








网络设计的技巧
1. optimization失败的时候应该怎么办
为什么会失败。
对于Loss的最后的值不满意。
某一处,梯度趋近于0。
但不仅仅可能是局部最小值,也可能是鞍状。
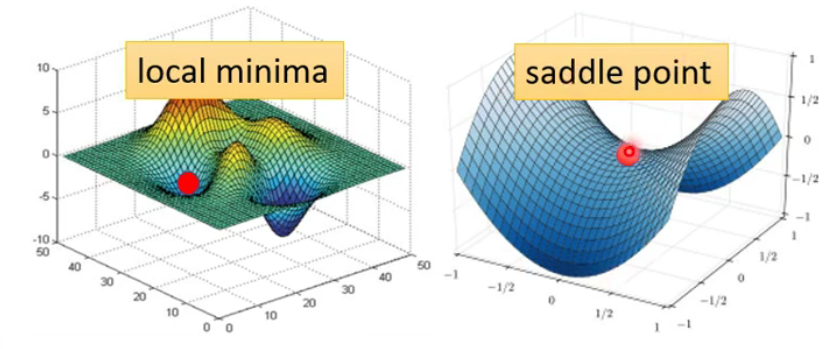
如何知道所处的位置(critical point)是哪一个?
- local minima暂时无法逃离
- saddle point可以鉴别,在其周围存在更低点
怎么知道Loss function的形状?【数学公式推导】
-
在ɵ’处的Loss fuction可以用泰勒公式表示:

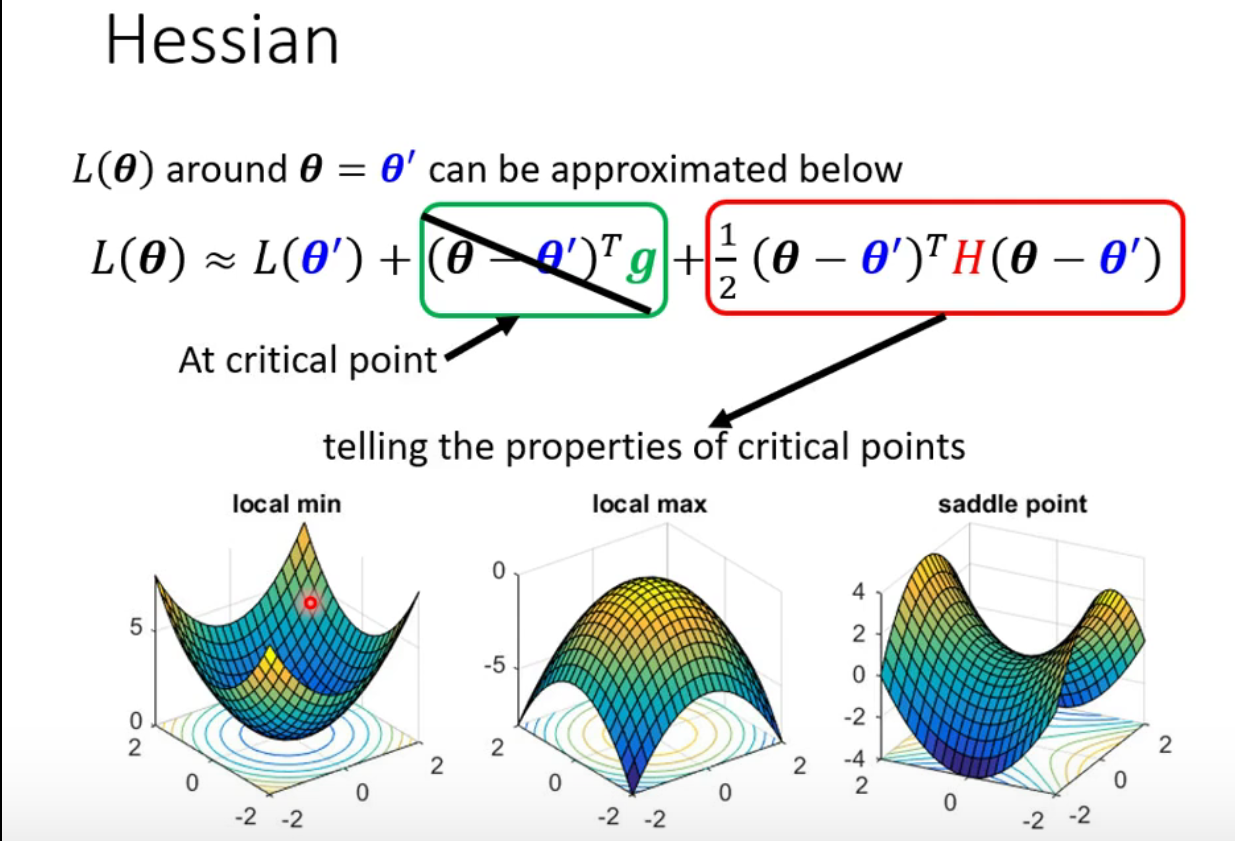
如何根据后面这一项判断critical point处的情况?:
- positive definite 正定
- negative definite 负定
- eigen value 特征值

对于saddle point,我们虽然不用担心g无法继续提供参数优化的方向,但仍需要通过其他途径得到优化方向,比如
H:
(例子)
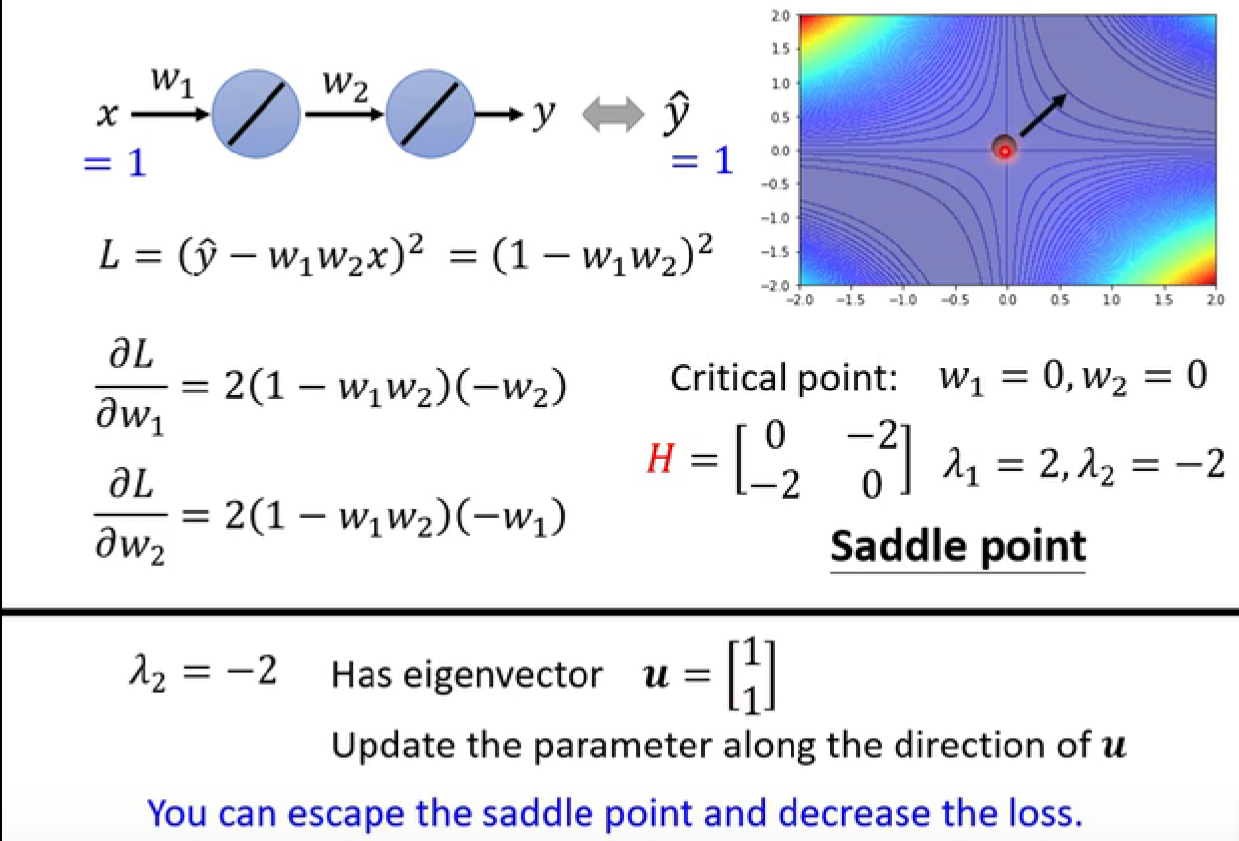
- 但实际中不太可能用这种方法,因为运算量过大。后续会有其他的方法逃离saddle point
-
saddle point 和 local minima 哪一个更常见?【更多参数,更高维度】
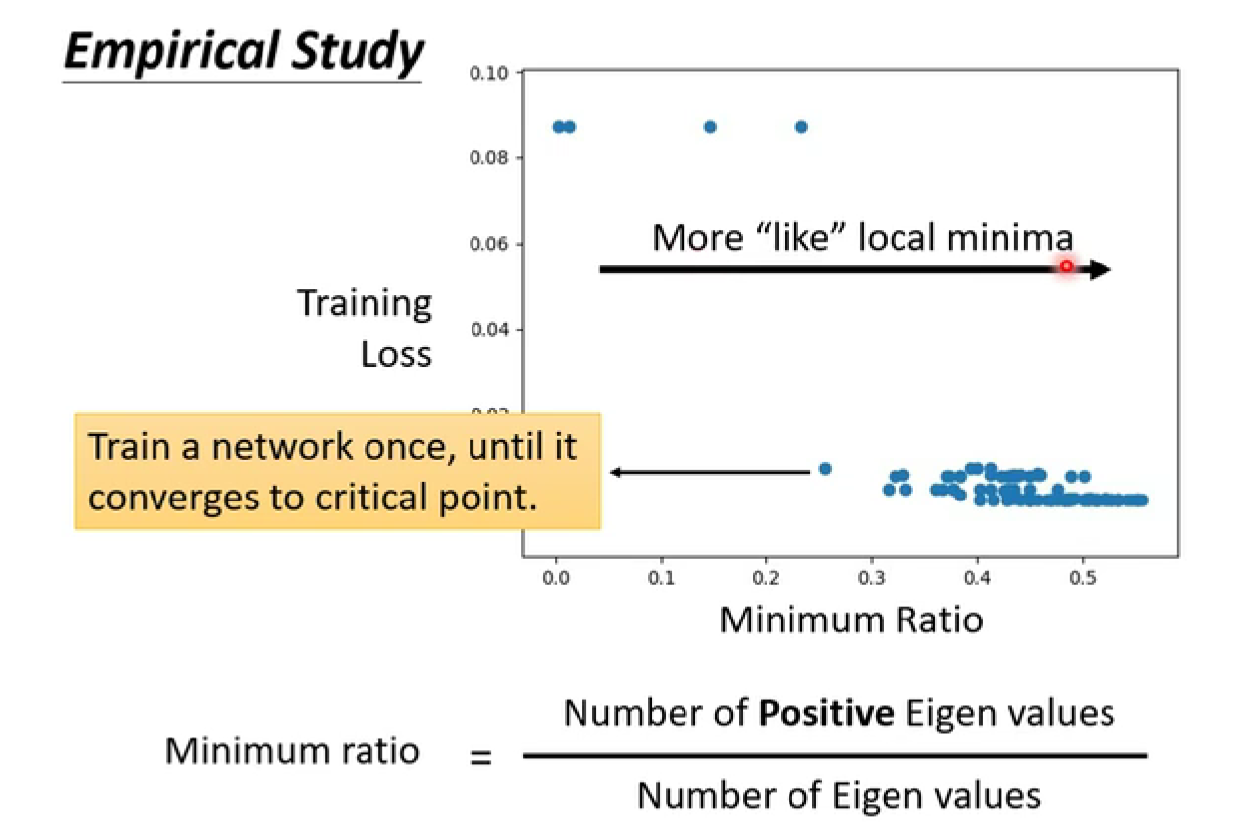
所以local minima并没有那么常见
2. batch(批次)和momentum(动量)的训练技巧
将数据集分为一个一个的batch,再计算Loss和gradient,再更新参数。一轮(epoch)看完所有的batch。
每一个epoch开始前会shuffle(洗牌),打乱后重新分batch。
为什么要分batch?
