










python接口的实现及说明详见:【pytorch】将模型部署至生产环境:借助TensorRT 8完成代码优化及部署(一):python接口实现
(一)转换思路及模型准备:
转换思路为:pytorch -> onnx -> onnx2trt -> TensorRT
其中pytorch -> onnx详见上一篇博文。
(二)代码实现:该代码是在官方样例sampleOnnxMNIST的基础上修改而来的。
#include "argsParser.h"
#include "buffers.h"
#include "common.h"
#include "logger.h"
#include "parserOnnxConfig.h"
#include "NvInfer.h"
#include <cuda_runtime_api.h>
#include <opencv.hpp>
#include <cstdlib>
#include <fstream>
#include <iostream>
#include <sstream>
//创建一个可自动析构的智能指针,该指针的模板在samplesCommon函数中提供
using samplesCommon::SampleUniquePtr;
class OnnxForTensorRT
{
public:
OnnxForTensorRT(const samplesCommon::OnnxSampleParams& params)
: mParams(params)
, mEngine(nullptr)
{
}
//!
//! \brief Function builds the network engine
//!
bool build();
//!
//! \brief Runs the TensorRT inference engine for this sample
//!
bool infer();
private:
//输入参数的集合:
samplesCommon::OnnxSampleParams mParams; //!< The parameters for the sample.
nvinfer1::Dims mInputDims; //!< The dimensions of the input to the network.
nvinfer1::Dims mOutputDims; //!< The dimensions of the output to the network.
int mNumber{0}; //!< The number to classify
std::shared_ptr<nvinfer1::ICudaEngine> mEngine; //!引擎保存处
//opencv图片转至tensorRT所需格式:
std::vector<float> OnnxForTensorRT::prepareImage(std::vector<cv::Mat>& vec_img);
//!
//! \brief Parses an ONNX model for MNIST and creates a TensorRT network
//!
bool constructNetwork(SampleUniquePtr<nvinfer1::IBuilder>& builder,
SampleUniquePtr<nvinfer1::INetworkDefinition>& network, SampleUniquePtr<nvinfer1::IBuilderConfig>& config,
SampleUniquePtr<nvonnxparser::IParser>& parser);
//!
//! \brief Reads the input and stores the result in a managed buffer
//!
bool processInput(const samplesCommon::BufferManager& buffers);
//!
//! \brief Classifies digits and verify result
//!
bool verifyOutput(const samplesCommon::BufferManager& buffers);
};
//!
//! \brief Creates the network, configures the builder and creates the network engine
//!
//! \details This function creates the Onnx MNIST network by parsing the Onnx model and builds
//! the engine that will be used to run MNIST (mEngine)
//!
//! \return Returns true if the engine was created successfully and false otherwise
//!
bool OnnxForTensorRT::build()
{
auto builder = SampleUniquePtr<nvinfer1::IBuilder>(nvinfer1::createInferBuilder(sample::gLogger.getTRTLogger()));
if (!builder)
{
return false;
}
//第一维为动态:
const auto explicitBatch = 1U << static_cast<uint32_t>(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
auto network = SampleUniquePtr<nvinfer1::INetworkDefinition>(builder->createNetworkV2(explicitBatch));
if (!network)
{
return false;
}
auto config = SampleUniquePtr<nvinfer1::IBuilderConfig>(builder->createBuilderConfig());
if (!config)
{
return false;
}
auto parser
= SampleUniquePtr<nvonnxparser::IParser>(nvonnxparser::createParser(*network, sample::gLogger.getTRTLogger()));
if (!parser)
{
return false;
}
auto constructed = constructNetwork(builder, network, config, parser);
if (!constructed)
{
return false;
}
// CUDA stream used for profiling by the builder.
