






基本概念
随机变量

大写字母:随机变量
小写字母:观测值
概率密度函数


基本性质:

期望:

随机抽样:
专业术语
state(状态)action(动作)agent(智能体)

policy(策略),强化学习学的就是policy函数

reward奖励

state transition状态转移
状态转移函数只有环境知道,玩家不知道

交互


随机性
动作的随机

状态转移的随机


rewards and return

折扣回报

Value Functions价值函数
动作价值函数

At+1等,St+1等被积分积掉了(求期望);st,at是被观测到的变量;π代表策略函数
Qπ可以反映当前状态st下,做动作at的好坏程度
 Qπ对策略函数求最大化得到Q*最优动作价值函数,可以用来对动作a做评价,可以指导当前做决策
Qπ对策略函数求最大化得到Q*最优动作价值函数,可以用来对动作a做评价,可以指导当前做决策
状态价值函数:

Vπ告诉我们当前状态好不好


动作是连续的就用积分,比如自动驾驶方向盘角度
总结价值函数

控制智能体的两种方式
强化学习的目标就是学到π函数或者Q*函数

用gym做实验
先安装gym,再在python里调用gym


实际上action不能像上图一样随机,应该用policy更新
总结


价值学习
思想:学习一个函数来近似Q*
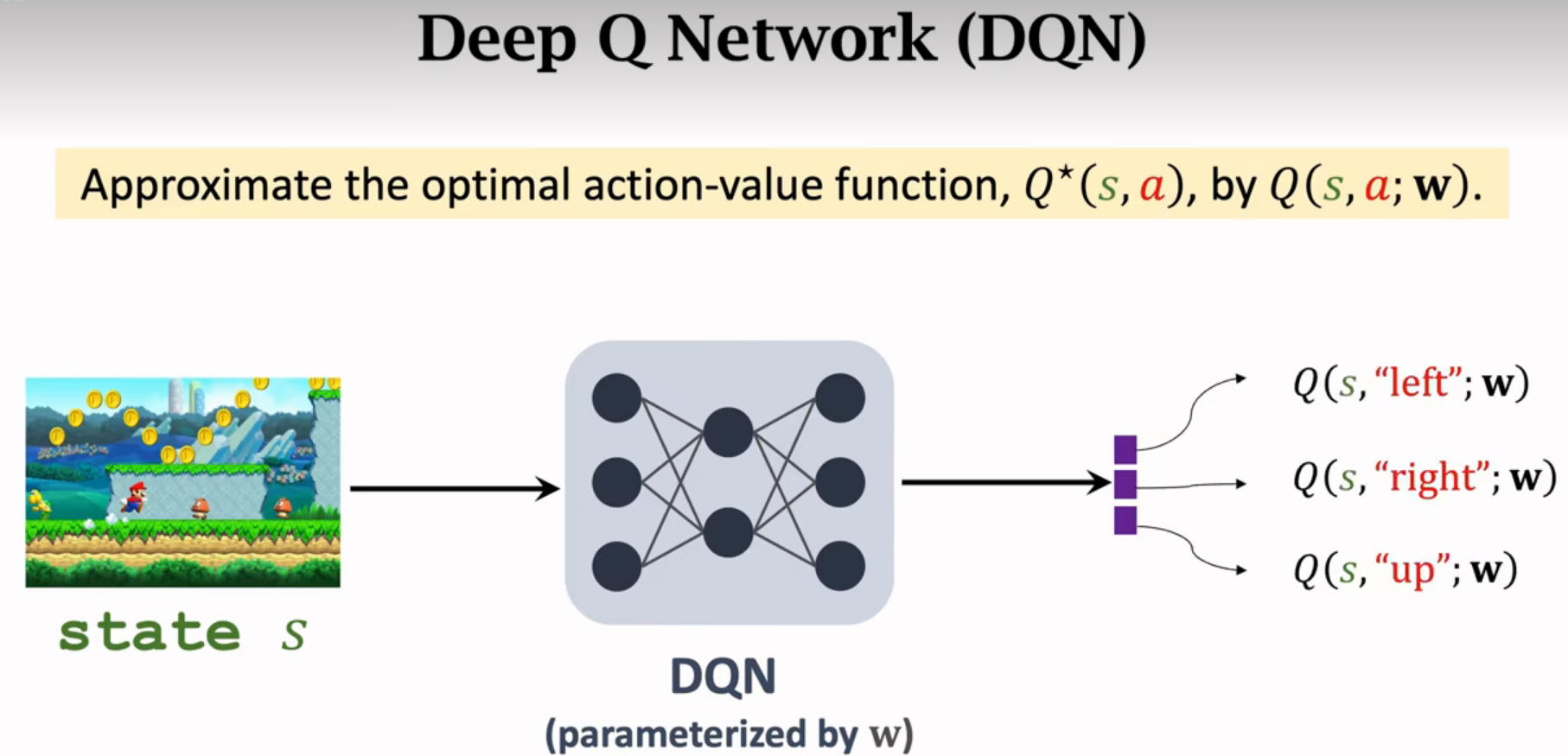
Deep Q-Network(DQN)
用神经网络近似Q*函数
Q*可以给每个动作打分


神经网络记为Q(s,a;w),神经网络的参数是w,输入是s,输出是很多数值(是对每个动作的打分)通过奖励来学这个神经网络,打分就会越来越准。


训练DQN
TD算法


α是学习率或者叫步长
用wt+1代替wt,那么预测值更接近真实值,因为梯度下降减小了loss。(个人理解:想象L与w正相关,那么L对w求导为正,wt减去一个正值,wt变小,由于w与L正相关关系所以L变小;L与w负相关的话,L对w求导为负,wt减去负值,wt增大,由于负相关关系L还是变小)


TD learning for DQN





总结

DQN的输入:s,输出:对每个动作的打分
一开始DQN的模型参数是随机的,强化学习就是通过奖励来更新模型参数,让模型越来越好

策略学习
策略函数 Policy Function


状态价值函数

给定策略函数π,Vπ可以评价当前状态好坏;给定状态s,Vπ可以评价策略π的好坏
策略学习

用神经网络来替代策略函数,θ是神经网络的参数

想让目标函数J(θ)越来越大,所以用梯度上升算法
近似计算策略梯度






蒙特卡洛近似:抽一个或者很多个随机样本,用随机样本来近似期望
更新策略梯度时,用g(,θ)来近似。

比如从:向上、向左、向右三个动作中抽样,抽到了向左,就用向左作为,计算g(
,θ)的函数值来近似策略梯度
总结策略梯度算法


(需要玩完游戏,记录所有s a r才能计算qt)
用神经网络近似Qπ

总结

Actor-Critic方法
actor是策略网络,用来控制agent运动,运动员
critic是价值网络,用来给动作打分,裁判

价值网络和策略网络

策略网络

价值网络

训练神经网络

学习策略网络是为了让V函数的值更大,也就是运动员得到更高的平均分。为了学习策略网络π,需要价值网络q来当裁判打分。
裁判靠环境给的奖励reward(看成上帝打分)来改进自己,裁判要让自己的打分接近上帝的打分。学习q是为了让打分更精准。







算法总结

第9的qt可以换成deta_t:

总结


终极目的:学策略网络

AlphaGo




蒙特卡洛
通过均匀抽样计算π

Buffon投针


求阴影面积


近似求积分





用蒙特卡洛近似期望


总结

随机排列Random Permutaion
均匀随机排列uniform random permutation




Fisher-Yates算法原始版本
生成随机数


假设有随机数生成器:





时间复杂度:

改进的Fisher-Yates算法








...依次进行直到抽完


c++编程实现


总结


TD算法
Sarsa算法
折扣回报






表格形式Sarsa算法




神经网络版Sarsa



总结

Q-learning
Q-learning与Sarsa对比


DQN是对最优动作Q*的近似
TD Target






表格形式Q-learning
找最大值:


DQN版本



Q-learning总结

Multi-Step TD Target

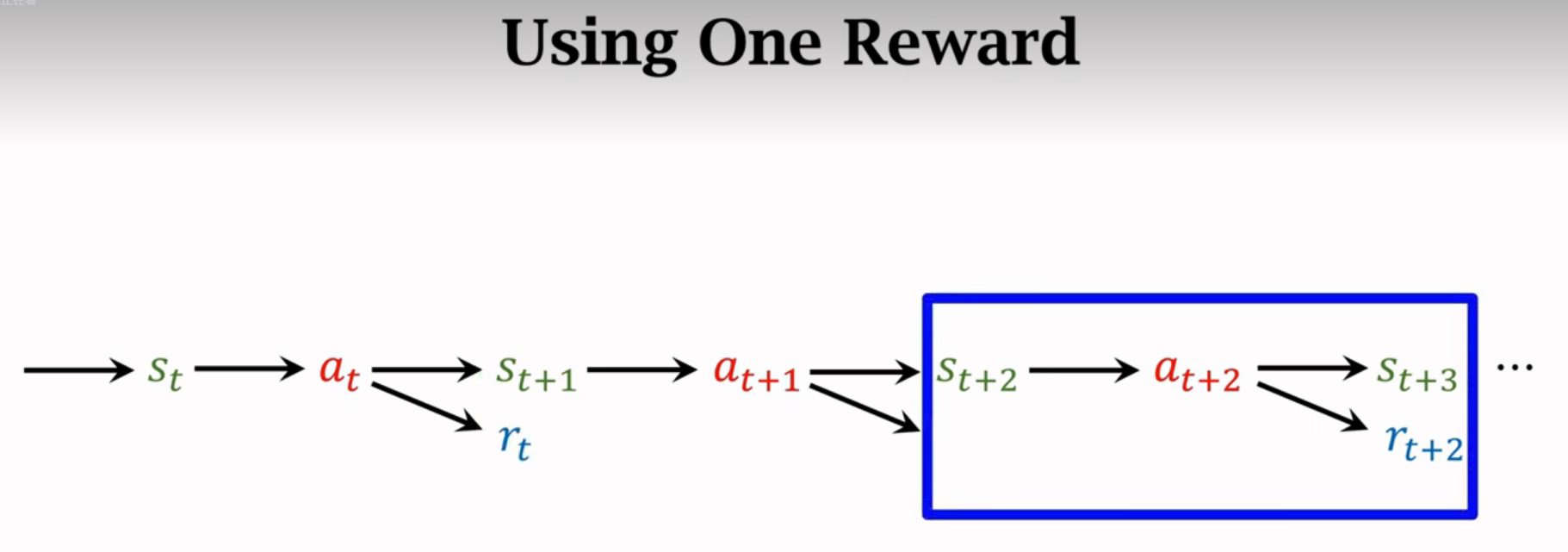
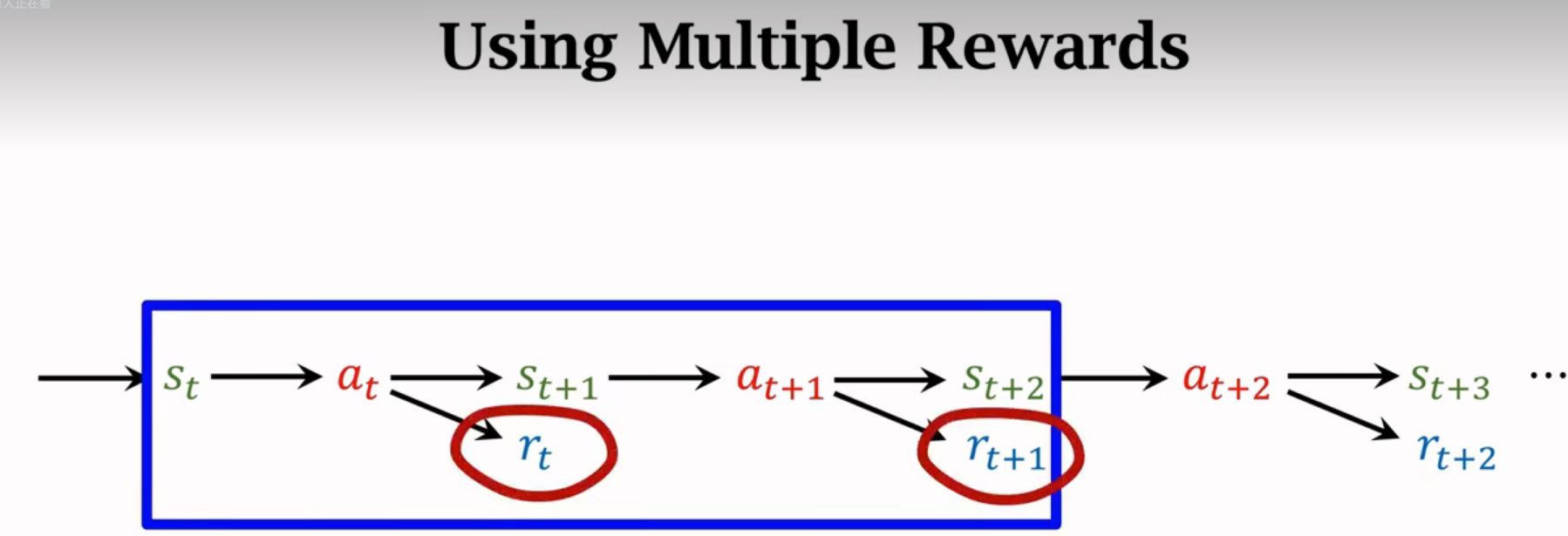



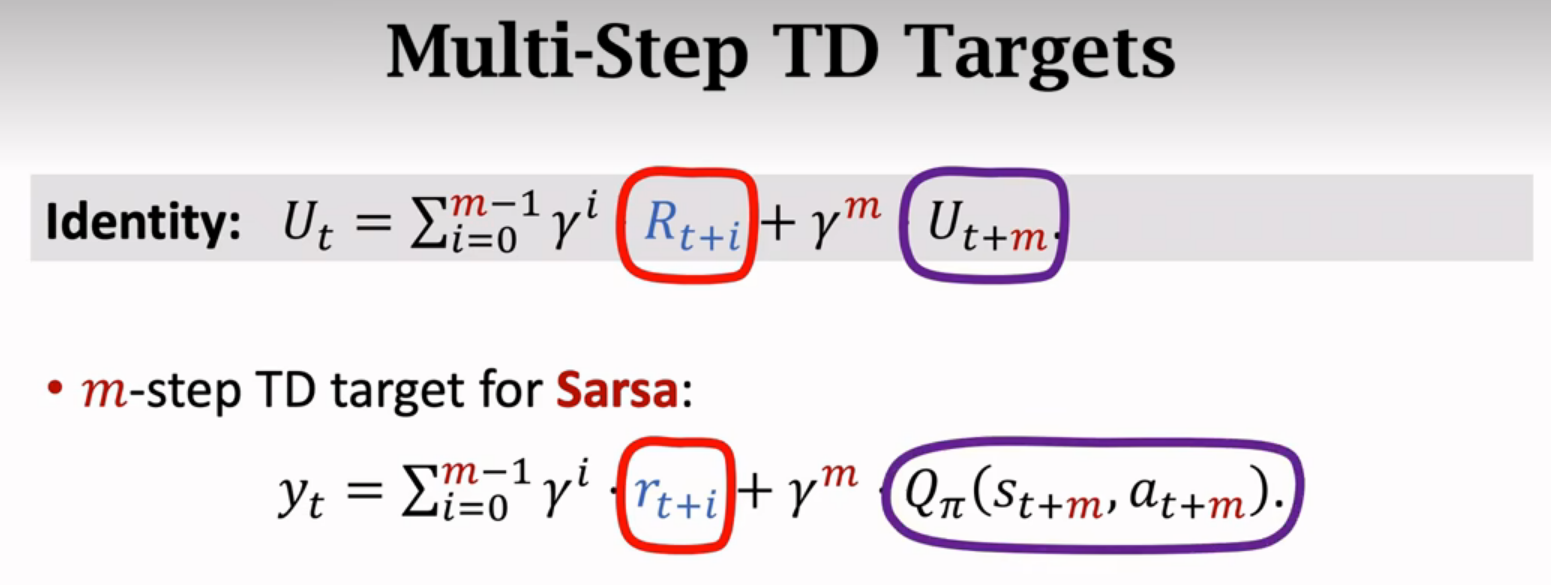
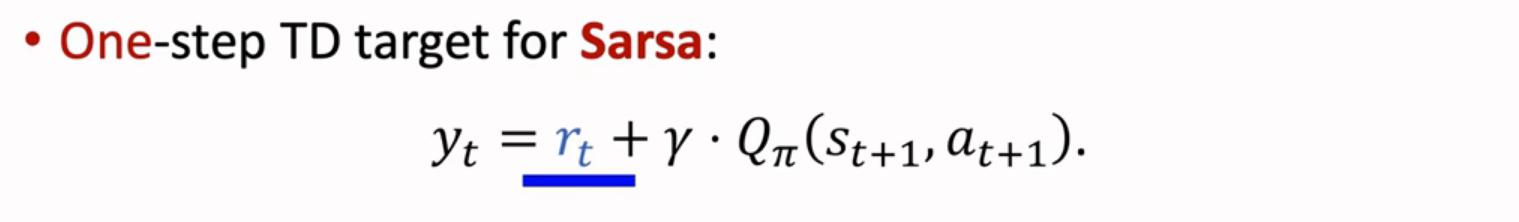

