







 本文深入探讨Skia渲染引擎的工作原理,解析从指令层到实现层的分层设计思想,详细介绍SkCanvas、SkDraw、SkBlitter等核心组件的功能与实现细节。同时,文章通过实例演示了常见图像绘制方法的使用技巧。
本文深入探讨Skia渲染引擎的工作原理,解析从指令层到实现层的分层设计思想,详细介绍SkCanvas、SkDraw、SkBlitter等核心组件的功能与实现细节。同时,文章通过实例演示了常见图像绘制方法的使用技巧。
从渲染流程上分,Skia可分为如下三个层级:
1、指令层:SkPicture、SkDeferredCanvas->SkCanvas
这一层决定需要执行哪些绘图操作,绘图操作的预变换矩阵,当前裁剪区域,绘图操作产生在哪些layer上,Layer的生成与合并。
2、解析层:SkBitmapDevice->SkDraw->SkScan、SkDraw1Glyph::Proc
这一层决定绘制方式,完成坐标变换,解析出需要绘制的形体(点/线/规整矩形)并做好抗锯齿处理,进行相关资源解析并设置好Shader。
3、渲染层:SkBlitter->SkBlitRow::Proc、SkShader::shadeSpan等
这一层进行采样(如果需要),产生实际的绘制效果,完成颜色格式适配,进行透明度混合和抖动处理(如果需要)。
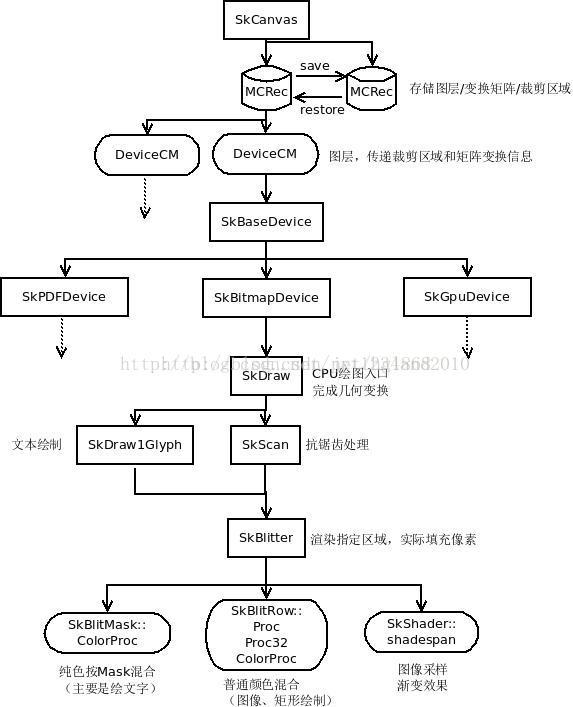
二、主要类介绍
1、SkCanvas
这是复杂度超出想像的一个类。
(1)API设计
a、创建:
在Android中,主要的创建方法是由SkBitmap创建SkCanvas:
explicit SkCanvas(const SkBitmap& bitmap);
这个方法是由bitmap创建一个SkBitmapDevice,再将这个SkBitmapDevice设定为SkCanvas的渲染目标。
5.0之后提供了一个快捷方法创建SkCanvas:
static SkCanvas* NewRasterDirect(const SkImageInfo&, void*, size_t);
这样Android的GraphicBuffer就不需要建一个SkBitmap和它关联了,可以解除SkBitmap类和android runtime的关系(虽然如此,目前Android5.0上,还是按建SkBitmap的方法去关联GraphicBuffer)。
5.0之后引入的离屏渲染:
static SkCanvas* NewRaster(const SkImageInfo&);
创建一个SkCanvas,绘制的内容需要通过readPixels去读取,仍然是CPU绘图的方式。(个人觉得这个是转入GPU硬件加速的一个比较方便的接口,不知道出于什么考虑还是用CPU绘图。)
b、状态:
矩阵状态:
矩阵决定当前绘制的几何变换
rotate、skew、scale、translate、concat
裁剪状态:
裁剪决定当前绘制的生效范围
clipRect、clipRRect、clipPath、clipRegion
保存与恢复:
save、saveLayer、saveLayerAlpha、restore
c、渲染:
大部分渲染的API都可由这三个组合而成:
drawRect(矩形/图像绘制)、drawPath(不规则图形图像绘制)和drawText(文本绘制)
d、像素的读取与写入
readPixels、writePixels
这两个API主要由device实现,考虑到不同绘图设备的异质性。
(2)MCRec状态栈
fMCStack是存储的全部状态集,fMCRec则是当前的状态。
在 save saveLayer saveLayerAlpha 时,会新建一个MCRec,在restore时,销毁栈顶的MCRec。
(代码见:SkCanvas.cpp internalSave函数,通过这段代码可以了解一下new的各种用法~。)
每个状态包括如下信息:
class SkCanvas::MCRec {
public:
int fFlags;//保存的状态标识(是否保存矩阵/裁剪/图层)
SkMatrix* fMatrix;//矩阵指针,若这个状态有独立矩阵,则指向内存(fMatrixStorage),否则用上一个MCRec的fMatrix
SkRasterClip* fRasterClip;//裁剪区域,若这个状态有独立裁剪区域,则指向内存(fRasterClip),否则继承上一个的。
SkDrawFilter* fFilter;
DeviceCM* fLayer;//这个状态所拥有的layer(需要在此MCRec销毁时回收)
DeviceCM* fTopLayer;//这个状态下,所需要绘制的Layer链表。(这些Layer不一定属于此状态)
......
