







DMDataWatch
一种高可用数据库解决方案,主备节点间通过日志同步来保证数据的同步,可以实现数据库快速切换与灾难性恢复,满足用户对数据安全性和高可用性的需求,提供不间断的数据库服务。
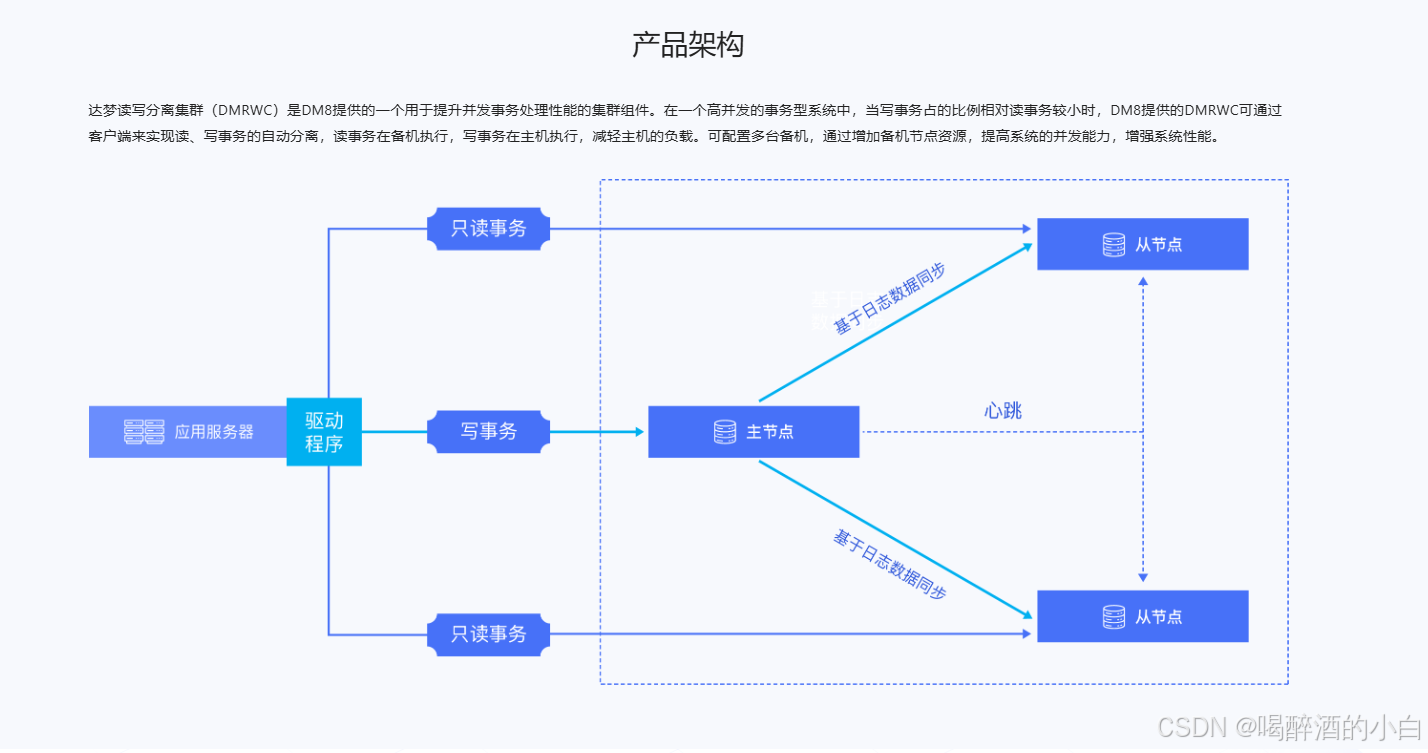
DMRWC
在保障主库和备库事务强一致的前提下,开创性地在接口层(JDBC、DPI 等)将只读操作自动分流到备库,有效降低主库的负载,提升系统吞吐量,适用于读多写少的业务场景。
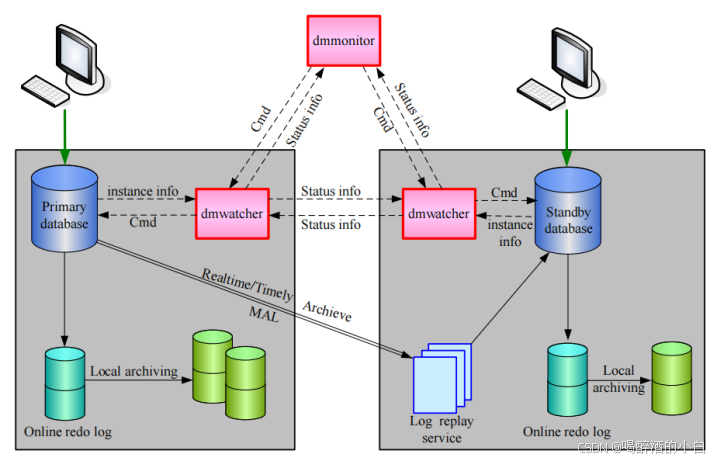
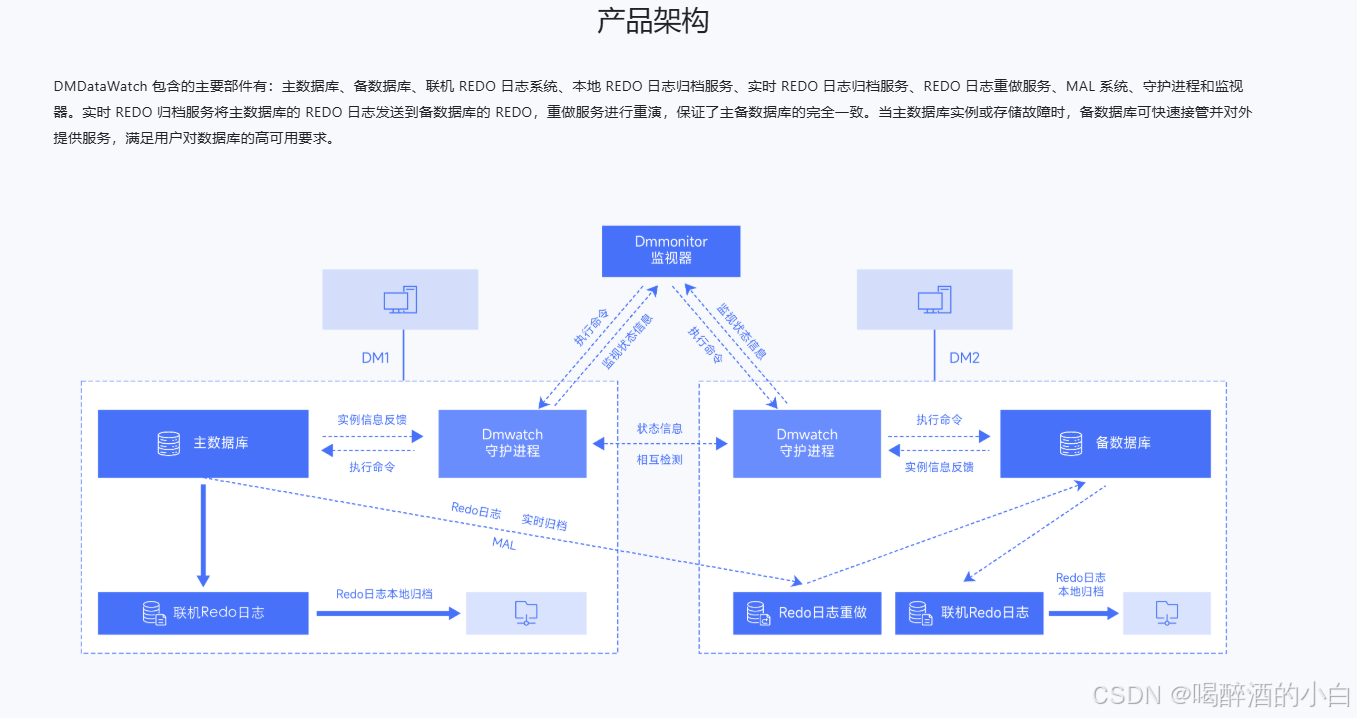
数据守护的核心组件是dmwatcher守护进程和dmmonitor监视器。数据同步依赖与于达梦特有的MAL系统。MAL 系统是基于 TCP 协议实现的一种内部通信机制,具有可靠、灵活、高效的特性。**达梦通过 MAL 系统实现 Redo 日志传输,以及其他一些实例间的消息通讯。**在物理组成上,MAL系统需要在数据库服务器上单独规划一片网卡,并使之与业务网络隔离。
主备
读写分离
主备模式
即时归档(Timely)
在主库将 Redo 日志写入联机日志文件后,通过 MAL 系统将 Redo日志发送到备库。即时归档与实时归档的主要区别是 Redo 日志的发送时机不同。
事务一致模式:主库在事务提交前,将重做日志同步传输到备库,并等待备库确认日志已接收并应用。这种模式确保主备数据一致,但可能对主库性能有一定影响。
高性能模式:主库在事务提交后,异步将重做日志传输到备库,无需等待备库确认。这种模式对主库性能影响较小,但在故障情况下可能存在数据不一致的风险。
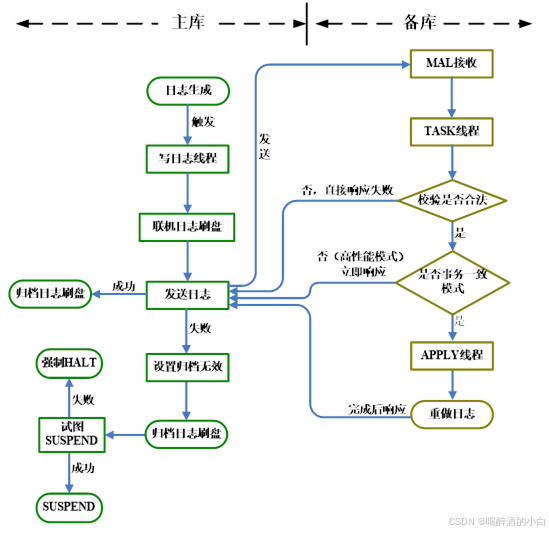
读写分离集群可以配置为即时归档,也可以配置为实时归档,这两种配置方式仅仅是归档流程上有差别,读写分离集群的特性仍然是一致的。即时归档流程与实时归档流程存在一定差异:
-
主库先将日志写入本地联机 Redo 日志文件中,再发送 RLOG_PKG 到备库。
-
备库日志重演时机有两种选择:
事务一致模式 要求备库在重演 Redo 日志完成后再响应主库。
高性能模式 与实时归档一样,收到 Redo 日志后,马上响应主库。 -
即时归档的同步机制可以保证备库的 Redo 日志不会比主库的 Redo 日志多,因此即时备库不需要 KEEP_RLOG_PKG,收到 RLOG_PKG 直接加入到 Apply 任务系统,启动 Redo 日志重演。
-
备库故障或主备库之间网络故障,导致发送 RLOG_PKG 失败后,主库马上修改即时归档为 Invalid 状态,并切换数据库为 Suspend 状态。
-
即时归档修改为 Invalid 状态后,会强制断开对应此备库上存在影子会话的用户会话,避免只读操作继续分发到该备库,导致查询数据不一致。
实时归档(Realtime) – 实时主备
实时主备由一个主库以及一个或者多个配置了实时(Realtime)归档的备库组成,其主要目的是保障数据库可用性,提高数据安全性。实时主备系统中,主库提供完整的数据库功能,备库提供只读服务。主库修改数据产生的Redo日志,通过实时归档机制,在写入联机Redo日志文件之前发送到备库,实时备库通过重演Redo日志与主库保持数据同步。当主库出现故障时,备库在将所有Redo日志重演结束后,就可以切换为主库对外提供数据库服务。
