种模式的话,将 6381 的主节点配置为 6380 。主节点 6379 只有一个从机。
如果现在 6379 节点宕机了, 6380 和 6381 节点都是从节点,只能进行读操作,都不会自动变为主节点。需要手动将其中一个变为主节点,使用如下命令:
SLAVEOF no one
redis主从复制危险操作
使用热更新配置误操作
redis主从复制如果使用热更新配置,有时候会因为选错主机把从库误认为主库,结果在主库上执行了 slaveof ,这样就会导致主库上的数据被清空,因为从库上是没有数据的。
从库在同步主库的时候会把原本自己的数据全部清空。
误操作过程
#从库数据为0
127.0.0.1:6379> DBSIZE
(integer) 0
#主库数据为2001
127.0.0.1:6379> DBSIZE
(integer) 2001
#在主库上操作同步本该从库的数据
127.0.0.1:6379> SLAVEOF 192.168.81.220 6379
OK
#再次查看数据,数据已经清空
127.0.0.1:6379> DBSIZE
(integer) 0
避免热更新配置误操作
1.不使用热更新,直接在配置文件里配置主从。
2.在执行slaveof的时候先执行bgsave,把数据手动备份一下,然后在数据目录,将rdb文件复制成另一个文件,做备份,这样即使出现问题也能即使恢复。
bgsave之后不用重启,直接备份rdb文件即可。
#手动持久化
127.0.0.1:6379> BGSAVE
Background saving started
#备份rdb文件
[root@redis-1 ~]# cd /data/redis_cluster/redis_6379/
[root@redis-1 /data/redis_cluster/redis_6379]# cd data/
[root@redis-1 /data/redis_cluster/redis_6379/data]# cp redis_6379.rdb redis_6379.rdb.bak
#再次同步错误的主库,造成数据丢失
127.0.0.1:6379> SLAVEOF 192.168.81.220 6379
OK
127.0.0.1:6379> keys *
(empty list or set)
#还原备份的rdb文件,先停掉redis,在还原
[root@redis-1 ~]# redis-cli shutdown
[root@redis-1 /data/redis_cluster/redis_6379/data]# cp redis_6379.rdb.bak redis_6379.rdb
#查看还原后的数据
[root@redis-1 ~]# redis-server /data/redis_cluster/redis_6379/conf/redis_6379.conf
127.0.0.1:6379> DBSIZE
(integer) 2001
模拟 redis 主从复制错误数据恢复
模拟 redis 主从同步误操作数据恢复。
大致思路
1.清空两台redis的数据
2.在主库上创建一些数据,然后使用bgsave命令,将数据保存到磁盘,再将磁盘的rdb文件备份
3.再将从库的数据同步过来,模拟主库数据丢失
4.从rdb备份文件还原数据库
这个实验的主要的目的是操作redis备份还原。
清空数据
两台redis都需要操作,先关闭再删除数据再启动。
[root@redis-1 ~]# redis-cli shutdown
[root@redis-1 ~]# rm -rf /data/redis_cluster/redis_6379/data/*
[root@redis-1 ~]# redis-server /data/redis_cluster/redis_6379/conf/redis_6379.conf
[root@redis-1 ~]# redis-cli
127.0.0.1:6379> keys *
(empty list or set)
在主库批量创建数据并备份
#批量创建数据
[root@redis-1 ~]# for i in {0..2000}; do redis-cli set k_${i} v_${i}; echo "k_${i} is ok"; done
127.0.0.1:6379> DBSIZE
(integer) 2001
#将近数据写入到
127.0.0.1:6379> BGSAVE
Background saving started
#备份rdb文件
[root@redis-1 /data/redis_cluster/redis_6379/data]# cp redis_6379.rdb redis_6379.rdb.bak
[root@redis-1 /data/redis_cluster/redis_6379/data]# ll
总用量 56
-rw-r--r--. 1 root root 27877 1月 28 21:00 redis_6379.rdb
-rw-r--r--. 1 root root 27877 1月 28 21:01 redis_6379.rdb.bak
同步从库的数据造成数据丢失
这时从库的数据应该是空的。
[root@redis-2 ~]# redis-cli
127.0.0.1:6379> keys *
(empty list or set)
主库同步从库的数据,同步完主库数据丢失,这样就模拟了主库数据丢失的情况。
127.0.0.1:6379> SLAVEOF 192.168.81.220 6379
OK
127.0.0.1:6379> keys *
(empty list or set)
恢复主库的数据
先关掉redis,还原,最后在开启redis。
#关掉redis
[root@redis-1 ~]# redis-cli shutdown
#还原rdb备份文件
[root@redis-1 /data/redis_cluster/redis_6379/data]# cp redis_6379.rdb.bak redis_6379.rdb
cp:是否覆盖"redis_6379.rdb"?y
#启动redis
[root@redis-1 ~]# redis-server /data/redis_cluster/redis_6379/conf/redis_6379.conf
#查看数据是否还原
[root@redis-1 ~]# redis-cli
127.0.0.1:6379> keys *

模拟线上环境主库宕机故障恢复
思路
1.首先保证主从同步已经配置完成,主库从库都有数据
2.关闭redis主库,模拟redis主库宕机
3.查看redis从库是否还存在数据,是否可读可写(不能写,只能读)
4.关闭从库的slaveof,停止主从同步,将应用连接redis的地址改成从库,保证业务不断
5.修复主库,主库上线后,与从库建立主从复制关系,原来的从库(redis-2)就变成了主库,现在的主库变成了从库(redis-1)这时 关掉应用程序,停止数据写入
6.然后将现在主库(redis-2)的数据同步到现在的从库(redis-1)
7.关闭现在从库(redis-1)的slaveof,停止主从复制,然后将现在主库(redis-2)配置salveof,同步原来的主库(redis-1)
8.数据同步完,原来的主库从库就恢复完毕了
简单明了的一句话: 主库因为某种原因宕机无法提供服务了,直接将从库切换成主库提供服务,然后后原来的主库恢复后同步当前主库的数据,然后停掉所有线上运行的程序,将现在的主库去同步恢复后的主库,重新生成主从关系。
配置主从模拟线上环境
配置主从前先保证主库上面有数据
#登陆主库redis-1查看是否有数据
[root@redis-1 ~]# redis-cli
127.0.0.1:6379> DBSIZE
(integer) 2001
#登陆从库redis-2查看是否有数据
[root@redis-2 ~]# redis-cli
127.0.0.1:6379> keys *
(empty list or set)
#从库没有数据的情况下在从库上配置主从,同步主库的数据
127.0.0.1:6379> SLAVEOF 192.168.81.210 6379
OK
#数据已经同步
127.0.0.1:6379> DBSIZE
(integer) 2001
模拟主库宕机验证从库是否可读写
#直接关掉主库,造成宕机
[root@redis-1 ~]# redis-cli shutdown
#查看从库是否可读写
只能读,不能写
[root@redis-2 ~]# redis-cli get k_1
"v_1"
[root@redis-2 ~]# redis-cli set k999 k_1
(error) READONLY You can't write against a read only slave.
主库一宕机,从库就会一直输出日志提示连接不上主库
关闭从库的主从复制保证业务的不间断
现在主库是不可用的,从库也只能读不能写,但是数据只有这么一份了,我们只能关闭从库上的主从复制,让从库变成主库,再配置业务的redis地址,首先要保证业务的不中断
#关闭从库redis-2的主从同步配置,使其成为主库
[root@redis-2 ~]# redis-cli slaveof no one
OK
#将应用的redis地址修改为从库,只要从库关掉了主从配置,他自己就是一个可读可写的库了,库里有故障前的所有数据,可以先保证业务的不间断
修复故障的主库同步原来从库的数据
修复完主库,已经是有数据的了,为什么还要同步从库的数据呢,因为在主库挂掉的那一瞬间,从库去掉了主从配置,自己已经成了主库,并且也提供了一段时间的数据写入,这时从库的数据时最完整的。
同步现在主库(原来的从库)的数据时,先要将应用关掉,不要在往里写数据了
在主库(原来的从库上)写入几个新的数据,模拟产生的新数据
[root@redis-2 ~]# redis-cli
127.0.0.1:6379> set zuixinshujv vvvvv
OK
在重新上线的主库上配置主从同步,使自己变成从库,同步主库的(原来的从库)数据
同步之后,现在从库(重新修复的主库已经有最新数据了)
同步之前先将应用停掉,不要再往redis中写数据
[root@redis-1 ~]# redis-cli
127.0.0.1:6379> SLAVEOF 192.168.81.220 6379
OK
127.0.0.1:6379> get zuixinshujv
"vvvvv"
从库重新上线为主库
这里的从库重新上线指的就是原来故障的主库,现在已经同步到最新数据了,因此要上线成为主库,之前选他作为主库就是因为他的性能比从库各方面都要高,避免将来因为性能再次发生故障,因此要切换
#关闭从库(原来的主库)的主从配置
[root@redis-1 ~]# redis-cli
127.0.0.1:6379> SLAVEOF no one
OK
#在主库(原来的从库)配置主从复制
[root@redis-2 ~]# redis-cli
127.0.0.1:6379> SLAVEOF 192.168.81.210 6379
OK
将应用的redis地址再次修改为主库的地址
目前主库已经恢复了,并且主从之前重新建立了主从同步关系,现在就可以把应用的redis地址修改为主库,启动应用就可以了。
更深入理解 Redis 主从复制
我们通过几个问题来深入理解主从复制。
当主服务器不进行持久化时复制的安全性
在进行主从复制设置时,强烈建议在主服务器上开启持久化,当不能这么做时,比如考虑到延迟的问题,应该将实例配置为避免自动重启。
为什么不持久化的主服务器自动重启非常危险呢?
为了更好的理解这个问题,看下面这个失败的例子,其中主服务器和从服务器中数据库都被删除了。
- 我们设置节点A为主服务器,关闭持久化,节点B和C从节点A复制数据。
- 这时出现了一个崩溃,但Redis具有自动重启系统,重启了进程,因为关闭了持久化,节点重启后只有一个空的数据集。
- 节点B和C从节点A进行复制,现在节点A是空的,所以节点B和C上的复制数据也会被删除。
- 当在高可用系统中使用Redis Sentinel,关闭了主服务器的持久化,并且允许自动重启,这种情况是很危险的。比如主服务器可能在很短的时间就完成了重启,以至于Sentinel都无法检测到这次失败,那么上面说的这种失败的情况就发生了。
- 如果数据比较重要,并且在使用主从复制时关闭了主服务器持久化功能的场景中,都应该禁止实例自动重启。
为什么全量复制使用RDB而不使用AOF?
1、RDB文件内容是经过压缩的二进制数据(不同数据类型数据做了针对性优化),文件很小。而AOF文件记录的是每一次写操作的命令,写操作越多文件会变得很大,其中还包括很多对同一个key的多次冗余操作。在主从全量数据同步时,传输RDB文件可以尽量降低对主库机器网络带宽的消耗,从库在加载RDB文件时,一是文件小,读取整个文件的速度会很快,二是因为RDB文件存储的都是二进制数据,从库直接按照RDB协议解析还原数据即可,速度会非常快,而AOF需要依次重放每个写命令,这个过程会经历冗长的处理逻辑,恢复速度相比RDB会慢得多,所以使用RDB进行主从全量复制的成本最低。
2、假设要使用AOF做全量复制,意味着必须打开AOF功能,打开AOF就要选择文件刷盘的策略,选择不当会严重影响Redis性能。而RDB只有在需要定时备份和主从全量复制数据时才会触发生成一次快照。而在很多丢失数据不敏感的业务场景,其实是不需要开启AOF的。
为什么还有无磁盘复制模式?
Redis 默认是磁盘复制,但是如果使用比较低速的磁盘,这种操作会给主服务器带来较大的压力。Redis从2.8.18版本开始尝试支持无磁盘的复制。使用这种设置时,子进程直接将RDB通过网络发送给从服务器,不使用磁盘作为中间存储。
无磁盘复制模式:master 创建一个新进程直接 dump RDB 到slave的socket,不经过主进程,不经过硬盘。适用于disk较慢,并且网络较快的时候。
使用repl-diskless-sync配置参数来启动无磁盘复制。
使用repl-diskless-sync-delay 参数来配置传输开始的延迟时间;master等待一个repl-diskless-sync-delay的秒数,如果没slave来的话,就直接传,后来的得排队等了; 否则就可以一起传。
为什么还会有从库的从库的设计?
通过分析主从库间第一次数据同步的过程,你可以看到,一次全量复制中,对于主库来说,需要完成两个耗时的操作:生成 RDB 文件和传输 RDB 文件。
如果从库数量很多,而且都要和主库进行全量复制的话,就会导致主库忙于 fork 子进程生成 RDB 文件,进行数据全量复制。fork 这个操作会阻塞主线程处理正常请求,从而导致主库响应应用程序的请求速度变慢。此外,传输 RDB 文件也会占用主库的网络带宽,同样会给主库的资源使用带来压力。那么,有没有好的解决方法可以分担主库压力呢?
其实是有的,这就是“ 主 - 从 - 从” 模式。
在刚才介绍的主从库模式中,所有的从库都是和主库连接,所有的全量复制也都是和主库进行的。现在,我们可以通过“主 - 从 - 从”模式将主库生成 RDB 和传输 RDB 的压力,以级联的方式分散到从库上。
简单来说,我们在部署主从集群的时候,可以手动选择一个从库(比如选择内存资源配置较高的从库),用于级联其他的从库。然后,我们可以再选择一些从库(例如三分之一的从库),在这些从库上执行如下命令,让它们和刚才所选的从库,建立起主从关系。
replicaof 所选从库的IP 6379
这样一来,这些从库就会知道,在进行同步时,不用再和主库进行交互了,只要和级联的从库进行写操作同步就行了,这就可以减轻主库上的压力,如下图所示:
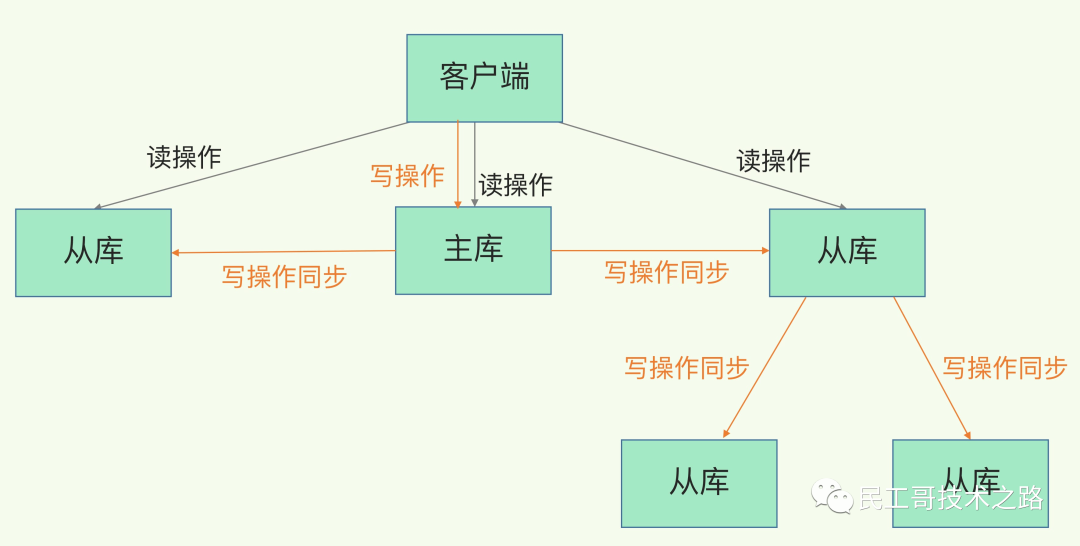
级联的“主-从-从”模式好了,到这里,我们了解了主从库间通过全量复制实现数据同步的过程,以及通过“主 - 从 - 从”模式分担主库压力的方式。那么,一旦主从库完成了全量复制,它们之间就会一直维护一个网络连接,主库会通过这个连接将后续陆续收到的命令操作再同步给从库,这个过程也称为基于长连接的命令传播,可以避免频繁建立连接的开销。
读写分离及其中的问题
在主从复制基础上实现的读写分离,可以实现Redis的读负载均衡:由主节点提供写服务,由一个或多个从节点提供读服务(多个从节点既可以提高数据冗余程度,也可以最大化读负载能力);在读负载较大的应用场景下,可以大大提高Redis服务器的并发量。下面介绍在使用Redis读写分离时,需要注意的问题。
延迟与不一致问题
前面已经讲到,由于主从复制的命令传播是异步的,延迟与数据的不一致不可避免。如果应用对数据不一致的接受程度程度较低,可能的优化措施包括:优化主从节点之间的网络环境(如在同机房部署);监控主从节点延迟(通过offset)判断,如果从节点延迟过大,通知应用不再通过该从节点读取数据;使用集群同时扩展写负载和读负载等。
在命令传播阶段以外的其他情况下,从节点的数据不一致可能更加严重,例如连接在数据同步阶段,或从节点失去与主节点的连接时等。从节点的slave-serve-stale-data参数便与此有关:它控制这种情况下从节点的表现;如果为yes(默认值),则从节点仍能够响应客户端的命令,如果为no,则从节点只能响应info、slaveof等少数命令。该参数的设置与应用对数据一致性的要求有关;如果对数据一致性要求很高,则应设置为no。
数据过期问题
在单机版Redis中,存在两种删除策略:
惰性删除 :服务器不会主动删除数据,只有当客户端查询某个数据时,服务器判断该数据是否过期,如果过期则删除。
定期删除 :服务器执行定时任务删除过期数据,但是考虑到内存和CPU的折中(删除会释放内存,但是频繁的删除操作对CPU不友好),该删除的频率和执行时间都受到了限制。
在主从复制场景下,为了主从节点的数据一致性,从节点不会主动删除数据,而是由主节点控制从节点中过期数据的删除。由于主节点的惰性删除和定期删除策略,都不能保证主节点及时对过期数据执行删除操作,因此,当客户端通过Redis从节点读取数据时,很容易读取到已经过期的数据。
Redis 3.2中,从节点在读取数据时,增加了对数据是否过期的判断:如果该数据已过期,则不返回给客户端;将Redis升级到3.2可以解决数据过期问题。
故障切换问题
在没有使用哨兵的读写分离场景下,应用针对读和写分别连接不同的Redis节点;当主节点或从节点出现问题而发生更改时,需要及时修改应用程序读写Redis数据的连接;连接的切换可以手动进行,或者自己写监控程序进行切换,但前者响应慢、容易出错,后者实现复杂,成本都不算低。
总结
在使用读写分离之前,可以考虑其他方法增加Redis的读负载能力:如尽量优化主节点(减少慢查询、减少持久化等其他情况带来的阻塞等)提高负载能力;使用Redis集群同时提高读负载能力和写负载能力等。如果使用读写分离,可以使用哨兵,使主从节点的故障切换尽可能自动化,并减少对应用程序的侵入。
参考文章:
https://jiangxl.blog.csdn.net/article/details/120646992
https://www.cnblogs.com/itzhouq/p/redis5.html
https://www.pdai.tech/md/db/nosql-redis/db-redis-x-copy.html
(九):Redis sentinel 集群原理部署及数据恢复
在上文主从复制的基础上,如果主节点出现故障该怎么办呢?在 Redis 主从集群中,哨兵机制是实现主从库自动切换的关键机制,它有效地解决了主从复制模式下故障转移的问题。
哨兵机制(Redis Sentinel)
Redis Sentinel,即 Redis 哨兵,在 Redis 2.8 版本开始引入。哨兵的核心功能是主节点的自动故障转移。
下图是一个典型的哨兵集群监控的逻辑图:
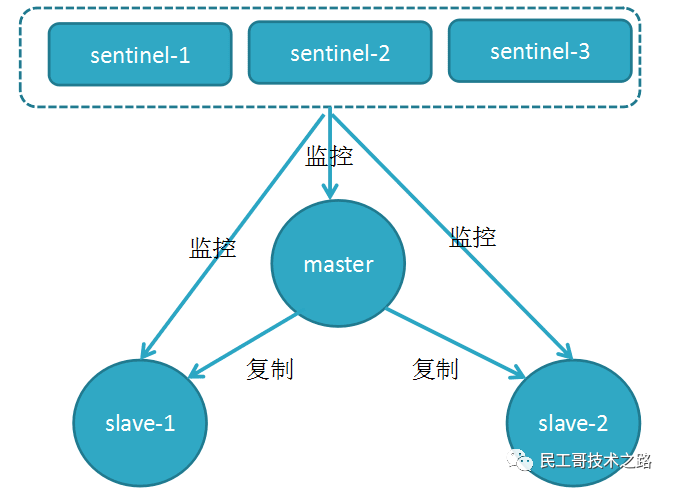
哨兵实现了什么功能呢?
下面是Redis官方文档的描述:
- 监控(Monitoring) :哨兵会不断地检查主节点和从节点是否运作正常。
- 自动故障转移(Automatic failover) :当主节点不能正常工作时,哨兵会开始自动故障转移操作,它会将失效主节点的其中一个从节点升级为新的主节点,并让其他从节点改为复制新的主节点。
- 配置提供者(Configuration provider) :客户端在初始化时,通过连接哨兵来获得当前Redis服务的主节点地址。
- 通知(Notification) :哨兵可以将故障转移的结果发送给客户端。
其中,监控和自动故障转移功能,使得哨兵可以及时发现主节点故障并完成转移;而配置提供者和通知功能,则需要在与客户端的交互中才能体现。
哨兵集群的组建
上图中哨兵集群是如何组件的呢?哨兵实例之间可以相互发现,要归功于 Redis 提供的 pub/sub 机制,也就是 发布/订阅 机制。
在主从集群中,主库上有一个名为 sentinel:hello 的频道,不同哨兵就是通过它来相互发现,实现互相通信的。在下图中,哨兵 1 把自己的 IP(172.16.19.3)和端口(26579)发布到 sentinel:hello 频道上,哨兵 2 和 3 订阅了该频道。那么此时,哨兵 2 和 3 就可以从这个频道直接获取哨兵 1 的 IP 地址和端口号。然后,哨兵 2、3 可以和哨兵 1 建立网络连接。
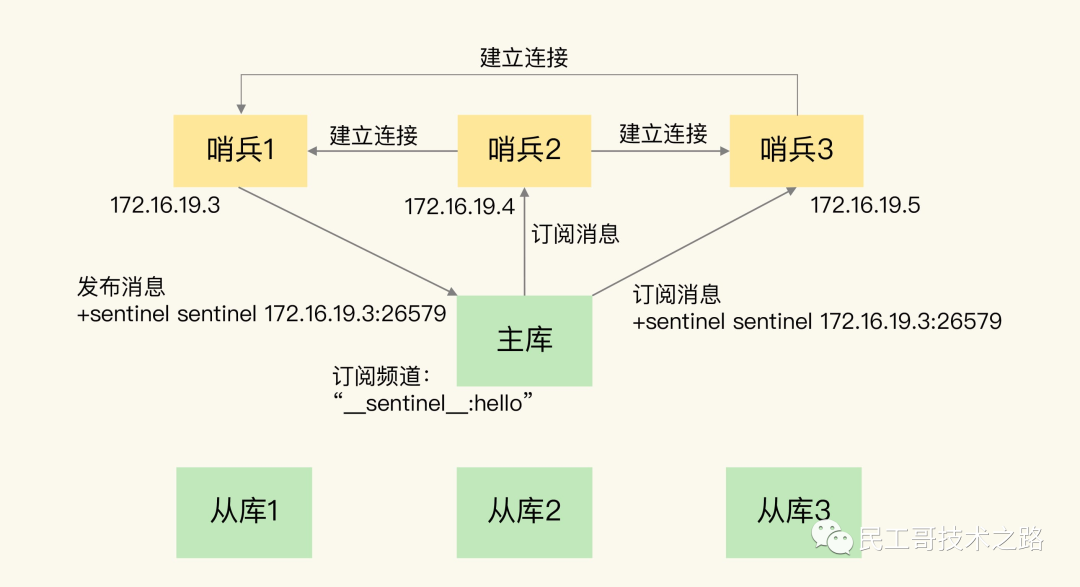
通过这个方式,哨兵 2 和 3 也可以建立网络连接,这样一来,哨兵集群就形成了。它们相互间可以通过网络连接进行通信,比如说对主库有没有下线这件事儿进行判断和协商。
哨兵监控 Redis 库
哨兵监控什么呢?怎么监控呢?
这是由哨兵向主库发送 INFO 命令来完成的。就像下图所示,哨兵 2 给主库发送 INFO 命令,主库接受到这个命令后,就会把从库列表返回给哨兵。接着,哨兵就可以根据从库列表中的连接信息,和每个从库建立连接,并在这个连接上持续地对从库进行监控。哨兵 1 和 3 可以通过相同的方法和从库建立连接。
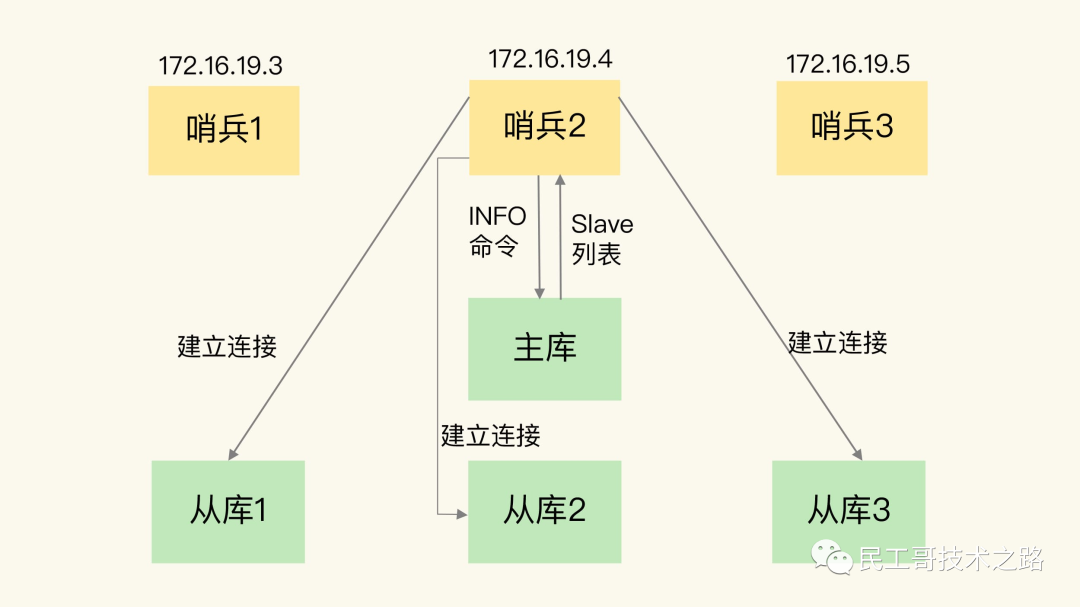
主库下线的判定
哨兵如何判断主库已经下线了呢?
首先要理解两个概念: 主观下线和客观下线
- 主观下线:任何一个哨兵都是可以监控探测,并作出Redis节点下线的判断;
- 客观下线:有哨兵集群共同决定Redis节点是否下线;
当某个哨兵(如下图中的哨兵2)判断主库“主观下线”后,就会给其他哨兵发送 is-master-down-by-addr 命令。接着,其他哨兵会根据自己和主库的连接情况,做出 Y 或 N 的响应,Y 相当于赞成票,N 相当于反对票。
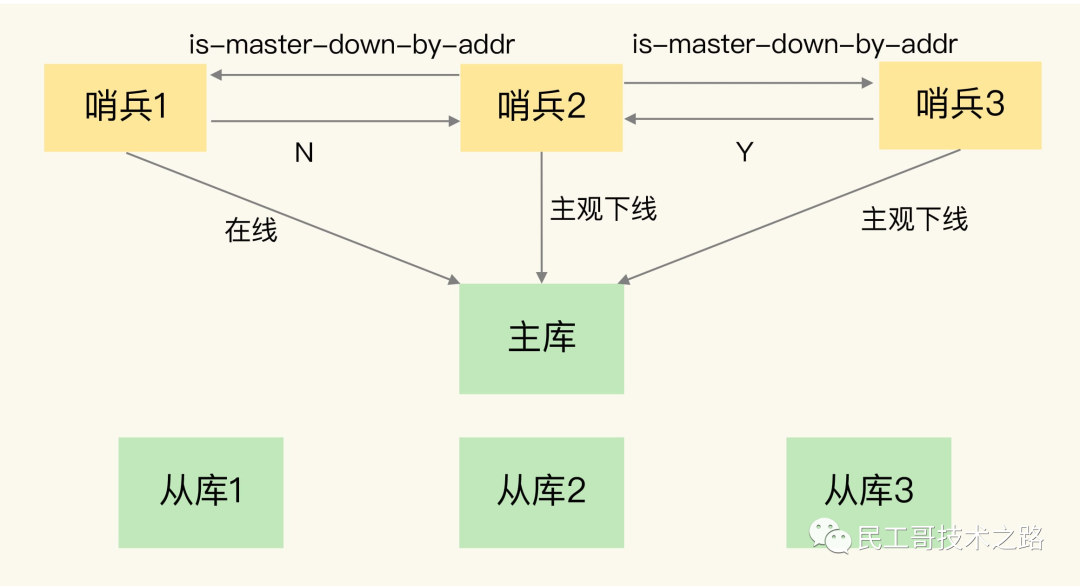
如果赞成票数(这里是2)是大于等于哨兵配置文件中的 quorum 配置项(比如这里如果是quorum=2), 则可以判定主库客观下线了。
哨兵集群的选举
判断完主库下线后,由哪个哨兵节点来执行主从切换呢?这里就需要哨兵集群的选举机制了。
为什么必然会出现选举/共识机制?
为了避免哨兵的单点情况发生,所以需要一个哨兵的分布式集群。作为分布式集群,必然涉及共识问题(即选举问题);同时故障的转移和通知都只需要一个主的哨兵节点就可以了。
哨兵的选举机制是什么样的?
哨兵的选举机制其实很简单,就是一个 Raft 选举算法: 选举的票数大于等于num(sentinels)/2+1时,将成为领导者,如果没有超过,继续选举
任何一个想成为 Leader 的哨兵,要满足两个条件:
第一,拿到半数以上的赞成票;
第二,拿到的票数同时还需要大于等于哨兵配置文件中的 quorum 值。
以 3 个哨兵为例,假设此时的 quorum 设置为 2,那么,任何一个想成为 Leader 的哨兵只要拿到 2 张赞成票,就可以了。
更进一步理解
这里很多人会搞混 判定客观下线 和 是否能够主从切换(用到选举机制) 两个概念,我们再看一个例子。
Redis 1主4从,5个哨兵,哨兵配置quorum为2,如果3个哨兵故障,当主库宕机时,哨兵能否判断主库“客观下线”?能否自动切换?
经过实际测试:
1、哨兵集群可以判定主库“主观下线”。 由于quorum=2,所以当一个哨兵判断主库“主观下线”后,询问另外一个哨兵后也会得到同样的结果,2个哨兵都判定“主观下线”,达到了quorum的值,因此,哨兵集群可以判定主库为“客观下线”。
2、但哨兵不能完成主从切换。 哨兵标记主库“客观下线后”,在选举“哨兵领导者”时,一个哨兵必须拿到超过多数的选票(5/2+1=3票)。但目前只有2个哨兵活着,无论怎么投票,一个哨兵最多只能拿到2票,永远无法达到N/2+1选票的结果。
新主库的选出
主库既然判定客观下线了,那么如何从剩余的从库中选择一个新的主库呢?
- 过滤掉不健康的(下线或断线),没有回复过哨兵ping响应的从节点
- 选择salve-priority从节点优先级最高(redis.conf)的
- 选择复制偏移量最大,只复制最完整的从节点
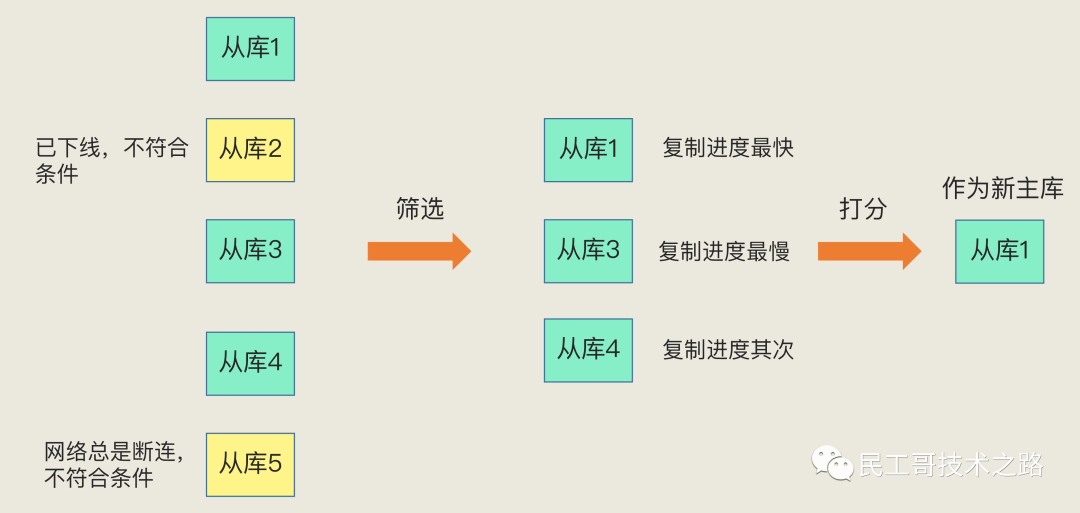
故障的转移
新的主库选择出来后,就可以开始进行故障的转移了。
假设根据我们一开始的图:(我们假设:判断主库客观下线了,同时选出sentinel 3是哨兵leader)
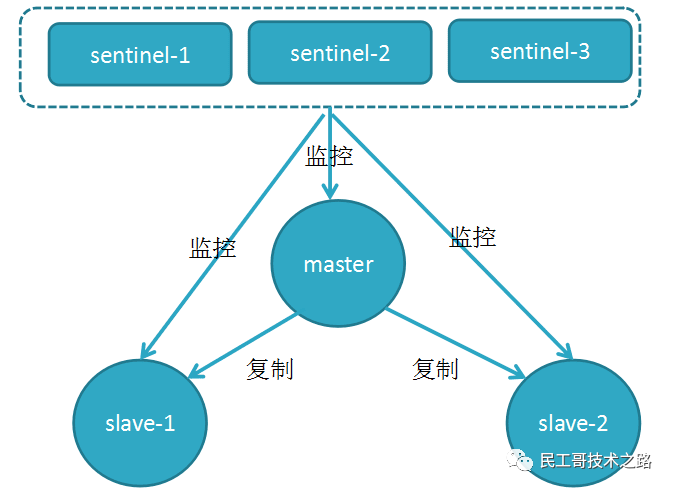
故障转移流程如下
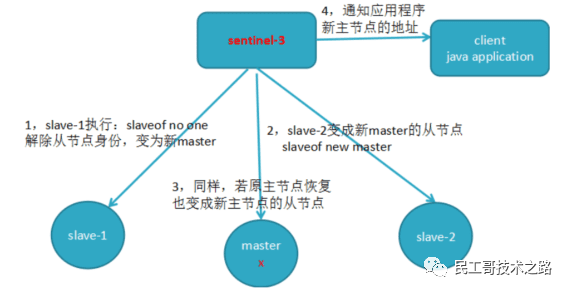
- 将slave-1脱离原从节点(PS: 5.0 中应该是replicaof no one),升级主节点,
- 将从节点slave-2指向新的主节点
- 通知客户端主节点已更换
- 将原主节点(oldMaster)变成从节点,指向新的主节点
转移之后
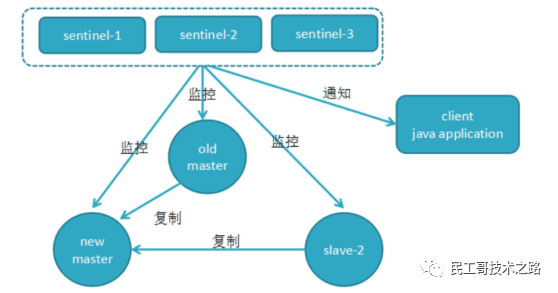
搭建redis哨兵集群
环境准备
配置哨兵集群步骤:
1.在所有节点搭建redis
2.配置主从复制,一主两从
3.在所有节点配置sentinel,启动sentinel后,配置文件会自动增加
在所有机器上部署redis
192.168.81.210配置
1.创建redis部署路径
[root@redis-1 ~]# mkdir -p /data/redis_cluster/redis_6379/{conf,pid,logs,data}
2.下载redis
[root@redis-1 ~]# mkdir /data/soft
[root@redis-1 ~]# cd /data/soft
[root@redis-1 /data/soft]# wget https://repo.huaweicloud.com/redis/redis-3.2.9.tar.gz
3.便于安装redis
[root@redis-1 /data/soft]# tar xf redis-3.2.9.tar.gz -C /data/redis_cluster/
[root@redis-1 /data/soft]# cd /data/redis_cluster/
[root@redis-1 /data/redis_cluster]# ln -s redis-3.2.9/ redis
[root@redis-1 /data/redis_cluster]# cd redis/src
[root@redis-1 /data/redis_cluster/redis]# make && make install
4.准备配置文件
[root@redis-1 ~]# vim /data/redis_cluster/redis_6379/conf/redis_6379.conf
daemonize yes
bind 192.168.81.210 127.0.0.1
port 6379
pidfile /data/redis_cluster/redis_6379/pid/redis_6379.pid
logfile /data/redis_cluster/redis_6379/logs/redis_6379.log
databases 16
dbfilename redis_6379.rdb
dir /data/redis_cluster/redis_6379/data/
save 900 1
save 300 100
save 60 10000
5.启动redis
[root@redis-1 ~]# redis-server /data/redis_cluster/redis_6379/conf/redis_6379.conf
192.168.81.220配置
由于redis-1已经部署好了一套redis,我们可以直接复制过来使用
1.使用rsync将redis-1的redis目录拷贝过来你
[root@redis-1 ~]# rsync -avz /data root@192.168.81.220:/
2.查看拷贝过来的目录文件
[root@redis-2 ~]# ls /data/redis_cluster/
redis redis-3.2.9 redis_6379
[root@redis-2 ~]# ls /data/redis_cluster/redis_6379/
conf data logs pid
3.编译安装redis,使系统能使用redis命令
直接执行make install即可,因为编译步骤在redis-1已经做了
[root@redis-2 ~]# cd /data/redis_cluster/redis-3.2.9/
[root@redis-2 /data/redis_cluster/redis-3.2.9]# make install
4.修改redis配置文件
[root@redis-2 ~]# vim /data/redis_cluster/redis_6379/conf/redis_6379.conf
bind 192.168.81.220 127.0.0.1
5.启动redis
[root@redis-2 ~]# redis-server /data/redis_cluster/redis_6379/conf/redis_6379.conf
192.168.81.230配置
由于redis-1已经部署好了一套redis,我们可以直接复制过来使用
1.使用rsync将redis-1的redis目录拷贝过来你
[root@redis-1 ~]# rsync -avz /data root@192.168.81.230:/
2.查看拷贝过来的目录文件
[root@redis-3 ~]# ls /data/redis_cluster/
redis redis-3.2.9 redis_6379
[root@redis-3 ~]# ls /data/redis_cluster/redis_6379/
conf data logs pid
3.编译安装redis,使系统能使用redis命令
直接执行make install即可,因为编译步骤在redis-1已经做了
[root@redis-3 ~]# cd /data/redis_cluster/redis-3.2.9/
[root@redis-3 /data/redis_cluster/redis-3.2.9]# make install
4.修改redis配置文件
[root@redis-3 ~]# vim /data/redis_cluster/redis_6379/conf/redis_6379.conf
bind 192.168.81.230 127.0.0.1
5.启动redis
[root@redis-3 ~]# redis-server /data/redis_cluster/redis_6379/conf/redis_6379.conf
三台redis部署完成
[root@redis-1 ~]# ps aux | grep redis
root 21860 0.1 0.5 139020 9740 ? Ssl 09:36 0:16 redis-server 192.168.81.210:6379
root 25296 0.0 0.0 112724 984 pts/0 S+ 13:15 0:00 grep --color=auto redis
[root@redis-1 ~]# ssh 192.168.81.220 "ps aux | grep redis"
root 47658 0.1 0.5 141068 10780 ? Ssl 1月28 1:24 redis-server 192.168.81.220:6379
root 63254 0.0 0.0 113176 1588 ? Ss 13:15 0:00 bash -c ps aux | grep redis
root 63271 0.0 0.0 112724 968 ? S 13:15 0:00 grep redis
[root@redis-1 ~]# ssh 192.168.81.230 "ps aux | grep redis"
root 56584 0.1 0.7 136972 7548 ? Ssl 13:13 0:00 redis-server 192.168.81.230:6379
root 56644 0.0 0.1 113176 1588 ? Ss 13:15 0:00 bash -c ps aux | grep redis
root 56661 0.0 0.0 112724 968 ? S 13:15 0:00 grep redis
配置redis主从
要在两台slave上同步主库配置
1.配置主从复制
[root@redis-2 ~]# redis-cli
127.0.0.1:6379> SLAVEOF 192.168.81.210 6379
OK
[root@redis-3 ~]# redis-cli
127.0.0.1:6379> SLAVEOF 192.168.81.220 6379
OK
2.主库新建一个key
127.0.0.1:6379> set name jiangxl
OK
3.从库查看是否复制
[root@redis-2 ~]# redis-cli
127.0.0.1:6379> get name
"jiangxl"
[root@redis-3 ~]# redis-cli
127.0.0.1:6379> get name
"jiangxl"
部署哨兵进程sentinel
配置文件解释
sentinel monitor mymaster 192.168.81.210 6379 2 //设置主节点信息,mymaster是主节点别名,就是随便起一个名字,然后填写主节点的ip地址,2表示当主节点挂掉后,有2个sentinel同意后才会选举新的master,一组哨兵集群,要把名称都写成一样的
sentinel down-after-milliseconds mymaster 3000 //主库宕机多少秒,从库在进行切换,因为有时因为网络波动,如果只要主库一宕机就切换主从,那么redis可能一直处于正在切换状态
sentinel parallel-syncs mymaster 1 //允许几个节点同时向主库同步数据
sentinel failover-timeout mymaster 18000 //故障转移超时时间,当从库同步主库的rdb文件,多长时间没有同步完就认为超时
三台redis服务器都要按如下配置,已经将配置文件中的bind写成了系统变量,在配合cat写入到文件,因此直接执行如下命令即可
1.创建哨兵服务配置路径
mkdir -p /data/redis_cluster/redis_26379/{conf,data,pid,logs}
2.写入哨兵配置文件
cat > /data/redis_cluster/redis_26379/conf/redis_26379.conf <<EOF
bind $(ifconfig | awk 'NR==2{print $2}')
port 26379
daemonize yes
logfile /data/redis_cluster/redis_26379/logs/redis_26379.log
dir /data/redis_cluster/redis_26379/data
sentinel monitor mymaster 192.168.81.210 6379 2
sentinel down-after-milliseconds mymaster 3000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 18000
EOF
配置完记得查看下配置文件bind一列是否是各自主机的ip地址
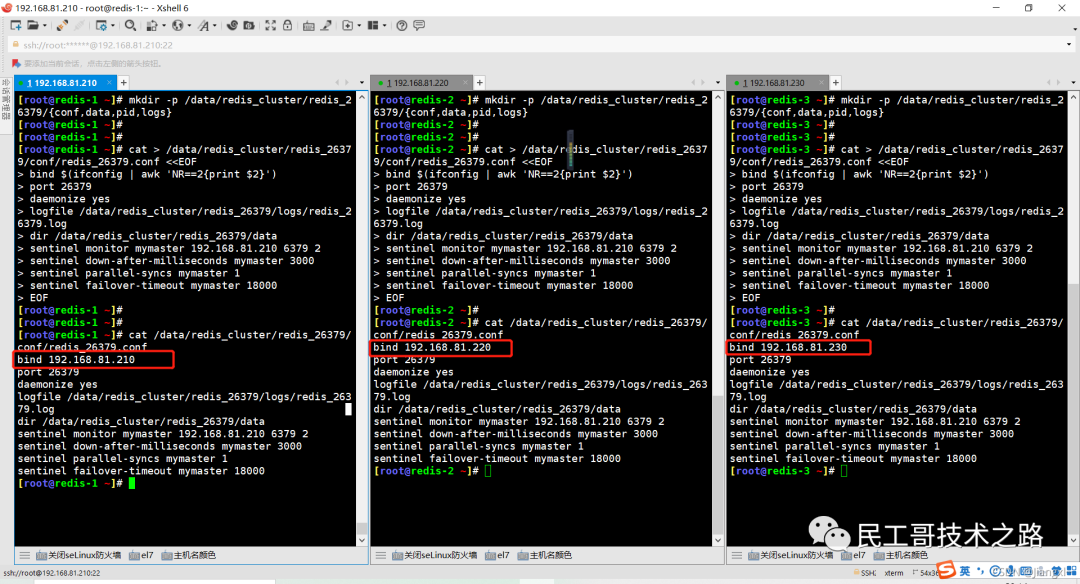
启动哨兵观察配置文件的变化
三台机器都这么操作启动哨兵
redis-sentinel /data/redis_cluster/redis_26379/conf/redis_26379.conf
观察哨兵启动前后配置文件的变化
启动前

