







数学基础
一.数理逻辑题(5分,第1小题2分,第2小题3分)
1.只有天不下雨,我才开车出行。
答:P : 天下雨; Q: 我开车出行。Q →¬ P
2 猫必捕鼠。(分别用全称量词和存在量词描述)
答:P(x): x是猫; Q(x) : x是鼠 C(x,y): x捕y。全称量词描述: ∀x∀y(P(x)∧Q(y)→C(x,y));存在量词描述: ¬∃x¬∃y(P(x)∧Q(y)∧¬C(x,y))
二.填空题
1、 f ( x ) = ( 1 − 2 t ) − 7 f(x) =(1-2t)^{-7} f(x)=(1−2t)−7中, t 5 t^5 t5的系数是。14784
在展开式 f ( t ) = ( 1 − 2 t ) − 7 f(t) = (1 - 2t)^{-7} f(t)=(1−2t)−7 中,求 t 5 t^5 t5 项的系数,可以通过广义二项式定理解决。具体步骤如下:
-
广义二项式展开式:
( 1 − x ) − n = ∑ k = 0 ∞ ( n + k − 1 k ) x k (1 - x)^{-n} = \sum_{k=0}^{\infty} \binom{n+k-1}{k} x^k (1−x)−n=k=0∑∞(kn+k−1)xk
其中,( n = 7 ),( x = 2t )。 -
通项公式:
展开式中 t k t^k tk项的系数为:
( 7 + k − 1 k ) ⋅ ( 2 ) k = ( 6 + k k ) ⋅ 2 k \binom{7+k-1}{k} \cdot (2)^k = \binom{6+k}{k} \cdot 2^k (k7+k−1)⋅(2)k=(k6+k)⋅2k -
代入 ( k = 5 ):
系数 = ( 11 5 ) ⋅ 2 5 = 462 ⋅ 32 = 14 , 784 \text{系数} = \binom{11}{5} \cdot 2^5 = 462 \cdot 32 = 14,\!784 系数=(511)⋅25=462⋅32=14,784
答案:
t
5
t^5
t5 的系数为
14784
\boxed{14784}
14784。
2、3种不同甜点,每种都足够多,则小王选取4个甜点的方式有_种。
答案:15种。
解析:
此问题属于组合数学中的“可重复组合”问题,即从3种不同的甜点中选取4个,允许每种甜点被重复选取,且不考虑顺序。计算公式为组合数
C
(
n
+
k
−
1
,
k
)
C(n + k - 1, k)
C(n+k−1,k),其中 ( n = 3 )(甜点种类数),( k = 4 )(选取数量)。具体步骤如下:
-
公式应用:
使用可重复组合公式:
C ( 3 + 4 − 1 , 4 ) = C ( 6 , 4 ) = 15 C(3 + 4 - 1, 4) = C(6, 4) = 15 C(3+4−1,4)=C(6,4)=15
或等价地:
C ( 6 , 2 ) = 15 C(6, 2) = 15 C(6,2)=15 -
验证与枚举:
通过列举所有可能的非负整数解 ( x_1 + x_2 + x_3 = 4 ),得到15种不同的组合方式。例如:
• (4,0,0), (3,1,0), (3,0,1),
• (2,2,0), (2,1,1), (2,0,2),
• (1,3,0), (1,2,1), (1,1,2),
• (1,0,3), (0,4,0), (0,3,1),
• (0,2,2), (0,1,3), (0,0,4)。
结论:小王共有15种不同的选取方式。
3.设T是有k个顶点的树,则T的着色数是。
树的着色数为 2 。
这是因为:
- 树是二分图。树作为一种无环连通图,其结构天然满足二分图的性质,即顶点集可以划分为两个独立集(相邻顶点颜色不同)。因此,用两种颜色即可完成正常顶点着色。
- 交替染色法。对于任意树,可以选取一个顶点作为根节点,按照路径长度的奇偶性交替使用两种颜色。具体来说:
• 与根节点路径长度为偶数的顶点着第一种颜色;
• 路径长度为奇数的顶点着第二种颜色。
这种着色方法保证了相邻顶点颜色不同,且只需两种颜色。
结论:无论树的顶点数 ( k ) 是多少,其着色数始终为 2。
4、
m
=
p
t
1
…
…
p
t
k
\mathrm{m}=p^{t 1} \ldots \ldots p^{t k}
m=pt1……ptk 是 m 的唯一素数分解,其中
p
t
1
…
.
.
.
p
t
k
p^{t 1} \ldots . . . p^{t k}
pt1…...ptk 是不同的素数,满足:
u
(
m
)
=
{
0
∃
i
∈
{
1
,
2
,
3
,
…
k
}
,
t
i
>
0
1
m
=
1
(
−
1
)
k
∀
i
∈
{
1
,
2
,
3
,
…
k
}
,
t
i
=
1
u(m)=\left\{\begin{array}{cc} 0 & \exists i \in\{1,2,3, \ldots k\}, t_{i}>0 \\ 1 & m=1 \\ (-1)^{k} & \forall i \in\{1,2,3, \ldots k\}, t_{i}=1 \end{array}\right.
u(m)=⎩
⎨
⎧01(−1)k∃i∈{1,2,3,…k},ti>0m=1∀i∈{1,2,3,…k},ti=1
对于大于 1 的整数 n , ∑ d / n u ( d ) = ? n, \sum_{d / n} u(d)=? n,∑d/nu(d)=?
对于大于1的整数 ( n ),所有整除 ( n ) 的正整数 ( d ) 的 ( u(d) ) 之和为 0。
解析:
题目中定义的函数 u ( m ) u(m) u(m) 实际等价于莫比乌斯函数 μ ( m ) \mu(m) μ(m),其定义如下:
- 若 ( m = 1 ),则 μ ( 1 ) = 1 \mu(1) = 1 μ(1)=1;
- 若 ( m ) 有平方因子(即存在素数p 使得 p 2 ∣ m p^2 \mid m p2∣m),则 μ ( m ) = 0 \mu(m) = 0 μ(m)=0;
- 若 ( m ) 是无平方因子的数(即 m = p 1 p 2 ⋯ p k m = p_1 p_2 \cdots p_k m=p1p2⋯pk,其中 p i p_i pi 为不同素数),则 μ ( m ) = ( − 1 ) k \mu(m) = (-1)^k μ(m)=(−1)k。
根据莫比乌斯反演定理,对于任意整数
n
>
1
n > 1
n>1 ,其所有因数的莫比乌斯函数之和为 0,即:
∑
d
∣
n
μ
(
d
)
=
0.
\sum_{d \mid n} \mu(d) = 0.
d∣n∑μ(d)=0.