auto profileStream = samplesCommon::makeCudaStream();
if (!profileStream)
{
return false;
}
config->setProfileStream(*profileStream);
//设置最大批,由算法推理出应创建的引擎大小:
builder->setMaxBatchSize(8);
//设置动态维度的最大及最小值
nvinfer1::IOptimizationProfile* profile = builder->createOptimizationProfile();
profile->setDimensions("input", OptProfileSelector::kMIN, Dims4(1,3, 32, 32));
profile->setDimensions("input", OptProfileSelector::kOPT, Dims4(1, 3, 32, 32));
profile->setDimensions("input", OptProfileSelector::kMAX, Dims4(8, 3, 32, 32));
config->addOptimizationProfile(profile);
//这里序列化出的引擎文件不能跨平台或TensorRT版本移植。引擎是特定于确切的GPU模型
SampleUniquePtr<IHostMemory> plan{builder->buildSerializedNetwork(*network, *config)};
if (!plan)
{
return false;
}
std::ofstream engineFile("./class10.trt", std::ios::binary);
if (!engineFile)
{
std::cout << "Cannot open engine file: " << "./class10.trt" << std::endl;
return false;
}
engineFile.write(static_cast<char*>(plan->data()), plan->size());
std::cout << "已序列化模型";
return !engineFile.fail();
return true;
}
//!
//! \brief Uses a ONNX parser to create the Onnx MNIST Network and marks the
//! output layers
//!
//! \param network Pointer to the network that will be populated with the Onnx MNIST network
//!
//! \param builder Pointer to the engine builder
//!
bool OnnxForTensorRT::constructNetwork(SampleUniquePtr<nvinfer1::IBuilder>& builder,
SampleUniquePtr<nvinfer1::INetworkDefinition>& network, SampleUniquePtr<nvinfer1::IBuilderConfig>& config,
SampleUniquePtr<nvonnxparser::IParser>& parser)
{//locateFile:用于定位目标文件用:给出部分文件路径,从当前路径及其父路径,最多找10层,返回文件的完整路径
auto parsed = parser->parseFromFile(locateFile(mParams.onnxFileName, mParams.dataDirs).c_str(),
static_cast<int>(sample::gLogger.getReportableSeverity()));
if (!parsed)
{
return false;
}
if (mParams.fp16)
{
config->setFlag(BuilderFlag::kFP16);
}
if (mParams.int8)
{
config->setFlag(BuilderFlag::kINT8);
samplesCommon::setAllDynamicRanges(network.get(), 127.0f, 127.0f);
}
samplesCommon::enableDLA(builder.get(), config.get(), mParams.dlaCore);
return true;
}
//!
//! \brief Runs the TensorRT inference engine for this sample
//!
//! \details This function is the main execution function of the sample. It allocates the buffer,
//! sets inputs and executes the engine.
//!
bool OnnxForTensorRT::infer()
{
//读取反序列化的trt模型:
SampleUniquePtr<IRuntime> runtime{ createInferRuntime(sample::gLogger.getTRTLogger()) };
if (!runtime)
{
return false;
}
runtime->setDLACore(mParams.dlaCore);
std::ifstream engineFile("./class10.trt", std::ios::binary);
if (!engineFile)
{
std::cout << "Error opening engine file: " << "./class10.trt" << std::endl;
return nullptr;
}
engineFile.seekg(0, engineFile.end);
long int fsize = engineFile.tellg();
engineFile.seekg(0, engineFile.beg);
std::vector<char> engineData(fsize);
engineFile.read(engineData.data(), fsize);
if (!engineFile)
{
std::cout << "Error loading engine file: " << "./class10.trt" << std::endl;
return nullptr;
}
//这里反序列化引擎文件变成引擎
mEngine = std::shared_ptr<nvinfer1::ICudaEngine>(
runtime->deserializeCudaEngine(engineData.data(), fsize, nullptr), samplesCommon::InferDeleter());
if (!mEngine)
{
return false;
}
//设置输入向量的维度大小:这里batch是动态的,所以第一维得出是-1,其实应该为1
mInputDims = mEngine->getBindingDimensions(0);
mInputDims.d[0] = mParams.batchSize;
//设置输出维度,10分类:
mOutputDims = Dims2(1,10);
//this->mInputDims = Dims4(1, 3, 32, 32);
//通过mEngine创建buffer
samplesCommon::BufferManager buffers(mEngine, mParams.batchSize);
//通过mEngine创建Context
auto context = SampleUniquePtr<nvinfer1::IExecutionContext>(mEngine->createExecutionContext());
//设置实际的批大小
context->setBindingDimensions(0, mInputDims);
if (!context)
{
return false;
}
//将图片输入存入buffers
if (!processInput(buffers))
{
return false;
}
//将buffer从本地内存读至GPU显存
buffers.copyInputToDevice();
//执行推理
bool status = context->execute(mParams.batchSize,buffers.getDeviceBindings().data());
if (!status)
{
return false;
}
//推理结果返回本地内存
buffers.copyOutputToHost();
// Verify results
if (!verifyOutput(buffers))
{
return false;
}
return true;
}
//!