启动后
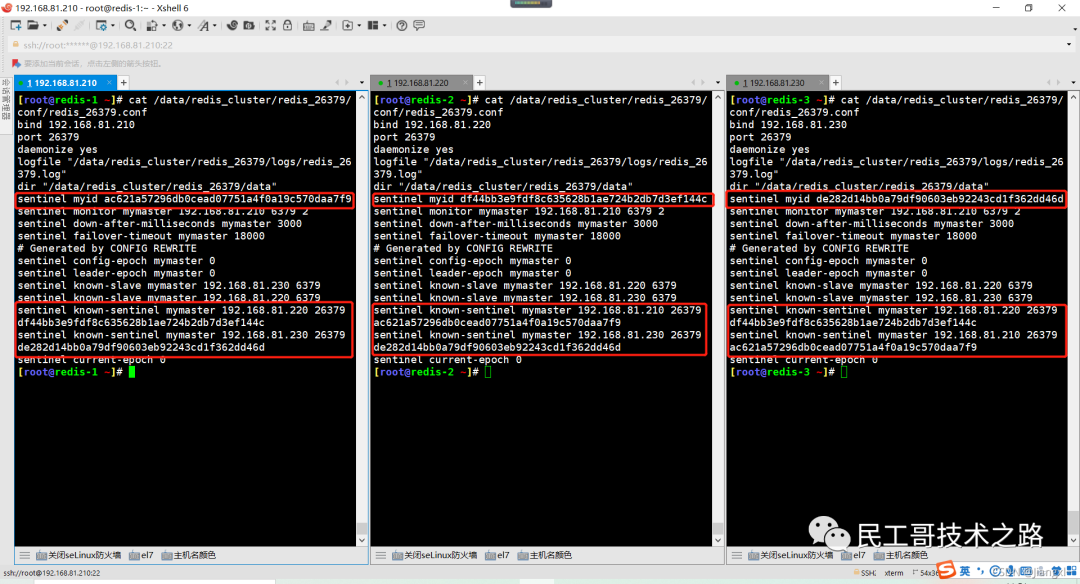
每台哨兵主机都自动增加了一个myid的配置,这个就是当主库挂掉后,哨兵选举的依据, 判断谁的myid大谁就当选为主库。
每台哨兵主机还自动增加了sentinel known-sentinel这个配置,这个配置每个哨兵会记录集群中其他节点的id号,这样就能够实现信息共享,即使应用在询问哨兵进程谁是主库,这时由于每个哨兵进程都有其他节点的信息,因此就能里面告诉应用谁是主库。
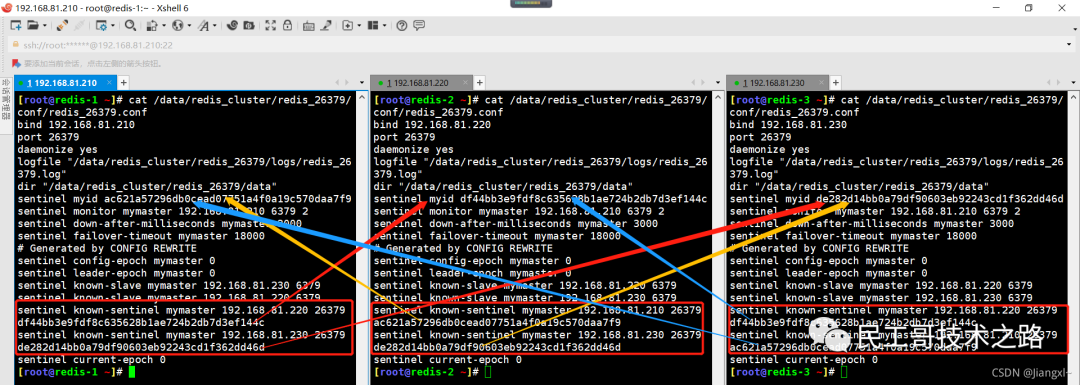
模拟主库故障验证应用是否可用
配置完哨兵后,每个节点上都有集群的信息共享,当主库挂掉后,哨兵进程确认主库下线了,哨兵根据各自的id大小选举新的主库,接替主库的工作,保证应用程序不受影响,当主库修复好后,在通过提权的方式先同步目前主库的数据,在让自身成为主库。
#关闭主库的redis服务,reids正常关闭,sentinel直接kill
[root@redis-1 ~]# redis-cli shutdown
[root@redis-1 ~]# pkill redis
#查看配置文件看看谁的myid大
redis-2的myid比较大
[root@redis-1 ~]# grep 'known-sentinel' /data/redis_cluster/redis_26379/conf/redis_26379.conf
sentinel known-sentinel mymaster 192.168.81.220 26379 df44bb3e9fdf8c635628b1ae724b2db7d3ef144c
sentinel known-sentinel mymaster 192.168.81.230 26379 de282d14bb0a79df90603eb92243cd1f362dd46d
#测试redis-2是否可用写入数据
可以写入数据,redis-2被选为主库
[root@redis-1 ~]# redis-cli -h 192.168.81.220 set gzzy_test guzhangzhuanyi
OK
[root@redis-1 ~]# redis-cli -h 192.168.81.220 config get slaveof
1) "slaveof"
2) ""
#测试redis-3是否可用写入数据
写入数据失败,并且同步的是redis-2的数据,因此redis-2为主库
[root@redis-1 ~]# redis-cli -h 192.168.81.230 set kkkk111 vvv
(error) READONLY You can't write against a read only slave.
[root@redis-1 ~]# redis-cli -h 192.168.81.230 config get slaveof
1) "slaveof"
2) "192.168.81.220 6379"
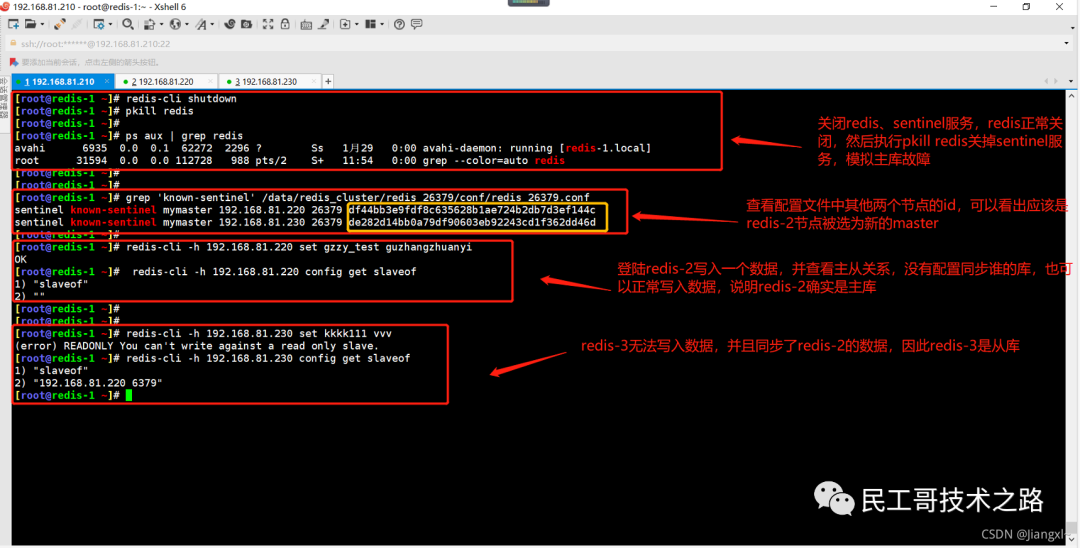
主库挂掉其他节点配置文件的变化
主库挂掉后,其他两个节点选举出master后,配置文件也会填写为新master的地址。
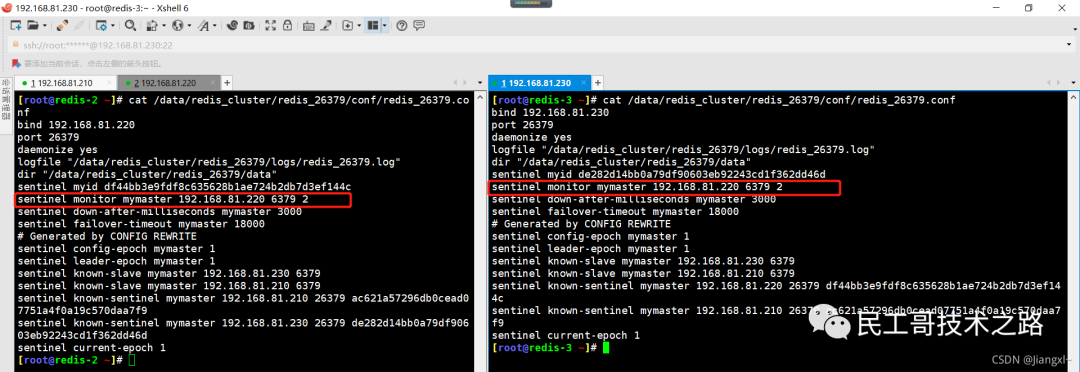
至此,一个 Redis 哨兵集群架构说部署完成了。
Redis 哨兵集群主库故障数据恢复实践
当主库修复后重新上线首先通过哨兵知道谁是当前的主库,然后就会去找主库同步数据,并且会自动修改配置文件,当数据同步后,想恢复的主库重新成为主库则需要把主库的权重调高,然后重新选举,这时原来的主库就能成为新的主库,调整完再将主库的权重值调成默认的。
实现思路
1.将故障的主库重新恢复
2.查看当前的主从状态,验证由于主库宕机,与从库产生的数据是否同步
3.调整权重值
4.重新选举,使原来的主库变成新的主库
5.恢复的主库重新成为新的主库后,要把调整的权重值全部变成默认值
主库可以重新加入哨兵集群的前提:剩余的两个节点必须有一个是master,且这两个节点配置文件已经指定了新的master地址
恢复损坏的主库
#恢复主库
[root@redis-1 ~]# redis-server /data/redis_cluster/redis_6379/conf/redis_6379.conf
[root@redis-1 ~]#
[root@redis-1 ~]# redis-sentinel /data/redis_cluster/redis_26379/conf/redis_26379.conf
#查看其他两个节点的日志输出,任意一个节点都会输出,表示redis-1已经加入集群了
tail -f /data/redis_cluster/redis_26379/logs/redis_26379.log
78223:X 30 Jan 12:05:09.073 # -sdown sentinel ac621a57296db0cead07751a4f0a19c570daa7f9 192.168.81.210 26379 @ mymaster 192.168.81.220 6379,

