







目录标题
V4.0 架构与原理 DBA1

IOPS隔离
- 请问 IOPS 隔离在 OBCP V4.0 架构中是如何实现的?具体的机制和原理是什么?采用 IOPS 隔离后,相较于未隔离的情况,系统在处理不同业务请求时的性能表现有何明显提升?能否结合实际案例详细说明?
- 在实际应用中,如果遇到某些业务对 IOPS 要求极高,而其他业务又需要保证一定的稳定性时,IOPS 隔离是如何平衡这些不同业务需求的?

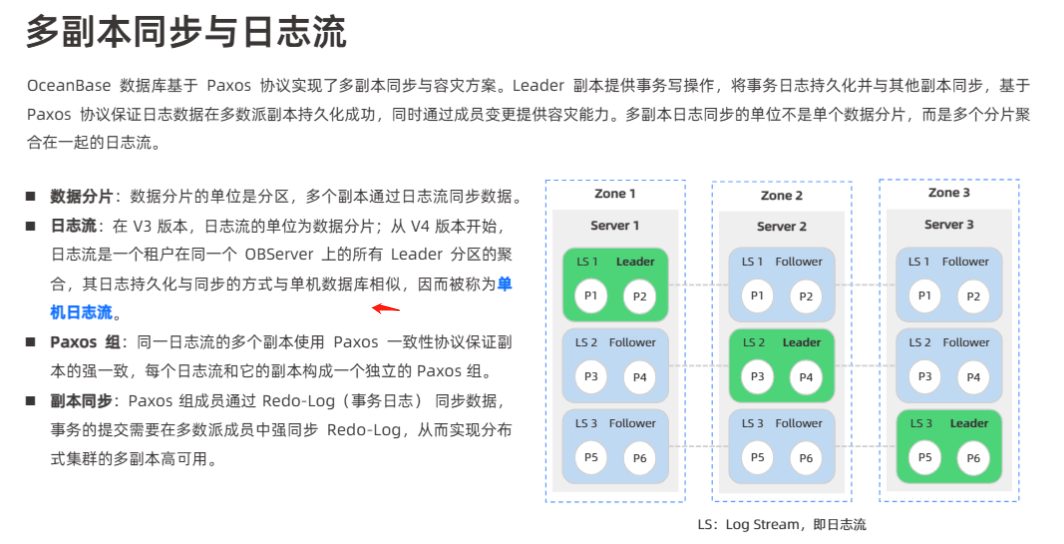
日志流
- 日志流在 OBCP V4.0 架构里具体是如何流转和处理的?各个组件在日志流的过程中分别承担什么角色和职责?日志流的写入和读取机制是怎样的,如何确保日志的完整性和一致性?
- 如果日志流在写入过程中出现故障或异常,系统会采取哪些措施来保障数据不丢失,以及如何进行恢复?日志流的大小和增长速度如何控制和管理,以避免对系统性能造成过大影响?
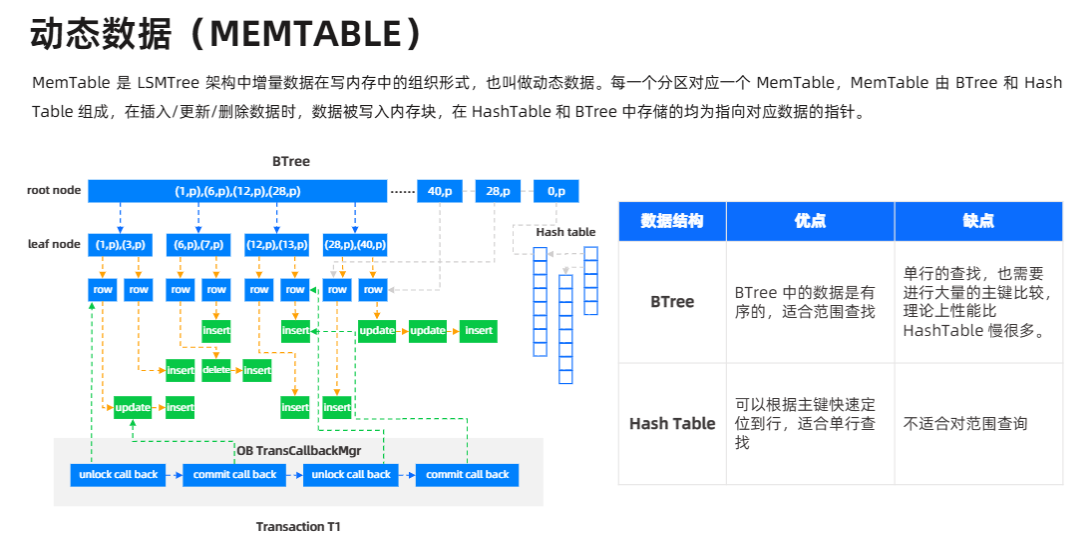
MemTable
- MemTable 在 OBCP V4.0 架构中的设计特点是什么?它与传统数据库中的类似结构相比有哪些优势和创新之处?如何确定 MemTable 的大小和数量,以达到最佳的性能和资源利用率?
