为什么TCP 会粘包
前几天,调试mina的TCP通信, 第一个协议包解析正常,第二个数据包不完整。为什么会这样吗,我们用mina这样通信框架,还会出现这种问题? 带者问题,我们先分析一下问题。
提到通信, 我们面临都通信协议,数据协议的选择。 通信协议我们可选择TCP/UDP:
- TCP(transport control protocol,传输控制协议)是面向连接的,面向流的,提供高可靠性服务。收发两端(客户端和服务器端)都要有一一成对的socket,因此,发送端为了将多个发往接收端的包,更有效的发到对方,使用了优化方法(Nagle算法),将多次间隔较小且数据量小的数据,合并成一个大的数据块,然后进行封包。这样,接收端,就难于分辨出来了,必须提供科学的拆包机制。 即面向流的通信是无消息保护边界的。
- UDP(user datagram protocol,用户数据报协议)是无连接的,面向消息的,提供高效率服务。不会使用块的合并优化算法,, 由于UDP支持的是一对多的模式,所以接收端的skbuff(套接字缓冲区)采用了链式结构来记录每一个到达的UDP包,在每个UDP包中就有了消息头(消息来源地址,端口等信息),这样,对于接收端来说,就容易进行区分处理了。 即面向消息的通信是有消息保护边界的。
由于TCP无消息保护边界, 需要在消息接收端处理消息边界问题。也就是为什么我们以前使用UDP没有此问题。 反而使用TCP后,出现少包的现象。
粘包的分析
上面说了原理,但可能有人使用TCP通信会出现多包/少包,而一些人不会。那么我们具体分析一下,少包,多包的情况。
- 正常情况,发送及时每消息发送,接收也不繁忙,及时处理掉消息。像UDP一样.
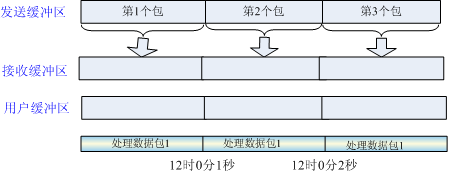
- 发送粘包,多次间隔较小且数据量小的数据,合并成一个大的数据块,然后进行封包. 这种情况和客户端处理繁忙,接收缓存区积压,用户一次从接收缓存区多个数据包的接收端处理一样。
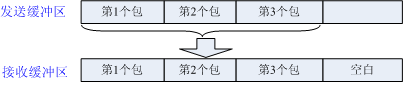
- 发送粘包或接收缓存区积压,但用户缓冲区大于接收缓存区数据包总大小。此时需要考虑处理一次处理多数据包的情况,但每个数据包都是完整的。
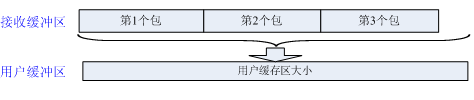
- 发送粘包或接收缓存区积压, 用户缓存区是数据包大小的整数倍。 此时需要考虑处理一次处理多数据包的情况,但每个数据包都是完整的。
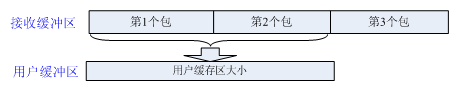
- 发送粘包或接收缓存区积压, 用户缓存区不是数据包大小的整数倍。 此时需要考虑处理一次处理多数据包的情况,同时也需要考虑数据包不完整。
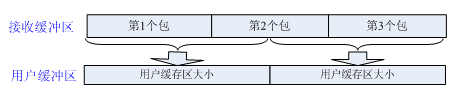
我们的情况就属于最后一种,发生了数据包不完整的情况。
啰嗦了这么多,总结 一下, 就两种情况下会发生粘包。
- 发送端需要等缓冲区满才发送出去,造成粘包
- 接收方不及时接收缓冲区的包,造成多个包接收
如何应对
先卖个关子, 不是所有的粘包都需要处理。 我们先列举一下,免得在编码过程中,因为知道了粘包的情况下,都处理粘包。
- 连续的数据流不需要处理。如一个在线视频,它是一个连续不断的流, 不需要考虑分包。
- 每发一个消息,建一次连接的情况。
- 发送端使用了TCP强制数据立即传送的操作指令push。
- UDP, 前面已说明白了。在这在强调一下,UDP不需要处理,免的忘记了。
- 如果用socket编写编程的话, 我就不多说我, 可参考下面的资料:
- Grizzly: http://grizzly.java.net/nonav/docs/docbkx2.0/html/coreframework-samples.html User Guide 第二章的样例:解析收到的消息。
- xSocket:http://xsocket.sourceforge.net/core/tutorial/V2/TutorialCore.htm 第 18 节。
- Netty: http://netty.io/docs/3.2.6.Final/api/org/jboss/netty/handler/codec/frame/FrameDecoder.html FrameDecoder 的 API 文档。Netty 抽象了一个“消息桢解码器”的类来处理这些。
- Mina 2:http://mina.apache.org/chapter-11-codec-filter.html
- Mina 2:如果En文不好的话, 可参考http://freemart.iteye.com/blog/836654。 它在判断包是否完整时,有个小缺陷,它没使用IOBuffer的prefixedDataAvailable。但注释写的比较好。
把官网上的代码,也在这展示一下。
public class ImageResponseDecoder extends CumulativeProtocolDecoder {
/**
* 返回值的解释:
* 1、false, 继续接收下一批数据,有两种情形,如缓冲区数据刚刚就是一个完整消息,或不够一条消息时。如果不够一条消息,那么会将下一批数据和剩余消息进行合并
* 2、true, 当缓冲区的消息多于一条消息时,剩余消息会再会推送至doDecode
*/
protected boolean doDecode(IoSession session, IoBuffer in, ProtocolDecoderOutput out)throws Exception {
//发送数据时,头四个字节记录了消息的长度。 此方法会读四个字节,并和实现流长度对比。返回前,将流reset.