查看恢复的主库redis-1配置文件
[root@redis-1 ~]# cat /data/redis_cluster/redis_26379/conf/redis_26379.conf
bind 192.168.81.210
port 26379
daemonize yes
logfile "/data/redis_cluster/redis_26379/logs/redis_26379.log"
dir "/data/redis_cluster/redis_26379/data"
sentinel myid ac621a57296db0cead07751a4f0a19c570daa7f9
sentinel monitor mymaster 192.168.81.220 6379 2
可以看到已经自动修改为当前库的地址
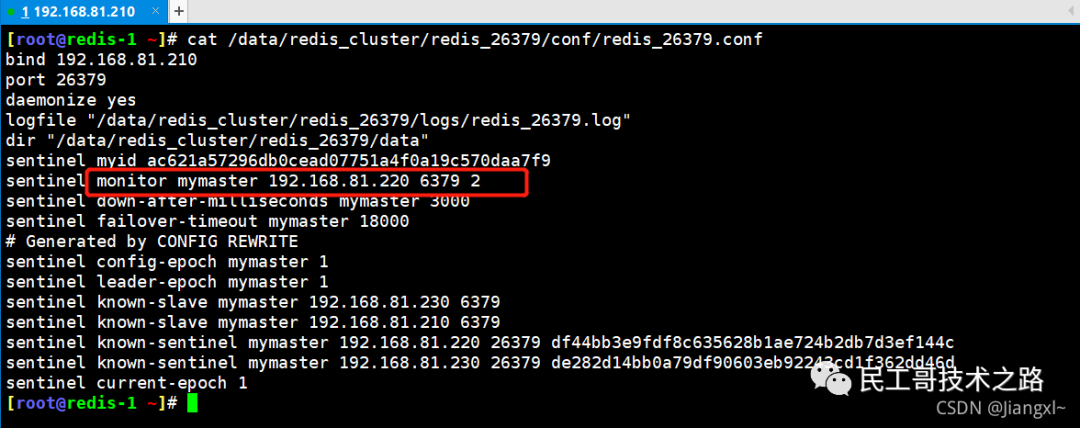
查看恢复的主库redis-1的主从关系
#已经同步了当前主库redis-2
[root@redis-1 ~]# redis-cli
127.0.0.1:6379> CONFIG GET slaveof
1) "slaveof"
2) "192.168.81.220 6379"
#已经可以看到主库宕机阶段,从库变为主库产生的最新数据
127.0.0.1:6379> get gzzy_test
"guzhangzhuanyi"
配置恢复的主库的权重值,使其重新选举为主库
哨兵的选举首先是
- 查看谁的权重优先级比较高的当选为主库
- 权重优先级一致,就比较id,id大的当选
#查看其他两个节点的权重值
[root@redis-1 ~]# redis-cli -h 192.168.81.220 -p 6379 config get slave-priority
1) "slave-priority"
2) "100"
[root@redis-1 ~]# redis-cli -h 192.168.81.230 -p 6379 config get slave-priority
1) "slave-priority"
2) "100"
#将其他两个节点的权重值改为0
[root@redis-1 ~]# redis-cli -h 192.168.81.220 -p 6379 config set slave-priority 0
OK
[root@redis-1 ~]# redis-cli -h 192.168.81.230 -p 6379 config set slave-priority 0
OK
#设置恢复的主库的权限优先级高于其他两个节点
[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6379 config set slave-priority 150
OK
[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6379 config get slave-priority
1) "slave-priority"
2) "150"
#重新选举
[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 26379 sentinel failover mymaster
#查看其他节点sentinel输出的日志
[root@redis-3 ~]# tail -f /data/redis_cluster/redis_26379/logs/redis_26379.log
78223:X 30 Jan 12:32:27.591 * +convert-to-slave slave 192.168.81.220:6379 192.168.81.220 6379 @ mymaster 192.168.81.210 6379
根据日志的输出,可以明显的看出调整了redis-1的权重优先级为150,比其他两个节点的高,因此redis-1就变成了主库。
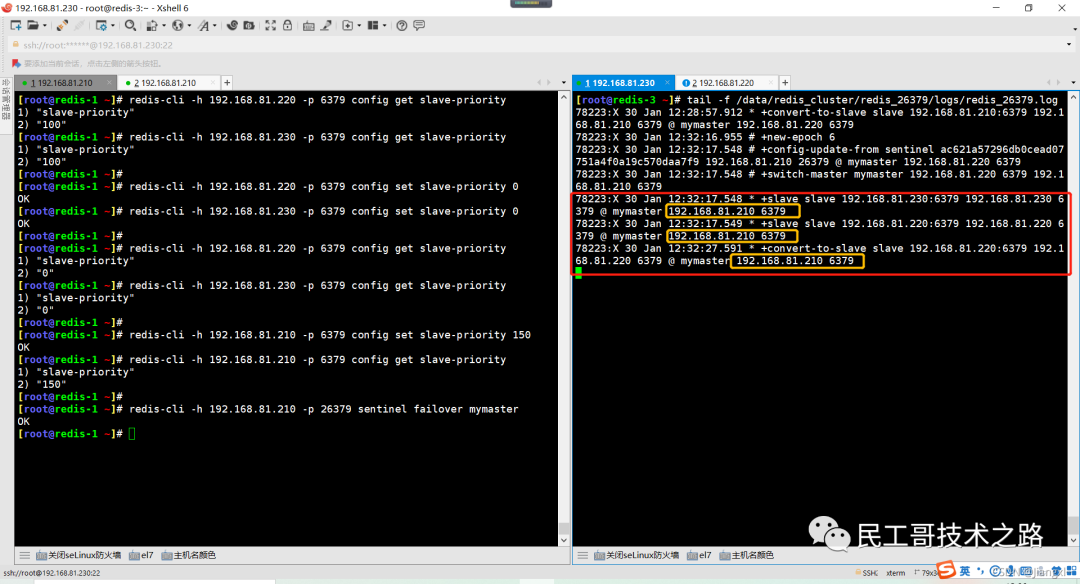
查看节点的主从复制关系。
主库没有同步的库,其他两个节点都同步redis-1的主库。
[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6379 config get slaveof
1) "slaveof"
2) ""
[root@redis-1 ~]# redis-cli -h 192.168.81.220 -p 6379 config get slaveof
1) "slaveof"
2) "192.168.81.210 6379"
[root@redis-1 ~]# redis-cli -h 192.168.81.230 -p 6379 config get slaveof
1) "slaveof"
2) "192.168.81.210 6379"
将权重值调整为默认值
将权重值调整为默认值,方便下次选举时作为判断条件。
[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6379 config set slave-priority 100
OK
[root@redis-1 ~]# redis-cli -h 192.168.81.220 -p 6379 config set slave-priority 100
OK
[root@redis-1 ~]# redis-cli -h 192.168.81.230 -p 6379 config set slave-priority 100
OK
参考文章:
https://www.pdai.tech/md/db/nosql-redis/db-redis-x-sentinel.html
https://jiangxl.blog.csdn.net/article/details/120703648
https://jiangxl.blog.csdn.net/article/details/120703831
(十):Redis Cluster 集群分片技术
如果面对海量数据那么必然需要构建master(主节点分片)之间的集群,同时必然需要吸收高可用(主从复制和哨兵机制)能力,即每个master分片节点还需要有slave节点,这是分布式系统中典型的纵向扩展(集群的分片技术)的体现;所以在 Redis 3.0 版本中对应的设计就是Redis Cluster。
Redis 集群的设计目标
Redis-cluster 是一种服务器 Sharding技术 ,Redis3.0以后版本正式提供支持。Redis Cluster在设计时考虑了什么?
Redis Cluster goals
高性能可线性扩展至最多 1000 节点。集群中没有代理,(集群节点间)使用异步复制,没有归并操作(merge operations on values)。
-
可接受的写入安全 :系统尝试(采用best-effort方式)保留所有连接到master节点的client发起的写操作。通常会有一个小的时间窗,时间窗内的已确认写操作可能丢失(即,在发生failover之前的小段时间窗内的写操作可能在failover中丢失)。而在(网络)分区故障下,对少数派master的写入,发生写丢失的时间窗会很大。
-
可用性 :Redis Cluster 在以下场景下集群总是可用:大部分master节点可用,并且对少部分不可用的master,每一个master至少有一个当前可用的slave。更进一步,通过使用 replicas migration 技术,当前没有slave的master会从当前拥有多个slave的master接受到一个新slave来确保可用性。
Clients and Servers roles in the Redis Cluster protocol
Redis Cluster的节点负责维护数据,和获取集群状态,这包括将keys映射到正确的节点。集群节点同样可以自动发现其他节点、检测不工作节点、以及在发现故障发生时晋升slave节点到master。
所有集群节点通过由TCP和二进制协议组成的称为 Redis Cluster Bus 的方式来实现集群的节点自动发现、故障节点探测、slave升级为master等任务。每个节点通过cluster bus连接所有其他节点。节点间使用 gossip协议 进行集群信息传播,以此来实现新节点发现,发送ping包以确认对端工作正常,以及发送cluster消息用来标记特定状态。cluster bus还被用来在集群中创博Pub/Sub消息,以及在接收到用户请求后编排手动failover。
Write safety
Redis Cluster在节点间采用了异步复制,以及 last failover wins 隐含合并功能(implicit merge function)(【译注】不存在合并功能,而是总是认为最近一次failover的节点是最新的)。这意味着最后被选举出的master所包含的数据最终会替代(同一前master下)所有其他备份(replicas/slaves)节点(包含的数据)。当发生分区问题时,总是会有一个时间窗内会发生写入丢失。然而,对连接到多数派master(majority of masters)的client,以及连接到少数派master(mimority of masters)的client,这个时间窗是不同的。
相比较连接到少数master(minority of masters)的client,对连接到多数master(majority of masters)的client发起的写入,Redis cluster会更努力地尝试将其保存。下面的场景将会导致在主分区的master上,已经确认的写入在故障期间发生丢失:
写入请求达到master,但是当master执行完并回复client时,写操作可能还没有通过异步复制传播到它的slave。如果master在写操作抵达slave之前挂了,并且master无法触达(unreachable)的时间足够长而导致了slave节点晋升,那么这个写操作就永远地丢失了。通常很难直接观察到,因为master尝试回复client(写入确认)和传播写操作到slave通常几乎是同时发生。然而,这却是真实世界中的故障方式。(【译注】不考虑返回后宕机的场景,因为宕机导致的写入丢失,在单机版redis上同样存在,这不是redis cluster引入的目的及要解决的问题)。
另一种理论上可能发生写入丢失的模式是:
- master因为分区原因不可用(unreachable)
- 该master被某个slave替换(failover)
- 一段时间后,该master重新可用
- 在该old master变为slave之前,一个client通过过期的路由表对该节点进行写入。
上述第二种失败场景通常难以发生,因为:
- 少数派master(minority master)无法与多数派master(majority master)通信达到一定的时间后,它将拒绝写入,并且当分区恢复后,该master在重新与多数派master建立连接后,还将保持拒绝写入状态一小段时间来感知集群配置变化。留给client可写入的时间窗很小。
- 发生这种错误还有一个前提是,client一直都在使用过期的路由表(而实际上集群因为发生了failover,已有slave发生了晋升)。
写入少数派master(minority side of a partition)会有一个更长的时间窗会导致数据丢失。因为如果最终导致了failover,则写入少数派master的数据将会被多数派一侧(majority side)覆盖(在少数派master作为slave重新接入集群后)。
特别地,如果要发生failover,master必须至少在NODE_TIMEOUT时间内无法被多数masters(majority of maters)连接,因此如果分区在这一时间内被修复,则不会发生写入丢失。当分区持续时间超过NODE_TIMEOUT时,所有在这段时间内对少数派master(minority side)的写入将会丢失。然而少数派一侧(minority side)将会在NODE_TIMEOUT时间之后如果还没有连上多数派一侧,则它会立即开始拒绝写入,因此对少数派master而言,存在一个进入不可用状态的最大时间窗。在这一时间窗之外,不会再有写入被接受或丢失。
可用性(Availability)
Redis Cluster在少数派分区侧不可用。在多数派分区侧,假设由多数派masters存在并且不可达的master有一个slave,cluster将会在NODE_TIMEOUT外加重新选举所需的一小段时间(通常1~2秒)后恢复可用。
这意味着,Redis Cluster被设计为可以忍受一小部分节点的故障,但是如果需要在大网络分裂(network splits)事件中(【译注】比如发生多分区故障导致网络被分割成多块,且不存在多数派master分区)保持可用性,它不是一个合适的方案(【译注】比如,不要尝试在多机房间部署redis cluster,这不是redis cluster该做的事)。
假设一个cluster由N个master节点组成并且每个节点仅拥有一个slave,在多数侧只有一个节点出现分区问题时,cluster的多数侧(majority side)可以保持可用,而当有两个节点出现分区故障时,只有 1-(1/(N_2-1)) 的可能性保持集群可用。也就是说,如果有一个由5个master和5个slave组成的cluster,那么当两个节点出现分区故障时,它有 1/(5_2-1)=11.11%的可能性发生集群不可用。
Redis cluster提供了一种成为 Replicas Migration 的有用特性特性,它通过自动转移备份节点到孤master节点,在真实世界的常见场景中提升了cluster的可用性。在每次成功的failover之后,cluster会自动重新配置slave分布以尽可能保证在下一次failure中拥有更好的抵御力。
性能(Performance)
Redis Cluster不会将命令路由到其中的key所在的节点,而是向client发一个重定向命令 (- MOVED) 引导client到正确的节点。最终client会获得一个最新的cluster(hash slots分布)展示,以及哪个节点服务于命令中的keys,因此clients就可以获得正确的节点并用来继续执行命令。
因为master和slave之间使用异步复制,节点不需要等待其他节点对写入的确认(除非使用了WAIT命令)就可以回复client。同样,因为multi-key命令被限制在了临近的key(near keys)(【译注】即同一hash slot内的key,或者从实际使用场景来说,更多的是通过hash tag定义为具备相同hash字段的有相近业务含义的一组keys),所以除非触发resharding,数据永远不会在节点间移动。
普通的命令(normal operations)会像在单个redis实例那样被执行。这意味着一个拥有N个master节点的Redis Cluster,你可以认为它拥有N倍的单个Redis性能。同时,query通常都在一个round trip中执行,因为client通常会保留与所有节点的持久化连接(连接池),因此延迟也与客户端操作单台redis实例没有区别。
在对数据安全性、可用性方面提供了合理的弱保证的前提下,提供极高的性能和可扩展性,这是Redis Cluster的主要目标。
避免合并(merge)操作
Redis Cluster设计上避免了在多个拥有相同key-value对的节点上的版本冲突(及合并/merge),因为在redis数据模型下这是不需要的。Redis的值同时都非常大;一个拥有数百万元素的list或sorted set是很常见的。同样,数据类型的语义也很复杂。传输和合并这类值将会产生明显的瓶颈,并可能需要对应用侧的逻辑做明显的修改,比如需要更多的内存来保存meta-data等。
这里(【译注】刻意避免了merge)并没有严格的技术限制。CRDTs或同步复制状态机可以塑造与redis类似的复杂的数据类型。然而,这类系统运行时的行为与Redis Cluster其实是不一样的。Redis Cluster被设计用来支持非集群redis版本无法支持的一些额外的场景。
主要模块介绍
Redis Cluster Specification同时还介绍了Redis Cluster中主要模块,这里面包含了很多基础和概念,我们需要先了解下。
哈希槽(Hash Slot)
Redis-cluster 没有使用一致性hash,而是引入了哈希槽的概念 。Redis-cluster中有16384(即2的14次方)个哈希槽,每个key通过CRC16校验后对16383取模来决定放置哪个槽。Cluster中的每个节点负责一部分hash槽(hash slot)。
比如集群中存在三个节点,则可能存在的一种分配如下:
- 节点A包含0到5500号哈希槽;
- 节点B包含5501到11000号哈希槽;
- 节点C包含11001 到 16384号哈希槽。
Keys hash tags
Hash tags提供了一种途径, 用来将多个(相关的)key分配到相同的hash slot中 。这时Redis Cluster中实现multi-key操作的基础。
hash tag规则如下,如果满足如下规则,{和}之间的字符将用来计算HASH_SLOT,以保证这样的key保存在同一个slot中。
- key包含一个{字符
- 并且 如果在这个{的右面有一个}字符
- 并且 如果在{和}之间存在至少一个字符
例如:
- {user1000}.following和{user1000}.followers这两个key会被hash到相同的hash slot中,因为只有user1000会被用来计算hash slot值。
- foo{}{bar}这个key不会启用hash tag因为第一个{和}之间没有字符。
- foozap这个key中的{bar部分会被用来计算hash slot
- foo{bar}{zap}这个key中的bar会被用来计算计算hash slot,而zap不会
Cluster nodes属性
每个节点在cluster中有一个唯一的名字。这个名字由160bit随机十六进制数字表示,并在节点启动时第一次获得(通常通过/dev/urandom)。节点在配置文件中保留它的ID,并永远地使用这个ID,直到被管理员使用CLUSTER RESET HARD命令hard reset这个节点。
节点ID被用来在整个cluster中标识每个节点。一个节点可以修改自己的IP地址而不需要修改自己的ID。Cluster可以检测到IP /port的改动并通过运行在cluster bus上的gossip协议重新配置该节点。
节点ID不是唯一与节点绑定的信息,但是他是唯一的一个总是保持全局一致的字段。每个节点都拥有一系列相关的信息。一些信息时关于本节点在集群中配置细节,并最终在cluster内部保持一致的。而其他信息,比如节点最后被ping的时间,是节点的本地信息。
每个节点维护着集群内其他节点的以下信息:node id, 节点的IP和port,节点标签,master node id(如果这是一个slave节点),最后被挂起的ping的发送时间(如果没有挂起的ping则为0),最后一次收到pong的时间,当前的节点configuration epoch ,链接状态,以及最后是该节点服务的hash slots。
对节点字段更详细的描述,可以参考对命令 CLUSTER NODES的描述。
CLUSTER NODES命令可以被发送到集群内的任意节点,他会提供基于该节点视角(view)下的集群状态以及每个节点的信息。
下面是一个发送到一个拥有3个节点的小集群的master节点的CLUSTER NODES输出的例子。
$ redis-cli cluster nodes
d1861060fe6a534d42d8a19aeb36600e18785e04 127.0.0.1:6379 myself - 0 1318428930 1 connected 0-1364
3886e65cc906bfd9b1f7e7bde468726a052d1dae 127.0.0.1:6380 master - 1318428930 1318428931 2 connected 1365-2729
d289c575dcbc4bdd2931585fd4339089e461a27d 127.0.0.1:6381 master - 1318428931 1318428931 3 connected 2730-4095
在上面的例子中,按顺序列出了不同的字段:
node id, address:port, flags, last ping sent, last pong received, configuration epoch, link state, slots.
Cluster总线
每个Redis Cluster节点有一个额外的TCP端口用来接受其他节点的连接。这个端口与用来接收client命令的普通TCP端口有一个固定的offset。该端口等于普通命令端口加上10000.例如,一个Redis街道口在端口6379坚挺客户端连接,那么它的集群总线端口16379也会被打开。
节点到节点的通讯只使用集群总线,同时使用集群总线协议:有不同的类型和大小的帧组成的二进制协议。集群总线的二进制协议没有被公开文档话,因为他不希望被外部软件设备用来预计群姐点进行对话。
集群拓扑
Redis Cluster是一张全网拓扑,节点与其他每个节点之间都保持着TCP连接。在一个拥有N个节点的集群中,每个节点由N-1个TCP传出连接,和N-1个TCP传入连接。这些TCP连接总是保持活性(be kept alive)。当一个节点在集群总线上发送了ping请求并期待对方回复pong,(如果没有得到回复)在等待足够成时间以便将对方标记为不可达之前,它将先尝试重新连接对方以刷新与对方的连接。而在全网拓扑中的Redis Cluster节点,节点使用gossip协议和配置更新机制来避免在正常情况下节点之间交换过多的消息,因此集群内交换的消息数目(相对节点数目)不是指数级的。
节点握手
节点总是接受集群总线端口的链接,并且总是会回复ping请求,即使ping来自一个不可信节点。然而,如果发送节点被认为不是当前集群的一部分,所有其他包将被抛弃。
节点认定其他节点是当前集群的一部分有 两种方式 :
1.如果一个节点出现在了一条MEET消息中。一条meet消息非常像一个PING消息,但是它会强制接收者接受一个节点作为集群的一部分。节点只有在接收到系统管理员的如下命令后,才会向其他节点发送MEET消息:
CLUSTER MEET ip port
2.如果一个被信任的节点gossip了某个节点,那么接收到gossip消息的节点也会那个节点标记为集群的一部分。也就是说,如果在集群中,A知道B,而B知道C,最终B会发送gossip消息到A,告诉A节点C是集群的一部分。这时,A会把C注册未网络的一部分,并尝试与C建立连接。
这意味着,一旦我们把某个节点加入了连接图(connected graph),它们最终会自动形成一张全连接图(fully connected graph)。这意味着只要系统管理员强制加入了一条信任关系(在某个节点上通过meet命令加入了一个新节点),集群可以自动发现其他节点。
请求重定向
Redis cluster采用去中心化的架构,集群的主节点各自负责一部分槽,客户端如何确定key到底会映射到哪个节点上呢?这就是我们要讲的请求重定向。
在cluster模式下,节点对请求的处理过程如下:
- 检查当前key是否存在当前NODE?
- 通过crc16(key)/16384计算出slot
- 查询负责该slot负责的节点,得到节点指针
- 该指针与自身节点比较
- 若slot不是由自身负责,则返回MOVED重定向
- 若slot由自身负责,且key在slot中,则返回该key对应结果
- 若key不存在此slot中,检查该slot是否正在迁出(MIGRATING)?
- 若key正在迁出,返回ASK错误重定向客户端到迁移的目的服务器上
- 若Slot未迁出,检查Slot是否导入中?
- 若Slot导入中且有ASKING标记,则直接操作
- 否则返回MOVED重定向
这个过程中有两点需要具体理解下:MOVED重定向 和 ASK重定向。
Moved 重定向
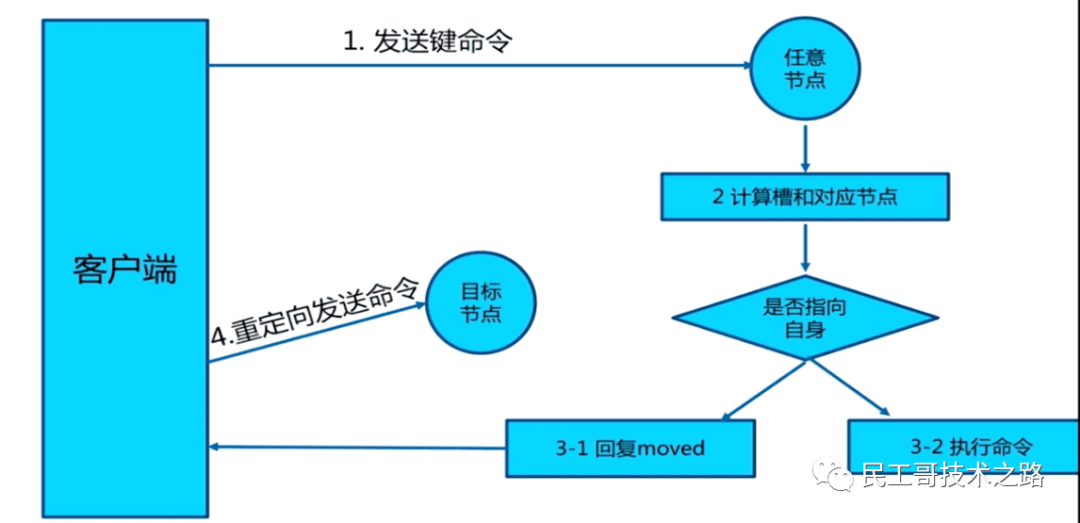
- 槽命中:直接返回结果
- 槽不命中:即当前键命令所请求的键不在当前请求的节点中,则当前节点会向客户端发送一个Moved 重定向,客户端根据Moved 重定向所包含的内容找到目标节点,再一次发送命令。
从下面可以看出 php 的槽位9244不在当前节点中,所以会重定向到节点 192.168.2.23:7001中。redis-cli会帮你自动重定向(如果没有集群方式启动,即没加参数 -c,redis-cli不会自动重定向),并且编写程序时,寻找目标节点的逻辑需要交予程序员手动完成。
cluster keyslot keyName # 得到keyName的槽
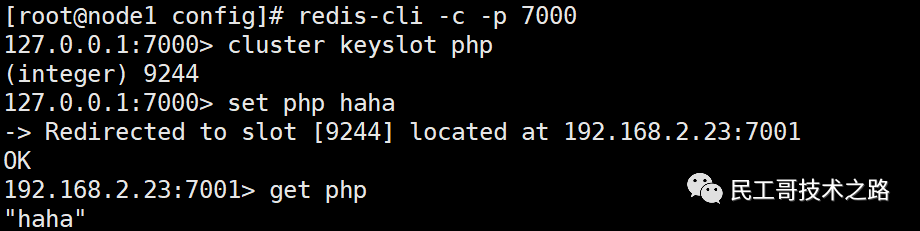
ASK 重定向
Ask重定向发生于集群伸缩时,集群伸缩会导致槽迁移,当我们去源节点访问时,此时数据已经可能已经迁移到了目标节点,使用Ask重定向来解决此种情况。
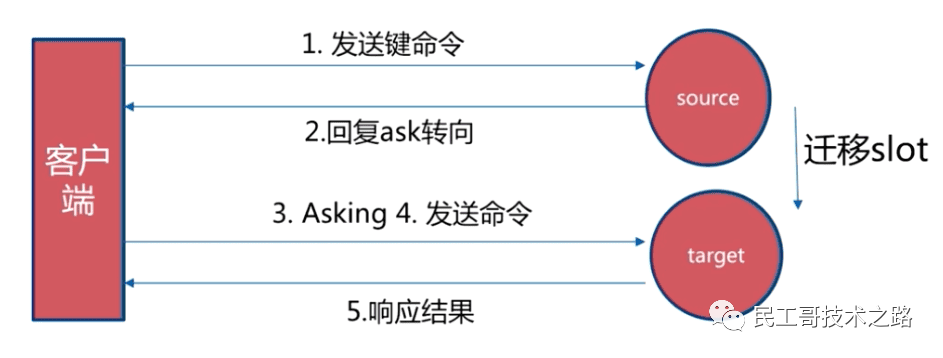
smart客户端
上述两种重定向的机制使得客户端的实现更加复杂,提供了smart客户端(JedisCluster)来减低复杂性,追求更好的性能。客户端内部负责计算/维护键-> 槽 -> 节点映射,用于快速定位目标节点。
实现原理:
- 从集群中选取一个可运行节点,使用 cluster slots得到槽和节点的映射关系
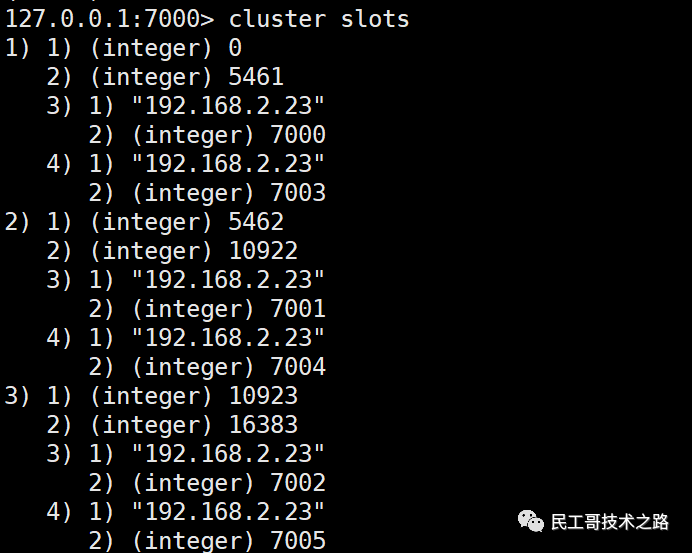
-
将上述映射关系存到本地,通过映射关系就可以直接对目标节点进行操作(CRC16(key) -> slot -> node),很好地避免了Moved重定向,并为每个节点创建JedisPool
-
至此就可以用来进行命令操作
状态检测及维护
Redis Cluster中节点状态如何维护呢?这里便涉及 有哪些状态,底层协议Gossip,及具体的通讯(心跳)机制 。@pdai
Cluster中的每个节点都维护一份在自己看来当前整个集群的状态,主要包括:
- 当前集群状态
- 集群中各节点所负责的slots信息,及其migrate状态
- 集群中各节点的master-slave状态
- 集群中各节点的存活状态及不可达投票
当集群状态变化时,如新节点加入、slot迁移、节点宕机、slave提升为新Master,我们希望这些变化尽快的被发现,传播到整个集群的所有节点并达成一致。节点之间相互的心跳(PING,PONG,MEET)及其携带的数据是集群状态传播最主要的途径。
Gossip协议
Redis Cluster 通讯底层是Gossip协议,所以需要对Gossip协议有一定的了解。
gossip 协议(gossip protocol)又称 epidemic 协议(epidemic protocol),是基于流行病传播方式的节点或者进程之间信息交换的协议。在分布式系统中被广泛使用,比如我们可以使用 gossip 协议来确保网络中所有节点的数据一样。
Gossip协议已经是P2P网络中比较成熟的协议了。Gossip协议的最大的好处是, 即使集群节点的数量增加,每个节点的负载也不会增加很多,几乎是恒定的。这就允许Consul管理的集群规模能横向扩展到数千个节点。
Gossip算法又被称为反熵(Anti-Entropy),熵是物理学上的一个概念,代表杂乱无章,而反熵就是在杂乱无章中寻求一致,这充分说明了Gossip的特点:在一个有界网络中,每个节点都随机地与其他节点通信,经过一番杂乱无章的通信,最终所有节点的状态都会达成一致。每个节点可能知道所有其他节点,也可能仅知道几个邻居节点,只要这些节可以通过网络连通,最终他们的状态都是一致的,当然这也是疫情传播的特点。
上面的描述都比较学术,其实Gossip协议对于我们吃瓜群众来说一点也不陌生,Gossip协议也成为流言协议,说白了就是八卦协议,这种传播规模和传播速度都是非常快的,你可以体会一下。所以计算机中的很多算法都是源自生活,而又高于生活的。
Gossip协议的使用
Redis 集群是去中心化的,彼此之间状态同步靠 gossip 协议通信,集群的消息有以下几种类型:
- Meet 通过「cluster meet ip port」命令,已有集群的节点会向新的节点发送邀请,加入现有集群。
- Ping 节点每秒会向集群中其他节点发送 ping 消息,消息中带有自己已知的两个节点的地址、槽、状态信息、最后一次通信时间等。
- Pong 节点收到 ping 消息后会回复 pong 消息,消息中同样带有自己已知的两个节点信息。
- Fail 节点 ping 不通某节点后,会向集群所有节点广播该节点挂掉的消息。其他节点收到消息后标记已下线。
基于Gossip协议的故障检测
集群中的每个节点都会定期地向集群中的其他节点发送PING消息,以此交换各个节点状态信息,检测各个节点状态: 在线状态、疑似下线状态PFAIL、已下线状态FAIL。
-
自己保存信息:当主节点A通过消息得知主节点B认为主节点D进入了疑似下线(PFAIL)状态时,主节点A会在自己的clusterState.nodes字典中找到主节点D所对应的clusterNode结构,并将主节点B的下线报告添加到clusterNode结构的fail_reports链表中,并后续关于结点D疑似下线的状态通过Gossip协议通知其他节点。
-
一起裁定:如果集群里面,半数以上的主节点都将主节点D报告为疑似下线,那么主节点D将被标记为已下线(FAIL)状态,将主节点D标记为已下线的节点会向集群广播主节点D的FAIL消息,所有收到FAIL消息的节点都会立即更新nodes里面主节点D状态标记为已下线。
-
最终裁定:将 node 标记为 FAIL 需要满足以下两个条件:
- 有半数以上的主节点将 node 标记为 PFAIL 状态。
- 当前节点也将 node 标记为 PFAIL 状态。
通讯状态和维护
我们理解了Gossip协议基础后,就可以进一步理解Redis节点之间相互的通讯 心跳 (PING,PONG,MEET)实现和维护了。我们通过几个问题来具体理解。
什么时候进行心跳?
Redis节点会记录其向每一个节点上一次发出ping和收到pong的时间,心跳发送时机与这两个值有关。通过下面的方式既能保证及时更新集群状态,又不至于使心跳数过多:
- 每次Cron向所有未建立链接的节点发送ping或meet
- 每1秒从所有已知节点中随机选取5个,向其中上次收到pong最久远的一个发送ping
- 每次Cron向收到pong超过timeout/2的节点发送ping
- 收到ping或meet,立即回复pong
发送哪些心跳数据?
- Header,发送者自己的信息
- 所负责slots的信息
- 主从信息
- ip port信息
- 状态信息
- Gossip,发送者所了解的部分其他节点的信息
- ping_sent, pong_received
- ip, port信息
- 状态信息,比如发送者认为该节点已经不可达,会在状态信息中标记其为PFAIL或FAIL
如何处理心跳?
新节点加入
- 发送meet包加入集群
- 从pong包中的gossip得到未知的其他节点
- 循环上述过程,直到最终加入集群
Slots信息
- 判断发送者声明的slots信息,跟本地记录的是否有不同
- 如果不同,且发送者epoch较大,更新本地记录
- 如果不同,且发送者epoch小,发送Update信息通知发送者
Master slave信息
发现发送者的master、slave信息变化,更新本地状态
节点Fail探测(故障发现)
- 超过超时时间仍然没有收到pong包的节点会被当前节点标记为PFAIL
- PFAIL标记会随着gossip传播
- 每次收到心跳包会检测其中对其他节点的PFAIL标记,当做对该节点FAIL的投票维护在本机
- 对某个节点的PFAIL标记达到大多数时,将其变为FAIL标记并广播FAIL消息
注:Gossip的存在使得集群状态的改变可以更快的达到整个集群。每个心跳包中会包含多个Gossip包,那么多少个才是合适的呢,redis的选择是N/10,其中N是节点数,这样可以保证在PFAIL投票的过期时间内,节点可以收到80%机器关于失败节点的gossip,从而使其顺利进入FAIL状态。
将信息广播给其它节点?
当需要发布一些非常重要需要立即送达的信息时,上述心跳加Gossip的方式就显得捉襟见肘了,这时就需要向所有集群内机器的广播信息,使用广播发的场景:
- 节点的Fail信息 :当发现某一节点不可达时,探测节点会将其标记为PFAIL状态,并通过心跳传播出去。当某一节点发现这个节点的PFAIL超过半数时修改其为FAIL并发起广播。
- Failover Request信息 :slave尝试发起FailOver时广播其要求投票的信息
- 新Master信息 :Failover成功的节点向整个集群广播自己的信息
故障恢复(Failover)
master节点挂了之后,如何进行故障恢复呢?
当slave发现自己的master变为FAIL状态时,便尝试进行Failover,以期成为新的master。由于挂掉的master可能会有多个slave。Failover的过程需要经过类Raft协议的过程在整个集群内达到一致, 其过程如下:
- slave发现自己的master变为FAIL
- 将自己记录的集群currentEpoch加1,并广播Failover Request信息
- 其他节点收到该信息,只有master响应,判断请求者的合法性,并发送FAILOVER_AUTH_ACK,对每一个epoch只发送一次ack
- 尝试failover的slave收集FAILOVER_AUTH_ACK
- 超过半数后变成新Master
- 广播Pong通知其他集群节点
扩容&缩容
Redis Cluster是如何进行扩容和缩容的呢?
扩容
当集群出现容量限制或者其他一些原因需要扩容时,redis cluster提供了比较优雅的集群扩容方案。
1.首先将新节点加入到集群中,可以通过在集群中任何一个客户端执行cluster meet 新节点ip:端口,或者通过redis-trib add node添加,新添加的节点默认在集群中都是主节点。
2.迁移数据 迁移数据的大致流程是,首先需要确定哪些槽需要被迁移到目标节点,然后获取槽中key,将槽中的key全部迁移到目标节点,然后向集群所有主节点广播槽(数据)全部迁移到了目标节点。直接通过redis-trib工具做数据迁移很方便。现在假设将节点A的槽10迁移到B节点,过程如下:
B:cluster setslot 10 importing A.nodeId
A:cluster setslot 10 migrating B.nodeId
循环获取槽中key,将key迁移到B节点
A:cluster getkeysinslot 10 100
A:migrate B.ip B.port "" 0 5000 keys key1[ key2....]
向集群广播槽已经迁移到B节点
cluster setslot 10 node B.nodeId
缩容
缩容的大致过程与扩容一致,需要判断下线的节点是否是主节点,以及主节点上是否有槽,若主节点上有槽,需要将槽迁移到集群中其他主节点,槽迁移完成之后,需要向其他节点广播该节点准备下线(cluster forget nodeId)。最后需要将该下线主节点的从节点指向其他主节点,当然最好是先将从节点下线。
更深入理解
通过几个例子,再深入理解Redis Cluster
为什么Redis Cluster的Hash Slot 是16384?
我们知道一致性hash算法是2的16次方,为什么hash slot是2的14次方呢?
在redis节点发送心跳包时需要把所有的槽放到这个心跳包里,以便让节点知道当前集群信息,16384=16k,在发送心跳包时使用char进行bitmap压缩后是2k(2 * 8 (8 bit) * 1024(1k) = 16K),也就是说使用2k的空间创建了16k的槽数。
虽然使用CRC16算法最多可以分配65535(2^16-1)个槽位,65535=65k,压缩后就是8k(8 * 8 (8 bit) * 1024(1k) =65K),也就是说需要需要8k的心跳包,作者认为这样做不太值得;并且一般情况下一个redis集群不会有超过1000个master节点,所以16k的槽位是个比较合适的选择。
为什么Redis Cluster中不建议使用发布订阅呢?
在集群模式下,所有的publish命令都会向所有节点(包括从节点)进行广播,造成每条publish数据都会在集群内所有节点传播一次,加重了带宽负担,对于在有大量节点的集群中频繁使用pub,会严重消耗带宽,不建议使用。(虽然官网上讲有时候可以使用Bloom过滤器或其他算法进行优化的)
其它常见方案
还有一些方案出现在历史舞台上,我挑了几个经典的。简单了解下,增强下关联的知识体系。
Redis Sentinel 集群 + Keepalived/Haproxy
底层是 Redis Sentinel 集群,代理着 Redis 主从,Web 端通过 VIP 提供服务。当主节点发生故障,比如机器故障、Redis 节点故障或者网络不可达,Redis 之间的切换通过 Redis Sentinel 内部机制保障,VIP 切换通过 Keepalived 保障。
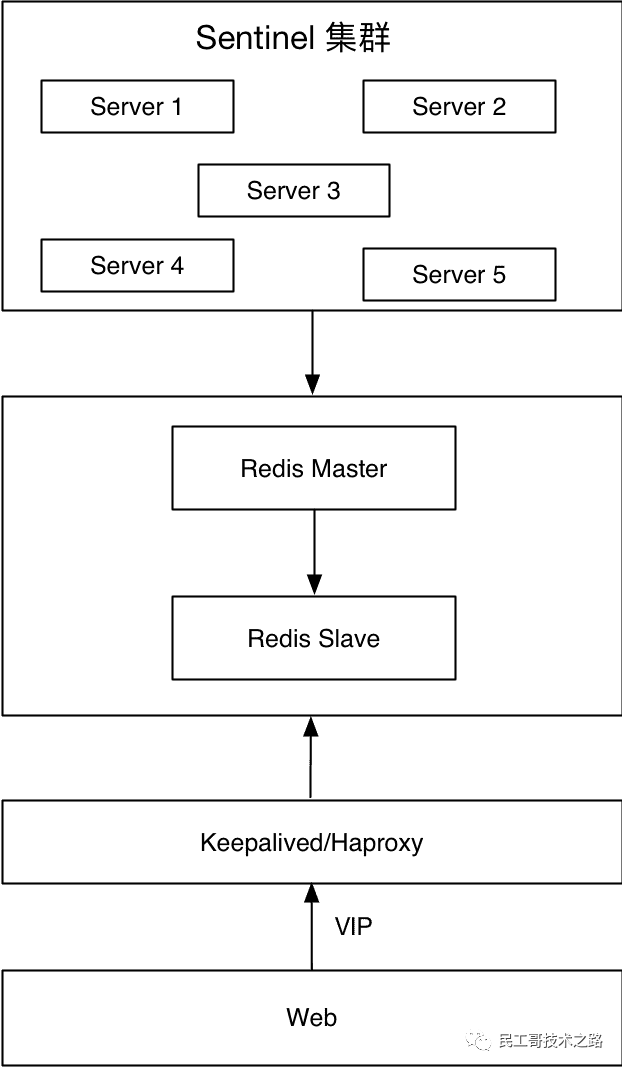
优点:
- 秒级切换
- 对应用透明
缺点:
- 维护成本高
- 存在脑裂
- Sentinel 模式存在短时间的服务不可用
Twemproxy
多个同构 Twemproxy(配置相同)同时工作,接受客户端的请求,根据 hash 算法,转发给对应的 Redis。
Twemproxy 方案比较成熟了,但是效果并不是很理想。一方面是定位问题比较困难,另一方面是它对自动剔除节点的支持不是很友好。
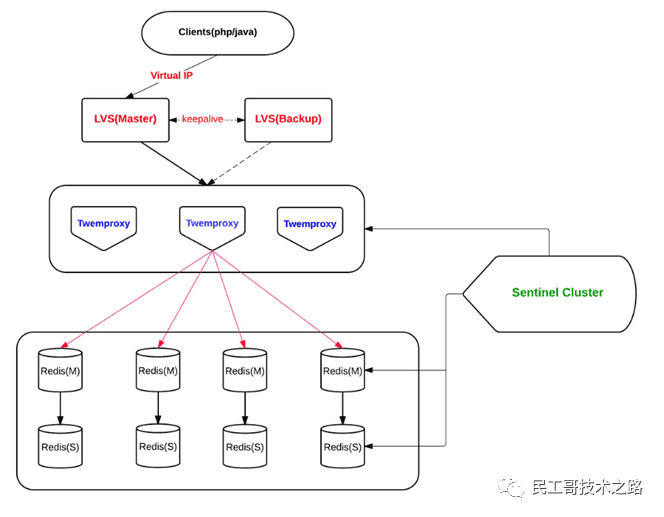
优点:
- 开发简单,对应用几乎透明
- 历史悠久,方案成熟
缺点:
- 代理影响性能
- LVS 和 Twemproxy 会有节点性能瓶颈
- Redis 扩容非常麻烦
- Twitter 内部已放弃使用该方案,新使用的架构未开源
Codis
Codis 是由豌豆荚开源的产品,涉及组件众多,其中 ZooKeeper 存放路由表和代理节点元数据、分发 Codis-Config 的命令;Codis-Config 是集成管理工具,有 Web 界面供使用;Codis-Proxy 是一个兼容 Redis 协议的无状态代理;Codis-Redis 基于 Redis 2.8 版本二次开发,加入 slot 支持,方便迁移数据。
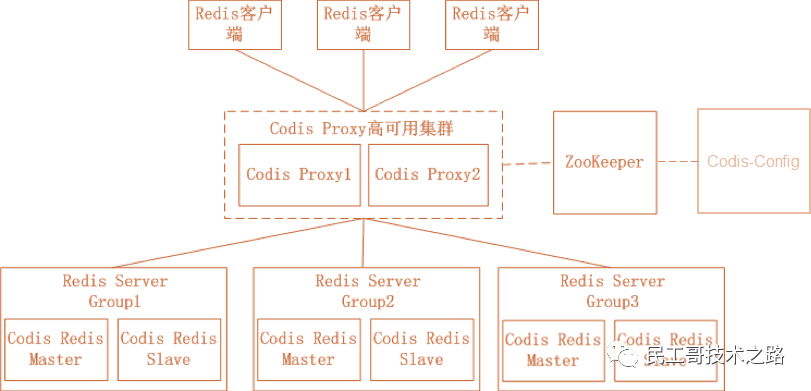
优点:
- 开发简单,对应用几乎透明
- 性能比 Twemproxy 好
- 有图形化界面,扩容容易,运维方便
缺点:
- 代理依旧影响性能
- 组件过多,需要很多机器资源
- 修改了 Redis 代码,导致和官方无法同步,新特性跟进缓慢
- 开发团队准备主推基于 Redis 改造的 reborndb
链接:
https://pdai.tech/md/db/nosql-redis/db-redis-x-cluster.html
(十一):Redis Cluster 交叉复制与故障切换实战
cluster 集群架构图
通过hash分配数据分片到不同的redis主机。
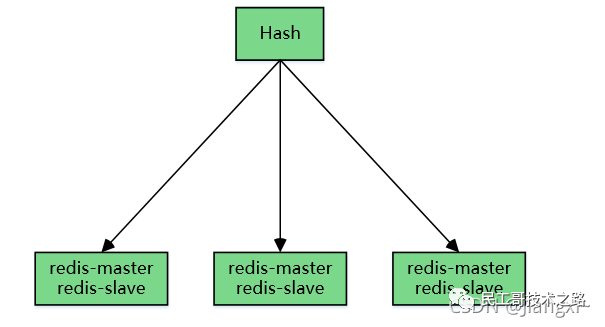
在应用端配置redis cluster地址时需要将所有节点的ip和端口都添加上。
使用cluster集群创建的key,在哪个节点上创建的只能是自身节点可以查到数据,其他节点看不到。
redis cluster不合理的架构图
不太合理的架构图
cluster集群每个机器上都有多个master和slave,如果master节点的数据备份都在自己主机的slave上,那么当服务器1坏掉后,这个机器上的数据就丢失了,数据丢失整个应用就崩溃了。
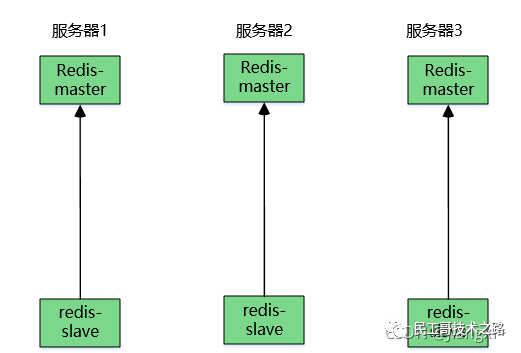
合理的架构图
每个节点slave都存放在别的主机,即使当前主机挂掉,另一台直接还原数据即可。
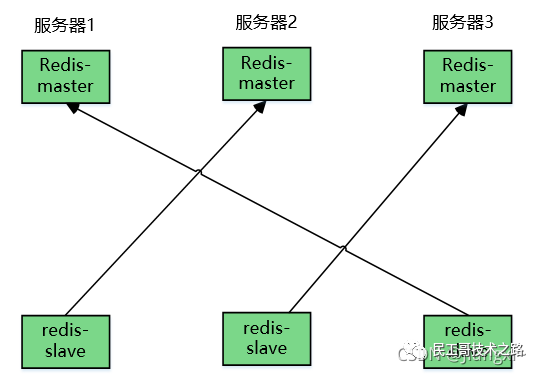
部署一个cluster三主三从集群具体步骤
- 在三台主机上部署redis,分别启动两个不同端口的redis,一个主库一个从库
- 配置cluster集群自动发现,使得集群中各个主机都知道其他主机上的redis节点
- 配置集群hash分配槽位,有了槽位才可以存储数据
- 使用cluster replicate使多出来的三个主库变成从库,这样就实现了三主三从
环境准备
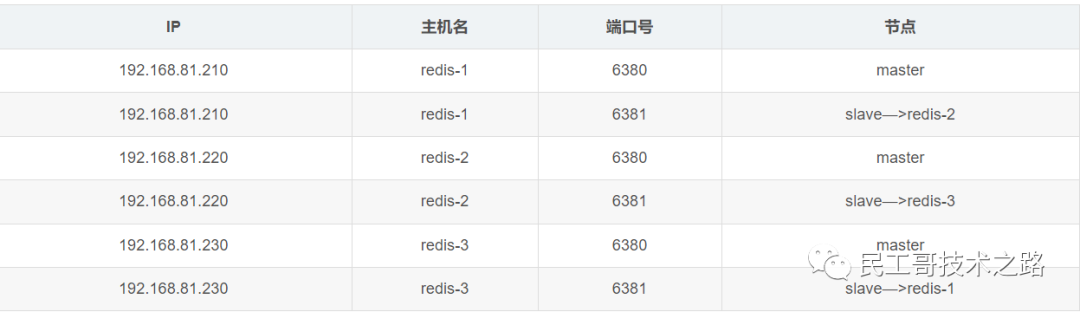
部署redis cluster节点
搭建一个三主三从的redis cluster集群。配置文件中的bind也可以写成如下样子,自动识别bind地址。
bind $(ifconfig | awk 'NR==2{print $2}')
配置文件含义
port 6380 //redis端口
daemonize yes //后台启动
logfile /data/redis_cluster/redis_6380/logs/redis_6380.log //日志路径
pidfile /data/redis_cluster/redis_6380/pid/redis_6380.log //pid存放路径
dbfilename “redis_6380.rdb” //数据文件名称
dir /data/redis_cluster/redis_6380/data //数据文件存放目录
cluster-enabled yes //开启集群模式
cluster-config-file node_6380.conf //集群数据文件路径,保存集群信息的文件
cluster-node-timeout 15000 //集群故障转移时间,多长时间无响应就切
redis-1配置
配置文件自动识别bind地址
#创建节点配置文件路径
[root@redis-1 ~]# mkdir -p /data/redis_cluster/redis_{6380,6381}/{conf,data,logs,pid}
#准备两个配置文件一个6380,一个6381
[root@redis-1 ~]# cat > /data/redis_cluster/redis_6380/conf/redis_6380.conf <<EOF
bind $(ifconfig | awk 'NR==2{print $2}')
port 6380
daemonize yes
logfile /data/redis_cluster/redis_6380/logs/redis_6380.log
pidfile /data/redis_cluster/redis_6380/pid/redis_6380.log
dbfilename "redis_6380.rdb"
dir /data/redis_cluster/redis_6380/data
cluster-enabled yes
cluster-config-file node_6380.conf
cluster-node-timeout 15000
EOF
[root@redis-1 ~]# cat > /data/redis_cluster/redis_6381/conf/redis_6381.conf <<EOF
bind $(ifconfig | awk 'NR==2{print $2}')
port 6381
daemonize yes
logfile /data/redis_cluster/redis_6381/logs/redis_6381.log
pidfile /data/redis_cluster/redis_6381/pid/redis_6381.log
dbfilename "redis_6381.rdb"
dir /data/redis_cluster/redis_6381/data
cluster-enabled yes
cluster-config-file node_6381.conf
cluster-node-timeout 15000
EOF
#启动rediscluster
[root@redis-1 ~]# redis-server /data/redis_cluster/redis_6380/conf/redis_6380.conf
[root@redis-1 ~]# redis-server /data/redis_cluster/redis_6381/conf/redis_6381.conf
#查看进程和端口
[root@redis-1 ~]# ps aux | grep redis
[root@redis-1 ~]# netstat -lnpt | grep redis
redis-2配置
配置文件自动识别bind地址
[root@redis-2 ~]# mkdir -p /data/redis_cluster/redis_{6380,6381}/{conf,data,logs,pid}
[root@redis-2 ~]# cat > /data/redis_cluster/redis_6380/conf/redis_6380.conf <<EOF
bind $(ifconfig | awk 'NR==2{print $2}')
port 6380
daemonize yes
logfile /data/redis_cluster/redis_6380/logs/redis_6380.log
pidfile /data/redis_cluster/redis_6380/pid/redis_6380.log
dbfilename "redis_6380.rdb"
dir /data/redis_cluster/redis_6380/data
cluster-enabled yes
cluster-config-file node_6380.conf
cluster-node-timeout 15000
EOF
[root@redis-2 ~]# cat > /data/redis_cluster/redis_6381/conf/redis_6381.conf <<EOF
bind $(ifconfig | awk 'NR==2{print $2}')
port 6381
daemonize yes
logfile /data/redis_cluster/redis_6381/logs/redis_6381.log
pidfile /data/redis_cluster/redis_6381/pid/redis_6381.log
dbfilename "redis_6381.rdb"
dir /data/redis_cluster/redis_6381/data
cluster-enabled yes
cluster-config-file node_6381.conf
cluster-node-timeout 15000
EOF
[root@redis-2 ~]#
[root@redis-2 ~]# redis-server /data/redis_cluster/redis_6380/conf/redis_6380.conf
[root@redis-2 ~]# redis-server /data/redis_cluster/redis_6381/conf/redis_6381.conf
[root@redis-2 ~]#
[root@redis-2 ~]# ps aux | grep redis
[root@redis-2 ~]# netstat -lnpt | grep redis
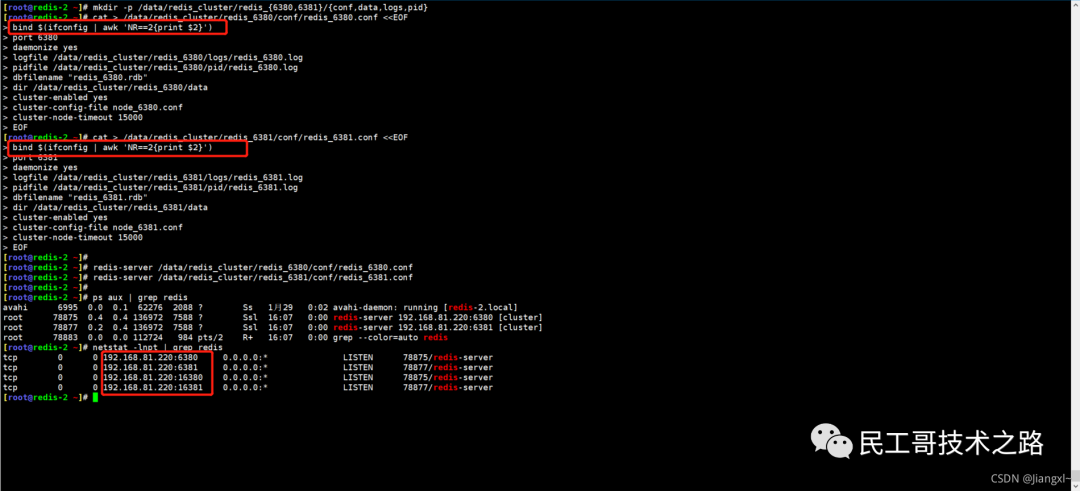
redis-3配置
手动填写bind ip地址
[root@redis-3 ~]# mkdir -p /data/redis_cluster/redis_{6380,6381}/{conf,data,logs,pid}
[root@redis-3 ~]# cat > /data/redis_cluster/redis_6380/conf/redis_6380.conf <<EOF
bind 192.168.81.230
port 6380
daemonize yes
logfile /data/redis_cluster/redis_6380/logs/redis_6380.log
pidfile /data/redis_cluster/redis_6380/pid/redis_6380.log
dbfilename "redis_6380.rdb"
dir /data/redis_cluster/redis_6380/data
cluster-enabled yes
cluster-config-file node_6380.conf
cluster-node-timeout 15000
EOF
[root@redis-3 ~]# cat > /data/redis_cluster/redis_6381/conf/redis_6381.conf <<EOF
bind 192.168.81.230
port 6381
daemonize yes
logfile /data/redis_cluster/redis_6381/logs/redis_6381.log
pidfile /data/redis_cluster/redis_6381/pid/redis_6381.log
dbfilename "redis_6381.rdb"
dir /data/redis_cluster/redis_6381/data
cluster-enabled yes
cluster-config-file node_6381.conf
cluster-node-timeout 15000
EOF
[root@redis-3 ~]#
[root@redis-3 ~]# redis-server /data/redis_cluster/redis_6380/conf/redis_6380.conf
[root@redis-3 ~]# redis-server /data/redis_cluster/redis_6381/conf/redis_6381.conf
[root@redis-3 ~]#
[root@redis-3 ~]# ps aux | grep redis
[root@redis-3 ~]# netstat -lnpt | grep redis
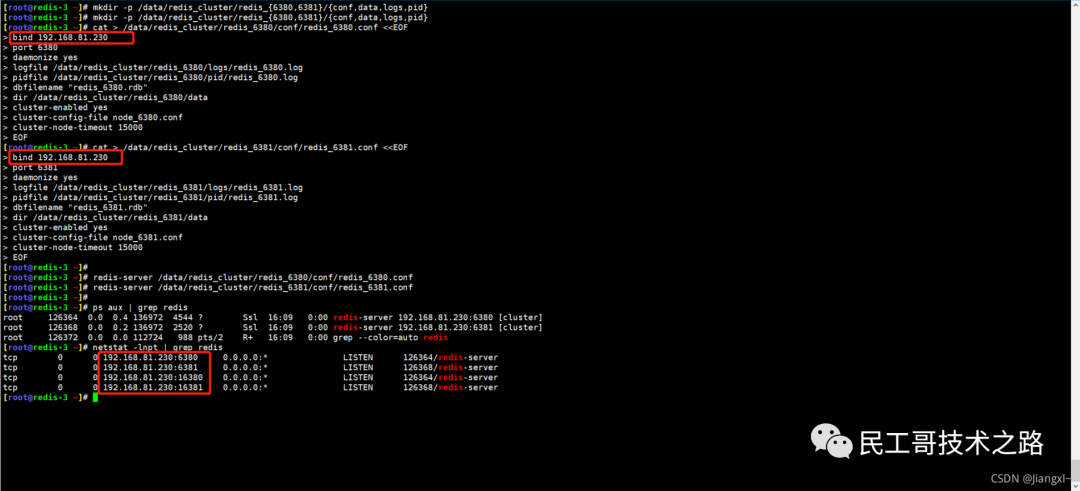
查看redis cluster进程
每个节点启动了cluster后,进程名上会增加cluster。
每个redis节点会开放两个端口,服务端口6380,集群通信端口16380(在服务端口基础上增加10000)。
#查看进程
[root@redis-1 ~]# ps aux | grep redis
avahi 6935 0.0 0.1 62272 2296 ? Ss 1月29 0:02 avahi-daemon: running [redis-1.local]
root 31846 0.3 0.5 141068 10800 ? Ssl 1月30 10:13 redis-server 192.168.81.210:6379
root 31859 0.3 0.4 136972 7744 ? Ssl 1月30 11:43 redis-sentinel 192.168.81.210:26379 [sentinel]
root 78126 0.2 0.4 136972 7584 ? Ssl 14:40 0:00 redis-server 192.168.81.210:6380 [cluster]
root 78130 0.4 0.4 136972 7588 ? Ssl 14:40 0:00 redis-server 192.168.81.210:6381 [cluster]
root 78136 0.0 0.0 112728 988 pts/2 R+ 14:40 0:00 grep --color=auto redis
[root@redis-1 ~]# netstat -lnpt | grep redis
tcp 0 0 192.168.81.210:26379 0.0.0.0:* LISTEN 31859/redis-sentine
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 31846/redis-server
tcp 0 0 192.168.81.210:6379 0.0.0.0:* LISTEN 31846/redis-server
tcp 0 0 192.168.81.210:6380 0.0.0.0:* LISTEN 78126/redis-server
tcp 0 0 192.168.81.210:6381 0.0.0.0:* LISTEN 78130/redis-server
tcp 0 0 192.168.81.210:16380 0.0.0.0:* LISTEN 78126/redis-server
tcp 0 0 192.168.81.210:16381 0.0.0.0:* LISTEN 78130/redis-server
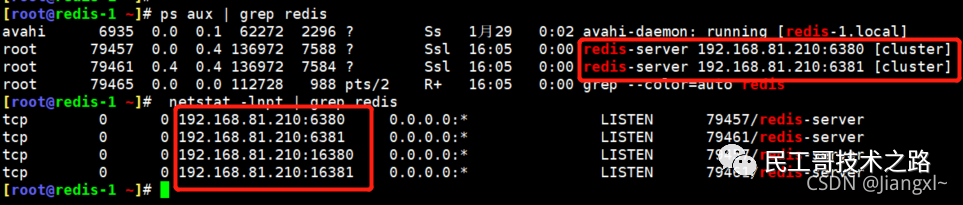
查看集群信息文件内容
集群模式的redis除了原有的配置文件之外又增加了一个集群配置文件,当集群内节点信息发生变化时,如添加节点,节点下线,故障转移等,节点都会自动保存集群状态到配置文件,redis自动维护集群配置文件,不需要手动修改防止节点重启时产生错乱。
在集群启动后会生成一个数据文件,这个数据文件其实保存的就是集群的信息,在没有配置集群互相发现时,单个节点只保存自己的集群信息,文件中有节点id信息,每个节点的id都是唯一的。
当配置了互相发现了配置文件中就会增加所有节点的信息。
[root@redis-1 ~]# cat /data/redis_cluster/redis_6380/data/node_6380.conf
b7748aedb5e51921db67c54e0c6263ed28043948 :0 myself,master - 0 0 0 connected
vars currentEpoch 0 lastVoteEpoch 0
[root@redis-1 ~]# cat /data/redis_cluster/redis_6381/data/node_6381.conf
1ec79d498ecf9f272373740e402398e4c69cacb2 :0 myself,master - 0 0 0 connected
vars currentEpoch 0 lastVoteEpoch 0
也可以登录redis进行查看
[root@redis-1 ~]# for i in {1..3}
do
for j in {0..1}
do
echo "192.168.81.2${i}0---638${j}"
redis-cli -h 192.168.81.2${i}0 -p 638${j} cluster nodes
done
done
192.168.81.210---6380
b7748aedb5e51921db67c54e0c6263ed28043948 :6380 myself,master - 0 0 0 connected
192.168.81.210---6381
1ec79d498ecf9f272373740e402398e4c69cacb2 :6381 myself,master - 0 0 0 connected
192.168.81.220---6380
87ea6206f3db1dbaa49522bed15aed6f3bf16e22 :6380 myself,master - 0 0 0 connected
192.168.81.220---6381
bedd9482b08a06b0678fba01bb1c24165e56636c :6381 myself,master - 0 0 0 connected
192.168.81.230---6380
759ad5659d449dc97066480e1b7efbc10b34461d :6380 myself,master - 0 0 0 connected
192.168.81.230---6381
a2c95db5d6f9f288e6768c8d00e90fb7631f3021 :6381 myself,master - 0 0 0 connected
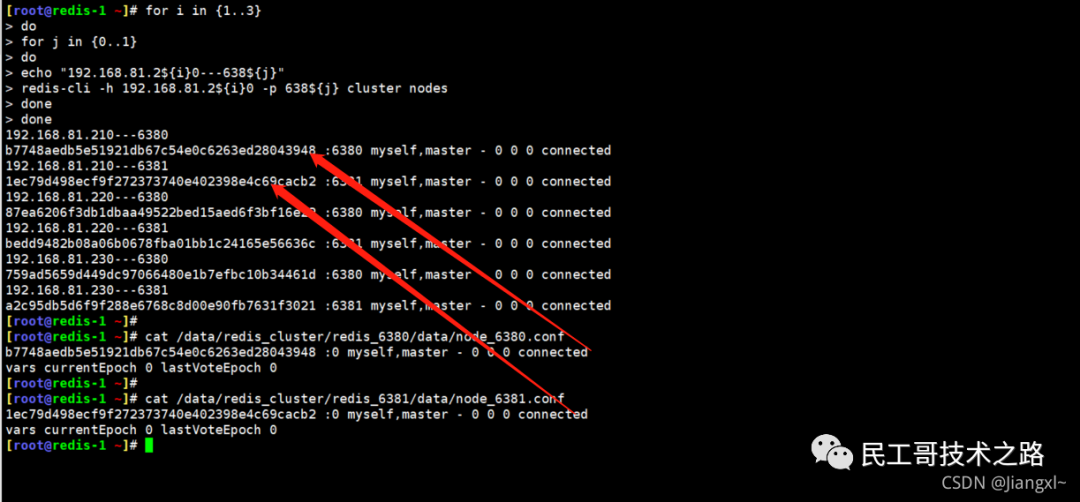
更多关于 Redis 学习的文章,请参阅:NoSQL 数据库系列之 Redis,本系列持续更新中。
配置cluster集群互相发现
互相发现概念
cluster集群互相发现只需要在一个节点上配置,所有节点都会接收到配置信息并自动加入到配置文件中。
例如在redis-1的6380节点上增加了本机的6381端口和redis-2的6380端口,这时在redis-2上查看6380的配置里面就能看到6380节点和redis-1的6380以及6381节点信息,这时redis-3的两个节点还有本机的6381则还是一条,因为他们没有加入。
在哪个节点添加的发现另一个节点的信息,那么当前这个节点就已经加入到了集群中。
其实只要在集群的任意一个节点配置,集群的所有节点都会自动添加配置。
下面演示一个在reids-1上添加几个节点,在redis-2上看是否自动配置。
#在redis-1的6380节点上增加本机的6381和redis-2的6380端口
[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6380
192.168.81.210:6380> CLUSTER MEET 192.168.81.210 6381
OK
192.168.81.210:6380> CLUSTER MEET 192.168.81.220 6380
OK
#查看redis-2的6380集群配置文件
[root@redis-2 ~]# cat /data/redis_cluster/redis_6380/data/node_6380.conf
1ec79d498ecf9f272373740e402398e4c69cacb2 192.168.81.210:6381 master - 0 1612169525469 1 connected
b7748aedb5e51921db67c54e0c6263ed28043948 192.168.81.210:6380 master - 0 1612169525369 0 connected
87ea6206f3db1dbaa49522bed15aed6f3bf16e22 192.168.81.220:6380 myself,master - 0 0 2 connected
vars currentEpoch 2 lastVoteEpoch 0
很明显的看出已经将redis-1的6380和6381以及redis-2本机的6380端口都加到了集群配置文件中
#查看redis-2的6381节点集群配置文件
[root@redis-2 ~]# cat /data/redis_cluster/redis_6381/data/node_6381.conf
bedd9482b08a06b0678fba01bb1c24165e56636c :0 myself,master - 0 0 0 connected
vars currentEpoch 0 lastVoteEpoch 0
将集群的所有节点进行互相发现
在集群的任意一个节点配置就可以
#配置互相发现
[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6380
192.168.81.210:6380> CLUSTER MEET 192.168.81.210 6381
OK
192.168.81.210:6380> CLUSTER MEET 192.168.81.220 6380
OK
192.168.81.210:6380> CLUSTER MEET 192.168.81.220 6381
OK
192.168.81.210:6380> CLUSTER MEET 192.168.81.230 6380
OK
192.168.81.210:6380> CLUSTER MEET 192.168.81.230 6381
OK
#查看配置文件是否增加,所有节点的配置文件都会生成
[root@redis-1 ~]# cat /data/redis_cluster/redis_6381/data/node_6381.conf
759ad5659d449dc97066480e1b7efbc10b34461d 192.168.81.230:6380 master - 0 1612169812886 4 connected
1ec79d498ecf9f272373740e402398e4c69cacb2 192.168.81.210:6381 myself,master - 0 0 1 connected
87ea6206f3db1dbaa49522bed15aed6f3bf16e22 192.168.81.220:6380 master - 0 1612169814797 2 connected
bedd9482b08a06b0678fba01bb1c24165e56636c 192.168.81.220:6381 master - 0 1612169815806 0 connected
a2c95db5d6f9f288e6768c8d00e90fb7631f3021 192.168.81.230:6381 master - 0 1612169815708 5 connected
b7748aedb5e51921db67c54e0c6263ed28043948 192.168.81.210:6380 master - 0 1612169816814 3 connected
vars currentEpoch 5 lastVoteEpoch 0
cluster集群分配操作
redis cluster通讯流程
集群内消息传递是同步的
在分布式存储中需要提供维护节点元数据信息的机制,所谓元数据是指:节点负责哪些数据,是否出现故障灯状态信息,redis集群采用gossip协议,gossip协议工作原理就是节点彼此不断交换信息,一段时间后所有的节点偶会指定集群完整信息,这种方式类似于流言传播,因此只需要在一台节点配置集群信息所有节点都能收到信息
通信过程:
1.集群中的每一个节点都会单独开辟一个tcp通道用于节点之间彼此通信,通信端口在基础端口上增加10000
2.每个节点在固定周期内通过特定规则选择结构节点发送ping消息
3.接收到ping消息的节点用pong作为消息响应,集群中每个节点通过一定规则挑选要通信的节点,每个节点可能知道全部节点的信息,也可能知道部分节点信息,只要这些节点彼此可以正常通信,最终他们就会达成一致的状态,当节点出现故障,新节点加入,主从角色变化等,彼此之间不断发生ping/pong消息,最终达成同步的模板
通讯消息类型:gossip,信息交换,常见的消息分为ping、pong、meet、fail。
通讯示意图
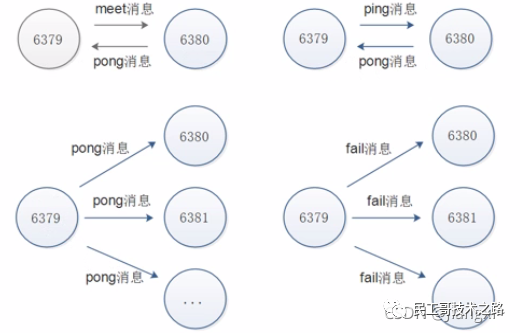
没有分配槽位时集群的状态,所有节点执行cluster info,cluster_state都是fail,fail状态表示集群不可用,没有分配槽位,cluster_slots都会显示0。
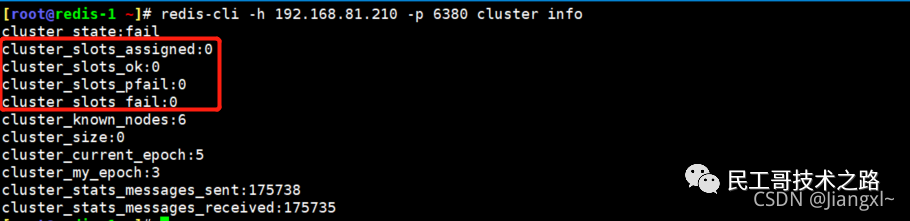
手动配置集群槽位
每个cluster集群都有16384个槽位,我们有三台机器,想要手动分配平均就需要使用16384除3。
redis-1 0-5461
redis-2 5462-10922
redis-3 10923-16383
分配槽位语法格式(交互式):CLUSTER ADDSLOTS 0 5461。
分配槽位语法:redis-cli -h 192.168.81.210 -p 6380 cluster addslots {0…5461}。
删除槽位分配语法格式:redis-cli -h 192.168.81.210 -p 6380 cluster delslots {5463…10921}。
#配置手动分配槽位
[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6380 cluster addslots {0..5461}
OK
[root@redis-1 ~]# redis-cli -h 192.168.81.220 -p 6380 cluster addslots {5462..10922}
OK
[root@redis-1 ~]# redis-cli -h 192.168.81.230 -p 6380 cluster addslots {10923..16383}
OK
#查看集群状态,到目前为止集群已经是可用的了
[root@redis-1 ~]# redis-cli -h 192.168.81.220 -p 6380 cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:5
cluster_my_epoch:2
cluster_stats_messages_sent:170143
cluster_stats_messages_received:170142
#查看nodes文件内容
[root@redis-1 ~]# redis-cli -h 192.168.81.220 -p 6380 cluster nodes
a2c95db5d6f9f288e6768c8d00e90fb7631f3021 192.168.81.230:6381 master - 0 1612251539412 5 connected
bedd9482b08a06b0678fba01bb1c24165e56636c 192.168.81.220:6381 master - 0 1612251538402 0 connected
87ea6206f3db1dbaa49522bed15aed6f3bf16e22 192.168.81.220:6380 myself,master - 0 0 2 connected 5462-10922
b7748aedb5e51921db67c54e0c6263ed28043948 192.168.81.210:6380 master - 0 1612251540418 3 connected 0-5461
1ec79d498ecf9f272373740e402398e4c69cacb2 192.168.81.210:6381 master - 0 1612251537394 1 connected
759ad5659d449dc97066480e1b7efbc10b34461d 192.168.81.230:6380 master - 0 1612251536386 4 connected 10923-16383
创建key验证集群是否可用
不是所有的key都能插入,有的key插入的时候就提示说你应该去192.168.81.230上插入,这时手动到对应的主机上执行就可以插入,这是由于cluster集群槽位都是分布在不同节点的,每次新建一个key,都会通过hash算法均匀的在不同节点去创建
不同节点创建的key只由自己节点可以看到自己创建的数据
[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6380
192.168.81.210:6380> set k1 v1
(error) MOVED 12706 192.168.81.230:6380
192.168.81.210:6380> set k2 v2
OK
192.168.81.210:6380> set k3 v3
OK
192.168.81.210:6380> set k4 v4
(error) MOVED 8455 192.168.81.220:6380
192.168.81.210:6380> set k5 v5
(error) MOVED 12582 192.168.81.230:6380
192.168.81.210:6380> set k6 v6
OK
[root@redis-1 ~]# redis-cli -h 192.168.81.230 -p 6380
192.168.81.230:6380> set k1 v1
OK
192.168.81.230:6380> set k5 v5
OK
[root@redis-1 ~]# redis-cli -h 192.168.81.220 -p 6380
192.168.81.220:6380> set k4 v4
OK
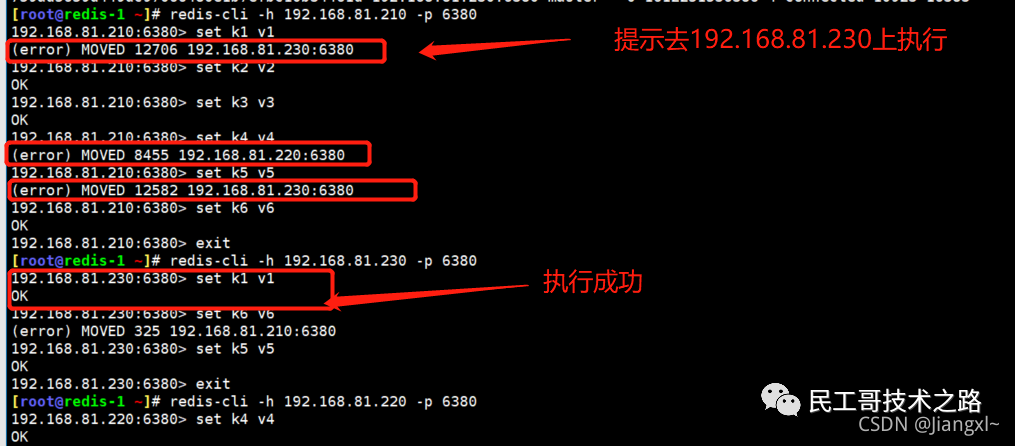
ASK路由解决key创建提示去别的主机创建
可以通过ASK路由解决创建key时提示去别的主机进行创建。
ASK路由创建key时,如果可以在本机直接创建就会执行创建key的命令,如果不能再本机执行,他会根据提示的主机去对应主机上创建key。
ASK路径的特性:每次通过hash在指定主机上创建了key后就会停留在这个主机上。
只需要执行redis-cli时加上-c参数即可。
[root@redis-1 ~]# redis-cli -c -h 192.168.81.210 -p 6380
192.168.81.210:6380> set k8 v8
-> Redirected to slot [8331] located at 192.168.81.220:6380
OK
192.168.81.220:6380> set k9 v9
-> Redirected to slot [12458] located at 192.168.81.230:6380
OK
192.168.81.230:6380> set k10 v10
OK
192.168.81.230:6380> set k11 v11
OK
192.168.81.230:6380> set k12 v12
-> Redirected to slot [2863] located at 192.168.81.210:6380
OK
192.168.81.210:6380> set k13 v13
-> Redirected to slot [6926] located at 192.168.81.220:6380
OK
192.168.81.220:6380> set k14 v14
-> Redirected to slot [11241] located at 192.168.81.230:6380
OK
#很清楚的展示了在哪台主机上创建
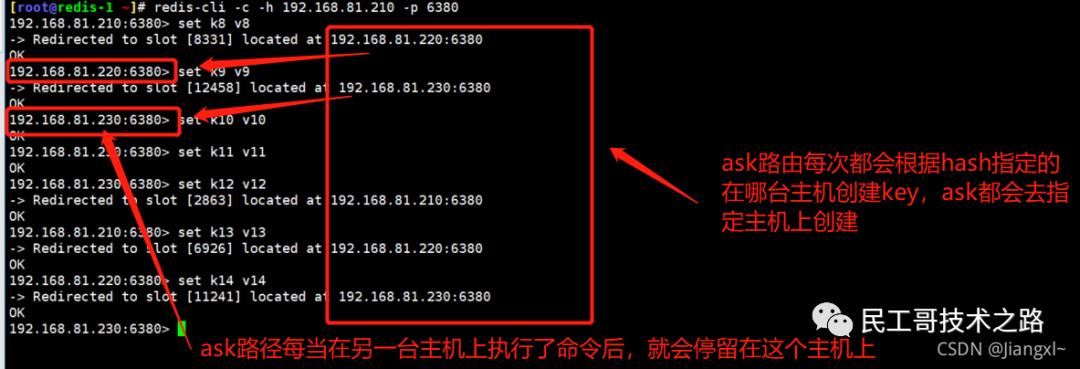
验证hash分配是否均已
cluster架构是分布式的,创建的key会通过hash将数据均已的分布在每台主机的槽位上。
#插入一千条数据,查看三个节点是否分配均已
插入的时候使用-c,自动在某个节点上插入数据
[root@redis-1 ~]# for i in {1..1000}
do
redis-cli -c -h 192.168.81.210 -p 6380 set key_${i} value_${i}
done
#查看每个节点的数据量,可以看到非常均匀,误差只有一点点
[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6380
192.168.81.210:6380> DBSIZE
(integer) 339
[root@redis-1 ~]# redis-cli -h 192.168.81.220 -p 6380
192.168.81.220:6380> DBSIZE
(integer) 339
[root@redis-1 ~]# redis-cli -h 192.168.81.230 -p 6380
192.168.81.230:6380> DBSIZE
(integer) 336
192.168.81.230:6380> exit
配置cluster集群三主三从高可用
实现步骤
- 使用cluster replicate将主机的6381redis节点交叉成为别的主机6380节点的从库
- 查看集群状态即可
三主三从架构图
三主三从是redis cluster最常用的架构,每个从节点复制的都不是本机主库的数据,而是其他节点主库的数据,这样即使某一台主机坏掉了,从节点备份还是在其他机器上,这样就做到了高可用,三主三从架构允许最多坏一台主机。
三主三从我们采用交叉复制架构类型,这样可以做到最多坏一台主机集群还是正常可以用的,如果每台主机的6381节点都是6380节点的备份,那么这台机器坏了,集群就不可用了,因此想要做到高可用,就采用交叉复制。
交叉复制的架构,当主节点挂掉了,主节点备份的从节点就会自动成为主节点,当主节点上线后。
每个节点的6380端口都是主库,6381端口都是从库。
从节点对应的主节点关系
- redis-1的6381从节点对应的主节点是redis-2的6380主节点
- redis-2的6381从节点对应的主节点是redis-3的6380主节点
- redis-3的6381从节点对应的主节点是redis-1的6380主节点
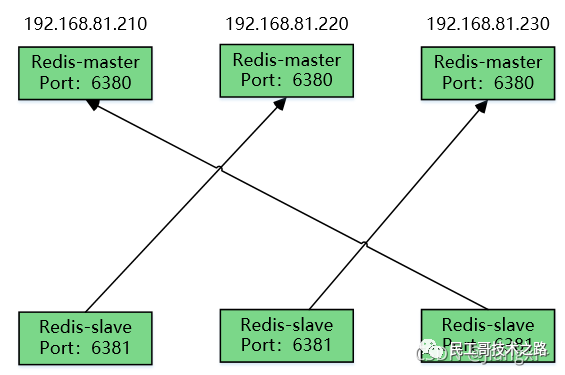
将每一个节点都配置rdb持久化
在所有节点端口的配置文件中加上rdb持久化配置即可。
vim /data/redis_cluster/redis_6380/conf/redis_6380.conf
bind 192.168.81.210
port 6380
daemonize yes
logfile /data/redis_cluster/redis_6380/logs/redis_6380.log
pidfile /data/redis_cluster/redis_6380/pid/redis_6380.log
dbfilename "redis_6380.rdb"
dir /data/redis_cluster/redis_6380/data
cluster-enabled yes
cluster-config-file node_6380.conf
cluster-node-timeout 15000
#持久化配置
save 60 10000
save 300 10
save 900 1
重启redis
redis-cli -h 192.168.81.210 -p 6380 shutdown
redis-server /data/redis_cluster/redis_6380/conf/redis_6380.conf
配置三主三从
配置三主三从规范操作步骤
- 将集群信息粘到txt中,只保留下6380端口信息
- 配置命令在txt中准备好在复制到命令行
主节点我们已经有了,目前6个节点全是主节点,我们需要把所有主机的6381的主节点配置成从节点。
从节点对应的主节点关系:
- redis-1的6381从节点对应的主节点是redis-2的6380主节点
- redis-2的6381从节点对应的主节点是redis-3的6380主节点
- redis-3的6381从节点对应的主节点是redis-1的6380主节点
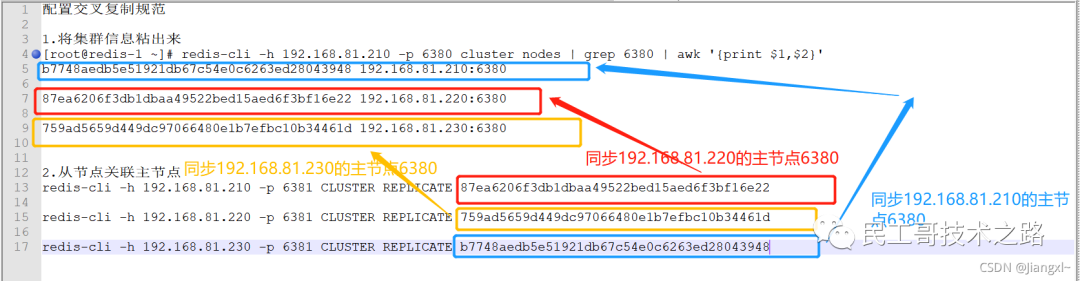
CLUSTER REPLICATE 是配置当前节点成为某个主节点的从节点,replicate命令其实就相当于执行了slaveof,同步了某一个主库,并且在日志中查看到的就是主从同步的过程
#配置从节点连接主节点,交叉式复制
[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6381 CLUSTER REPLICATE 87ea6206f3db1dbaa49522bed15aed6f3bf16e22
OK
[root@redis-1 ~]# redis-cli -h 192.168.81.220 -p 6381 CLUSTER REPLICATE 759ad5659d449dc97066480e1b7efbc10b34461d
OK
[root@redis-1 ~]# redis-cli -h 192.168.81.230 -p 6381 CLUSTER REPLICATE b7748aedb5e51921db67c54e0c6263ed28043948
OK
#查看集群节点信息,发现已经是三主三从了
[root@redis-1 ~]# redis-cli -h 192.168.81.230 -p 6381 cluster nodes
a2c95db5d6f9f288e6768c8d00e90fb7631f3021 192.168.81.230:6381 myself,slave b7748aedb5e51921db67c54e0c6263ed28043948 0 0 5 connected
bedd9482b08a06b0678fba01bb1c24165e56636c 192.168.81.220:6381 slave 759ad5659d449dc97066480e1b7efbc10b34461d 0 1612323918342 4 connected
b7748aedb5e51921db67c54e0c6263ed28043948 192.168.81.210:6380 master - 0 1612323919350 3 connected 0-5461
1ec79d498ecf9f272373740e402398e4c69cacb2 192.168.81.210:6381 slave 87ea6206f3db1dbaa49522bed15aed6f3bf16e22 0 1612323917331 2 connected
759ad5659d449dc97066480e1b7efbc10b34461d 192.168.81.230:6380 master - 0 1612323916826 4 connected 10923-16383
87ea6206f3db1dbaa49522bed15aed6f3bf16e22 192.168.81.220:6380 master - 0 1612323920357 2 connected 5462-10922
配置完主从,可以看到集群中已经有slave节点了,并且也是交叉复制的。
打开主库的日志可以看到哪个从库同步了主库的日志,打开从库的日志可以看到同步了哪个主库的日志。
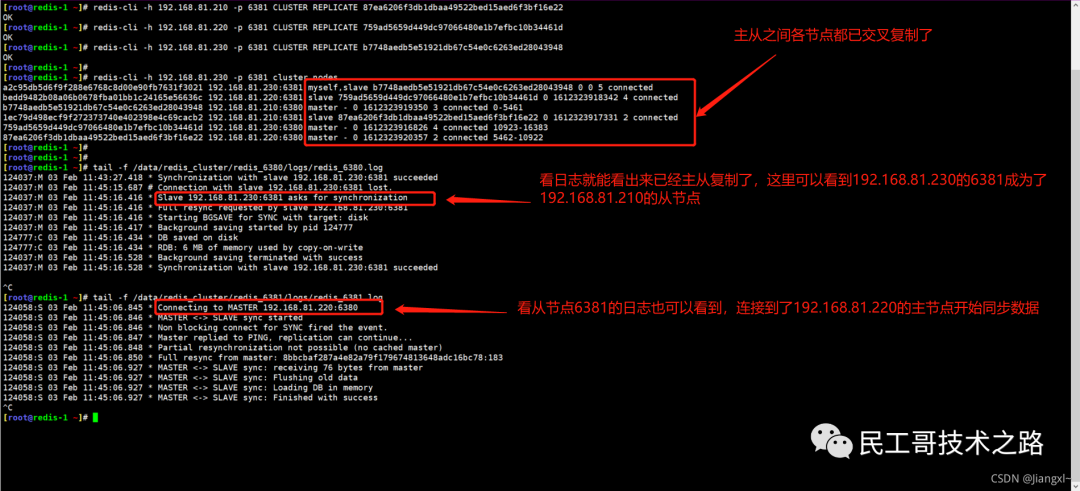
模拟故障转移
三主三从架构允许最多坏一台主机,模拟将redis-1机器的主库6380挂掉,查看集群间的故障迁移
思路 :
1.将redis-1的6380主库关掉,查看集群状态信息是否将slave自动切换为master
2.当master上线后会变成一个节点的从库
3.将master通过cluster failover重新成为主库
模拟坏掉redis-1的主库并验证就能是否可用
#挂掉redis-1的主库
[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6380 shutdown
#查看日志
先是由于主库挂了状态变成fail,当从库变成主库后,状态再次变为ok
[root@redis-1 ~]# tail -f /data/redis_cluster/redis_6381/logs/redis_6381.log
124058:S 03 Feb 13:16:00.233 # Cluster state changed: fail
124058:S 03 Feb 13:17:01.857 # Cluster state changed: ok
#查看集群信息
[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6381 cluster nodes
#查看集群状态
[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6381 cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:7
cluster_my_epoch:2
cluster_stats_messages_sent:18202
cluster_stats_messages_received:17036
#验证集群是否可用
[root@redis-1 ~]# redis-cli -c -h 192.168.81.210 -p 6381 set k1111 v1111
OK
当主库挂掉后,查看集群信息时会看到提示主库已经是fail状态,此时可用看到192.168.81.230机器的6381端口成为了master,192.168.81.230的6381端口是redis-1的从库,从库变为主库后,集群状态再次变为ok。
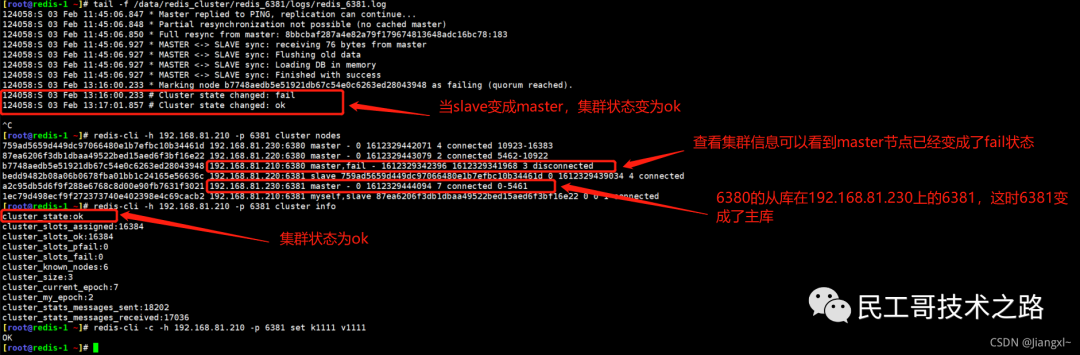
redis-1节点的主库恢复目前的架构图
当主库重新加入集群后,架构图就变成了如下样子,主库的6380就成为了192.168.81.230的从库,而192.168.81.230的从库变成了192.168.81.210的主库。
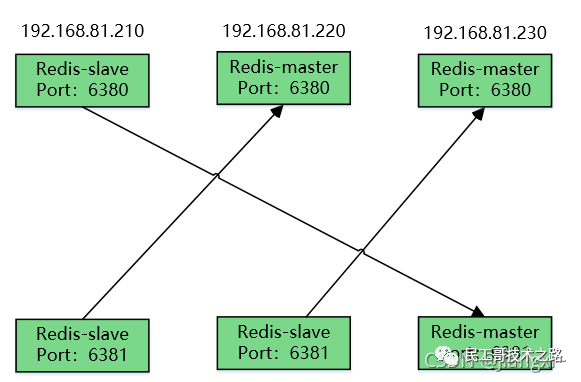
#启动redis-1的6380主库
[root@redis-1 ~]# redis-server /data/redis_cluster/redis_6380/conf/redis_6380.conf
#查看集群信息
[root@redis-1 ~]# redis-cli -c -h 192.168.81.210 -p 6380 cluster nodes
1ec79d498ecf9f272373740e402398e4c69cacb2 192.168.81.210:6381 slave 87ea6206f3db1dbaa49522bed15aed6f3bf16e22 0 1612330250901 2 connected
b7748aedb5e51921db67c54e0c6263ed28043948 192.168.81.210:6380 myself,slave a2c95db5d6f9f288e6768c8d00e90fb7631f3021 0 0 3 connected
759ad5659d449dc97066480e1b7efbc10b34461d 192.168.81.230:6380 master - 0 1612330255958 4 connected 10923-16383
bedd9482b08a06b0678fba01bb1c24165e56636c 192.168.81.220:6381 slave 759ad5659d449dc97066480e1b7efbc10b34461d 0 1612330252920 4 connected
a2c95db5d6f9f288e6768c8d00e90fb7631f3021 192.168.81.230:6381 master - 0 1612330254941 7 connected 0-5461
87ea6206f3db1dbaa49522bed15aed6f3bf16e22 192.168.81.220:6380 master - 0 1612330256960 2 connected 5462-10922
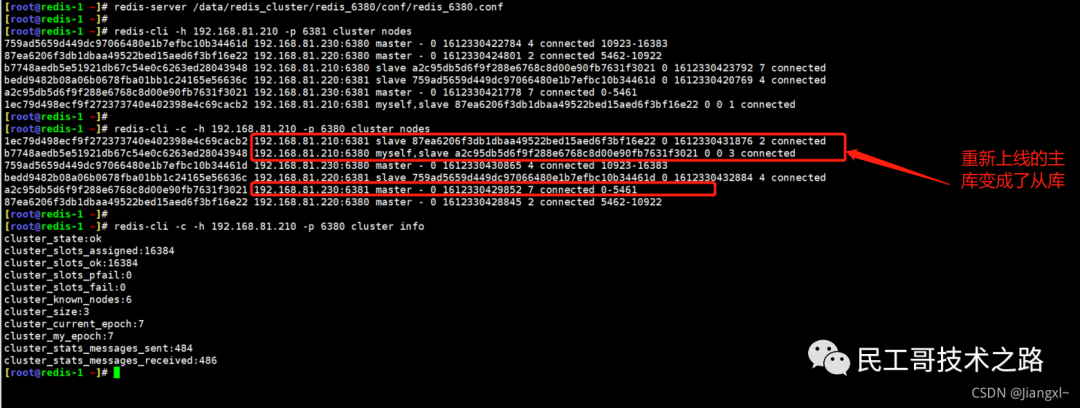
将恢的主库重新变为主库
目前主库已经重新上线了,且现在是192.168.81.230的从库,而原来192.168.81.230的从库变成了现在192.168.81.210的主库,我们需要把关系切换回来,不能让一台机器上同时存在两台主库,每次故障处理后一定要把架构修改会原来的样子。
从库切换成主库也特别简单,只需要执行一个cluster falover即可变为主库。
cluster falover确实也类似于关系互换,简单理解就是原来的从变成了主,现在的主变成了从,这样一来就可以把故障恢复的主机重新变为主库。
cluster falover原理:falover原理也就是先执行了slave no one,然后在对应的由主库变为从库的机器上执行了slave of。
#将故障上线的主库重新成为主库
[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6380
192.168.81.210:6380> CLUSTER FAILOVER
OK
#查看集群信息,192.168.81.210的发现6380重新成为了master,192.168.81.230的从库变成了slave
[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6381 cluster nodes
759ad5659d449dc97066480e1b7efbc10b34461d 192.168.81.230:6380 master - 0 1612331847795 12 connected 10923-16383
87ea6206f3db1dbaa49522bed15aed6f3bf16e22 192.168.81.220:6380 master - 0 1612331849307 11 connected 5462-10922
b7748aedb5e51921db67c54e0c6263ed28043948 192.168.81.210:6380 master - 0 1612331848299 10 connected 0-5461
bedd9482b08a06b0678fba01bb1c24165e56636c 192.168.81.220:6381 slave 759ad5659d449dc97066480e1b7efbc10b34461d 0 1612331850317 12 connected
a2c95db5d6f9f288e6768c8d00e90fb7631f3021 192.168.81.230:6381 slave b7748aedb5e51921db67c54e0c6263ed28043948 0 1612331851324 10 connected
1ec79d498ecf9f272373740e402398e4c69cacb2 192.168.81.210:6381 myself,slave 87ea6206f3db1dbaa49522bed15aed6f3bf16e22 0 0 8 connected
查看集群信息,192.168.81.210的发现6380重新成为了master,192.168.81.230的从库变成了slave。