};
DeviceCM:图层链表,包装一个SkBaseDevice,附加一个位置偏移变化的矩阵(在saveLayer时指定的坐标)。
(3)两重循环绘制
研究Skia的人,一般来说都会被一开始的两重循环弄晕一会,比如drawRect的代码:
LOOPER_BEGIN(paint, SkDrawFilter::kRect_Type, bounds)
while (iter.next()) {
iter.fDevice->drawRect(iter, r, looper.paint());
}
LOOPER_END
先完全展开上面的代码:
AutoDrawLooper looper(this, paint, false, bounds);
while (looper.next(type)) {
SkDrawIter iter(this);
while (iter.next()) {
iter.fDevice->drawRect(iter, r, looper.paint());
}
}
第一重循环即 AutoDrawLooper,这个next实际上是做一个后处理,在存在 SkImageFilter 的情况下,先渲染到临时Layer上,再将这个Layer做Filter处理后画到当前device上。
第二重循环是SkDrawIter,这个是绘制当前状态所依附的所有Layer。
一般情况下,这两重循环都可以忽略,单纯当它是走下流程就好了。
个人认为Skia在绘制入口SkCanvas的设计并不是很好,图层、矩阵与裁剪存在一起,导致渲染任务难以剥离,后面GPU渲染和延迟渲染的引入都让人感到有些生硬。
2、SkDraw、SkBlitter
这两个类在后续章节还会提到,这里只简单介绍:
SkDraw是CPU绘图的实现入口,主要任务是做渲染准备(形状确定、几何变换、字体解析、构建图像Shader等)。
SkBlitter 不是单独的一个类,指代了一系列根据图像格式、是否包含Shader等区分出来的一系列子类。
这一族类执行大块头的渲染任务,把像素绘制上去。
三、渲染框架设计思想分析
1、指令层与实现层分离
SkCanvas不直接执行渲染,由SkBaseDevice根据设备类型,选择渲染方法。这样虽然是同一套API,但可以用作GPU绘图、pdf绘制、存储显示列表等各种功能。在API集上做优化,避免冗余绘制,也因此成为可能(注:这个google虽然在尝试,但目前看来没有明显效果,实现起来确实也很困难)。
2、图=形+色的设计思想
由SkDraw和SkScan类中控制绘制的形,由SkBlitter和SkShader控制绘制的色,将绘图操作分解为形状与色彩两部分,这一点和OpenGL的顶点变换——光栅——片断着色管线相似,非常有利于扩展,各种2D图元的绘制基本上就完全支持了。
3、性能调优集中化
将耗时的函数抽象都抽象为proc,由一个工厂制造,便于集中对这一系列函数做优化。
此篇讲Skia绘制图片的流程,在下一篇讲图像采样原理、混合和抖动技术
1、API用法
(1)drawBitmap
void drawBitmap(const SkBitmap& bitmap, SkScalar left, SkScalar top, const SkPaint* paint = NULL);
将bitmap画到x,y的位置(这本身是一个平移,需要和SkCanvas中的矩阵状态叠加)。
(2)drawBitmapRect 和 drawBitmapRectToRect
void drawBitmapRect(const SkBitmap& bitmap, const SkRect& dst, const SkPaint* paint = NULL);
void drawBitmapRectToRect(const SkBitmap& bitmap, const SkRect* src, const SkRect& dst, const SkPaint* paint, DrawBitmapRectFlags flags);
将源图src矩阵部分,画到目标dst区域去。
最后一个flags是AndroidL上为了gpu绘制效果而加上去的,在CPU绘制中不需要关注。
(3)drawSprite
void drawSprite(const SkBitmap& bitmap, int x, int y, const SkPaint* paint);
无视SkCanvas的矩阵状态,将bitmap平移到x,y的位置。
(4)drawBitmapMatrix
void drawBitmapMatrix(const SkBitmap& bitmap, const SkMatrix& matrix, const SkPaint* paint);
绘制的bitmap带有matrix的矩形变换,需要和SkCanvas的矩形变换叠加。
(5)drawRect
void drawRect(const SkRect& r, const SkPaint& paint);
这个是最通用的方法,多用于需要加入额外效果的场景,比如需要绘制重复纹理。关于Tile的两个参数就是OpenGL纹理贴图中水平垂直方向上的边界处理模式。
由这种用法,大家不难类推到非矩形图像绘制的方法,比如画圆角矩形图标、把方图片裁剪成一个圆等。
下面是一个Demo程序
#include "SkBitmapProcShader.h"
#include "SkCanvas.h"
#include "SkBitmap.h"
#include "SkImageDecoder.h"
#include "SkImageEncoder.h"
#include "SkRect.h"
int main()
{
const int w = 1080;
const int h = 1920;
/*准备目标图片和源图片*/
SkBitmap dst;
dst.allocPixels(SkImageInfo::Make(w, h, kN32_SkColorType, kPremul_SkAlphaType));
SkCanvas c(dst);
SkBitmap src;
SkImageDecoder::DecodeFile("test.jpg", &src);
/*各种绘制图片方法使用示例*/
{
c.drawBitmap(src, 0, 0, NULL);
}
{
c.drawSprite(src, 400, 400, NULL);
}
{
SkRect dstR;
r.set(29, 29, 100, 100);
SkRect srcR;
r.set(0,0,40,50);
c.drawBitmapRectToRect(src, &srcR, dstR, NULL);
}
{
SkMatrix m;
m.setScale(1.4,4.3);
c.drawBitmapMatrix(src, m, NULL);
}
{
SkRect dstRect;
dstRect.set(100,100,480,920);
SkPaint paint;
SkMatrix m;
m.setScale(3.2, 4.1);
SkShader* shader = CreateBitmapShader(src, SkShader::kRepeat_TileMode, SkShader::kRepeat_TileMode, m, NULL);
paint.setShader(shader);
SkSafeUnref(shader);
c.drawRect(dstRect, paint);
}
/*输出图片*/
SkImageEncoder::EncodeFile("output.jpg", dst, SkImageEncoder::kJPEG_Type, 100);
return 1;
}
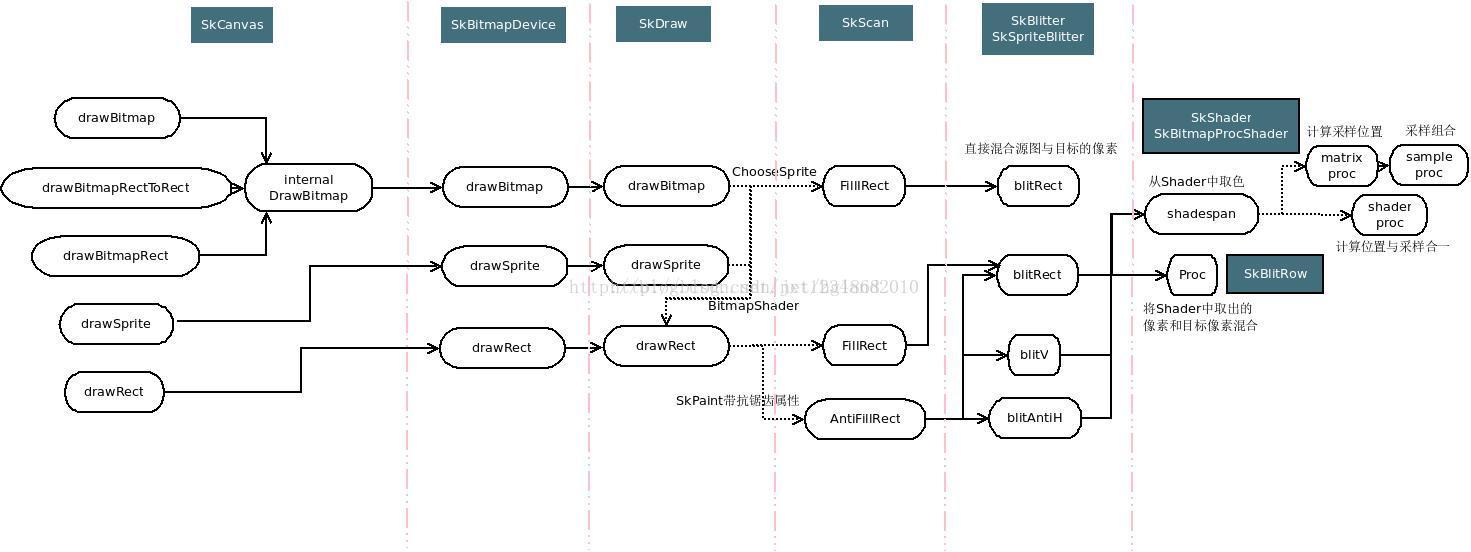
(1)SkCanvas两重循环调到SkBitmapDevice,进而调到SkDraw
在SkDraw中,drawBitmap的渲染函数统一为:
void SkDraw::drawBitmap(const SkBitmap& bitmap, const SkMatrix& prematrix, const SkPaint& origPaint) const;
(2)Sprite简易模式
在满足如下条件时,走进Sprite简易模式。
代码见 external/skia/src/core/SkDraw.cpp drawBitmap 函数
a、(bitmap.colorType() != kAlpha_8_SkColorType && just_translate(matrix, bitmap))
kAlpha_8_SkColorType 的图像只有一个通道alpha,按 drawMask 方式处理,将Paint中的颜色按图像的alpha预乘,叠加到目标区域上。