-
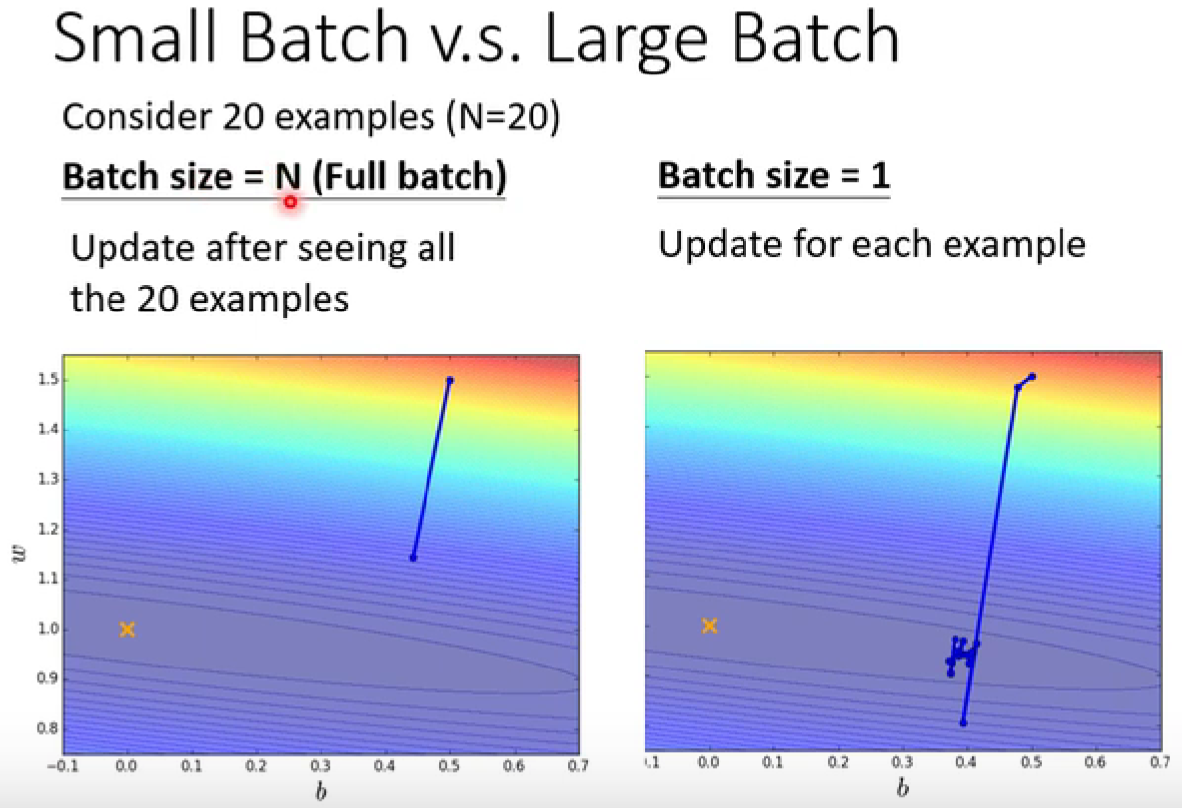
左边的蓄力时间较长,但方向更稳定(powerful)
右边蓄力的时间更短,但方向更不稳定(noisy)
(多核处理器)如果考虑平行运算,并不一定左边的时间更长
但是noisy的过程的training结果更好:更小的batch size 的结果会更好。(可以进行解释)
batch大小对于训练结果的影响:
(以MINIST和CIFAR-10为例)
-
MNIST:(Mixed National Institute of Standards and Technology),手写数字辨识。
-
CIFAR-10:10个类型的图片训练集
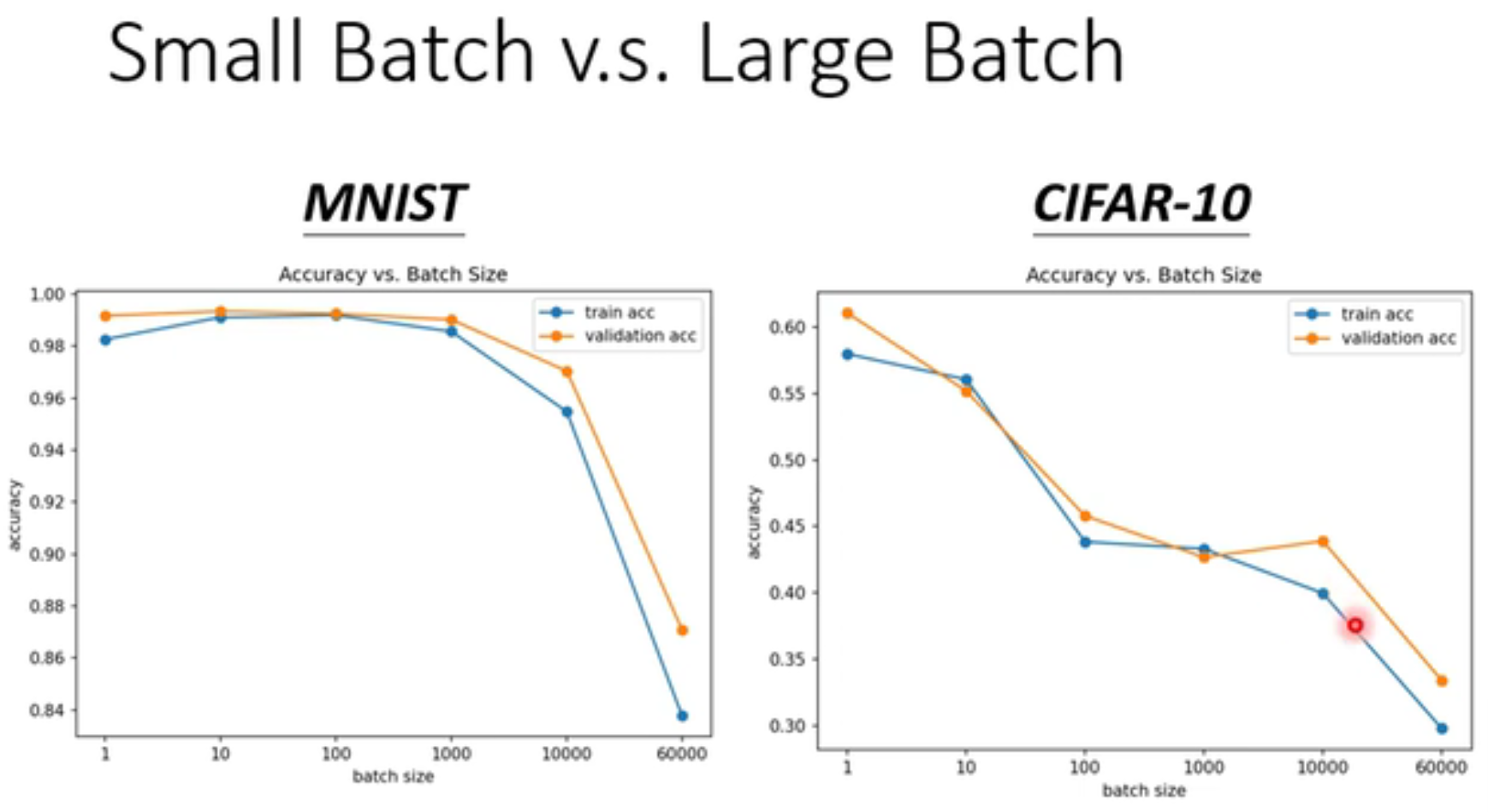
不仅是对于training ,对于testing,小的batch size的结果会比较好。
