







public class Demo{
public static void main(String[] args) {
test();
}
public static void test( ) {
int a1 = 100;
int a2 = 200;
int a3 = 300;
int a4 = 400;
int a5 = 500;
int a6 = 600;
int a7 = 700;
int a8 = 800;
int a9 = 900;
int a10 = 1000;
int h1 = ( a1 + a2 ) * ( ( a3 + a4 ) - ( a5 + a6 / a7 ) ) - a8 + a9 / a10;
}
}
idea 安装 ASM bytecode outline 之后,右键上面的类,选择 Show Bytecode Outline ,会生成 java 字节码的可视化代码,如下图红框中是代码 “int h1 = ( a1 + a2 ) * ( ( a3 + a4 ) - ( a5 + a6 / a7 ) ) - a8 + a9 / a10” 对应的字节码指令:
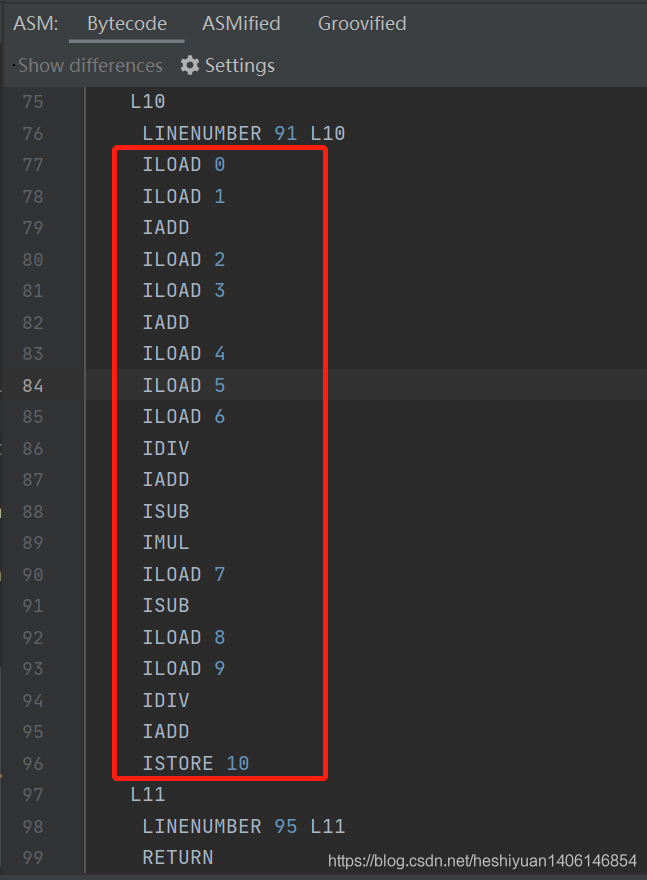
下面表格列出了代码 “int h1 = ( a1 + a2 ) * ( ( a3 + a4 ) - ( a5 + a6 / a7 ) ) - a8 + a9 / a10” 的字节码指令执行过程中操作数栈的出栈、入栈情况,ILOAD 是对 int 类型的数的压栈操作,“ILOAD x” 表示将第 x 个变量( int 类型 )压入栈顶,对栈深度的贡献为 +1,同理,加减乘除指令( IADD、ISUB、IMUL、IDIV )表示弹出栈顶的两个元素,然后将计算结果重新压入栈顶,对栈深度贡献为-1( 即 -2 + 1 )。
| 指令 | 对栈深度的贡献 | 执行完后的栈深度 | 此时栈状态 |
|---|---|---|---|
| ILOAD 0 | +1 | 1 | a1 |
| ILOAD 1 | +1 | 2 | a2 a1 |
| IADD | -1 | 1 | a1 + a2 |
| ILOAD 2 | +1 | 2 | a3 a1 + a2 |
| ILOAD 3 | +1 | 3 | a4 a3 a1 + a2 |
| IADD | -1 | 2 | a3 + a4 a1 + a2 |
| ILOAD 4 | +1 | 3 | a5 a3 + a4 a1 + a2 |
| ILOAD 5 | +1 | 4 | a6 a5 a3 + a4 a1 + a2 |
| ILOAD 6 | +1 | 5 | a7 a6 a5 a3 + a4 a1 + a2 |
| IDIV | -1 | 4 | a6 / a7 a5 a3 + a4 a1 + a2 |
| IADD | -1 | 3 | a5 + a6 / a7 a3 + a4 a1 + a2 |
| ISUB | -1 | 2 | ( a3 + a4 ) - ( a5 + a6 / a7 ) a1 + a2 |
| IMUL | -1 | 1 | ( a1 + a2 ) * ( ( a3 + a4 ) - ( a5 + a6 / a7 ) ) |
| ILOAD 7 | +1 | 2 | a8 ( a1 + a2 ) * ( ( a3 + a4 ) - ( a5 + a6 / a7 ) ) |
| ISUB | -1 | 1 | ( a1 + a2 ) * ( ( a3 + a4 ) - ( a5 + a6 / a7 ) ) - a8 |
| ILOAD 8 | +1 | 2 | a9 ( a1 + a2 ) * ( ( a3 + a4 ) - ( a5 + a6 / a7 ) ) - a8 |
| ILOAD 9 | +1 | 3 | a10 a9 ( a1 + a2 ) * ( ( a3 + a4 ) - ( a5 + a6 / a7 ) ) - a8 |