到此cluster集群故障转移成功,集群状态一切正常。
[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6380 cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:16
cluster_my_epoch:16
cluster_stats_messages_sent:18614
cluster_stats_messages_received:3497
需要注意的几点
生产环境数据量可能非常大,当主库故障重新上线时,执行CLUSTER FAILOVER会很慢,因为这个就相当于是主从复制切换了,从库(刚上线的原来主库)关闭主从复制,主库(主库坏掉前的从库)同步从库(刚上线的原来主库)数据,然后从库(刚上线的原来主库)重新变为主库,这个时间一定要等,切记,千万不要因为慢在主库上(主库坏掉前的从库)同步手动进行了CLUSTER REPLICATE,这样确实会非常快的将主库(主库坏掉前的从库)重新变为从库,但也意味着这个节点数据全部丢失,因为clusert replicate相当于slaveof,slaveof会把自己的库清掉,这时候从库(刚上线的原来主库)在执行这CLUSTER FAILOVER同步着主库(主库坏掉前的从库)的数据,主库那边执行了replicate去同步从库(刚上线的原来主库),从而导致从库(刚上线的原来主库)还没有同步完主库(主库坏掉前的从库的数据),主库(主库坏掉前的从库)数据就丢失,整个集群还是可以用的,只是这个主库节点和从节点数据全部丢失,其他两个主库从库还能使用。
切记,当从库执行CLUSTER FAILOVER变为主库时,一定不要在主库上执行CLUSTER REPLICATE变为从库,虽然CLUSTER REPLICATE变为从库很快,但是会清空自己的数据去同步主库,这时主库还没有数据,因此就会导致数据全部丢失。
CLUSTER FAILOVER:首先执行slave on one变为一个单独的节点,然后在要变成从库的节点上执行slaveof,只要从库执行完slave of,执行CLUSTER FAILOVER的节点就变成了主库。
CLUSTER REPLICATE:只是执行了slaveof使自身成为从节点。
当redis cluster主从正在同步时,不要执行cluster replicate,当主从复制完在执行,如何看主从是否复制完就要看节点的rdb文件是否是.tmp结尾的,如果是tmp结尾就说明他们正在同步数据,此时不要对集群做切换操作
总结
- 3.0版本以后推出集群功能
- cluster集群有16384个槽位,误差在2%之间
- 槽位与序号顺序无关,重点是槽的数量
- 通过发现集群,与集群之间实现消息传递
- 配置文件无需手动修改,都是自动生成的
- 分配操作,必须将所有的槽位分配完毕
- 理清复制关系,画图,按照图形执行复制命令
- 当集群状态为ok时,集群才可以正常使用
- 反复测试,批量插入key,验证分配是否均匀
- 测试高可用,关闭任意主节点,集群是否自动转移
- 当主节点修复后,执行主从关系切换
- 做实验尽量贴合生成环境,尽量使用和生成环境一样数量的数据
- 评估和记录同步数据、故障转移完成的时间
- 向领导汇报时要有图、文档、实验环境,随时都可以演示
当应用需要连接 redis cluster 集群时要将所有节点都写在配置文件中。
来源:
https://jiangxl.blog.csdn.net/article/details/120879397
(十二):使用 Redis 官方工具自动部署 Cluster 集群实践
手动搭建集群便于理解集群创建的流程和细节 ,不过手动搭建集群需要很多步骤,当集群节点众多时,必然会加大搭建集群的复杂度和运维成本,因此 官方提供了 redis-trib.rb 的工具方便我们快速搭建集群。
redis-trib.rb是采用 Ruby 实现的 redis 集群管理工具,内部通过 Cluster相关命令帮我们简化集群创建、检查、槽迁移和均衡等常见运维操作,使用前要安装 ruby 依赖环境。
redis-trib.rb无法实现所有节点都交叉复制 ,总会有一个节点不交叉,因此在安装完cluster以后,需要手动调整交叉。
环境准备
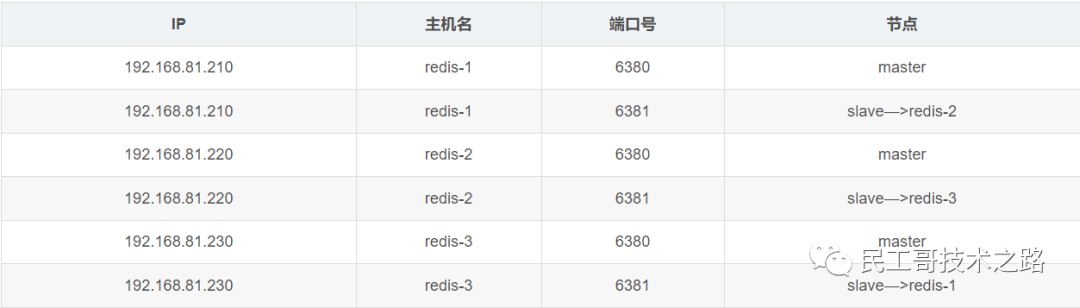
安装ruby环境
只在使用redis-trib的机器上安装即可
//安装ruby管理工具
[root@redis-1 ~]# yum -y install rubygems
//移除官网源
[root@redis-1 ~]# gem sources --remove https://rubygems.org/
https://rubygems.org/ removed from sources
//增加阿里云源
[root@redis-1 ~]# gem sources -a http://mirrors.aliyun.com/rubygems/
http://mirrors.aliyun.com/rubygems/ added to sources
//更新缓存
[root@redis-1 ~]# gem update --system
ruby2.3.0以下版本执行会报错
//安装ruby支持redis的插件
[root@redis-1 ~]# gem install redis -v 3.3.5
Fetching: redis-3.3.5.gem (100%)
Successfully installed redis-3.3.5
Parsing documentation for redis-3.3.5
Installing ri documentation for redis-3.3.5
1 gem installed
使用redis-trib自动部署cluster集群
所有节点安装redis
#创建部署路径
mkdir -p /data/redis_cluster/redis_{6380,6381}/{conf,data,logs,pid}
#准备配置文件
cat > /data/redis_cluster/redis_6380/conf/redis_6380.conf <<EOF
bind $(ifconfig | awk 'NR==2{print $2}')
port 6380
daemonize yes
logfile /data/redis_cluster/redis_6380/logs/redis_6380.log
pidfile /data/redis_cluster/redis_6380/pid/redis_6380.log
dbfilename "redis_6380.rdb"
dir /data/redis_cluster/redis_6380/data
cluster-enabled yes
cluster-config-file node_6380.conf
cluster-node-timeout 15000
save 60 10000
save 300 10
save 900 1
EOF
cat > /data/redis_cluster/redis_6381/conf/redis_6381.conf <<EOF
bind $(ifconfig | awk 'NR==2{print $2}')
port 6381
daemonize yes
logfile /data/redis_cluster/redis_6381/logs/redis_6381.log
pidfile /data/redis_cluster/redis_6381/pid/redis_6381.log
dbfilename "redis_6381.rdb"
dir /data/redis_cluster/redis_6381/data
cluster-enabled yes
cluster-config-file node_6381.conf
cluster-node-timeout 15000
save 60 10000
save 300 10
save 900 1
EOF
#启动redis
./redis_shell.sh start 6380
./redis_shell.sh start 6381
使用redis-trib部署cluster集群
语法格式: ./redis-trib.rb create --replicas 每个主节点的副本数量(从库数量) cluster节点地址
create //创建
–replicas //指定主库的副本数量,也就是从库数量
使用redis-trib安装的cluster集群,总会有一个节点不是交叉复制的,需要手动调整,因为trib也是根据节点地址交叉对应,到了最后一个机器已经没有第二个可以与它交叉的机器,它只能和自己去复制
[root@redis-1 ~]# cd /data/redis_cluster/redis-3.2.9/src
[root@redis-1 /data/redis_cluster/redis-3.2.9/src]# ./redis-trib.rb create --replicas 1 192.168.81.210:6380 192.168.81.220:6380 192.168.81.230:6380 192.168.81.210:6381 192.168.81.220:6381 192.168.81.230:6381
#安装完查看集群准备已经是可用的
[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6380
192.168.81.210:6380> CLUSTER info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:6
cluster_my_epoch:1
cluster_stats_messages_sent:1618
cluster_stats_messages_received:1618
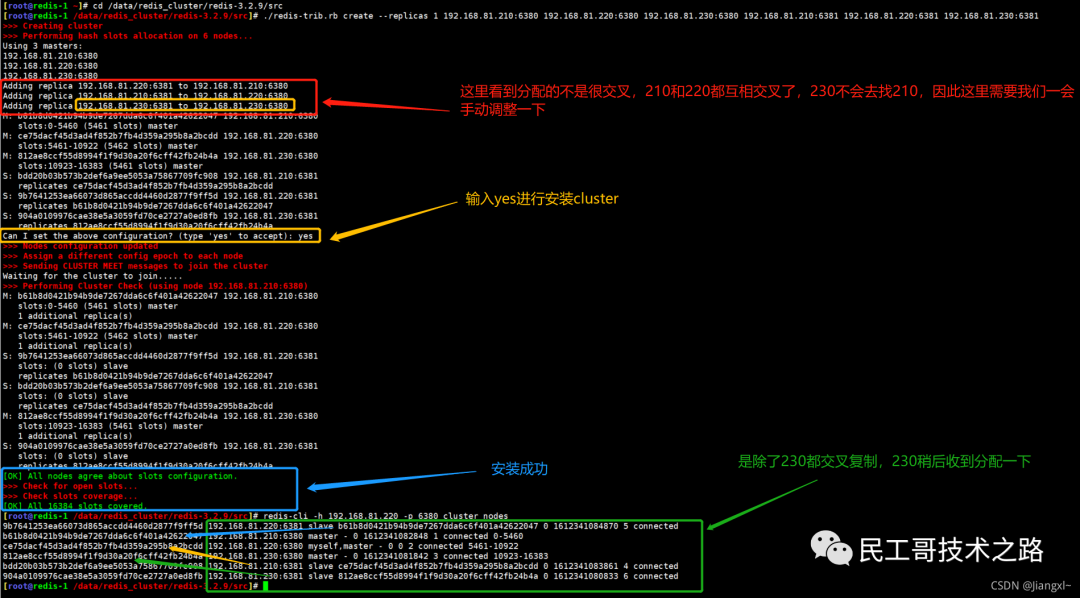
手动调整三主三从交叉复制
由于只有redis-3的复制不是交叉的,如果直接让redis-3去交叉复制某一个节点,那么就没有节点去复制redis-3的6380了,因此我们要手动调整所有节点之间的交叉入职
举个例子:redis-3的6381要成为redis-1的6380的主库,需要去redis-3的6381redis交互式操作
#获取主节点的信息
[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6381 cluster nodes | grep 6380 | awk '{print $1.$2}'
812ae8ccf55d8994f1f9d30a20f6cff42fb24b4a192.168.81.230:6380
ce75dacf45d3ad4f852b7fb4d359a295b8a2bcdd192.168.81.220:6380
b61b8d0421b94b9de7267dda6c6f401a42622047192.168.81.210:6380
#配置三主三从交叉复制
[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6381
192.168.81.210:6381> CLUSTER REPLICATE ce75dacf45d3ad4f852b7fb4d359a295b8a2bcdd
OK
[root@redis-2 ~]# redis-cli -h 192.168.81.220 -p 6381
192.168.81.220:6381> CLUSTER REPLICATE 812ae8ccf55d8994f1f9d30a20f6cff42fb24b4a
OK
[root@redis-3 ~]# redis-cli -h 192.168.81.230 -p 6381
192.168.81.230:6381> CLUSTER REPLICATE b61b8d0421b94b9de7267dda6c6f401a42622047
OK
#查看集群信息已经交叉复制
[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6381 cluster nodes
812ae8ccf55d8994f1f9d30a20f6cff42fb24b4a 192.168.81.230:6380 master - 0 1612342768677 3 connected 10923-16383
bdd20b03b573b2def6a9ee5053a75867709fc908 192.168.81.210:6381 myself,slave ce75dacf45d3ad4f852b7fb4d359a295b8a2bcdd 0 0 4 connected
9b7641253ea66073d865accdd4460d2877f9ff5d 192.168.81.220:6381 slave 812ae8ccf55d8994f1f9d30a20f6cff42fb24b4a 0 1612342767669 5 connected
ce75dacf45d3ad4f852b7fb4d359a295b8a2bcdd 192.168.81.220:6380 master - 0 1612342766658 2 connected 5461-10922
904a0109976cae38e5a3059fd70ce2727a0ed8fb 192.168.81.230:6381 slave b61b8d0421b94b9de7267dda6c6f401a42622047 0 1612342769686 3 connected
b61b8d0421b94b9de7267dda6c6f401a42622047 192.168.81.210:6380 master - 0 1612342770189 1 connected 0-5460

查看集群完整性
如果集群没问题会输出ok
[root@redis-1 ~]# cd /data/redis_cluster/redis-3.2.9/src
[root@redis-1 /data/redis_cluster/redis-3.2.9/src]# ./redis-trib.rb check 192.168.81.210:6380
验证hash分配是否均匀
#首先插入1000条数据
[root@redis-1 ~]# for i in {1..1000}
do
redis-cli -c -h 192.168.81.210 -p 6380 set key_${i} value_${i}
done
#查看每个节点的数据量
[root@redis-1 ~]# redis-cli -c -h 192.168.81.210 -p 6380 dbsize
(integer) 334
[root@redis-1 ~]# redis-cli -c -h 192.168.81.220 -p 6380 dbsize
(integer) 336
[root@redis-1 ~]# redis-cli -c -h 192.168.81.230 -p 6380 dbsize
(integer) 330
查看集群分配的误差值
[root@redis-1 /data/redis_cluster/redis-3.2.9/src]# ./redis-trib.rb rebalance 192.168.81.210:6380
>>> Performing Cluster Check (using node 192.168.81.210:6380)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
*** No rebalancing needed! All nodes are within the 2.0% threshold.