-
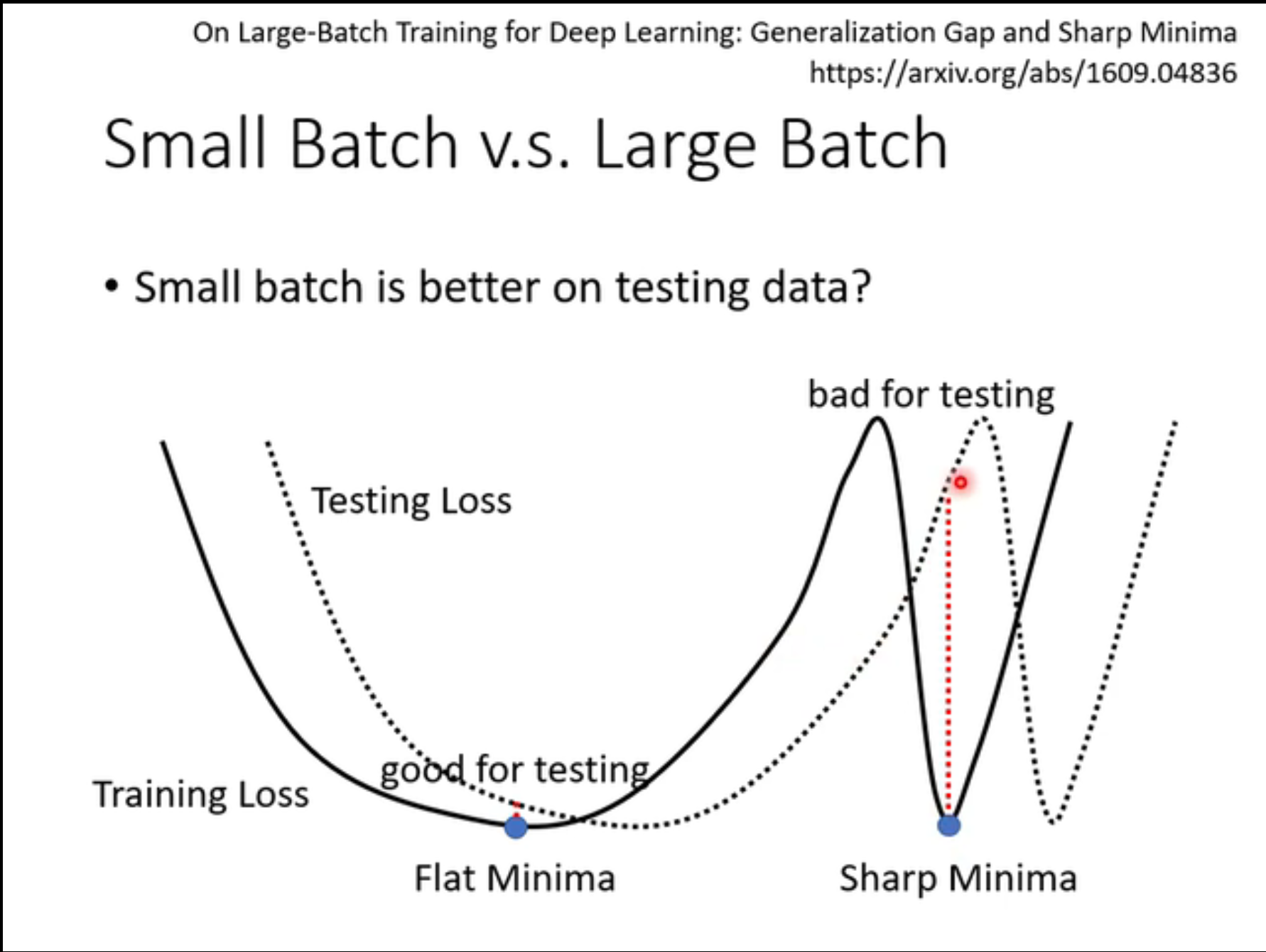
flat minima对于testing会比较有利。
-
小的batch size会倾向于将结果带到flat minima里面。
-
大小 batch size 的对比:
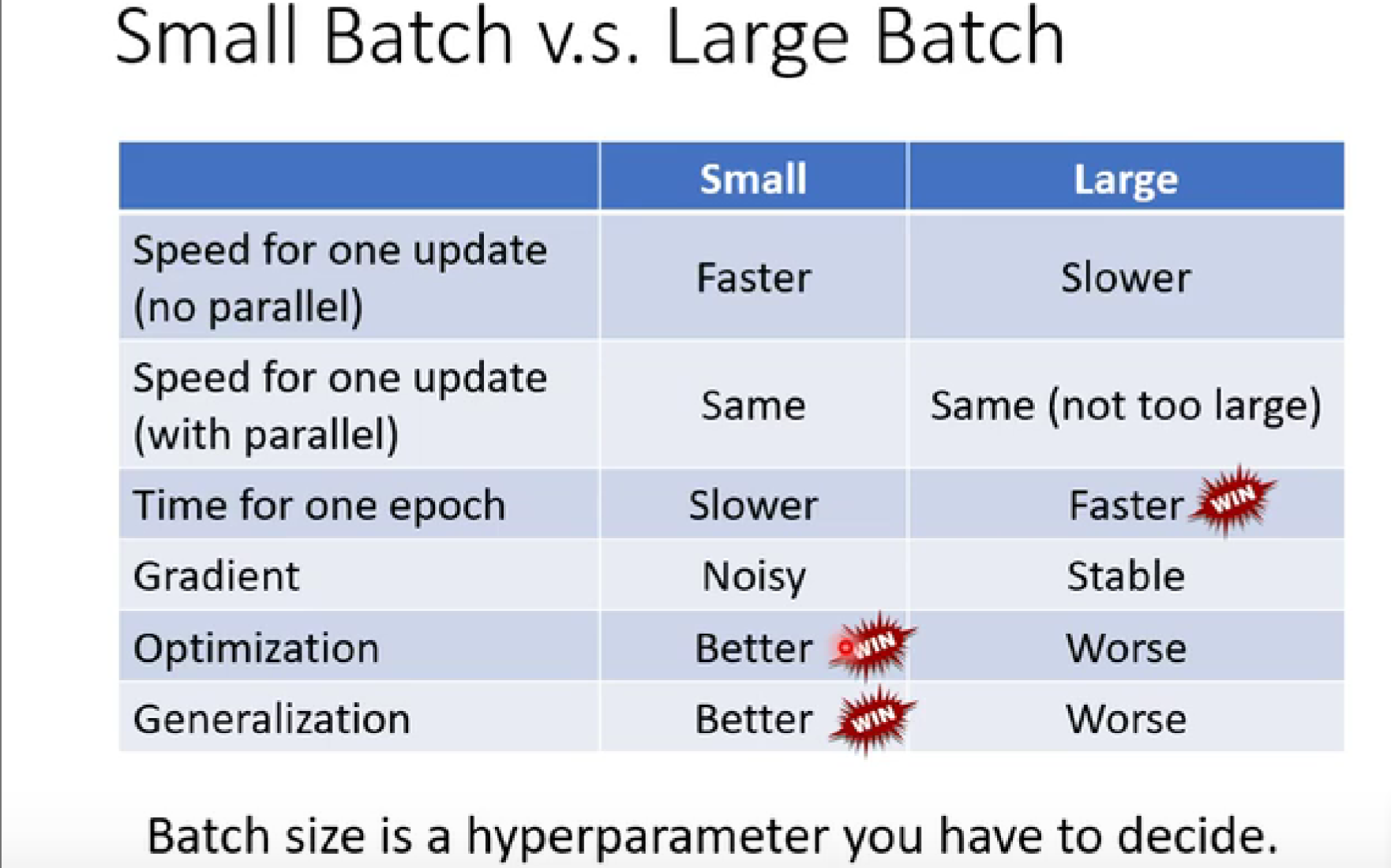
- hyperparameter:超参数
- optimization:优化
- generalization:泛化
Momentum动量
实际的物理世界中,球体从斜坡表面滚下来时,并不一定会被local minima卡住。如何将这一思想运用到gradient decent中呢?
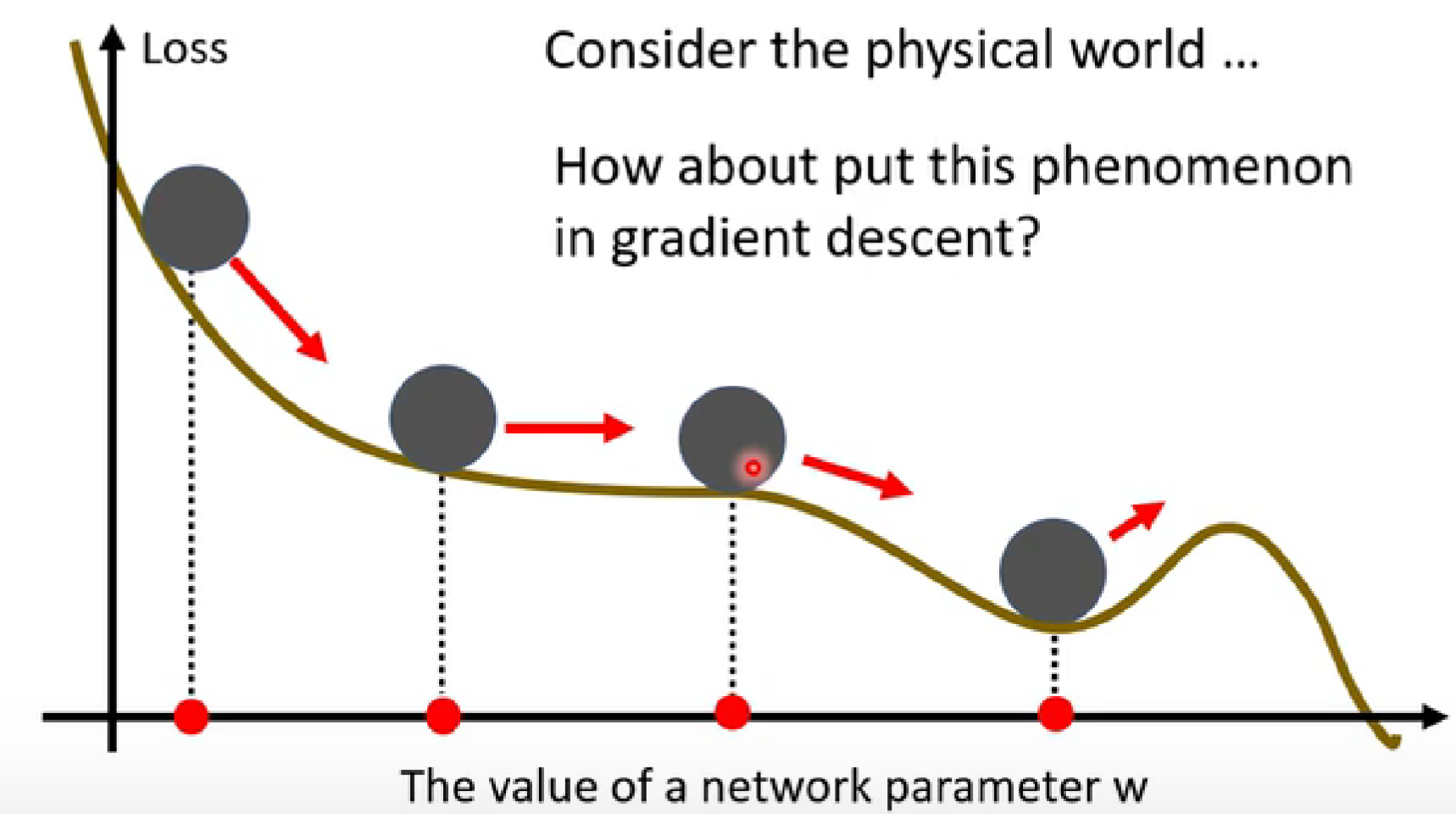

-
思想:下一次移动的方向不只是考虑现在的gradient,而是考虑之前的所有gradient的总和。