//! \brief Reads the input and stores the result in a managed buffer
//!
bool OnnxForTensorRT::processInput(const samplesCommon::BufferManager& buffers)
{
const int inputH = mInputDims.d[3];
const int inputW = mInputDims.d[2];
const int batch = mInputDims.d[0];
const int channel = mInputDims.d[1];
//使用opencv读取图片,并转换通道为rgb以适应模型,cv::IMREAD_COLOR将任何图像均转为BGR彩色图像(三通道)进行读取
cv::Mat img = cv::imread("C://Users//25360//Desktop//monodepth.jpeg", cv::IMREAD_COLOR);
cv::cvtColor(img, img, cv::COLOR_BGR2RGB);
std::vector<cv::Mat> vec_img;
//这里测试输入只有一张图片:
vec_img.push_back(img);
std::vector<float> data=prepareImage(vec_img);
float* hostDataBuffer = static_cast<float*>(buffers.getHostBuffer(mParams.inputTensorNames[0]));
//opencv读取图片进行线性化为tensorRT需要的格式
for (int i = 0; i < inputH * inputW* batch* channel; i++)
{
hostDataBuffer[i] = data[i];
}
return true;
}
//输入图片为OPENCV的//HWC图片
std::vector<float> OnnxForTensorRT::prepareImage(std::vector<cv::Mat>& vec_img) {
const int inputH = mInputDims.d[3];
const int inputW = mInputDims.d[2];
const int batch = mInputDims.d[0];
const int channel = mInputDims.d[1];
std::vector<float> result(batch*channel * inputW * inputH);
float* data = result.data();
int index = 0;
for (const cv::Mat& src_img : vec_img)
{
if (!src_img.data)
continue;
cv::Mat flt_img = cv::Mat::zeros(cv::Size(inputW, inputH), src_img.type());
cv::Mat rsz_img;
cv::resize(src_img, flt_img, cv::Size(inputW, inputH));
flt_img.convertTo(flt_img, CV_32FC3);//, , 1.0 / 255
//HWC TO CHW
int channelLength = inputW * inputH;
std::vector<cv::Mat> split_img = {
cv::Mat(inputH, inputW, CV_32FC1, data + channelLength * (index + 2)), // Mat与result数据区域共享
cv::Mat(inputH, inputW, CV_32FC1, data + channelLength * (index + 1)),
cv::Mat(inputH, inputW, CV_32FC1, data + channelLength * index)
};
index += 3;
cv::split(flt_img, split_img); // 通道分离
}
return result; // result与split_img的数据共享
}
//!
//! \brief Classifies digits and verify result
//!
//! \return whether the classification output matches expectations
//!
bool OnnxForTensorRT::verifyOutput(const samplesCommon::BufferManager& buffers)
{
const int outputSize = mOutputDims.d[1];
float* output = static_cast<float*>(buffers.getHostBuffer(mParams.outputTensorNames[0]));
std::cout << "输出结果为";
for (int i = 0; i < outputSize; i++)
{
std::cout <<output[i] << " ";
}
return true;
}
//!
//! \brief Initializes members of the params struct using the command line args
//!
samplesCommon::OnnxSampleParams initializeSampleParams(const samplesCommon::Args& args)
{
samplesCommon::OnnxSampleParams params;
if (args.dataDirs.empty()) // Use default directories if user hasn't provided directory paths
{
params.dataDirs.push_back("data/mnist/");
params.dataDirs.push_back("data/samples/mnist/");
}
else // Use the data directory provided by the user
{
params.dataDirs = args.dataDirs;
}
params.onnxFileName = "modelForTensorRT.onnx";
params.inputTensorNames.push_back("input");
params.outputTensorNames.push_back("output");
params.dlaCore = args.useDLACore;
params.int8 = args.runInInt8;
params.fp16 = args.runInFp16;
return params;
}
//!