just_translate表示matrix为一个平移矩阵,这时不涉及旋转缩放,bitmap的像素点和SkCanvas绑定的dstBitmap的像素点此时存在连续的一一对齐关系。
b、clipHandlesSprite(*fRC, ix, iy, bitmap))
这个条件是指当前SkCanvas的裁剪区域不需要考虑抗锯齿或者完全包含了bitmap的渲染区域。SkCanvas的任何渲染都必须在裁剪区域之内,因此如果图像跨越了裁剪区域边界而且裁剪区域需要考虑抗锯齿,在边界上需要做特殊处理。
注:裁剪区域的设置API
void SkCanvas::clipRect(const SkRect& rect, SkRegion::Op op, bool doAA)
doAA即是否在r的边界非整数时考虑抗锯齿。
满足条件,创建SkSpriteBlitter,由SkScan::FillIRect按每个裁剪区域调用SkSpriteBlitter的blitRect。
这种情况下可以直接做颜色转换和透明度合成渲染过去,不需要做抗锯齿和图像插值,也就不需要走取样——混合流程,性能是最高的。
满足条件后通过ChooseSprite去选一个SkSpriteBlitter
详细代码见 external/skia/src/core/SkBlitter_Sprite.cpp 中的 ChooseSprite 函数。
这函数实际上很多场景都没覆盖到,因此很可能是选不到的,这时就开始转回drawRect流程。
(3)创建BitmapShader
在 SkAutoBitmapShaderInstall install(bitmap, paint); 这一句代码中,为paint创建了bitmapShader:
fPaint.setShader(CreateBitmapShader(src, SkShader::kClamp_TileMode,
SkShader::kClamp_TileMode,
localMatrix, &fAllocator));
然后就可以使用drawRect画图像了。
(4)drawRect
不能使用SkSpriteBlitter的场景,走drawRect通用流程。
这里有非常多的分支,只讲绘制实矩形的情形。
通过 SkAutoBlitterChoose -> SkBlitter::Choose,根据Canvas绑定的Bitmap像素模式,paint属性去选择blitter。
绘制图片时paint有Shader(SkBitmapProcShader),因此是选的是带Shader的Blitter,比如适应ARGB格式的 SkARGB32_Shader_Blitter
(5)SkScan
在SkScan中,对每一个裁剪区域,将其与绘制的rect求交,然后渲染这个相交区域。此外,在需要时做抗锯齿。
做抗锯齿的基本方法就是对浮点的坐标,按其离整数的偏离度给一个alpha权重,将颜色乘以此权重(减淡颜色)画上去。
SkScan中在绘制矩形时,先用blitV绘制左右边界,再用blitAntiH绘制上下边界,中间大块的不需要考虑抗锯齿,因而用blitRect。
(6)blitRect
这一步先通过 Shader的shadeSpan方法取对应位置的像素,再将此像素通过SkBlitRow的proc叠加上去。
如果不需要考虑混合模式,可以跳过proc。
参考代码:external/skia/src/core/SkBlitter_ARGB32.cpp 中的blitRect
(7)shadeSpan
这里只考虑 SkBitmapProcShader 的shadeSpan,这主要是图像采样的方法。详细代码见 external/skia/src/core/SkBitmapProcShader.cpp
对每一个目标点,先通过 matrixProc 取出需要参考的源图像素,然后用sampleProc将这些像素合成为一个像素值。(和OpenGL里面的texture2D函数原理很类似)。
若存在 shaderProc(做线性插值时,上面的步骤是可以优化的,完全可以取出一群像素一起做插值计算),以shaderProc代替上面的两步流程,起性能优化作用。
3、SkBlitter接口解析
(1)blitH
virtual void blitH(int x, int y, int width);
从x,y坐标开始,渲染一行width个像素
(2)blitV
virtual void blitV(int x, int y, int height, SkAlpha alpha);
从x,y开始,渲染一列height个像素,按alpha值对颜色做减淡处理
(3)blitAntiH
virtual void blitAntiH(int x, int y, const SkAlpha antialias[], const int16_t runs[]);
如流程图所标示的,这个函数的用来渲染上下边界,作抗锯齿处理。
(4)blitRect
virtual void blitRect(int x, int y, int width, int height);
绘制矩形区域,这个地方就不需要考虑任何的几何变换、抗锯齿等因素了。
(5)blitMask
virtual void blitMask(const SkMask& mask, const SkIRect& clip);
主要绘制文字时使用,以一个颜色乘上mash中的透明度,叠加。
一、采样流程
我们先看一个具体的blitRect实现。
void SkARGB32_Shader_Blitter::blitRect(int x, int y, int width, int height) {
SkASSERT(x >= 0 && y >= 0 &&
x + width <= fDevice.width() && y + height <= fDevice.height());
uint32_t* device = fDevice.getAddr32(x, y);
size_t deviceRB = fDevice.rowBytes();
SkShader::Context* shaderContext = fShaderContext;
SkPMColor* span = fBuffer;
if (fConstInY) {
if (fShadeDirectlyIntoDevice) {
// shade the first row directly into the device
shaderContext->shadeSpan(x, y, device, width);
span = device;
while (--height > 0) {
device = (uint32_t*)((char*)device + deviceRB);
memcpy(device, span, width << 2);
}
} else {
shaderContext->shadeSpan(x, y, span, width);
SkXfermode* xfer = fXfermode;
if (xfer) {
do {
xfer->xfer32(device, span, width, NULL);
y += 1;
device = (uint32_t*)((char*)device + deviceRB);
} while (--height > 0);
} else {
SkBlitRow::Proc32 proc = fProc32;
do {
proc(device, span, width, 255);
y += 1;
device = (uint32_t*)((char*)device + deviceRB);
} while (--height > 0);
}
}
return;
}
if (fShadeDirectlyIntoDevice) {
void* ctx;
SkShader::Context::ShadeProc shadeProc = shaderContext->asAShadeProc(&ctx);
if (shadeProc) {
do {
shadeProc(ctx, x, y, device, width);
y += 1;
device = (uint32_t*)((char*)device + deviceRB);
} while (--height > 0);
} else {
do {
shaderContext->shadeSpan(x, y, device, width);
y += 1;
device = (uint32_t*)((char*)device + deviceRB);
} while (--height > 0);
}
} else {
SkXfermode* xfer = fXfermode;
if (xfer) {
do {
shaderContext->shadeSpan(x, y, span, width);