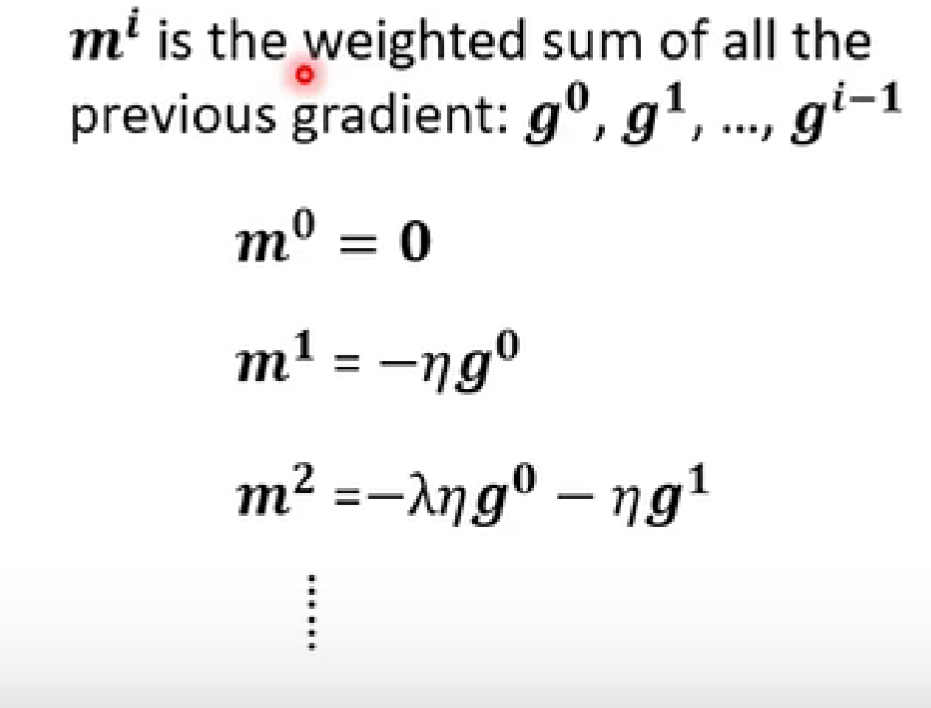
3. 自动调整学习率 learning rate
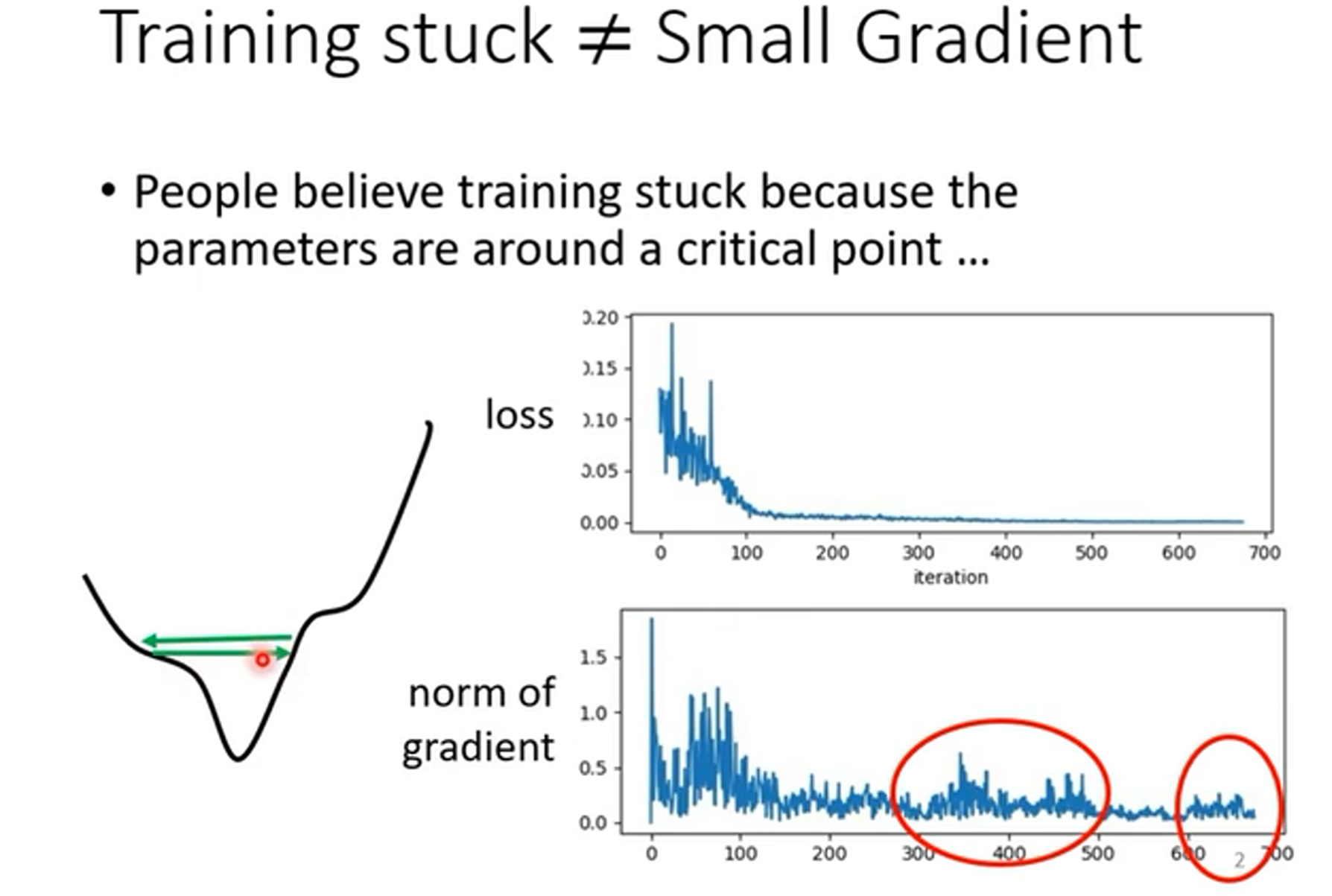
- 训练卡住的原因不一定是梯度最小,也可能是左边山谷的情况,无法下降到Loss最低点。
不同的参数需要不同的学习率。
常见的算法:
-
均方根
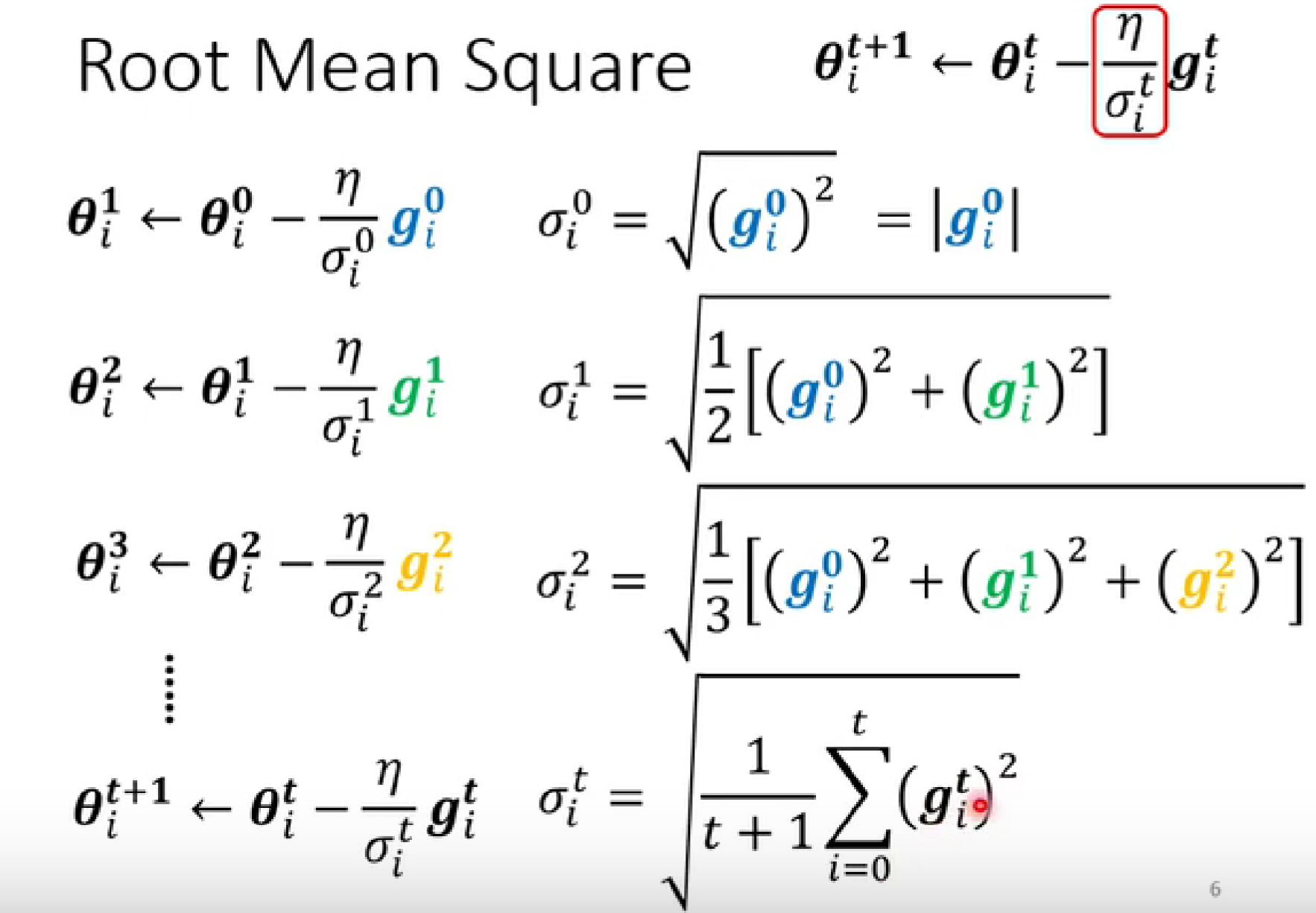
-
RMSProp【更优】
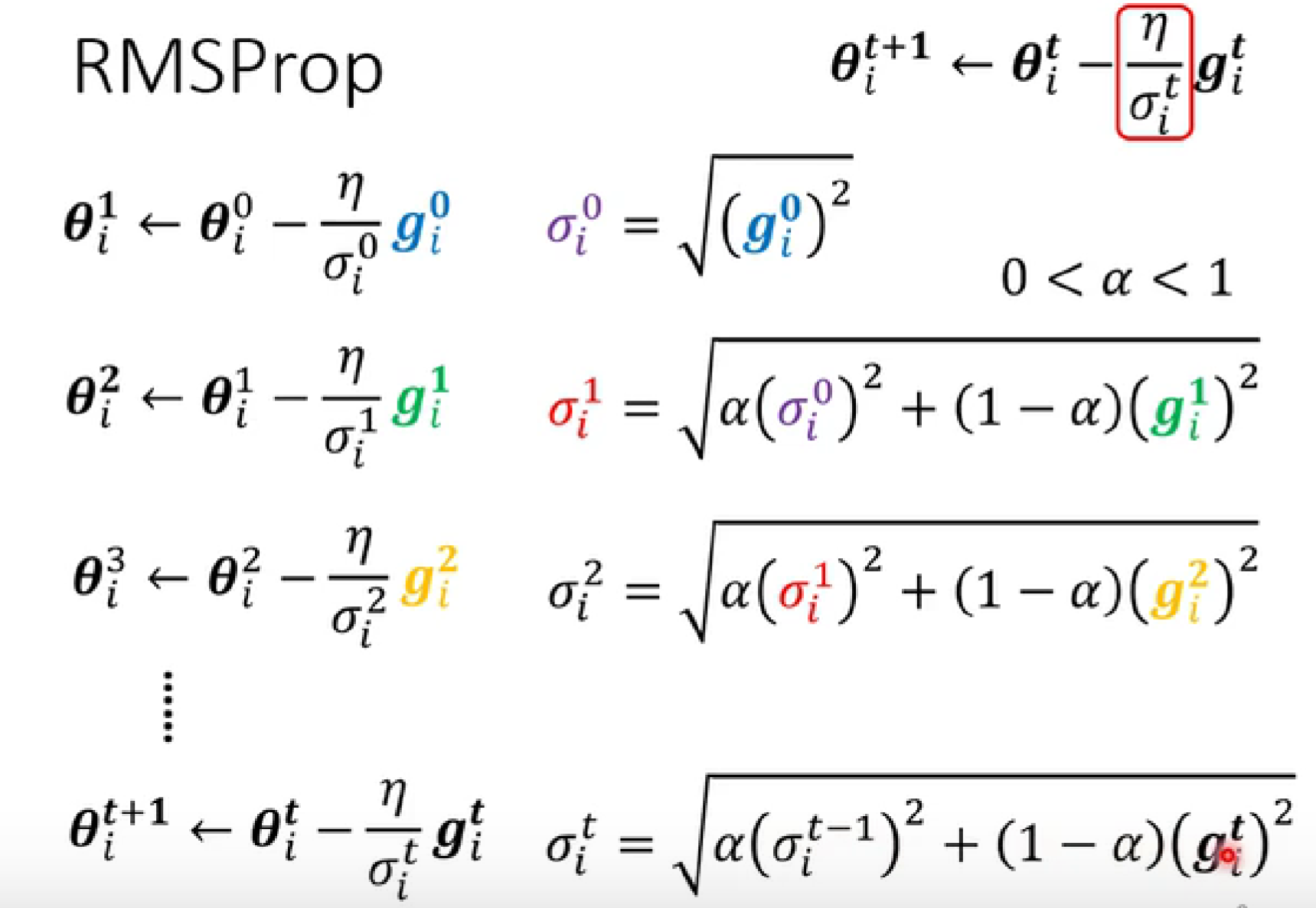
越临近的gradient的重要性越大,而相隔越久的gradient的重要性越低。
-
Adam:RMSProp+Momentum
pytorch里写的很完整了。
