






翻译自:Getting Started With Storm (作者:Jonathan Leibiusky, Gabriel Eisbruch and Dario Simonassi)
由于本人英文水平和理解有限,翻译难免错误,还望大家多多指正,请联系storm_getstarted@126.com
欢迎大家留言跟帖或邮件至storm_getstarted@126.com,共同学习Storm
在这一章,我们将动手创建一个Storm项目和第一个Storm topology。
下面假定你已经安装了最新的Jre 1.6。我们推荐使用Oracle提供的JRE,你可以在http://www.java.com/downloads/找到。
操作模式
在我们开始操作之前,理解Storm的操作方式是很重要的。运行Storm有两种方式。
本地模式
在本地模式下,Storm拓扑(topology)运行在本地机器的单个JVM中。这种模式被用于开发、测试和调试,因为它非常容易观察到所有的拓扑组件一起工作。在这种模式下,我们可以调整参数使我们看到我们的拓扑在不同的Storm配置环境下的运行状况。要在本地模式下运行拓扑,我们必须下载Storm开发依赖包,它们负责开发和测试我们的拓扑的所有事情。我们将在我们创建第一个Storm项目时见到。
在本地模式下运行一个拓扑和在Storm集群中运行时相似的。然而,确保所有的组件式线程安全的非常重要,因为当它们以远程模式部署时(即在不同的JVM或不同的物理机器)将不会有直接通信和共享内存。
在本章的所有示例中,我们将以本地模式运行。
远程模式
在远程模式下,我们向Storm集群提交拓扑。Storm集群由很多进程组成,通常运行在不同的机器中。远程模式不会显示调试信息,这也是它也被认为是生产模式的原因。然而,也可以在单个开发机器上创建一个Storm集群,为了确保在生产环境下运行拓扑不会有任何问题,在部署到生产环境前这么做是一个好方法。
你将会在第六章学习到更多有关远程模式的内容,我将在附录B中告诉你如何安装一个集群。
Hello World Storm
在这个项目中,我们将创建一个计数单词的简单拓扑。我们可以叫这个Storm拓扑为“Hello World”。然而,这个一个非常强大的拓扑,因为它可以扩展到几乎无限的大小,同时在一些小的修改后还可以使用它来构建一个统计系统。例如,我们可以修改项目来找Twitter中热门话题。
创建拓扑,我们需要使用一个spout来负责读入单词,第一个bolt来标准化单词,第二个bolt来计数单词,如图2-1所示。
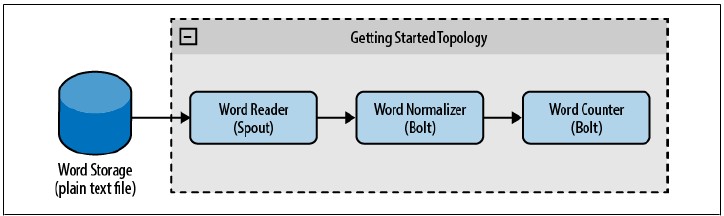
图2-1 topology初步
你可以在https://github.com/storm-book/examples-ch02-getting_started/zipball/master
下载示例zip形式源代码。
如果你使用git(分布式的版本控制和源代码管理),你可以在你想要存储源代码的目录中运行git clone git@github.com:storm-book/examples-ch02-getting_started.git
检查Java安装
创建环境的第一步是检查你正在运行的Java版本。打开一个windows终端,运行命令java –version。我们可以看到类似下面的内容。
java -version
java version "1.6.0_26"
Java(TM) SE Runtime Environment (build 1.6.0_26-b03)
Java HotSpot(TM) Server VM (build 20.1-b02, mixed mode)如果不是,检查Java安装。(查看http://www.java.com/download/)
创建项目
首先创建一个你准备存放应用的文件夹(如其它Java应用一样)。这个文件夹将用于存放项目源代码。
下一步,我们需要下载Storm依赖包:将会被加入到应用类路径(classpath)的jar包集。你可以在下面两种方式中任选其一来完成。
l 下载依赖包,解压,加入到项目类路径
l 使用Apache Maven
Maven是一个软件项目管理和理解工具。它可以被用于管理一个项目开发周期的多个方面,从依赖到发布构建过程。在这本书,我们将广泛地使用它。要检查maven是否已安装,运行命令mvn。如果没有,你可以在http://maven.apache.org/download.html下载到它。
尽管为了使用Storm成为Maven专家是没有必要的,但了解Maven是如何工作的还是很有用的。你可以在Apache Maven站点(http://maven.apache.org/)了解到更多相关内容。
定义项目结构,首先需要创建pom.xml(Project objectmodel,项目对象模型)文件,它描述了项目依赖包、如何打包、源代码等等。我们将使用由nathanmarz(https://github.com/nathanmarz/)建立的Maven依赖仓库,具体位置在https://github.com/nathanmarz/storm/wiki/Maven。
Storm的Maven依赖包包含了所有在本地模式下运行Storm所需的库。
使用这些依赖,我们可以创建一个运行我们的拓扑所必须的基本的组件的描述文件pom.xml。
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>storm.book</groupId>
<artifactId>Getting-Started</artifactId>
<version>0.0.1-SNAPSHOT</version>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.6</source>
<target>1.6</target>
<compilerVersion>1.6</compilerVersion>
</configuration>
</plugin>
</plugins>
</build>
<repositories>
<!-- Repository where we can found the storm dependencies -->