xfer->xfer32(device, span, width, NULL);
y += 1;
device = (uint32_t*)((char*)device + deviceRB);
} while (--height > 0);
} else {
SkBlitRow::Proc32 proc = fProc32;
do {
shaderContext->shadeSpan(x, y, span, width);
proc(device, span, width, 255);
y += 1;
device = (uint32_t*)((char*)device + deviceRB);
} while (--height > 0);
}
}
}
其中shadeSpan用来将shader中x,y坐标处的值取n个到dst的buffer中。对于图像绘制时,它是 SkBitmapProcShader,这里是其实现:
void SkBitmapProcShader::BitmapProcShaderContext::shadeSpan(int x, int y, SkPMColor dstC[],
int count) {
const SkBitmapProcState& state = *fState;
if (state.getShaderProc32()) {
state.getShaderProc32()(state, x, y, dstC, count);
return;
}
uint32_t buffer[BUF_MAX + TEST_BUFFER_EXTRA];
SkBitmapProcState::MatrixProc mproc = state.getMatrixProc();
SkBitmapProcState::SampleProc32 sproc = state.getSampleProc32();
int max = state.maxCountForBufferSize(sizeof(buffer[0]) * BUF_MAX);
SkASSERT(state.fBitmap->getPixels());
SkASSERT(state.fBitmap->pixelRef() == NULL ||
state.fBitmap->pixelRef()->isLocked());
for (;;) {
int n = count;
if (n > max) {
n = max;
}
SkASSERT(n > 0 && n < BUF_MAX*2);
#ifdef TEST_BUFFER_OVERRITE
for (int i = 0; i < TEST_BUFFER_EXTRA; i++) {
buffer[BUF_MAX + i] = TEST_PATTERN;
}
#endif
mproc(state, buffer, n, x, y);
#ifdef TEST_BUFFER_OVERRITE
for (int j = 0; j < TEST_BUFFER_EXTRA; j++) {
SkASSERT(buffer[BUF_MAX + j] == TEST_PATTERN);
}
#endif
sproc(state, buffer, n, dstC);
if ((count -= n) == 0) {
break;
}
SkASSERT(count > 0);
x += n;
dstC += n;
}
}
流程如下:
1、存在 shaderProc,直接用
2、计算一次能处理的像素数count
3、mproc计算count个坐标,sproc根据坐标值去取色
注意到之前三个函数指针:
state.getShaderProc32
mproc = state.getMatrixProc
sproc = state.getShaderProc32
这三个函数指针在一开始创建blitter时设定:
SkBlitter::Choose -> SkShader::createContext -> SkBitmapProcShader::onCreateContext -> SkBitmapProcState::chooseProcs
1、(优化步骤)在大于SkPaint::kLow_FilterLevel的质量要求下,试图做预缩放。
2、选择matrix函数:chooseMatrixProc。
3、选择sample函数:
(1)高质量:setBitmapFilterProcs
(2)kLow_FilterLevel或kNone_FilterLevel:采取flags计算的方法,根据x,y变化矩阵情况和采样要求选择函数
4、(优化步骤)在满足条件时,选取shader函数,此函数替代matrix和sample函数
5、(优化步骤)platformProcs(),进一步选择优化版本的sample函数
对于RGB565格式的目标,使用的是SkShader的 shadeSpan16 方法。shadeSpan16的代码逻辑类似,不再说明。
bool SkBitmapProcState::chooseProcs(const SkMatrix& inv, const SkPaint& paint) {
SkASSERT(fOrigBitmap.width() && fOrigBitmap.height());
fBitmap = NULL;
fInvMatrix = inv;
fFilterLevel = paint.getFilterLevel();
SkASSERT(NULL == fScaledCacheID);
// possiblyScaleImage will look to see if it can rescale the image as a
// preprocess; either by scaling up to the target size, or by selecting
// a nearby mipmap level. If it does, it will adjust the working
// matrix as well as the working bitmap. It may also adjust the filter
// quality to avoid re-filtering an already perfectly scaled image.
if (!this->possiblyScaleImage()) {
if (!this->lockBaseBitmap()) {
return false;
}
}
// The above logic should have always assigned fBitmap, but in case it
// didn't, we check for that now...
// TODO(dominikg): Ask humper@ if we can just use an SkASSERT(fBitmap)?
if (NULL == fBitmap) {
return false;
}
// If we are "still" kMedium_FilterLevel, then the request was not fulfilled by possiblyScale,
// so we downgrade to kLow (so the rest of the sniffing code can assume that)
if (SkPaint::kMedium_FilterLevel == fFilterLevel) {
fFilterLevel = SkPaint::kLow_FilterLevel;
}
bool trivialMatrix = (fInvMatrix.getType() & ~SkMatrix::kTranslate_Mask) == 0;
bool clampClamp = SkShader::kClamp_TileMode == fTileModeX &&
SkShader::kClamp_TileMode == fTileModeY;
if (!(clampClamp || trivialMatrix)) {
fInvMatrix.postIDiv(fOrigBitmap.width(), fOrigBitmap.height());
}
// Now that all possible changes to the matrix have taken place, check
// to see if we're really close to a no-scale matrix. If so, explicitly
// set it to be so. Subsequent code may inspect this matrix to choose
// a faster path in this case.