一步的效果通常不如多步的

经验回放Experience Replay
DQN回顾
TD算法



之前算法的缺点


经验回放
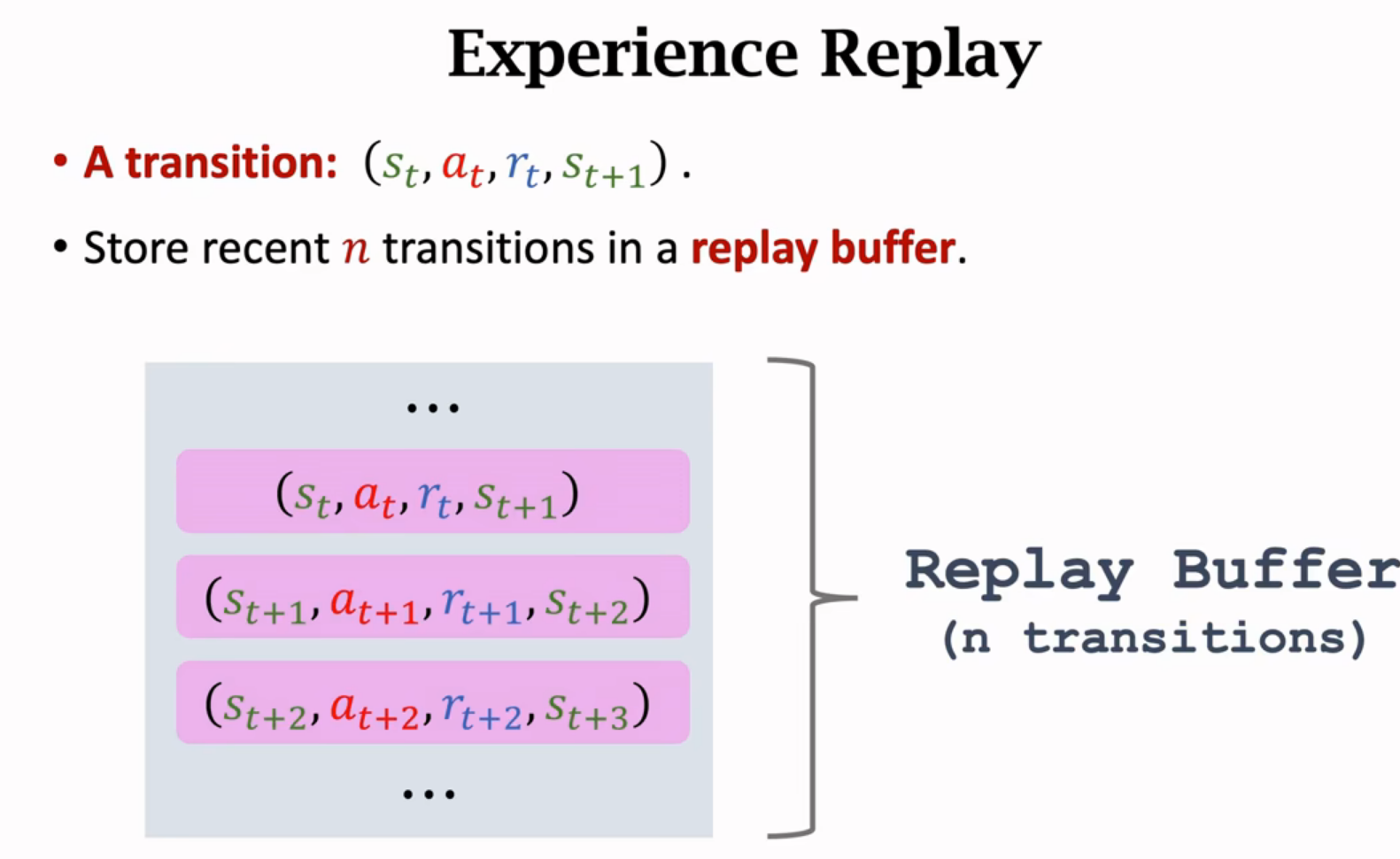


这里只用了一个transition,实际上一般是随机抽取多个transitions,算出多个随机梯度,用梯度的平均更新w


优先经验回放


训练出来的DQN不熟悉右边的场景,所以预测偏离TD target,所以TD error大,越重要,抽样概率应该越大