<repository>
<id>clojars.org</id>
<url>http://clojars.org/repo</url>
</repository>
</repositories>
<dependencies>
<!-- Storm Dependency -->
<dependency>
<groupId>storm</groupId>
<artifactId>storm</artifactId>
<version>0.6.0</version>
</dependency>
</dependencies>
</project>前几行指定项目名和版本。接下来,加入一个编译器插件,告诉Maven代码必须使用Java1.6进行编译。下一步定义了仓库(Maven支持同一个项目多个仓库)。Clojars是一个存放Storm依赖的仓库。Maven将自动下载所有在本地模式下运行Storm所需的子依赖包。
对于一个典型的Maven Java项目,将会是如下结构。
our-application-folder/
├── pom.xml
└── src
└── main
└── java
├── spouts
└── bolts
└── resources
文件夹下将包含我们的源代码,同时Word文件将会被放入resource文件夹下处理。
命令mkdir –p 会创建所需的所有父目录。
创建我们的第一个拓扑
构建我们的第一个拓扑,我们将创建所有的运行单词计数的类。可能在这个阶段有一部分示例不够清晰,但我们将在接下来的章节进行解释。
Spout
WordReader是一个spout类,它将实现接口IRichSpout。我们将在第四章了解到更多细节。WordReader负责读入文件,并将每行提供给bolt进一步处理。
Spout发送一个定义的字段列表。这种架构允许spout定义字段来让其它bolts消费,不同的bolt可以从相同的spout流中读入数据。
示例2-1包含了完整的类代码(我们将按照示例来分析代码的每个部分)。
示例2-1src/main/java/spouts/WordReader.java
package spouts;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.util.Map;
importbacktype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichSpout;
importbacktype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
public class WordReader implements IRichSpout {
private SpoutOutputCollector collector;
private FileReader fileReader;
private boolean completed = false;
private TopologyContext context;
public boolean isDistributed() {return false;}
public void ack(Object msgId) {
System.out.println("OK:"+msgId);
}
public void close() {}
public void fail(Object msgId) {
System.out.println("FAIL:"+msgId);
}
/**
* The only thing that the methods will do It is emit each
* file line
*/
public void nextTuple() {
/**
* The nextuple it is called forever, so if we have been readed the file
* we will wait and then return
*/
if(completed){
try {
Thread.sleep(1000);
} catch (InterruptedExceptione) {
//Do nothing
}
return;
}
String str;
//Open the reader
BufferedReader reader = new BufferedReader(fileReader);
try{
//Read all lines
while((str = reader.readLine())!= null){
/**
* By each line emmit a new value with the line as a their
*/
this.collector.emit(new Values(str),str);
}
}catch(Exception e){
throw new RuntimeException("Errorreading tuple",e);
}finally{
completed = true;
}
}
/**
* We will create the file and get the collector object
*/
public void open(Map conf,TopologyContext context,
SpoutOutputCollector collector) {
try {
this.context = context;
this.fileReader = new FileReader(conf.get("wordsFile").toString());
} catch (FileNotFoundExceptione) {
throw new RuntimeException("Errorreading file
["+conf.get("wordFile")+"]");
}
this.collector = collector;
}
/**
* Declare the output field "word"
*/
public void declareOutputFields(OutputFieldsDeclarerdeclarer) {