回到前面的例子,使用累积的梯度动态调整学习率,在后面的地方会因为累计的原因而偶发爆发,出现下列情况。
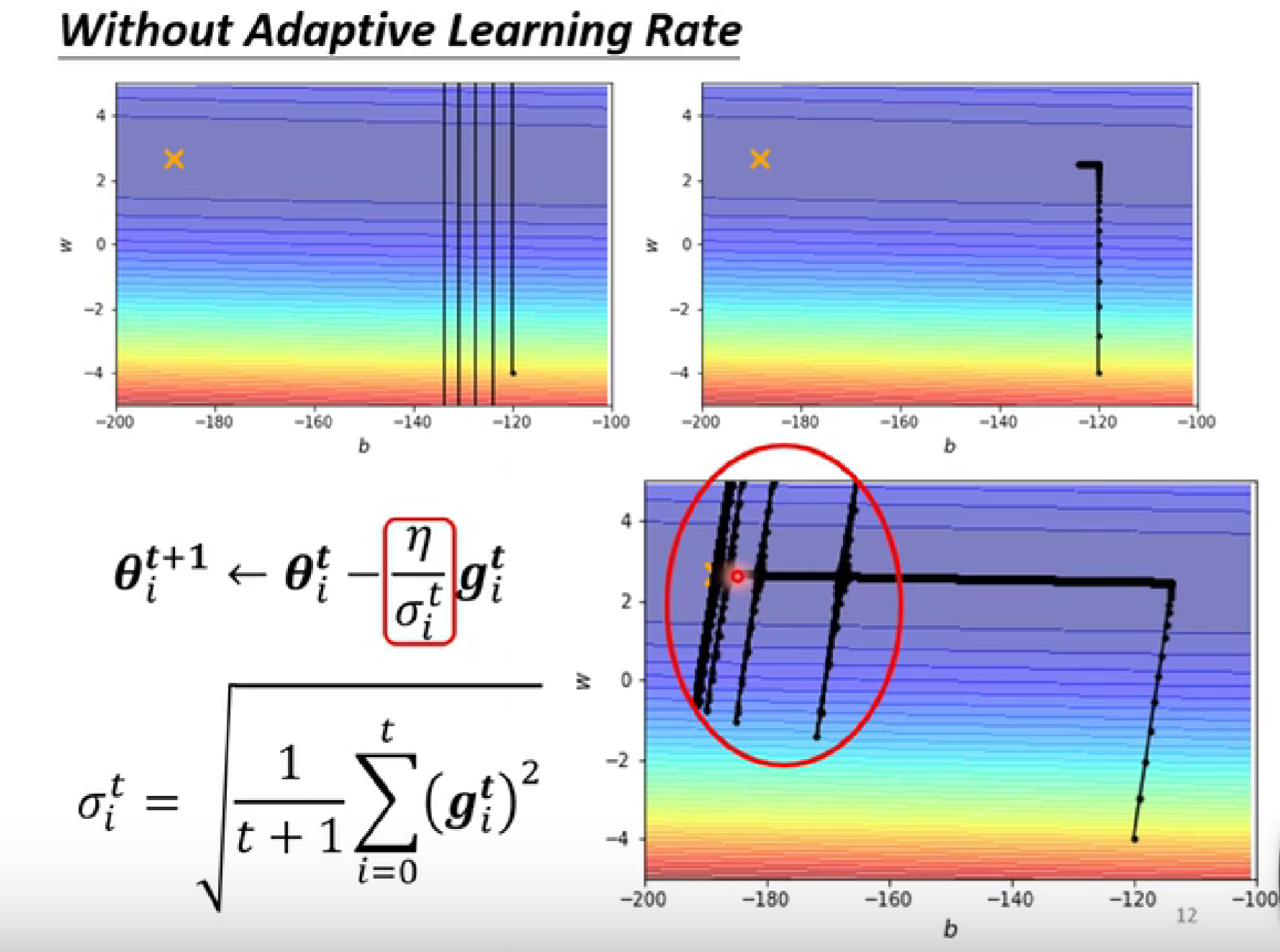
-
解决办法:learning rate scheduling
- 随着时间的进行,使学习率不断变小。
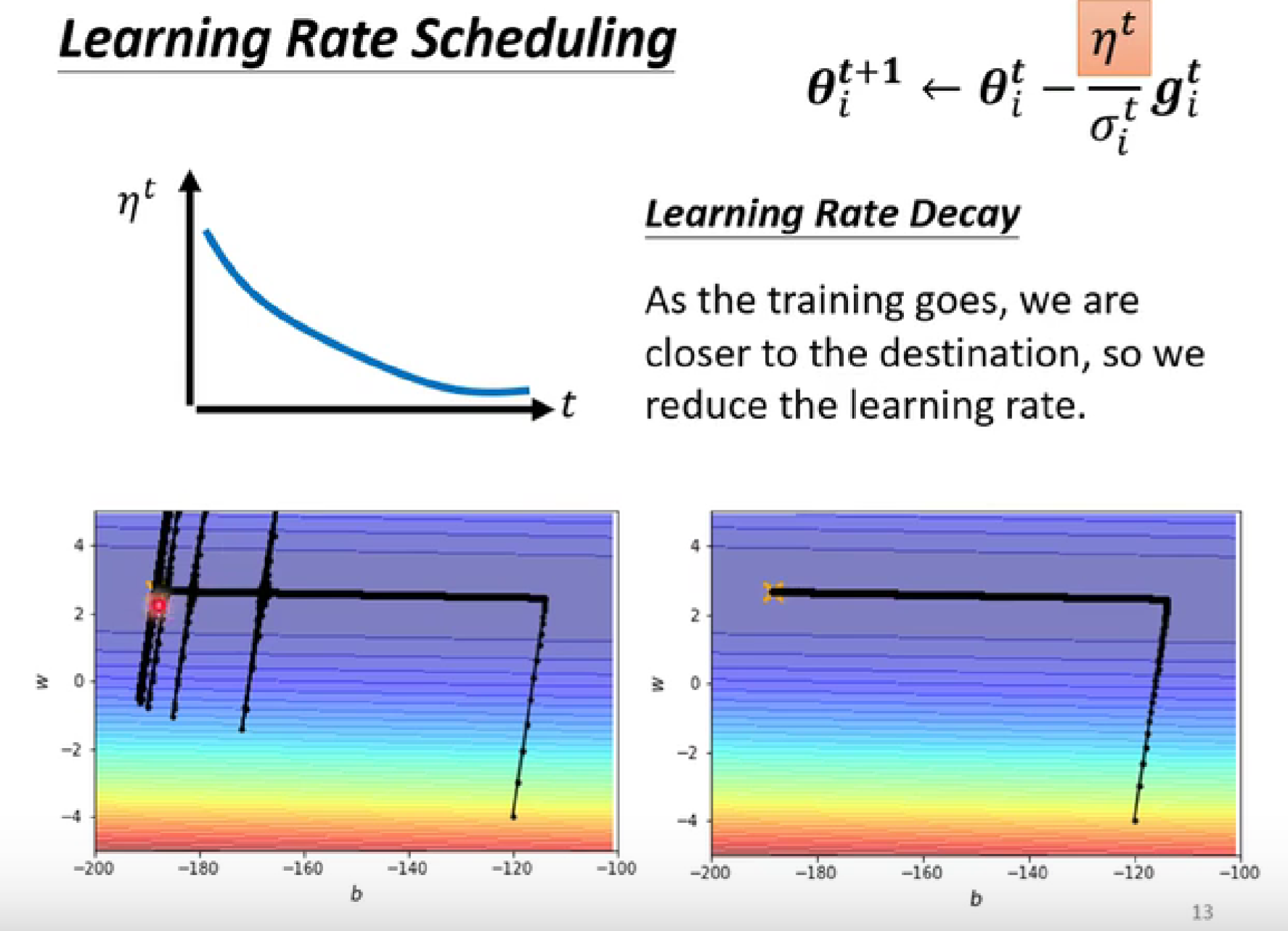
-
warm up(先变大,后变小)【训练BERT的时候会需要用到】
BERT:基于变换器的双向编码器表示技术,用于NLP的预训练。
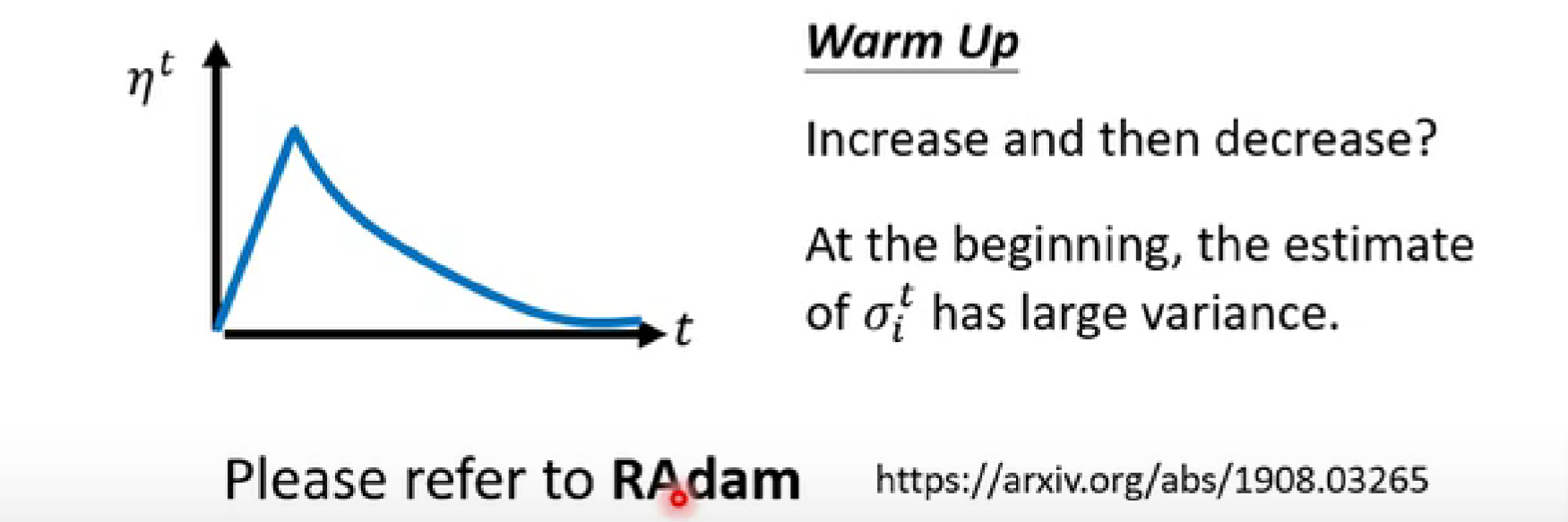
- 在开始地方的learning rate设置较小,使其熟悉开始的地方。等熟悉好了之后再调大learning rate ,进行与前一种方案相同的操作。
4. 损失函数(Loss)的影响
如何修改error surface?