将主库产生的Redo 日志通过 MAL 系统传递到备库,实时归档是实时主备的实现基础。实时归档只在主库生效。
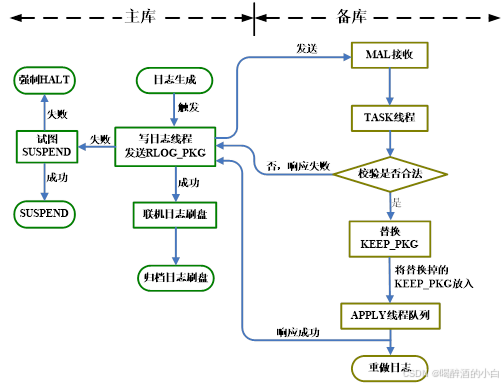
主库生成联机 Redo 日志,当触发日志写文件操作后,日志线程先将 RLOG_PKG 发送到备库,备库接收后进行合法性校验(包括日志是否连续、备库状态是否 Open 等),不合法则返回错误信息,合法则作为 KEEP_RLOG_PKG 保留在内存中,原有 KEEP_RLOG_PKG 的 Redo 日志加入 Apply 任务队列进行 Redo 日志重演,并响应主库日志接收成功。当有多个备库时,主库需要收到所有备库的响应消息才继续后续操作。
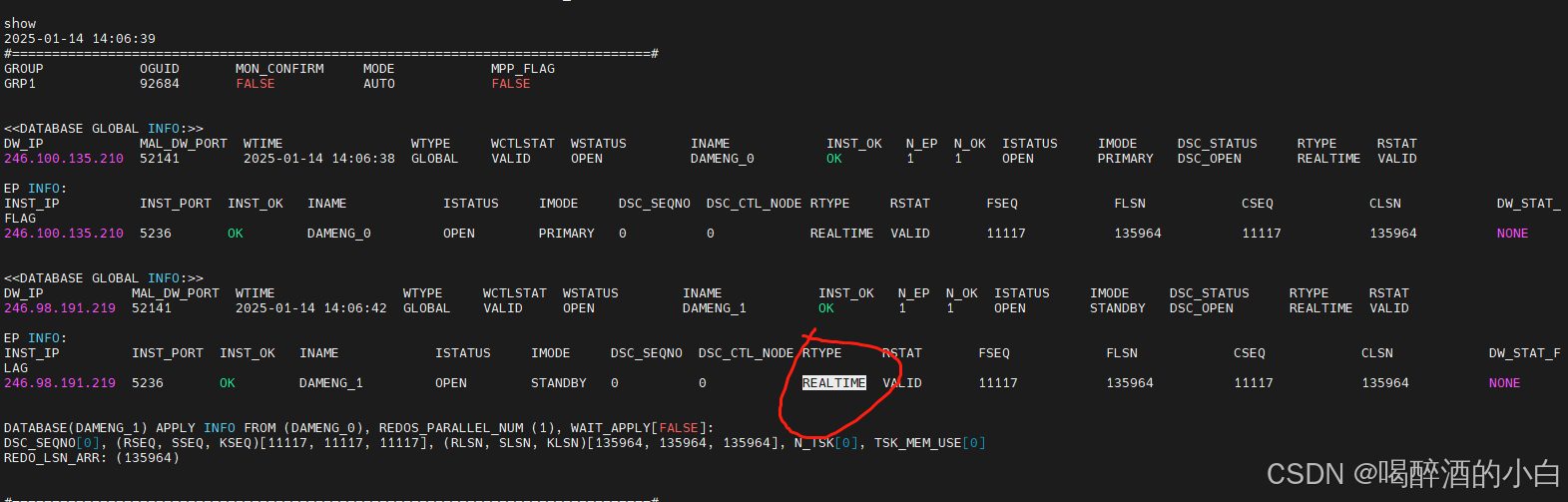
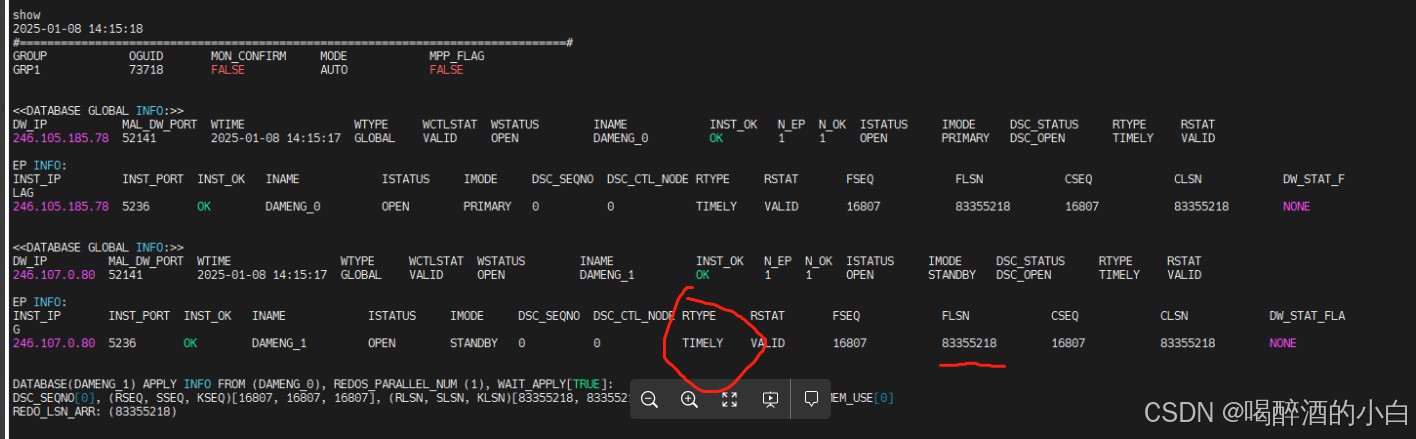
达梦数据库主备状态监控信息
达梦数据库主备状态监控信息,可能是。以下是对日志中关键信息的分析:
第一组数据(主库)
- DW_IP:
246.99.134.237 - RTYPE:
REALTIME表示实时复制。 - RSTAT:
VALID表示当前状态有效。 - WTIME:
2025-01-07 20:40:28表示最后更新时间。 - INST_OK:
OK表示实例运行正常。 - ISTATUS:
AFTER REDO表示在重做日志应用之后。 - IMODE:
PRIMARY表示这是主库实例。 - DSC_STATUS:
DSC_OPEN表示数据同步通道是打开的。
RTYPE:节点实例配置的归档类型,只统计 REALTIME/TIMELY 这两种归档类型,如果这两种归档都没有配置,则显示为 NONE。
第二组数据(备库)
- DW_IP:
246.103.176.223 - RTYPE:
REALTIME同样表示实时复制。 - RSTAT:
INVALID表示当前状态无效,可能是因为备库没有正确连接到主库。 - WTIME:
2025-01-07 20:40:28同样是最后更新时间。 - INST_OK:
OK表示实例运行正常。 - ISTATUS:
MOUNT表示备库已经挂载,但是没有应用日志。 - IMODE:
STANDBY表示这是备库实例。 - DSC_STATUS:
DSC_OPEN表示数据同步通道是打开的。
应用信息
- APPLY INFO FROM(DAMENG_1): 备库从主库
DAMENG_1应用日志。 - REDOS_PARALLEL_NUM(1): 表示并行重做日志的数量为1。
- WAIT_APPLY[FALSE]: 表示没有等待应用日志。
- DSC_SEQNO[0]: 表示数据同步序列号为0。
- (RSEQ,SSEQ,KSEQ)[427924913, 427924913, 427924913]: 表示重做序列号、提交序列号和日志序列号都是427924913。
