







1 Hive SQL
1 select查询
select time, ip from access;
select * from access;
不会触发MR操作
2 函数
upper()等函数
select upper(url) from access;
不会触发MR操作
3 统计函数
count()
max()
min()
avg()
sum()
select count(*), max(time), min(time), avg(time), sum(time) from access;
会触发MR操作
4 distinct去除重复值
select distinct(id) from access;
会触发MR操作
5 limit限制返回记录的条数
select upper(url) from access limit 3;
不会触发MR操作
6 为列名取别名
But: Hive SQL不显示列名称,So:意义不大
select upper(url) bpx_url from access;
不会触发MR操作
7 case when then 多路分支
类似Java中switch...case
8 like 模糊查询
select * from access where url like '%2%';
不会触发MR操作
9 group by分组统计
select id, avg(time) from access group by id;
会触发MR操作
10 having过滤分组统计结果
select id, avg(time) from access group by id having avg(time) > '17/May/2015:08:05:24+0000';
会触发MR操作
11 inner join内联接
12 left outer join & right outer join外联接
13 full outer join 外部联接
14 order by 排序
asc升序 - 默认
desc降序
会触发MR操作
15 where查找
select * from access where ip=10.10.10.10;
>不支持子查询
>利用联接查询来实现
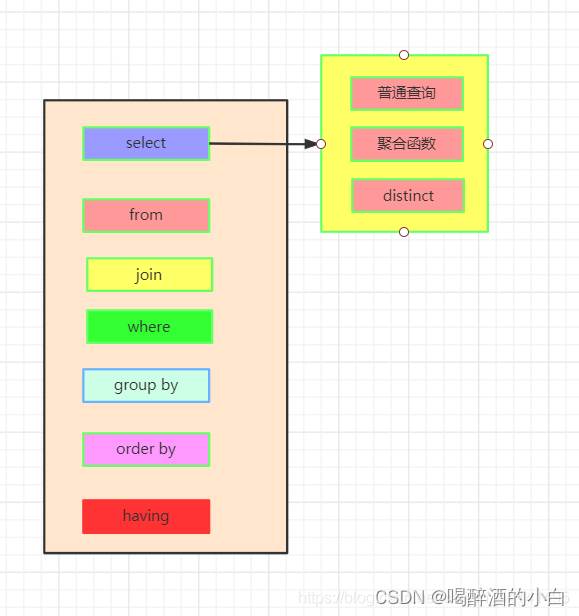
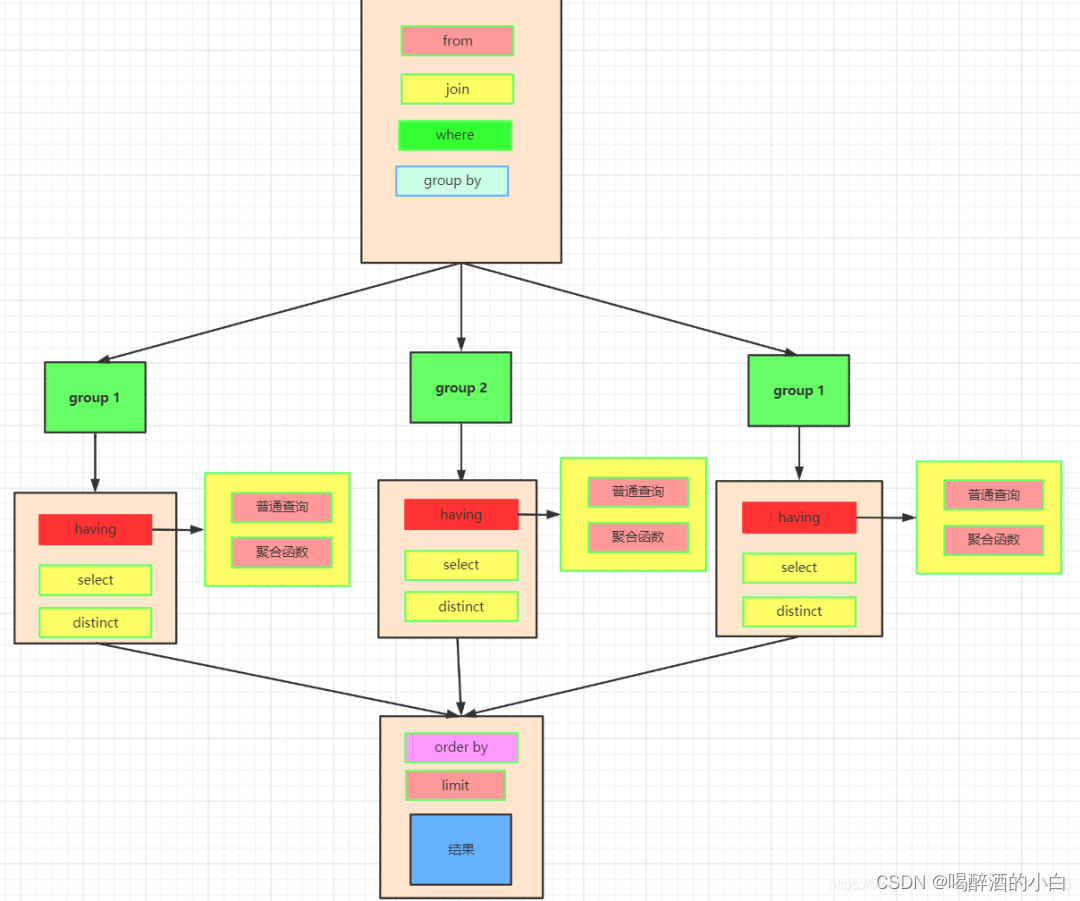
2 Hive 不涉及子查询的单表查询SQL执行顺序
FROM + 表名
WHERE + 查询条件
GROUP BY + 字段名
HAVING + 查询条件
DISTINCT + 字段名
ORDER BY + 字段名
LIMIT + 数量
3 常用关键词解释
| 关键词 | 解释 |
|---|---|
| SELECT | 告诉数据库提取数据的时候所需字段名称。字段名称可以是表中已有的字段,也可以是函数基于表中字段名称生成的字段名称。多个字段名称之间用英文符号,分隔开来。 |
| FROM | 告诉数据库提取数据的时候需要的表或视图。 |
| WHERE | 限定数据查询的条件,提取数据子集。查询条件包括:比较运算符、成员运算符、通配符、逻辑运算符。 |
| GROUP BY | 聚合(统计)时候的分组操作,通常与聚合函数一起使用,例如统计商品页这个月每天的访问量,访问量的计算就是统计过程,以天为单位进行统计就是分组。需要写入被分组的字段,可以填写多个字段。 |
| HAVING | 同WHERE作用都都是为了筛选数据,不同之处在于WHERE是针对表中已经存在的字段进行筛选,HAVING是针对统计结果的筛选。需要写入具体的筛选条件,筛选条件不能存在通配符。 |
| ORDER BY | 对查询结果的排序,可以按照某个字段名称或某些个字段名称来进行升序或降序的设置。多个字段名称之间用英文符号,分隔开来。默认按照升序排序,但可以通过DESC来实现降序排序。 |
| LIMIT | 限定查询返回的记录行数,可以是前几行或中间几行以及末几行。搭配ORDER BY子句可以实现TOPN。 |
https://mp.weixin.qq.com/s/rKn9AnlSEMiVTIQTLEH3Sg















 694
694











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