结论:
对于
n
>
1
n > 1
n>1,所求的和为
0
\boxed{0}
0。

三、计算题
1.求[99...1000]范围内,不能被5,6,8中任何一个整数整除的数的个数。
解:
总基数计算
区间[99,1000]的整数总数为:
N
=
1000
−
99
+
1
=
902
N = 1000 - 99 + 1 = 902
N=1000−99+1=902
计算能被5、6、8整除的数的个数
-
能被5整除的数(集合A)
∣ A ∣ = ⌊ 1000 5 ⌋ − ⌊ 98 5 ⌋ = 200 − 19 = 181 |A| = \left\lfloor \frac{1000}{5} \right\rfloor - \left\lfloor \frac{98}{5} \right\rfloor = 200 - 19 = 181 ∣A∣=⌊51000⌋−⌊598⌋=200−19=181 -
能被6整除的数(集合B)
∣ B ∣ = ⌊ 1000 6 ⌋ − ⌊ 98 6 ⌋ = 166 − 16 = 150 |B| = \left\lfloor \frac{1000}{6} \right\rfloor - \left\lfloor \frac{98}{6} \right\rfloor = 166 - 16 = 150 ∣B∣=⌊61000⌋−⌊698⌋=166−16=150 -
能被8整除的数(集合C)
∣ C ∣ = ⌊ 1000 8 ⌋ − ⌊ 98 8 ⌋ = 125 − 12 = 113 |C| = \left\lfloor \frac{1000}{8} \right\rfloor - \left\lfloor \frac{98}{8} \right\rfloor = 125 - 12 = 113 ∣C∣=⌊81000⌋−⌊898⌋=125−12=113
计算两两集合的交集
-
同时被5和6整除(最小公倍数30)
∣ A ∩ B ∣ = ⌊ 1000 30 ⌋ − ⌊ 98 30 ⌋ = 33 − 3 = 30 |A \cap B| = \left\lfloor \frac{1000}{30} \right\rfloor - \left\lfloor \frac{98}{30} \right\rfloor = 33 - 3 = 30 ∣A∩B∣=⌊301000⌋−⌊3098⌋=33−3=30 -
同时被6和8整除(最小公倍数24)
∣ B ∩ C ∣ = ⌊ 1000 24 ⌋ − ⌊ 98 24 ⌋ = 41 − 4 = 37 |B \cap C| = \left\lfloor \frac{1000}{24} \right\rfloor - \left\lfloor \frac{98}{24} \right\rfloor = 41 - 4 = 37 ∣B∩C∣=⌊241000⌋−⌊2498⌋=41−4=37 -
同时被5和8整除(最小公倍数40)
∣ A ∩ C ∣ = ⌊ 1000 40 ⌋ − ⌊ 98 40 ⌋ = 25 − 2 = 23 |A \cap C| = \left\lfloor \frac{1000}{40} \right\rfloor - \left\lfloor \frac{98}{40} \right\rfloor = 25 - 2 = 23 ∣A∩C∣=⌊401000⌋−⌊4098⌋=25−2=23
计算三集合的交集
同时被5、6、8整除(最小公倍数120)
∣
A
∩
B
∩
C
∣
=
⌊
1000
120
⌋
=
8
|A \cap B \cap C| = \left\lfloor \frac{1000}{120} \right\rfloor = 8
∣A∩B∩C∣=⌊1201000⌋=8
应用三集合容斥原理
不能被5、6、8整除的数的个数为:
∣
A
c
∩
B
c
∩
C
c
∣
=
N
−
∣
A
∣
−
∣
B
∣
−
∣
C
∣
+
∣
A
∩
B
∣
+
∣
B
∩
C
∣
+
∣
A
∩
C
∣
−
∣
A
∩
B
∩
C
∣
=
902
−
181
−
150
−
113
+
30
+
37
+
23
−
8
=
540
\begin{align*} \left| A^c \cap B^c \cap C^c \right| &= N - |A| - |B| - |C| + |A \cap B| + |B \cap C| + |A \cap C| - |A \cap B \cap C| \\ &= 902 - 181 - 150 - 113 + 30 + 37 + 23 - 8 \\ &= 540 \end{align*}
∣Ac∩Bc∩Cc∣=N−∣A∣−∣B∣−∣C∣+∣A∩B∣+∣B∩C∣+∣A∩C∣−∣A∩B∩C∣=902−181−150−113+30+37+23−8=540
验证公式正确性
根据三集合容斥原理的公式:
∣
A
∪
B
∪
C
∣
=
∣
A
∣
+
∣
B
∣
+
∣
C
∣
−
∣
A
∩
B
∣
−
∣
B
∩
C
∣
−
∣
A
∩
C
∣
+
∣
A
∩
B
∩
C
∣
|A \cup B \cup C| = |A| + |B| + |C| - |A \cap B| - |B \cap C| - |A \cap C| + |A \cap B \cap C|
∣A∪B∪C∣=∣A∣+∣B∣+∣C∣−∣A∩B∣−∣B∩C∣−∣A∩C∣+∣A∩B∩C∣
用户的计算通过总基数减去能被至少一个数整除的集合,逻辑正确,数值计算无误。
最终答案
在区间[99, 1000]内,不能被5、6、8中任何一个数整除的数的个数为540。
验证过程符合容斥原理的数学逻辑,结果准确。
2.求 ¬ ( P → Q ) ∧ ( ¬ P → R ) \neg(P \rightarrow Q) \wedge(\neg P \rightarrow R) ¬(P→Q)∧(¬P→R)的主析取范式和合取范式,并用最大项最小项的形式按顺序表示出来。(第一个空格里面是等价符号,最后的 Q 为 R )
真值表法求主范式
命题变元:
P
,
Q
,
R
P, Q, R
P,Q,R,共
2
3
=
8
2^3=8
23=8 种赋值组合。
构造真值表如下:
| P P P | Q Q Q | R R R | ¬ ( P → Q ) \neg(P \rightarrow Q) ¬(P→Q) | ¬ P → R \neg P \rightarrow R ¬P→R | ¬ ( P → Q ) ∧ ( ¬ P → R ) \neg(P \rightarrow Q) \land (\neg P \rightarrow R) ¬(P→Q)∧(¬P→R) |
|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 1 | 0 |
| 0 | 0 | 1 | 0 | 1 | 0 |
| 0 | 1 | 0 | 0 | 1 | 0 |
| 0 | 1 | 1 | 0 | 1 | 0 |
| 1 | 0 | 0 | 1 | 1 | 1 |
| 1 | 0 | 1 | 1 | 1 | 1 |
| 1 | 1 | 0 | 0 | 1 | 0 |
| 1 | 1 | 1 | 0 | 1 | 0 |
成真赋值:仅当 P = 1 , Q = 0 P=1, Q=0 P=1,Q=0 时公式为真,对应两种组合:
-
(
1
,
0
,
0
)
(1,0,0)
(1,0,0) → 二进制
100→ 十进制 4 → 极小项 m 4 = P ∧ ¬ Q ∧ ¬ R m_4 = P \land \neg Q \land \neg R m4=P∧¬Q∧¬R -
(
1
,
0
,
1
)
(1,0,1)
(1,0,1) → 二进制
101→ 十进制 5 → 极小项 m 5 = P ∧ ¬ Q ∧ R m_5 = P \land \neg Q \land R m5=P∧¬Q∧R
成假赋值:其余 6 种组合,对应极大项:
•
(
0
,
0
,
0
)
(0,0,0)
(0,0,0) →
M
0
=
P
∨
Q
∨
R
M_0 = P \lor Q \lor R
M0=P∨Q∨R
•
(
0
,
0
,
1
)
(0,0,1)
(0,0,1) →
M
1
=
P
∨
Q
∨
¬
R
M_1 = P \lor Q \lor \neg R
M1=P∨Q∨¬R
•
(
0
,
1
,
0
)
(0,1,0)
(0,1,0) →
M
2
=
P
∨
¬
Q
∨
R
M_2 = P \lor \neg Q \lor R
M2=P∨¬Q∨R
•
(
0
,
1
,
1
)
(0,1,1)
(0,1,1) →
M
3
=
P
∨
¬
Q
∨
¬
R
M_3 = P \lor \neg Q \lor \neg R
M3=P∨¬Q∨¬R
•
(
1
,
1
,
0
)
(1,1,0)
(1,1,0) →
M
6
=
¬
P
∨
¬
Q
∨
R
M_6 = \neg P \lor \neg Q \lor R
M6=¬P∨¬Q∨R
•
(
1
,
1
,
1
)
(1,1,1)
(1,1,1) →
M
7
=
¬
P
∨
¬
Q
∨
¬
R
M_7 = \neg P \lor \neg Q \lor \neg R
M7=¬P∨¬Q∨¬R
主范式表示
-
主析取范式(极小项析取)
⋁ ( m 4 , m 5 ) ⟺ ( P ∧ ¬ Q ∧ ¬ R ) ∨ ( P ∧ ¬ Q ∧ R ) \bigvee (m_4, m_5) \iff (P \land \neg Q \land \neg R) \lor (P \land \neg Q \land R) ⋁(m4,m5)⟺(P∧¬Q∧¬R)∨(P∧¬Q∧R) -
主合取范式(极大项合取)
⋀ ( M 0 , M 1 , M 2 , M 3 , M 6 , M 7 ) ⟺ ( P ∨ Q ∨ R ) ∧ ( P ∨ Q ∨ ¬ R ) ∧ ( P ∨ ¬ Q ∨ R ) ∧ ( P ∨ ¬ Q ∨ ¬ R ) ∧ ( ¬ P ∨ ¬ Q ∨ R ) ∧ ( ¬ P ∨ ¬ Q ∨ ¬ R ) \bigwedge (M_0, M_1, M_2, M_3, M_6, M_7) \iff (P \lor Q \lor R) \land (P \lor Q \lor \neg R) \land (P \lor \neg Q \lor R) \land (P \lor \neg Q \lor \neg R) \land (\neg P \lor \neg Q \lor R) \land (\neg P \lor \neg Q \lor \neg R) ⋀(M0,M1,M2,M3,M6,M7)⟺(P∨Q∨R)∧(P∨Q∨¬R)∧(P∨¬Q∨R)∧(P∨¬Q∨¬R)∧(¬P∨¬Q∨R)∧(¬P∨¬Q∨¬R)
3.有t个球排一排(t>=3),用红橙黄绿蓝五种颜色给这t个球涂色,每个球只能涂一种颜色,如果要求红橙黄色的球至少出现一个,问有多少种不同的涂色方法。
解:即有红、橙、黄、蓝、绿5种球,每种颜色有无穷个,从中取t排列,且球数满足红橙黄的球至少出现一次。这样该题就变成了排列型数列,即用指数型母函数的方法来解。
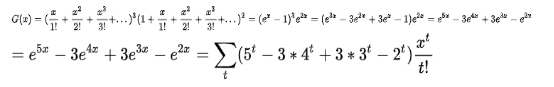
四、问答题
设教室有8个座位排成一排,有A1,A2,A3,A4,A5,A6,A7,A8共8位同学,每位同学都 A i \mathrm {A}_{i} Ai坐在第i(i=1,2,3.....8)个位置上.
(1)若第二节课要求A1-A4与自己第一节课时位置不同,A5-A8与第一节课相同,有多少种坐法?
D
4
=
4
!
(
1
−
1
1
!
+
1
2
!
−
1
3
!
+
1
4
!
)
=
24
×
(
1
−
1
+
1
2
−
1
6
+
1
24
)
=
24
×
9
24
=
9
D_{4}=4!\left(1-\frac{1}{1!}+\frac{1}{2!}-\frac{1}{3!}+\frac{1}{4!}\right)=24 \times\left(1-1+\frac{1}{2}-\frac{1}{6}+\frac{1}{24}\right)=24 \times \frac{9}{24}=9
D4=4!(1−1!1+2!1−3!1+4!1)=24×(1−1+21−61+241)=24×249=9
(2)第二节课要求只有四位同学与第一节课不同,但不指定是哪四位。有多少种坐法?