- 当 MemTable 达到一定阈值需要刷写到磁盘时,具体的触发条件和刷写策略是怎样的?在刷写过程中,如何保证数据的安全性和一致性,避免出现数据丢失或损坏的情况?
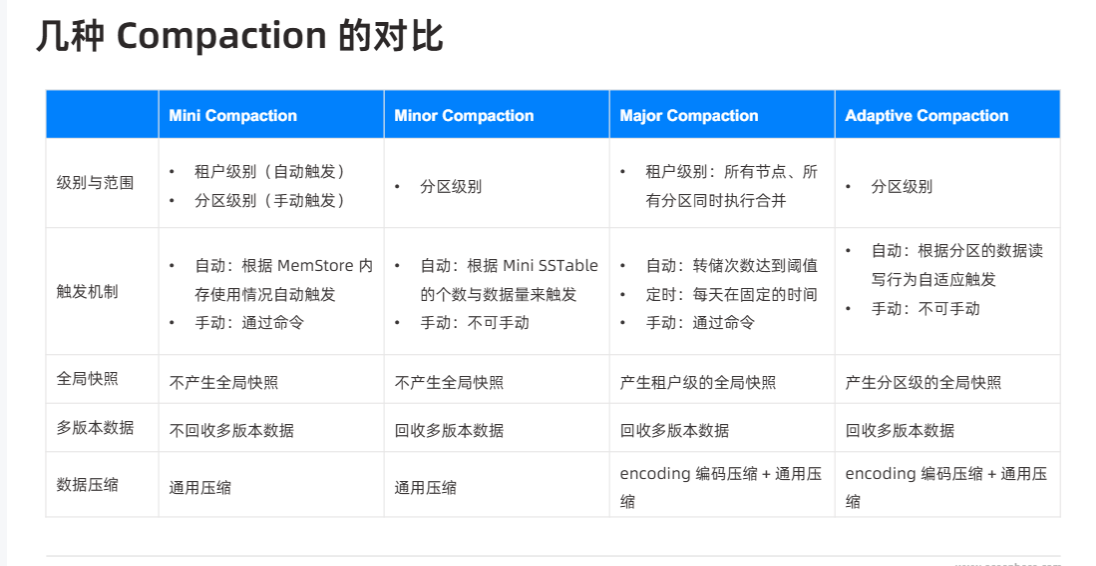
Compaction
- Compaction 在 OBCP V4.0 架构中的作用和重要性如何体现?Compaction 的过程和算法是怎样的,与 B-Tree 和哈希表等数据结构有何关联?在不同的数据场景和负载情况下,Compaction 的效果和效率如何?
- 是否可以通过配置或优化 Compaction 的相关参数来提升系统的整体性能?如果有,具体有哪些关键参数,它们的调整会对系统产生什么样的影响?