- (RLSN, SLSN, KLSN)[165200582407, 165200582407, 165200582407]: 表示重做日志序列号、提交日志序列号和最后日志序列号都是165200582407。
- N_TSK[0]: 表示任务数量为0。
- TSK_MEM_USE[0]: 表示任务内存使用为0。
- REDO_LSN_ARR:(165200582407): 表示重做日志序列号数组中包含165200582407。
结论
主库 DAMENG_1 运行正常,并且数据同步通道是打开的。备库 DAMENG_0 也运行正常,但是状态显示为无效,可能是因为它还没有开始应用主库的日志,或者存在网络连接问题。备库的状态需要进一步检查,以确保它能够正确地从主库接收并应用日志。如果备库长时间处于 INVALID 状态,可能需要进行故障排查。
重做日志恢复过程
这段日志记录了达梦数据库(DMDB)在某个时间点的重做日志恢复过程。以下是对日志中关键信息的分析:
-
初始化重做日志:
plog_redo_init(redo_type: 2) by ckpt info, set redo_lsn from 0 to 165303628991- 这表示重做日志初始化开始,通过检查点(ckpt)信息设置重做日志序列号(LSN)从0变更到165303628991。
-
设置包序列号:
set rpkg_seq from 0 to 427938847, rpkg_lsn from 0 to 165303628991- 这里设置了重做包的序列号(rpkg_seq)和重做包的LSN。
-
重做日志接收初始化:
plog_redo_recv_init, max_ckpt_lsn:165303628991, max_apply_lsn:41238036770, plog_pwr_hash is NULL: TRUE- 初始化重做日志接收,记录了最大的检查点LSN和最大的应用LSN,以及plog_pwr_hash(可能是一个校验和或者相关参数)为NULL。
-
配置参数变更:
INI parameter REDOS_ENABLE_SELECT changed, the original value 1, new value 0- 这表示配置参数REDOS_ENABLE_SELECT被更改,原始值为1,新值为0。
-
开始重做日志恢复:
begin redo log recover, last ckpt lsn: 165303628991- 开始重做日志的恢复工作,最后一个检查点的LSN为165303628991。
-
重做日志包加载完成:
plog_redo_it rlog_pkg load finished, total_rpkgs:1614, total_rpkg_bytes:502364160- 重做日志包加载完成,总共加载了1614个包,总字节数为502364160。
-
重做日志恢复完成:
redo log recover finished- 重做日志恢复完成。
-
重做记录统计:
total redo 281243 rrec, 0 rrec opt by pwr, code:0- 总共有281243条重做记录被应用,没有记录被pwr(可能是一个特定的优化或者参数)优化,返回代码为0,表示成功。