解: 8 位同学选 4 位不在自己的位置上,共有
C
8
4
C_{8}^{4}
C84 种选法,每确定 4 位同学后根据(1)的结论有 9 种不同的坐法,因此总共有 9 \times C_{8}^{4} 种做法
9 × C 8 4 = 9 × 8 ! 4 ! 4 ! = 9 × 40320 24 × 24 = 630 9 \times C_{8}^{4}=9 \times \frac{8!}{4!4!}=9 \times \frac{40320}{24 \times 24}=630 9×C84=9×4!4!8!=9×24×2440320=630
五.证明题
设+表示两个集合的对称差,对于三个集合A、B、C,如果A⊕B=A⊕C,,则B=C。
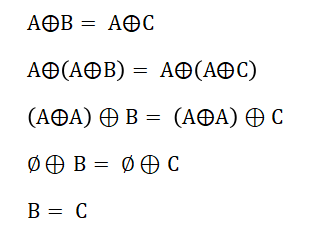
计算机网络
一、填空题
1. 于选择性重传滑动窗口协议,若序号为 N 位,则接收窗口的最大尺寸为 \text { 于选择性重传滑动窗口协议,若序号为 } \mathrm{N} \text { 位,则接收窗口的最大尺寸为 } 于选择性重传滑动窗口协议,若序号为 N 位,则接收窗口的最大尺寸为
2 n − 1 2^{n-1} 2n−1
当序号位数为 N 时,接收窗口的最大尺寸为 ( 2^{N-1} )。
原理分析
-
窗口重叠问题
选择性重传协议允许接收方缓存未按序到达的帧,但窗口移动时需确保新旧窗口的序号范围不重叠。若接收窗口过大,窗口滑动后可能出现新旧窗口包含相同序号的情况,导致接收方无法区分新旧帧。 -
窗口尺寸与序号范围的关系
• 序号位数为 N 时,序号范围为 ( 0 \sim 2^N-1 )(共 ( 2^N ) 个唯一序号)。
• 若接收窗口的尺寸超过序号范围的一半(即 ( 2^{N-1} )),窗口滑动后可能覆盖旧窗口的序号区域,引发混淆。 -
示例验证
以 N=3 为例,序号范围为 0~7,接收窗口最大为 4(即 2 3 − 1 2^{3-1} 23−1)。若接收窗口设为 5,窗口滑动后可能出现新窗口(如 5~9)与旧窗口(如 0~4)的重叠(假设序号循环使用),导致错误接收。
协议特性
• 发送窗口与接收窗口对称性
在选择重传协议中,发送窗口和接收窗口的最大尺寸通常相等,均为
2
N
−
1
2^{N-1}
2N−1。
例如,当 N=3 时,发送窗口和接收窗口的最大值均为 4。
• 与其他滑动窗口协议的对比
• 回退N协议:接收窗口固定为1,发送窗口最大为 ( 2^N-1 )。
• 停等协议:发送窗口和接收窗口均为1。
选择重传通过增大接收窗口提升效率,但需严格限制窗口尺寸以避免错误。
总结
对于序号位数为 N 的选择性重传协议,接收窗口的最大尺寸为 ( 2^{N-1} ),这一限制是防止序号循环导致窗口重叠的关键设计。
2.以太网交换机按照_算法建立转发表,并通过帧中的_进行地址学习。
-
转发表的建立算法
以太网交换机采用自学习算法(Self-Learning Algorithm)动态构建转发表。其核心流程为:
• 当交换机从某端口接收到数据帧时,提取帧中的源MAC地址,并将该地址与接收端口关联记录到转发表中;
• 若转发表中已存在该MAC地址,则更新其对应端口信息;
• 通过持续学习各端口的源MAC地址,逐步完善转发表。 -
地址学习依据的帧字段
地址学习的关键依据是数据帧中的源MAC地址字段。例如:
• 当主机A发送数据帧到主机B时,交换机会解析帧头的源MAC地址(如00:11:22:33:44:55),并将其与接收端口(如Port 1)绑定记录;
• 这一过程无需人工干预,完全由交换机自动完成。 -
补充机制
• 老化机制:转发表项设置生存时间(TTL),若超时未更新则自动删除,避免过时信息占用资源;
• 泛洪机制:当目标MAC地址不在转发表时,交换机会广播数据帧到所有端口(除接收端口),确保目标设备能收到数据。
答案总结
以太网交换机按照自学习算法建立转发表,并通过帧中的源MAC地址进行地址学习。这一机制结合老化与泛洪策略,实现了高效、动态的网络数据转发。
3.以211.115.32.0开始有连续可用的IP地址,若某个单位需要申请800个地址,掩码的前缀长度为_位,相当于_个连续的C类地址块。
1. 掩码前缀长度的计算
• 主机位数需求:
可用主机数公式为
2
h
−
2
≥
800
2^h - 2 \geq 800
2h−2≥800,其中 ( h ) 为主机位数。
解得 ( h = 10 )(( 2^{10} - 2 = 1022 ),满足800个地址需求)。
• 前缀长度:
前缀长度 = 总位数(32) - 主机位数(10) = 22位 。
2. 所需的C类地址块数量
• C类地址块特性:
每个C类地址块默认提供256个IP地址(可用主机数为254个)。
• 需求换算:
( 800 \div 256 = 3.125 ),向上取整需4个连续C类地址块 。
总结
• 掩码前缀长度:22位
• C类地址块数量:4个
• 实际可用地址:1022个(满足800个需求)
4.主机A向主机B发送IP分组,途中经过6个路由器,那么在IP分组的发送过程中,共使心了_次ARP协议。
答案:7次共需7次,主机先通过arp得到第一个路由器的MAC,之后每一个路由器转发前都通过ARP得到下一跳路由器的MAC,最后一条路由器将IP包发给B前仍要通过ARP得到B的MAC,共 7 次。
二、单项选择题(每小题1分,共5分)
1、要控制网络上的广播风暴,可以采用的方法为()
A用集线器将网络分段
B.用网桥将网络分段
C.用交换机将网络分段
D.用路由器将网络分段
要控制网络上的广播风暴,关键在于分割广播域。以下是对各选项的分析:
-
集线器(Hub):工作在物理层,所有连接设备处于同一广播域。集线器仅扩展传输距离,无法隔离广播帧,因此无法控制广播风暴。
-
网桥(Bridge):工作在数据链路层,通过MAC地址转发帧。虽然能分割冲突域,但默认会广播所有广播帧到所有端口,无法隔离广播域。
-
交换机(Switch):默认行为与普通网桥类似,所有端口属于同一广播域。但若配置VLAN(虚拟局域网),可划分多个广播域。题目未明确说明是否使用VLAN,因此默认情况下无法控制广播风暴。
-
路由器(Router):工作在网络层,每个接口独立为一个广播域。路由器通过IP寻址隔离子网,广播帧不会跨路由器传播,天然分割广播域,是最直接有效的方法。
结论:题目未提及VLAN配置,因此最符合题意且无需额外条件的正确答案是 D. 用路由器将网络分段。
2.若IP地址是10.12.100.2,子网掩码是255.255.224.0 则该子网的地址是( )
A.10.12.0.0
B.10.12.32.0
C.10.12.96.0
D.10.12.128.0
根据题目要求,给定IP地址为10.12.100.2,子网掩码为255.255.224.0,计算子网地址的过程如下:
1. 核心计算步骤
-
将IP地址和子网掩码转换为二进制
• IP地址:10.12.100.2 → 00001010.00001100.01100100.00000010
• 子网掩码:255.255.224.0 → 11111111.11111111.11100000.00000000 -
按位与运算
对二进制形式的IP地址和子网掩码逐位进行逻辑与(AND)运算:00001010.00001100.01100100.00000010 (IP地址) AND 11111111.11111111.11100000.00000000 (子网掩码) = 00001010.00001100.01100000.00000000 (网络地址)• 结果:二进制网络地址为 10.12.96.0(对应选项C)。
2. 关键验证
• 子网掩码的第三字节分析:
子网掩码的第三字节为 224(二进制 11100000),表示前 3位 为网络位,后 5位 为主机位。
• IP地址的第三字节为 100(二进制 01100100),与掩码的 11100000 进行与运算后,保留前3位 011,后5位清零,结果为 01100000(十进制 96)。
• 网络地址的规则性:
子网掩码为 255.255.224.0(即 /19),其子网划分的增量值为 32(由 2^5=32 主机位决定)。因此,合法的子网地址第三字节应为 32的倍数(如 0、32、64、96、128 等)。
• 10.12.96.0 符合这一规则,而其他选项(如 32、128)与计算结果不符。
3. 选项排除
• 选项A(10.12.0.0):子网掩码为 /19,第三字节未清零至0,排除。
• 选项B(10.12.32.0):第三字节 32 是32的倍数,但与IP地址的第三字节 100 运算后不匹配,排除。
• 选项D(10.12.128.0):第三字节 128 超出当前掩码的覆盖范围,排除。
答案
正确选项:C. 10.12.96.0
通过二进制逻辑与运算和子网划分规则验证,该子网的网络地址为 10.12.96.0。
3.不属于路由选择协议的功能是( )
A.发现下一跳的物理地址
B.获得网络拓扑结构信息
C.将路由信息在互连网络内扩散
D.创建链路状态数据库
答案:A. 发现下一跳的物理地址
路由选择协议的核心功能是在网络中动态维护和更新路由信息,确保路由器能够选择最优路径转发数据分组。结合搜索结果中的定义和功能描述,分析如下:
-
选项A(发现下一跳的物理地址)
• 不属于路由选择协议的功能。
• 下一跳的物理地址(MAC地址)通过ARP协议解析,而非路由选择协议。例如,当路由器需要转发数据时,若目标IP地址的MAC地址未知,会触发ARP请求以获取。
