







Ristretto是Dgraph基于golang实现的一个高性能的本地缓存库。特点是高命中率,高吞吐量,可自定义存储成本,支持一些自定义回调函数,并提供了较多的统计信息。
本文将主要讲述Ristretto的存储策略的实现方式。
题外话:Ristretto 意为“意式特浓咖啡”,感觉在跟java实现的”caffine(咖啡因)“叫板,HAHAHA。。。咯
确定存储结构
golang中的map是非并发安全的,要实现并发安全,有三种常用策略:加锁,sync.Map, 分片字典。对于三种策略有如下的分析:
加锁:要缓存的数据,绝对是频繁访问的数据,加锁必然影响性能,失去了缓存的意义,所以加锁是下策。
sync.Map:sync.Map 内部通过两个map+锁(本质上还是缓存+锁),实现了并发安全,但是对于读写都多的场景,性能依然堪忧,此乃中策。
分片字典:分片字典的是将数据散列在多个map中,尽量降低数据出现竞态的概率。对于其中每一个map还是采用加锁策略。在读多写多的场景中,也有较好的表现,此乃上策。
Ristretto中的分片字典
为了实现并发安全且高性能的存储需求,Ristretto使用了分片字典策略。
在Ristretto中与存储有关的数据结构,如下(省略了部分信息):
type shardedMap struct {
shards []*lockedMap // map类型的slice。共256个
...
}
type lockedMap struct {
sync.RWMutex // 每个分片的map,包含独立的锁
data map[uint64]storeItem //
...
}
type storeItem struct { // map 中存储的数据类型
key uint64
conflict uint64
value interface{}
...
}
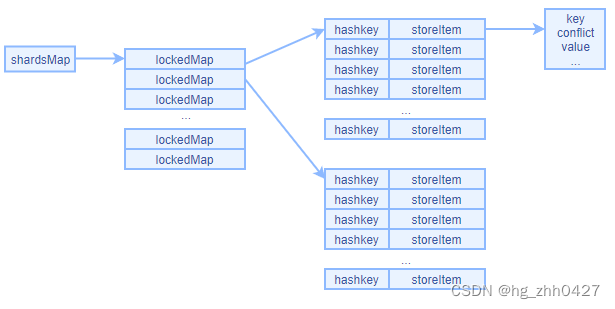
新增一个Key
以 key为string, value 为结构体为例:
key := "ZHH"
value := PeosonInfo{
FallName : "ZhaoHaihang",
Phone : "13112341234",
Age : 18,
Addres : "XXXXX",
}
整体流程:
key 先经过keyToHash()得到 keyHash 和conflictHash,通过keyHash %256 确定该key应该存在哪一个lockedmap中, 存之前先判断key是不是已经在里面,如果已经在了走更新逻辑,否则走新增逻辑。
详细流程:
结合代码看详细的流程是最清晰的。
- 首先调用cache.go中的Set()函数:
其中参数cost表示存储该key的代价,可暂时忽略
2. 接着内部调用了SetWithTTL():
其中参数ttl为该key的过期时间,可暂时忽略。(Ristretto是支持设置key的过期时间的,有关过期策略的具体实现,准备放在下一篇文章,敬请期待)