分类Classification
-
这样的表示方法不太适合
可能会有“1、2更接近,1、3差距更大”的误解
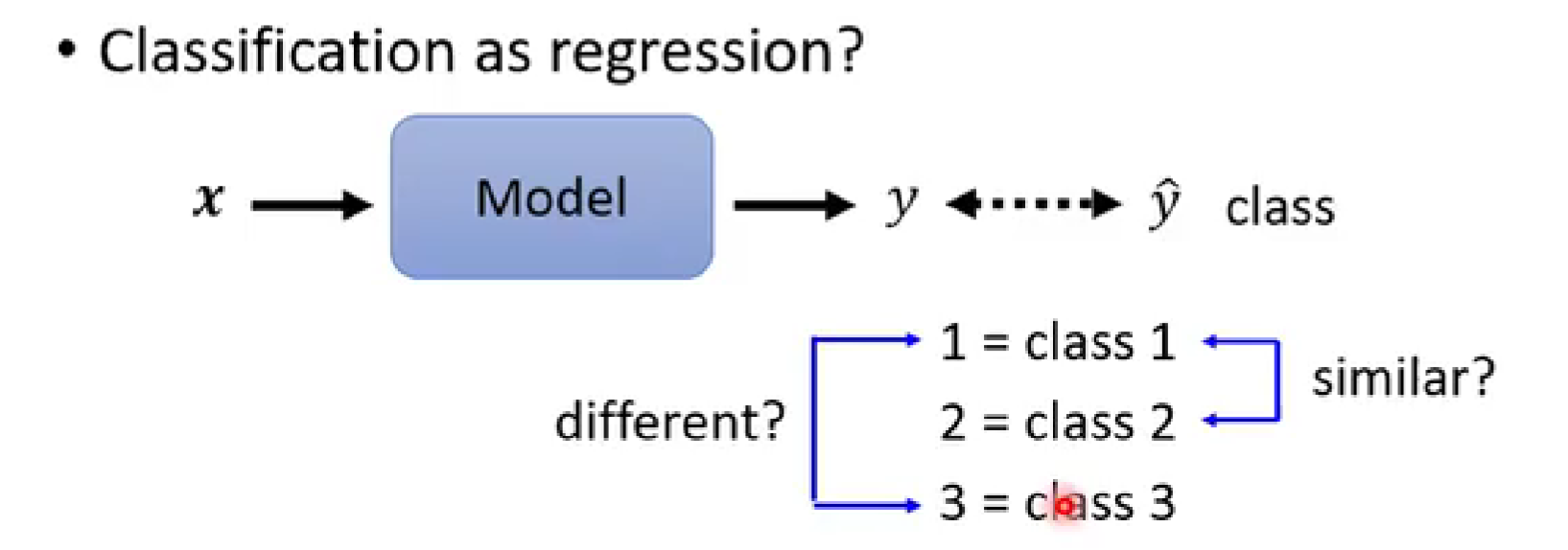
-
更好的表示方法:one-hot vector
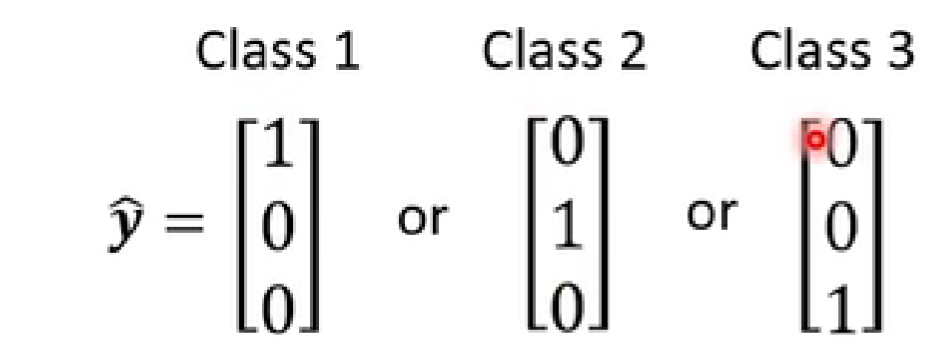
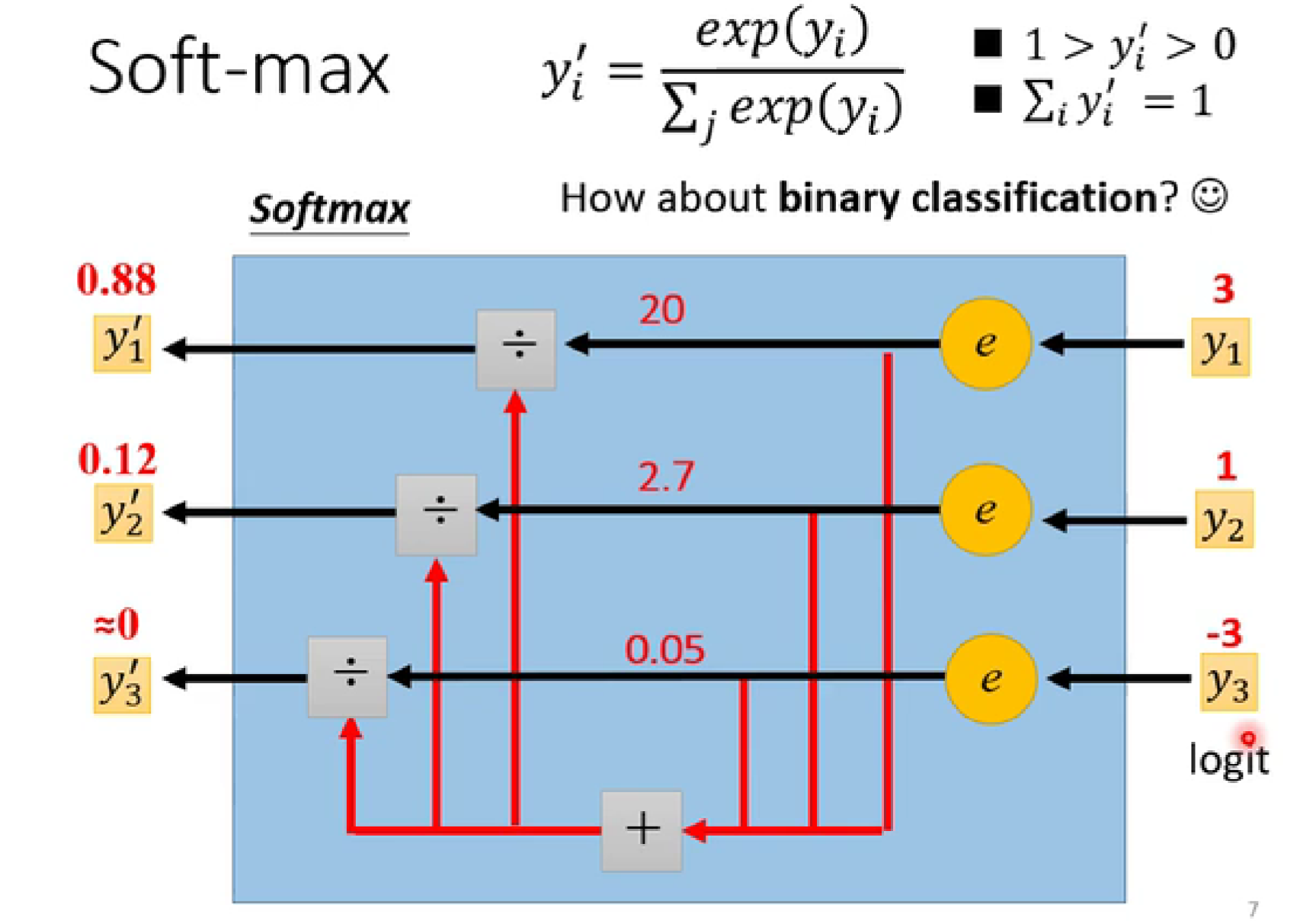
将预测值y转化为概率y':
分类问题的Loss函数:
-
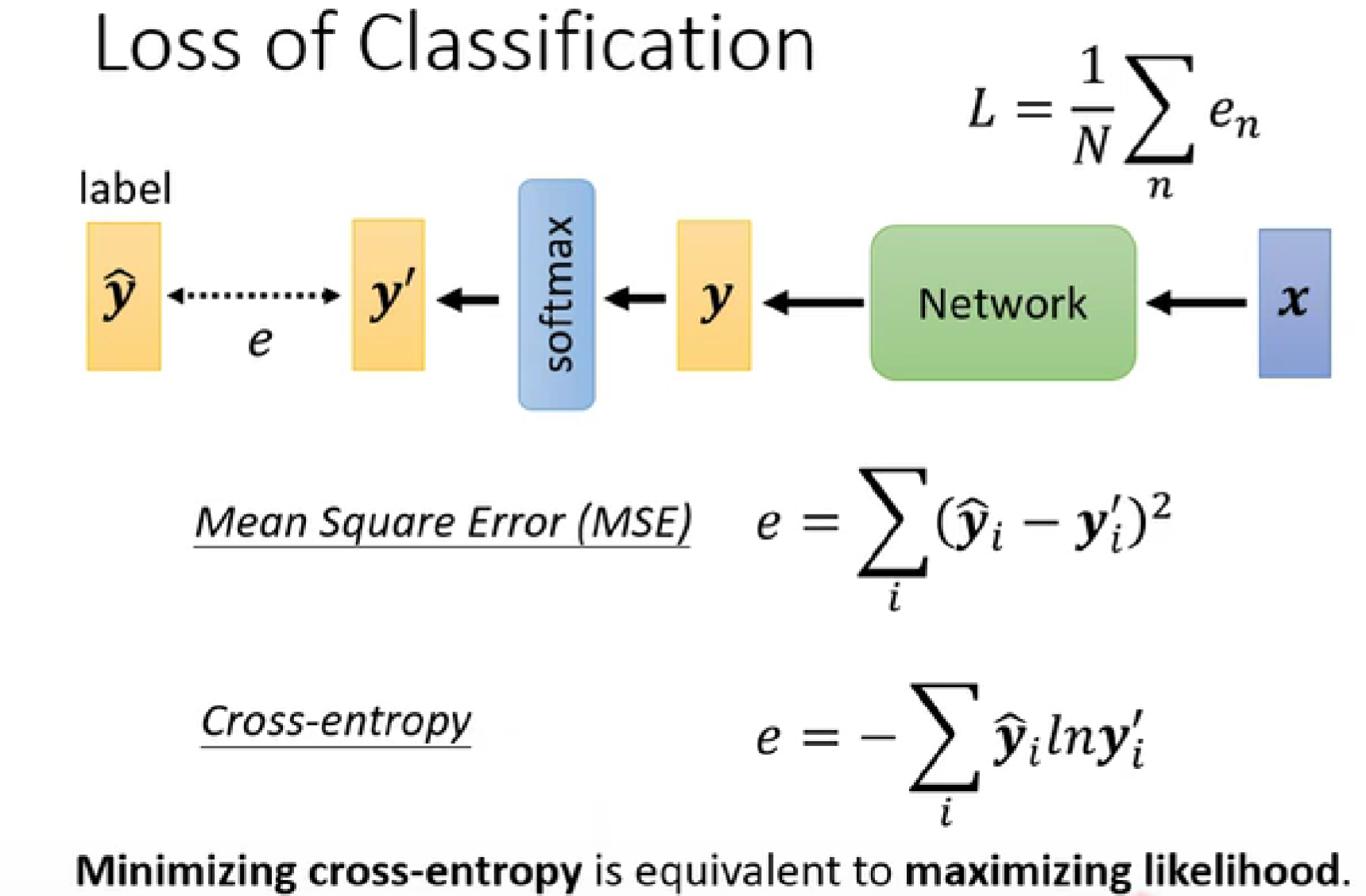
-
cross-entropy:交叉熵(里面包含了softmax-pytorch自动加入在最后一层)