• 路由选择协议仅负责逻辑路径的选择,不涉及物理层地址的映射。 -
选项B(获得网络拓扑结构信息)
• 属于路由选择协议的功能。
• 路由选择协议(如OSPF、RIP)通过交换路由信息,动态构建和维护网络拓扑结构。例如,OSPF通过链路状态广播(LSA)收集全网拓扑信息。 -
选项C(将路由信息在互连网络内扩散)
• 属于路由选择协议的功能。
• 路由选择协议的核心机制是路由信息的扩散与共享。例如,RIP通过周期性广播路由表,BGP通过邻居会话交换路由更新。 -
选项D(创建链路状态数据库)
• 属于路由选择协议的功能(链路状态协议特有)。
• OSPF等链路状态协议会创建并维护链路状态数据库(LSDB),记录全网链路的详细状态信息,用于计算最短路径。
总结
路由选择协议的核心任务是逻辑路径的发现与维护,而物理地址的解析(如MAC地址)依赖其他协议(如ARP)。因此,正确答案为 A. 发现下一跳的物理地址。
4.主机甲与主机乙之间已建立TCP连接,主机甲向主机乙发送了三个TCP段,其中有效载荷长度分别为400,500,600字节,第一个段的序号为200,传输过程中第二个段丢失,主机乙收到第一和第三个段后分别返回确认,分别返回的两个确认号是( )。
A.600和900
B.600和1500
C. 600和600
D.600和1100
答案:C. 600和600
解析
根据TCP的累积确认机制和题目条件,确认号表示期望接收的下一个字节序号,具体分析如下:
-
第一个段(序号200,长度400字节)
• 覆盖字节范围:200 ~ 599(含)。
• 接收方正确接收后,返回确认号 600(即下一个期望的序号)。 -
第三个段(序号1100,长度600字节)
• 覆盖字节范围:1100 ~ 1699(含)。
• 由于第二个段(序号600,长度500字节)丢失,接收方无法确认600 ~ 1099的数据。即使收到第三个段,TCP要求数据必须按序接收,因此接收方缓存第三个段,但确认号仍保持为 600(表示仍等待600开始的连续数据)。 -
确认号的逻辑
• 接收方在收到非连续数据段时,会重复发送上一次的确认号(600),直到中间缺失的段被重传并正确接收。
• 题目中两次确认的确认号均为 600,选项C正确。
关键验证
• 序号计算:
• 第一个段结束于599,第二个段应覆盖600 ~ 1099,第三个段覆盖1100 ~ 1699。
• 第二个段丢失导致接收方无法确认后续数据,确认号始终为600。
• TCP规则:
累积确认机制下,确认号仅基于连续接收的最大字节序号,非连续数据不影响确认号。
总结
无论是否收到后续非连续数据,确认号始终为下一个期望的连续字节序号。因此,两次确认号均为 600,正确答案为 C. 600和600。
5.下列协议中使用UDP协议传送的是 ( )
A.FTP
B.DNS
C.HTTP
D.OSPF
答案:B. DNS
解析
-
FTP (File Transfer Protocol)
• 使用TCP协议(端口20/21)。
• 文件传输需要可靠连接,确保数据完整性。 -
DNS (Domain Name System)
• 默认使用UDP(端口53),适用于快速解析请求(如域名→IP)。
• 仅当响应数据超过512字节或需要区域传输时,才切换至TCP。 -
HTTP (Hypertext Transfer Protocol)
• 使用TCP(端口80/443),确保网页内容(HTML、图片等)完整传输。 -
OSPF (Open Shortest Path First)
• 直接封装在IP协议中(协议号89),不依赖TCP/UDP,自行处理可靠性与路由更新。
结论
只有DNS在常规操作中使用UDP进行数据传输,因此正确答案为 B. DNS。
三、名词解释(4分)
1.最小生成树算法
答:最小生成树(Minimum Spanning Tree,MST)或者称为最小代价生成树Minimum- cost Spannirng Tree:对无向连通图的生成树,各边的权值总和称为生成树的权,权最小的生成树称为最小生成树。构造最小生成树的准则有3 条。(1)必须只使用该网络中的边来构造最小生成树。(2)必须使用且仅使用n-1条边来连接网络中的n个顶点。(3)不能使用产生回路的边。构造最小生成树的算法主要有:克鲁斯卡尔(Kruskal)算法、Boruvka算法和普里姆(Prim)算法,它们都得遵守以上准则。它们都采用了一种逐步求解的策略。
2.CSMA/CA
答:无线局域网CSMA/CA的协议,即载波监听多址接入/碰撞避免(Carrier Sense Multiple Access/ Collision Avoidance),在CSMA的基础上增加了一个碰撞避免(Collision Avoidance)功能,而不再实现碰撞检测功能。由于不可能避免所有的碰撞,且无线信道误码率较高,802.11还使用了数据链路层确认机制来保证数据被正确接收。
四、问答和计算题(共15分)(计算中记, 1 G ≈ 1 0 9 1\mathrm {G}\approx 10^{9} 1G≈109, 1 M ≈ 1 0 6 1\mathrm {M}\approx 10^{6} 1M≈106, 1 ∼ K ≈ 1 0 3 1\mathrm {\sim K}\approx 10^{3} 1∼K≈103)
1.(共 4 分)假设地球到某个行星的距离的为 9 × 1 0 10 9 \times 10^{10} 9×1010 米,在一条 128 Mbps 的点到点链路上传输数据帧。大小为 64 K 字节,光速为 3 × 1 0 8 3 \times 10^{8} 3×108 米/秒
(1)若采*用简单停-等协议,信道利用率是多少?
(2)若使链路利用率达到 100 % 发送窗口是多少字节?(忽略协议处理时延)
解答
(1)信道利用率计算
• 传播时延(单程):
T
prop
=
9
×
1
0
10
米
3
×
1
0
8
米/秒
=
300
秒
T_{\text{prop}} = \frac{9 \times 10^{10} \, \text{米}}{3 \times 10^8 \, \text{米/秒}} = 300 \, \text{秒}
Tprop=3×108米/秒9×1010米=300秒
• 往返时间(RTT):
RTT
=
2
×
T
prop
=
600
秒
\text{RTT} = 2 \times T_{\text{prop}} = 600 \, \text{秒}
RTT=2×Tprop=600秒
• 传输时延:
T
tx
=
64
×
1
0
3
字节
×
8
位/字节
128
×
1
0
6
位/秒
=
0.004
秒
T_{\text{tx}} = \frac{64 \times 10^3 \, \text{字节} \times 8 \, \text{位/字节}}{128 \times 10^6 \, \text{位/秒}} = 0.004 \, \text{秒}
Ttx=128×106位/秒64×103字节×8位/字节=0.004秒
• 总周期时间:
T
total
=
T
tx
+
RTT
=
0.004
+
600
=
600.004
秒
T_{\text{total}} = T_{\text{tx}} + \text{RTT} = 0.004 + 600 = 600.004 \, \text{秒}
Ttotal=Ttx+RTT=0.004+600=600.004秒
• 信道利用率:
η
=
T
tx
T
total
=
0.004
600.004
≈
6.67
×
1
0
−
6
=
0.00067
%
\eta = \frac{T_{\text{tx}}}{T_{\text{total}}} = \frac{0.004}{600.004} \approx 6.67 \times 10^{-6} = \boxed{0.00067\%}
η=TtotalTtx=600.0040.004≈6.67×10−6=0.00067%
(2)发送窗口大小计算
• 带宽时延积(BDP):
BDP
=
带宽
×
RTT
=
128
×
1
0
6
位/秒
×
600
秒
=
76.8
×
1
0
9
位
\text{BDP} = \text{带宽} \times \text{RTT} = 128 \times 10^6 \, \text{位/秒} \times 600 \, \text{秒} = 76.8 \times 10^9 \, \text{位}
BDP=带宽×RTT=128×106位/秒×600秒=76.8×109位
• 转换为字节:
窗口大小
=
76.8
×
1
0
9
位
8
位/字节
=
9.6
×
1
0
9
字节
\text{窗口大小} = \frac{76.8 \times 10^9 \, \text{位}}{8 \, \text{位/字节}} = \boxed{9.6 \times 10^9 \, \text{字节}}
窗口大小=8位/字节76.8×109位=9.6×109字节
结论
- 使用停-等协议时,信道利用率极低,仅 0.00067%。
- 要达到100%链路利用率,发送窗口需覆盖带宽时延积,即 9.6×10⁹字节。
同样的题如下:
地球到一个遥远行星的距离大约是 9 × 1 0 10 9 \times 10^{10} 9×1010 米。如果采用停-等式协议在一条 64 Mbps
的点到点链路上传输帧,试问信道的利用率是多少?假设帧的大小为 32 KB ,光的速度是 3 × 1 0 8 m / s 3 \times 10^{8} \mathrm{~m} / \mathrm{s} 3×108 m/s 。