非均匀抽样代替均匀抽样


如果一条transition有较大的抽样概率则学习率应该小


总结
均匀抽样时学习率固定成α,现在使用不同的抽样概率会造成DQN的预测有偏差,为了消除偏差,应该相应调整学习率,把学习率按照抽样概率p来调整

Target Network & Double DQN


高估





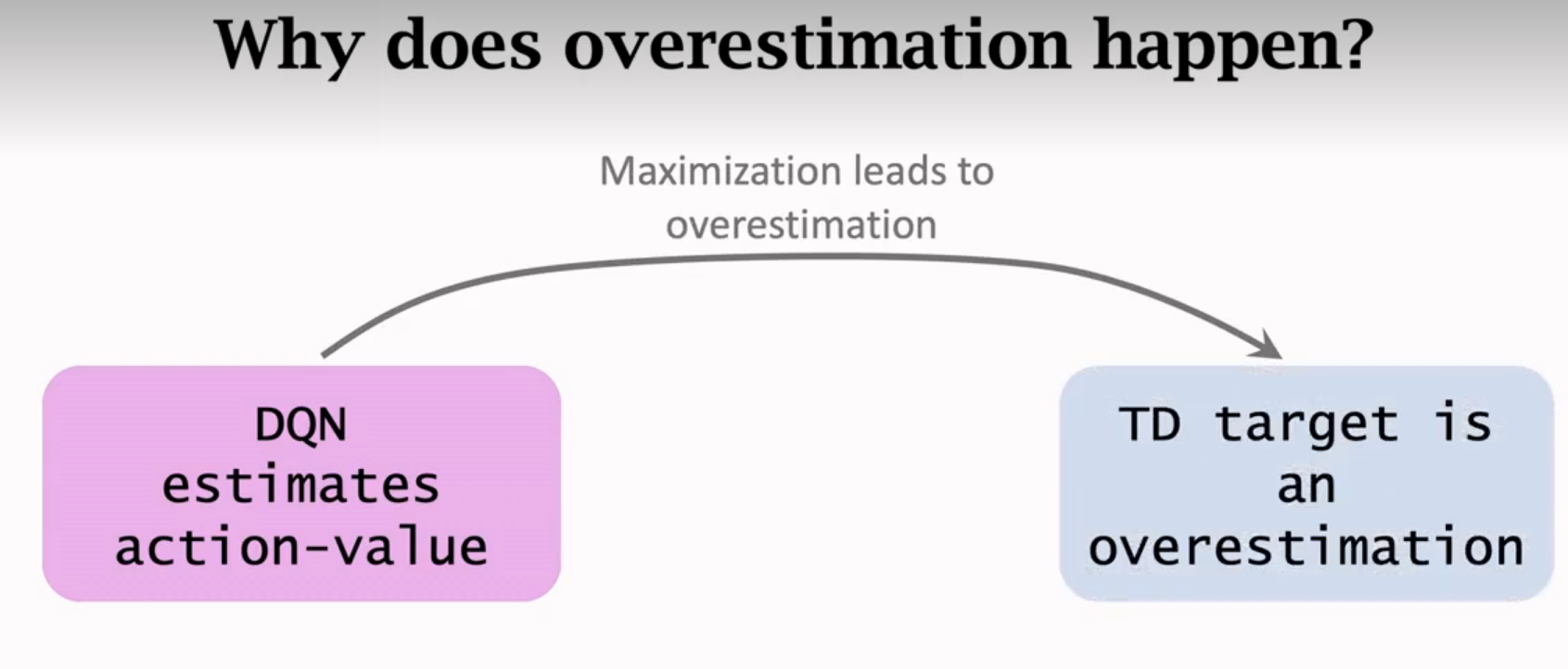