maximizing likelihood:最大化的可能性
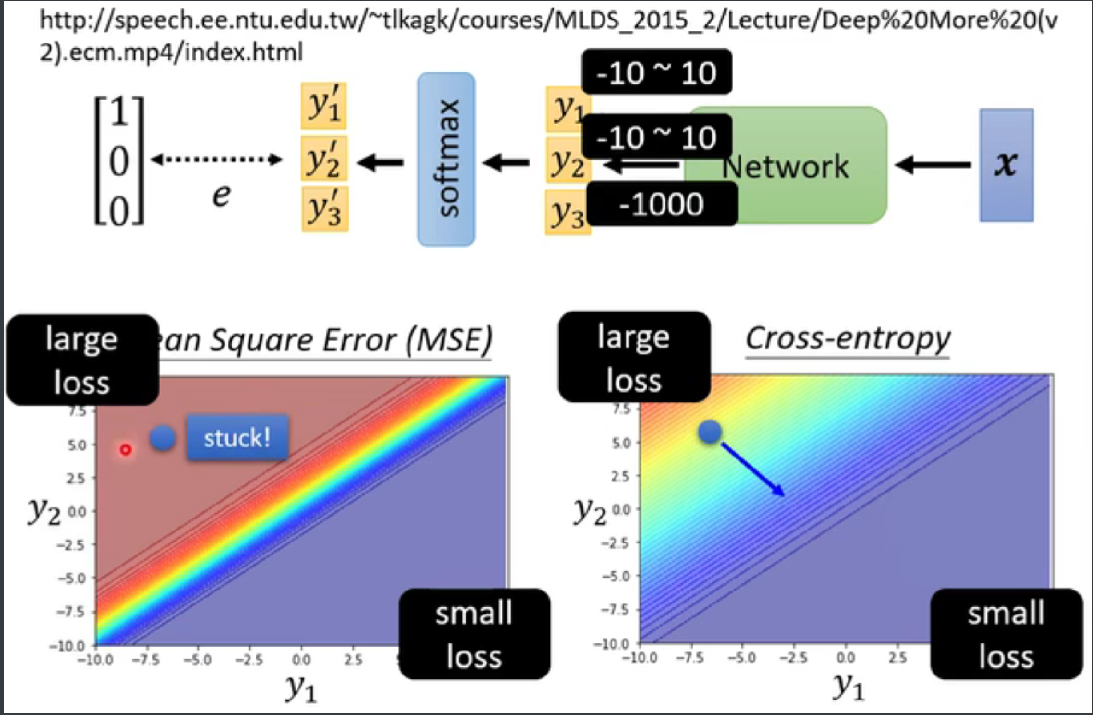
cross-entropy在起点较大的时候,有斜率,利于training。
5. 批次标准化(batch normalization)简介
error surface比较崎岖,可以在最开始将其铲平
feature normalization特征标准化(归一化)
training部分:
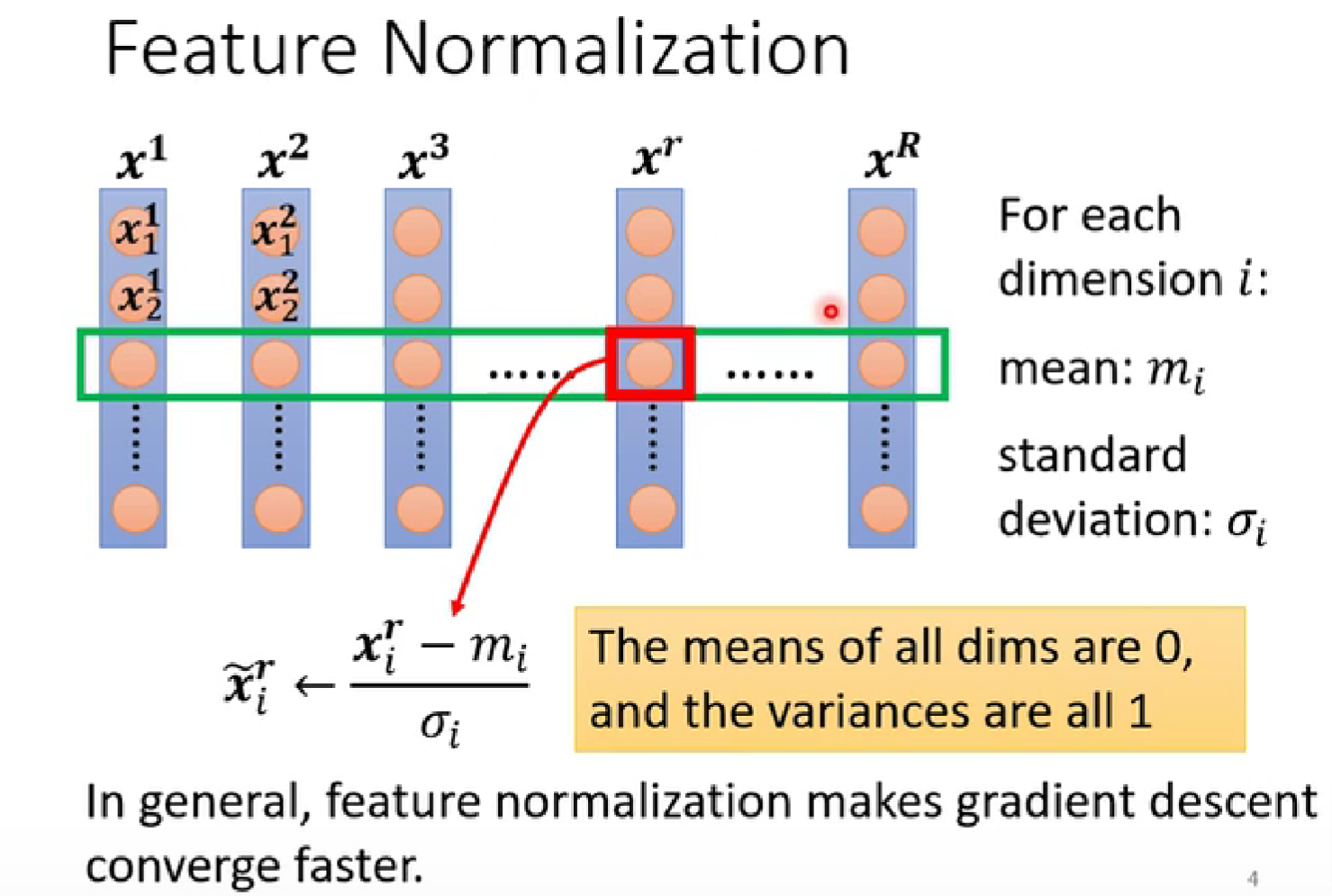
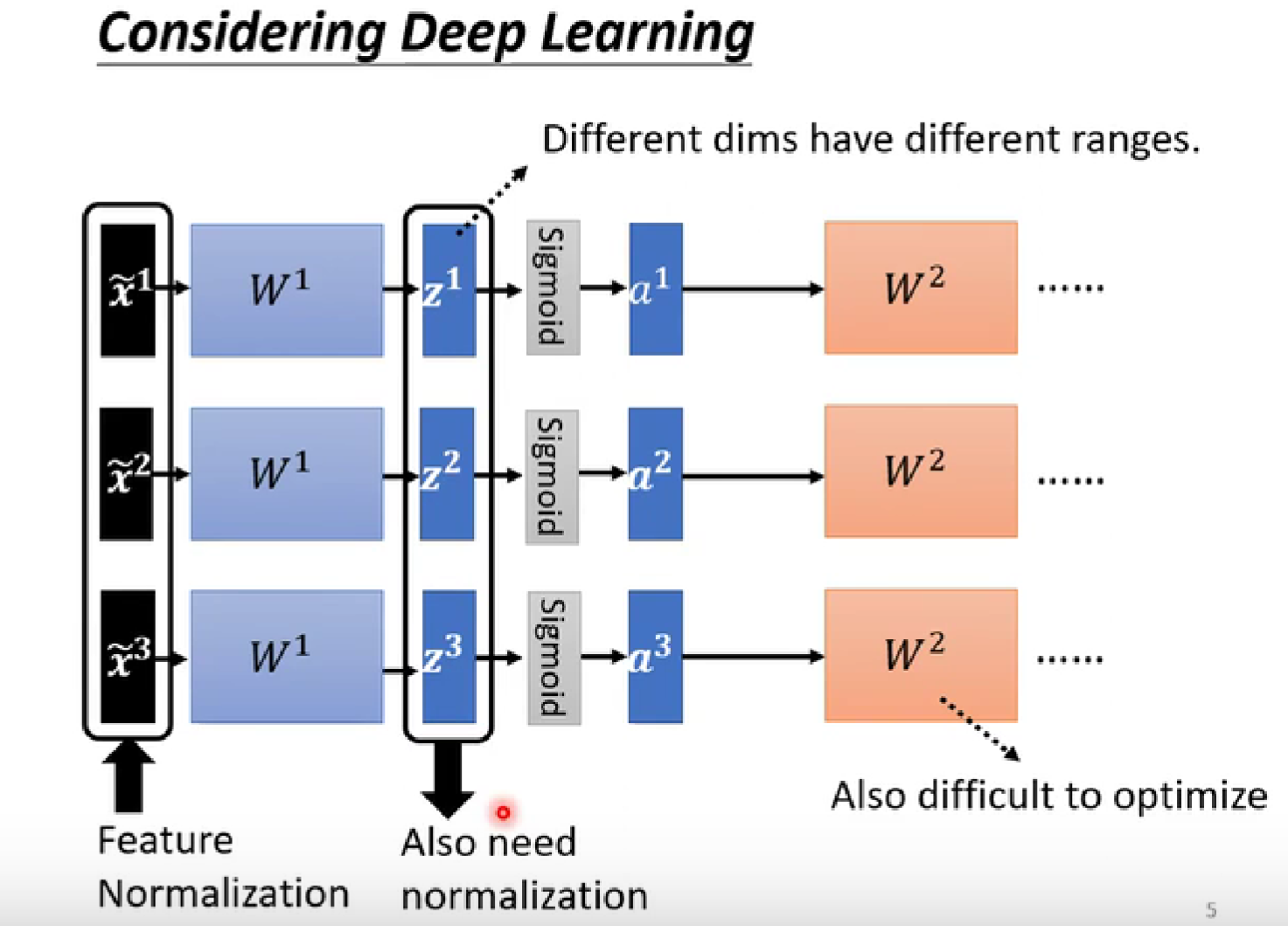
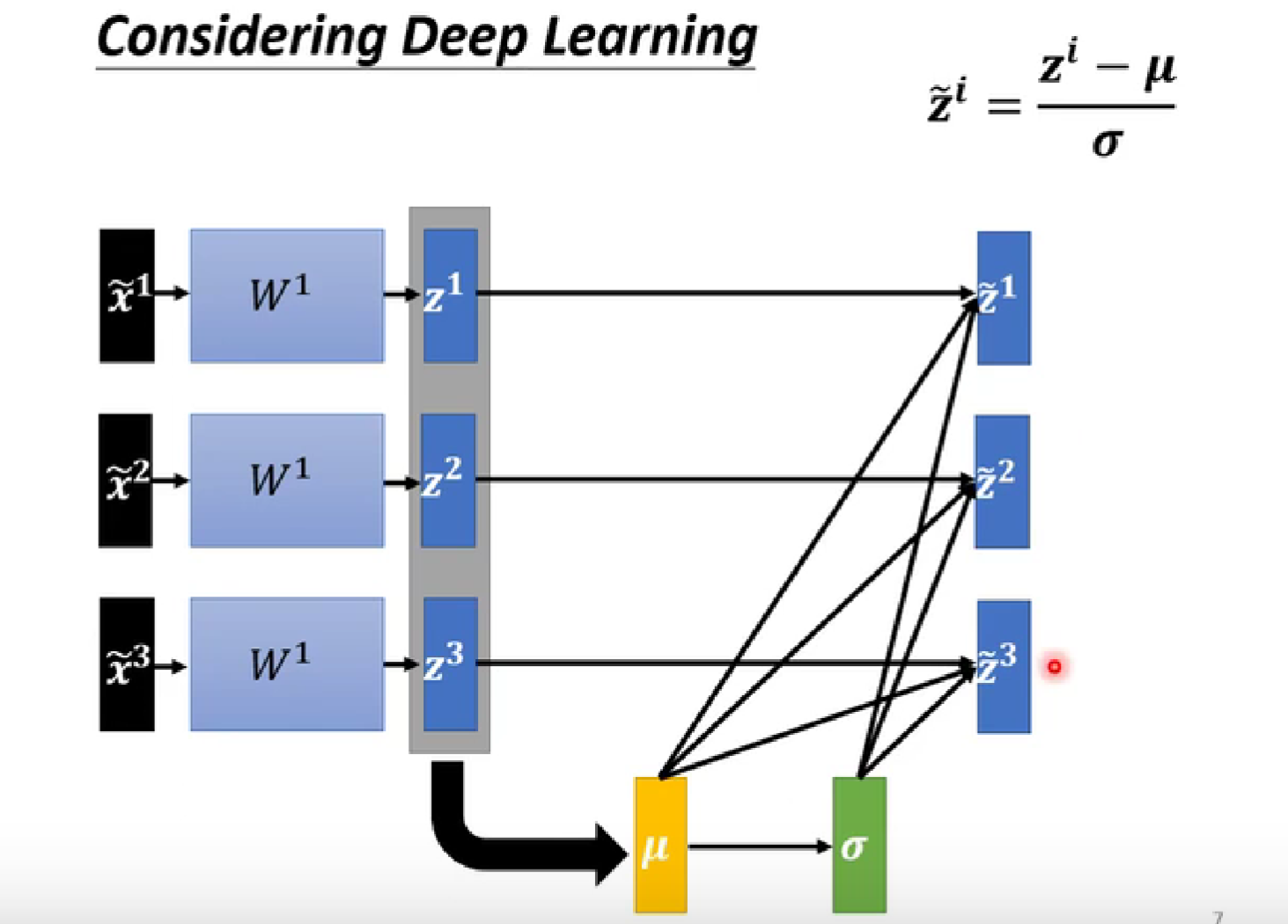