pwr 很可能是一个特定的优化机制(例如“power optimization”或“performance write reduction”),专门用来优化 redo 日志处理的性能或减少某些开销。
结论
日志显示达梦数据库成功完成了重做日志的初始化和恢复过程。所有的重做日志包都被加载和应用,没有错误发生。这通常是数据库启动过程中的一部分,确保在崩溃或重启后,所有的更改都能被正确地应用,以保持数据的一致性。
回滚百分比
分析1
这段日志显示了数据库的页面回滚百分比(page rollback percent),这是数据库事务日志中的一个重要指标,用于衡量在事务回滚时需要回滚的页面百分比。以下是对日志中关键信息的分析:
-
日志时间戳:
2025-01-07 21:01:44.269和2025-01-07 21:02:05.005分别表示两条日志记录的时间。
-
日志级别:
[INF0]表示这是信息级别的日志。
-
数据库标识:
database P0000000486 T0000000000000000622表示这是数据库实例的标识。
-
页面回滚信息:
total [208076/472861] page rollback percent: 44%和total [212805/472861] page rollback percent: 45%表示在给定的时间点,数据库中回滚的页面数与总页面数的比例。这里显示了两个不同的时间点,回滚百分比从44%增加到了45%。
-
事务ID:
T0000000000000000622表示这是事务的标识。
结论
日志显示数据库的页面回滚百分比在两个连续的时间点有所增加,这可能意味着在这段时间内有更多的事务需要回滚。页面回滚百分比的增加可能与数据库的负载、事务的复杂性或硬件性能有关。如果这个百分比持续增加,可能需要进一步分析数据库的性能和事务处理策略。
建议
- 监控页面回滚百分比,如果持续增加,可能需要优化事务处理。
- 检查是否有长时间运行的事务或锁争用问题。
- 考虑硬件性能,如内存和磁盘I/O,是否满足数据库的需求。
分析2
这两条日志出现在达梦数据库(DM Database)的运行日志中,描述了与 页面回滚(Page Rollback) 相关的操作状态。以下是详细分析、可能的故障模拟方法,以及数据库原理层面的解释。
一、日志解析
-
日志内容分析:
total [208076/472861] page rollback percent: 44%
表示系统中一共需要回滚 472,861 页,当前已经完成回滚 208,076 页,回滚进度为 44%。total [212805/472861] page rollback percent: 45%
表示继续回滚后,完成页数增加到 212,805 页,进度提升到 45%。
-
核心指标:
-
Page Rollback(页面回滚):
数据库中的一个操作,用于撤销对某些页面的更改,使其恢复到某个一致性状态(通常是事务开始前或某个检查点之前的状态)。
在以下场景中常见:- 事务回滚: 当事务失败或被用户显式回滚时,涉及的数据页面需要撤销。
- 崩溃恢复: 数据库重启后,未完成的事务需要回滚,恢复一致性。
- 闪回(Flashback): 回滚到之前的某个特定时间点。
-