链接:
https://blog.csdn.net/weixin_44953658/article/details/121265752
(十三):Redis Cluster 集群扩容原理与实践
Cluster 集群扩容概念
当redis数据量日渐增长,当内存不够用的时候,这时候就需要集群扩容了,cluster集群扩容可以增加内存也可以增加节点 ,因为redis数据都是存在内存中。
redis cluster增加节点进行扩容步骤:
1.在新的服务器上部署redis cluster
2.使用工具将新部署的节点加到集群中
3.使用工具将集群槽位重新分配
4.将主从复制关系调整成交叉模式
扩容原理
原来的节点算好要拿出多少的槽位给新加的节点,新加的节点准备导入的槽位,准备的前提条件就是加入集群,一切准备就绪后,主节点将划分出来的槽位分配给新节点,然后将相关槽位的数据迁移到新的节点。
4个节点的redis cluster,每个节点的槽位时16384/4,一个节点4096个槽位 。
扩容前后的架构图对比图
新增节点后,主从复制就变成了四主四从,只需要变动192.168.81.230的从库关系即可,192.168.81.230节点从库复制192.168.81.240节点的主库,192.168.81.240从库复制192.168.81.210的主库
环境准备
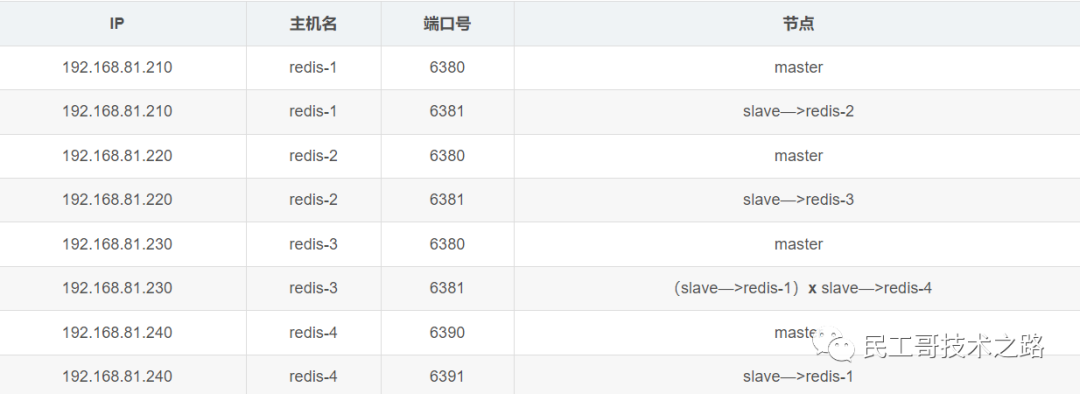
在新节点部署redis cluster
#将redis管理工具从redis-1拷贝到redis-4并安装
[root@redis-1 ~]# scp -rp /data/redis_cluster root@192.168.81.240:/data
[root@redis-4 ~]# cd /data/redis_cluster/redis-3.2.9
[root@redis-4 /data/redis_cluster/redis-3.2.9]# make install
#创建部署路径
[root@redis-4 ~]# mkdir -p /data/redis_cluster/redis_{6390,6391}/{conf,data,logs,pid}
#准备配置文件
[root@redis-4 ~]# cat > /data/redis_cluster/redis_6390/conf/redis_6390.conf <<EOF
bind $(ifconfig | awk 'NR==2{print $2}')
port 6390
daemonize yes
logfile /data/redis_cluster/redis_6390/logs/redis_6390.log
pidfile /data/redis_cluster/redis_6390/pid/redis_6390.log
dbfilename "redis_6390.rdb"
dir /data/redis_cluster/redis_6390/data
cluster-enabled yes
cluster-config-file node_6390.conf
cluster-node-timeout 15000
save 60 10000
save 300 10
save 900 1
EOF
[root@redis-4 ~]# cat > /data/redis_cluster/redis_6391/conf/redis_6391.conf <<EOF
bind $(ifconfig | awk 'NR==2{print $2}')
port 6391
daemonize yes
logfile /data/redis_cluster/redis_6391/logs/redis_6391.log
pidfile /data/redis_cluster/redis_6391/pid/redis_6391.log
dbfilename "redis_6391.rdb"
dir /data/redis_cluster/redis_6391/data
cluster-enabled yes
cluster-config-file node_6391.conf
cluster-node-timeout 15000
save 60 10000
save 300 10
save 900 1
EOF
#启动redis
[root@redis-4 ~]# ./redis_shell.sh start 6390
[root@redis-4 ~]# ./redis_shell.sh start 6391
使用工具将redis-4加入集群
在原来集群的任意一台机器安装了 ruby 环境即可操作。
安装ruby环境
//安装ruby管理工具
[root@redis-1 ~]# yum -y install rubygems
//移除官网源
[root@redis-1 ~]# gem sources --remove https://rubygems.org/
https://rubygems.org/ removed from sources
//增加阿里云源
[root@redis-1 ~]# gem sources -a http://mirrors.aliyun.com/rubygems/
http://mirrors.aliyun.com/rubygems/ added to sources
//更新缓存
[root@redis-1 ~]# gem update --system
ruby2.3.0以下版本执行会报错
//安装ruby支持redis的插件
[root@redis-1 ~]# gem install redis -v 3.3.5
Fetching: redis-3.3.5.gem (100%)
Successfully installed redis-3.3.5
Parsing documentation for redis-3.3.5
Installing ri documentation for redis-3.3.5
1 gem installed
将redis-4加入集群
需要将redis-4的6390和6391端口都加入到集群,可以使用工具进行添加。
命令: ./redis-trib.rb add-node 新节点:端口 现有集群:端口
[root@redis-1 ~]# cd /data/redis_cluster/redis-3.2.9/src/
[root@redis-1 /data/redis_cluster/redis-3.2.9/src]# ./redis-trib.rb add-node 192.168.81.240:6390 192.168.81.210:6380
[root@redis-1 /data/redis_cluster/redis-3.2.9/src]# ./redis-trib.rb add-node 192.168.81.240:6391 192.168.81.210:6380
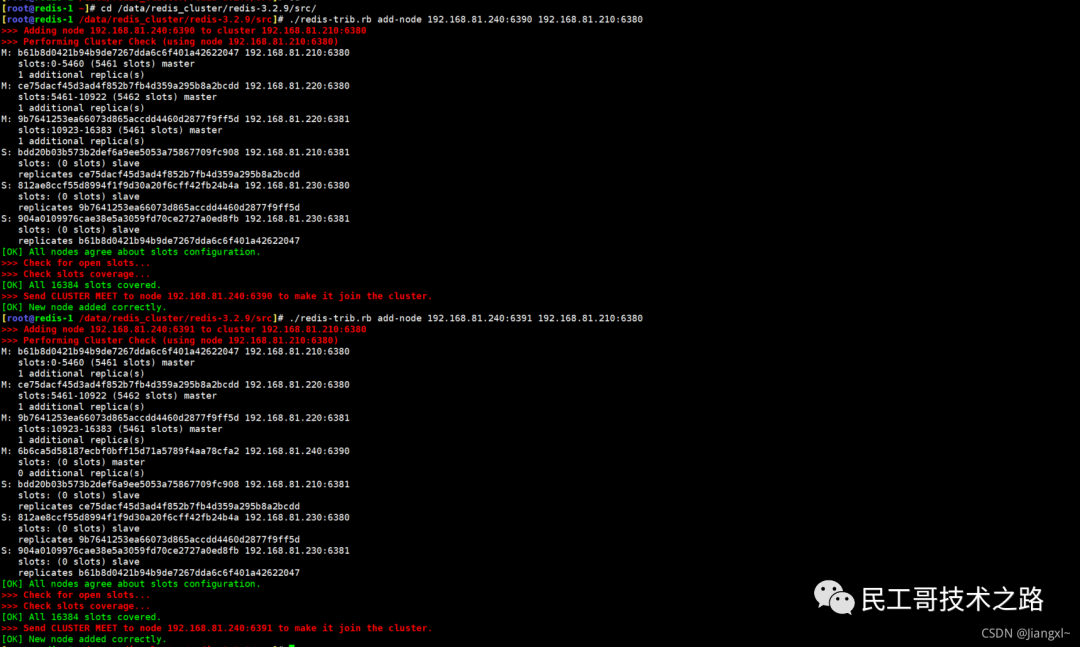
查看集群信息,已经有8个节点
[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6380 cluster nodes
ce75dacf45d3ad4f852b7fb4d359a295b8a2bcdd 192.168.81.220:6380 master - 0 1612424799243 2 connected 5461-10922
9b7641253ea66073d865accdd4460d2877f9ff5d 192.168.81.220:6381 master - 0 1612424801262 8 connected 10923-16383
b19722a1d3d482a2c6eaaec15e5e72018600389f 192.168.81.240:6391 master - 0 1612424797227 0 connected
6b6ca5d58187ecbf0bff15d71a5789f4aa78cfa2 192.168.81.240:6390 master - 0 1612424796216 9 connected
bdd20b03b573b2def6a9ee5053a75867709fc908 192.168.81.210:6381 slave ce75dacf45d3ad4f852b7fb4d359a295b8a2bcdd 0 1612424796721 4 connected
812ae8ccf55d8994f1f9d30a20f6cff42fb24b4a 192.168.81.230:6380 slave 9b7641253ea66073d865accdd4460d2877f9ff5d 0 1612424800253 8 connected
904a0109976cae38e5a3059fd70ce2727a0ed8fb 192.168.81.230:6381 slave b61b8d0421b94b9de7267dda6c6f401a42622047 0 1612424798232 6 connected
b61b8d0421b94b9de7267dda6c6f401a42622047 192.168.81.210:6380 myself,master - 0 0 1 connected 0-5460
将槽位重新分配
当新节点加入集群后,需要重新分配槽位,否则整个集群是无法使用的。
命令格式: ./redis-trib.rb reshard 集群任意一个主库的ip:端口
分配的时候可以选择all,直接将所有节点分出一部分槽位迁移给新节点。
也可以指定某个节点迁移出一部分槽位给新节点。
所有节点分出槽位给新节点
[root@redis-1 ~]# cd /data/redis_cluster/redis-3.2.9/src
[root@redis-1 /data/redis_cluster/redis-3.2.9/src]# ./redis-trib.rb reshard 192.168.81.210:6380
How many slots do you want to move (from 1 to 16384)? 4096
//需要迁移的槽位数量,也就是要拿出多少个槽位给新节点,我们输入4096,因为16384除4刚好是4096
What is the receiving node ID? 6b6ca5d58187ecbf0bff15d71a5789f4aa78cfa2
//迁移给目标节点的ID号,也就是新节点的6390ID号,6390作为新节点的主库
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1:all
//迁移方式:all将所有主节点分出一部分槽位给新节点
Do you want to proceed with the proposed reshard plan (yes/no)? yes //是否继续分配
设置要迁移的槽位数量,填写4096
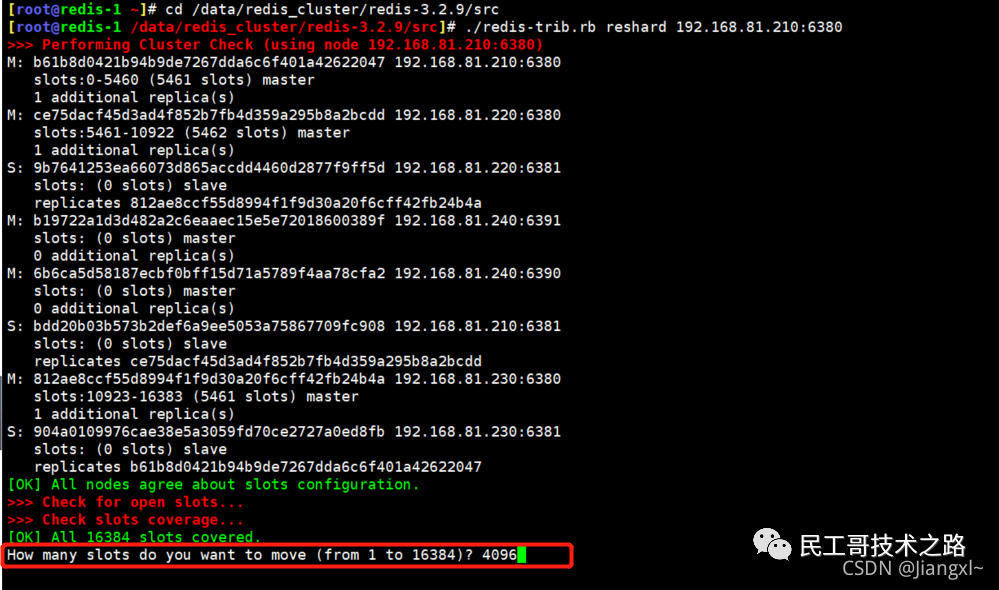
填写要迁移到目标节点的ID号,也就是要迁移给谁,这里我们要迁移给新加的节点,我们要让新机器的6390节点成为主库,因此就填写6390节点的ID号。
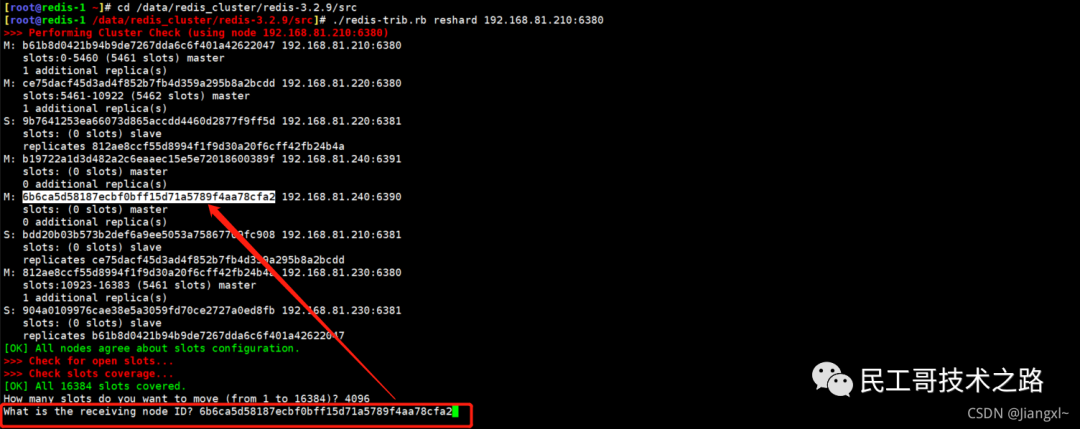
设置要从哪个节点上迁移槽位,可以一台一台的迁移,也可以填写all,all的意思是从所有节点上一共取出4096个槽位分给新机器,如果使用all迁移,会把所有主节点迁移出一部分槽位给新节点,执行完all直接就退出工具。
我们使用all自动将所有主节点进行迁移,直接输入all即可自动迁移,一般都使用all。
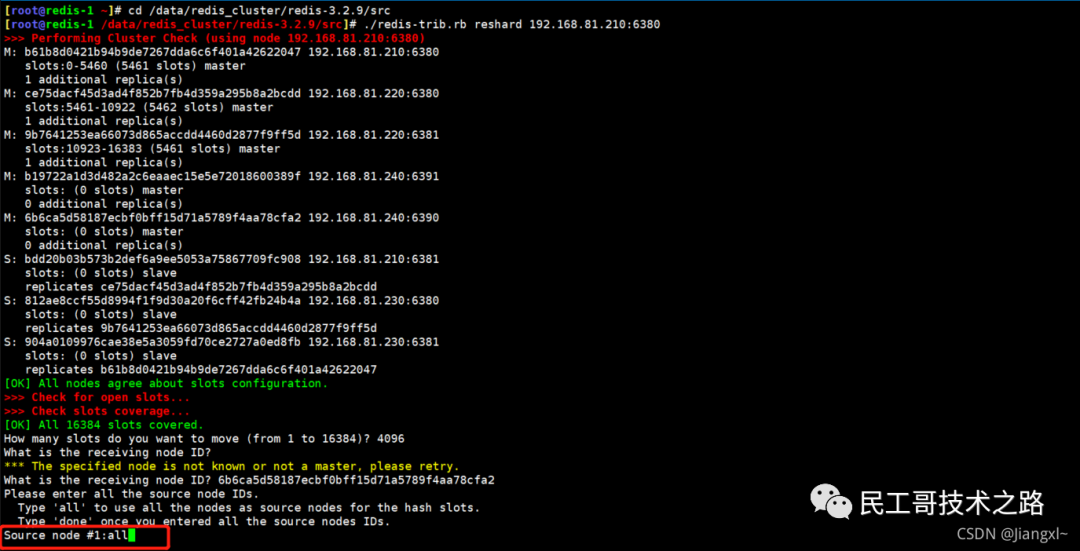
提示我们是否继续分配,我们选择yes
迁移完成自动退出程序
迁移指定节点的槽位给新节点
前面步骤一致,只需要在source node选择指定节点即可。
填写要迁移的主节点ID,填写完主机节点ID后,输入done,回车之后开始迁移数据。
提示我们是否继续,我们输入yes图片开始数据迁移

查看集群信息及状态
当6390分配完槽位后,可以看下集群信息是否分配成功。
[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6380 cluster nodes
可以看到6390上有3段槽位号,说明是从三个节点上分出来的,正好也验证了之前说的一句话,槽位顺序不一定要存在,只要槽位数量够就可以

再次使用reshard命令即可看到都是4096个槽位

查看集群状态
[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6380 cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:8 #节点数已经是8个了
cluster_size:4
cluster_current_epoch:11
cluster_my_epoch:1
cluster_stats_messages_sent:67364
cluster_stats_messages_received:67293
配置四主四从交叉复制
目前是5个主节点3个从节点,显然是不合理的,我们要手动配置一些交叉复制实现四主四从。
只需要操作192.168.81.230的6381端口和192.168.81.240的6391端口即可
- 192.168.81.230的6381端口作为192.168.81.240的6390端口的从库
- 192.168.81.240的6391作为192.168.81.210的6380端口的从库
再配置与新节点交叉复制的时候,建议先操作192.168.81.230,这样192.168.81.210的主库就没有需要传输rdb文件到从库了,也可以减轻主库的压力,如果先让192.168.81.240配置交叉,这样一来192.168.81.210的主库就有2份复制了,主库就需要一次传输2份rdb文件,压力也就大了
注意:先做192.168.81.230的交叉在做192.168.81.240的交叉
配置四主四从交叉复制
#将master主库的所有ID获取下来
[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6380 cluster nodes | grep 'master' | awk '{print $1,$2}'
ce75dacf45d3ad4f852b7fb4d359a295b8a2bcdd 192.168.81.220:6380
6b6ca5d58187ecbf0bff15d71a5789f4aa78cfa2 192.168.81.240:6390
812ae8ccf55d8994f1f9d30a20f6cff42fb24b4a 192.168.81.230:6380
b61b8d0421b94b9de7267dda6c6f401a42622047 192.168.81.210:6380
#建议在记事本里准备好命令
redis-3同步redis-4
192.168.81.230:6381> CLUSTER REPLICATE 6b6ca5d58187ecbf0bff15d71a5789f4aa78cfa2
redis-4同步redis-3
192.168.81.240:6391> CLUSTER REPLICATE b61b8d0421b94b9de7267dda6c6f401a42622047
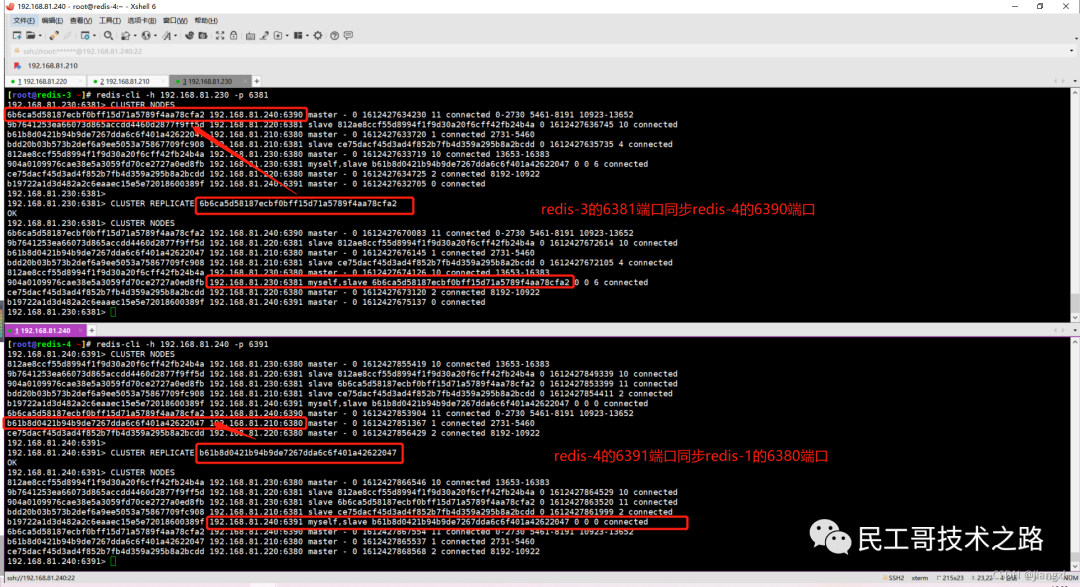
查看集群信息及状态
[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6380 cluster nodes
[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6380 cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:8
cluster_size:4
cluster_current_epoch:11
cluster_my_epoch:1
cluster_stats_messages_sent:69698
cluster_stats_messages_received:69627
[root@redis-1 ~]#
已经是四主四从了,并且集群状态也是ok
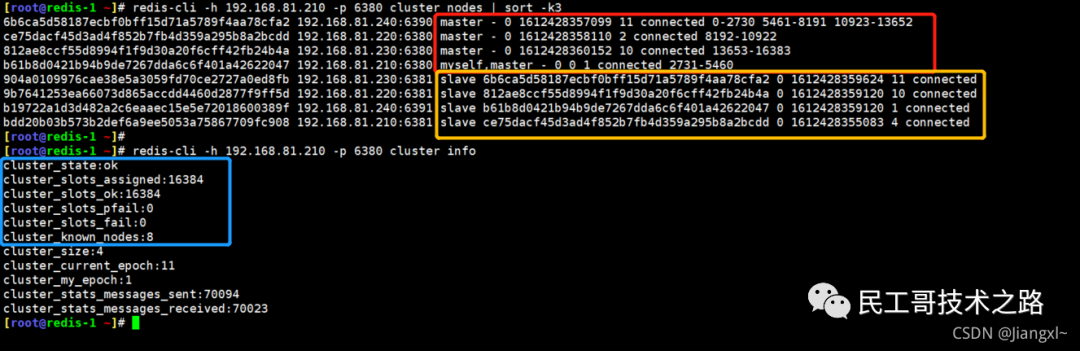
来源:
https://jiangxl.blog.csdn.net/article/details/121329856
(十四):Redis Cluster 集群收缩原理与实践
Cluster 集群收缩概念
当项目压力承载力过高时,需要增加节点来提高负载,当项目压力不是很大时,也希望能够将集群收缩下来,给其他项目使用 ,这就要用到集群收缩了
集群收缩操作和集群扩容是一样的,只需要把方向反过来即可。
扩容的时候执行一次命令就可以实现槽位迁移成功,而收缩的时候有几个主节点就需要执行多少次,比如除去要下线的节点,还有3个主节点,那么就需要执行三次,填写迁移出槽位的数量也需要除以3,每个节点也需要平均分配。
收缩的时候首先要填写分出多少个槽位,然后填写要分给谁,最后填写从哪分出槽位,一般分多少个槽位,就需要看要下线的主机上有多少个槽位,然后除以集群主节点数,使每一个主机点分到的槽位都是相同的,填写要分配给谁的时候,第一次填写第一个主节点的ID,第二次填写第二个主节点的ID,最后填写提供槽位的节点ID,就是下线节点的ID号。
集群收缩扩容槽位的时候不会影响数据的使用。
集群收缩的源端就是要下线的主节点,目标端就是在线的主节点(分配给谁的节点)。
咱们要清楚一点,只有主节点是有槽位的,因此呢需要将主节点的槽位分配给其他主节点,当槽位清空后,这个主机节点就可以下线了。
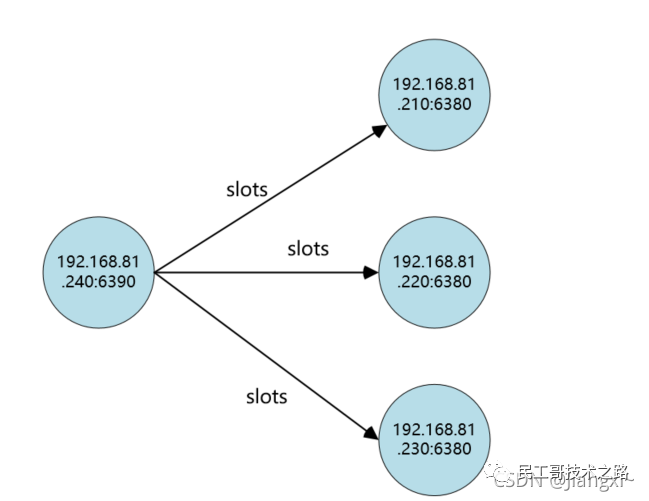
收缩集群前后对比图
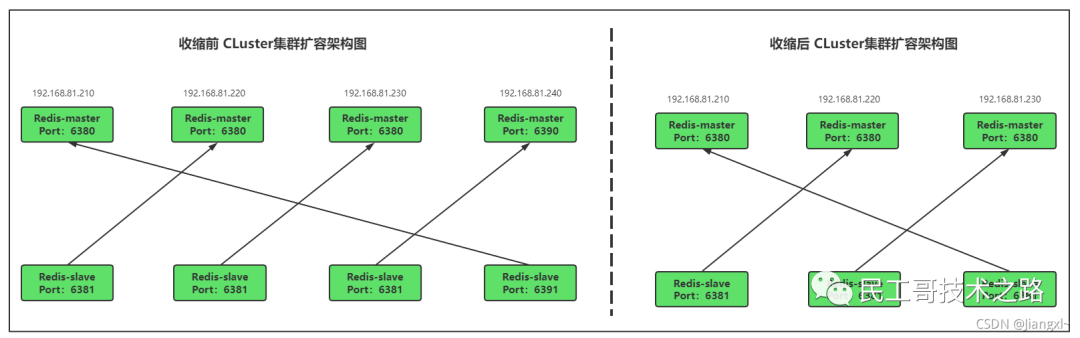
集群收缩操作步骤:
1.执行reshard命令将需要下线的主节点进行槽位分散。
2.有几个主节点就需要执行几次reshard命令,首先填写要分出的槽位数,然后填写分给谁,最后填写从哪里分。
3.当槽位分散完成后,要下线的主节点没有任何数据时,将节点从集群中删除。
集群信息
目前集群时四主四从共8个节点,我们需要将集群改为三主三从,收缩出两个节点给其他程序使用。
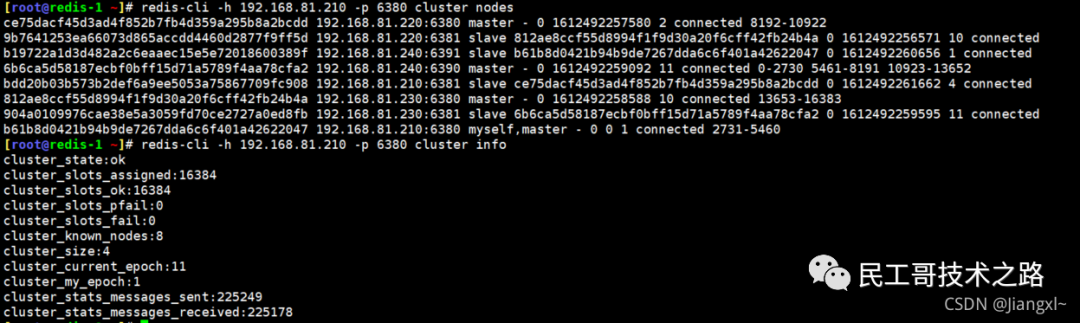
将6390主节点从集群中收缩
计算需要分给每一个节点的槽位数
可以看到6390节点上有4096个槽位,删除要下线的6390节点后,我们还有3个主节点,4096除3得到1365,分配槽位的时候给每个节点分配1365个槽位即可均匀。
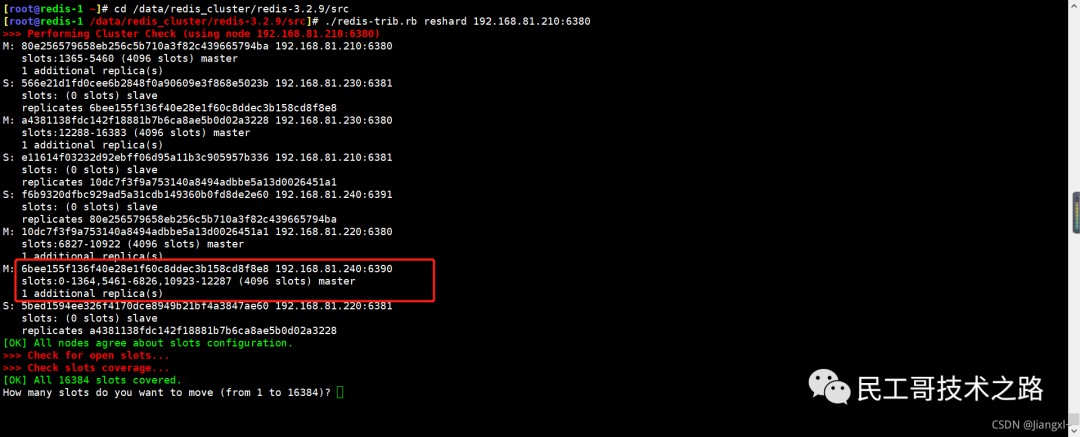
分配1365个槽位给192.168.81.210的6380节点
我们需要将192.168.81.240的6390节点分出1365个槽位给192.168.81.210的6380节点。
只需要把What is the receiving node ID填写成192.168.81.210的6380节点ID即可,指的是分配出来的槽位要给谁。
然后source node填写192.168.81.240的6390节点的ID,这里指的是从哪个节点上分出1365个槽位,填写ID后,回车后会提示还要从哪个节点上分配槽位,因为只有6390需要分出槽位,所以在这里填写done,表示只有这个一个节点分出1365个槽位给其他节点。
[root@redis-1 /data/redis_cluster/redis-3.2.9/src]# ./redis-trib.rb reshard 192.168.81.210:6380
How many slots do you want to move (from 1 to 16384)? 1365 #分配出多少个槽位
What is the receiving node ID? 80e256579658eb256c5b710a3f82c439665794ba #将槽位分给那个节点
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1:6bee155f136f40e28e1f60c8ddec3b158cd8f8e8 #从哪个节点分出槽位
Source node #2:done
Do you want to proceed with the proposed reshard plan (yes/no)? yes #输入yes继续
下面是收缩节点的过程截图。
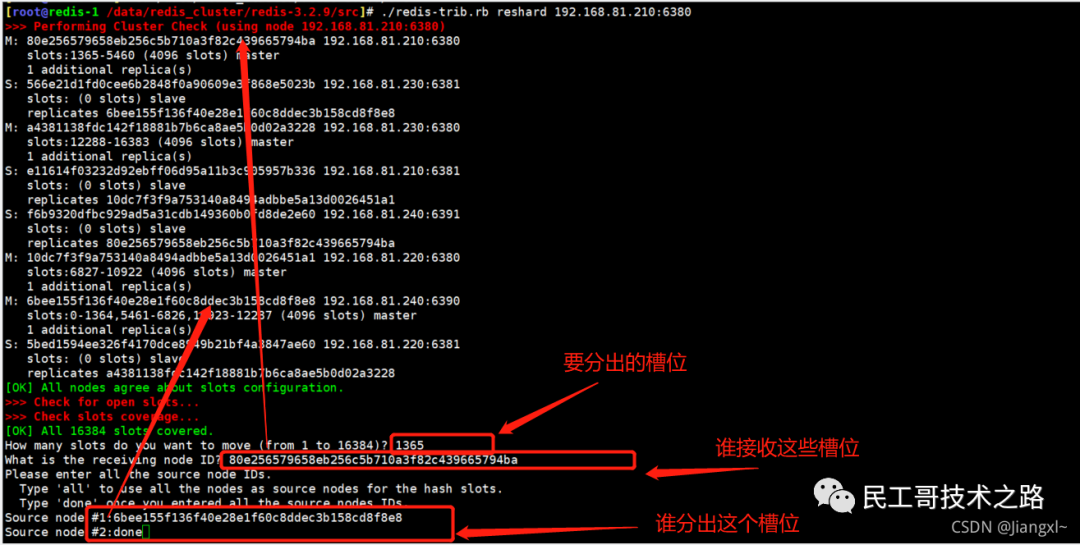
数据迁移过程。
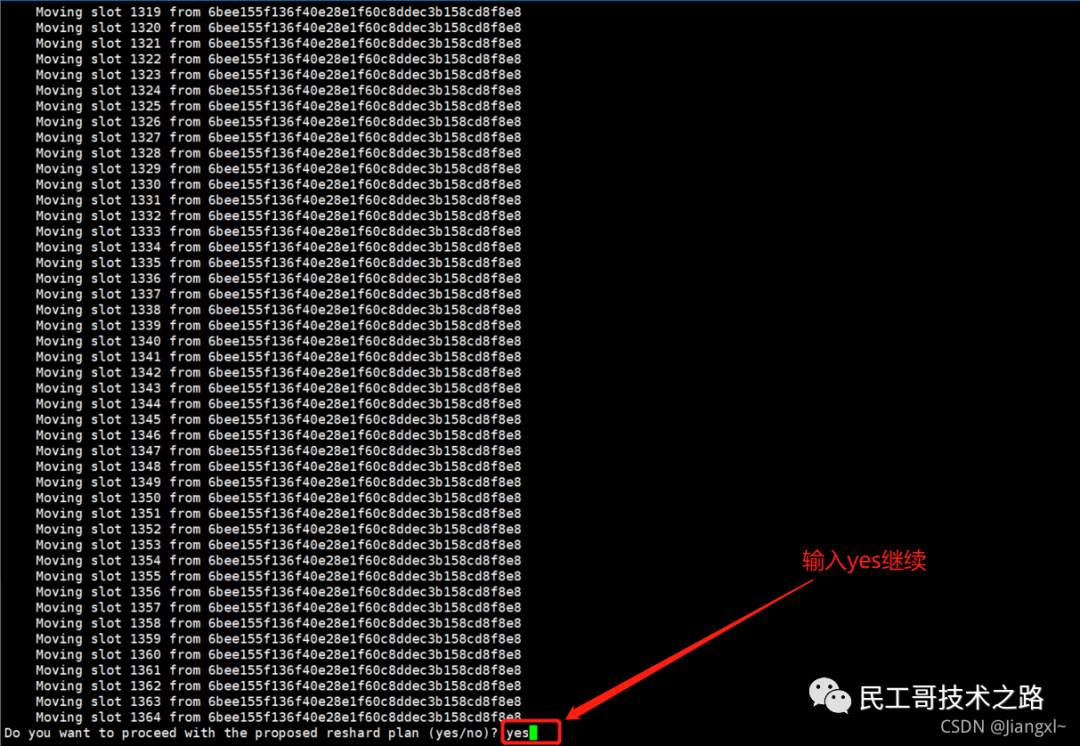
槽位分出迁移成功。
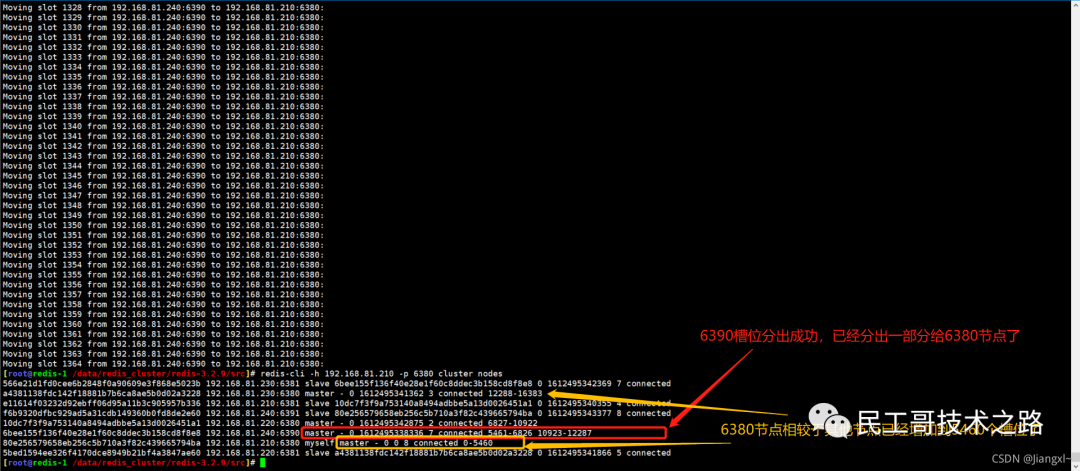
分配1365个槽位给192.168.81.220的6380节点
[root@redis-1 /data/redis_cluster/redis-3.2.9/src]# ./redis-trib.rb reshard 192.168.81.210:6380
How many slots do you want to move (from 1 to 16384)? 1365 #分配出多少个槽位
What is the receiving node ID? 10dc7f3f9a753140a8494adbbe5a13d0026451a1 #将槽位分给那个节点
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1:6bee155f136f40e28e1f60c8ddec3b158cd8f8e8 #从哪个节点分出槽位
Source node #2:done
Do you want to proceed with the proposed reshard plan (yes/no)? yes #输入yes继续
收缩过程截图展示。
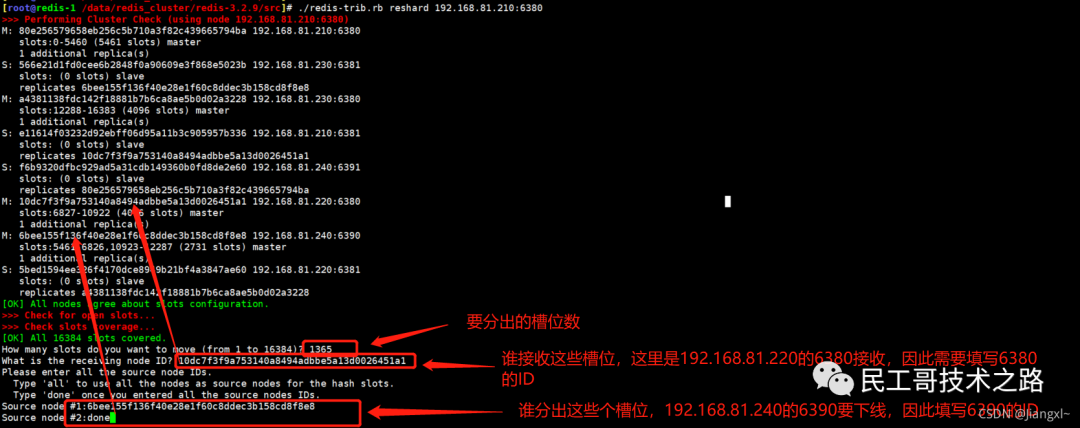
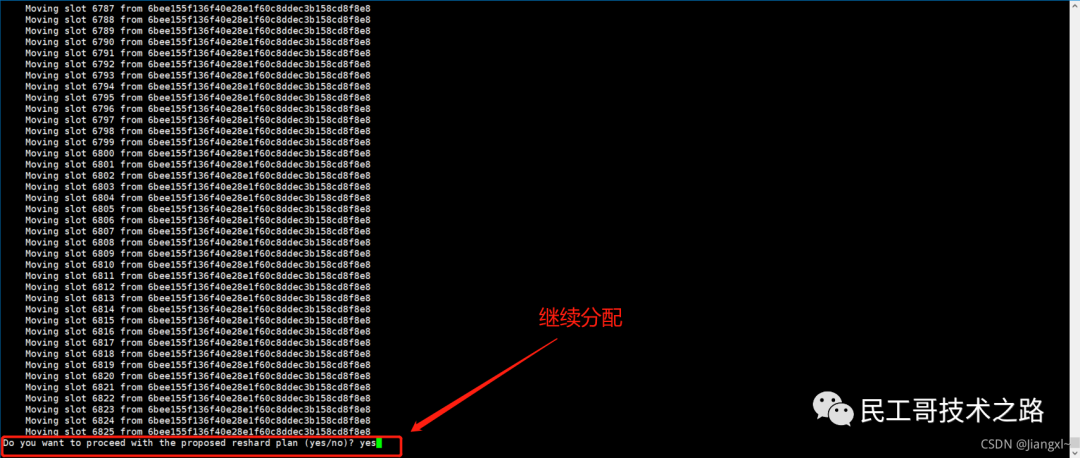
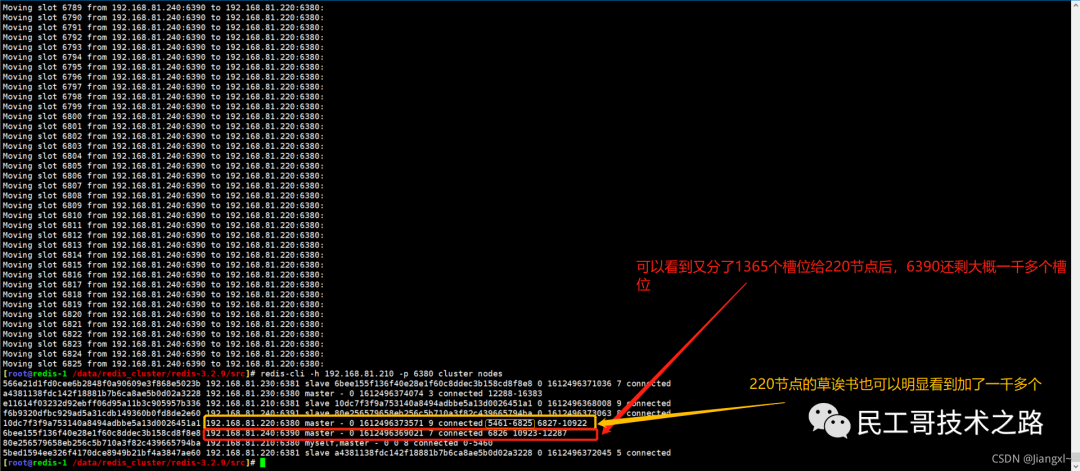
分配1365个槽位给192.168.81.230的6380节点
[root@redis-1 /data/redis_cluster/redis-3.2.9/src]# ./redis-trib.rb reshard 192.168.81.210:6380
How many slots do you want to move (from 1 to 16384)? 1366 #分配出多少个槽位
What is the receiving node ID? a4381138fdc142f18881b7b6ca8ae5b0d02a3228 #将槽位分给那个节点
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1:6bee155f136f40e28e1f60c8ddec3b158cd8f8e8 #从哪个节点分出槽位
Source node #2:done
Do you want to proceed with the proposed reshard plan (yes/no)? yes #输入yes继续
code here...
收缩过程截图展示。
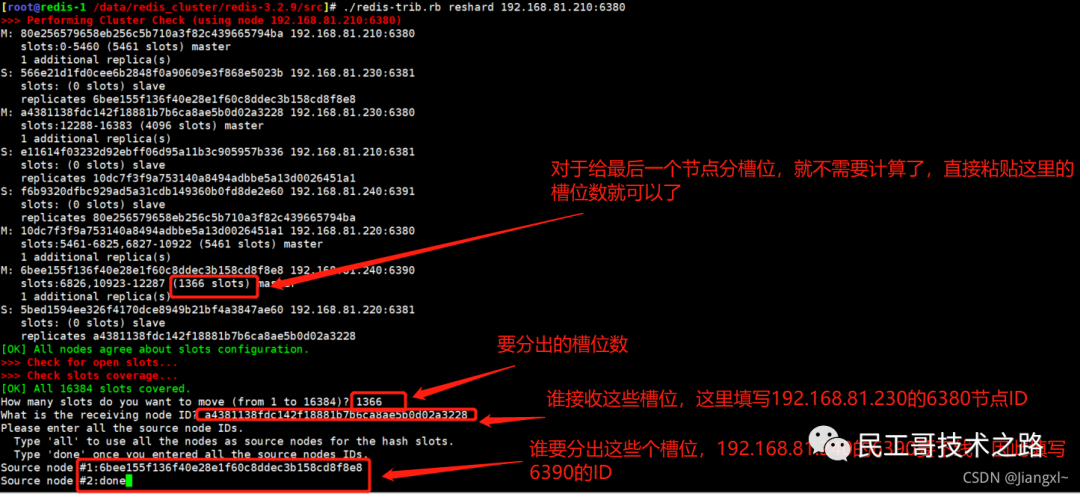

当最后一个节点迁移完数据后,6390主节点槽位数变为0。
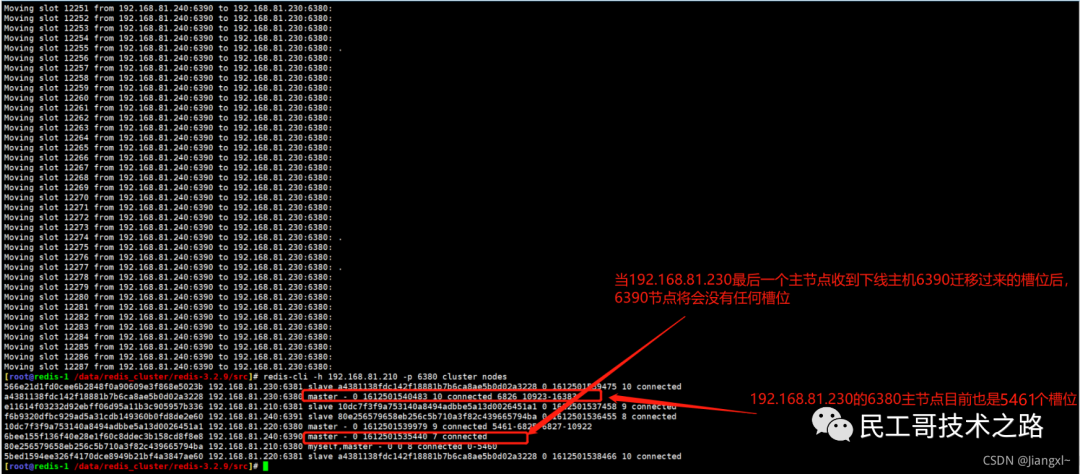
查看当前集群槽位分配
槽位及数据已经从6390即将下线的主机迁移完毕,可以看下当前集群三个主节点的槽位数。
可以非常清楚的看到,现在每个主节点的槽位数为5461。
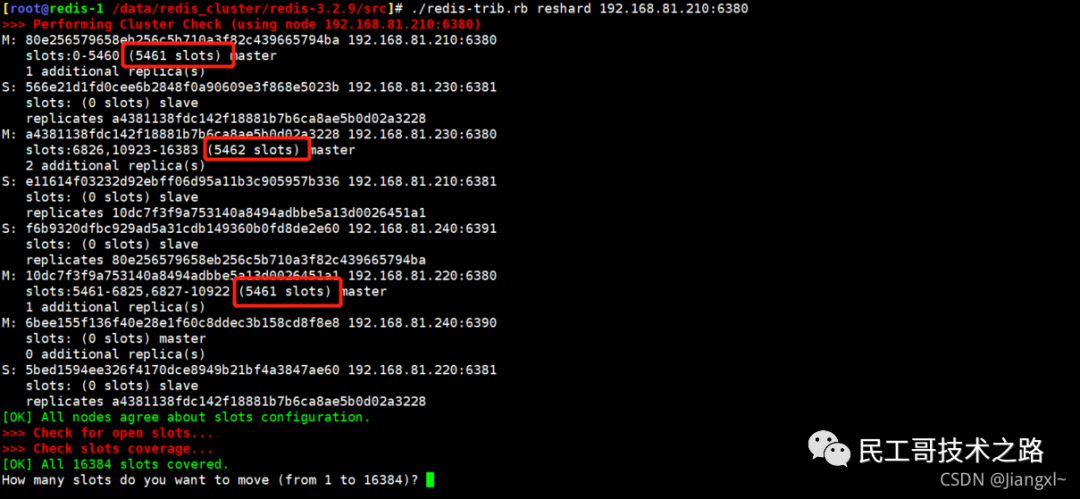
如果觉得槽位重新分配后顺序不太满意,那么在执行一下reshard,把其它节点的槽位都分给192.168.81.210的6380上,这样一来,210的6380拥有的槽位就是0-16383,然后在将210的槽位一个节点分给5461个,分完之后,各节点的顺序就一致了。

验证数据迁移过程是否导致数据异常
多开几个窗口,一个执行数据槽位迁移,一个不断创建key,一个查看key的创建进度,一个查看key的数据。
持续测试,发现没有任何数据异常,全部显示ok。

将下线的主节点从集群中删除
删除节点
使用redis-trib删除一个节点,如果这个节点存在复制关系,有节点在复制当前节点或者当前节点复制别的节点的数据,redis-trib会自动处理复制关系,然后将节点删除,节点删除后会把对应的进程也停止运行。
删除节点之前必须确保该节点没有任何槽位和数据,否则会删除失败。
命令: ./redis-trib.rb del-node 节点IP:端口 ID
[root@redis-1 /data/redis_cluster/redis-3.2.9/src]# ./redis-trib.rb del-node 192.168.81.240:6390 6bee155f136f40e28e1f60c8ddec3b158cd8f8e8
>>> Removing node 6bee155f136f40e28e1f60c8ddec3b158cd8f8e8 from cluster 192.168.81.240:6390
>>> Sending CLUSTER FORGET messages to the cluster...
>>> SHUTDOWN the node.
[root@redis-1 /data/redis_cluster/redis-3.2.9/src]# ./redis-trib.rb del-node 192.168.81.240:6391 f6b9320dfbc929ad5a31cdb149360b0fd8de2e60
>>> Removing node f6b9320dfbc929ad5a31cdb149360b0fd8de2e60 from cluster 192.168.81.240:6391
>>> Sending CLUSTER FORGET messages to the cluster...
>>> SHUTDOWN the node.
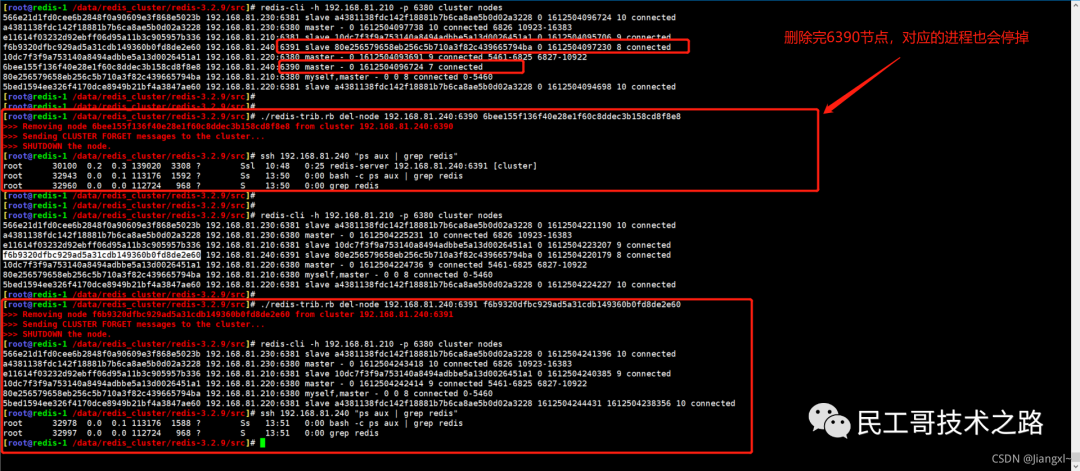
调整主从交叉复制
删掉192.168.81.240服务器上的两个redis节点后,192.168.81.210服务器上的6380就没有了复制关系,我们需要把192.168.81.230的6381节点复制192.168.81.210的6380节点。
[root@redis-1 ~]# redis-cli -h 192.168.81.230 -p 6381
192.168.81.230:6381> CLUSTER REPLICATE 80e256579658eb256c5b710a3f82c439665794ba
OK

当节点存在数据无法删除
[root@redis-1 /data/redis_cluster/redis-3.2.9/src]# ./redis-trib.rb del-node 192.168.81.220:6380 10dc7f3f9a753140a8494adbbe5a13d0026451a1
>>> Removing node 10dc7f3f9a753140a8494adbbe5a13d0026451a1 from cluster 192.168.81.220:6380
[ERR] Node 192.168.81.220:6380 is not empty! Reshard data away and try again.