declarer.declare(new Fields("line"));
}
}public void open(Map conf,TopologyContext ontext, SpoutOutputCollector collector)是所有spout被调用的第一个方法。接收参数包括:TopologyContext,包含所有拓扑数据;conf,在拓扑定义时创建;SpoutOutputCollector,允许我们向bolts发送要处理的数据。接下来的代码是open方法的实现:
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
try {
this.context = context;
this.fileReader = newFileReader(conf.get("wordsFile").toString());
} catch (FileNotFoundException e) {
throw new RuntimeException("Error reading file ["+conf.get("wordFile")+"]");
}
this.collector = collector;
}在这个方法中创建了一个reader,它负责读取文件。接下来,我们需要实现public voidnextTuple(),它将向bolts发送要处理的数据。在我们的示例中,该方法将读入文件并将每行数据作为一个值发送。
public void nextTuple() {
if(completed){
try {
Thread.sleep(1);
} catch (InterruptedException e) {
//Do nothing
}
return;
}
String str;
BufferedReader reader = new BufferedReader(fileReader);
try{
while((str = reader.readLine()) != null){
this.collector.emit(new Values(str));
}
}catch(Exception e){
throw new RuntimeException("Error reading tuple",e);
}finally{
completed = true;
}
}Values是ArrayList的实现,链表的元素被传入到构造函数中。
nextTuple方法和ack()、fail()方法被以相同周期地调用。在没有要做的事情时,它必须释放线程的控制权,以使其它方法有机会被调用。所以,nextTuple方法的第一行检查工作是否已完成。如果这样,它将会在重新运行前休息至少1ms来降低处理器负载。如果有工作要做,文件的每行内容将被作为一个值发送。
Tuple是一个命名的值的列表,值可以是任意类型的Java对象(只要是可序列号对象)。默认情况下,Storm可以序列通用的类型,包括字符串、字节数组、ArrayList、HashMap和HashSet等。
Bolts
现在我们已经拥有一个从文件读入并发送每行内容作为tuple的一个spout。接下来,我们需要创建两个bolts来处理这些tuple(如图2-1)。这些bolt均实现backtype.storm.topology.IRichBolt接口。
Bolt中最重要的方法是voidexecute(Tuple input),一旦有tuple输入它就会被调用。Bolt对每个tuple处理后可以发送多个tuple。
Bolt和spout可以发送任意多的tuple。当nextTuple或execute方法被调用时,它们可以发送0,1或多个tuple。你将在第五章了解到更多相关内容。
第一个bolt,WordNormalizer,将负责处理每行并标准化。它将行拆分为单词,强制转换所有单词为小写和去掉前后空白字符。
首先,我们需要声明bolt的输出参数:
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}这里,我们声明bolt发送一个名为word的字段。
接下来,我们实现方法public void execute(Tupleinput),负责处理每个tuple输入。
public void execute(Tuple input) {
String sentence = input.getString(0);
String[] words = sentence.split(" ");
for(String word : words){
word = word.trim();
if(!word.isEmpty()){
word = word.toLowerCase();
//Emit the word
collector.emit(new Values(word));
}
}
// Acknowledge the tuple
collector.ack(input);
}第一行从tuple中读入值。值可以按名字或按索引位置读取。值被处理并使用collector对象发送。每一个tuple被处理后,collector的ack方法被调用以指示处理已经完全成功。如果tuple不能被处理,collector的fail方法将会被调用。
示例2-2包含了类的完整代码
示例2-2src/main/java/bolts/WordNormalizer.java
package bolts;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
public class WordNormalizer implements IRichBolt {
private OutputCollector collector;
public void cleanup() {}
/**
* The bolt will receive the line from the
* words file and process it to Normalize this line
*
* The normalize will be put the words in lower case
* and split the line to get all words in this
*/