Total Pages(总页数):
表示需要回滚的页面总数。这个数字可能很大,表明影响范围较广。
-
二、从数据库原理层面分析
-
页面回滚的原因:
- 未提交事务:
数据库在发生崩溃或异常关闭时,所有未提交事务都需要被回滚。这包括修改的页面、索引等。 - 检查点机制:
数据库通常定期将脏页写入磁盘(即检查点)。如果在最近的检查点后发生了系统故障,所有脏页的操作需要回滚。 - 系统故障:
可能是硬件(磁盘或内存)问题、宕机或软件故障。
- 未提交事务:
-
如何回滚:
- 通过事务日志(Redo 和 Undo Log):
数据库依赖 Redo 日志 和 Undo 日志 来回滚事务:- Redo 日志:记录对数据的修改操作,用于重放。
- Undo 日志:记录撤销操作,用于回滚。
流程: - 数据库从 Undo 日志中找到需要回滚的操作。
- 回滚对应页面上的更改,使其恢复为之前的状态。
- 每次回滚完成后,更新回滚进度。
- 通过事务日志(Redo 和 Undo Log):
-
影响进度的因素:
- 需要回滚的页数: 页数越多,回滚时间越长。
- I/O 性能: 数据页需要读写磁盘,受限于 I/O 带宽。
- 并发任务: 如果有大量并发操作,回滚可能受到 CPU 和内存资源的限制。
三、如何模拟该故障
-
模拟步骤:
- 环境准备:
搭建达梦数据库实例,准备一个较大的数据库(含大量数据页)。 - 引入长事务:
- 创建一个大事务(比如对大量数据执行插入/更新操作),但不要提交。
- 在事务进行过程中,故意断电、强制杀掉数据库进程,模拟崩溃。
- 触发回滚:
- 重启数据库。
- 数据库在启动时会触发崩溃恢复,并开始回滚未完成的事务。
- 环境准备:
-
可能的故障表现:
- 数据库日志中会看到类似的页面回滚进度日志。
- 数据库可能会因高负载而性能下降,尤其是当页面回滚涉及大量磁盘 I/O 时。
四、优化与解决方法
-
优化回滚性能:
- 合理设置检查点间隔:
- 检查点越频繁,未刷盘的脏页越少,崩溃恢复时需要回滚的页数越少。
- 提升硬件性能:
- 增强磁盘 I/O 性能(如使用 SSD),减少回滚操作的时间。
- 并行回滚:
- 确保数据库配置了多线程或并行回滚机制,以提高效率。
- 合理设置检查点间隔:
-
预防此类问题:
- 事务控制:
- 避免长事务,确保事务及时提交。
- 监控与告警:
- 设置系统监控,捕获异常情况并及时响应。
- 备份和恢复:
- 定期备份数据,崩溃后可通过备份快速恢复。
- 事务控制:
五、总结
日志 total [208076/472861] page rollback percent: 44% 和 total [212805/472861] page rollback percent: 45% 表明数据库正在进行页面回滚操作,回滚未提交的事务修改。这通常是由于系统崩溃或异常关闭导致的事务恢复操作。
通过模拟故障(未提交事务 + 崩溃),可以触发类似的回滚过程。优化方案包括合理配置数据库参数、提高硬件性能、避免长事务等。
回滚时间长短与 Redo 日志大小 并没有直接的关系,但两者之间可能存在 间接联系,具体要视具体数据库的实现逻辑和场景而定。以下是详细的分析:
回滚时间与 Redo 的关系?