在上题的问题中,假设用滑动窗口协议来代替停-等协议。试问多大的发送窗口才能使得链路利用率为 100 % 100 \% 100%
?发送方和接收方的协议处理时间可以忽略不计}。
解答
(1)信道利用率计算
• 传播时延(单程):
T
prop
=
9
×
1
0
10
米
3
×
1
0
8
米/秒
=
300
秒
T_{\text{prop}} = \frac{9 \times 10^{10} \, \text{米}}{3 \times 10^8 \, \text{米/秒}} = 300 \, \text{秒}
Tprop=3×108米/秒9×1010米=300秒
• 往返时间(RTT):
RTT
=
2
×
T
prop
=
600
秒
\text{RTT} = 2 \times T_{\text{prop}} = 600 \, \text{秒}
RTT=2×Tprop=600秒
• 传输时延:
T
tx
=
32
×
1
0
3
字节
×
8
位/字节
64
×
1
0
6
位/秒
=
0.004
秒
T_{\text{tx}} = \frac{32 \times 10^3 \, \text{字节} \times 8 \, \text{位/字节}}{64 \times 10^6 \, \text{位/秒}} = 0.004 \, \text{秒}
Ttx=64×106位/秒32×103字节×8位/字节=0.004秒
• 总周期时间:
T
total
=
T
tx
+
RTT
=
0.004
+
600
=
600.004
秒
T_{\text{total}} = T_{\text{tx}} + \text{RTT} = 0.004 + 600 = 600.004 \, \text{秒}
Ttotal=Ttx+RTT=0.004+600=600.004秒
• 信道利用率:
η
=
T
tx
T
total
=
0.004
600.004
≈
6.67
×
1
0
−
6
=
0.00067
%
\eta = \frac{T_{\text{tx}}}{T_{\text{total}}} = \frac{0.004}{600.004} \approx 6.67 \times 10^{-6} = \boxed{0.00067\%}
η=TtotalTtx=600.0040.004≈6.67×10−6=0.00067%
结论
使用停-等式协议时,由于往返时间极大(600秒)而传输时间极短(0.004秒),信道利用率仅为 0.00067%,表明链路几乎完全空闲。
解答
要使得链路利用率达到 100%,发送窗口需覆盖带宽时延积(BDP),即链路中可容纳的最大数据量。具体步骤如下:
1. 计算带宽时延积(BDP)
• 带宽:( 64 , \text{Mbps} = 64 \times 10^6 , \text{位/秒} )
• 往返时间(RTT):
T
prop
=
9
×
1
0
10
3
×
1
0
8
=
300
秒
,
RTT
=
2
×
T
prop
=
600
秒
T_{\text{prop}} = \frac{9 \times 10^{10}}{3 \times 10^8} = 300 \, \text{秒}, \quad \text{RTT} = 2 \times T_{\text{prop}} = 600 \, \text{秒}
Tprop=3×1089×1010=300秒,RTT=2×Tprop=600秒
• BDP(位):
BDP
=
带宽
×
RTT
=
64
×
1
0
6
×
600
=
3.84
×
1
0
10
位
\text{BDP} = \text{带宽} \times \text{RTT} = 64 \times 10^6 \times 600 = 3.84 \times 10^{10} \, \text{位}
BDP=带宽×RTT=64×106×600=3.84×1010位
• BDP(字节):
BDP
=
3.84
×
1
0
10
8
=
4.8
×
1
0
9
字节
\text{BDP} = \frac{3.84 \times 10^{10}}{8} = 4.8 \times 10^9 \, \text{字节}
BDP=83.84×1010=4.8×109字节
2. 计算发送窗口(以帧数为单位)
• 每帧大小:( 32 , \text{KB} = 32 \times 10^3 , \text{字节} )(题目约定 ( 1\mathrm{K} \approx 10^3 ))
• 窗口帧数:
W
=
BDP
帧大小
=
4.8
×
1
0
9
32
×
1
0
3
=
150
,
000
帧
W = \frac{\text{BDP}}{\text{帧大小}} = \frac{4.8 \times 10^9}{32 \times 10^3} = 150,000 \, \text{帧}
W=帧大小BDP=32×1034.8×109=150,000帧
3. 验证时间比值法
• 单帧传输时间:
T
tx
=
32
×
1
0
3
×
8
64
×
1
0
6
=
0.004
秒
T_{\text{tx}} = \frac{32 \times 10^3 \times 8}{64 \times 10^6} = 0.004 \, \text{秒}
Ttx=64×10632×103×8=0.004秒
• 窗口帧数:
W
=
RTT
T
tx
=
600
0.004
=
150
,
000
帧
W = \frac{\text{RTT}}{T_{\text{tx}}} = \frac{600}{0.004} = 150,000 \, \text{帧}
W=TtxRTT=0.004600=150,000帧
4. 结论
• 发送窗口大小需至少为 ( 150,000 , \text{帧} ),对应总字节数为 ( 4.8 \times 10^9 , \text{字节} )。
• 若严格按 ( \frac{\text{RTT} + T_{\text{tx}}}{T_{\text{tx}}} ) 计算(如题目答案),结果为 ( 150,001 ),但实际只需覆盖 BDP,故正确答案为:
1.5
×
1
0
5
帧
或
4.8
×
1
0
9
字节
\boxed{1.5 \times 10^5 \, \text{帧}} \quad \text{或} \quad \boxed{4.8 \times 10^9 \, \text{字节}}
1.5×105帧或4.8×109字节
2.(共 5 分)若使用 TCP 协议传送文件,TCP 的报文段大小为 1K 字节(假设无拥塞,无丢失分组),接收方通告窗口为 1 M 字节。
(1)简要说明 TCP 慢启动算法。
(2)当慢启动阶段发送窗口达到 1 M 字节时。用了多少个往返时延(RTT)
(1)解:慢启动算法(slow start),是传输控制协议使用的一种拥塞控制机制。工作原理为在主机刚刚开始发送报文段时,可先设置拥塞窗口cwnd=1,即设置为一个最大报文段 MSS 的数值。在每收到一个对新的报文段的确认后,将拥塞窗口加1,即增加一个MSS的数值。用这样的方法逐步增大发送端的 拥塞窗口cwnd,可以使分组注入到网络的速率更加合理。其实慢启动一点也不慢只是起点比较低,是指数增长。
(2)解:假设当慢启动阶段发送窗口达到 1 M 字节时,用了 x 个往返时延,则开始 —>
c
w
n
d
=
1
个
M
S
S
=
1
K
=
103
\mathrm{cwnd}=1 个 MSS=1K=103
cwnd=1个MSS=1K=103
经过 1 个 RTT 后-->
c
w
n
d
=
2
1
M
S
S
=
2
∗
1
0
3
cwnd =2^{1} MSS =2^{*} 10^{3}
cwnd=21MSS=2∗103
经过 2 个 RTT 后 -->
c
w
n
d
=
2
2
M
S
S
=
4
∗
1
0
3
cwnd =2^{2} MSS =4^{*} 10^{3}
cwnd=22MSS=4∗103
经过 3 个 RTT 后 -->
c
w
n
d
=
2
3
M
S
S
=
8
∗
1
0
3
\mathrm{cwnd}=2^{3} \mathrm{MSS}=8^{*} 10^{3}
cwnd=23MSS=8∗103
经过 x 个 RTT 后 -->
c
c
w
n
d
=
2
x
M
S
S
=
2
∗
∗
1
0
3
=
1
0
6
c cwnd =2^{x} \quad MSS =2^{* *} 10^{3}=10^{6}
ccwnd=2xMSS=2∗∗103=106
2
x
=
1
0
3
2
10
=
1024
x
≈
10
2^{x}=10^{3} 2^{10}=1024 x \approx 10
2x=103210=1024x≈10 故,因此,用了 10 个 RTT。
3.(共6分)如图1所示的网络中,采用距离向量算法进行路由选择。
(1)初始时,每个节点只知道到达相邻节点的距离,写出节点E的距离向量表(目标,开销,下一跳)。
(1) E路由,初始距离向量表
| 目标 | 开销 | 下一跳 |
|---|---|---|
| A | 5 | A |
| B | ∞ | 无 |
| C | ∞ | 无 |
| D | 6 | D |
| E | 0 | 直连 |
| F | 4 | F |
(2)第一次交换距离向量时,每个节点仅将初始时的路由表告知其相邻节点,试写出更新后节点E的距离向量表。
| 目标节点 | 开销 | 下一跳 |