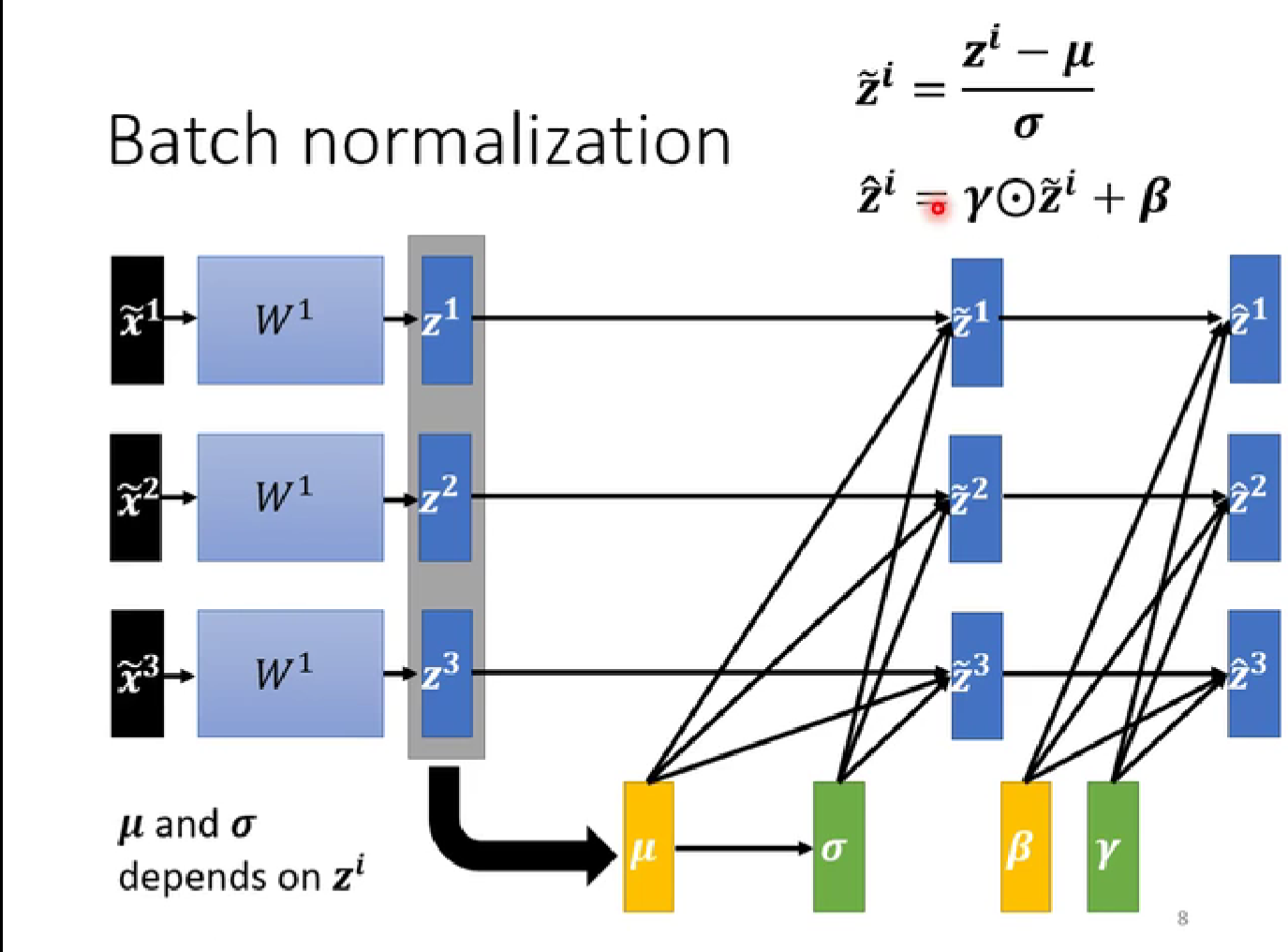
testing部分:

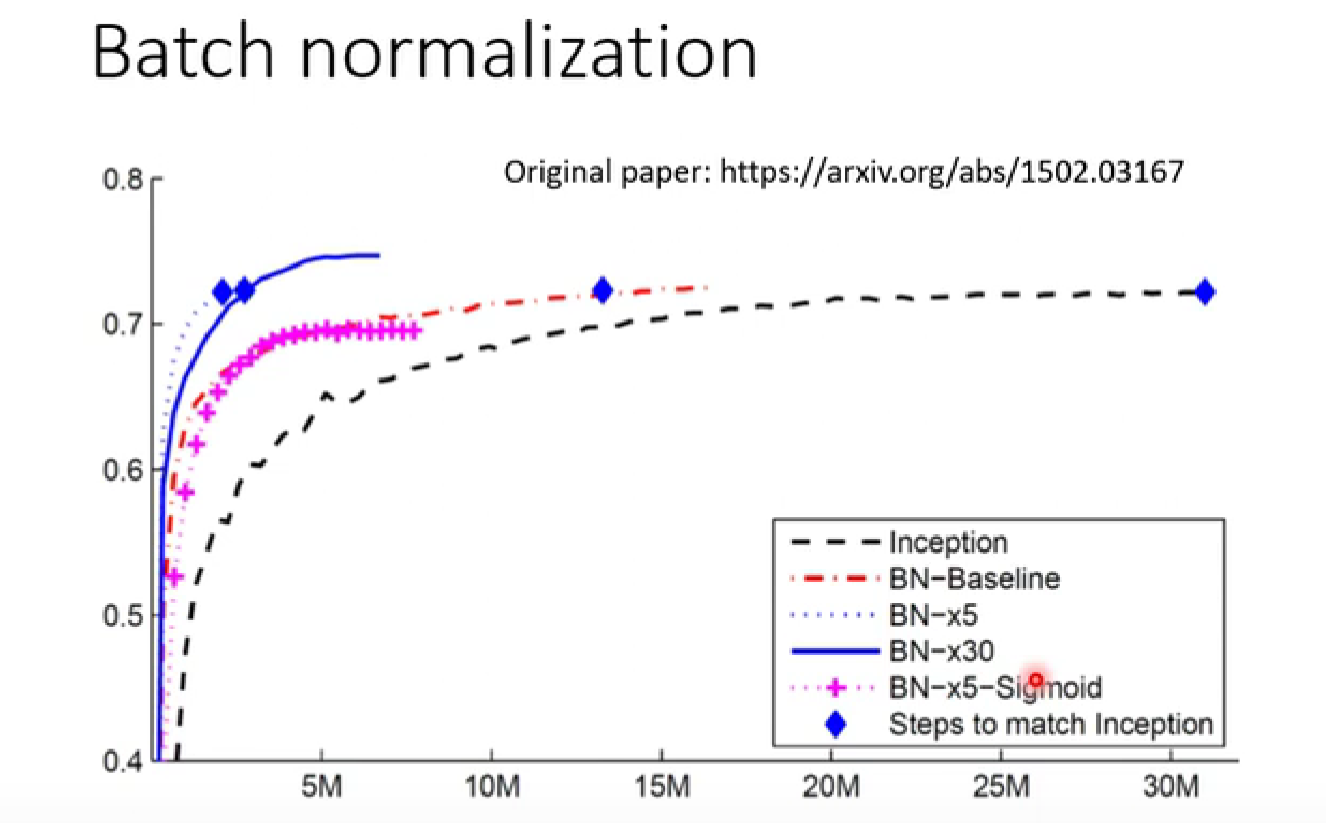
batch normalization在CNN上的表现:
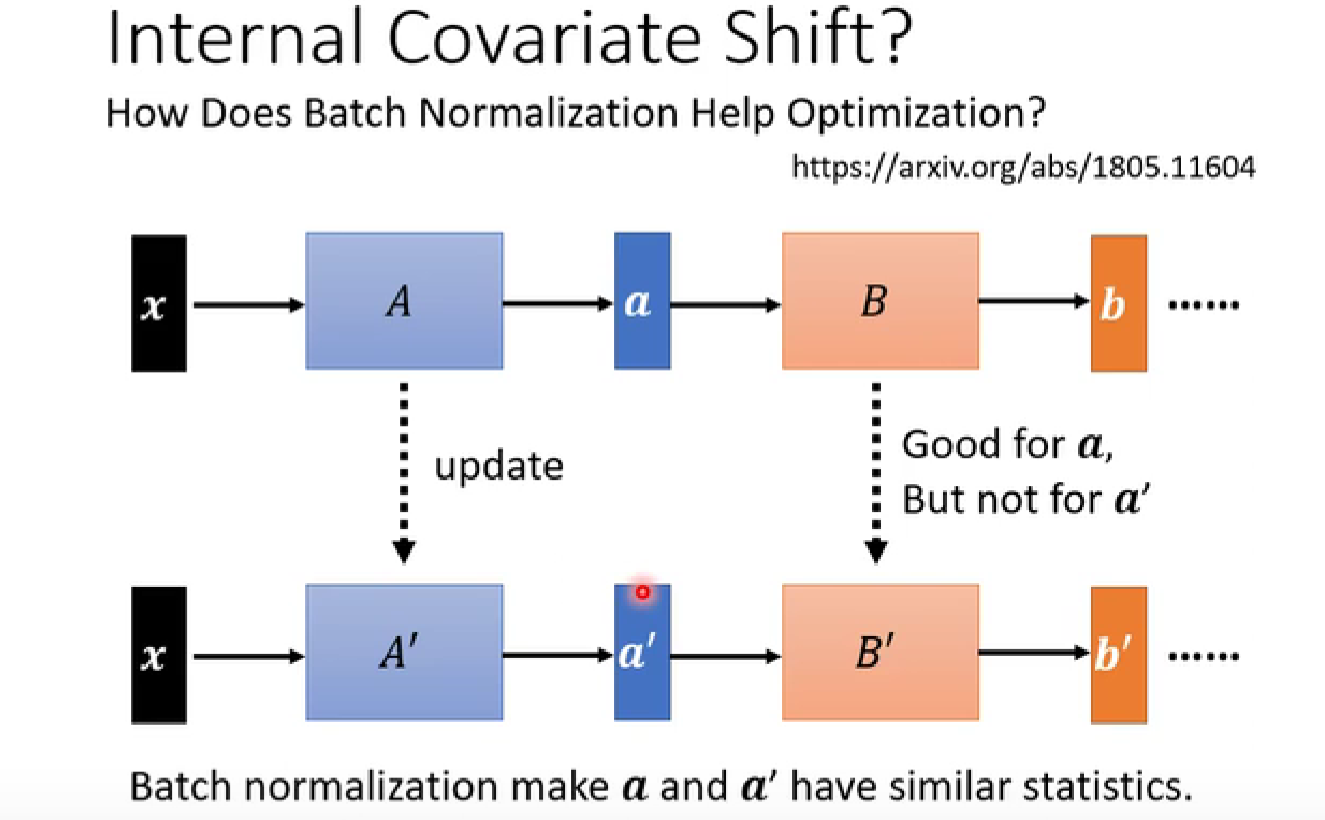
covariate shift 协变量转变
- 使下图中的
a和a'更加接近,可能有利于训练














 198
198











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