一、回滚时间与 Redo 的关系
-
回滚的核心依赖:
回滚主要依赖 Undo 日志(而不是 Redo 日志)。- Undo 日志:记录了每次数据变更的“逆操作”,用于将修改撤销到初始状态。
- Redo 日志:记录事务对数据的所有变更,用于重放数据修改以确保一致性。
回滚操作时:
- 数据库会根据 Undo 日志 找到需要撤销的操作,并将变更还原。
- Redo 日志主要用于 崩溃恢复 和 重做操作,与回滚直接关系较小。
-
间接关系:
回滚时间可能与 Redo 日志大小产生间接联系,具体表现为以下情况:- 长事务导致更多的 Redo 日志写入:
- 如果长事务未提交,它会不断生成 Redo 和 Undo 日志。
- 事务规模越大,涉及的页面越多,Undo 日志也会更大,回滚需要的时间也会更长。
- 恢复过程中涉及 Redo 日志的重做:
- 在崩溃恢复阶段,Redo 日志需要先完成重放,然后才能开始未完成事务的回滚。
- 如果 Redo 日志很大,重做的时间会拖延回滚的开始时间,从整体上延长了恢复时间。
- 长事务导致更多的 Redo 日志写入:
二、影响回滚时间的主要因素
-
需要回滚的事务规模:
- 未提交事务中,涉及的行数或数据页越多,回滚时间越长。
- 大量更新、大量插入、大量删除操作都会增加回滚所需的时间。
-
Undo 日志大小:
- Undo 日志是回滚的核心依据。如果事务涉及的大量变更操作生成了非常大的 Undo 日志,回滚操作需要更长的时间。
-
I/O 性能:
- 回滚操作涉及大量的磁盘读写,特别是需要撤销对磁盘页面的修改时,I/O 性能是瓶颈。
- 如果数据库的磁盘 IOPS(每秒读写操作数)有限,回滚会变得很慢。
-
并发性:
- 数据库支持的并行回滚线程数会影响回滚速度。如果回滚操作是单线程的,时间会显著增加。
-
脏页(Dirty Pages)和检查点:
- 检查点后的未刷盘数据页需要回滚。如果检查点间隔过长,脏页数量多,回滚时间可能会增加。
-
锁争用:
- 在回滚期间,如果有其他事务或操作正在访问相关资源,会导致锁争用,从而延长回滚时间。
三、如何优化回滚时间
-
避免长事务:
- 长事务会生成大量的 Undo 和 Redo 日志,回滚时开销巨大。应尽量拆分长事务,减少单个事务处理的数据量。
-
合理配置检查点:
- 缩短检查点间隔(减少脏页数量),减少需要回滚的页面数。
-
优化硬件性能:
- 使用 SSD 提高 I/O 性能,提升回滚过程中对页面的读写效率。
-
提升回滚并行性:
- 确保数据库配置了多线程回滚机制,例如在达梦数据库中,通过相关参数(如并行回滚线程数)调整。
-
监控和日志管理:
- 定期清理日志文件,避免日志积累过多影响恢复和回滚操作。
四、总结
回滚时间的长短主要取决于 事务规模 和 Undo 日志大小,与 Redo 日志大小 并没有直接关系,但可能因为 Redo 日志在恢复阶段的重放操作间接影响回滚的开始时间。
若 Redo 日志过大,可能意味着事务规模较大或长时间未提交,这也会导致 Undo 日志增长,从而延长回滚时间。因此优化事务的执行、减少长事务和合理管理日志是关键手段。
待 Purge 的事务数(OBJ_NUM)不断增长
在数据库系统中,待 Purge 的事务数(OBJ_NUM)不断增长 通常意味着系统中存在大量未完成的清理任务。这与数据库的 MVCC(多版本并发控制) 机制以及事务和垃圾数据的清理有关。以下是对这个现象的具体解释:
一、待 Purge 的事务数(OBJ_NUM)解释
-
Purge 的概念:
- Purge(清理):
在数据库中,Purge 指的是删除已提交或已回滚事务所遗留的历史版本或无用数据(垃圾数据),从而释放存储空间、减少资源占用。 - MVCC(多版本并发控制):
在 MVCC 模式下,数据库会为每个事务创建数据的多个版本:- 读取事务可以看到符合其隔离级别的历史版本。
- 写入事务则会创建新的数据版本。
- Purge 主要用于删除这些旧版本(快照数据)和无用事务的记录。
- Purge(清理):
-
OBJ_NUM 的含义:
- OBJ_NUM 是数据库中待清理的事务对象或无效版本数量的指标。
当事务提交或回滚后,这些事务的历史版本并不会立即被删除,而是由后台清理线程负责 Purge 操作。
- OBJ_NUM 是数据库中待清理的事务对象或无效版本数量的指标。
-
OBJ_NUM 不断增长的原因:
- 如果数据库后台清理线程无法跟上事务产生的速度,或者清理机制受阻,OBJ_NUM 会不断增长,表明积累了越来越多的待清理事务或数据版本。
二、OBJ_NUM 不断增长的原因分析
-
长时间未提交的事务:
- 未提交的长事务会导致数据库无法清理这些事务对应的数据版本,因为 MVCC 需要保留这些版本以供其他事务读取。
- 导致历史版本被保留的时间过长,增加 Purge 的负担。
-
事务并发量过高:
- 如果有大量高并发的短事务频繁提交,历史版本会快速积累,而 Purge 线程的处理速度无法跟上事务产生的速度,导致待清理对象数增加。
-
Purge 线程性能受限:
- 数据库后台清理线程数量不足或优先级较低,导致 Purge 任务积压。
- 磁盘 I/O 性能瓶颈使得清理操作效率低下。
-
锁争用或死锁:
- 如果清理操作需要获取某些资源的锁,而这些资源被其他事务长时间占用,Purge 任务可能被阻塞。
-
历史版本保留策略:
- 数据库配置了较高的版本保留时间(如长时间保留历史快照以满足业务需求),导致清理周期延长。
- 某些数据库会为支持闪回查询(Flashback Query)或恢复操作而保留更多的历史数据。
-
系统崩溃或重启:
- 崩溃恢复后,未完成的清理任务可能需要重新执行,这也会导致 OBJ_NUM 暂时增长。
三、OBJ_NUM 不断增长的影响
-
存储空间耗尽:
- 随着垃圾数据和无效版本的积累,磁盘空间会逐渐被占满,影响数据库正常运行。