|---|---|---|
| A | 5 | A |
| B | 7 | A |
| C | 8 | D |
| D | 6 | D |
| E | 0 | 直连 |
| F | 4 | F |
(3)当节点F到节点E的链路出现故障后,试分析距离向量算法可能出现的慢收敛问题。
网络阻碍,导致慢收敛问题:RIP存在的一个问题是当网络出现故障时,要经过较长的时间才能将此信息传送到所有的路由器。E在收到F的报文更新之前,给(A和D)还发送原来的报文,我们拿A来看,因为此时A也不知道F也出了故障,E收到 A 的更新报文后,误认为经过 A 可以到 F,于是更新自己的路由表说,我到 F 的距离为 10,下一跳经过 A; 然后将此更新送给 A,A 又更新路由表说我到 F 距离 11,下一跳经过 E;就这样不断更新下去,直到 E 和 A 到 F 的 距离都增大到 16 时,E 和 A 才知道 F 是不可达的。于是这样好消息传播的快,坏消息传播的慢,网络出故障的传播 时间要经过较长的时间。这就是 RIP 协议的慢收敛问题。

软件工程
一、单项选择题(每小题1分,共5分)
1.创建和分发软件产品版本并安装到它们的工作场所,这是RUP的 (B) 工作表应做的事情。
A.分析和设计
B.部署
C.需求
D.配置和变更管理
B RUP (Rational Unified Process) 静态视角工作流说明
| 工作流 | 描述 |
|---|---|
| 业务建模 | 使用业务用例对业务过程进行建模 |
| 需求 | 找出与系统进行交互的参与者并开发用例,完成对系统需求的建模 |
| 分析和设计 | 使用体系结构模型、构件模型、对象模型和交互模型来创建并记录设计模型 |
| 实现 | 实现系统中的构件并将它们合理安排在子系统中。从设计模型自动代码生成有助于加快此过程 |
| 测试 | 测试是一个反复过程,它的执行是与实现紧密相关联的。系统测试紧随实现环节的完成 |
| 部署 | 创建和分发产品版本并安装到它们的工作场所 |
| 配置和变更管理 | 支持工作流管理对系统的变更 |
| 项目管理 | 支持工作流管理系统开发 |
| 环境 | 用于提供软件开发团队可用的合适的软件工具 |
2.在描述UML用例模型活动场景的顺序图中,将所有相关对象安排在图的顶部,其中最靠近参与者(外部实体)的对象属于 ©。
A.实体类
B.控制类
C.边界类
D.主动类
答:C
UML类的三种类型:(1)边界类,用于描述外部参与者与系统之间的交互的类。 边界类位于系统与外界的交界处,窗体、报表、以及表示通讯协议的类、直接与外部设备交互的类、直接与外部系统交互的类等都是边界类。通过用例图可以确定需要的边界类,每个Actor/Use Case 对至少要一个边界类,但并非每个 Actor/Use Case对要唯一的边界类。(2)控制类,控制其他类;每个用例通常有一个控制类,控制用例中的事件顺序,控制类也可以在多个用例间共用。其他类并不向控制类发送很多消息,而是由控制类发出很多消息。(3)实体类,存储信息和相关行为的类; 实体类保存要放进持久存储体的信息。持久存储体就是数据库、文件等可以永久存储数据的介质。实体类可以通过事件流和交互图发现。通常每个实体类在数据库中有相应的表,实体类中的属性对应数据库表中的字段。
3.在软件生存周期过程中,属于生存周期基本过程的是 ( )。
A.运行过程
B.管理过程
C.配置管理过程
D.质量保证过程
根据软件生存周期过程的定义,属于生存周期基本过程的是选项A:运行过程。以下是具体分析:
答案解析
软件生存周期的基本过程是指与软件生产直接相关的核心活动集。根据国际标准ISO/IEC 12207及多份搜索结果:
• 基本过程包括:获取过程、供应过程、开发过程、运行过程、维护过程。
• 运行过程(选项A)是软件部署后实际投入使用并持续提供服务的关键阶段,属于基本过程的核心环节。
其他选项的归类如下:
- 管理过程(选项B):属于组织过程,负责项目计划、资源分配和进度监控,而非直接生产活动。
- 配置管理过程(选项C)和质量保证过程(选项D):属于支持过程,为基本过程提供辅助保障(如版本控制、质量审核等)。
扩展说明
-
基本过程的核心作用:
• 运行过程:确保软件在用户环境中稳定运行,满足实际需求。
• 开发过程:包含需求分析、设计、编码、测试等核心生产活动。
• 维护过程:持续修复缺陷、优化性能或适应环境变化。 -
其他过程分类:
• 支持过程:如配置管理、质量保证、验证等,确保基本过程的规范性和质量。
• 组织过程:如管理、基础设施、培训等,支撑整个软件工程体系的运作。
结论
正确答案为 A. 运行过程。
4.在有关程序设计风格或编码规范的说法中,错误的是 ( )。
A.可以把多个短语句写在一行内
B.在源程序的首部应插入注释
C.标识符的命名应清晰并有明确含义
D.不能随便改变与其他模块的接口
在程序设计风格或编码规范中,错误的说法是选项A:“可以把多个短语句写在一行内”。以下是具体分析:
选项A:可以把多个短语句写在一行内
错误原因:
• 违反代码可读性原则:所有搜索结果均强调代码应保持简洁和可读性。例如,网页4明确指出:“不允许把多个短语句写在一行中,即一行只写一条语句”。
• 规范示例:
rect.length = 0; rect.width = 0; // 错误写法
rect.length = 0; // 正确写法
rect.width = 0; // 正确写法
将多个短语句写在一行会导致代码拥挤,增加维护难度。
其他选项的正确性分析
-
选项B:在源程序的首部应插入注释
• 正确:几乎所有编码规范都要求文件头部包含注释,说明文件功能、作者、修改历史等信息(如网页3、4、5均提到文件头注释的必要性)。 -
选项C:标识符的命名应清晰并有明确含义
• 正确:这是编码规范的核心原则之一。例如:
◦ 网页1指出“忽视命名规范”是典型的不良编程风格;
◦ 网页3和网页4详细规定了变量、函数等的命名规则(如使用驼峰式、避免拼音等)。 -
选项D:不能随便改变与其他模块的接口
• 正确:接口的稳定性是模块化设计的重要原则。例如:
◦ 网页3提到“模块间应通过接口函数访问全局数据,避免直接耦合”;
◦ 网页5强调“接口隔离原则”,要求接口尽量细化并保持稳定。
总结
错误的说法是 选项A,因其直接违反代码可读性和格式规范。其他选项均符合主流编码规范的要求。
5.在有关软件测试的测试用例设计方法中,属于白盒测试的是 ()。
A.边界值分析法
B.条件组合覆盖法
C.等价类划分法
D.因果图法
答:B
黑盒测试:等价类划分、边界值分析法、猜错法、因果图;白盒测试:代码检查法、静态结构分析法、静态质量度量法、逻辑覆盖法、基本路径测试法、域测试、符号测试、路径覆盖和程序变异。
二、判断题(每小题1分,共5分。如果正确,用“✓”表示,否则,用“x”表示)
1.软件需求规格说明应描述待开发系统“能做什么”而不是“怎样实现”。(✓)
答案:正确
解析:
软件需求规格说明书(SRS)的核心是定义系统的功能需求、性能需求及约束条件,而非具体实现细节。根据搜索结果,SRS应明确系统“应实现哪些功能”及“达到何种性能标准”,而非描述技术实现方式。例如:
“SRS中的功能需求必须明确系统应该做什么,而非如何实现”。
“需求规格说明书是技术指南,侧重于‘做什么’,而非‘怎么做’”。
因此,该说法符合标准需求工程规范。
2.划分程序的模块机构时,要求模块的控制范围应在该模块的作用范围内。 (x)
答案:错误
解析:
模块的控制范围包括模块本身及其所有的从属模块。模块的作用范围是指模块一个判定的作用范围,凡是受这个判定影响的所有模块都属于这个判定的作用范围。原则上一个模块的作用范围应该在其控制范围之内,若没有,则可以将判定所在模块合并到父模块中,使判定处于较高层次;将受判定影响的模块下移到
控制范围内;将判定上移到层次中较高的位置。
3.建立系统体系结构的第一步是建立系统的逻辑视图,即建立系统面向问题的逻辑架构。
(✓)
4.在设计软件测试用例时应尽量把所有可能的情况都考虑到。(x)
软件测试用例的详细程度首先要以覆盖到测试点为基本要求
5.编制预算和进度表,属于CMMI已管理级“项目策划”过程域的专用实践。(✓)
# CMMI阶段式表示(成熟度等级与过程域)
## 第2级 已管理级 过程域(PA)
### 需求管理(REQM)
- **SG1 管理需求**
- SP1.1 获得各方对需求的共同理解
- SP1.2 获得各方对需求的承诺
- SP1.3 管理需求的变更
- SP1.4 维护需求的双向可追溯性(需求跟踪矩阵)
- SP1.5 识别项目工作与需求的不一致之处
### 项目规划(PP)
- **SG1 项目估算**
- SP1.1 估算范围(任务描述、工作包、工作分解结构WBS)
- SP1.2 估算工作成果和任务属性(估算模型、估算结果)
- SP1.3 定义项目生命周期
- SP1.4 估算工作量和成本
- **SG2 制定项目计划**
- SP2.1 编制预算和进度
- SP2.2 识别项目风险
- SP2.3 规划项目数据
- SP2.4 规划项目资源
- SP2.5 规划知识和技能
- SP2.6 规划干系人参与
- SP2.7 建立项目计划
- **SG3 获得计划的承诺**
- SP3.1 审查从属计划
- SP3.2 协调工作与资源配置
- SP3.3 获得计划承诺
### 项目监控(PMC)
- **SG1 根据计划监控项目**
- SP1.1 监督项目计划的参数
- SP1.2 监督承诺
- SP1.3 监督风险
- SP1.4 监督数据管理
- SP1.5 监督干系人参与