//! \brief Prints the help information for running this sample
//!
void printHelpInfo()
{
std::cout
<< "Usage: ./sample_onnx_mnist [-h or --help] [-d or --datadir=<path to data directory>] [--useDLACore=<int>]"
<< std::endl;
std::cout << "--help Display help information" << std::endl;
std::cout << "--datadir Specify path to a data directory, overriding the default. This option can be used "
"multiple times to add multiple directories. If no data directories are given, the default is to use "
"(data/samples/mnist/, data/mnist/)"
<< std::endl;
std::cout << "--useDLACore=N Specify a DLA engine for layers that support DLA. Value can range from 0 to n-1, "
"where n is the number of DLA engines on the platform."
<< std::endl;
std::cout << "--int8 Run in Int8 mode." << std::endl;
std::cout << "--fp16 Run in FP16 mode." << std::endl;
}
int main(int argc, char** argv)
{
samplesCommon::Args args;
args.batch = 1;
//给出放置onnx的路径:
args.dataDirs.push_back("class10");
//这里不再使用外部传入参数的形式:
bool argsOK = true;//samplesCommon::parseArgs(args, argc, argv);
if (!argsOK)
{
sample::gLogError << "Invalid arguments" << std::endl;
//printHelpInfo();
return EXIT_FAILURE;
}
//if (args.help)
//{
// printHelpInfo();
// return EXIT_SUCCESS;
//}
//定义测试名:创建日志管理器gLogger
auto sampleTest = sample::gLogger.defineTest("TensorRTForClass10", argc, argv);
sample::gLogger.reportTestStart(sampleTest);
OnnxForTensorRT sample(initializeSampleParams(args));
//下面的预编译标志,在序列化模型时为1,完成onnx->.trt,进行推断时为0:
#if 1
if (!sample.build())
{
return sample::gLogger.reportFail(sampleTest);
}
#else
//输入->Buffer->CUDA->执行推理->Buffer->输出
//Host就是本机内存,输入和输出最终都是要返回到Host的。
if (!sample.infer())
{
return sample::gLogger.reportFail(sampleTest);
}
#endif
return sample::gLogger.reportPass(sampleTest);
}
其中对于官方提供的样例公共类,为使公共类适用动态变换的batchsize,避免报assert(engine->hasImplicitBatchDimension() || mBatchSize == 0)的错误,将buffer.h中的BufferManager类修改为:
其余头文件引用官方样例:
class BufferManager
{
public:
static const size_t kINVALID_SIZE_VALUE = ~size_t(0);
//!
//! \brief Create a BufferManager for handling buffer interactions with engine.
//!
BufferManager(std::shared_ptr<nvinfer1::ICudaEngine> engine, const int batchSize = 0,
const nvinfer1::IExecutionContext* context = nullptr)
: mEngine(engine)
, mBatchSize(batchSize)
{
//hasImplicitBatchDimension()在无动态batchsize时返回true:
assert(!engine->hasImplicitBatchDimension() || mBatchSize == 0);
// Create host and device buffers
for (int i = 0; i < mEngine->getNbBindings(); i++)
{
auto dims = context ? context->getBindingDimensions(i) : mEngine->getBindingDimensions(i);
size_t vol = context || !mBatchSize ? 1 : static_cast<size_t>(mBatchSize);
nvinfer1::DataType type = mEngine->getBindingDataType(i);
int vecDim = mEngine->getBindingVectorizedDim(i);
if (-1 != vecDim) // i.e., 0 != lgScalarsPerVector
{
int scalarsPerVec = mEngine->getBindingComponentsPerElement(i);
dims.d[vecDim] = divUp(dims.d[vecDim], scalarsPerVec);
vol *= scalarsPerVec;
}
if (dims.d[0] == -1) dims.d[0] = vol;
vol *= samplesCommon::volume(dims);
std::unique_ptr<ManagedBuffer> manBuf{new ManagedBuffer()};
manBuf->deviceBuffer = DeviceBuffer(vol, type);
manBuf->hostBuffer = HostBuffer(vol, type);
mDeviceBindings.emplace_back(manBuf->deviceBuffer.data());
mManagedBuffers.emplace_back(std::move(manBuf));
}
}
//!