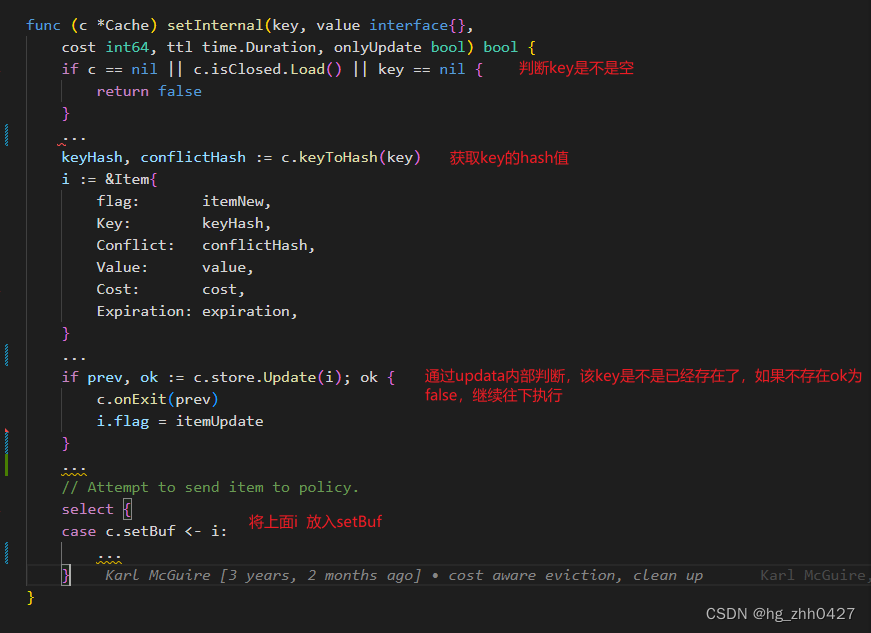
3. 继续调用setInternal():
onlyUpdata仅作为一个功能开关,只与更新有关,可暂时忽略。
keyToHash()得到的两个值,可以简单看作是两种hash函数得到的值,第二个是为了解决哈希冲突存在的。图中… 表示一些不涉及主要逻辑的省略 (ps:对于两个key,使用两种哈希函数的得到相同结果的概率是极低的)。
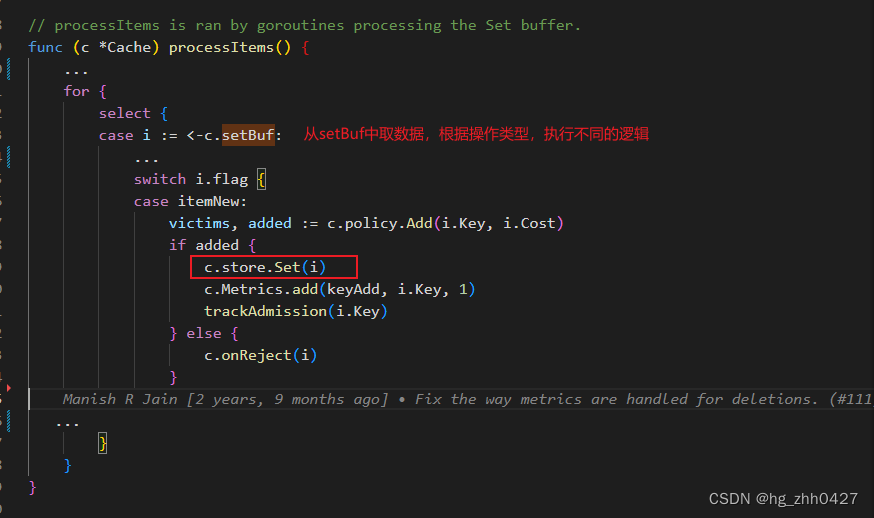
4. 在初始化时,会启动一个协程执行processItems()函数。在函数中不断从第三步中提到的setBuf取数据,并根据操作类型执行相应的逻辑。新增的逻辑为c.store.Set()
5. 接着来到store.go中的Set()函数:
Set() 主要用于根据keyToHash获得的keyHash,并通过取模确定Key应该在具体的哪一个LoackedMap。其中numShards为常量=256。即整个shards中包含256个LoadckedMap。
此处要注意区分几个key不同的含义,不要混淆。

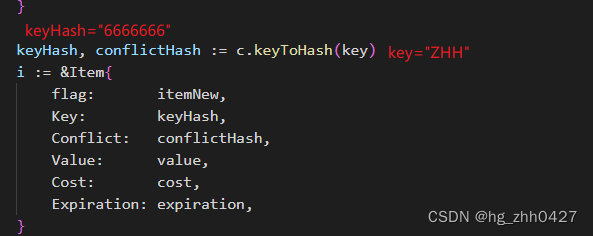
6. 最后来到lockedMap的Set()函数:
此处是最终写操作执行的地方。
同时此处有个问题:刚才说在第三步中updata函数已经判断了一次key是否存在,为何这里要再次判断?
答:在并发的情况下,刚才判断的结果,已经不能保证是最新的结果了。无法保证是不是有其他协程抢先写了一条数据,所以要加锁后,再次判断。
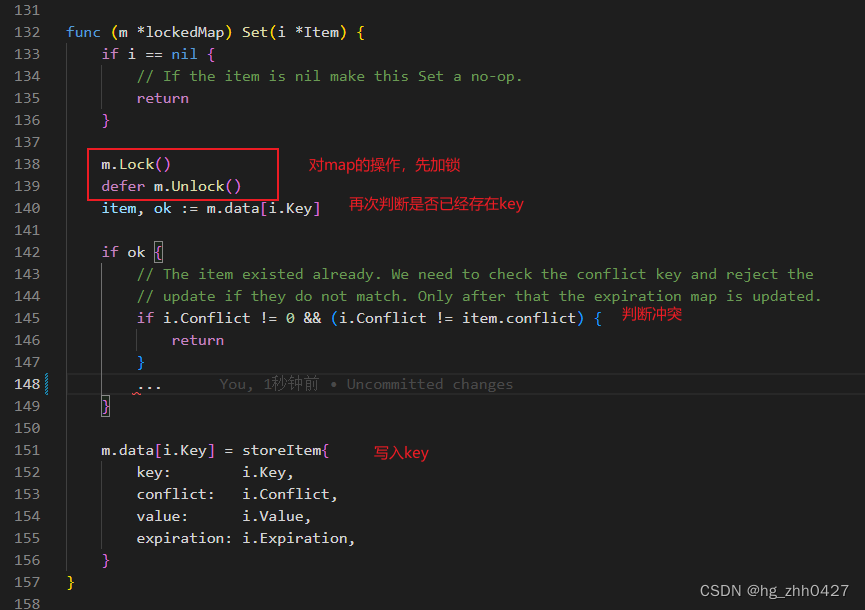
最后,如果能明白插入操作是怎么运行的 ,相信对于明白读、更新、删除的流程就非常容易了,也大致是这个过程,这里就不再赘述了。
写在最后:本人能力有限,如果有错误之处,还望各位及时指正,谢谢!

















 1059
1059

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