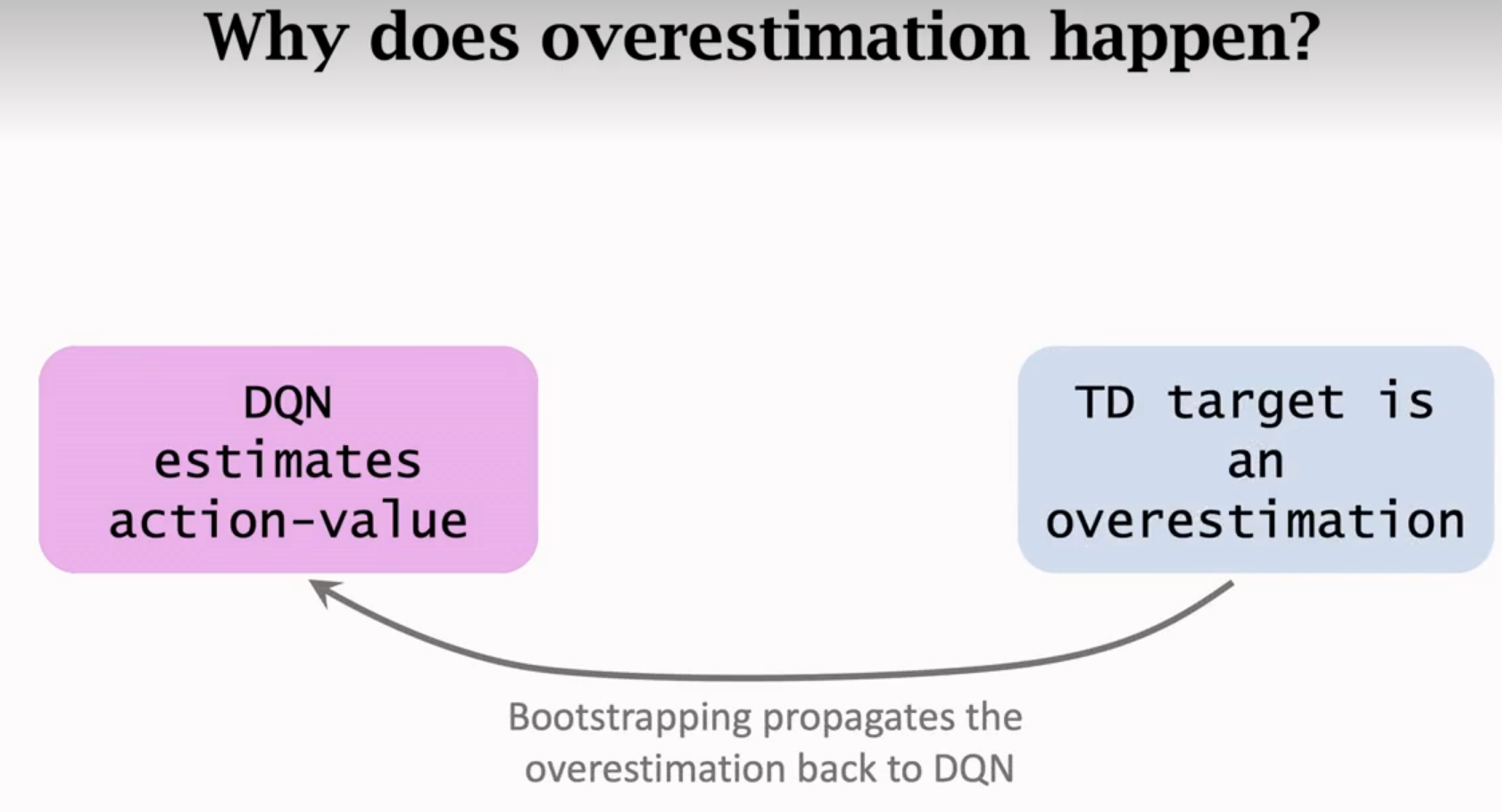
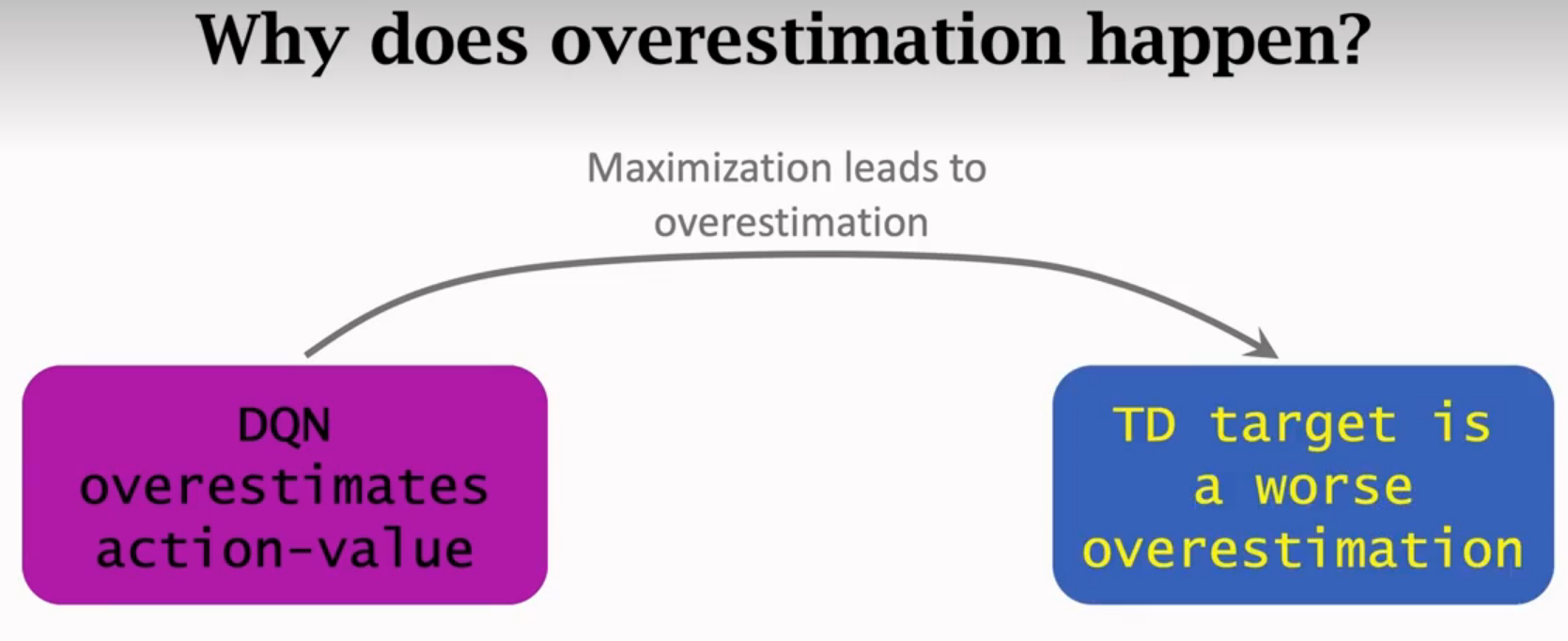
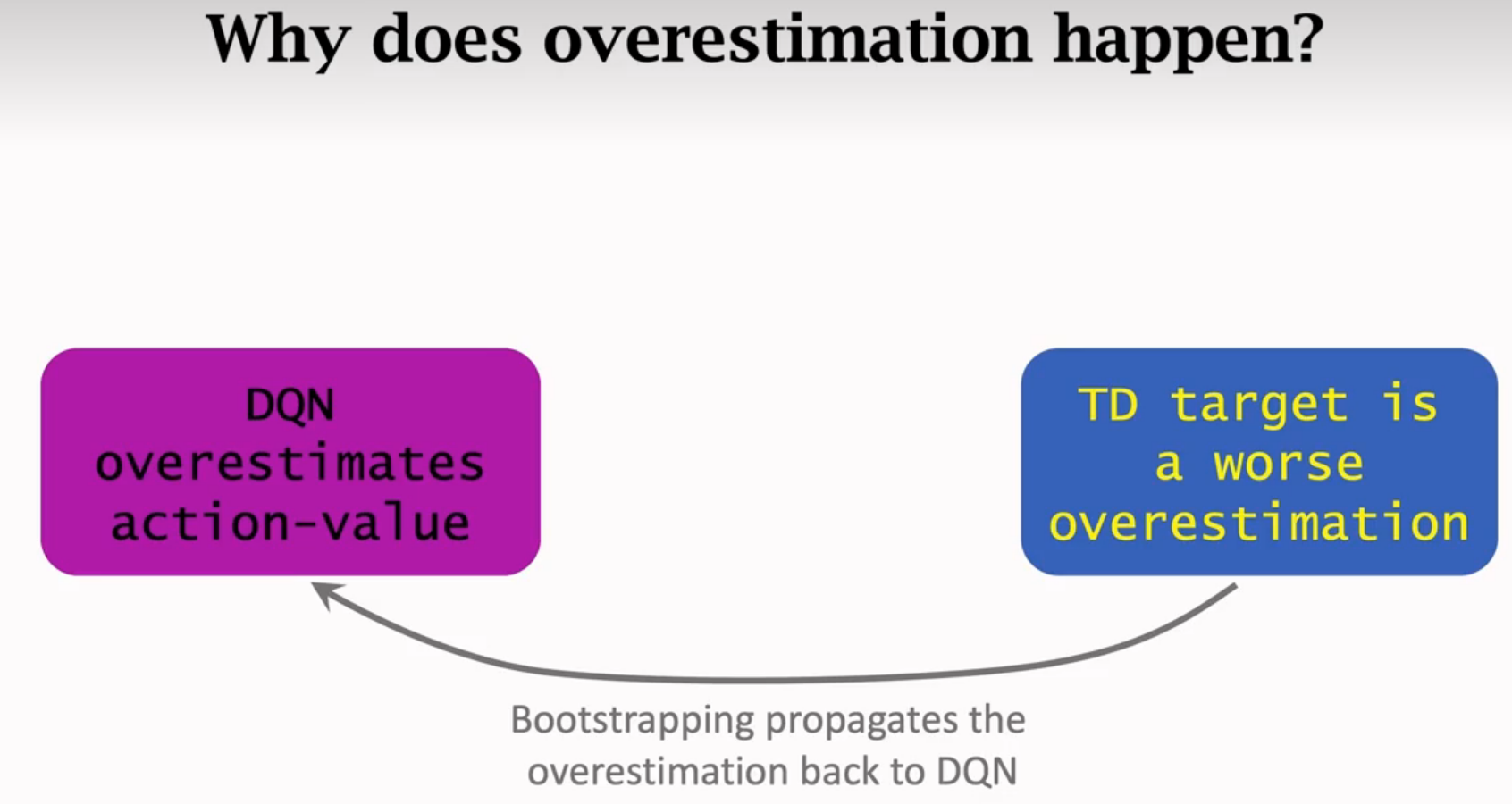
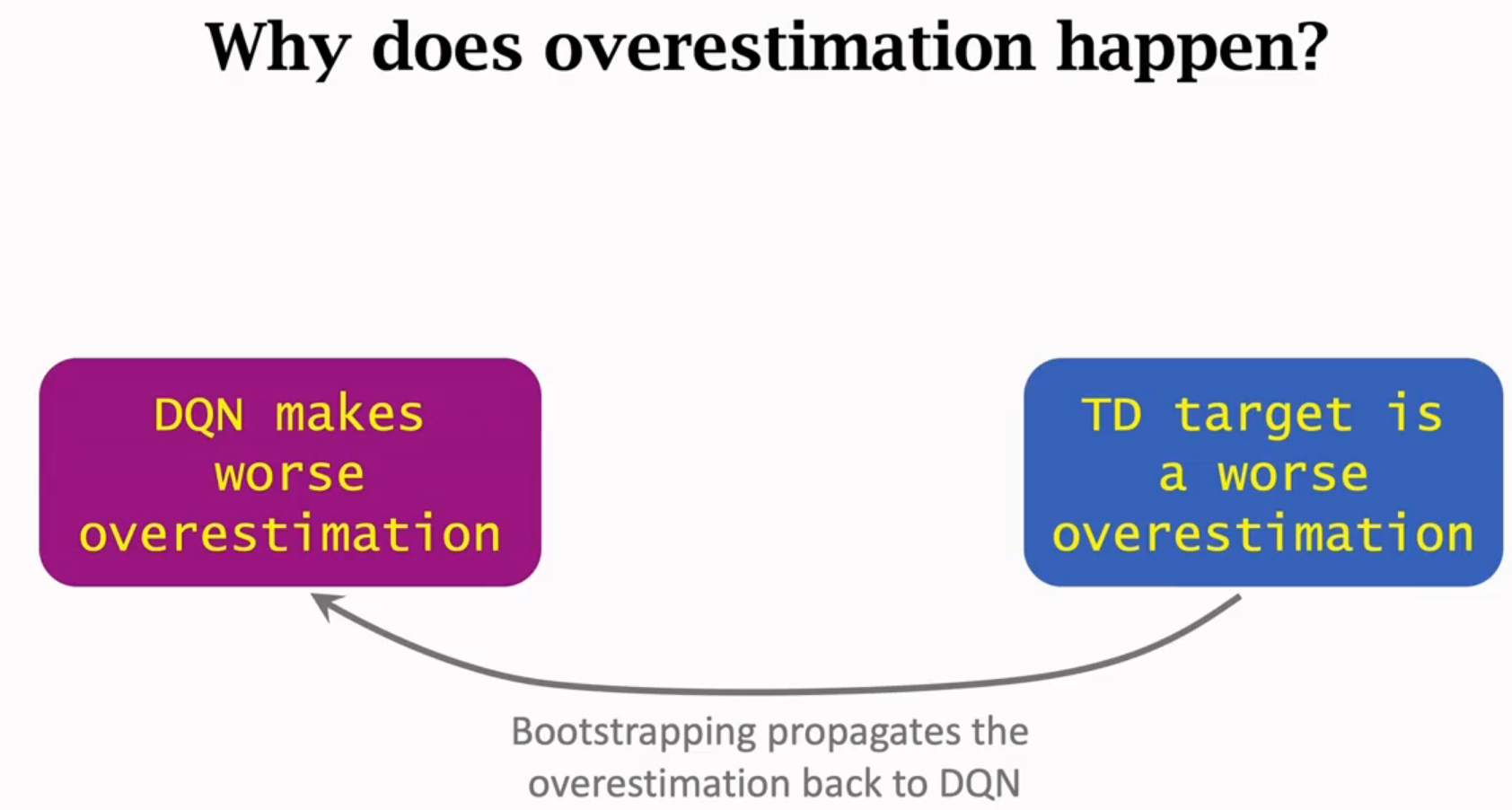
高估的缺点
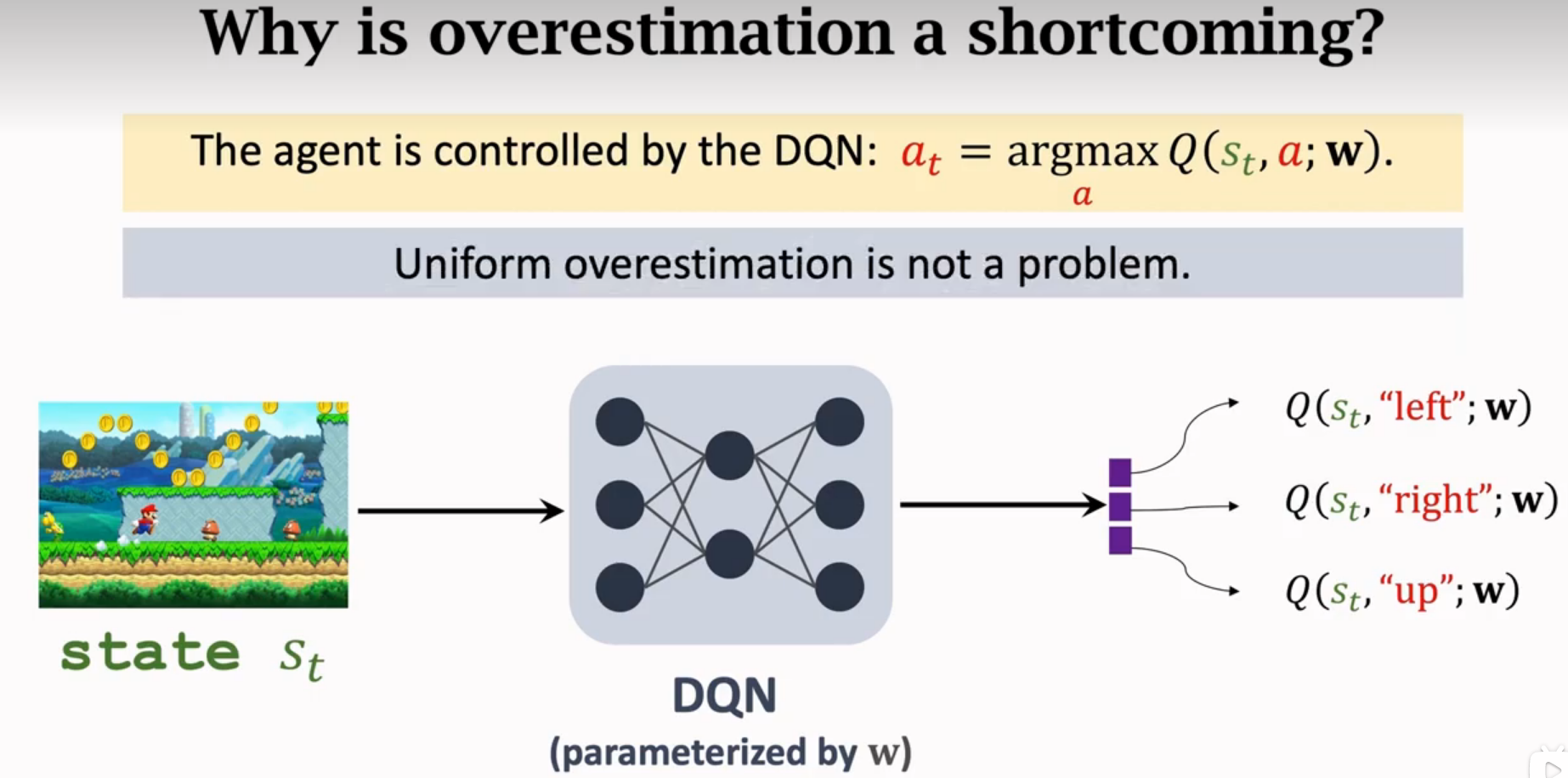