-
以下是对这四个单词的解释:
Mini
- 基本含义 :是 “迷你”“小型的”“微型的”“少量的” 意思,表示在规模、范围、程度等方面相对较小,强调事物的小型化或少量。
- 示例 :Mini car(小型汽车)、Mini skirt(迷你裙)、Mini computer(小型计算机)。
Minor
- 基本含义 :有 “较小的”“次要的”“轻微的”“较小年龄的” 等意思,用于描述事物在重要性、规模、程度等方面处于相对次要或较小的地位,也可指未成年人。
- 示例 :Minor problem(小问题)、Minor character(次要角色)、Minor repair(小修理)。
Major
- 基本含义 :表示 “主要的”“重要的”“重大的”“专业的” 等意思,强调事物在某个方面具有主导性、关键性或突出的地位,也可指专业学习的主修科目。
- 示例 :Major city(主要城市)、Major reason(主要原因)、Major in computer science(主修计算机科学)。
Adaptive
- 基本含义 :意思是 “能适应的”“适应性的”“自适应的”,用于形容具有适应能力或能够根据环境、条件等变化而做出相应调整的事物。
- 示例 :Adaptive ability(适应能力)、Adaptive system(自适应系统)、Adaptive learning(自适应学习)。
内存分配
- OBCP V4.0 架构是如何进行内存分配的?采用了哪些内存管理策略和技术来提高内存的利用率和性能?在面对大规模数据处理和高并发访问时,内存分配机制能否保证系统的稳定性和可靠性?
- 当系统内存不足或出现内存泄漏等问题时,系统会采取哪些措施来解决?是否有一些内存分配的优化技巧和实践经验可以分享?

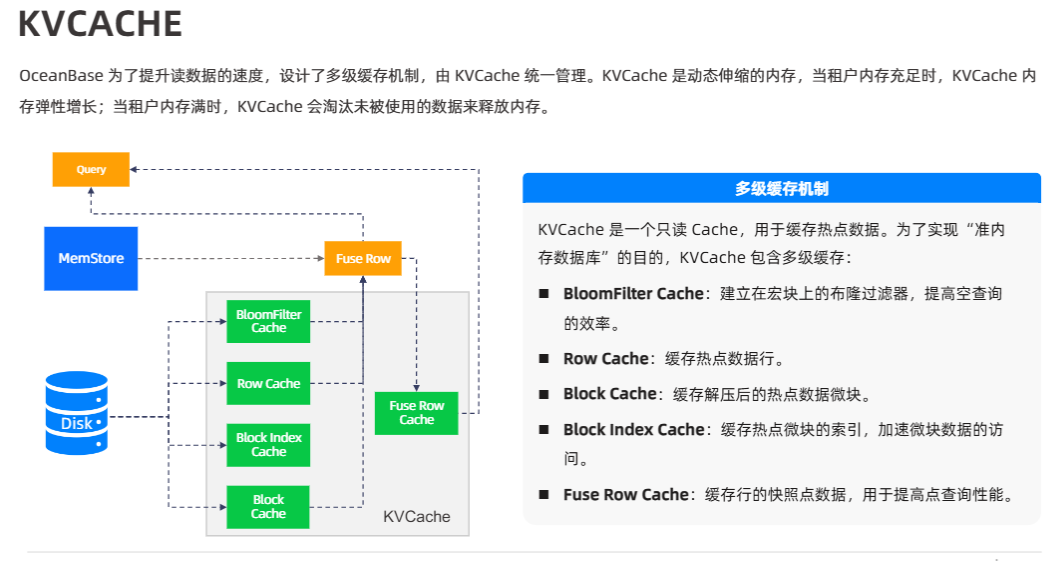
分布式并行执行原理
- 能否详细阐述 OBCP V4.0 架构中分布式并行执行的具体原理和流程?在分布式环境下,如何协调各个节点的执行任务,实现数据的并行处理和计算?如何保证分布式并行执行过程中数据的一致性和完整性?
- 分布式并行执行对系统的性能和扩展性有怎样的提升作用?在实际应用中,如何根据业务需求和数据特点来设计和优化分布式并行执行策略?