// This code will only execute if the matrix has some scale component;
// if it's already pure translate then we won't do this inversion.
if (matrix_only_scale_translate(fInvMatrix)) {
SkMatrix forward;
if (fInvMatrix.invert(&forward)) {
if (clampClamp ? just_trans_clamp(forward, *fBitmap)
: just_trans_general(forward)) {
SkScalar tx = -SkScalarRoundToScalar(forward.getTranslateX());
SkScalar ty = -SkScalarRoundToScalar(forward.getTranslateY());
fInvMatrix.setTranslate(tx, ty);
}
}
}
fInvProc = fInvMatrix.getMapXYProc();
fInvType = fInvMatrix.getType();
fInvSx = SkScalarToFixed(fInvMatrix.getScaleX());
fInvSxFractionalInt = SkScalarToFractionalInt(fInvMatrix.getScaleX());
fInvKy = SkScalarToFixed(fInvMatrix.getSkewY());
fInvKyFractionalInt = SkScalarToFractionalInt(fInvMatrix.getSkewY());
fAlphaScale = SkAlpha255To256(paint.getAlpha());
fShaderProc32 = NULL;
fShaderProc16 = NULL;
fSampleProc32 = NULL;
fSampleProc16 = NULL;
// recompute the triviality of the matrix here because we may have
// changed it!
trivialMatrix = (fInvMatrix.getType() & ~SkMatrix::kTranslate_Mask) == 0;
if (SkPaint::kHigh_FilterLevel == fFilterLevel) {
// If this is still set, that means we wanted HQ sampling
// but couldn't do it as a preprocess. Let's try to install
// the scanline version of the HQ sampler. If that process fails,
// downgrade to bilerp.
// NOTE: Might need to be careful here in the future when we want
// to have the platform proc have a shot at this; it's possible that
// the chooseBitmapFilterProc will fail to install a shader but a
// platform-specific one might succeed, so it might be premature here
// to fall back to bilerp. This needs thought.
if (!this->setBitmapFilterProcs()) {
fFilterLevel = SkPaint::kLow_FilterLevel;
}
}
if (SkPaint::kLow_FilterLevel == fFilterLevel) {
// Only try bilerp if the matrix is "interesting" and
// the image has a suitable size.
if (fInvType <= SkMatrix::kTranslate_Mask ||
!valid_for_filtering(fBitmap->width() | fBitmap->height())) {
fFilterLevel = SkPaint::kNone_FilterLevel;
}
}
// At this point, we know exactly what kind of sampling the per-scanline
// shader will perform.
fMatrixProc = this->chooseMatrixProc(trivialMatrix);
// TODO(dominikg): SkASSERT(fMatrixProc) instead? chooseMatrixProc never returns NULL.
if (NULL == fMatrixProc) {
return false;
}
///
// No need to do this if we're doing HQ sampling; if filter quality is
// still set to HQ by the time we get here, then we must have installed
// the shader procs above and can skip all this.
if (fFilterLevel < SkPaint::kHigh_FilterLevel) {
int index = 0;
if (fAlphaScale < 256) { // note: this distinction is not used for D16
index |= 1;
}
if (fInvType <= (SkMatrix::kTranslate_Mask | SkMatrix::kScale_Mask)) {
index |= 2;
}
if (fFilterLevel > SkPaint::kNone_FilterLevel) {
index |= 4;
}
// bits 3,4,5 encoding the source bitmap format
switch (fBitmap->colorType()) {
case kN32_SkColorType:
index |= 0;
break;
case kRGB_565_SkColorType:
index |= 8;
break;
case kIndex_8_SkColorType:
index |= 16;
break;
case kARGB_4444_SkColorType:
index |= 24;
break;
case kAlpha_8_SkColorType:
index |= 32;
fPaintPMColor = SkPreMultiplyColor(paint.getColor());
break;
default:
// TODO(dominikg): Should we ever get here? SkASSERT(false) instead?
return false;
}
#if !SK_ARM_NEON_IS_ALWAYS
static const SampleProc32 gSkBitmapProcStateSample32[] = {
S32_opaque_D32_nofilter_DXDY,
S32_alpha_D32_nofilter_DXDY,
S32_opaque_D32_nofilter_DX,
S32_alpha_D32_nofilter_DX,
S32_opaque_D32_filter_DXDY,
S32_alpha_D32_filter_DXDY,
S32_opaque_D32_filter_DX,
S32_alpha_D32_filter_DX,
S16_opaque_D32_nofilter_DXDY,
S16_alpha_D32_nofilter_DXDY,
S16_opaque_D32_nofilter_DX,
S16_alpha_D32_nofilter_DX,
S16_opaque_D32_filter_DXDY,
S16_alpha_D32_filter_DXDY,
S16_opaque_D32_filter_DX,
S16_alpha_D32_filter_DX,
SI8_opaque_D32_nofilter_DXDY,
SI8_alpha_D32_nofilter_DXDY,
SI8_opaque_D32_nofilter_DX,
SI8_alpha_D32_nofilter_DX,
SI8_opaque_D32_filter_DXDY,
SI8_alpha_D32_filter_DXDY,
SI8_opaque_D32_filter_DX,
SI8_alpha_D32_filter_DX,
S4444_opaque_D32_nofilter_DXDY,
S4444_alpha_D32_nofilter_DXDY,
S4444_opaque_D32_nofilter_DX,
S4444_alpha_D32_nofilter_DX,
S4444_opaque_D32_filter_DXDY,
S4444_alpha_D32_filter_DXDY,
S4444_opaque_D32_filter_DX,
S4444_alpha_D32_filter_DX,