-
查询性能下降:
- 大量历史版本的存在可能导致查询性能下降,因为数据库在查找最新版本时需要遍历更多的版本链。
-
回滚和恢复时间延长:
- 如果事务需要回滚或系统需要崩溃恢复,OBJ_NUM 增长可能导致清理任务堆积,恢复时间大幅延长。
四、如何解决 OBJ_NUM 不断增长的问题
-
优化长事务管理:
- 避免长时间未提交的事务。
- 定期检查是否有异常的长事务运行,并及时终止。
-
增加 Purge 线程:
- 根据数据库配置,增加 Purge 线程的数量或优先级,使其能更快地清理垃圾数据。
- 在达梦数据库中,可以调整相关参数(如后台线程数)以提高清理效率。
-
调整 MVCC 保留策略:
- 缩短历史版本的保留时间。
- 评估闪回查询的实际需求,避免保留过多版本。
-
监控 I/O 性能:
- 优化数据库的磁盘 I/O 性能,确保清理操作不会受限于硬件瓶颈。
- 使用 SSD 提升磁盘读写速度。
-
避免锁争用:
- 优化表和索引的设计,减少锁争用的可能性。
- 分析清理任务中是否存在阻塞,及时排除死锁问题。
-
升级数据库版本:
- 如果数据库版本较旧,可能存在 Purge 机制上的性能问题,建议升级到最新版本以获得更好的清理性能。
五、总结
OBJ_NUM 不断增长 表明数据库中积累了大量待清理的事务或历史版本。这通常与长事务、后台清理线程性能不足、磁盘 I/O 瓶颈等因素相关。
优化方案包括合理管理长事务、增加 Purge 线程、缩短版本保留时间等,同时需要针对数据库性能瓶颈进行针对性调整。
如需进一步细化问题定位和解决,可以提供具体的数据库配置参数或性能指标,我可以为您提供更有针对性的建议!
模拟故障
达梦数据库(DMDB)提供了一些工具和方法来模拟和测试重做日志的生成和恢复过程。以下是一些可以用来模拟重做日志生成的步骤和工具:
-
使用BenchmarkSQL进行测试:BenchmarkSQL是一个用于数据库性能测试的工具,它可以模拟大量的事务操作,包括增删改等,从而生成重做日志。你可以通过运行BenchmarkSQL脚本来创建测试数据和执行事务操作。
-
使用达梦数据库的日志管理功能:达梦数据库提供了日志管理功能,你可以通过SQL命令来查看和管理重做日志文件。例如,使用
ALTER DATABASE ADD LOGFILE命令来添加新的重做日志文件,或者使用SELECT * FROM V$RLOG;来查看当前的重做日志信息。 -
模拟故障和恢复:在测试环境中,你可以通过模拟数据库故障(如突然关闭数据库服务或模拟数据文件损坏)来触发重做日志的恢复过程。然后,通过重启数据库并应用重做日志来恢复数据。
-
使用达梦数据库的重做日志文件:达梦数据库的重做日志文件以
.log为扩展名,记录了所有对数据库的修改操作。你可以通过分析这些日志文件来了解在故障发生前系统做了哪些动作,并可以重做这些动作使系统恢复到故障之前的状态。 -
查看和管理重做日志:达梦数据库提供了视图
V$RLOG和V$RLOGFILE来查看重做日志的总体信息和日志文件的详细信息。这些视图可以帮助你了解重做日志的状态,包括当前日志的检查点LSN、文件LSN等。
请注意,模拟重做日志的生成和恢复过程可能会对数据库性能产生影响,因此在生产环境中进行这些操作之前,确保你已经做好了充分的备份和准备。同时,建议在测试环境中进行这些操作,以避免对实际数据造成影响。
检查点(checkpoint)操作的详细信息
这段日志记录了达梦数据库(DMDB)的检查点(checkpoint)操作的详细信息。检查点是数据库系统中的一个过程,用于确保数据库的一致性,并将内存中的更改刷新到磁盘上。以下是对日志中关键信息的分析:
-
日志时间戳:
2025-01-08 14:08:12.495表示日志记录的时间。
-
日志级别:
[INFO]表示这是信息级别的日志,用于记录正常操作的详细信息。
-
数据库标识:
database P0000000225表示这是数据库实例的标识。
-
事务标识:
T0000000000000000349表示这是事务的标识。
-
检查点日志调整信息:
ckpt2_log_adjust:后面跟着的是检查点相关的一系列参数:ckpt_lsn(79937055):检查点的日志序列号。ckpt_fil(0):检查点所在的日志文件编号。ckpt_off(110931968):检查点在日志文件中的偏移量。cur_lsn(83354367):当前的日志序列号。l_next_seq(16782):下一个日志序列号。g_next_seq(16782):全局下一个日志序列号。cur_free(210587648):当前可用空间。total_space(536862720):总空间。used_space(99655680):已使用空间。free_space(437207040):剩余空间。n_ep(1):扩展页的数量。db_open_id(4):数据库打开的标识。
-
检查点结束信息:
checkpoint end, 3224 pages flushed:检查点操作结束,共有3224页被刷新到磁盘。used_space[99655680]:检查点结束后的已使用空间。free_space[437207040]:检查点结束后的剩余空间。
结论
日志显示达梦数据库成功完成了检查点操作,这包括将内存中的更改刷新到磁盘上,以确保数据的持久性和一致性。检查点操作结束后,数据库的已使用空间和剩余空间被更新,这有助于监控数据库的存储使用情况。
建议
- 定期监控数据库的存储使用情况,确保有足够的空间来处理数据增长。
- 检查点操作是数据库维护的重要组成部分,应确保其正常运行。
- 如果发现空间使用增长过快,可能需要考虑优化数据库的存储使用或增加存储资源。
磁盘I/O性能和CPU性能。下面是对这些数据的分析:
磁盘I/O性能
- Device:
sdk表示正在监控的磁盘设备。 - tps: 每秒传输次数(Transfers Per Second),这里是 1668.00,表示每秒磁盘有 1668 次读写操作。
- kB_read/s: 每秒读的千字节数,这里是 32552.00 KB/s,表示磁盘每秒读取 32552 KB 的数据。
- kB_wrtn/s: 每秒写的千字节数,这里是 2456.00 KB/s,表示磁盘每秒写入 2456 KB 的数据。
- kB_dscd/s: 每秒丢弃的千字节数,这里是 0.00 KB/s,表示没有数据被丢弃。
- kB_read: 读取的总千字节数,这里是 32552 KB。
- kB_wrtn: 写入的总千字节数,这里是 2456 KB。
- kB_dscd: 丢弃的总千字节数,这里是 0 KB。
磁盘的读操作明显多于写操作,这可能表明系统正在进行大量的数据读取,可能是数据库查询或其他读密集型操作。磁盘没有数据丢弃,这通常是一个好迹象,表明磁盘没有出现严重的过载。
CPU性能
- suser: 用户空间占用的CPU时间百分比,这里是 5.78%。
- snice: 调整过优先级的用户进程占用的CPU时间百分比,这里是 0.00%。
- ssysten: 系统空间占用的CPU时间百分比,这里是 1.67%。
- siowait: CPU等待I/O操作完成的时间百分比,这里是 0.27%。
- ssteal: 虚拟机偷取的CPU时间百分比,这里是 0.00%,这在物理机上通常为0。
- sidle: CPU空闲时间百分比,这里是 92.27%。
CPU的使用率相对较低,大部分时间处于空闲状态(92.27%)。用户空间和系统空间的CPU使用率都很低,这表明CPU资源非常充足,没有过载的迹象。等待I/O操作的时间也非常短,这进一步表明磁盘I/O操作并没有成为系统的瓶颈。
总体来看,这个系统在磁盘I/O和CPU方面都表现得相当轻松,没有明显的性能瓶颈。如果这是在高负载情况下的读数,那么系统可能还有提升性能的空间。如果这是在低负载情况下的读数,那么系统的性能表现是正常的。
模拟语句
DROP PROCEDURE batch_insert;
DROP TABLE test_table;
CREATE TABLE test_table (
id INT ,
name VARCHAR(50),
value INT,
insert_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP -- 新增列,自动记录插入时间
);
ALTER TABLE test_table ADD insert_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP;
CREATE PROCEDURE batch_insert(v_count IN NUMBER)
AS
BEGIN
FOR i IN 1..v_count LOOP -- 使用传入的参数v_count作为循环次数
INSERT INTO test_table (id, name, value) VALUES (i, 'Test' || TO_CHAR(i), i * 10);
END LOOP;
COMMIT; -- 循环结束后提交事务
END;
START TRANSACTION;
CALL batch_insert(1);
CALL batch_insert(10000000);
SELECT * FROM test_table;
/opt/dmdbms/bin/disql ADMIN1/\"xxxx\"@10.10.1x.12:3x
SELECT SESS_ID,SQL_TEXT,STATE,CREATE_TIME,CLNT_HOST FROM V$SESSIONS;
SELECT * FROM V$RLOG;
SELECT * FROM V$RLOGFILE;
SELECT
(RLOG_SIZE / 1024 / 1024 ) AS SIZE_MB
FROM
V$RLOGFILE;
select * from dba_data_files where tablespace_name='ROLL';
select * from v$purge;
SELECT * FROM V$ARCH_STATUS;
SELECT * FROM SYSOBJECTS WHERE NAME LIKE '%ARCH%';
SELECT * FROM dba_tables WHERE TABLE_NAME LIKE '%ARCH%';
SELECT * FROM ALL_ALL_TABLES;
select * from V$RAPPLY_STAT;
CREATE PROCEDURE batch_delete(v_count IN NUMBER)
AS
v_max_id NUMBER;
BEGIN
-- 首先查询出要删除的最大id值
SELECT MAX(id) INTO v_max_id FROM test_table;
-- 如果表中没有数据,则直接退出存储过程
IF v_max_id IS NULL THEN
DBMS_OUTPUT.PUT_LINE('No records to delete.');
RETURN;
END IF;
-- 从最大id开始向前删除,以减少锁竞争
FOR i IN REVERSE 1..v_count LOOP
DELETE FROM test_table WHERE id = v_max_id - i;
END LOOP;
-- 如果需要,可以在这里提交事务
-- COMMIT;
END;
START TRANSACTION;
CALL batch_delete(10000);

















 1764
1764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