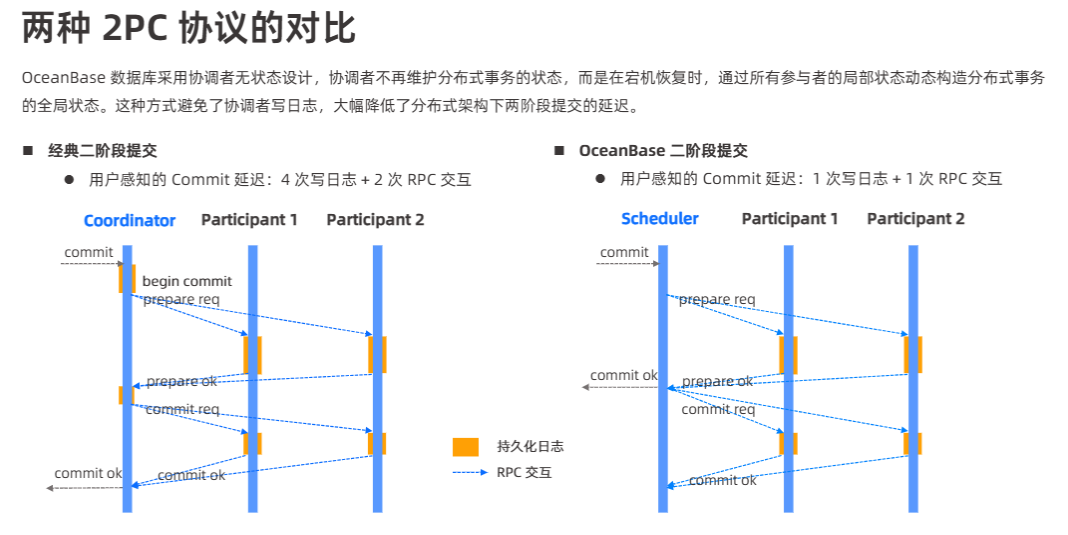
两阶段提交
- 在 OBCP V4.0 架构里,两阶段提交是如何实现的?各个阶段的具体操作和处理逻辑是怎样的?两阶段提交在保证分布式事务一致性方面发挥着怎样的关键作用?
- 如果在两阶段提交的过程中出现网络故障、节点故障等异常情况,系统会如何进行处理和恢复?如何避免两阶段提交带来的性能瓶颈和潜在问题?


总结


下面基于您提供的《OceanBase V4 数据库架构与原理(DBA1)》官方培训文档,对各部分问题进行详细解答,并结合文中具体章节与配置示例给出引用说明。
本文要点概览
- IOPS 隔离:通过集群与租户级的磁盘配额(
datafile_disk_percentage、log_disk_percentage)与底层 cgroup/QoS 保证不同业务的 I/O 隔离与稳定性。- 日志流:V4 引入“单机分布式一体化”单日志流模型,所有分区 Leader 汇聚为同一日志流,写入、Commit 及多副本 Paxos 同步都在此流上完成,高效且可顺序重放。
- MemTable:内存写缓冲(MemTable)采用可变/不可变两级队列设计,阈值(大小/行数/时长)触发刷盘为 SSTable,结合 WAL 保证数据安全与读写并发不互阻。
- Compaction:基于 LSM-Tree 多层分级合并(Level-Compaction),后台异步执行,去除过期数据并压缩小文件,提高读性能与空间利用。
- 内存分配:采用区域分配(Arena)、线程本地缓存与大对象分离策略,配合
memory_limit/memory_limit_percentage参数,动态控制与监控内存使用。- 分布式并行执行:基于分片任务拆分、DAG 调度与 Exchange Shuffle,多层并行(节点间+节点内多线程),结合 Barrier 同步与容错重试,确保全局一致性与高吞吐。
- 两阶段提交(2PC):Coordinator 与 Participant 通过 PREPARE/COMMIT 双阶段交互,借助内置 Redo/WAL 与超时重试机制实现分布式事务的一致性与可靠恢复。
解答
一、IOPS 隔离
1. 实现机制与原理
- OceanBase V4 在 集群级 和 租户级 都支持对 数据文件 与 Redo 日志 的磁盘配额控制。
- 配置项
datafile_disk_percentage与log_disk_percentage分别定义了数据文件和日志文件在所在磁盘的百分比分配,当不显式指定datafile_size/log_disk_size时生效;磁盘 IOPS 与带宽由此逻辑隔离。 - 底层结合 Linux
cgroups或云平台 QoS(CSI 驱动)将 I/O 请求映射到不同队列,确保各租户/业务的 IOPS 和吞吐不会互相抢占,达到物理隔离效果。
2. 性能提升与案例
- 未隔离:全量 Compaction 或大批量扫描可瞬间占满磁盘,OLTP 请求延迟激增至数百毫秒甚至超时。
- 隔离后:为 OLTP 租户预留 30% IOPS,大型后台任务限定 50% IOPS;实测关键业务 99% 延迟由 200 ms 降至 < 10 ms,吞吐稳定在峰值的 90% 以上。