// A8 treats alpha/opaque the same (equally efficient)
SA8_alpha_D32_nofilter_DXDY,
SA8_alpha_D32_nofilter_DXDY,
SA8_alpha_D32_nofilter_DX,
SA8_alpha_D32_nofilter_DX,
SA8_alpha_D32_filter_DXDY,
SA8_alpha_D32_filter_DXDY,
SA8_alpha_D32_filter_DX,
SA8_alpha_D32_filter_DX
};
static const SampleProc16 gSkBitmapProcStateSample16[] = {
S32_D16_nofilter_DXDY,
S32_D16_nofilter_DX,
S32_D16_filter_DXDY,
S32_D16_filter_DX,
S16_D16_nofilter_DXDY,
S16_D16_nofilter_DX,
S16_D16_filter_DXDY,
S16_D16_filter_DX,
SI8_D16_nofilter_DXDY,
SI8_D16_nofilter_DX,
SI8_D16_filter_DXDY,
SI8_D16_filter_DX,
// Don't support 4444 -> 565
NULL, NULL, NULL, NULL,
// Don't support A8 -> 565
NULL, NULL, NULL, NULL
};
#endif
fSampleProc32 = SK_ARM_NEON_WRAP(gSkBitmapProcStateSample32)[index];
index >>= 1; // shift away any opaque/alpha distinction
fSampleProc16 = SK_ARM_NEON_WRAP(gSkBitmapProcStateSample16)[index];
// our special-case shaderprocs
if (SK_ARM_NEON_WRAP(S16_D16_filter_DX) == fSampleProc16) {
if (clampClamp) {
fShaderProc16 = SK_ARM_NEON_WRAP(Clamp_S16_D16_filter_DX_shaderproc);
} else if (SkShader::kRepeat_TileMode == fTileModeX &&
SkShader::kRepeat_TileMode == fTileModeY) {
fShaderProc16 = SK_ARM_NEON_WRAP(Repeat_S16_D16_filter_DX_shaderproc);
}
} else if (SK_ARM_NEON_WRAP(SI8_opaque_D32_filter_DX) == fSampleProc32 && clampClamp) {
fShaderProc32 = SK_ARM_NEON_WRAP(Clamp_SI8_opaque_D32_filter_DX_shaderproc);
}
if (NULL == fShaderProc32) {
fShaderProc32 = this->chooseShaderProc32();
}
}
// see if our platform has any accelerated overrides
this->platformProcs();
return true;
}
二、MatrixProc和SampleProc
MatrixProc的使命是生成坐标集。SampleProc则根据坐标集取像素,采样合成
我们先倒过来看 sampleProc 看这个坐标集是怎么使用的:
nofilter_dx系列:
void MAKENAME(_nofilter_DXDY)(const SkBitmapProcState& s,
const uint32_t* SK_RESTRICT xy,
int count, DSTTYPE* SK_RESTRICT colors) {
for (int i = (count >> 1); i > 0; --i) {
XY = *xy++;
SkASSERT((XY >> 16) < (unsigned)s.fBitmap->height() &&
(XY & 0xFFFF) < (unsigned)s.fBitmap->width());
src = ((const SRCTYPE*)(srcAddr + (XY >> 16) * rb))[XY & 0xFFFF];
*colors++ = RETURNDST(src);
XY = *xy++;
SkASSERT((XY >> 16) < (unsigned)s.fBitmap->height() &&
(XY & 0xFFFF) < (unsigned)s.fBitmap->width());
src = ((const SRCTYPE*)(srcAddr + (XY >> 16) * rb))[XY & 0xFFFF];
*colors++ = RETURNDST(src);
}
if (count & 1) {
XY = *xy++;
SkASSERT((XY >> 16) < (unsigned)s.fBitmap->height() &&
(XY & 0xFFFF) < (unsigned)s.fBitmap->width());
src = ((const SRCTYPE*)(srcAddr + (XY >> 16) * rb))[XY & 0xFFFF];
*colors++ = RETURNDST(src);
}
}
这两个系列是直接取了x,y坐标处的图像像素
filter_dx系列:
filter_dxdy系列:
void MAKENAME(_filter_DX)(const SkBitmapProcState& s,const uint32_t* SK_RESTRICT xy,
int count, DSTTYPE* SK_RESTRICT colors) {
SkASSERT(count > 0 && colors != NULL);
SkASSERT(s.fFilterLevel != SkPaint::kNone_FilterLevel);
SkDEBUGCODE(CHECKSTATE(s);)
#ifdef PREAMBLE
PREAMBLE(s);
#endif
const char* SK_RESTRICT srcAddr = (const char*)s.fBitmap->getPixels();
size_t rb = s.fBitmap->rowBytes();
unsigned subY;
const SRCTYPE* SK_RESTRICT row0;
const SRCTYPE* SK_RESTRICT row1;
// setup row ptrs and update proc_table
{
uint32_t XY = *xy++;
unsigned y0 = XY >> 14;
row0 = (const SRCTYPE*)(srcAddr + (y0 >> 4) * rb);
row1 = (const SRCTYPE*)(srcAddr + (XY & 0x3FFF) * rb);
subY = y0 & 0xF;
}
do {
uint32_t XX = *xy++; // x0:14 | 4 | x1:14
unsigned x0 = XX >> 14;
unsigned x1 = XX & 0x3FFF;
unsigned subX = x0 & 0xF;
x0 >>= 4;
FILTER_PROC(subX, subY,
SRC_TO_FILTER(row0[x0]),
SRC_TO_FILTER(row0[x1]),
SRC_TO_FILTER(row1[x0]),
SRC_TO_FILTER(row1[x1]),
colors);
colors += 1;
} while (--count != 0);
#ifdef POSTAMBLE
POSTAMBLE(s);
#endif
}
void MAKENAME(_filter_DXDY)(const SkBitmapProcState& s,
const uint32_t* SK_RESTRICT xy,
int count, DSTTYPE* SK_RESTRICT colors) {
SkASSERT(count > 0 && colors != NULL);
SkASSERT(s.fFilterLevel != SkPaint::kNone_FilterLevel);
SkDEBUGCODE(CHECKSTATE(s);)
#ifdef PREAMBLE
PREAMBLE(s);
#endif
const char* SK_RESTRICT srcAddr = (const char*)s.fBitmap->getPixels();
size_t rb = s.fBitmap->rowBytes();
do {
uint32_t data = *xy++;
unsigned y0 = data >> 14;
unsigned y1 = data & 0x3FFF;
unsigned subY = y0 & 0xF;
y0 >>= 4;
data = *xy++;
unsigned x0 = data >> 14;
unsigned x1 = data & 0x3FFF;
unsigned subX = x0 & 0xF;
x0 >>= 4;