//! \brief Returns a vector of device buffers that you can use directly as
//! bindings for the execute and enqueue methods of IExecutionContext.
//!
std::vector<void*>& getDeviceBindings()
{
return mDeviceBindings;
}
//!
//! \brief Returns a vector of device buffers.
//!
const std::vector<void*>& getDeviceBindings() const
{
return mDeviceBindings;
}
//!
//! \brief Returns the device buffer corresponding to tensorName.
//! Returns nullptr if no such tensor can be found.
//!
void* getDeviceBuffer(const std::string& tensorName) const
{
return getBuffer(false, tensorName);
}
//!
//! \brief Returns the host buffer corresponding to tensorName.
//! Returns nullptr if no such tensor can be found.
//!
void* getHostBuffer(const std::string& tensorName) const
{
return getBuffer(true, tensorName);
}
//!
//! \brief Returns the size of the host and device buffers that correspond to tensorName.
//! Returns kINVALID_SIZE_VALUE if no such tensor can be found.
//!
size_t size(const std::string& tensorName) const
{
int index = mEngine->getBindingIndex(tensorName.c_str());
if (index == -1)
return kINVALID_SIZE_VALUE;
return mManagedBuffers[index]->hostBuffer.nbBytes();
}
//!
//! \brief Dump host buffer with specified tensorName to ostream.
//! Prints error message to std::ostream if no such tensor can be found.
//!
void dumpBuffer(std::ostream& os, const std::string& tensorName)
{
int index = mEngine->getBindingIndex(tensorName.c_str());
if (index == -1)
{
os << "Invalid tensor name" << std::endl;
return;
}
void* buf = mManagedBuffers[index]->hostBuffer.data();
size_t bufSize = mManagedBuffers[index]->hostBuffer.nbBytes();
nvinfer1::Dims bufDims = mEngine->getBindingDimensions(index);
size_t rowCount = static_cast<size_t>(bufDims.nbDims > 0 ? bufDims.d[bufDims.nbDims - 1] : mBatchSize);
int leadDim = mBatchSize;
int* trailDims = bufDims.d;
int nbDims = bufDims.nbDims;
// Fix explicit Dimension networks
if (!leadDim && nbDims > 0)
{
leadDim = bufDims.d[0];
++trailDims;
--nbDims;
}
os << "[" << leadDim;
for (int i = 0; i < nbDims; i++)
os << ", " << trailDims[i];
os << "]" << std::endl;
switch (mEngine->getBindingDataType(index))
{
case nvinfer1::DataType::kINT32: print<int32_t>(os, buf, bufSize, rowCount); break;
case nvinfer1::DataType::kFLOAT: print<float>(os, buf, bufSize, rowCount); break;
case nvinfer1::DataType::kHALF: print<half_float::half>(os, buf, bufSize, rowCount); break;
case nvinfer1::DataType::kINT8: assert(0 && "Int8 network-level input and output is not supported"); break;
case nvinfer1::DataType::kBOOL: assert(0 && "Bool network-level input and output are not supported"); break;
}
}
//!
//! \brief Templated print function that dumps buffers of arbitrary type to std::ostream.
//! rowCount parameter controls how many elements are on each line.
//! A rowCount of 1 means that there is only 1 element on each line.
//!
template <typename T>
void print(std::ostream& os, void* buf, size_t bufSize, size_t rowCount)
{
assert(rowCount != 0);
assert(bufSize % sizeof(T) == 0);
T* typedBuf = static_cast<T*>(buf);
size_t numItems = bufSize / sizeof(T);
for (int i = 0; i < static_cast<int>(numItems); i++)
{
// Handle rowCount == 1 case
if (rowCount == 1 && i != static_cast<int>(numItems) - 1)
os << typedBuf[i] << std::endl;
else if (rowCount == 1)
os << typedBuf[i];
// Handle rowCount > 1 case
else if (i % rowCount == 0)
os << typedBuf[i];
else if (i % rowCount == rowCount - 1)
os << " " << typedBuf[i] << std::endl;
else
os << " " << typedBuf[i];
}
}
//!