解决

Target Network


隔一段时间才更新w-


Double DQN




Double DQN为什么更好

总结

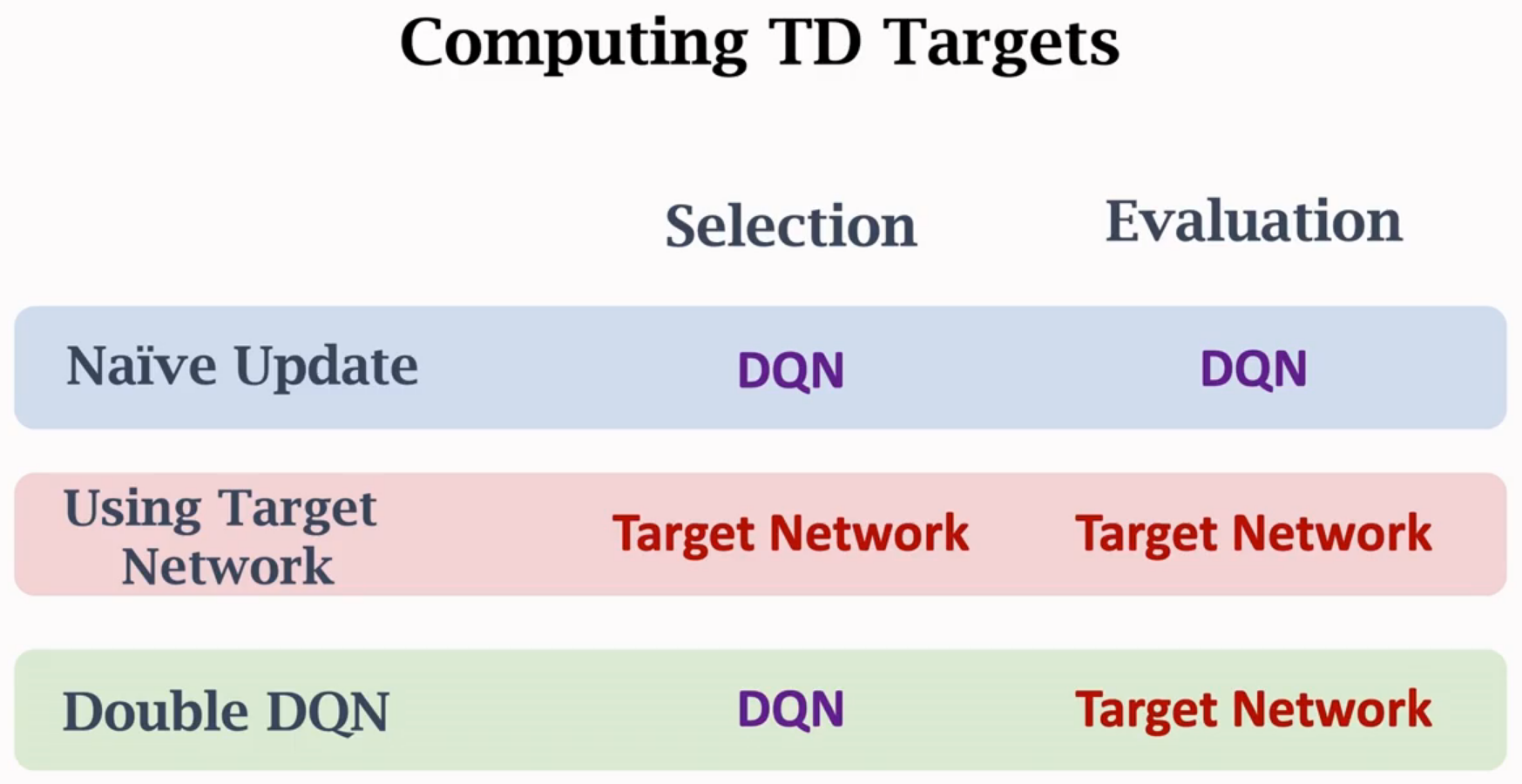
Double DQN同时缓解造成高估的两个因素,所以效果最好
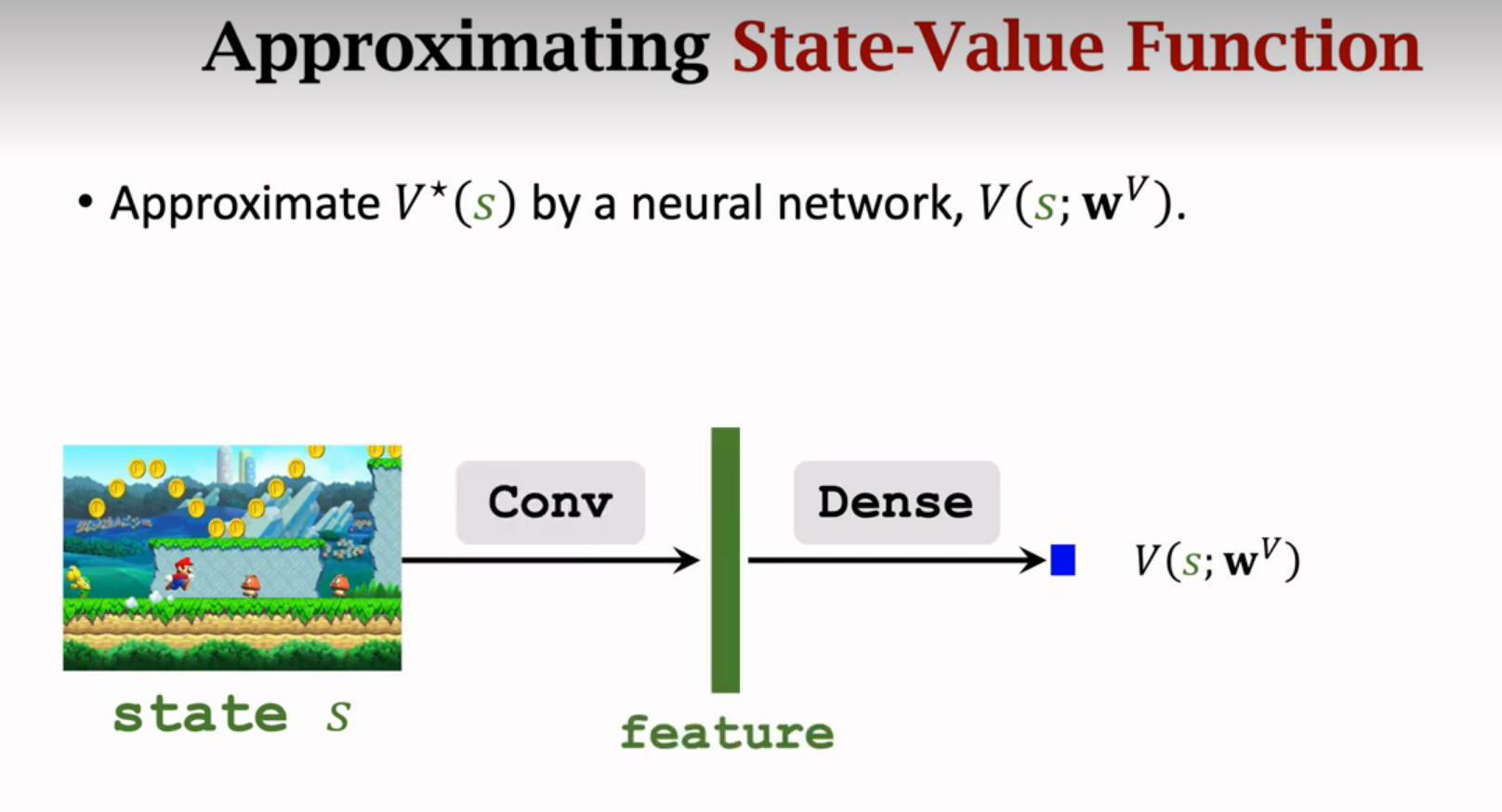
Dueling Network
对网络结构进行改进,也可以大幅度提升DQN的表现
Advantage Function优势函数