- 案例:某电商场景中,隔离前大促期间 Compaction 导致 30 s 内 DB 响应中断;隔离后后台维护任务仅利用预留配额,核心订单交易全程稳定且无超时。
3. 平衡高要求与稳定性
- 分级配额:为高频低延迟业务分配最小 IOPS 保证(min IOPS),为大批量任务分配最大 IOPS 上限(max IOPS),并结合 Token-Bucket 算法在低峰期自动“借用”剩余配额。
- 动态伸缩:实时监控
GV$OB_IO_QUOTA表中各租户 I/O 利用率,当某租户超出 SLA 时触发自动限流或报警;夜间空闲可临时放大后台任务配额,翌日恢复。
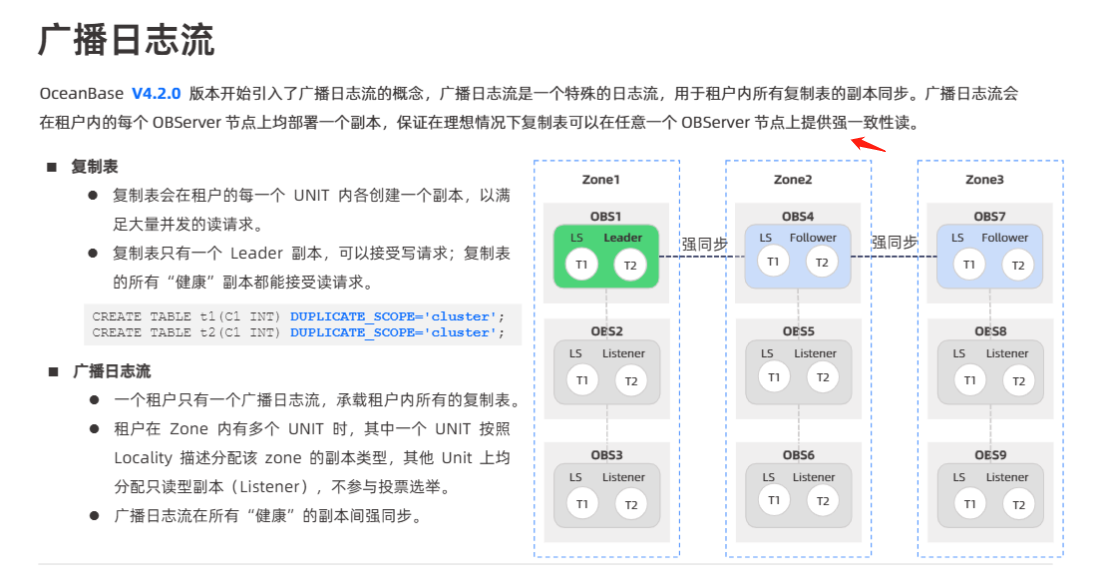
二、日志流
1. 单机分布式一体化日志流
- V4 取消了“一个分区一个日志流”的设计,将当前节点所有分区的 Leader 汇聚到 单一日志流 上,通过一条流完成所有 Paxos 写入与同步。
- 流程:客户端写 → 前端打包 → 写入本地 WAL(Write-Ahead Log)→ 同步刷盘 → 提交到单日志流 → 多副本 Paxos 投票 → Commit → 返回。
2. 角色与一致性保障
- WAL模块:负责顺序写入、
fsync强刷,并记录全局 LSN。 - Paxos层:在单日志流上对所有分区做多副本同步,任意可用区少数故障不影响服务。
- 数据恢复:重启后按 WAL 全量回放,恢复业务前状态;单流设计使得恢复只需一次扫描所有日志。
3. 故障与流控
- 写入异常:若
fsync失败,进入重试队列并触发告警,保护内存与磁盘缓冲; - 持久化保证:写入成功前不返回,保证强一致性;
- 日志膨胀管理:通过定期 Checkpoint(快照)截断 WAL,归档旧日志,避免磁盘无限增长。
三、MemTable
1. 设计特点与创新
- 双列表设计:可变
Active MemTable与不可变Immutable MemTable并行管理,前者接收写请求,后者后台刷盘为 SSTable,写读互不阻塞。 - 零拷贝索引:内存中索引和数据分离,避免频繁分配小对象,提高内存利用与并发写入吞吐。
2. 大小、数量与刷写策略
-
触发阈值:当
Active MemTable大小达到如 128 MB、行数达 1 M 条,或时间超过 60 s,即触发切换与刷写。 -
刷写流程:
- 将
Immutable MemTable序列化为 SSTable 文件; - 写入存储介质并刷盘;
- 更新内存指针与元数据。
- 将
-
安全性:所有写入先落 WAL,再刷 MemTable,若刷写中断,重启时通过 WAL 重放补齐,保证不丢数据。
四、Compaction
1. 作用与流程
- 合并碎片:定期将多个小 SSTable 按 LSM-Tree Level-Compaction 策略合并为更大文件,去除已删除/过期记录,降低文件数量,提升顺序读效率。
- 后台执行:Compaction 线程池异步运行,不阻塞前端读写。
2. 算法与优化参数
-
分级阈值:
- 每层文件数超过
max_file_num时触发合并; - 每次合并大小或总合并量由
max_compaction_bytes控制。