const SRCTYPE* SK_RESTRICT row0 = (const SRCTYPE*)(srcAddr + y0 * rb);
const SRCTYPE* SK_RESTRICT row1 = (const SRCTYPE*)(srcAddr + y1 * rb);
FILTER_PROC(subX, subY,
SRC_TO_FILTER(row0[x0]),
SRC_TO_FILTER(row0[x1]),
SRC_TO_FILTER(row1[x0]),
SRC_TO_FILTER(row1[x1]),
colors);
colors += 1;
} while (--count != 0);
#ifdef POSTAMBLE
POSTAMBLE(s);
#endif
}
将四个相邻像素取出来之后,作Filter处理
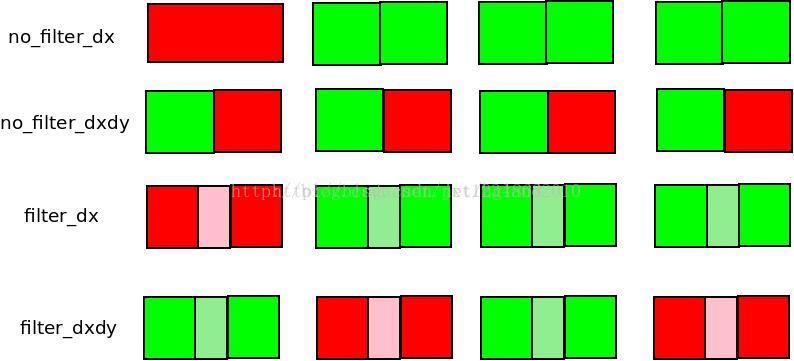
看晕了么,其实总结一下是这样:
nofilter_dx,第一个32位数表示y,其余的32位数包含两个x坐标。
nofilter_dxdy,用16位表示x,16位表示y。这种情况就是取的最近值,直接到x,y坐标处取值就可以了。
filter_dxdy系列,每个32位数分别表示X和Y坐标(14:4:14),交错排列,中间的差值部分是相差的小数扩大16倍而得的近似整数。
filter_dx系列,第一个数为Y坐标用14:4:14的方式存储,后面的数为X坐标,也用14:4:14的方式存储,前后为对应坐标,中间为放大16倍的距离,这个情况是一行之内y坐标相同(只做缩放或小数平移的情况),一样是作双线性插值。
下面我们来看matrixproc的实现,
先跟进 chooseMatrixProc的代码:
SkBitmapProcState::MatrixProc SkBitmapProcState::chooseMatrixProc(bool trivial_matrix) {// test_int_tileprocs();
// check for our special case when there is no scale/affine/perspective
if (trivial_matrix) {
SkASSERT(SkPaint::kNone_FilterLevel == fFilterLevel);
fIntTileProcY = choose_int_tile_proc(fTileModeY);
switch (fTileModeX) {
case SkShader::kClamp_TileMode:
return clampx_nofilter_trans;
case SkShader::kRepeat_TileMode:
return repeatx_nofilter_trans;
case SkShader::kMirror_TileMode:
return mirrorx_nofilter_trans;
}
}
int index = 0;
if (fFilterLevel != SkPaint::kNone_FilterLevel) {
index = 1;
}
if (fInvType & SkMatrix::kPerspective_Mask) {
index += 4;
} else if (fInvType & SkMatrix::kAffine_Mask) {
index += 2;
}
if (SkShader::kClamp_TileMode == fTileModeX && SkShader::kClamp_TileMode == fTileModeY) {
// clamp gets special version of filterOne
fFilterOneX = SK_Fixed1;
fFilterOneY = SK_Fixed1;
return SK_ARM_NEON_WRAP(ClampX_ClampY_Procs)[index];
}
// all remaining procs use this form for filterOne
fFilterOneX = SK_Fixed1 / fBitmap->width();
fFilterOneY = SK_Fixed1 / fBitmap->height();
if (SkShader::kRepeat_TileMode == fTileModeX && SkShader::kRepeat_TileMode == fTileModeY) {
return SK_ARM_NEON_WRAP(RepeatX_RepeatY_Procs)[index];
}
fTileProcX = choose_tile_proc(fTileModeX);
fTileProcY = choose_tile_proc(fTileModeY);
fTileLowBitsProcX = choose_tile_lowbits_proc(fTileModeX);
fTileLowBitsProcY = choose_tile_lowbits_proc(fTileModeY);
return GeneralXY_Procs[index];
}
有些函数是找符号找不到的,我们注意到SkBitmapProcState.cpp 中包含了多次 SkBitmapProcState_matrix.h 头文件:
#if !SK_ARM_NEON_IS_ALWAYS
#define MAKENAME(suffix) ClampX_ClampY ## suffix
#define TILEX_PROCF(fx, max) SkClampMax((fx) >> 16, max)
#define TILEY_PROCF(fy, max) SkClampMax((fy) >> 16, max)
#define TILEX_LOW_BITS(fx, max) (((fx) >> 12) & 0xF)
#define TILEY_LOW_BITS(fy, max) (((fy) >> 12) & 0xF)
#define CHECK_FOR_DECAL
#include "SkBitmapProcState_matrix.h"
/*
* Copyright 2011 Google Inc.
*
* Use of this source code is governed by a BSD-style license that can be
* found in the LICENSE file.
*/
#include "SkMath.h"
#include "SkMathPriv.h"
#define SCALE_FILTER_NAME MAKENAME(_filter_scale)
#define AFFINE_FILTER_NAME MAKENAME(_filter_affine)
#define PERSP_FILTER_NAME MAKENAME(_filter_persp)
#define PACK_FILTER_X_NAME MAKENAME(_pack_filter_x)
#define PACK_FILTER_Y_NAME MAKENAME(_pack_filter_y)
#ifndef PREAMBLE
#define PREAMBLE(state)
#define PREAMBLE_PARAM_X
#define PREAMBLE_PARAM_Y
#define PREAMBLE_ARG_X
#define PREAMBLE_ARG_Y
#endif
// declare functions externally to suppress warnings.
void SCALE_FILTER_NAME(const SkBitmapProcState& s,
uint32_t xy[], int count, int x, int y);
void AFFINE_FILTER_NAME(const SkBitmapProcState& s,
uint32_t xy[], int count, int x, int y);
void PERSP_FILTER_NAME(const SkBitmapProcState& s,
uint32_t* SK_RESTRICT xy, int count,
int x, int y);
static inline uint32_t PACK_FILTER_Y_NAME(SkFixed f, unsigned max,
SkFixed one PREAMBLE_PARAM_Y) {
unsigned i = TILEY_PROCF(f, max);
i = (i << 4) | TILEY_LOW_BITS(f, max);
return (i << 14) | (TILEY_PROCF((f + one), max));
}
static inline uint32_t PACK_FILTER_X_NAME(SkFixed f, unsigned max,
SkFixed one PREAMBLE_PARAM_X) {
unsigned i = TILEX_PROCF(f, max);
i = (i << 4) | TILEX_LOW_BITS(f, max);
return (i << 14) | (TILEX_PROCF((f + one), max));
}
void SCALE_FILTER_NAME(const SkBitmapProcState& s,
uint32_t xy[], int count, int x, int y) {
SkASSERT((s.fInvType & ~(SkMatrix::kTranslate_Mask |
SkMatrix::kScale_Mask)) == 0);
SkASSERT(s.fInvKy == 0);
PREAMBLE(s);