if (in.prefixedDataAvailable(4)) {
int length = in.getInt();
byte [] bytes = newbyte[length];
in.get(bytes);
ByteArrayInputStream bais =new ByteArrayInputStream(bytes);
BufferedImage image = ImageIO.read(bais);
out.write(image);
return true;//如果读取内容后还粘了包,系统会自动处理。
}else{
returnfalse;//继续接收数据,以待数据完整
}
}
}
- 再总结一下处理流程: 就发送数据时,包开始写入消息长度n, 当接收到的缓存区数据m,各处理流程如下:
- 1)若n<m,则表明数据流包含多包数据,从其头部截取n个字节存入临时缓冲区,剩余部分数据依此继续循环处理,直至结束。或n>m
- 2)若n=m,则表明数据流内容恰好是一完整结构数据,直接将其存入临时缓冲区即可。
- 3)若n >m,则表明数据流内容尚不够构成一完整结构数据,需留待与下一包数据合并后再行处理。
参考
一般所谓的TCP粘包是在一次接收数据不能完全地体现一个完整的消息数据。TCP通讯为何存在粘包呢?主要原因是TCP是以流的方式来处理数据,再加上网络上MTU的往往小于在应用处理的消息数据,所以就会引发一次接收的数据无法满足消息的需要,导致粘包的存在。处理粘包的唯一方法就是制定应用层的数据通讯协议,通过协议来规范现有接收的数据是否满足消息数据的需要。在应用中处理粘包的基础方法主要有两种分别是以4节字描述消息大小或以结束符,实际上也有两者相结合的如HTTP,redis的通讯协议等。
在平时交流过程发现一些朋友即使做了这些协议的处理,但有时在处理数据的时候也会出现数据不对的情况。这主要原因他们在一些个别情况下没有处理好。因为当一系列的消息发送过来的时候,对于4节字头或结束符分布位置都是不确定的。一种简单的情况就是当前消息处理完成后,紧接着就是处理一下个消息的4节字描述,但在实际情况下当前接收的buffer剩下的内容有可能不足4节字的。如果你想通过通讯的程序来测这情况相对来说触发的机率性不高,所以对于协议分析的功能最好通过单元测试来模拟。
通过下面这个图可以更清晰地了解协议标记数据分布的情况

下面简单地介绍一下4字节描述大小和结束符和处理方式。
4字节大小描述方式
1 public void Import(byte[] data, int start, int count) 2 { 3 while (count > 0) 4 { 5 if (!mLoading) 6 { 7 mCheckSize.Reset(); 8 mStream.SetLength(0); 9 mStream.Position = 0;10 mLoading = true;11 }12 if (mCheckSize.Length == -1)13 {14 while (count > 0 && mCheckSize.Length == -1)15 {16 mCheckSize.Import(data[start]);17 start++;18 count--;19 }20 }21 else22 {23 if (OnImport(data, ref start, ref count))24 {25 mLoading = false;26 if (Receive != null)27 {28 mStream.Position = 0;29 Receive(mStream);30 }31 }32 }33 }34 }35 36 37 public void Import(byte value)38 {39 LengthData[mIndex] = value;40 if (mIndex == 3)41 {42 Length = BitConverter.ToInt32(LengthData, 0);43 if (!LittleEndian)44 Length = Endian.SwapInt32(Length);45 }46 else47 {48 mIndex++;49 }50 }
代码很简单如果没有长度描述的情况就把数据导入到消息长度描述的buffer中,如果当前buffer满足4位的情况直接得到相应长度。后面的工作就是获取相应长度的buffer即可。
结束符方式
1 public void Import(byte[] data, int start, int count) 2 { 3 while (count > 0) 4 { 5 if (!mLoading) 6 { 7 mStream.SetLength(0); 8 mStream.Position = 0; 9 mLoading = true;10 }11 if (data[x] == mEof[0])12 {13 start += mEof.Length;14 count -= mEof.Length;15 mLoading = false;16 if (Receive != null)17 {18 mStream.Position = 0;19 Receive(mStream);20 }21 }22 else23 {24 mStream.Write(data[start]);25 start++;26 count--;27 }28 }29 }
结束符的处理方式就相对来说简单多了。
以上就是两种TCP数据处理粘包的情况,相关代码紧供参考。
关于Tcp封包