- SP1.6 进度审查
- SP1.7 里程碑审查
- **SG2 管理纠正措施**
- SP2.1 分析问题
- SP2.2 采取纠正措施
- SP2.3 管理纠正措施
### 供应商协议管理(SAM)
- **SG1 签订供应商协议**
- SP1.1 确定采购方式
- SP1.2 选择供应商
- SP1.3 签订供应商协议
- **SG2 履行供应商协议**
- SP2.1 执行供应商协议
- SP2.2 监督选定的供应过程
- SP2.3 评价供应商产品
- SP2.4 验收供应商产品
- SP2.5 移交产品
### 度量分析(MA)
- **SG1 协调度量和分析活动**
- SP1.1 确定度量目标
- SP1.2 细化度量(代码行数、工时、挣值管理等)
- SP1.3 确定数据收集和存储规格
- SP1.4 确定分析规程
- **SG2 提供度量结果**
- SP2.1 收集度量数据
- SP2.2 分析度量数据
- SP2.3 存储数据和度量结果
- SP2.4 通报度量结果
### 过程和产品质量保证(PPQA)
- **SG1 客观评价过程和成果**
- SP1.1 客观评价过程
- SP1.2 客观评价成果或服务
- **SG2 提供客观的理解**
- SP2.1 通报不合规问题,并确保问题得以解决
- SP2.2 建立记录
### 配置管理(CM)
- **SG1 建立基线**
- SP1.1 识别配置项(对外交付产品、对内交付工作成果、外购产品)
- SP1.2 建立配置管理系统(配置系统、变更请求数据库)
- SP1.3 创建或发布基线
- **SG2 跟踪并控制变更**
- SP2.1 跟踪变更请求
- SP2.2 控制变更
- **SG3 建立完整性**
- SP3.1 建立配置管理记录(变更记录、配置项历史等)
- SP3.2 执行配置审计
---
## 第3级 已定义级 过程域(PA)
### 需求开发(RD)
- **SG1 开发客户需求**
- SP1.1 获取客户的需要
- SP1.2 开发客户的需求
- **SG2 开发产品需求**
- SP2.1 建立产品需求和构建需求
- SP2.2 分配产品构建需求
- SP2.3 确定接口需求
- **SG3 分析和确认需求**
- SP3.1 建立操作概念和场景
- SP3.2 定义需求
- SP3.3 分析需求
- SP3.4 平衡需求
- SP3.5 确认需求
### 技术方案(TS)
- **SG1 选择产品构件方案**
- SP1.1 开发候选方案和制作选择标准
- SP1.2 选择产品构件方案
- **SG2 设计**
- SP2.1 设计产品构件
- SP2.2 建立技术数据包
- SP2.3 设计接口
- SP2.4 分析“制作、购买或重用”
- **SG3 实现产品设计**
- SP3.1 实现构件的设计
- SP3.2 编写产品支持文档
### 产品集成(PI)
- **SG1 准备产品集成**
- SP1.1 确定集成次序
- SP1.2 建立产品集成环境
- SP1.3 建立产品集成规程和准则
- **SG2 确保接口兼容**
- SP2.1 审查接口描述的完整性
- SP2.2 管理接口
- **SG3 组装产品构件和交付产品**
- SP3.1 确认产品集成已准备就绪
- SP3.2 组装产品构件
- SP3.3 核查组装的产品构件
- SP3.4 打包并交付产品或构件
### 验证(VAL)
- **SG1 准备验证**
- SP1.1 选择待验证的工作成果
- SP1.2 建立验证环境
- SP1.3 建立验证规程和准则
- **SG2 执行同行评审**
- SP2.1 准备同行评审
- SP2.2 执行同行评审
- SP2.3 分析同行评审
- **SG3 验证选定的工作成果**
- SP3.1 执行验证
- SP3.2 分析验证成果
### 确认(VER)
- **SG1 准备确认**
- SP1.1 选择待确认的产品
- SP1.2 建立确认环境
- SP1.3 建立确认规程和准则
- **SG2 确认产品或构件**
- SP2.2 执行确认
- SP2.3 分析确认结果
### 组织过程焦点(OPF)
- **SG1 确定过程改进机会**
- SP1.1 识别组织过程改进需要
- SP1.2 评估组织过程
- SP1.3 识别组织过程改进机会
- **SG2 规划和实施过程改进**
- SP2.1 制定过程行动计划
- SP2.2 实施过程行动计划
- **SG3 推广和丰富组织过程财富**
- SP3.1 推广组织过程财富
- SP3.2 推广组织标准过程
- SP3.3 监督实施
- SP3.4 将过程相关经验纳入组织过程财富
### 组织过程定义(OPD)
- **SG1 创建组织过程财富**
- SP1.1 建立标准过程
- SP1.2 建立生存周期模型描述
- SP1.3 建立组织度量库
- SP1.4 建立组织过程财富库
- SP1.5 建立工作环境标准
### 组织培训(OT)
- **SG1 建立组织级培训**
- SP1.1 确定战略培训需求
- SP1.2 确定由组织负责的培训需求
- SP1.3 建立组织培训计划
- SP1.4 建立培训能力
- **SG2 提供必要的培训**
- SP2.1 实施培训
- SP2.2 建立培训记录
- SP2.3 评价培训效果
### 集成化项目管理(IPM)
- **SG1 应用项目定义过程**
- SP1.1 建立项目定义过程
- SP1.2 利用组织过程财富规划项目活动
- SP1.3 建立项目工作环境
- SP1.4 集成计划
- SP1.5 利用集成计划管理项目
- SP1.6 丰富组织过程财富
- **SG2 与干系人协调合作**
- SP2.1 管理干系人参与
- SP2.2 管理依存关系
- SP2.3 解决协调问题
### 风险管理(RSKM)
- **SG1 风险管理准备**
- SP1.1 确定风险来源和类别
- SP1.2 定义风险参数
- SP1.3 建立风险管理策略
- **SG2 识别和分析风险**
- SP2.1 识别风险
- SP2.2 风险评估、分类和确定优先级
- **SG3 缓解风险**
- SP3.1 制定风险缓解计划(避免、控制、转移等)
- SP3.2 实施风险缓解计划
### 决策分析与解决方案(DAR)
- **SG1 评价候选方案**
- SP1.1 建立决策分析指导原则
- SP1.2 建立评价准则
- SP1.3 确定候选解决方案
- SP1.4 选择评价方法
- SP1.5 评价候选方案
- SP1.6 选择解决方案
---
## 第4级 量化管理级 过程域(PA)
### 组织过程绩效(OPP)
- **SG1 建立性能基线和模型**
- SP1.1 选择过程
- SP1.2 建立过程性能度量
- SP1.3 建立质量和过程性能目标
- SP1.4 建立过程性能基线
- SP1.5 建立过程性能模型
### 定量项目管理(QPM)
- **SG1 定量项目管理**
- SP1.1 建立项目目标
- SP1.2 确定项目定义过程
- SP1.3 选择用于定量管理的子过程
- SP1.4 管理项目性能
- **SG2 统计管理子过程性能**
- SP2.1 选择度量和分析技术
- SP2.2 运用统计方法理解过程变动
- SP2.3 监督选定的子过程性能
- SP2.4 记录统计管理数据
---
## 第5级 持续优化级 过程域(PA)
### 组织革新与推广(OID)
- **SG1 选择改进方案**
- SP1.1 收集和分析改进意见
- SP1.2 识别革新
- SP1.3 试点改进
- SP1.4 选择用于推广的改进方案
- **SG2 推广改进方案**
- SP2.1 策划推广
- SP2.2 管理推广
- SP2.3 度量改进效果
### 原因分析与解决方案(CAR)
- **SG1 确定缺陷原因**
- SP1.1 选择待分析的缺陷数据
- SP1.2 分析原因
- **SG2 解决产生缺陷的根源**
- SP2.1 实施行动建议
- SP2.2 评价变更的效果
- SP2.3 记录数据
三、简答题(每小题4分,共12分)
1.如果待开发软件是大系统的一部分。为什么在该软件的需求规格说明中需要针对大系统的描述。
答:软件需求规格说明书大致包括概述、功能性需求、非功能性需求、约束等几大块。
概述主要描述系统的上下文、关键性功能场景、角色以及角色能够使用的功能即用例。
功能性需求主要描述用例、报表、接口三大类。非功能性需求通常情况下有性能、安全等,视具体要求而定。约束同非功能性需求一样,有技术选型、软硬件、使用场景、UIUE的要求法律法规等。因为待开发软件是大系统的组成部分,当需求规格说明中具体描述待开发软件的功能及所应具有的外部行为时,必然要涉及到大系统的各种输入、输出和约束关系进行描述。
2.软件质量保证的活动之一是进行技术评审。什么是技术评审,它的主要目标是什么?
答:(1)技术评审(Technical Review): 是一种静态分析,评审对象通常是技术文档、计划、测试用例和测试数据、测试结果等,是质量控制最有效的手段之一。常见的技术评审包括了走查(Walkthrough)、轮查(Pass Around)、正式的同行评审(Peer Reviews)等。
(2)目的是尽早地发现工作成果中的缺陷,并帮助开发人员及时消除缺陷,从而有效地提高产品的质量。并向管理提供证据,以表明产品是否满足规范说明并遵从标准,而且可以控制变更。
3.什么是程序调试?程序调试活动是由哪两部分活动组成?