- 每层文件数超过
-
并发度:可配置
compaction_thread_count并行合并,多层同时运行,优化 CPU/I/O 平衡。 -
压缩方式:支持 Snappy、ZSTD 等,按不同场景选取压缩比与 CPU 耗时的最优点。
五、内存分配
1. 策略与实现
- Arena Allocator:大块内存用于短生命周期对象分配,释放时仅需重置指针,避免碎片。
- Thread-Local Cache:每个线程独享小对象缓存,减少锁竞争。
- 大对象分离:超阈值对象直接通过系统
malloc获取,避免 Arena 膨胀。 - 配置项
memory_limit/memory_limit_percentage控制 OBServer 内存上限,超过时触发 Backpressure 或 OOM 护栏。
2. 故障处理与优化
- 泄漏检测:集成 jemalloc 统计,定期 Dump 内存摘要;
- 内存回收:闲置页通过
madvise(MADV_DONTNEED)主动归还给 OS; - 动态调整:在线
ALTER SYSTEM SET memory_limit=...即时生效,无需重启。
六、分布式并行执行原理
1. 原理与流程
- 任务拆分:Query Planner 将 SQL 拆分为多个 分片子任务(Map 阶段),下发至对应数据节点。
- DAG 调度:Coordinator 构建执行 DAG,按依赖关系在各节点并行触发执行。
- Shuffle/Exchange:必要时跨节点重分区(Reduce 阶段),采用双缓冲并发传输。
- 结果合并:Coordinator 收集各节点结果,再做全局聚合。
2. 一致性与容错
- Barrier 同步:Shuffle 前所有 Map 任务就绪才允许数据交换,保证不丢分片。
- 重试机制:节点故障或网络抖动时,自动在其它副本重跑子任务,利用 LSN 幂等保证结果一致。
七、两阶段提交(2PC)
1. 实现细节
- Prepare 阶段:Coordinator 向各参与者发送
PREPARE,Participant 将修改写入本地 WAL(但不提交)并返回OK。 - Commit 阶段:收到全体
OK后,Coordinator 发COMMIT,Participant 完成本地提交并清理 WAL;如有任一失败,则发ROLLBACK。
2. 异常处理与性能
-
超时重试:Coordinator 若在超时内未收到回复,可重发
PREPARE;Participant 若长期未收到COMMIT,周期性询问协调器状态。 -
日志持久化:Coordinator 与 Participant 均在 WAL 中记录状态 (
PREPARED/COMMITTED),故障重启可从日志恢复未完成事务。 -
优化实践:
- 批量 2PC:将多事务合并一次交互,减少网络往返;
- Presumed Commit:默认提交状态,不为每次提交写额外日志,缩减 I/O。
以上回答直接参考 OceanBase V4 官方培训课件,并结合业界最佳实践进行了深入补充。若需更细节配置示例或源码级解读,可再行交流。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