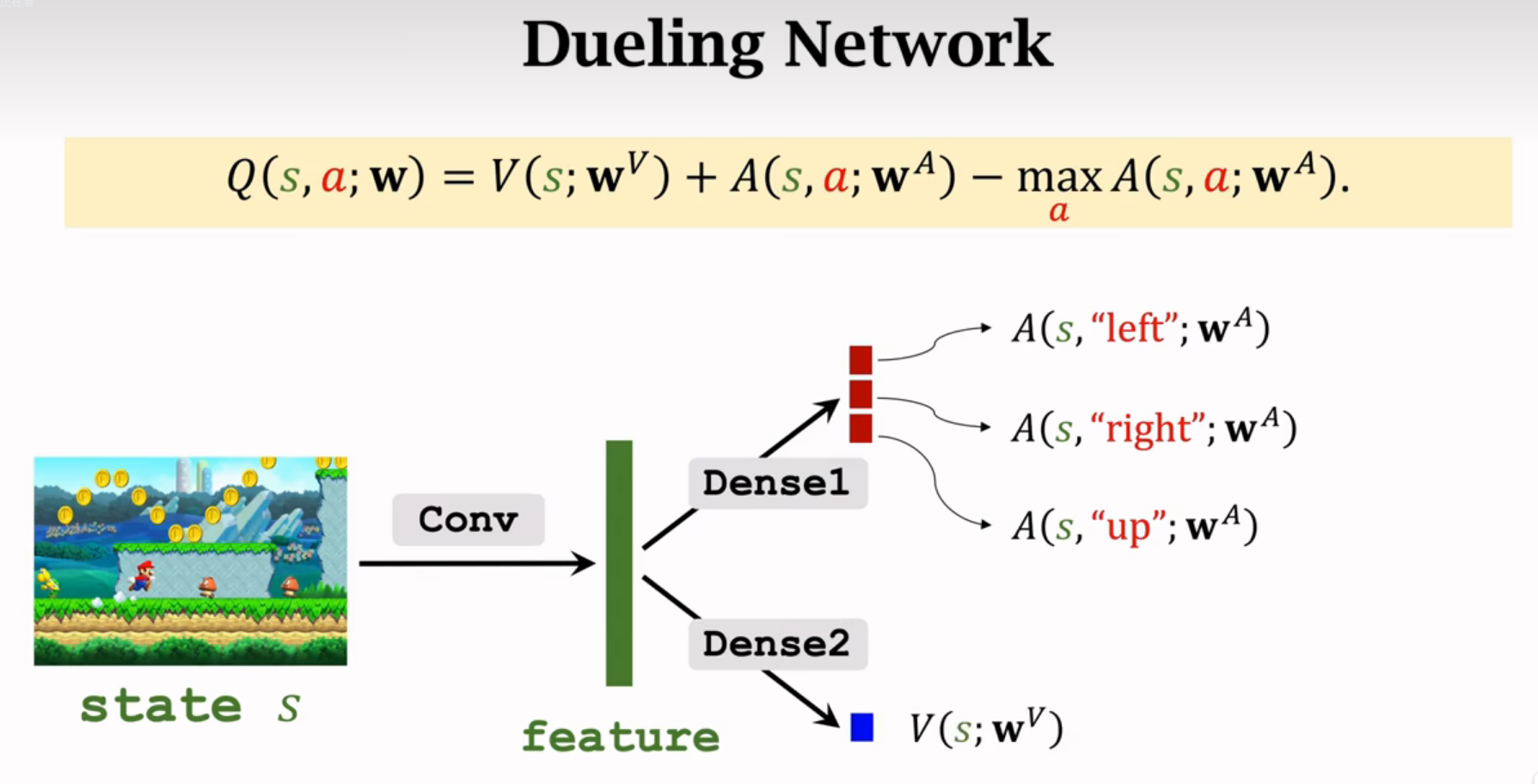
Dueling Network
传统DQN:
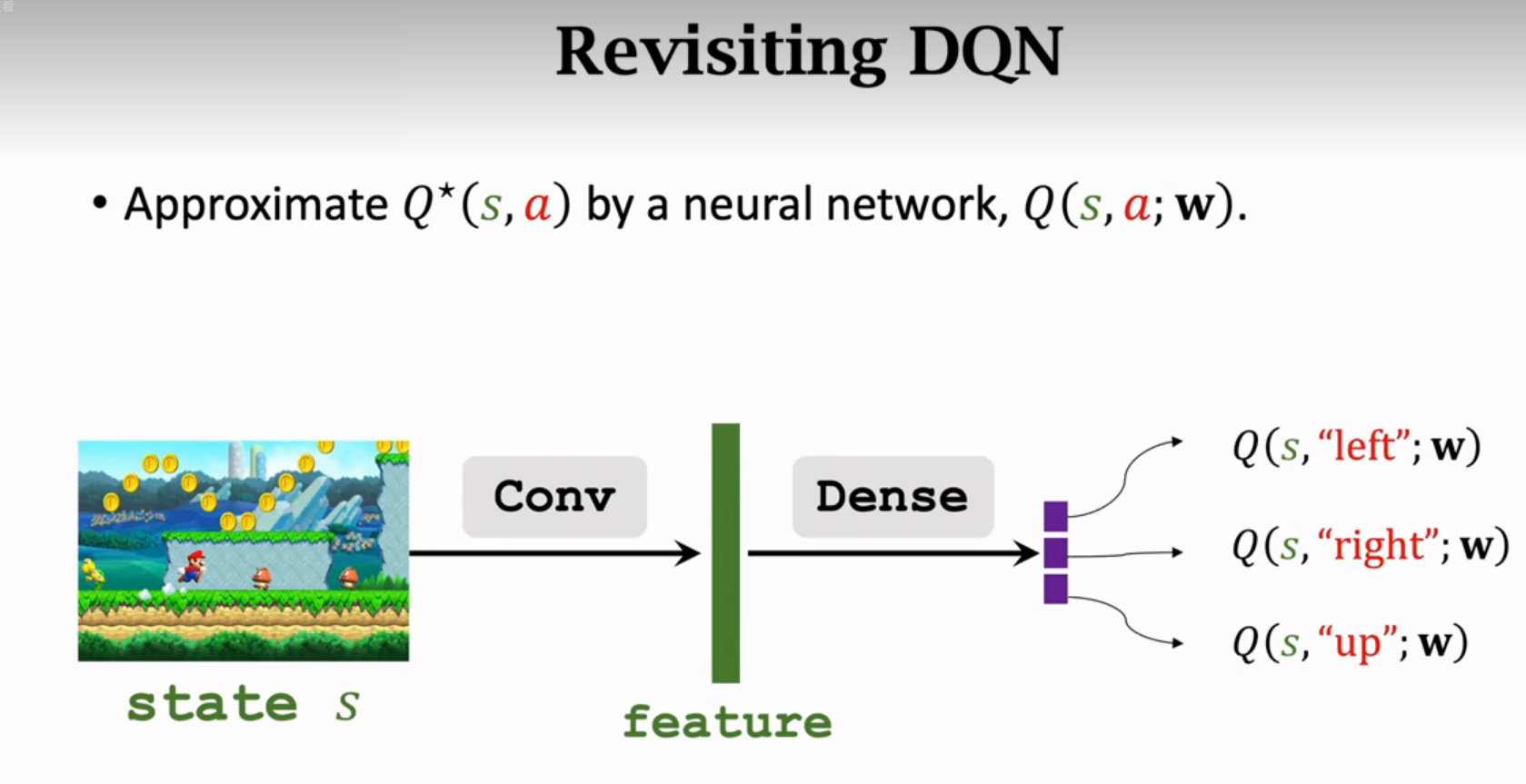
这节课介绍的结构:
神经网络的结构跟DQN一样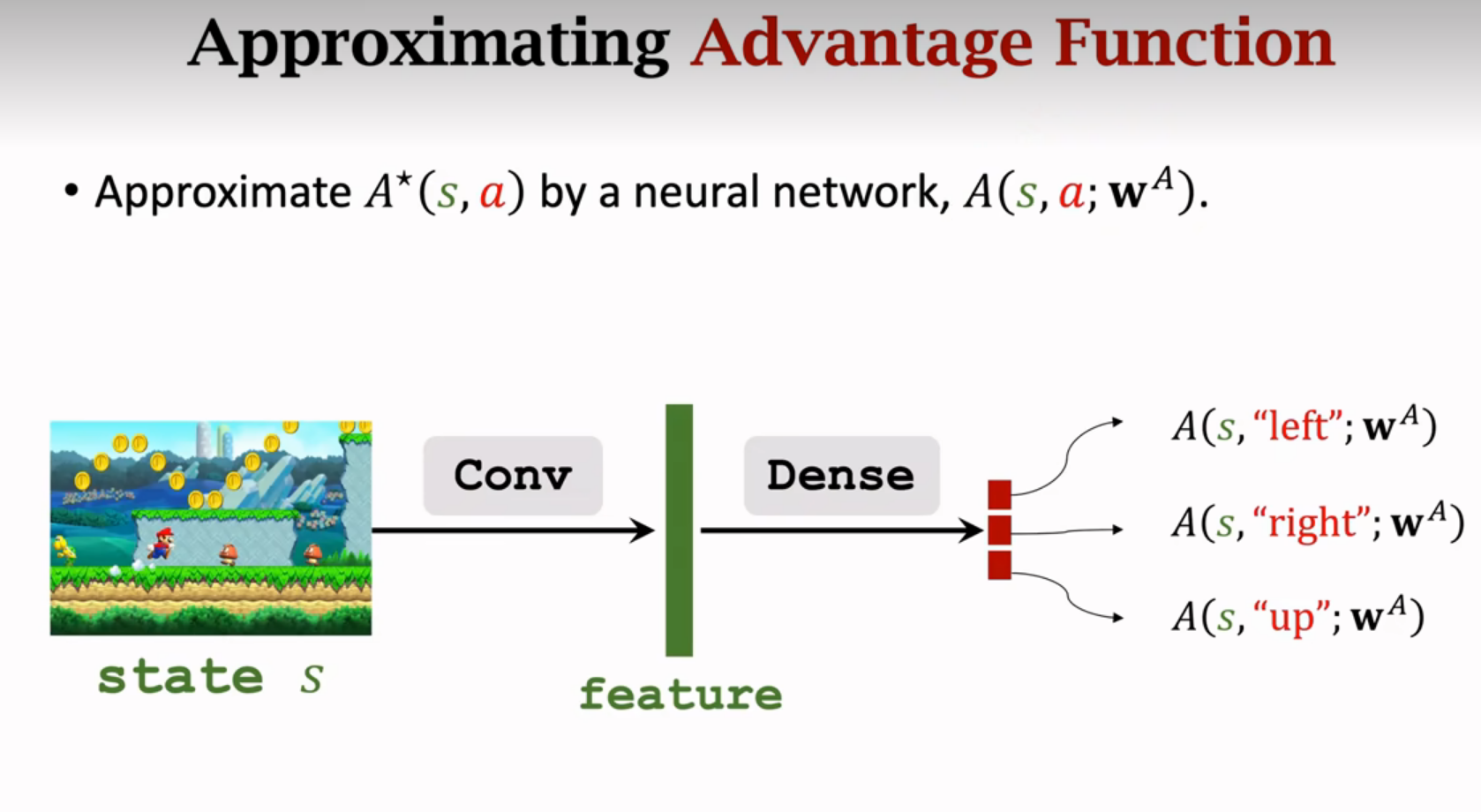
以上两图可以共享卷积层的参数

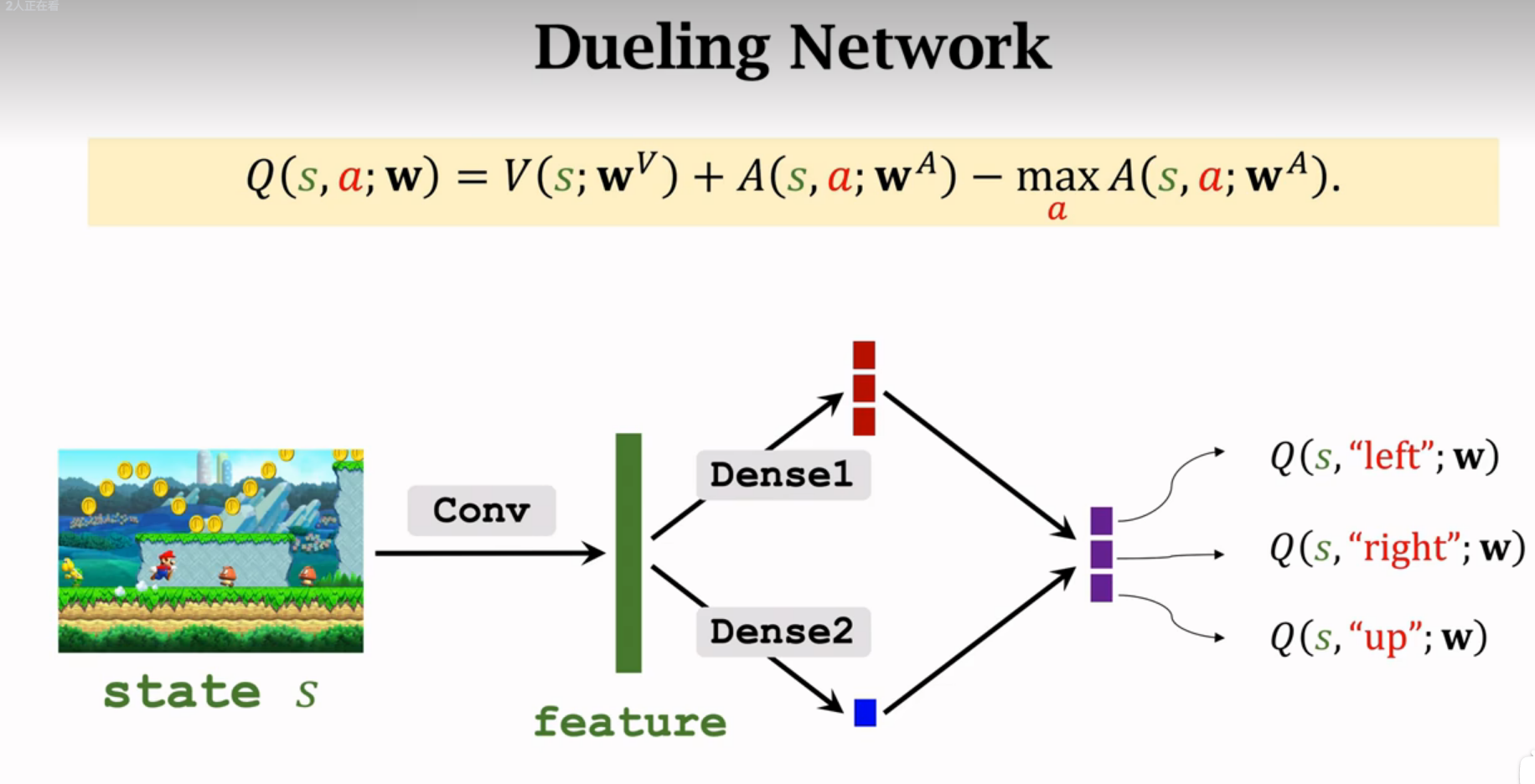
dueling network比DQN表现更好
训练
dueling network也可以用训练DQN的方法来训练
不唯一问题 
要是V和A都上下波动,幅度相同方向相反,那么dueling network的输出毫无差别,但是V和A都不稳定,都训练不好。解决:

替换成均值效果更好(无理论依据,仅实验效果好):

总结

Policy Gradient with Baseline
往策略梯度中加入baseline可以降低方差,收敛更快
策略梯度

baseline

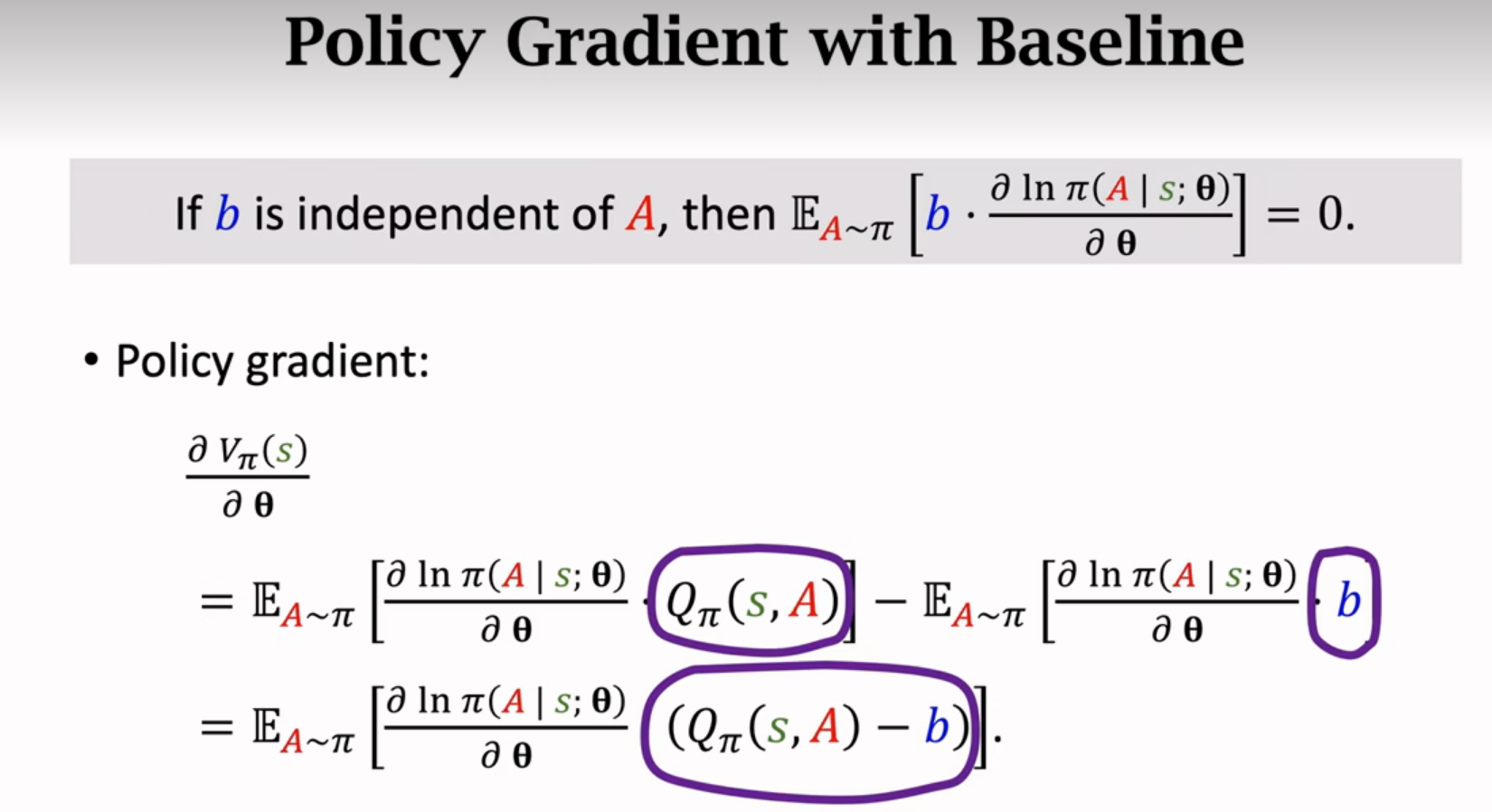

b会影响蒙特卡洛近似,选的b接近Qπ那么b会让蒙特卡洛近似的方差降低,算法收敛更快
蒙特卡洛近似
上面直接求期望比较困难,所以用蒙特卡洛对期望做近似

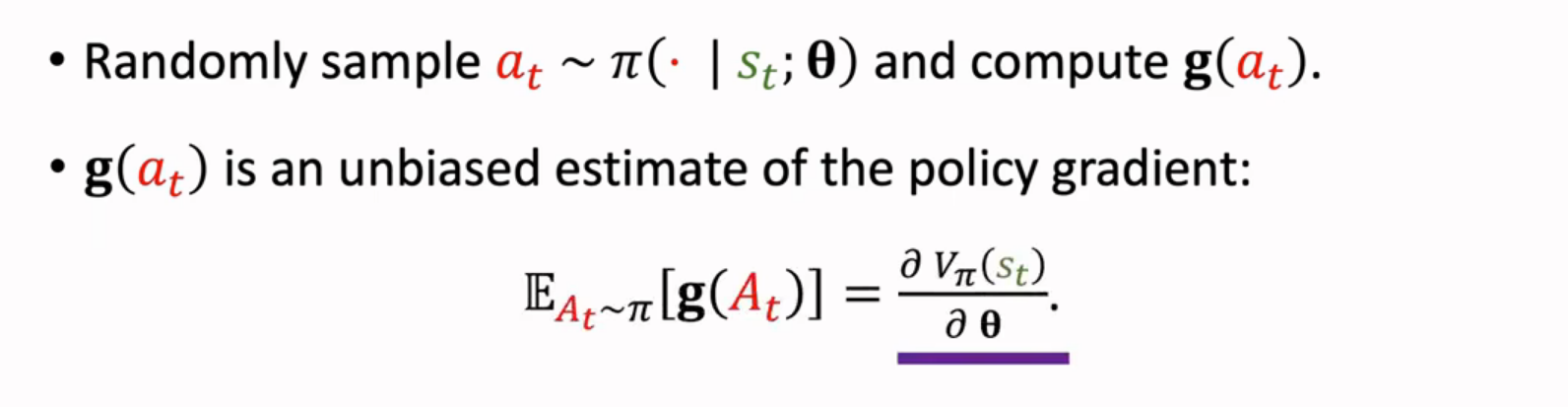


baseline的选择
baseline跟动作A无关就行


REINFORCE with Baseline
回顾






策略网络和价值网络
策略网络用来控制agent,价值网络起辅助作用作为baseline,帮助训练策略网络



REINFORCE with Baseline
用REINFORCE算法训练策略网络,用回归方法训练价值网络

圈出来的记作-δt,是价值网络的预测与真实观测到的回报ut之间的差


总结


Advantage Actor-Critic (A2C)

critic之前用的动作价值函数,现在用的状态价值函数,状态价值函数只跟s有关,跟a无关,更好训练

训练

算法理论推导

参考视频p16
REINFORCE与A2C异同
REINFORCE with baseline可以看做A2C的一种特例
都需要策略网络和价值网络,神经网络一样,但是价值网络的功能不一样。A2C的价值网络叫critic,用来评价actor的表现。REINFORCE中的价值网络仅仅是baseline,不会评价动作的好坏,唯一的用处就是降低随机梯度造成的方差。

用Multi-Step TD Target改进A2C




REINFORCE with Baseline

A2C(用TD Target,部分估计部分真实观测)与REINFORCE with Baseline(完全基于真实观测的奖励)的唯一区别:

REINFORCE与A2C异同
REINFORC是A2C的特例


离散控制与连续控制



DQN只能解决离散问题

Policy Network只能解决离散问题
连续空间离散化



Deterministic Policy Gradient(DPG)确定策略梯度
可以解决连续控制问题


DPG用在神经网络上:DDPG
DPG是一种Actor-Critic方法





改进:用Target Networks

初始高估就一直高估,初始低估就一直低估
解决方案:
 用来计算TD target的网络叫target network
用来计算TD target的网络叫target network

target policy network和policy network结构相同但是参数不同
target value network和value network结构相同但是参数不同


改进

随机策略和确定策略对比

随机策略做连续控制
复习






















 1008
1008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