public void execute(Tuple input) {
String sentence = input.getString(0);
String[] words = sentence.split(" ");
for(String word : words){
word = word.trim();
if(!word.isEmpty()){
word = word.toLowerCase();
//Emit the word
List a = new ArrayList();
a.add(input);
collector.emit(a,new Values(word));
}
}
// Acknowledge the tuple
collector.ack(input);
}
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.collector = collector;
}
/**
* The bolt will only emit the field "word"
*/
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}在这个类中,可以看到在单个execute调用中发送了多个tuple。如果方法接收到句子This is the Stormbook,在单次调用后,将会发送五个新的tuple。
下一个bolt,WordCounter,它负责单词计数。当拓扑完成时(即当cleanup方法被调用时),我们将看到每个单词的数目。
这是一个bolt不发送任何tuple的示例。在本例中,数据被加入到map中,但实际环境下可以将数据存储到数据库中。
package bolts;
import java.util.HashMap;
import java.util.Map;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class WordCounter implements IRichBolt {
Integer id;
String name;
Map<String, Integer> counters;
private OutputCollector collector;
/**
* At the end of the spout (when the cluster is shutdown
* We will show the word counters
*/
@Override
public void cleanup() {
System.out.println("-- Word Counter["+name+"-"+id+"] --");
for(Map.Entry<String, Integer> entry : counters.entrySet()){
System.out.println(entry.getKey()+": "+entry.getValue());
}
}
/**
* On each word We will count
*/
@Override
public void execute(Tuple input) {
String str = input.getString(0);
/**
* If the word dosn't exist in the map we will create
* this, if not We will add 1
*/
if(!counters.containsKey(str)){
counters.put(str, 1);
}else{
Integer c = counters.get(str) + 1;
counters.put(str, c);
}
//Set the tuple as Acknowledge
collector.ack(input);
}
/**
* On create
*/
@Override
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.counters = new HashMap<String, Integer>();
this.collector = collector;
this.name = context.getThisComponentId();
this.id = context.getThisTaskId();
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {}
}execute方法使用map来收集和单词的计算。当拓扑结束时,cleanup方法被调用并打印出计数map。(这仅仅是个示例,通常你在拓扑关闭时,需要使用cleanup方法来关闭主动连接和其它资源)
Main函数
在这个主函数中,我们将创建一个topology和一个LocalCluster对象,使你可以在本地测试和调试这个topology。结合Config对象,LocalCluster允许你试验不同的集群配置。例如,如果一个全局或类变量被偶然使用,你会在测试使用不同数目的workers时发现错误。(你会在第三章了解到更多有关config对象的知识)
所有的拓扑节点均应独立允许,而不能有进程间共享数据(例如无全局或类变量)。因为当拓扑运行在真实集群中时,这些进程可能运行在不同机器中。
我们将使用TopologyBuilder创建一个拓扑,它向Storm指定了节点的排列和数据的交换方式。
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("word-reader",new WordReader());
builder.setBolt("word-normalizer", newWordNormalizer()).shuffleGrouping("wordreader");
builder.setBolt("word-counter", newWordCounter()).shuffleGrouping("wordnormalizer");
spout和bolts使用shuffleGroupings相连,Storm的这种分组方式决定了从源节点向目标节点以随机分发的方式发送消息。
接下来,创建一个保护拓扑配置信息的config对象,它将会在运行时与集群配置合并,并通过prepare方法向所有节点发送。
