






看了不少大佬写的文章,在这里简要总结一下HashMap底层的原理:
jdk1.8之前:HashMap通过数组+链表实现
jdk1.8开始:HashMap通过数组+链表+红黑树实现
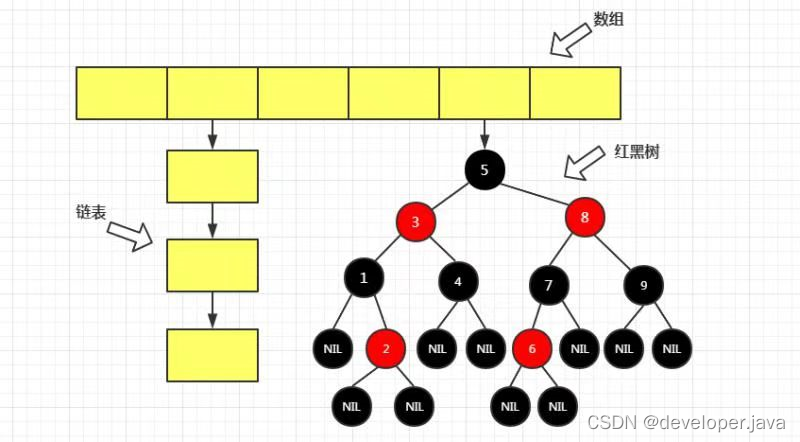
红黑树的特点
1、根节点和叶子节点为黑色
2、每个节点要么是红色,要么是黑色
3、从任意节点到其可达的叶子结点上的黑色节点数量相等
4、红色节点都是由黑色节点分隔开来的,不存在两个红色节点连在一起的情况
HashMap的定义中的几个重要的变量
1、初始容量:内部数组(哈希桶)的默认长度,默认为16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
2、哈希桶的最大容量:内部数组(哈希桶)的最大长度2^30
static final int MAXIMUM_CAPACITY = 1 << 30;
3、默认加载因子:数组长度达到总长度的0.75时自动扩容,第1次扩容为哈希桶长度为16*0.75=12时
static final float DEFAULT_LOAD_FACTOR = 0.75f;
4、哈希桶调整长度的阈值
int threshold;
HashMap不同参数的构造方法来实例化时,threshold的值:
- 指定初始容量:HashMap(int initialCapacity),此时threshold的值为不小于容量的2的次数
【例如:当我们指定了哈希桶初始容量时,比如31,这个时候threshold的值为32=2^5】
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
这时会调用HashMap(int initialCapacity, float loadFactor)
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
tableSizeFor(int cap)方法
// 找出最接近且不小于指定容量cap的2的次数
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
5、树化的最小数组长度:当哈希桶长度达到64,并且链表长度达到8时自动转为红黑树
static final int MIN_TREEIFY_CAPACITY = 64;
6、树化的阈值:当哈希桶的链表长度达到8时自动转为红黑树
static final int TREEIFY_THRESHOLD = 8;
7、红黑树退化为链表的阈值:当红黑树的节点减少到6时会自动转回链表
static final int UNTREEIFY_THRESHOLD = 6;
哈希表:结合数组和链表结构的特点,从而实现了查询和修改效率高,插入和删除效率也高的一种数据结构
什么是哈希算法?
哈希算法(也叫散列算法),就是把任意长度值(key)通过散列算法变换成固定长度的key(地址), 通过这个地址进行访问的数据结构,它通过把关键码值映射到表中一个位置来访问记录,以加快查找速度,哈希算法是不可逆的。
HashCode: 通过字符串算出它的ascii 码,进行mod(取模),算出哈希表中的下标 。取模的目的是节省内存空间。
map.put(k,v)实现原理
1、首先将k,v封装到Node对象当中(节点)。
2、然后它的底层会调用K的hashCode()方法得出hash值。
3、通过哈希表函数/哈希算法,将hash值转换成数组的下标,下标位置上如果没有任何元素,就把Node添加到这个位置上。如果说下标对应的位置上有链表。此时,就会拿着k和链表上每个节点的k进行equal。如果所有的equals方法返回都是false,那么这个新的节点将被添加到链表的末尾。如其中有一个equals返回了true,那么这个节点的value将会被覆盖。
map.get(k)实现原理
1、先调用k的hashCode()方法得出哈希值,并通过哈希算法转换成数组的下标。
2、通过上一步哈希算法转换成数组的下标之后,在通过数组下标快速定位到某个位置上。重点理解如果这个位置上什么都没有,则返回null。如果这个位置上有单向链表,那么它就会拿着参数K和单向链表上的每一个节点的K进行equals,如果所有equals方法都返回false,则get方法返回null。如果其中一个节点的K和参数K进行equals返回true,那么此时该节点的value就是我们要找的value了,get方法最终返回这个要找的value。
随机增删、查询效率都很高的原因是?
原因: 增删是在链表上完成的,而查询只需扫描部分,则效率高。
HashMap集合的key,会先后调用两个方法,hashCode()和equals()方法,这这两个方法都需要重写。
为什么放在hashMap集合key部分的元素需要重写equals方法?
因为equals()方法默认比较的是两个对象的内存地址















 643
643











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