很多朋友已经对此作了不少研究,也花费不少心血编写了实现代码和blog文档。当然也充斥着一些各式的评论,自己看了一下,总结一些心得。
首先我们学习一下这些朋友的心得,他们是:
http://blog.csdn.net/stamhe/article/details/4569530
http://www.cppblog.com/tx7do/archive/2011/05/04/145699.html
//………………
当然还有太多,很多东西粘来粘区也不知道到底是谁的原作,J
看这些朋友的blog是我建议亲自看一下TCP-IP详解卷1中的相关内容【原理性的内容一定要看】。
TCP大致工作原理介绍:
工作原理
TCP-IP详解卷1第17章中17.2节对TCP服务原理作了一个简明介绍(以下蓝色字体摘自《TCP-IP详解卷1第17章17.2节》):
尽管T C P和U D P都使用相同的网络层( I P),T C P却向应用层提供与U D P完全不同的服务。T C P提供一种面向连接的、可靠的字节流服务。
面向连接意味着两个使用T C P的应用(通常是一个客户和一个服务器)在彼此交换数据之前必须先建立一个T C P连接。这一过程与打电话很相似,先拨号振铃,等待对方摘机说“喂”,然后才说明是谁。在第1 8章我们将看到一个T C P连接是如何建立的,以及当一方通信结束后如何断开连接。
在一个T C P连接中,仅有两方进行彼此通信。在第1 2章介绍的广播和多播不能用于T C P。
T C P通过下列方式来提供可靠性:
• 应用数据被分割成T C P认为最适合发送的数据块。这和U D P完全不同,应用程序产生的数据报长度将保持不变。由T C P传递给I P的信息单位称为报文段或段( s e g m e n t)(参见图1 - 7)。在1 8 . 4节我们将看到T C P如何确定报文段的长度。
• 当T C P发出一个段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能及时收到一个确认,将重发这个报文段。在第2 1章我们将了解T C P协议中自适应的超时及重传策略。
• 当T C P收到发自T C P连接另一端的数据,它将发送一个确认。这个确认不是立即发送,通常将推迟几分之一秒,这将在1 9 . 3节讨论。
• T C P将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错, T C P将丢弃这个报文段和不确认收到此报文段(希望发端超时并重发)。
• 既然T C P报文段作为I P数据报来传输,而I P数据报的到达可能会失序,因此T C P报文段的到达也可能会失序。如果必要, T C P将对收到的数据进行重新排序,将收到的数据以正确的顺序交给应用层。
• 既然I P数据报会发生重复, T C P的接收端必须丢弃重复的数据。
• T C P还能提供流量控制。T C P连接的每一方都有固定大小的缓冲空间。T C P的接收端只允许另一端发送接收端缓冲区所能接纳的数据。这将防止较快主机致使较慢主机的缓冲区溢出。两个应用程序通过T C P连接交换8 bit字节构成的字节流。T C P不在字节流中插入记录标识符。我们将这称为字节流服务( byte stream service)。如果一方的应用程序先传1 0字节,又传2 0字节,再传5 0字节,连接的另一方将无法了解发方每次发送了多少字节。收方可以分4次接收这8 0个字节,每次接收2 0字节。一端将字节流放到T C P连接上,同样的字节流将出现在T C P连接的另一端。另外,T C P对字节流的内容不作任何解释。T C P不知道传输的数据字节流是二进制数据,还是A S C I I字符、E B C D I C字符或者其他类型数据。对字节流的解释由T C P连接双方的应用层解释。这种对字节流的处理方式与U n i x操作系统对文件的处理方式很相似。U n i x的内核对一个应用读或写的内容不作任何解释,而是交给应用程序处理。对U n i x的内核来说,它无法区分一个二进制文件与一个文本文件。
T C P如何确定报文段的长度
我仍然引用官方解释《TCP-IP详解卷1》第18章18.4节:
最大报文段长度( M S S)表示T C P传往另一端的最大块数据的长度。当一个连接建立时【三次握手】,连接的双方都要通告各自的M S S。我们已经见过M S S都是1 0 2 4。这导致I P数据报通常是4 0字节长:2 0字节的T C P首部和2 0字节的I P首部。
在有些书中,将它看作可“协商”选项。它并不是任何条件下都可协商。当建立一个连
接时,每一方都有用于通告它期望接收的M S S选项(M S S选项只能出现在S Y N报文段中)。如果一方不接收来自另一方的M S S值,则M S S就定为默认值5 3 6字节(这个默认值允许2 0字节的I P首部和2 0字节的T C P首部以适合5 7 6字节I P数据报)。
一般说来,如果没有分段发生, M S S还是越大越好(这也并不总是正确,参见图2 4 - 3和图2 4 - 4中的例子)。报文段越大允许每个报文段传送的数据就越多,相对I P和T C P首部有更高的网络利用率。当T C P发送一个S Y N时,或者是因为一个本地应用进程想发起一个连接,或者是因为另一端的主机收到了一个连接请求,它能将M S S值设置为外出接口上的M T U长度减去固定的I P首部和T C P首部长度。对于一个以太网, M S S值可达























 3967
3967

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