Config conf = new Config();
conf.put("wordsFile", args[0]);
conf.setDebug(true);设置属性wordsFile值为spout要读入的文件名,在开发环境下设置debug为true。当debug为true时,Storm将会打印出所有节点间的交换消息和其它对理解拓扑如何运行有用的信息。
如之前解释的,我们将使用LocalCluster对象来运行拓扑。在生产环境下,拓扑时持续运行的,但是对于我们的例子,我们只会运行拓扑几秒钟以便你可以看到结果。
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("Getting-Started-Toplogie", conf,builder.createTopology());
Thread.sleep(2000);
cluster.shutdown();使用createTopology、submitTopology方法创建和运行拓扑,休息2s(拓扑运行于不同的线程),接下来通过关闭集群来停止拓扑。
示例2-3汇总了所有代码。
示例2-3src/main/java/TopologyMain.java
import spouts.WordReader;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
import bolts.WordCounter;
import bolts.WordNormalizer;
public class TopologyMain {
public static void main(String[] args) throws InterruptedException {
//Topology definition
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("word-reader",new WordReader());
builder.setBolt("word-normalizer", new WordNormalizer())
.shuffleGrouping("word-reader");
builder.setBolt("word-counter", new WordCounter(),2)
.fieldsGrouping("word-normalizer", newFields("word"));
//Configuration
Config conf = new Config();
conf.put("wordsFile", args[0]);
conf.setDebug(false);
//Topology run
conf.put(Config.TOPOLOGY_MAX_SPOUT_PENDING, 1);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("Getting-Started-Toplogie", conf,
builder.createTopology());
Thread.sleep(1000);
cluster.shutdown();
}
}查看运行结果
你已经准备好运行你的第一个拓扑了!如果你创建一个拥有一行内容的src/main/resources/words.txt的文件,你就可以使用以下命令来运行拓扑:mvn exec:java-Dexec.mainClass="TopologyMain" -Dexec.args="src/main/resources/words.txt"
例如,你使用如下的words.txt文件
Storm
test
are
great
is
an
Storm
simple
application
but
very
powerful
really
Storm
is
great在日志中,你会看到类似如下内容:
is: 2
application: 1
but: 1
great: 1
test: 1
simple: 1
Storm: 3
really: 1
are: 1
great: 1
an: 1
powerful: 1
very: 1在这个示例中,你仅仅使用在每个节点上运行单个实例。如果你有一个很大的日志文件怎么办?你可以轻易地改变在系统中节点的数目来并行完成这个工作。在本例中,你将创建两个WordCounter实例:
builder.setBolt("word-counter", new WordCounter(),2)
.shuffleGrouping("word-normalizer");如果你重新运行这个项目,你将会看到
-- Word Counter [word-counter-2] --
application: 1
is: 1
great: 1
are: 1
powerful: 1
Storm: 3
-- Word Counter [word-counter-3] --
really: 1
is: 1
but: 1
great: 1
test: 1
simple: 1
an: 1
very: 1太好了!很简单地改变了并行级别(当然在实际中,每个实例会运行在单独的机器中)。但是这似乎有一个问题:单词is和great在每个WordCounter实例中计数了一次。为什么?当你使用shuffleGrouping时,等于告诉Storm以随机分发方式发送消息给每个bolt。在这个示例中,理想是将相同的单词发送给相同的WordCounter实例。要做到这一点,你可以将shuffleGrouping(“word-normalizer”)改为fieldsGrouping(“word-normalizer”,newFields(“word”))。重运行一次确认一下结果。你将在接下来的章节了解到分组和消息流的更多内容。
结论
我们已经讨论了Storm的本地模式和远程操作模式的区别,Storm的强大威力和开发的简单。在接下来的章节,你将会学习到更多Storm更深层次的基本概念。















 2512
2512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