| IDIV | -1 | 2 | a9 / a10 ( a1 + a2 ) * ( ( a3 + a4 ) - ( a5 + a6 / a7 ) ) - a8 |
| IADD | -1 | 1 | ( a1 + a2 ) * ( ( a3 + a4 ) - ( a5 + a6 / a7 ) ) - a8 + a9 / a10 |
所以我认为 java 编译器在编译时可以按照上述步骤确定整个过程中操作数栈的最大深度,至少理论上是可行的。如果存在分支判断时,每个单独的叶子分支的栈深度都可以确定,结果就取最大的那个就行了,比如:
boolean flag=true;
if( flag ){
int h1 = ( a1 + a2 ) * ( ( a3 + a4 ) - ( a5 + a6 / a7 ) ) - a8 + a9 / a10;//maxStackSize=5
}else {
int h2 = ( a1 + ( a2 + ( a3 + ( a4 + ( a5 + ( a6 + ( a7 + ( a8 + ( a9 + a10 ) ) ) ) ) ) ) ) );//maxStackSize=5
}这段代码的最大操作数栈深度为10,但是注意:
if( true ){
int h1 = ( a1 + a2 ) * ( ( a3 + a4 ) - ( a5 + a6 / a7 ) ) - a8 + a9 / a10;//maxStackSize=5
}else {
int h2 = ( a1 + ( a2 + ( a3 + ( a4 + ( a5 + ( a6 + ( a7 + ( a8 + ( a9 + a10 ) ) ) ) ) ) ) ) );//maxStackSize=5
}这段代码的操作数栈最大深度是5,因为 true是常量,编译器检测到后直接把判断分支干掉了,相当于字节码里面只有 “int h1 = ( a1 + a2 ) * ( ( a3 + a4 ) - ( a5 + a6 / a7 ) ) - a8 + a9 / a10” 这段代码 了。
可能有人会说我举的例子是很简单的情况,是一个固定的算术公式,最大栈深度很好确定,但如果是动态的复杂的情况呢?比如 for 循环,因为循环的次数都是不确定的。貌似不太好确定最大栈深度吧?那我们就来分析一下吧!
public static void test( ) {
int sum=0;
for(int i =0;i<10;i++){
sum+=i;
}
}这段代码生成的字节码指令如下:
public static test()V
L0
LINENUMBER 13 L0
ICONST_0 ==> int sum = 0;
ISTORE 0
L1
LINENUMBER 14 L1
ICONST_0 ==> int i = 0;
ISTORE 1
L2
FRAME APPEND [I I]
ILOAD 1
BIPUSH 10 ==> if( i < 10 ) 不成立,跳转到 return 处,否则 按顺序执行到 L4 处
IF_ICMPGE L3
L4
LINENUMBER 15 L4
ILOAD 0
ILOAD 1 ==> sum += i;
IADD
ISTORE 0
L5
LINENUMBER 14 L5
IINC 1 1 ==> i++,然后跳转到 L2 处,继续执行 if( i < 10 ) 判断
GOTO L2
L3
LINENUMBER 17 L3
FRAME CHOP 1
RETURN
L6
LOCALVARIABLE i I L2 L3 1
LOCALVARIABLE sum I L1 L6 0
MAXSTACK = 2
MAXLOCALS = 2
}显然 for 循环其实相当于多次执行了 if 分支判断,即相当于多个 if 分支,满足上述多分支判断情况,可以确定最大栈深度!














 585
585











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