//! \brief Copy the contents of input host buffers to input device buffers synchronously.
//!
void copyInputToDevice()
{
memcpyBuffers(true, false, false);
}
//!
//! \brief Copy the contents of output device buffers to output host buffers synchronously.
//!
void copyOutputToHost()
{
memcpyBuffers(false, true, false);
}
//!
//! \brief Copy the contents of input host buffers to input device buffers asynchronously.
//!
void copyInputToDeviceAsync(const cudaStream_t& stream = 0)
{
memcpyBuffers(true, false, true, stream);
}
//!
//! \brief Copy the contents of output device buffers to output host buffers asynchronously.
//!
void copyOutputToHostAsync(const cudaStream_t& stream = 0)
{
memcpyBuffers(false, true, true, stream);
}
~BufferManager() = default;
private:
void* getBuffer(const bool isHost, const std::string& tensorName) const
{
int index = mEngine->getBindingIndex(tensorName.c_str());
if (index == -1)
return nullptr;
return (isHost ? mManagedBuffers[index]->hostBuffer.data() : mManagedBuffers[index]->deviceBuffer.data());
}
void memcpyBuffers(const bool copyInput, const bool deviceToHost, const bool async, const cudaStream_t& stream = 0)
{
for (int i = 0; i < mEngine->getNbBindings(); i++)
{
void* dstPtr
= deviceToHost ? mManagedBuffers[i]->hostBuffer.data() : mManagedBuffers[i]->deviceBuffer.data();
const void* srcPtr
= deviceToHost ? mManagedBuffers[i]->deviceBuffer.data() : mManagedBuffers[i]->hostBuffer.data();
const size_t byteSize = mManagedBuffers[i]->hostBuffer.nbBytes();
const cudaMemcpyKind memcpyType = deviceToHost ? cudaMemcpyDeviceToHost : cudaMemcpyHostToDevice;
if ((copyInput && mEngine->bindingIsInput(i)) || (!copyInput && !mEngine->bindingIsInput(i)))
{
if (async)
CHECK(cudaMemcpyAsync(dstPtr, srcPtr, byteSize, memcpyType, stream));
else
CHECK(cudaMemcpy(dstPtr, srcPtr, byteSize, memcpyType));
}
}
}
std::shared_ptr<nvinfer1::ICudaEngine> mEngine; //!< The pointer to the engine
int mBatchSize; //!< The batch size for legacy networks, 0 otherwise.
std::vector<std::unique_ptr<ManagedBuffer>> mManagedBuffers; //!< The vector of pointers to managed buffers
std::vector<void*> mDeviceBindings; //!< The vector of device buffers needed for engine execution
};
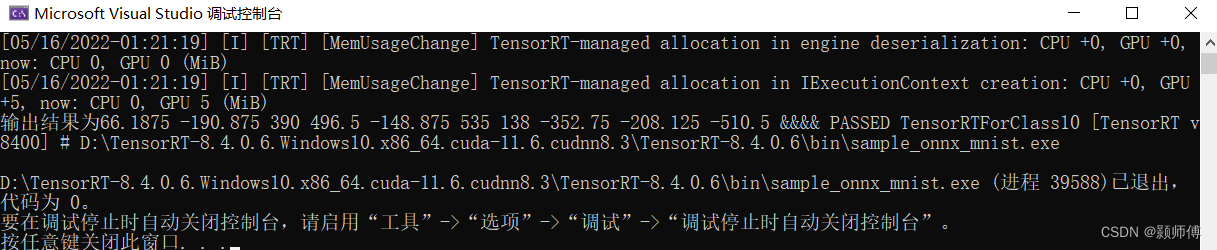
运行后输出结果为:
 全部详细代码及所需onnx文件见:代码备份
全部详细代码及所需onnx文件见:代码备份

















 2611
2611











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