将下线主机清空集群信息
redis-trib虽然能够将节点在集群中删除,但是无法将其的集群信息清空,如果集群信息还有保留,那么该接地那就无法加入其它集群。
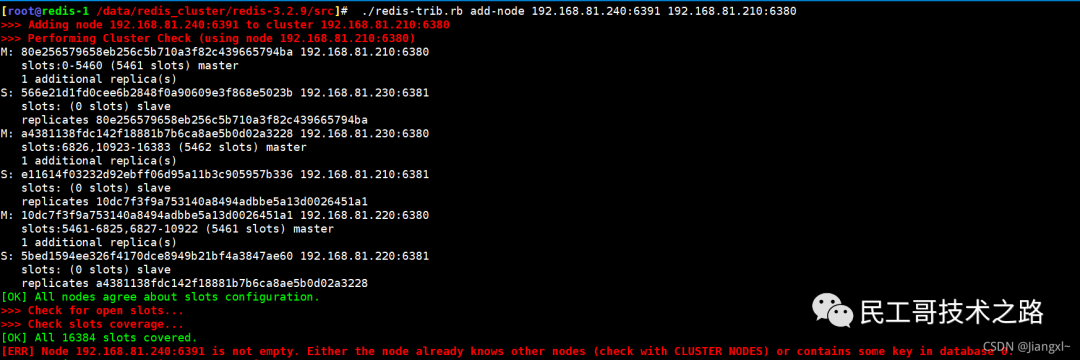
在下线的redis节点上使用cluster reset删除集群信息即可。
192.168.81.240:6390> CLUSTER reset
OK

来源:
https://jiangxl.blog.csdn.net/article/details/121465277
(十五):Redis 与Java\Php\Springboot 等应用的连接与使用
前言
我们之前对Redis的学习都是在命令行窗口,那么如何使用Java来对Redis进行操作呢?官方对于Java连接Redis的开发工具推荐了Jedis,通过Jedis同样可以实现对Redis的各种操作。本篇文章会介绍基于Linux上的Redis的Java连接操作。
准备步骤
修改配置文件redis.conf:
(1)注释以下属性,因为我们是需要进行远程连接的:
#bind:127.0.0.1
(2)将protected-mode 设置为no
protected-mode no
(3)设置为允许后台连接
daemonize yes
注意:
在远程服务器进行连接需要确保将以下三个步骤都完成:
- 设置服务器的安全组开放6379端口
- 防火墙开放端口:
firewall-cmd --zone=public --add-port=6379/tcp --permanet
- 重启防火墙:
systemctl restart firewalld.service
Jedis连接Redis
创建一个Maven项目,并导入以下依赖:
<dependencies>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
</dependencies>
测试连接:
package com.yixin;
import redis.clients.jedis.Jedis;
public class RedisTest {
public static void main(String[] args) {
//连接本地的 Redis 服务
Jedis jedis = new Jedis("服务器地址", 6379);
String response = jedis.ping();
System.out.println(response); // PONG
}
}
code here...
输出结果:
看到PONG说明我们成功连接上了我们服务器上的Redis了!
基本操作
操作String数据类型
package com.yixin;
import redis.clients.jedis.Jedis;
import java.util.Set;
public class Redis_String {
public static void main(String[] args) {
//连接本地的 Redis 服务
Jedis jedis = new Jedis("服务器地址", 6379);
String response = jedis.ping();
System.out.println(response); // PONG
//删除当前选择数据库中的所有key
System.out.println("删除当前选择数据库中的所有key:"+jedis.flushDB());
//Spring实例
//设置 redis 字符串数据
//新增<'name','yixin'>的键值对
jedis.set("name", "yixin");
// 获取存储的数据并输出
System.out.println("redis 存储的字符串为: "+ jedis.get("name"));
//判断某个键是否存在
System.out.println("判断某个键是否存在:"+jedis.exists("name"));
//系统中所有的键
Set<String> keys = jedis.keys("*");
System.out.println(keys);
//按索引查询
System.out.println("按索引查询:"+jedis.select(0));
//查看键name所存储的值的类型
System.out.println("查看键name所存储的值的类型:"+jedis.type("name"));
// 随机返回key空间的一个
System.out.println("随机返回key空间的一个:"+jedis.randomKey());
//重命名key
System.out.println("重命名key:"+jedis.rename("name","username"));
System.out.println("取出改后的name:"+jedis.get("username"));
//删除键username
System.out.println("删除键username:"+jedis.del("username"));
//删除当前选择数据库中的所有key
System.out.println("删除当前选择数据库中的所有key:"+jedis.flushDB());
//查看当前数据库中key的数目
System.out.println("返回当前数据库中key的数目:"+jedis.dbSize());
//删除数据库中的所有key
System.out.println("删除所有数据库中的所有key:"+jedis.flushAll());
}
}
操作List数据类型
package com.yixin;
import redis.clients.jedis.Jedis;
import java.util.List;
public class Redis_List {
public static void main(String[] args) {
//连接本地的 Redis 服务
Jedis jedis = new Jedis("服务器地址", 6379);
String response = jedis.ping();
System.out.println(response); // PONG
System.out.println("删除当前选择数据库中的所有key:"+jedis.flushDB());
//List实例
//存储数据到列表中
jedis.lpush("list", "num1");
jedis.lpush("list", "num2");
jedis.lpush("list", "num3");
// 获取存储的数据并输出
List<String> list = jedis.lrange("list", 0 ,-1);
for(int i=0; i<list.size(); i++) {
System.out.println("列表项为: "+list.get(i));
}
}
}
输出结果:

事务操作
package com.yixin;
import com.alibaba.fastjson.JSONObject;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Transaction;
public class Redis_Transaction {
public static void main(String[] args) {
//连接本地的 Redis 服务
Jedis jedis = new Jedis("服务器地址", 6379);
String response = jedis.ping();
System.out.println(response); // PONG
//事务测试
jedis.flushDB();
JSONObject jsonObject = new JSONObject();
jsonObject.put("hello","world");
jsonObject.put("name","yixin");
//开启事务
Transaction multi = jedis.multi();
String result = jsonObject.toJSONString();
// jedis.watch(result)
try {
multi.set("user1", result);
multi.set("user2", result);
int i = 1 / 0; // 代码抛出异常事务,执行失败!
multi.exec(); // 执行事务!
}catch (Exception e){
multi.discard();// 放弃事务
e.printStackTrace();
}finally {
System.out.println(jedis.get("user1"));
System.out.println(jedis.get("user2"));
jedis.close();
}
}
}
输出结果:
对于其他命令也基本类似,就不一一演示出来了,之前学过的Redis命令,在Java中同样可以进行使用。
SpringBoot集成Redis
介绍
这次我们并不使用jedis来进行连接,而是使用lettuce来进行连接,jedis和lettuce的对比如下:
- jedis:采用的直连,多个线程操作的话,是不安全的;想要避免不安全,使用jedis pool连接池。更像BIO模式
- lettuce:采用netty,实例可以在多个线程中共享,不存在线程不安全的情况;可以减少线程数量。更像NIO模式
集成Redis
创建Spring Boot项目
导入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
编写配置文件
application.properties:
#配置redis
# Redis服务器地址
spring.redis.host=服务器地址
# Redis服务器连接端口
spring.redis.port=6379
# Redis数据库索引(默认为0)
spring.redis.database=0
# Redis服务器连接密码(默认为空)
spring.redis.password=
# 连接池最大连接数(使用负值表示没有限制) 默认 8
spring.redis.lettuce.pool.max-active=8
# 连接池最大阻塞等待时间(使用负值表示没有限制) 默认 -1
spring.redis.lettuce.pool.max-wait=-1
# 连接池中的最大空闲连接 默认 8
spring.redis.lettuce.pool.max-idle=8
# 连接池中的最小空闲连接 默认 0
spring.redis.lettuce.pool.min-idle=0
编写测试类
package com.yixin;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
@SpringBootTest
class SpringbootRedisApplicationTests {
@Autowired
private RedisTemplate<String,String> redisTemplate;
@Test
void contextLoads() {
redisTemplate.opsForValue().set("name","yixin");
System.out.println(redisTemplate.opsForValue().get("name"));
}
}
输出:
这样就已经成功连接了!
在这种连接方式中,redisTemplate操作着不同的数据类型,api和我们的指令是一样的。
opsForValue:操作字符串 类似String
opsForList:操作List 类似List
opsForSet:操作Set,类似Set
opsForHash:操作Hash
opsForZSet:操作ZSet
opsForGeo:操作Geospatial
opsForHyperLogLog:操作HyperLogLog
除了基本的操作,我们常用的方法都可以直接通过redisTemplate操作,比如事务,和基本的CRUD。
保存对象
编写实体类
注意:要实现序列号Serializable。
package com.yixin.pojo;
import java.io.Serializable;
public class User implements Serializable {
private String name;
private int age;
public User(){
}
public User(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "User{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
编写RedsTemplate配置
Tip:在开发当中,我们可以直接把这个模板拿去使用。
package com.yixin.config;
import com.fasterxml.jackson.annotation.JsonAutoDetect;
import com.fasterxml.jackson.annotation.PropertyAccessor;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
@Configuration
public class RedisConfig {
@Bean
@SuppressWarnings("all")
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
//为了自己开发方便,一般直接使用 <String, Object>
RedisTemplate<String, Object> template = new RedisTemplate<String, Object>();
template.setConnectionFactory(factory);
// Json序列化配置
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
// String 的序列化
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
// key采用String的序列化方式
template.setKeySerializer(stringRedisSerializer);
// hash的key也采用String的序列化方式
template.setHashKeySerializer(stringRedisSerializer);
// value序列化方式采用jackson
template.setValueSerializer(jackson2JsonRedisSerializer);
// hash的value序列化方式采用jackson
template.setHashValueSerializer(jackson2JsonRedisSerializer);
template.afterPropertiesSet();
return template;
}
}
code here...
存储对象
package com.yixin;
import com.yixin.pojo.User;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
@SpringBootTest
class SpringbootRedisApplicationTests {
@Autowired
private RedisTemplate<String,Object> redisTemplate;
@Test
void contextLoads() {
User user=new User("yixin",18);
redisTemplate.opsForValue().set("user",user);
System.out.println(redisTemplate.opsForValue().get("user"));
}
}
输出结果:
PHP 使用 Redis
安装
开始在 PHP 中使用 Redis 前, 我们需要确保已经安装了 redis 服务及 PHP redis 驱动,且你的机器上能正常使用 PHP。接下来让我们安装 PHP redis 驱动:下载地址为:https://github.com/phpredis/phpredis/releases。
PHP安装redis扩展
以下操作需要在下载的 phpredis 目录中完成:
$ wget https://github.com/phpredis/phpredis/archive/3.1.4.tar.gz #下载
$ tar zxvf 3.1.4.tar.gz # 解压
$ cd phpredis-3.1.4 # 进入 phpredis 目录
$ /usr/local/php/bin/phpize # php安装后的路径
$ ./configure --with-php-config=/usr/local/php/bin/php-config #编译
$ make && make install
修改php.ini文件
vi /usr/local/php/lib/php.ini
增加如下内容:
extension_dir = "/usr/local/php/lib/php/extensions/no-debug-zts-20090626" extension=redis.so
安装完成后重启php-fpm 或 apache 。查看phpinfo信息,就能看到redis扩展。
连接到 redis 服务
实例
<?php
//连接本地的 Redis 服务
$redis = new Redis();
$redis->connect('127.0.0.1', 6379);
echo "Connection to server successfully";
//查看服务是否运行
echo "Server is running: " . $redis->ping();
?>
执行脚本,输出结果为:
Connection to server successfully
Server is running: PONG
Redis PHP String(字符串) 实例
<?php
//连接本地的 Redis 服务
$redis = new Redis();
$redis->connect('127.0.0.1', 6379);
echo "Connection to server successfully";
//设置 redis 字符串数据
$redis->set("tutorial-name", "Redis tutorial");
// 获取存储的数据并输出
echo "Stored string in redis:: " . $redis->get("tutorial-name");
?>
执行脚本,输出结果为:
Connection to server successfully
Stored string in redis:: Redis tutorial
Redis PHP List(列表) 实例
<?php
//连接本地的 Redis 服务
$redis = new Redis();
$redis->connect('127.0.0.1', 6379);
echo "Connection to server successfully";
//存储数据到列表中
$redis->lpush("tutorial-list", "Redis");
$redis->lpush("tutorial-list", "Mongodb");
$redis->lpush("tutorial-list", "Mysql");
// 获取存储的数据并输出
$arList = $redis->lrange("tutorial-list", 0 ,5);
echo "Stored string in redis";
print_r($arList);
?>
执行脚本,输出结果为:
Connection to server successfully
Stored string in redis
Mysql
Mongodb
Redis
Redis PHP Keys 实例
<?php
//连接本地的 Redis 服务
$redis = new Redis();
$redis->connect('127.0.0.1', 6379);
echo "Connection to server successfully";
// 获取数据并输出
$arList = $redis->keys("*");
echo "Stored keys in redis:: ";
print_r($arList);
?>
执行脚本,输出结果为:
Connection to server successfully
Stored string in redis::
tutorial-name
tutorial-list
参考:
https://www.runoob.com/redis/redis-php.html
https://yixinforu.blog.csdn.net/article/details/122906569
(十六):Redis 常用运维脚本
设计思路
redis 经常需要去管理,而编译安装的 redis 没有启动脚本以及运维相关的脚本,我们可以自己设计一个。
脚本需求 :
- 可以启动、关闭、重启redis
- 启动:当redis没有运行的时候直接启动并输出启动成功,运行了就输出已经启动,避免重复进程
- 关闭:如果进程存在就关闭并输出已经关闭,没有进程则直接输出redis没有启动
- 重启:当进程存在就先执行关闭再启动,并输出重启成功,如果进程不存在直接执行启动
- 可以查看redis进程
- 可以登录redis
- 可以查看redis日志
- 由于redis是多端口实例,因此需要能够实现指定一个端口就能够启动这个端口的进程
实现思路 :
- 将所有的功能都做成函数
- 通过判断$1输入的是什么指令,并执行对应的脚本
编写脚本
定义各种变量
将redis部署路径、端口号、配置文件、主机IP都定义成变量。
redis_port=$2 #redis端口
redis_name="redis_${redis_port}" #redis节点所在目录名称,即redis_6379
redis_home=/data/redis_cluster/${redis_name} #redis节点所在万年竹路径
redis_conf=${redis_home}/conf/${redis_name}.conf #redis配置文件路径
redis_host=`ifconfig ens33 | awk 'NR==2{print $2}'` #主机ip
redis_pass=$3 #redis密码,用到了在登陆那边加个-a参数
red="\e[031m"
green="\e[032m"
yellow="\e[033m"
black="\e[0m"
编写使用模块
主要实现如何使用这个脚本
Usage(){
echo "usage: sh $0 {start|stop|restart|login|ps|logs|-h} PORT"
}
编写启动模块
思路:首先判断指定端口的redis是否存在,如果不存在就执行启动命令,启动后输出启动成功,然后将开启的端口列出来。
这里还需要判断一下state的值是不是空的,因为到重启模块需要判断,在重启模块会定义一个state值,这里检测到state的值为空就输出echo的内容,到了restart的时候如果进程一开始是没有的无需输出echo内容,主要是为了重启的时候不输出这些echo。
启动后echo的时候,也会判断state的值,如果不为空就表示是重启了,就提示重启成功。
Start(){
redis_cz=`netstat -lnpt | grep redis | grep "${redis_port}" | wc -l`
if [ $redis_cz -eq 0 ];then
redis-server ${redis_conf}
if [ -z $state ];then
echo -e "${green}redis ${redis_port}实例启动成功!${black}"
else
echo -e "${green}redis ${redis_port}实例重启成功!${black}"
fi
netstat -lnpt | grep ${redis_port}
else
if [ -z $state ];then
echo -e "${yellow}redis "${redis_port}"实例已经是启动状态!${black}"
netstat -lnpt | grep ${redis_port}
fi
fi
}
编写关闭模块
思路:首先判断进程是否存在,如果存在就执行关闭命令,不存在就直接输出没有启动。
这里还需要判断一下state的值是不是空的,因为到重启模块需要判断,在重启模块会定义一个state值,这里检测到state的值为空就输出echo的内容,到了restart的时候如果进程一开始是没有的无需输出echo内容,主要是为了重启的时候不输出这些echo。
Stop(){
redis_cz=`netstat -lnpt | grep redis | grep "${redis_port}" | wc -l`
if [ $redis_cz -gt 0 ];then
redis-cli -h $redis_host -p $redis_port shutdown
if [ -z $state ];then
echo -e "${green}redis ${redis_port}实例关闭成功!"
fi
else
if [ -z $state ];then
echo -e "${red}redis "${redis_port}"实例没有启动!${black}"
fi
fi
}
编写重启模块
思路:重启模块直接调用Stop模块和Start模块即可。
重启模块一开始要增加一个state的变量,当执行stop模块的时候就去判断state的值,如果不为空即使是没有进程也不需要输出stop模块的echo命令,直接执行start,属于跳过某个命令的实现吧。
Restart(){
state=restart
Stop
Start
}
编写登陆模块
思路:首先判断redis有没有启动,如果没有启动就询问是否启动,按y启动,按n就退出。
Login(){
redis_cz=`netstat -lnpt | grep redis | grep "${redis_port}" | wc -l`
if [ $redis_cz -gt 0 ];then
redis-cli -h $redis_host -p $redis_port
else
echo -e "${red}redis ${redis_port}实例没有启动!${black}"
echo -en "${yellow}是否要启动reis? [y/n]${black}"
read action
case $action in
y|Y)
Start
Login
;;
n|N)
exit 1
;;
esac
fi
}
编写查看进程模块
思路:直接用ps查即可。
Ps(){
ps aux | grep redis
}
编写查看日志模块
思路:配合各种变量去找到指令路径的日志即可。
Logs(){
tail -f ${redis_home}/logs/${redis_name}.log
}
编写帮助信息模块
思路:通过echo输出提示信息。
Help(){
Usage
echo "+-------------------------------------------------------------------------------+"
echo "| start 启动redis |"
echo "| stop 关闭redis |"
echo "| restart 重启redis |"
echo "| login 登陆redis |"
echo "| ps 查看redis的进程信息,不需要加端口号 |"
echo "| logs 查看redis日志持续输出 |"
echo "| 除ps命令外,所有命令后面都需要加端口号 |"
echo "+-------------------------------------------------------------------------------+"
}
编写判断脚本参数模块
思路:判断脚本的参数是否不等于2,如果传入的参数不是两个的时候(因为很多模块都需要传入指令和端口这俩参数),再判断$1传入的值是不是ps和-h,因为ps和-h只需要一个参数即可,如果不是ps和-h,那么久输出使用方法,然后退出脚本。
if [ $# -ne 2 ];then
if [ "$1" != "ps" ] && [ "$1" != "-h" ];then
Usage
exit 1
fi
fi
编写指令判断模块
思路:通过case实现,根据不同的指令执行不同的函数。
case $1 in
start)
Start
;;
stop)
Stop
;;
restart)
Restart
;;
login)
Login
;;
ps)
Ps
;;
logs)
Logs
;;
-h)
Help
;;
*)
Help
;;
esac
整合脚本内容
#!/bin/bash
#redis控制脚本
redis_port=$2
redis_name="redis_${redis_port}"
redis_home=/data/redis_cluster/${redis_name}
redis_conf=${redis_home}/conf/${redis_name}.conf
redis_host=`ifconfig ens33 | awk 'NR==2{print $2}'`
redis_pass=$3
red="\e[031m"
green="\e[032m"
yellow="\e[033m"
black="\e[0m"
Usage(){
echo "usage: sh $0 {start|stop|restart|login|ps|logs|-h} PORT"
}
Start(){
redis_cz=`netstat -lnpt | grep redis | grep "${redis_port}" | wc -l`
if [ $redis_cz -eq 0 ];then
redis-server ${redis_conf}
if [ -z $state ];then
echo -e "${green}redis ${redis_port}实例启动成功!${black}"
else
echo -e "${green}redis ${redis_port}实例重启成功!${black}"
fi
netstat -lnpt | grep ${redis_port}
else
if [ -z $state ];then
echo -e "${yellow}redis "${redis_port}"实例已经是启动状态!${black}"
netstat -lnpt | grep ${redis_port}
fi
fi
}
Stop(){
redis_cz=`netstat -lnpt | grep redis | grep "${redis_port}" | wc -l`
if [ $redis_cz -gt 0 ];then
redis-cli -h $redis_host -p $redis_port shutdown
if [ -z $state ];then
echo -e "${green}redis ${redis_port}实例关闭成功!"
fi
else
if [ -z $state ];then
echo -e "${red}redis "${redis_port}"实例没有启动!${black}"
fi
fi
}
Restart(){
state=restart
Stop
Start
}
Login(){
redis_cz=`netstat -lnpt | grep redis | grep "${redis_port}" | wc -l`
if [ $redis_cz -gt 0 ];then
redis-cli -h $redis_host -p $redis_port
else
echo -e "${red}redis ${redis_port}实例没有启动!${black}"
echo -en "${yellow}是否要启动reis? [y/n]${black}"
read action
case $action in
y|Y)
Start
Login
;;
n|N)
exit 1
;;
esac
fi
}
Ps(){
ps aux | grep redis
}
Logs(){
tail -f ${redis_home}/logs/${redis_name}.log
}
Help(){
Usage
echo "+-------------------------------------------------------------------------------+"
echo "| start 启动redis |"
echo "| stop 关闭redis |"
echo "| restart 重启redis |"
echo "| login 登陆redis |"
echo "| ps 查看redis的进程信息,不需要加端口号 |"
echo "| logs 查看redis日志持续输出 |"
echo "| 除ps命令外,所有命令后面都需要加端口号 |"
echo "+-------------------------------------------------------------------------------+"
}
if [ $# -ne 2 ];then
if [ "$1" != "ps" ] && [ "$1" != "-h" ];then
Usage
exit 1
fi
fi
case $1 in
start)
Start
;;
stop)
Stop
;;
restart)
Restart
;;
login)
Login
;;
ps)
Ps
;;
logs)
Logs
;;
-h)
Help
;;
*)
Help
;;
esac
使用 redis 运维脚本
查看帮助信息
[root@redis-1 ~]# sh redis_shell.sh -h
usage: sh redis_shell.sh {start|stop|restart|login|ps|logs|-h} PORT
+-------------------------------------------------------------------------------+
| start 启动redis |
| stop 关闭redis |
| restart 重启redis |
| login 登陆redis |
| ps 查看redis的进程信息,不需要加端口号 |
| logs 查看redis日志持续输出 |
| 除ps命令外,所有命令后面都需要加端口号 |
+-------------------------------------------------------------------------------+
启动redis
第一次启动会提示启动成功,第二次在启动提示已经启动
[root@redis-1 ~]# sh redis_shell.sh start 6379
redis 6379实例启动成功!
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 101765/redis-server
tcp 0 0 192.168.81.210:6379 0.0.0.0:* LISTEN 101765/redis-server
[root@redis-1 ~]# sh redis_shell.sh start 6379
redis 6379实例已经是启动状态!
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 101765/redis-server
tcp 0 0 192.168.81.210:6379 0.0.0.0:* LISTEN 101765/redis-server
[root@redis-1 ~]#
关闭 redis
[root@redis-1 ~]# sh redis_shell.sh stop 6379
redis 6379实例关闭成功!
[root@redis-1 ~]#
[root@redis-1 ~]# sh redis_shell.sh stop 6379
redis 6379实例没有启动!
重启 redis
[root@redis-1 ~]# sh redis_shell.sh restart 6379
redis 6379实例重启成功!
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 102654/redis-server
tcp 0 0 192.168.81.210:6379 0.0.0.0:* LISTEN 102654/redis-server
登陆 redis
启动了redis进行登陆
[root@redis-1 ~]# sh redis_shell.sh login 6379
192.168.81.210:6379> DBSIZE
(integer) 0
没有启动redis进行登陆,首先询问是否启动,启动即可进入,不启动就退出
[root@redis-1 ~]# sh redis_shell.sh login 6379
redis 6379实例没有启动!
是否要启动reis? [y/n]y
redis 6379实例启动成功!
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN -
tcp 0 0 192.168.81.210:6379 0.0.0.0:* LISTEN -
192.168.81.210:6379> DBSIZE
(integer) 0
192.168.81.210:6379> exit
[root@redis-1 ~]# sh redis_shell.sh stop 6379
redis 6379实例关闭成功!
[root@redis-1 ~]# sh redis_shell.sh login 6379
redis 6379实例没有启动!
是否要启动reis? [y/n]n
查看进程
无需跟端口号
[root@redis-1 ~]# sh redis_shell.sh ps
avahi 6935 0.0 0.1 62272 2296 ? Ss 1月29 0:04 avahi-daemon: running [redis-1.local]
root 79457 0.1 0.4 136972 7720 ? Ssl 2月01 1:43 redis-server 192.168.81.210:6380 [cluster]
root 79461 0.1 0.4 136972 7688 ? Ssl 2月01 1:44 redis-server 192.168.81.210:6381 [cluster]
root 101261 0.0 0.3 151888 5648 pts/2 S+ 13:10 0:01 vim redis_shell.sh
root 102767 0.0 0.0 113176 1412 pts/0 S+ 13:51 0:00 sh redis_shell.sh ps
root 102772 0.0 0.0 112728 968 pts/0 R+ 13:51 0:00 grep redis
查看日志
持续输出日志信息
[root@redis-1 ~]# sh redis_shell.sh logs 6379
来源:
https://jiangxl.blog.csdn.net/article/details/121027928
(十七):Redis 缓存问题(一致性、击穿、穿透、雪崩、污染)
缓存存在的意义
将一些数据(最近访问的)放在缓存中,当客户端需要访问数据库中数据时,可以先访问缓存,如果它里面存在这样对应的数据就不会去访问数据库,从而减小数据库的压力。
那么客户端对数据库的操作有 增删改查,但是只有当查数据库里面的信息时才会先访问缓存,那么缓存里的数据时如何更新的?它会不会有数据更新不及时的问题?
如何保证缓存和数据库数据一致性
缓存数据插入的时机
当客户端来说, 查询数据时的步骤如下 :
1、首先到缓存查询数据,如果数据存在则直接获取数据返回
2、如果缓存不存在,需要查询数据库,从数据库获取数据并插入缓存,将数据返回
3、当第二次查询这个数据时并且这个数据在缓存中尚未过期,查询操作就可以查询缓存拿到对应的数据
缓存更新数据(3种方案)
客户端对数据库进行一个更改操作:
1、先删除缓存在更新数据库
进行更新数据库数据时,先删除缓存,然后更新数据库,后续的请求再次读取数据时,会从数据库中读取数据更新到缓存。
存在问题:删除缓存之后,更新数据库之前,这个时间段内如果有新的请求过来,就会从数据库中读到旧的数据并写入缓存,再次造成数据不一致,并且后续读操作都是旧数据。
2、先更新数据库在删除缓存
进行更新操作,先更新数据库,成功之后,在删除缓存,后续请求将新数据写回缓存。
存在问题:更新MySQL之后和删除缓存之前的这段时间内,请求读取的还是缓存内的旧数据,不过等数据库更新完成后,就会恢复一致。
3、异步更新缓存
数据库的更新操作完成后不直接操作缓存,将操作命令封装成消息放到消息队列里,然后由Redis自己去更新数据,消息队列保证数据操作数据的一致性,保证缓存数据的数据正常。
缓存问题
缓存穿透
大量请求在数据库查不到相应数据
概念
缓存穿透是指用户想查询一个数据,发现Redis中没有,也就是缓存没有命中,就像持久性数据库发起查询,发现数据库也没有这个数据,于是查询失败了, 当用户请求很多的情况下,缓存没有命中,数据库也没有数据,会都直接访问数据库,给数据库造成很大的压力,这就是缓存穿透。
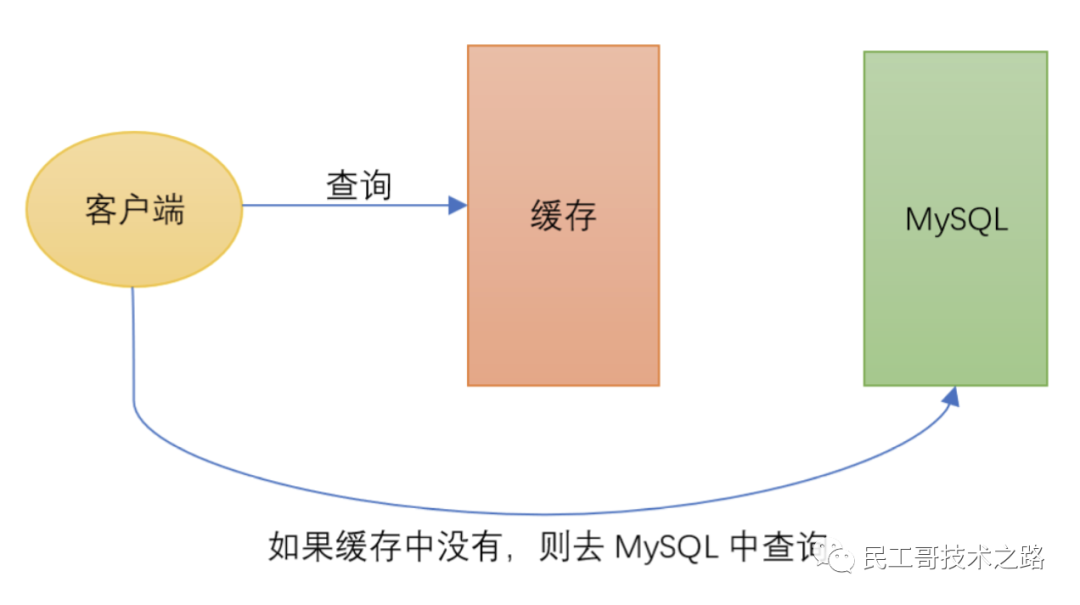
解决方案
第一种解决方案:使用布隆过滤器
判断对应的数据是否在这个数据库里,使用布隆过滤器,如果全返回1,则可能存在;如果返回结果存在一个不是1,那就肯定不在这个数据库中,这样就可以拒绝这个请求去访问数据库,大大降低数据库的压力。
布隆过滤器(Bloom Filter)的 核心实现是一个超大的位数组和几个哈希函数 。假设位数组的长度为m,哈希函数的个数为k。
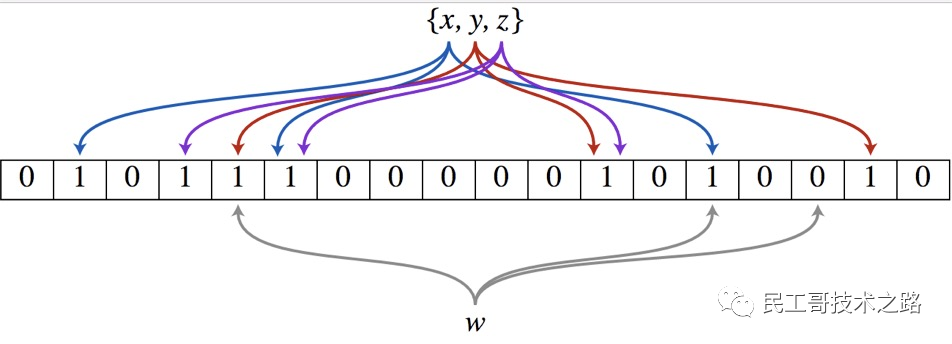
以上图为例,具体的操作流程:假设集合里面有3个元素{x, y, z},哈希函数的个数为3。首先将位数组进行初始化,将里面每个位都设置位0。对于集合里面的每一个元素,将元素依次通过3个哈希函数进行映射,每次映射都会产生一个哈希值,这个值对应位数组上面的一个点,然后将位数组对应的位置标记为1。查询W元素是否存在集合中的时候,同样的方法将W通过哈希映射到位数组上的3个点。如果3个点的其中有一个点不为1,则可以判断该元素一定不存在集合中。反之,如果3个点都为1,则该元素可能存在集合中。注意:此处不能判断该元素是否一定存在集合中,可能存在一定的误判率。可以从图中可以看到:假设某个元素通过映射对应下标为4,5,6这3个点。虽然这3个点都为1,但是很明显这3个点是不同元素经过哈希得到的位置,因此这种情况说明元素虽然不在集合中,也可能对应的都是1,这是误判率存在的原因。
使用布隆过滤器之后,将存储的数据放入布隆过滤器,每次数据查询首先查询布隆过滤器,当在过滤器中判断存在时在到数据库缓存查询,如果没有进入数据查询,如果在过滤器不存在,则直接返回告诉用户该数据查不到,这样能大大减轻数据库查询压力。
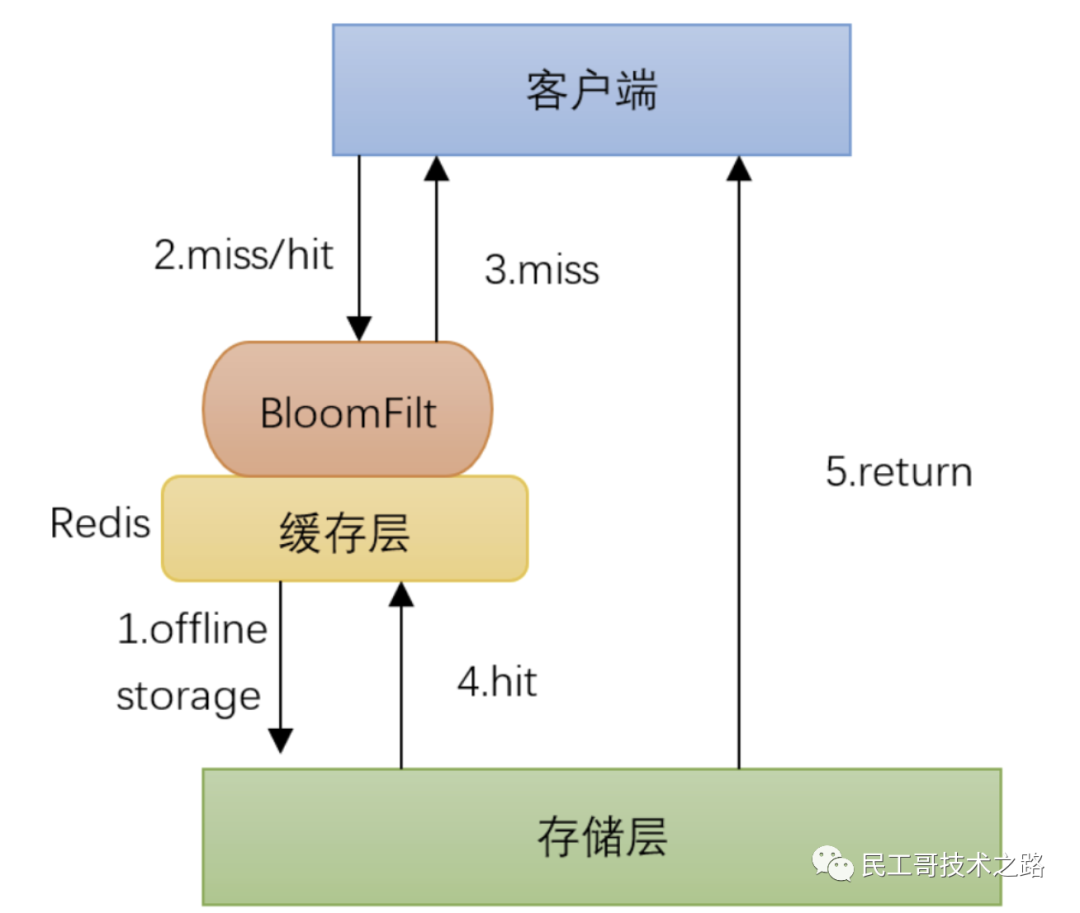
第二种方案:缓存空对象
当数据库数据不存在时,及时返回的空对象也缓存起来,同时设置一个过期时间,之后在访问数据将从缓存中获取,保护了数据库。
存在问题:
1、对空值设置过期时间,会存在更新数据库数据到缓存数据失效的一段时间,缓存数据有问题,会对要保证数据一致性的业务造成影响
2、会需要更多的空间来存储更多的控制,造成内存中有大量的空值的键
缓存击穿
请求量太大,缓存突然过期
缓存击穿是 指一个key是一个热点key,在不停的扛着大量的并发,当缓存中的key在失效的瞬间,持续的大并发就会穿破缓存,直接请求到数据库。对数据库造成瞬间压力过大。
解决方案
第一种方案:热点数据永不过期
从缓存角度看,没有设置过期时间,就不会存在缓存过期之后产生的问题。
第二种方案:加互斥锁
使用分布式锁,保证对每个key的访问同一时刻只能一个线程去查询后端服务,其他没有获取锁权限的线程则等待即可。
缓存雪崩
在某一个时间段,缓存集中过期失效或者Redis宕机。
对于数据库而言,所有请求压力会全部到达数据库,导致数据库调用量暴增,可能也造成数据库宕机的情况。
解决方案
第一种方案:Redis采用高可用
这种方案的思路就是讲数据在Redis中存放在服务器上,即使一个服务器挂掉,其他服务器还可以继续工作。
第二种方案:限流降级
这种思路就是在缓存失效后,通过加锁或者队列来控制读取数据库的线程数量让线程在队列排队,控制整体请求速率。
第三种方案:数据预热
数据预热及时在正是部署服务之前,先访问一遍数据,可以将大部分的数据加载到缓存中,在即将发生大并发之前已经加载不同的key,设置不同的过期时间,让缓存失效的时间更加均匀。
双写一致性
含义
双写一致性的含义就是: 保证缓存中的数据和DB中数据一致。
单线程下的解决方案
单线程下实际上就是指并发不大,或者说对缓存和DB数据一致性要求不是很高的情况。
该问题就是经典的: 缓存+数据库读写的模式,就是 Cache Aside Pattern
解决思路
- 查询的时候,先查缓存,缓存中有数据,直接返回;缓存中没有数据,去查询数据库,然后更新缓存。
- 更新DB的后,删除缓存。
剖析:
(1).为什么更新DB后,是删除缓存,而不是更新缓存呢?
举个例子,比如该DB更新的频率很高,比如1min中内更新100次把,如果更新缓存,缓存也对应了更新了100次,但缓存在这一分钟内根本没被调用,或者说该缓存10min才可能会被查询一次,那么频繁更新缓存是不是就产生了很多不必要的开销呢。
所以我们这里的思路是: 用到缓存的时候,才去计算缓存。
(2).该方案高并发场景下是否适用?
不适用
比如更新DB后,还有没有来得及删除缓存,别的请求就已经读取到缓存的数据了,此时读取的数据和DB中的实际的数据是不一致的。
高并发下的解决方案
使用内存队列解决,把 读请求 和 写请求 都放到队列中,按顺序执行(即串行化的方式解决) 。(要定义多个队列,不同的商品放到不同的队列中,换言之,同一个队列中只有一类商品)
剖析:
这种方案也有弊端,当并发量高了,队列容易阻塞,这个队列的位置,反而成了整个系统的瓶颈了,所以说100%完美的方案不存在,只有最适合的方案,没有最完美的方案。
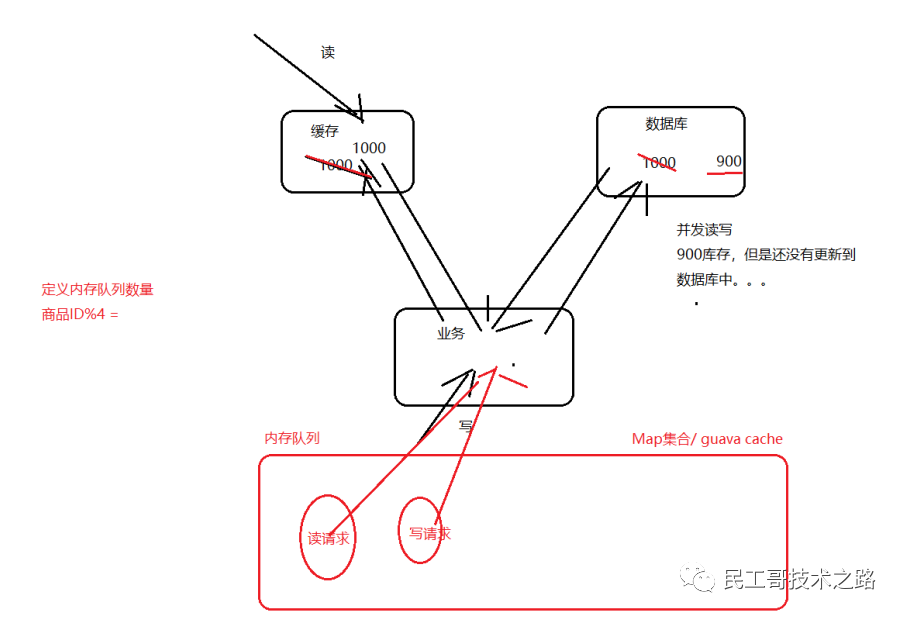
并发竞争
含义
多个微服务系统要同时操作redis的同一个key,比如正确的顺序是 A→B→C,A执行的时候,突然网络抖动了一下,导致B,C先执行了,从而导致整个流程业务错误。
解决方案
引入分布式锁(zookeeper 或 redis自身)
每个系统在操作之前,都要先通过 Zookeeper 获取分布式锁, 确保同一时间,只能有一个系统实例在操作这个个 Key,别系统都不允许读和写 。
热点缓存key的重建优化
背景
开发人员使用“缓存+过期时间”的策略既可以加速数据读写,又保证数据的定期更新,这种模式基本能够满足绝大部分需求。但是有两个问题如果同时出现,可能就会对应用造成致命的危害:
- 当前key是一个热点key(例如一个热门的娱乐新闻),并发量非常大。
- 重建缓存不能在短时间完成,可能是一个复杂计算,例如复杂的SQL、多次IO、 多个依赖等。
在缓存失效的瞬间,有大量线程来重建缓存,造成后端负载加大,甚至可能会让应用崩溃。
解决方案
要解决这个问题主要就是要 避免大量线程同时重建缓存。
我们可以利用 互斥锁 来解决,此方法 只允许一个线程重建缓存 ,其他线程等待重建缓存的线程执行完,重新从缓存获取数据即可。
代码思路分享:
String get(String key) {
// 从Redis中获取数据
String value = redis.get(key);
// 如果value为空, 则开始重构缓存
if (value == null) {
// 只允许一个线程重建缓存, 使用nx, 并设置过期时间ex
String mutexKey = "mutext:key:" + key;
if (redis.set(mutexKey, "1", "ex 180", "nx")) {
// 从数据源获取数据
value = db.get(key);
// 回写Redis, 并设置过期时间
redis.setex(key, timeout, value);
// 删除key\_mutex
redis.delete(mutexKey);
}
else {
//其它线程休息50ms,重写递归获取
Thread.sleep(50);
get(key);
}
}
return value;
}
缓存污染(或满了)
缓存污染问题说的是缓存中一些只会被访问一次或者几次的的数据,被访问完后,再也不会被访问到,但这部分数据依然留存在缓存中,消耗缓存空间。
缓存污染会随着数据的持续增加而逐渐显露,随着服务的不断运行,缓存中会存在大量的永远不会再次被访问的数据。缓存空间是有限的,如果缓存空间满了,再往缓存里写数据时就会有额外开销,影响Redis性能。这部分额外开销主要是指写的时候判断淘汰策略,根据淘汰策略去选择要淘汰的数据,然后进行删除操作。
最大缓存设置多大
系统的设计选择是一个权衡的过程:大容量缓存是能带来性能加速的收益,但是成本也会更高,而小容量缓存不一定就起不到加速访问的效果。一般来说,我会建议 把缓存容量设置为总数据量的 15% 到 30%,兼顾访问性能和内存空间开销。
对于 Redis 来说,一旦确定了缓存最大容量,比如 4GB,你就可以使用下面这个命令来设定缓存的大小了:
CONFIG SET maxmemory 4gb
不过,缓存被写满是不可避免的, 所以需要数据淘汰策略。
缓存淘汰策略
Redis共支持 八种淘汰策略 ,分别是 noeviction、volatile-random、volatile-ttl、volatile-lru、volatile-lfu、allkeys-lru、allkeys-random 和 allkeys-lfu 策略。
怎么理解呢?主要看分三类看:
- 不淘汰
- noeviction(v4.0后默认的)
- 对设置了过期时间的数据中进行淘汰
- 随机:volatile-random
- ttl:volatile-ttl
- lru:volatile-lru
- lfu:volatile-lfu
- 全部数据进行淘汰
- 随机:allkeys-random
- lru:allkeys-lru
- lfu:allkeys-lfu
BigKey的危害及优化
什么是BigKey
在Redis中,一个字符串最大512MB,一个二级数据结构(例如hash、list、set、zset)可以存储大约40亿个(2^32-1)个元素,但实际中如果下面两种情况,我就会认为它是bigkey。
字符串类型:它的big体现在单个value值很大,一般认为超过10KB就是bigkey。
非字符串类型:哈希、列表、集合、有序集合,它们的big体现在元素个数太多。
一般来说, string类型控制在10KB以内,hash、list、set、zset元素个数不要超过5000 。反例:一个包含200万个元素的list。非字符串的bigkey,不要使用del删除,使用hscan、sscan、zscan方式渐进式删除,同时要注意防止bigkey过期时间自动删除问题(例如一个200万的zset设置1小时过期,会触发del操作,造成阻塞)
BigKey的危害
- 导致redis阻塞
- 网络拥塞
bigkey也就意味着每次获取要产生的网络流量较大,假设一个bigkey为1MB,客户端每秒访问量为1000,那么每秒产生1000MB的流量,对于普通的千兆网卡(按照字节算是128MB/s)的服务器来说简直是灭顶之灾,而且一般服务器会采用单机多实例的方式来部署,也就是说一个bigkey
可能会对其他实例也造成影响,其后果不堪设想。
- 过期删除
有个bigkey,它安分守己(只执行简单的命令,例如hget、lpop、zscore等),但它设置了过期时间,当它过期后,会被删除,如果没有使用Redis 4.0的过期异步删除(lazyfree-lazy-expire yes),就会存在阻塞Redis的可能性。
BigKey的产生
一般来说,bigkey的产生都是由于程序设计不当,或者对于数据规模预料不清楚造成的,来看几个例子:
-
社交类 :粉丝列表,如果某些明星或者大v不精心设计下,必是bigkey。
-
统计类 :例如按天存储某项功能或者网站的用户集合,除非没几个人用,否则必是bigkey。
-
缓存类 :将数据从数据库load出来序列化放到Redis里,这个方式非常常用,但有两个地方需注意:第一,是不是有必要把所有字段都缓存;第二,有没有相关关联的数据,有的同学为了图方便把相关数据都存一个key下,产生bigkey。
BigKey的优化
- 拆
big list:list1、list2、…listN
big hash:可以将数据分段存储,比如一个大的key,假设存了1百万的用户数据,可以拆分成200个key,每个key下面存放5000个用户数据
合理采用数据结构
如果bigkey不可避免,也要思考一下要不要每次把所有元素都取出来(例如有时候仅仅需要hmget,而不是hgetall),删除也是一样,尽量使用优雅的方式来处理.
反例:
set user:1:name tom
set user:1:age 19
set user:1:favor football
推荐hash存对象
hmset user:1 name tom age 19 favor football
控制key的生命周期,redis不是垃圾桶。
建议使用expire设置过期时间(条件允许可以打散过期时间,防止集中过期)。
参考文章:
https://blog.csdn.net/xkyjwcc/article/details/121704554
https://www.cnblogs.com/shoshana-kong/p/17226404.html
(十八):Redis 内存消耗及回收
Redis 是一个开源、高性能的 Key-Value 数据库,被广泛应用在服务器各种场景中。Redis 是一种内存数据库,将数据保存在内存中,读写效率要比传统的将数据保存在磁盘上的数据库要快很多。所以,监控 Redis 的内存消耗并了解 Redis 内存模型对高效并长期稳定使用 Redis 至关重要。
在介绍之前先说明下,一般生产环境下,对开发同事不会开放直连 redis 集群的权限,一般是提供 daas 平台,通过可视化命令窗口,输入 redis 命令,一般只有 read 权限;对于 write 操作,需要提 redis 数据变更单,而对于 redis 内存、大 key、慢命令,一般都会将信息集成及中显示在监控看板,而不需要开发同事自己去输入命令;但是基本的相关知识还是要具备的。
reids 内存分析
redis 内存使用情况: info memory