const unsigned maxX = s.fBitmap->width() - 1;
const SkFixed one = s.fFilterOneX;
const SkFractionalInt dx = s.fInvSxFractionalInt;
SkFractionalInt fx;
{
SkPoint pt;
s.fInvProc(s.fInvMatrix, SkIntToScalar(x) + SK_ScalarHalf,
SkIntToScalar(y) + SK_ScalarHalf, &pt);
const SkFixed fy = SkScalarToFixed(pt.fY) - (s.fFilterOneY >> 1);
const unsigned maxY = s.fBitmap->height() - 1;
// compute our two Y values up front
*xy++ = PACK_FILTER_Y_NAME(fy, maxY, s.fFilterOneY PREAMBLE_ARG_Y);
// now initialize fx
fx = SkScalarToFractionalInt(pt.fX) - (SkFixedToFractionalInt(one) >> 1);
}
#ifdef CHECK_FOR_DECAL
if (can_truncate_to_fixed_for_decal(fx, dx, count, maxX)) {
decal_filter_scale(xy, SkFractionalIntToFixed(fx),
SkFractionalIntToFixed(dx), count);
} else
#endif
{
do {
SkFixed fixedFx = SkFractionalIntToFixed(fx);
*xy++ = PACK_FILTER_X_NAME(fixedFx, maxX, one PREAMBLE_ARG_X);
fx += dx;
} while (--count != 0);
}
}
void AFFINE_FILTER_NAME(const SkBitmapProcState& s,
uint32_t xy[], int count, int x, int y) {
SkASSERT(s.fInvType & SkMatrix::kAffine_Mask);
SkASSERT((s.fInvType & ~(SkMatrix::kTranslate_Mask |
SkMatrix::kScale_Mask |
SkMatrix::kAffine_Mask)) == 0);
PREAMBLE(s);
SkPoint srcPt;
s.fInvProc(s.fInvMatrix,
SkIntToScalar(x) + SK_ScalarHalf,
SkIntToScalar(y) + SK_ScalarHalf, &srcPt);
SkFixed oneX = s.fFilterOneX;
SkFixed oneY = s.fFilterOneY;
SkFixed fx = SkScalarToFixed(srcPt.fX) - (oneX >> 1);
SkFixed fy = SkScalarToFixed(srcPt.fY) - (oneY >> 1);
SkFixed dx = s.fInvSx;
SkFixed dy = s.fInvKy;
unsigned maxX = s.fBitmap->width() - 1;
unsigned maxY = s.fBitmap->height() - 1;
do {
*xy++ = PACK_FILTER_Y_NAME(fy, maxY, oneY PREAMBLE_ARG_Y);
fy += dy;
*xy++ = PACK_FILTER_X_NAME(fx, maxX, oneX PREAMBLE_ARG_X);
fx += dx;
} while (--count != 0);
}
void PERSP_FILTER_NAME(const SkBitmapProcState& s,
uint32_t* SK_RESTRICT xy, int count,
int x, int y) {
SkASSERT(s.fInvType & SkMatrix::kPerspective_Mask);
PREAMBLE(s);
unsigned maxX = s.fBitmap->width() - 1;
unsigned maxY = s.fBitmap->height() - 1;
SkFixed oneX = s.fFilterOneX;
SkFixed oneY = s.fFilterOneY;
SkPerspIter iter(s.fInvMatrix,
SkIntToScalar(x) + SK_ScalarHalf,
SkIntToScalar(y) + SK_ScalarHalf, count);
while ((count = iter.next()) != 0) {
const SkFixed* SK_RESTRICT srcXY = iter.getXY();
do {
*xy++ = PACK_FILTER_Y_NAME(srcXY[1] - (oneY >> 1), maxY,
oneY PREAMBLE_ARG_Y);
*xy++ = PACK_FILTER_X_NAME(srcXY[0] - (oneX >> 1), maxX,
oneX PREAMBLE_ARG_X);
srcXY += 2;
} while (--count != 0);
}
}
#undef MAKENAME
#undef TILEX_PROCF
#undef TILEY_PROCF
#ifdef CHECK_FOR_DECAL
#undef CHECK_FOR_DECAL
#endif
#undef SCALE_FILTER_NAME
#undef AFFINE_FILTER_NAME
#undef PERSP_FILTER_NAME
#undef PREAMBLE
#undef PREAMBLE_PARAM_X
#undef PREAMBLE_PARAM_Y
#undef PREAMBLE_ARG_X
#undef PREAMBLE_ARG_Y
#undef TILEX_LOW_BITS
#undef TILEY_LOW_BITS
然后我们就清楚了,这些函数名是用宏组合出来的。(神一般的代码。。。。。)
怎么算坐标的不详述了,主要按原理去推就可以了,坐标计算有三种模式:CLAMP(越界时限制在边界)、REPEAT(越界时从开头取起)、MIRROR(越界时取样方向倒转去取)。
sampleProc函数也是类似的方法组合出来的,不详述。
三、高级插值算法
双线性插值虽然在一般情况下够用了,但在放大图片时,效果还是不够好。需要更好的效果,可以用高级插值算法,代价是性能的大幅消耗。
高级插值算法目前在Android的Java代码处是走不进去的,不知道chromium是否用到。
几个要点:
1、在 setBitmapFilterProcs 时判断高级插值是否支持,若支持,设置 shaderProc 为 highQualityFilter32/highQualityFilter16(也就是独立计算坐标和采样像素)
2、highQualityFilter先通过变换矩阵计算原始点。
3、highQualityFilter根据 SkBitmapFilter 的采样窗口,将这个窗口中的所有点按其与原始点矩离,查询对应权重值,然后相加,得到最终像素点。
4、SkBitmapFilter 采用查表法去给出权重值,预计算由子类完成。
5、目前Skia库用的是双三次插值 mitchell 法。
SK_CONF_DECLARE(const char *, c_bitmapFilter, "bitmap.filter", "mitchell", "Which scanline bitmap filter to use [mitchell, lanczos, hamming, gaussian, triangle, box]");
详细代码见 external/skia/src/core/SkBitmapFilter.cpp,尽量这部分代码几乎无用武之地,但里面的公式很值得借鉴,随便改改就能做成 glsl shader 用。
看完这段代码,可以作不负责任的猜想:Skia设计之初,只考虑了近邻插值和双线性插值两种情况,因此采用这种模板方法,可以最小化代码量。而且MatrixProc和SampleProc可以后续分别作SIMD优化(Intel的SSE和ARM的Neon),以提高性能。
但是对于线性插值,两步法(取值——采样)在算法实现上本来就不是最优的,后面又不得不引入shader函数,应对一些场景做优化。高阶插值无法在这个设计下实现,因此又像补丁一样打上去。
四、总结
看完这一部分代码,有三个感受。
第一:绘张图片看上去一件简单的事,在渲染执行时,真心不容易,如果追求效果,还会有各种各样的花样。
第二:在性能有要求的场景下,用模板真是灾难:函数改写时,遇到模板,就不得不重新定义函数,并替换之,弄得代码看上去一下子混乱不少。
第三:从图像绘制这个角度上看,skia渲染性能虽然确实很好了,但远没有达到极限,仍然是有一定的优化空间的,如果这部分出现了性能问题,还是能做一定的优化的。关于Skia性能的讨论将放到介绍Skia系列的最后一章。
第四:OpenGL+glsl确实是轻松且高效多了,软件渲染在复杂场景上性能很有限。

















 6020
6020

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