示例:
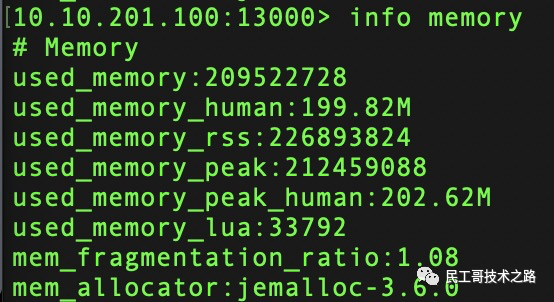
可以看到,当前节点内存碎片率为 226893824/209522728 ≈ 1.08,使用的内存分配器是 jemalloc。
used_memory_rss 通常情况下是大于 used_memory 的,因为内存碎片的存在。
但是 当操作系统把 redis 内存 swap 到硬盘时,memory_fragmentation_ratio 会小于 1 。redis 使用硬盘作为内存,因为硬盘的速度,redis 性能会受到极大的影响。
redis 内存使用
redis 的内存使用分布:自身内存,键值对象占用、缓冲区内存占用及内存碎片占用。
redis 空进程自身消耗非常的少,可以忽略不计,优化内存可以不考虑此处的因素。
对象内存
对象内存,也即真实存储的数据所占用的内存。
redis k-v 结构存储, 对象占用可以简单的理解为 k-size + v-size。
redis 的键统一都为字符串类型,值包含多种类型:string、list、hash、set、zset五种基本类型及基于 string 的 Bitmaps 和 HyperLogLog 类型等。
在实际的应用中,一定要做好 kv 的构建形式及内存使用预期,。
缓冲内存
缓冲内存包括三部分: 客户端缓存、复制积压缓存及 AOF 缓冲区。
客户端缓存
接入redis服务器的TCP连接输入输出缓冲内存占用,TCP 输入缓冲占用是不受控制的,最大允许空间为 1G。输出缓冲占用可以通过 client-output-buffer-limit 参数配置。
redis 客户端主要分为 从客户端、订阅客户端和普通客户端。
从客户端连接占用
也就是我们所说的 slave,主节点会为每一个从节点建立一条连接用于命令复制,缓冲配置为:client-output-buffer-limit slave 256mb 64mb 60。
主从之间的间络延迟及挂载的从节点数量是影响内存占用的主要因素。因此在涉及需要异 地部署 主从时要特别注意,另外,也要 避免主节点上挂载过多的从节点(<=2);
订阅客户端内存占用
发布订阅功能连接客户端使用单独的缓冲区,默认配置:client-output-buffer-limit pubsub 32mb 8mb 60。
当消费慢于生产时会造成缓冲区积压,因此需要特别注意消费者角色配比及生产、消费速度的监控。
普通客户端内存占用
除了上述之外的其它客户端,如我们通常的应用连接,默认配置:client-output-buffer-limit normal 1000。
可以看到,普通客户端没有配置缓冲区限制,通常一般的客户端内存消耗也可以忽略不计。
但是当 redis 服务器响应较慢时,容易造成大量的慢连接,主要表现为连接数的突增,如果不能及时处理,此时会严重影响 redis 服务节点的服务及恢复。
关于此, 在实际应用中需要注意几点:
- maxclients 最大连接数配置必不可少。
- 合理预估单次操作数据量(写或读)及网络时延 ttl。
- 禁止线上大吞吐量命令操作,如 keys 等。
高并发应用情景下,redis内存使用需要有实时的监控预警机制。
复制积压缓冲区
v2.8 之后提供的一个可重用的固定大小缓冲区,用以实现向从节点的部分复制功能,避免全量复制。配置单数:repl-backlog-size,默认 1M。单个主节点配置一个复制积压缓冲区。
AOF缓冲区
AOF重写期间增量的写入命令保存,此部分缓存占用大小取决于 AOF 重写时间及增量。
内存碎片内存占用
固定范围内存块儿分配。redis默认使用jemalloc内存分配器,其它包括glibc、tcmalloc。
内存分配器会首先将可管理的内存分配为规定不同大小的内存块以备不同的数据存储需求,但是,我们知道实际应用中需要存储的数据大小不一,规范不一,内存分配器只能选择最接近数据需求大小的内存块儿进行分配,这样就伴随着“占不满”空间的碎片浪费。
jemalloc针对内存碎片有相应的优化策略,正常碎片率为mem_fragmentation_ratio在1.03左右。
第二部分我们说过,对string值得频繁append及range操作会会导致内存碎片问题,另外,第七部分,SDS惰性内存回收也会导致内存碎片,同时过期键内存回收也伴随着所释放空间的无法充分利用,导致内存碎片率上升的问题。
碎片处理:
- 应用层面:尽量避免差异化的键值使用,做好数据对齐。
- redis服务层面:可以通过重启服务,进行碎片整理。
maxmemory 及 maxmemory-policy
redis 基于以上配置控制 redis 最大可用内存及内存回收。需要注意的是内存回收执行影响redis的性能,避免频繁的内存回收开销。
redis 子进程内存消耗
子进程即 redis 执行持久化(RDB/AOF)时 fork 的子任务进程。
关于 linux 系统的写时复制机制
父子进程会共享相同的物理内存页 ,父进程处理写请求时会对需要修改的页复制一份副本进行修改,子进程读取的内存则为fork时的父进程内存快照,因此,子进程的内存消耗由期间的写操作增量决定。
关于 linux 的透明大页机制THP(Transparent Huge Page)
THP 机制会降低 fork 子进程的速度 :写时复制内存页由 4KB 增大至 2M。高并发情境下,写时复制内存占用消耗影响会很大,因此需要选择性关闭。
关于linux配置
一般需要配置 linux 系统 vm.overcommit_memory = 1 ,以允许系统可以分配所有的物理内存。防止fork任务因内存而失败。
redis 内存管理
redis 的内存管理主要分为两方面: 内存上限控制及内存回收管理 。
内存上限:maxmemory
目的:缓存应用内存回收机制触发 + 防止物理内存用尽(redis 默认无限使用服务器内存) + 服务节点内存隔离(单服务器上部署多个 redis 服务节点)
在进行内存分配及限制时要充分考虑内存碎片占用影响。动态调整,扩展redis服务节点可用内存:config set maxmemory {}
内存回收
回收时机:键过期、内存占用达到上限
过期键删除
redis 键过期时间保存在内部的过期字典中,redis 采用惰性删除机制+定时任务删除机制。
惰性删除
即读时删除,读取带有超时属性的键时,如果键已过期,则删除然后返回空值。这种方式存在问题是,触发时机,加入过期键长时间未被读取,那么它将会一直存在内存中,造成内存泄漏。
定时任务删除
redis 内部维护了一个定时任务(默认每秒10次,可配置),通过自适应法进行删除。
删除逻辑如下:
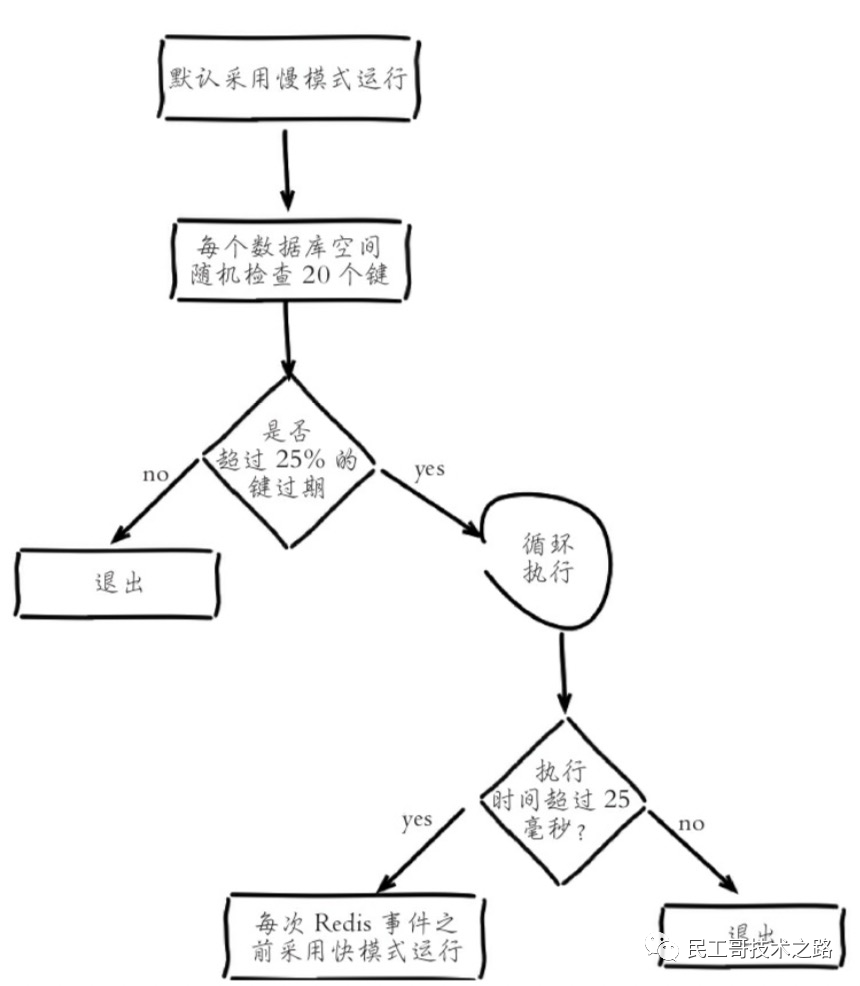
需要说明的一点是,快慢模式执行的删除逻辑相同,这是超时时间不同。
内存溢出控制
当内存达到 maxmemory,会触发内存回收策略,具体策略依据 maxmemory-policy 来执行。
- noevication:默认不回收,达到内存上限,则不再接受写操作,并返回错误。
- volatile-lru:根据LRU算法删除设置了过期时间的键,如果没有则不执行回收。
- allkeys-lru:根据LRU算法删除键,针对所有键。
- allkeys-random:随机删除键。
- volatitle-random:随机删除设置了过期时间的键。
- volatilte-ttl:根据键ttl,删除最近过期的键,同样如果没有设置过期的键,则不执行删除。
动态配置:config set maxmemory-policy {}
在设置了maxmemory情况下,每次的redis操作都会检查执行内存回收,因此对于线上环境,要确保所这只的 maxmemory > used_memory。
另外,可以通过动态配置 maxmemory 来主动触发内存回收。更多关于 Redis 学习的文章,请参阅:NoSQL 数据库系列之 Redis,本系列持续更新中。
内存回收策略
内存回收触发有两种情况,也就是 内存使用达到maxmemory上限时候触发的溢出回收 ,还有一种是我们设置了 **** 过期的对象到期的时候触发的到期释放的内存回收。
Redis内存使用达到maxmemory上限时候触发的溢出回收;Redis 提供了几种策略 (maxmemory-policy) 来让用户自己决定该如何腾出新的空间以继续提供读写服务:
(1)volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
(2)volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
(3)volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
(4)allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key(这个是最常用的)
(5)allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
(6)no-eviction:禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。这个应该没人使用吧!
4.0版本后增加以下两种:
(7)volatile-lfu:从已设置过期时间的数据集(server.db[i].expires)中挑选最不经常使用的数据淘汰
(8)allkeys-lfu:当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的key
redis默认的策略就是noeviction策略,如果想要配置的话,需要在配置文件中写这个配置:
maxmemory-policy volatile-lru
Redis 的 LRU 算法
LRU是Least Recently Used 近期最少使用算法,很多缓存策略都使用了这种策略进行空间的释放,在学习操作系统的内存回收的时候也用到了这种机制进行内存的回收,类似的还有LFU(Least Frequently Used)最不经常使用算法,这种算法。
我们在上面的描述中也可以了解到,redis使用的是一种类似LRU的算法进行内存溢出回收的,其算法的代码:
/* volatile-lru and allkeys-lru policy */
else if (server.maxmemory_policy == REDIS_MAXMEMORY_ALLKEYS_LRU ||
server.maxmemory_policy == REDIS_MAXMEMORY_VOLATILE_LRU)
{
struct evictionPoolEntry *pool = db->eviction_pool;
while(bestkey == NULL) {
evictionPoolPopulate(dict, db->dict, db->eviction_pool);
/* Go backward from best to worst element to evict. */
for (k = REDIS_EVICTION_POOL_SIZE-1; k >= 0; k--) {
if (pool[k].key == NULL) continue;
de = dictFind(dict,pool[k].key);
/* Remove the entry from the pool. */
sdsfree(pool[k].key);
/* Shift all elements on its right to left. */
memmove(pool+k,pool+k+1,
sizeof(pool[0])*(REDIS_EVICTION_POOL_SIZE-k-1));
/* Clear the element on the right which is empty
* since we shifted one position to the left. */
pool[REDIS_EVICTION_POOL_SIZE-1].key = NULL;
pool[REDIS_EVICTION_POOL_SIZE-1].idle = 0;
/* If the key exists, is our pick. Otherwise it is
* a ghost and we need to try the next element. */
if (de) {
bestkey = dictGetKey(de);
break;
} else {
/* Ghost... */
continue;
}
}
}
}
Redis会基于server.maxmemory_samples配置选取固定数目的key,然后比较它们的lru访问时间,然后淘汰最近最久没有访问的key,maxmemory_samples的值越大,Redis的近似LRU算法就越接近于严格LRU算法,但是相应消耗也变高。所以,频繁的进行这种内存回收是会降低redis性能的,主要是查找回收节点和删除需要回收节点的开销。
所以一般我们在配置redis的时候,尽量不要让它进行这种内存溢出的回收操作,redis是可以配置maxmemory,used_memory指的是redis真实占用的内存,但是由于操作系统还有其他软件以及内存碎片还有swap区的存在,所以我们实际的内存应该比redis里面设置的maxmemory要大,具体大多少视系统环境和软件环境来定。maxmemory也要比used_memory大,一般由于碎片的存在需要做1~2个G的富裕。
来源:
https://cnblogs.com/niejunlei/p/12898225.html
(十九):Redis Key 过期时间相关的命令、注意事项、回收策略
既然是缓存,就会涉及过期时间以及过期后清理回收内存的过程;
注意:实际上,redis的内存回收触发有 两种情况 ,上面说的是一种,也就是我们设置了 过期的对象到期的时候触发的到期释放的内存回收 ,还有一种是 内存使用达到maxmemory上限时候触发的溢出回收 。
概念
生存时间:(Time To Live, TTL) ,经过指定的秒/毫秒之后,服务器自动删除TTL为0的key
过期时间:(expire time) ,时间戳,表示一个具体时间点,到这个时间点后,服务器会删除key
相关命令
设置生存时间TTL
EXPIRE key ttl #设置ttl,单位s
PEXPIRE key ttl #设置ttl,单位ms
可以对一个已经带有生存时间的 key 执行 EXPIRE 命令,新指定的生存时间会取代旧的生存时间。
EXPIRE key seconds
为给定 key 设置生存时间,当 key 过期时(生存时间为 0 ),它会被自动删除。
在 Redis 中,带有生存时间的 key 被称为『易失的』(volatile)。
生存时间可以通过使用 DEL 命令来删除整个 key 来移除,或者被 SET 和 GETSET 命令覆写(overwrite),这意味着,如果一个命令只是修改(alter)一个带生存时间的 key 的值而不是用一个新的 key 值来代替(replace)它的话,那么生存时间不会被改变。
比如说,对一个 key 执行 INCR 命令,对一个列表进行 LPUSH 命令,或者对一个哈希表执行 HSET 命令,这类操作都不会修改 key 本身的生存时间。
另一方面,如果使用 RENAME 对一个 key 进行改名,那么改名后的 key 的生存时间和改名前一样。
RENAME 命令的另一种可能是,尝试将一个带生存时间的 key 改名成另一个带生存时间的 another_key ,这时旧的 another_key (以及它的生存时间)会被删除,然后旧的 key 会改名为 another_key ,因此,新的 another_key 的生存时间也和原本的 key 一样。
使用 PERSIST 命令可以在不删除 key 的情况下,移除 key 的生存时间,让 key 重新成为一个『持久的』(persistent) key 。
PEXPIRE key milliseconds
这个命令和 EXPIRE 命令的作用类似,但是它以毫秒为单位设置 key 的生存时间,而不像 EXPIRE 命令那样,以秒为单位。
返回值:设置成功返回 1 。
当 key 不存在或者不能为 key 设置生存时间时(比如在低于 2.1.3 版本的 Redis 中你尝试更新 key 的生存时间),返回 0 。
示例:
redis> SET cache_page "www.AA.com"
OK
redis> EXPIRE cache_page 30 # 设置过期时间为 30 秒
(integer) 1
redis> TTL cache_page # 查看剩余生存时间
(integer) 23
redis> EXPIRE cache_page 30000 # 更新过期时间
(integer) 1
redis> TTL cache_page
(integer) 29996
设置过期时间 (指定过期的时间节点)
EXPIREAT key timestamp #设置expire time,s
PEXPIREAT key timestamp #设置exprie time,ms
EXPIREAT key timestamp
EXPIREAT 的作用和 EXPIRE 类似,都用于为 key 设置生存时间。
不同在于 EXPIREAT 命令接受的时间参数是 UNIX 时间戳(unix timestamp)。
PEXPIREAT key milliseconds-timestamp
这个命令和 EXPIREAT 命令类似,但它以毫秒为单位设置 key 的过期 unix 时间戳。
过期时间的精确度
在 Redis 2.4 版本中,过期时间的延迟在 1 秒钟之内 —— 也即是,就算 key 已经过期,但它还是可能在过期之后一秒钟之内被访问到,而在新的 Redis 2.6 版本中,延迟被降低到 1 毫秒之内。
以上4种命令虽然各有不同,但是其底层都是使用 PEXPIREAT 实现的!
删除和更新
PERSIST key #移除生存时间
PERSIST key
移除给定 key 的生存时间,将这个 key 从『易失的』(带生存时间 key )转换成『持久的』(一个不带生存时间、永不过期的 key )。
DLE 命令可以删除key,也会删除其生存时间
SET 和 GETSET 命令也可以覆写生存时间
查看剩余存活时间
TTL key #计算key的剩余生存时间,s
PTTL key #计算key的剩余生存时间,ms
TTL key
以秒为单位,返回给定 key 的剩余生存时间(TTL, time to live)。
PTTL key
这个命令类似于TTL命令,但它以毫秒为单位返回 key 的剩余生存时间。
返回值:
- 当 key 不存在时,返回 -2 。
- 当 key 存在但没有设置剩余生存时间时,返回 -1 。
- 否则,以秒为单位,返回 key 的剩余生存时间。
原理:过期时间如何保存
redisDb结果的expires字典中保存了数据库中的所有key的过期时间,redisDb的声明如下:
/* Redis database representation. There are multiple databases identified
* by integers from 0 (the default database) up to the max configured
* database. The database number is the 'id' field in the structure. */
//每个数据库都是一个redisDb,id为数据库编号
typedef struct redisDb {
dict *dict; //键空间,保存了数据中所有键值对
dict *expires; //过期字典,保存了数据库中所有键的过期时间
dict *blocking_keys;
dict *ready_keys;
dict *watched_keys;
struct evictionPoolEntry *eviction_pool;
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
} redisDb;
expires 的键是一个指针,指向某个键对象,值是一个 long long 类型整数,保存了过期时间,是一个毫秒精度的UNIX时间戳
可见,过期时间的保存是使用key来作为关联的,所以操作用,修改key均可以修改过期时间,而只修改key的value,是不是改变其过期时间的;
如何计算过期时间?
底层的处理方式也很简单,获取key的生存时间戳,减去当前时间戳即可;
- 如果键不存在,则返回-2;
- 如果键没有设置过期时间,则返回-1;
同样可以使用此方法判断key是否过期,TTL/PTTL 结果小于0,则表示过去,大于0,则表示未过期;
Redis的key过期删除策略
有哪些过期删除策略?
-
定时删除 :设置键的过期时间的同时,设置一个定时器,来删除键
-
惰性删除 :放任过期键不管,每次从键空间取值时,检查是否过期,以决定是否删除;
-
定期删除 :每隔一段时间,进行一次数据库检查,删除里面的过期键,至于,要删除多少过期键,以及要检查多少数据库,由算法决定;
各自的利弊?
定时删除
定时删除是指在设置键的过期时间的同时,创建一个定时器,让定时器在键的过期时间来临时,立即执行对键的删除操作。
定时删除策略对内存是最友好的:通过使用定时器,定时删除策略可以保证过期键会尽可能快的被删除,并释放过期键所占用的内存。
定时删除策略的缺点是,他对CPU时间是最不友好的:再过期键比较多的情况下,删除过期键这一行为可能会占用相当一部分CPU时间。
除此之外,创建一个定时器需要用到Redis服务器中的时间事件。而当前时间事件的实现方式----无序链表,查找一个事件的时间复杂度为O(N)----并不能高效地处理大量时间事件。
惰性删除
惰性删除是指放任键过期不管,但是每次从键空间中获取键时,都检查取得的键是否过期,如果过期的话就删除该键,如果没有过期就返回该键。
惰性删除策略对CPU时间来说是最友好的,但对内存是最不友好的。如果数据库中有非常多的过期键,而这些过期键又恰好没有被访问到的话,那么他们也许永远也不会被删除。
Redis 的惰性删除策略由 db.c/expireIfNeeded 函数实现,所有读写Redis的命令在执行之前都会调用expireIfNeeded 函数
定期删除
定期删除是指每隔一段时间,程序就对数据库进行一次检查,删除里面的过期键。
定期删除策略是前两种策略的一种整合和折中:
定期删除策略每隔一段时间执行一次删除过期键操作,并通过限制删除操作执行的时长和频率来减少删除操作对CPU时间的影响。
除此之外,通过定期删除过期键,定期删除策略有效地减少了因为过期键带来的内存浪费。
定期删除策略的难点是确定删除操作执行的时长和频率:
如果删除操作执行的太频繁或者执行的时间太长,定期删除策略就会退化成定时删除策略,以至于将CPU时间过多的消耗在删除过期键上面。
如果删除操作执行的太少,或者执行的时间太短,定期删除策略又会和惰性删除策略一样,出现浪费内存的情况。
redis的过期删除策略?
那你有没有想过一个问题,Redis里面如果有大量的key,怎样才能高效的找出过期的key并将其删除呢,难道是遍历每一个key吗?假如同一时期过期的key非常多,Redis会不会因为一直处理过期事件,而导致读写指令的卡顿。
这里说明一下,Redis是单线程的,所以一些耗时的操作会导致Redis卡顿,比如当Redis数据量特别大的时候,使用keys * 命令列出所有的key。
Redis所有的键都可以设置过期属性,内部保存在过期字典中。由于进程内保存大量的键,维护每个键精准的过期删除机制会导致消耗大量的 CPU,对于单线程的Redis来说成本过高。
因此—— Redis服务器实际使用的是惰性删除和定期删除两种策略 :通过配合使用这两种删除策略,服务器可以很好的在合理使用CPU时间和避免浪费内存空间之间取得平衡。
-
惰性删除 :顾名思义,指的是不主动删除,当用户访问已经过期的对象的时候才删除种方式看似很完美,在访问的时候检查key的过期时间,最大的优点是节省cpu的开销,不用另外的内存和TTL链表来维护删除信息。但是如果一个key已经过期了,如果长时间没有被访问,那么这个key就会一直存留在内存之中,严重消耗了内存资源。
-
定时任务删除 :为了弥补第一种方式的缺点,redis内部还维护了一个定时任务,默认每秒运行10次。定时任务中删除过期逻辑采用了自适应算法,使用快、慢两种速率模式回收键。
-
定期删除 :Redis会将所有设置了过期时间的key放入一个字典中,然后每隔一段时间从字典中随机一些key检查过期时间并删除已过期的key。
Redis默认每秒进行10次过期扫描:
- 从过期字典中随机20个key
- 删除这20个key中已过期的
- 如果超过25%的key过期,则重复第一步
同时,为了保证不出现循环过度的情况,Redis还设置了扫描的时间上限,默认不会超过25ms。
图示:
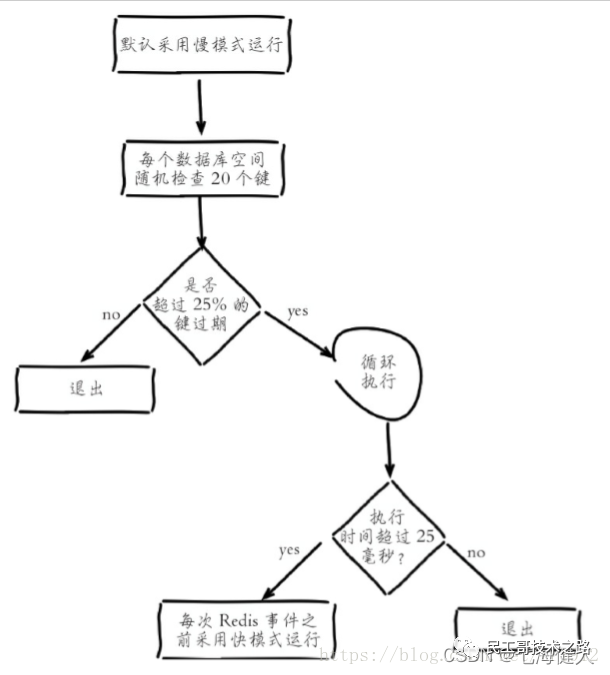
流程说明:
- 定时任务在每个数据库空间随机检查20个键,当发现过期时删除对应的键。
- 如果超过检查数25%的键过期,循环执行回收逻辑直到不足25%或 运行超时为止,慢模式下超时时间为25毫秒。
- 如果之前回收键逻辑超时,则在Redis触发内部事件之前再次以快模 式运行回收过期键任务,快模式下超时时间为1毫秒且2秒内只能运行1次。
- 快慢两种模式内部删除逻辑相同,只是执行的超时时间不同。
定期删除策略的实现
过期键的定期删除策略由函数redis.c/activeExpireCycle实现,每当Redis服务器周期性操作redis.c/serverCron函数执行时,activeExpireCycle函数就会被调用,它在规定的时间内分多次遍历服务器中的各个数据库,从数据库的expires字典中随机检查一部分键的过期时间,并删除其中的过期键。
redis过期时间的注意事项
DEL/SET/GETSET等命令会清除过期时间
在使用DEL、SET、GETSET等会覆盖key对应value的命令操作一个设置了过期时间的key的时候,会导致对应的key的过期时间被清除。
//设置mykey的过期时间为300s
127.0.0.1:6379> set mykey hello ex 300
OK
//查看过期时间
127.0.0.1:6379> ttl mykey
(integer) 294
//使用set命令覆盖mykey的内容
127.0.0.1:6379> set mykey olleh
OK
//过期时间被清除
127.0.0.1:6379> ttl mykey
(integer) -1
INCR/LPUSH/HSET等命令则不会清除过期时间
而在使用INCR/LPUSH/HSET这种只是修改一个key的value,而不是覆盖整个value的命令,则不会清除key的过期时间。
INCR:
//设置incr_key的过期时间为300s
127.0.0.1:6379> set incr_key 1 ex 300
OK
127.0.0.1:6379> ttl incr_key
(integer) 291
//进行自增操作
127.0.0.1:6379> incr incr_key
(integer) 2
127.0.0.1:6379> get incr_key
"2"
//查询过期时间,发现过期时间没有被清除
127.0.0.1:6379> ttl incr_key
(integer) 277
LPUSH:
//新增一个list类型的key,并添加一个为1的值
127.0.0.1:6379> LPUSH list 1
(integer) 1
//为list设置300s的过期时间
127.0.0.1:6379> expire list 300
(integer) 1
//查看过期时间
127.0.0.1:6379> ttl list
(integer) 292
//往list里面添加值2
127.0.0.1:6379> lpush list 2
(integer) 2
//查看list的所有值
127.0.0.1:6379> lrange list 0 1
1) "2"
2) "1"
//能看到往list里面添加值并没有使过期时间清除
127.0.0.1:6379> ttl list
(integer) 252
PERSIST命令会清除过期时间
当使用PERSIST命令将一个设置了过期时间的key转变成一个持久化的key的时候,也会清除过期时间。
127.0.0.1:6379> set persist_key haha ex 300
OK
127.0.0.1:6379> ttl persist_key
(integer) 296
//将key变为持久化的
127.0.0.1:6379> persist persist_key
(integer) 1
//过期时间被清除
127.0.0.1:6379> ttl persist_key
(integer) -1
使用RENAME命令,老key的过期时间将会转到新key上
在使用例如:RENAME KEY_A KEY_B命令将KEY_A重命名为KEY_B,不管KEY_B有没有设置过期时间,新的key KEY_B将会继承KEY_A的所有特性。
//设置key_a的过期时间为300s
127.0.0.1:6379> set key_a value_a ex 300
OK
//设置key_b的过期时间为600s
127.0.0.1:6379> set key_b value_b ex 600
OK
127.0.0.1:6379> ttl key_a
(integer) 279
127.0.0.1:6379> ttl key_b
(integer) 591
//将key_a重命名为key_b
127.0.0.1:6379> rename key_a key_b
OK
//新的key_b继承了key_a的过期时间
127.0.0.1:6379> ttl key_b
(integer) 248
这里篇幅有限,我就不一一将key_a重命名到key_b的各个情况列出来,大家可以在自己电脑上试一下key_a设置了过期时间,key_b没设置过期时间这种情况。
使用EXPIRE/PEXPIRE设置的过期时间为负数或者使用EXPIREAT/PEXPIREAT设置过期时间戳为过去的时间会导致key被删除
EXPIRE:
127.0.0.1:6379> set key_1 value_1
OK
127.0.0.1:6379> get key_1
"value_1"
//设置过期时间为-1
127.0.0.1:6379> expire key_1 -1
(integer) 1
//发现key被删除
127.0.0.1:6379> get key_1
(nil)
EXPIREAT:
127.0.0.1:6379> set key_2 value_2
OK
127.0.0.1:6379> get key_2
"value_2"
//设置的时间戳为过去的时间
127.0.0.1:6379> expireat key_2 10000
(integer) 1
//key被删除
127.0.0.1:6379> get key_2
(nil)
EXPIRE命令可以更新过期时间
对一个已经设置了过期时间的key使用expire命令,可以更新其过期时间。
//设置key_1的过期时间为100s
127.0.0.1:6379> set key_1 value_1 ex 100
OK
127.0.0.1:6379> ttl key_1
(integer) 95
更新key_1的过期时间为300s
127.0.0.1:6379> expire key_1 300
(integer) 1
127.0.0.1:6379> ttl key_1
(integer) 295
在Redis2.1.3以下的版本中,使用expire命令更新一个已经设置了过期时间的key的过期时间会失败。并且对一个设置了过期时间的key使用LPUSH/HSET等命令修改其value的时候,会导致Redis删除该key。
来源:
https://blog.csdn.net/minghao0508/article/details/123895525
(二十):Redis 性能优化与问题排查
前言
你们是否遇到过以下这些场景:
- 在 Redis 上执行同样的命令,为什么有时响应很快,有时却很慢?
- 为什么 Redis 执行 SET、DEL 命令耗时也很久?
- 为什么我的 Redis 突然慢了一波,之后又恢复正常了?
- 为什么我的 Redis 稳定运行了很久,突然从某个时间点开始变慢了?
Redis真的变慢了吗?
首先,在开始之前,你需要弄清楚Redis是否真的变慢了?
如果你发现你的业务服务 API 响应延迟变长,首先你需要先排查服务内部,究竟是哪个环节拖慢了整个服务。
比较高效的做法是,在服务内部集成链路追踪(打印日志的方式也可以),也就是在服务访问外部依赖的出入口,记录每次请求外部依赖的响应延时。
如果你发现确实是操作 Redis 的这条链路耗时变长了,那么此刻你需要把焦点关注在业务服务到 Redis 这条链路上。
Redis这条链路变慢的原因可能也有 2 个:
- 业务服务器到 Redis 服务器之间的网络存在问题,例如网络线路质量不佳,网络数据包在传输时存在延迟、丢包等情况;
- Redis 本身存在问题,需要进一步排查是什么原因导致 Redis 变慢。
第一种情况发生的概率比较小,如果有,找网络运维。我们这篇文章,重点关注的是第二种情况。
什么是基准性能?
排除网络原因,如何确认你的 Redis 是否真的变慢了?首先,你需要对 Redis 进行基准性能测试,了解你的 Redis 在生产环境服务器上的基准性能。基准性能就是指 Redis 在一台负载正常的机器上,其最大的响应延迟和平均响应延迟分别是怎样的?
方式一:redis-cli --intrinsic-latency
方式二:redis-benchmark
使用复杂度过高的命令
你需要去查看一下 Redis 的慢日志slowlog(又不会!)。Redis 提供了慢日志命令的统计功能,它记录了有哪些命令在执行时耗时比较久。
redis.config文件:
- 慢日志的阈值:CONFIG SET slowlog-log-slower-than 5000
- 只保留最近 500 条慢日志 : CONFIG SET slowlog-max-len 500
127.0.0.1:6379> SLOWLOG get 5
1) 1) (integer) 32693 # 慢日志ID
2) (integer) 1593763337 # 执行时间戳
3) (integer) 5299 # 执行耗时(微秒)
4) 1) "LRANGE" # 具体执行的命令和参数
2) "user_list:2000"
3) "0"
4) "-1"
通过查看慢日志,我们就可以知道在什么时间点,执行了哪些命令比较耗时。
- 经常使用 O(N) 以上复杂度的命令,例如 keys、flushdb类命令。
- 使用O(N) 复杂度的命令,但 N 的值非常大。如:hgetall、lrange、smembers、zrange等并非不能使用,但是需要明确N的值。
第一种情况导致变慢的原因在于,Redis 在操作内存数据时,时间复杂度过高 ,要花费更多的 CPU 资源。
第二种情况导致变慢的原因在于,Redis 一次需要返回给客户端的数据过多 ,更多时间 花费在数据协议的组装和网络传输过程 中。
另外,如果你的应用程序操作 Redis 的QPS不是很大,但 Redis 实例的 CPU 使用率却很高,那么很有可能是使用了复杂度过高的命令导致的。Redis 是单线程处理客户端请求的,如果你经常使用以上命令,那么当Redis处理客户端请求时,一旦前面某个命令发生耗时,就会导致后面的请求发生排队,对于客户端来说,响应延迟也会变长。
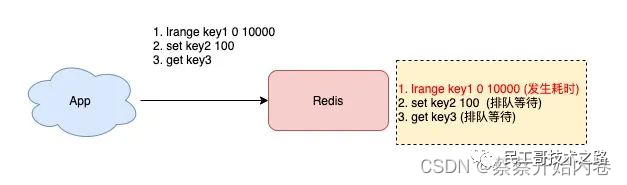
操作 bigkey
你查询慢日志发现,并不是复杂度过高的命令导致的,而都是 SET / DEL 这种简单命令出现在慢日志中,那么你就要怀疑你的实例否写入了bigkey。
Redis 在写入数据时,需要为新的数据分配内存,相对应的,当从 Redis 中删除数据时,它会释放对应的内存空间。如果一个 key 写入的 value 非常大,那么 Redis 在分配内存时就会比较耗时。同样的,当删除这个 key 时,释放内存也会比较耗时,这种类型的 key 我们一般称之为 bigkey。
如何扫描出实例中 bigkey 的分布情况呢?
第一种:Redis 提供了扫描 bigkey 的命令,执行以下命令就可以扫描出,一个实例中 bigkey的分布情况:
$ redis-cli -h 127.0.0.1 -p 6379 --bigkeys -i 0.01
...
-------- summary -------
Sampled 829675 keys in the keyspace!
Total key length in bytes is 10059825 (avg len 12.13)
Biggest string found 'key:291880' has 10 bytes
Biggest list found 'mylist:004' has 40 items
Biggest set found 'myset:2386' has 38 members
Biggest hash found 'myhash:3574' has 37 fields
Biggest zset found 'myzset:2704' has 42 members
36313 strings with 363130 bytes (04.38% of keys, avg size 10.00)
787393 lists with 896540 items (94.90% of keys, avg size 1.14)
1994 sets with 40052 members (00.24% of keys, avg size 20.09)
1990 hashs with 39632 fields (00.24% of keys, avg size 19.92)
1985 zsets with 39750 members (00.24% of keys, avg size 20.03)
每种 ** 数据类型(5个基础类型,不是全部数据) ** 所占用的最大内存 / 拥有最多元素的 key 是哪一个,以及每种数据类型在整个实例中的占比和平均大小 / 元素数量。使用这个命令的原理,就是 Redis 在内部执行了 SCAN 命令,遍历整个实例中所有的 key,然后针对 key 的类型,分别执行 STRLEN、LLEN、HLEN、SCARD、ZCARD 命令,来获取 String 类型的长度、容器类型(List、Hash、Set、ZSet)的元素个数。
当执行这个命令时,要注意 2 个问题:
-
对线上实例进行 bigkey 扫描时,Redis 的 OPS ( 每秒操作次数)会突增,为了降低扫描过程中对 Redis 的影响,最好控制一下扫描的频率,指定-i参数即可,它表示扫描过程中每次扫描后休息的时间间隔,单位是秒。
-
扫描结果中,对于容器类型(List、Hash、Set、ZSet)的 key,只能扫描出元素最多的 key。但一个 key 的元素多,不一定表示占用内存也多,你还需要根据业务情况,进一步评估内存占用情况。
第二种:rdb_bigkeys工具,go写的一款工具,分析rdb文件,找出文件中的大key,直接导出到csv文件,方便查看,个人推荐使用该工具去查找大key。
工具地址:https://github.com/weiyanwei412/rdb_bigkeys
针对 bigkey 导致延迟的问题,有什么好的解决方案呢?
- 拒绝bigkey(十分推荐)
- 导致redis阻塞
- 网络拥塞
- 过期删除:设置了过期时间,当它过期后,会被删除,如果没有使用Redis 4.0的过期异步删除(lazyfree-lazy-expire yes),就会存在阻塞Redis的可能性。
- Redis 是 4.0 以上版本,用 UNLINK 命令替代 DEL,此命令可以把释放 key 内存的操作,放到后台线程中去执行,从而降低对 Redis 的影响;
- Redis 是 4.0 以上版本,可以开启 lazy-free 机制(lazyfree-lazy-user-del = yes),在执行 DEL 命令时,释放内存也会放到后台线程中执行。
bigkey 在很多场景下,依旧会产生性能问题。例如,bigkey 在分片集群模式下,对于 数据的迁移 也会有性能影响, 数据过期、数据淘汰、透明大页 ,都会受到bigkey的影响。
集中过期
如果你发现,平时在操作 Redis 时,并没有延迟很大的情况发生,但在某个时间点突然出现一波延时,其现象表现为:变慢的时间点很有规律,每间隔多久就会发生一波延迟。如果是出现这种情况,那么你需要排查一下,业务代码中是否存在设置大量 key 集中过期的情况。如果有大量的key在某个固定时间点集中过期,在这个时间点访问 Redis 时,就有可能导致延时变大。
Redis对于过期键有三种清除策略:
-
被动删除:当读/写一个已经过期的key时,会触发惰性删除策略,直接删除掉这个过期key;
-
主动删除:由于惰性删除策略无法保证冷数据被及时删掉,所以Redis会定期主动淘汰一批已过期的key,Redis 内部维护了一个定时任务,默认每隔 100 毫秒就会从全局的过期哈希表中随机取出 20 个 key,然后删除其中过期的 key,如果过期 key 的比例超过了 25%,则继续重复此过程,直到过期 key 的比例下降到 25% 以下,或者这次任务的执行耗时超过了 25 毫秒,才会退出循环。这个主动过期 key 的定时任务,是在 Redis 主线程中执行的。
当前已用内存超过maxmemory限定时,触发内存淘汰策略。
也就是说如果在执行主动过期的过程中,出现了需要大量删除过期 key 的情况,那么此时应用程序在访问Redis时,必须要等待这个过期任务执行结束,Redis 才可以服务这个客户端请求。此时需要过期删除的是一个 bigkey,那么这个耗时会更久。而且,这个操作延迟的命令并不会记录在慢日志中。慢日志中没有操作耗时的命令,但我们的应用程序却感知到了延迟变大,其实时间都花费在了删除过期 key 上,这种情况我们需要尤为注意。
解决方法
- 集中过期 key 增加一个随机过期时间,把集中过期的时间打散,降低 Redis 清理过期key的压力;
- Redis 是 4.0 以上版本,可以开启lazy-free机制,当删除过期 key 时,把释放内存的操作放到后台线程中执行,避免阻塞主线程。
实例内存达到上限
原因在于,当 Redis 内存达到 maxmemory 后,每次写入新的数据之前,Redis 必须先从实例中踢出一部分数据,让整个实例的内存维持在 maxmemory 之下,然后才能把新数据写进来。
- allkeys-lru:不管 key 是否设置了过期,淘汰最近最少访问的 key
- volatile-lru:只淘汰最近最少访问、并设置了过期时间的 key
- allkeys-random:不管 key 是否设置了过期,随机淘汰 key
- volatile-random:只随机淘汰设置了过期时间的 key
- allkeys-ttl:不管 key 是否设置了过期,淘汰即将过期的 key
- noeviction:不淘汰任何 key,实例内存达到 maxmeory 后,再写入新数据直接返回错
- allkeys-lfu:不管 - key 是否设置了过期,淘汰访问频率最低的 key(4.0+版本支持)
- volatile-lfu:只淘汰访问频率最低、并设置了过期时间 key(4.0+版本支持)
Redis 的淘汰数据的逻辑与删除过期 key 的一样,也是在命令真正执行之前执行的,也就是说它也会增加我们操作 Redis 的延迟,而且,写 OPS 越高,延迟也会越明显。Redis 实例中还存储了 bigkey,那么在淘汰删除 bigkey 释放内存时,也会耗时比较久。
优化建议:
- 避免存储 bigkey,降低释放内存的耗时;
- 淘汰策略改为随机淘汰,随机淘汰比 LRU 要快很多(视业务情况调整);
- 拆分实例,把淘汰key的压力分摊到多个实例上;
- 如果使用的是 Redis 4.0 以上版本,开启 layz-free 机制,把淘汰 key 释放内存的操作放到后台线程中执行(配置 lazyfree-lazy-eviction = yes);
持久化/同步影响
fork耗时严重
操作 Redis 延迟变大,都发生在 Redis 后台 RDB 和AOF rewrite 期间,那你就需要排查,在这期间有可能导致变慢的情况。当 Redis 开启了后台 RDB 和 AOF rewrite 后,在执行时,它们都需要主进程创建出一个子进程进行数据的持久化。主进程创建子进程,会调用操作系统提供的fork函数。而 fork 在执行过程中,主进程需要拷贝自己的内存页表给子进程,如果这个实例很大,那么这个拷贝的过程也会比较耗时。而且这个 fork 过程会消耗大量的CPU资源,在完成fork之前,整个 Redis 实例会被阻塞住,无法处理任何客户端请求。如果此时你的 CPU 资源本来就很紧张,那么 fork 的耗时会更长,甚至达到秒级,这会严重影响 Redis 的性能。
你可以在 Redis 上执行 INFO 命令,查看 latest_fork_usec 项,单位微秒。
数据持久化会生成 RDB 之外,当主从节点第一次建立数据同步时,主节点也创建子进程生成 RDB,然后发给从节点进行一次全量同步,所以,这个过程也会对 Redis 产生性能影响。
优化
- 控制 Redis 实例的内存:尽量在 10G 以下,执行 fork 的耗时与实例大小有关,实例越大,耗时越久
- 合理配置数据持久化策略:在 slave 节点执行 RDB 备份,推荐在低峰期执行,而对于丢失数据不敏感的业务(例如把 Redis 当做纯缓存使用),可以关闭 AOF 和 AOF rewrite。
- Redis 实例不要部署在虚拟机上:fork 的耗时也与系统也有关,虚拟机比物理机耗时更久。
- 降低主从库全量同步的概率:适当调大· repl-backlog-size· 参数,避免主从全量同步。
开启内存大页
什么是内存大页?
我们都知道,应用程序向操作系统申请内存时,是按内存页进行申请的,而常规的内存页大小是 4KB 。
Linux 内核从2.6.38开始 ,支持了 内存大页 机制,该机制允许应用程序以 2MB 大小为单位,向操作系统申请内存。应用程序每次向操作系统申请的内存单位变大了,但这也意味着申请内存的耗时变长。主进程fork子进程后,此时的主进程依旧是可以接收写请求的,而进来的写请求,会采用 Copy On Write(写时复制)的方式操作内存数据。 主进程一旦有数据需要修改,Redis 并不会直接修改现有内存中的数据,而是先将这块内存数据拷贝出来,再修改这块新内存的数据。 写时复制你也可以理解成,谁需要发生写操作,谁就需要先拷贝,再修改。
注意,主进程在拷贝内存数据时,这个阶段就涉及到新内存的申请,如果此时操作系统开启了内存大页,那么在此期间,客户端即便只修改 10B 的数据,Redis 在申请内存时也会以 2MB 为单位向操作系统申请,申请内存的耗时变长,进而导致每个写请求的延迟增加,影响到 Redis 性能。如果这个写请求操作的是一个 bigkey,那主进程在拷贝这个 bigkey 内存块时,一次申请的内存会更大,时间也会更久。可见,bigkey 在这里又一次影响到了性能。
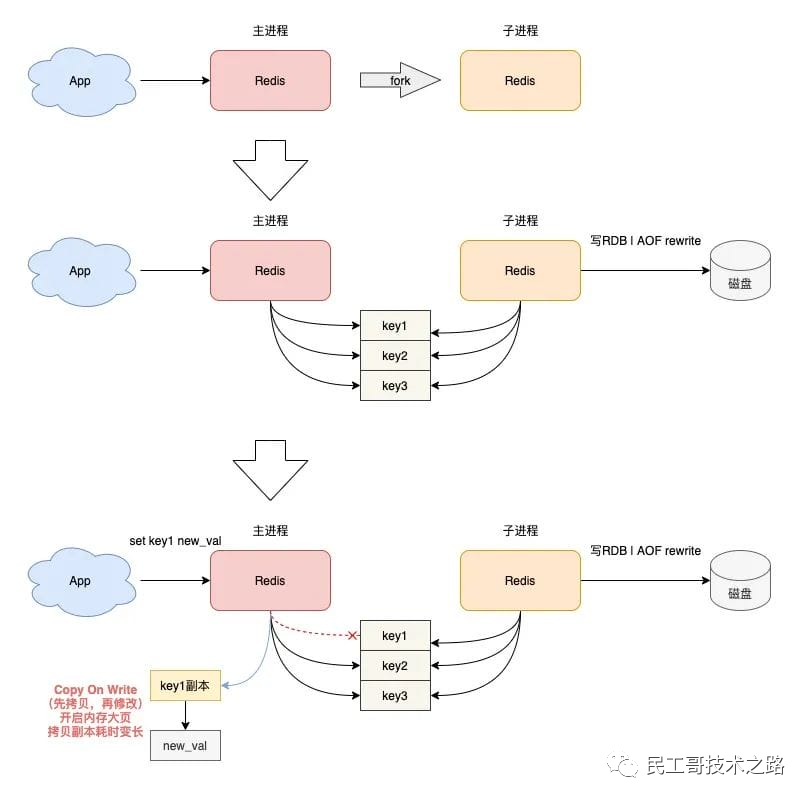
开启AOF
-
AOF 配置为 appendfsync always,那么 Redis 每处理一次写操作,都会把这个命令写入到磁盘中才返回,整个过程都是在主线程执行的,这个过程必然会加重Redis写负担。
-
AOF 配置为appendfsync no,Redis 每次写操作只写内存,什么时候把内存中的数据刷到磁盘,交给操作系统决定,对 Redis 的性能影响最小,但当 Redis 宕机时,会丢失一部分数据,为了数据的安全性。
-
AOF 配置为appendfsync everysec ,当 Redis 后台线程在执行 AOF 文件刷盘时,如果此时磁盘的IO负载很高,那这个后台线程在执行刷盘操作(fsync系统调用)时就会被阻塞住。此时的主线程依旧会接收写请求,紧接着,主线程又需要把数据写到文件内存中(write 系统调用),但此时的后台子线程由于磁盘负载过高,导致 fsync 发生阻塞,迟迟不能返回,那主线程在执行 write 系统调用时,也会被阻塞住,直到后台线程fsync执行完成后,主线程执行 write 才能成功返回。
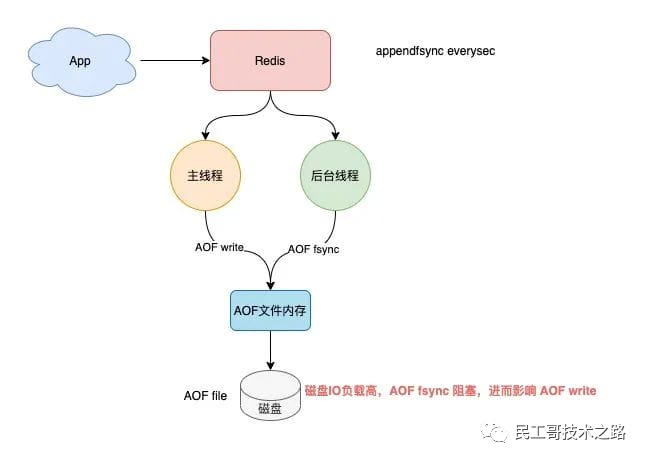
我总结了以下几种情况,你可以参考进行 问题排查 :
- 子进程正在执行 AOF rewrite,这个过程会占用大量的磁盘 IO 资源;
- 有其他应用程序在执行大量的写文件操作,也会占用磁盘 IO 资源;
Redis 的 AOF 后台子线程刷盘操作,撞上了子进程 AOF rewrite!Redis 提供了一个配置项,当子进程在 AOF rewrite 期间,可以让后台子线程不执行刷盘(不触发 fsync 系统调用)操作。
这相当于在 AOF rewrite期间,临时把 appendfsync 设置为了 none,配置如下:
# AOF rewrite 期间,AOF 后台子线程不进行刷盘操作
# 相当于在这期间,临时把 appendfsync 设置为了 none
no-appendfsync-on-rewrite yes
开启这个配置项,在 AOF rewrite 期间,如果实例发生宕机,那么此时会丢失更多的数据,性能和数据安全性,你需要权衡后进行选择。
碎片整理
Redis 的数据都存储在内存中,当我们的应用程序频繁修改Redis中的数据时,就有可能会导致 Redis产生内存碎片。内存碎片会降低 Redis 的内存使用率,我们可以通过执行INFO命令,得到这个实例的内存碎片率:

used_memory 表示 Redis 存储数据的内存大小,
used_memory_rss 表示操作系统实际分配给 Redis 进程的大小。
mem_fragmentation_ratio> 1.5,说明内存碎片率已经超过了 50%,这时我们就需要采取一些措施来降低内存碎片了。
解决的方案一般如下:
- 如果你使用的是 Redis 4.0 以下版本,只能通过重启实例来解决
- 如果你使用的是 Redis 4.0 版本,它正好提供了自动碎片整理的功能,可以通过配置开启碎片自动整理但是,开启内存碎片整理,它也有可能会导致Redis性能下降。
原因在于,Redis 的碎片整理工作是也在主线程中执行的,当其进行碎片整理时,必然会消耗CPU资源,产生更多的耗时,从而影响到客户端的请求。
其他原因
- 频繁短连接:你的业务应用,应该使用长连接操作 Redis,避免频繁的短连接。
- 其它程序争抢资源:其它程序占用 CPU、内存、磁盘资源,导致分配给 Redis 的资源不足而受到影响。
总结
你应该也发现了,Redis 的性能问题,涉及到的知识点非常广,几乎涵盖了 CPU、内存、网络、甚至磁盘的方方面面,同时,你还需要了解计算机的体系结构,以及操作系统的各种机制。
从 资源使用 角度来看,包含的知识点如下:
- CPU相关:使用复杂度过高命令、数据的持久化,都与耗费过多的 CPU 资源有关
- 内存相关:bigkey 内存的申请和释放、数据过期、数据淘汰、碎片整理、内存大页、内存写时复制都与内存息息相关
- 磁盘相关:数据持久化、AOF 刷盘策略,也会受到磁盘的影响
- 网络相关:短连接、实例流量过载、网络流量过载,也会降低 Redis 性能
- 计算机系统:CPU 结构、内存分配,都属于最基础的计算机系统知识
- 操作系统:写时复制、内存大页、Swap、CPU 绑定,都属于操作系统层面的知识
优化的一些建议
1、尽量使用短的key
当然在精简的同时,不要为了key的“见名知意”。对于value有些也可精简,比如性别使用0、1。
2、避免使用keys *
keys *, 这个命令是阻塞的,即操作执行期间,其它任何命令在你的实例中都无法执行。当redis中key数据量小时到无所谓,数据量大就很糟糕了。所以我们应该避免去使用这个命令。可以去使用SCAN,来代替。
3、在存到Redis之前先把你的数据压缩下
redis为每种数据类型都提供了两种内部编码方式,在不同的情况下redis会自动调整合适的编码方式。
4、设置key有效期
我们应该尽可能的利用key有效期。比如一些临时数据(短信校验码),过了有效期Redis就会自动为你清除!
5、选择回收策略(maxmemory-policy)
当Redis的实例空间被填满了之后,将会尝试回收一部分key。根据你的使用方式,强烈建议使用 volatile-lru(默认) 策略——前提是你对key已经设置了超时。但如果你运行的是一些类似于 cache 的东西,并且没有对 key 设置超时机制,可以考虑使用 allkeys-lru 回收机制,具体讲解查看 。maxmemory-samples 3 是说每次进行淘汰的时候 会随机抽取3个key 从里面淘汰最不经常使用的(默认选项)。
maxmemory-policy 六种方式 :
volatile-lru #只对设置了过期时间的key进行LRU(默认值)
allkeys-lru #是从所有key里 删除 不经常使用的key
volatile-random #随机删除即将过期key
allkeys-random #随机删除
volatile-ttl #删除即将过期的
noeviction #永不过期,返回错误
6、使用bit位级别操作和byte字节级别操作来减少不必要的内存使用
bit位级别操作:GETRANGE, SETRANGE, GETBIT and SETBIT
byte字节级别操作:GETRANGE and SETRANGE
7、尽可能地使用hashes哈希存储
8、当业务场景不需要数据持久化时,关闭所有的持久化方式可以获得最佳的性能
数据持久化时需要在持久化和延迟/性能之间做相应的权衡.
9、想要一次添加多条数据的时候可以使用管道
10、限制redis的内存大小(64位系统不限制内存,32位系统默认最多使用3GB内存)
数据量不可预估,并且内存也有限的话,尽量限制下redis使用的内存大小,这样可以避免redis使用swap分区或者出现OOM错误。(使用swap分区,性能较低,如果限制了内存,当到达指定内存之后就不能添加数据了,否则会报OOM错误。可以设置maxmemory-policy,内存不足时删除数据)
11、SLOWLOG [get/reset/len]
slowlog-log-slower-than #它决定要对执行时间大于多少微秒(microsecond,1秒 = 1,000,000 微秒)的命令进行记录。
slowlog-max-len #它决定 slowlog 最多能保存多少条日志,当发现redis性能下降的时候可以查看下是哪些命令导致的。
来源:
https://blog.csdn.net/weixin_42128977/article/details/127622146
(二十一):Redis 性能测试及相关工具使用
为什么需要性能测试?
性能测试可以让我们了解 Redis 服务器的性能优劣。在实际的业务场景中,性能测试是必不可少的。在业务系统上线之前,我们都需要清楚地了解 Redis 服务器的性能,从而避免发生某些意外情况,比如数据量过大会导致服务器宕机等。
本文将介绍几种不同的方式对Redis的性能进行相关的测试,大家可以根据自己的实际使用需求来选择不同的工具。
redis-benchmark 介绍
为了解 Redis 在不同配置环境下的性能表现,Redis 提供了一种性能测试工具 redis-benchmark(也称压力测试工具),它通过同时执行多组命令实现对 Redis 的性能测试。
语法格式
redis-benchmark [option] [option value]
option #可选参数。
option value #具体的参数值。
注意:该命令是在 redis 的目录下执行的,而不是 redis 客户端的内部指令。
参数说明
Usage: redis-benchmark [-h ] [-p ] [-c ] [-n ] [-k ]
-h #设置redis服务端 IP (default 127.0.0.1)
-p #设置redis服务端 端口 (default 6379)
-a #设置redis服务端 密码
-c #设置多少个redis客户端并发连接redis服务端 (default 50)
-d #设置每次SET/GET值的数据大小,默认3字节 “VXK” (default 3)
-n #设置请求总数,若默认50个客户端,每个客户端只需要请求2000次 (default 100000)
-q #只显示每种类型测试 读/写 的秒数(不会输出大片测试过程)
-l #闭环模式,测试完后,循环上一次测试,(就是命令永远循环)
-r #设置指定数量的键;对SET/GET/INCR使用随机键,对SADD使用随机值,ZADD的随机成员和分数。
# 注:-r会被应用到key和counter键,并且拼接12位后缀标识为多少个;如 “key:000000000008” 代表生成的第八个键
-P #选项代表每个请求pipeline的数据量. Default 1 (no pipeline).
-t #设置选择性的测试操作,它只会对我们指定的命令测试 如 -t SET,SPOP,LPUSH (低版本只能测试17个命令) 注:看下面的性能测试方式,选择其中指定方式测试
-I #空闲模式。只需打开N个空闲连接并等待
-s #Server socket (覆盖主机和端口)
-k #1=保持活动状态 0=重新连接 (default 1)
# 注:默认测试是一旦第一次连接,后面就不会断开,直到测试完成,
# 注:若是 1 则代表每次请求完成则断开连接,下次请求再重新连接
#
–csv #以CSV格式输出,方便我们统计Excel等处理
–user #用于发送ACL样式的“验证用户名密码”。需要 -a。
–dbnum #选择指定的数据库号进行测试,redis默认数据库为(0~16) (default 0)
–threads #启动多线程模式来测试
–cluster #启用集群模式来测试
–enable-tracking #启动测试之前发送客户端跟踪
–help #帮助文档
–version #显示版本号
测试案例
①:连接redis服务器并测试以50个客户端并发(平分每个客户端2000次)访问100000次
./redis-benchmark -h 127.0.0.1 -p 6379 -c 50 -n 100000
②:不输出测试过程,只显示当前测试案例结束的时间
./redis-benchmark -h 127.0.0.1 -p 6379 -c 50 -n 100000 -q
④:综合上面,并设置每个请求的请求值的大小字节
./redis-benchmark -h 127.0.0.1 -p 6379 -c 50 -n 100000 -q -d 5
④:综合上面,并设置指定的测试案例
./redis-benchmark -h 127.0.0.1 -p 6379 -c 50 -n 100000 -q -d 5 -t SET,SADD,ZADD,GET
随机 set/get 100万条命令,1000 个并发
./redis-benchmark -a 123456 -h 192.168.61.129 -p 6379 -t set,get -r 1000000 -n 1000000 -c 1000
测试输出的格式说明:(以 SET 测试案例说明)
./redis-benchmark -h 127.0.0.1 -p 6379 -c 1000 -n 1000000 -t SET
====== SET ======
1000000 requests completed in 18.75 seconds
-- 1000000 请求用时 18.75 秒
1000 parallel clients
-- 每个客户端请求次数1000
3 bytes payload
-- 每次测试请求字节大小为 3byte
keep alive: 1
-- 保持活力模式 1 一直连接 (0则代表每次请求从新连接)
host configuration "save": 3600 1 300 100 60 10000
host configuration "appendonly": no
-- 上面两个主机配置 持久化方式关闭
multi-thread: no
-- 不是多线程测试
Latency by percentile distribution:
0.000% <= 6.159 milliseconds (cumulative count 1)
50.000% <= 13.191 milliseconds (cumulative count 500348)
75.000% <= 15.687 milliseconds (cumulative count 750168)
98.438% <= 26.799 milliseconds (cumulative count 984415)
100.000% <= 49.151 milliseconds (cumulative count 1000000)
100.000% <= 49.151 milliseconds (cumulative count 1000000)
Cumulative distribution of latencies:
0.000% <= 0.103 milliseconds (cumulative count 0)
1.234% <= 7.103 milliseconds (cumulative count 12338)
12.473% <= 9.103 milliseconds (cumulative count 124733)
49.156% <= 13.103 milliseconds (cumulative count 491559)
100.000% <= 48.127 milliseconds (cumulative count 999999)
100.000% <= 50.111 milliseconds (cumulative count 1000000)
Summary:
throughput summary: 53339.02 requests per second
-- 吞吐量摘要:每秒53339.02个请求
latency summary (msec):
--延迟摘要(毫秒)
avg min p50 p95 p99 max
13.639 6.152 13.191 21.663 28.351 49.151
memtier_benchmark 的使用
memtier_benchmark是Redis Labs推出的一款命令行工具。它可以根据需求生成多种结构的数据对数据库进行压力测试,以了解目标数据库的性能极限。其部分功能特性如下。
- 支持Redis和Memcached数据库测试。
- 支持多线程、多客户端测试。
- 可设置测试中的读写比例(SET: GET Ratio)。
- 可自定义测试中键的结构。
- 支持设置随机过期时间。
使用教程如下
安装依赖
memtier_benchmark的安装依赖以下依赖包:Git、libevent 2.0.10或更高版本、libpcre 8.x、autoconf、automake、GNU make、GCC C++ compiler。
yum install git
yum install autoconf automake make gcc-c++
yum install pcre-devel zlib-devel libmemcached-devel
# 如您系统中的libevent库不符合要求,下载并安装libevent-2.0.21
wget https://github.com/downloads/libevent/libevent/libevent-2.0.21-stable.tar.gz
tar xfz libevent-2.0.21-stable.tar.gz
pushd libevent-2.0.21-stable
./configure
make
sudo make install
popd
# 设置PKG_CONFIG_PATH使configure能够发现前置步骤安装的库。
export PKG_CONFIG_PATH=/usr/local/lib/pkgconfig:${PKG_CONFIG_PATH}
下载并编译memtier_benchmark
git clone https://github.com/RedisLabs/memtier_benchmark.git
cd memtier_benchmark
autoreconf -ivf
./configure
make
make install
测试方法
使用示例:
./memtier_benchmark -s r-XXXX.redis.rds.aliyuncs.com -p 6379 -a XXX -c 20 -d 32 --threads=10
--ratio=1:1 --test-time=1800 --select-db=10
具体参数如下:
-s #Redis数据库的连接地址
-a #Redis数据库的密码
-c #测试中模拟连接的客户端数量
-d #测试使用的对象数据的大小
–threads #测试中使用的线程数
–ratio #测试命令的读写比率(SET:GET Ratio)
–test-time #测试时长(单位:秒)
–select-db #测试使用的DB数量
python脚本对redis进行测试
除了使用redis-benchmark和memtier_benchmark,我们也可以使用python脚本对Redis进行性能测试。
首先需要安装python版本的Redis:
pip install redis
接着就可以编码连接Redis,并且进行测试:
简单连接
import redis
# 创建Redis对象进行连接
# 参数:decode_responses是否解码返回值
r = redis.Redis(host = 'localhost', port = 6379, password = '123456', decode_responses = True)
# 终端下的命令在代码中都是函数
r.set('name', 'xiaoming')
print(r.get('name'))
连接池
多个redis对象使用同一个连接池进行连接,避免了多次连接、断开等操作的系统开销
import redis
# 创建连接池,减少了多次的连接、断开的开销
pool = redis.ConnectionPool(password = '123456', decode_responses = True)
# 创建Redis对象
r = redis.Redis(connection_pool = pool)
print(r.get('name'))
使用管道
管道可以记录多个操作,然后一次将操作发送至数据库,避免了多次向服务器发送少量的数据,多个操作可以依次进行保存,然后发送,也可以进行连贯操作。
import redis
# 创建连接池,减少了多次的连接、断开的开销
pool = redis.ConnectionPool(password = '123456', decode_responses = True)
# 创建Redis对象
r = redis.Redis(connection_pool = pool)
# 创建管道
pipe = r.pipeline()
# 保存记录操作
#pipe.set('name', 'dahua')
#pipe.set('age', 20)
# 执行操作(发送到服务器),一次可以执行多个操作,可以避免多次的想服武器发送数据
#pipe.execute()
# 也可以进行连贯操作
pipe.set('name', 'haha').set('age', 10).execute()
print(r.get('name'))
参考文章:
https://cnblogs.com/uestc2007/p/16962523.html
https://blog.csdn.net/MOU_IT/article/details/121522395
(二十二):Redis 运维监控(指标、体系建设、工具使用)
如何理解Redis监控呢
Redis运维和监控的意义不言而喻,我认为主要从如下三方面去构建认知体系:
- 首先是Redis自身提供了哪些状态信息,以及有哪些常见的命令可以获取Redis的监控信息;
- 其次需要知道一些常见的UI工具可以可视化的监控Redis;
- 最后需要理解Redis的监控体系;
Redis用的好不好,如何让它更好,这是运维要做的;本文主要在 Redis自身状态及命令,可视化监控工具,以及Redis监控体系等方面帮助你构建对redis运维/监控体系的认知,它是性能优化的前提。
Redis 自身状态及命令
如果只是想简单看一下Redis的负载情况的话,完全可以用它提供的一些命令来完成。
状态信息 - info
Redis提供的INFO命令不仅能够查看实时的吞吐量(ops/sec),还能看到一些有用的运行时信息。
info查看所有状态信息
[root@redis_test_vm ~]# redis-cli -h 127.0.0.1
127.0.0.1:6379> auth xxxxx
OK
127.0.0.1:6379> info
# Server
redis_version:3.2.3 #redis版本号
redis_git_sha1:00000000 #git sha1摘要值
redis_git_dirty:0 #git dirty标识
redis_build_id:443e50c39cbcdbe0 #redis构建id
redis_mode:standalone #运行模式:standalone、sentinel、cluster
os:Linux 3.10.0-514.16.1.el7.x86_64 x86_64 #服务器宿主机操作系统
arch_bits:64 服务器宿主机CUP架构(32位/64位)
multiplexing_api:epoll #redis IO机制
gcc_version:4.8.5 #编译 redis 时所使用的 GCC 版本
process_id:1508 #服务器进程的 PID
run_id:b4ac0f9086659ce54d87e41d4d2f947e19c28401 #redis 服务器的随机标识符 (用于 Sentinel 和集群)
tcp_port:6380 #redis服务监听端口
uptime_in_seconds:520162 #redis服务启动以来经过的秒数
uptime_in_days:6 #redis服务启动以来经过的天数
hz:10 #redis内部调度(进行关闭timeout的客户端,删除过期key等等)频率,程序规定serverCron每秒运行10次
lru_clock:16109450 #自增的时钟,用于LRU管理,该时钟100ms(hz=10,因此每1000ms/10=100ms执行一次定时任务)更新一次
executable:/usr/local/bin/redis-server
config_file:/data/redis-6380/redis.conf 配置文件的路径
# Clients
connected_clients:2 #已连接客户端的数量(不包括通过从属服务器连接的客户端)
client_longest_output_list:0 #当前连接的客户端当中,最长的输出列表
client_biggest_input_buf:0 #当前连接的客户端当中,最大输入缓存
blocked_clients:0 #正在等待阻塞命令(BLPOP、BRPOP、BRPOPLPUSH)的客户端的数量
# Memory
used_memory:426679232 #由 redis 分配器分配的内存总量,以字节(byte)为单位
used_memory_human:406.91M #以可读的格式返回 redis 分配的内存总量(实际是used_memory的格式化)
used_memory_rss:443179008 #从操作系统的角度,返回 redis 已分配的内存总量(俗称常驻集大小)。这个值和 top 、 ps等命令的输出一致
used_memory_rss_human:422.65M # redis 的内存消耗峰值(以字节为单位)
used_memory_peak:426708912
used_memory_peak_human:406.94M
total_system_memory:16658403328
total_system_memory_human:15.51G
used_memory_lua:37888 # Lua脚本存储占用的内存
used_memory_lua_human:37.00K
maxmemory:0
maxmemory_human:0B
maxmemory_policy:noeviction
mem_fragmentation_ratio:1.04 # used_memory_rss/ used_memory
mem_allocator:jemalloc-4.0.3
# Persistence
loading:0 #服务器是否正在载入持久化文件,0表示没有,1表示正在加载
rdb_changes_since_last_save:3164272 #离最近一次成功生成rdb文件,写入命令的个数,即有多少个写入命令没有持久化
rdb_bgsave_in_progress:0 #服务器是否正在创建rdb文件,0表示否
rdb_last_save_time:1559093160 #离最近一次成功创建rdb文件的时间戳。当前时间戳 - rdb_last_save_time=多少秒未成功生成rdb文件
rdb_last_bgsave_status:ok #最近一次rdb持久化是否成功
rdb_last_bgsave_time_sec:-1 #最近一次成功生成rdb文件耗时秒数
rdb_current_bgsave_time_sec:-1 #如果服务器正在创建rdb文件,那么这个域记录的就是当前的创建操作已经耗费的秒数
aof_enabled:0 #是否开启了aof
aof_rewrite_in_progress:0 #标识aof的rewrite操作是否在进行中
aof_rewrite_scheduled:0 #rewrite任务计划,当客户端发送bgrewriteaof指令,如果当前rewrite子进程正在执行,那么将客户端请求的bgrewriteaof变为计划任务,待aof子进程结束后执行rewrite
aof_last_rewrite_time_sec:-1 #最近一次aof rewrite耗费的时长
aof_current_rewrite_time_sec:-1 #如果rewrite操作正在进行,则记录所使用的时间,单位秒
aof_last_bgrewrite_status:ok #上次bgrewriteaof操作的状态
aof_last_write_status:ok #上次aof写入状态
# Stats
total_connections_received:10 #服务器已经接受的连接请求数量
total_commands_processed:9510792 #redis处理的命令数
instantaneous_ops_per_sec:1 #redis当前的qps,redis内部较实时的每秒执行的命令数
total_net_input_bytes:1104411373 #redis网络入口流量字节数
total_net_output_bytes:66358938 #redis网络出口流量字节数
instantaneous_input_kbps:0.04 #redis网络入口kps
instantaneous_output_kbps:3633.35 #redis网络出口kps
rejected_connections:0 #拒绝的连接个数,redis连接个数达到maxclients限制,拒绝新连接的个数
sync_full:0 #主从完全同步成功次数
sync_partial_ok:0 #主从部分同步成功次数
sync_partial_err:0 #主从部分同步失败次数
expired_keys:0 #运行以来过期的key的数量
evicted_keys:0 #运行以来剔除(超过了maxmemory后)的key的数量
keyspace_hits:87 #命中次数
keyspace_misses:17 #没命中次数
pubsub_channels:0 #当前使用中的频道数量
pubsub_patterns:0 #当前使用的模式的数量
latest_fork_usec:0 #最近一次fork操作阻塞redis进程的耗时数,单位微秒
migrate_cached_sockets:0 #是否已经缓存了到该地址的连接
# Replication
role:master #实例的角色,是master or slave
connected_slaves:0 #连接的slave实例个数
master_repl_offset:0 #主从同步偏移量,此值如果和上面的offset相同说明主从一致没延迟,与master_replid可被用来标识主实例复制流中的位置
repl_backlog_active:0 #复制积压缓冲区是否开启
repl_backlog_size:1048576 #复制积压缓冲大小
repl_backlog_first_byte_offset:0 #复制缓冲区里偏移量的大小
repl_backlog_histlen:0 #此值等于 master_repl_offset - repl_backlog_first_byte_offset,该值不会超过repl_backlog_size的大小
# CPU
used_cpu_sys:507.00 #将所有redis主进程在核心态所占用的CPU时求和累计起来
used_cpu_user:280.48 #将所有redis主进程在用户态所占用的CPU时求和累计起来
used_cpu_sys_children:0.00 #将后台进程在核心态所占用的CPU时求和累计起来
used_cpu_user_children:0.00 #将后台进程在用户态所占用的CPU时求和累计起来
# Cluster
cluster_enabled:0
# Keyspace
db0:keys=5557407,expires=362,avg_ttl=604780497
db15:keys=1,expires=0,avg_ttl=0
code here...
查看某个section的信息
127.0.0.1:6379> info memory
# Memory
used_memory:1067440
used_memory_human:1.02M
used_memory_rss:9945088
used_memory_rss_human:9.48M
used_memory_peak:1662736
used_memory_peak_human:1.59M
total_system_memory:10314981376
total_system_memory_human:9.61G
used_memory_lua:37888
used_memory_lua_human:37.00K
maxmemory:0
maxmemory_human:0B
maxmemory_policy:noeviction
mem_fragmentation_ratio:9.32
mem_allocator:jemalloc-4.0.3
监控执行命令 - monitor
monitor用来监视服务端收到的命令。
127.0.0.1:6379> monitor
OK
1616045629.853032 [10 192.168.0.101:37990] "PING"
1616045629.858214 [10 192.168.0.101:37990] "PING"
1616045632.193252 [10 192.168.0.101:37990] "EXISTS" "test_key_from_app"
1616045632.193607 [10 192.168.0.101:37990] "GET" "test_key_from_app"
1616045632.200572 [10 192.168.0.101:37990] "SET" "test_key_from_app" "1616045625017"
1616045632.200973 [10 192.168.0.101:37990] "SET" "test_key_from_app" "1616045622621"
监控延迟
监控延迟 - latency
[root@redis_test_vm ~]# redis-cli --latency -h 127.0.0.1
min: 0, max: 1, avg: 0.21
如果我们故意用DEBUG命令制造延迟,就能看到一些输出上的变化:
[root@redis_test_vm ~]# redis-cli -h 127.0.0.1
127.0.0.1:6379> debug sleep 2
OK
(2.00s)
127.0.0.1:6379> debug sleep 3
OK
(3.00s)
观测延迟
[root@redis_test_vm ~]# redis-cli --latency -h 127.0.0.1
min: 0, max: 1995, avg: 1.60 (492 samples)
客户端监控 - ping
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> ping
PONG
同时monitor
127.0.0.1:6379> monitor
OK
1616045629.853032 [10 192.168.0.101:37990] "PING"
1616045629.858214 [10 192.168.0.101:37990] "PING"
服务端 - 内部机制
服务端内部的延迟监控稍微麻烦一些,因为延迟记录的默认阈值是0。尽管空间和时间耗费很小,Redis为了高性能还是默认关闭了它。所以首先我们要开启它,设置一个合理的阈值,例如下面命令中设置的100ms:
127.0.0.1:6379> CONFIG SET latency-monitor-threshold 100
OK
因为Redis执行命令非常快,所以我们用DEBUG命令人为制造一些慢执行命令:
127.0.0.1:6379> debug sleep 2
OK
(2.00s)
127.0.0.1:6379> debug sleep .15
OK
127.0.0.1:6379> debug sleep .5
OK
下面就用LATENCY的各种子命令来查看延迟记录:
- LATEST:四列分别表示事件名、最近延迟的Unix时间戳、最近的延迟、最大延迟。
- HISTORY:延迟的时间序列。可用来产生图形化显示或报表。
- GRAPH:以图形化的方式显示。最下面以竖行显示的是指延迟在多久以前发生。
- RESET:清除延迟记录。
127.0.0.1:6379> latency latest
1) 1) "command"
1) (integer) 1616058778
2) (integer) 500
3) (integer) 2000
127.0.0.1:6379> latency history command
1) 1) (integer) 1616058773
2) (integer) 2000
2) 1) (integer) 1616058776
2) (integer) 150
3) 1) (integer) 1616058778
2) (integer) 500
127.0.0.1:6379> latency graph command
command - high 2000 ms, low 150 ms (all time high 2000 ms)
--------------------------------------------------------------------------------
#
|
|
|_#
666
mmm
在执行一条DEBUG命令会发现GRAPH图的变化,多出一条新的柱状线,下面的时间2s就是指延迟刚发生两秒钟:
127.0.0.1:6379> debug sleep 1.5
OK
(1.50s)
127.0.0.1:6379> latency graph command
command - high 2000 ms, low 150 ms (all time high 2000 ms)
--------------------------------------------------------------------------------
#
| #
| |
|_#|
2222
333s
mmm
还有一个子命令DOCTOR,它能列出一些指导建议,例如开启慢日志进一步追查问题原因,查看是否有大对象被踢出或过期,以及操作系统的配置建议等。
127.0.0.1:6379> latency doctor
Dave, I have observed latency spikes in this Redis instance. You don't mind talking about it, do you Dave?
1. command: 3 latency spikes (average 883ms, mean deviation 744ms, period 210.00 sec). Worst all time event 2000ms.
I have a few advices for you:
- Check your Slow Log to understand what are the commands you are running which are too slow to execute. Please check http://redis.io/commands/slowlog for more information.
- Deleting, expiring or evicting (because of maxmemory policy) large objects is a blocking operation. If you have very large objects that are often deleted, expired, or evicted, try to fragment those objects into multiple smaller objects.
- I detected a non zero amount of anonymous huge pages used by your process. This creates very serious latency events in different conditions, especially when Redis is persisting on disk. To disable THP support use the command 'echo never > /sys/kernel/mm/transparent_hugepage/enabled', make sure to also add it into /etc/rc.local so that the command will be executed again after a reboot. Note that even if you have already disabled THP, you still need to restart the Redis process to get rid of the huge pages already created.
如果你沒有配置 CONFIG SET latency-monitor-threshold ., 会返回如下信息。
127.0.0.1:6379> latency doctor
I'm sorry, Dave, I can't do that. Latency monitoring is disabled in this Redis instance. You may use "CONFIG SET latency-monitor-threshold <milliseconds>." in order to enable it. If we weren't in a deep space mission I'd suggest to take a look at http://redis.io/topics/latency-monitor.
度量延迟Baseline - intrinsic-latency
延迟中的一部分是来自环境的,比如操作系统内核、虚拟化环境等等。Redis提供了让我们度量这一部分延迟基线(Baseline)的方法:
[root@redis_test_vm ~]# redis-cli --intrinsic-latency 100 -h 127.0.0.1
Could not connect to Redis at 127.0.0.1:6379: Connection refused
Max latency so far: 1 microseconds.
Max latency so far: 62 microseconds.
Max latency so far: 69 microseconds.
Max latency so far: 72 microseconds.
Max latency so far: 102 microseconds.
Max latency so far: 438 microseconds.
Max latency so far: 5169 microseconds.
Max latency so far: 9923 microseconds.
1435096059 total runs (avg latency: 0.0697 microseconds / 69.68 nanoseconds per run).
Worst run took 142405x longer than the average latency.
intrinsic-latency后面是测试的时长(秒),一般100秒足够了。
Redis可视化监控工具
在谈Redis可视化监控工具时,要分清工具到底是仅仅指标的可视化,还是可以融入监控体系(比如包含可视化,监控,报警等; 这是生产环境长期监控生态的基础)。
- 只能可视化指标不能监控: redis-stat、RedisLive、redmon 等工具
- 用于生产环境: 基于redis_exporter以及grafana可以做到指标可视化,持久化,监控以及报警等
redis-stat
redis-stat【https://github.com/junegunn/redis-stat】是一个比较有名的redis指标可视化的监控工具,采用ruby开发,基于redis的info和monitor命令来统计,不影响redis性能。
它提供了命令行彩色控制台展示模式
和web模式

全篇传送门
篇幅过长截断了。。。
全篇传送门: 《从菜鸟到大师之路 Redis 篇》

















 1360
1360

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