答:(1)程序调试:是测试发现错误后,进行的排错过程。软件错误的外部表现和它的内在原因之间可能并没有明显的联系;调试就是把症状和原因联系起来的过程;试图找出原因,以便改正错误。(2)组成活动:1)发现原因,排除错误。2)没有找出原因,从新设计测试用例。
四、建模题(共8分)
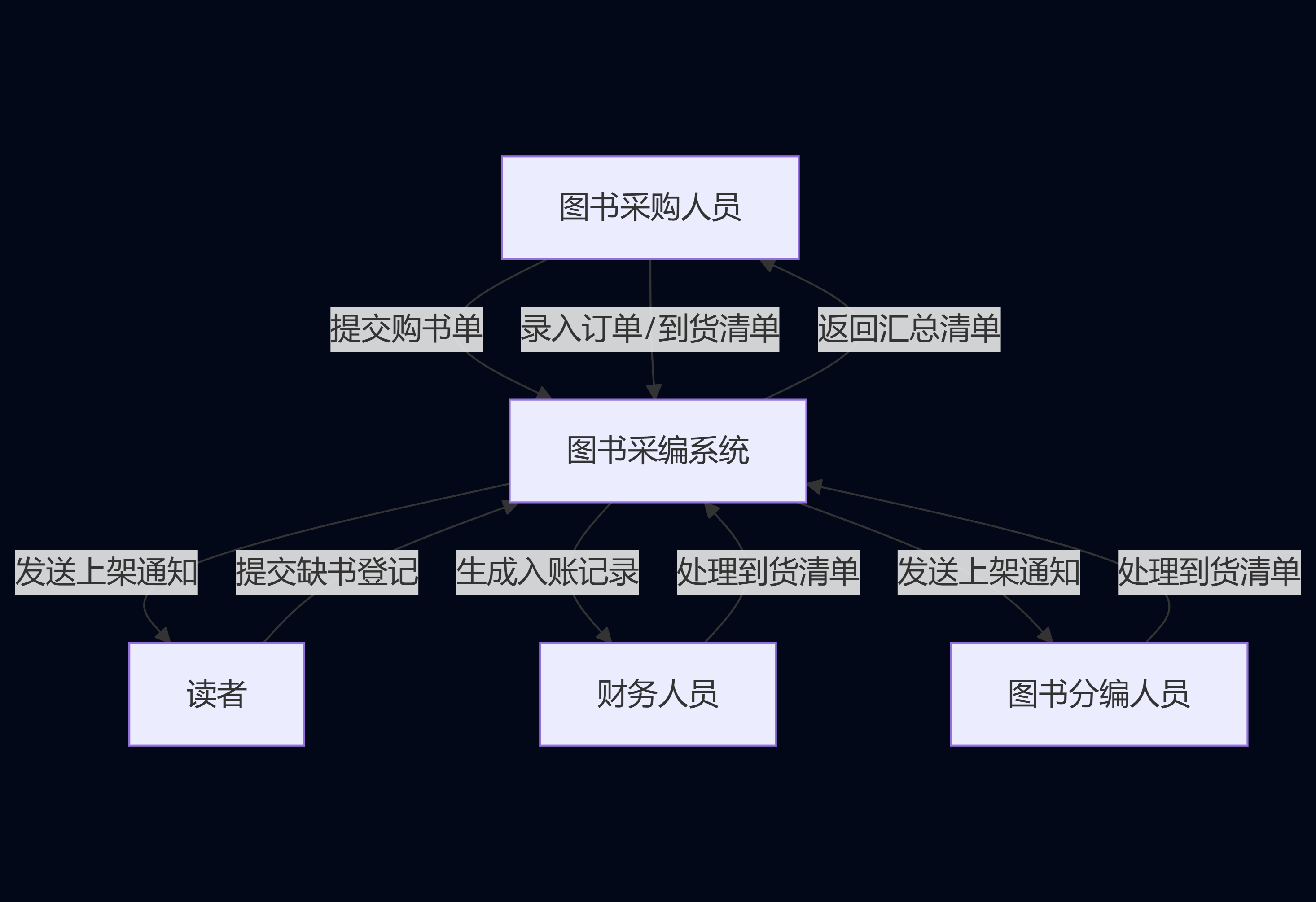
问题陈述:一个图书管理系统的简化的“图书采编”业务可描述如下:
图书采购人员
·提交购书单(包括ISBN号,书名,作者名,出版社,出版日期,印次,单价,册数);
·得到汇总的购书清单(包括ISBN号,书名,作者名,出版社,出版日期,印次,单价,册数,合计);
·录入图书订单(包括订单号,供货商名称,图书清单,总价,下单日期);
·录入图书到货清单(包括订单号,供货商名称,图书清单,总价,发货日期)
读者
·提交缺书登记表(包括 ISBN号,书名,作者名,出版社);
·得到图书上架通知(包括馆藏号,ISBN号,书名,作者名,出版社);
财务人员
·得到图书到货清单(包括订单号,供货商名称,图书清单,总价,发货日期);
·图书入账(包括ISBN号,订单号,书名,册数,单价,总价,入账日期);
·保存发票底单(包括发票流水号,发货单位,总价,开票日期);
图书分编人员
·得到图书到货清单(包括订单号,供货商名称,图书清单,总价,发货日期);
·编辑图书目录(包括馆藏号,ISBN号,书名,作者名,出版日期,印次,内容简介);
·发送图书上架通知(包括馆藏号,ISBN号,书名,作者名,出版社);
试回答:
(可能如下)
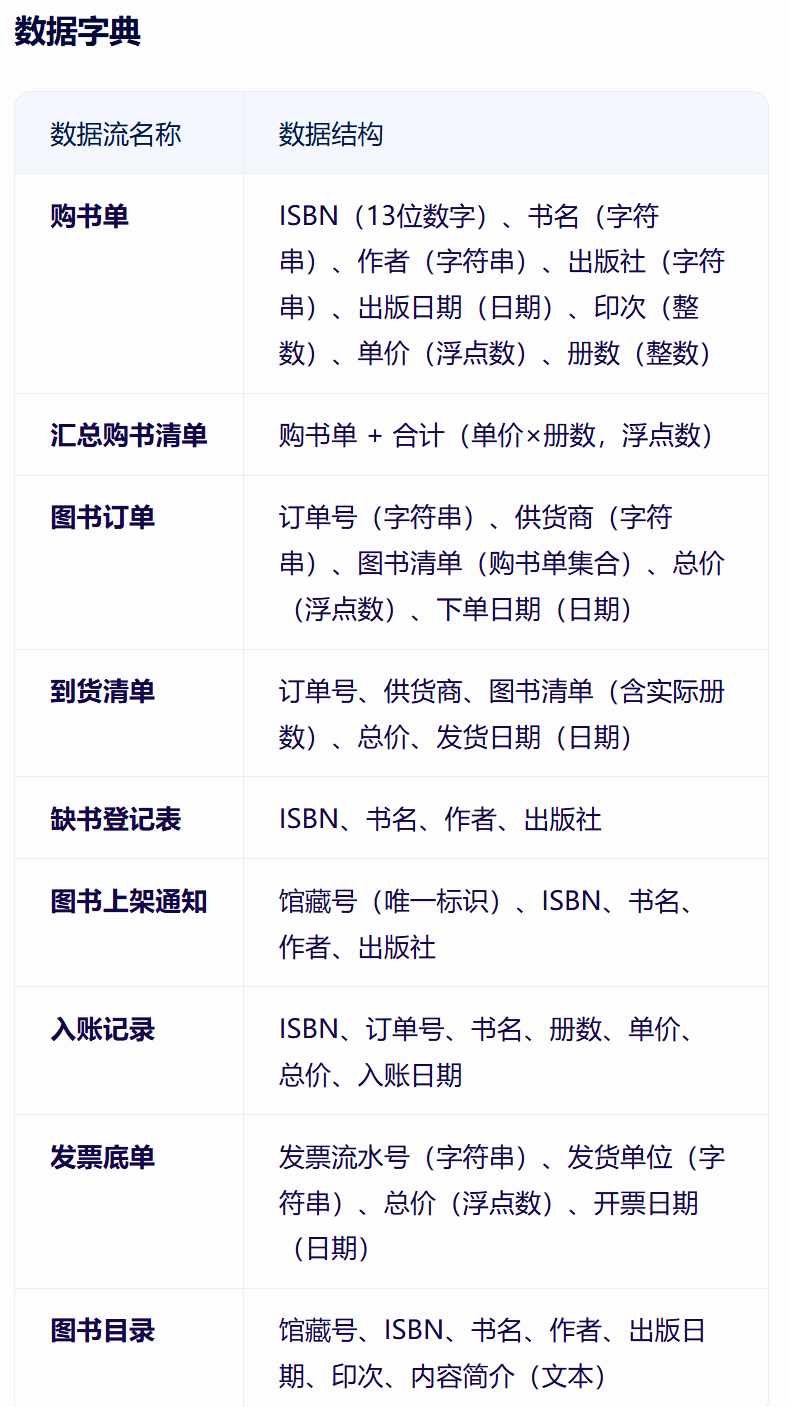
1.(3分)结构化分析方法给出该系统的顶层DFD 及其数据字典;
2.(2分)画出USE/CASE 图;
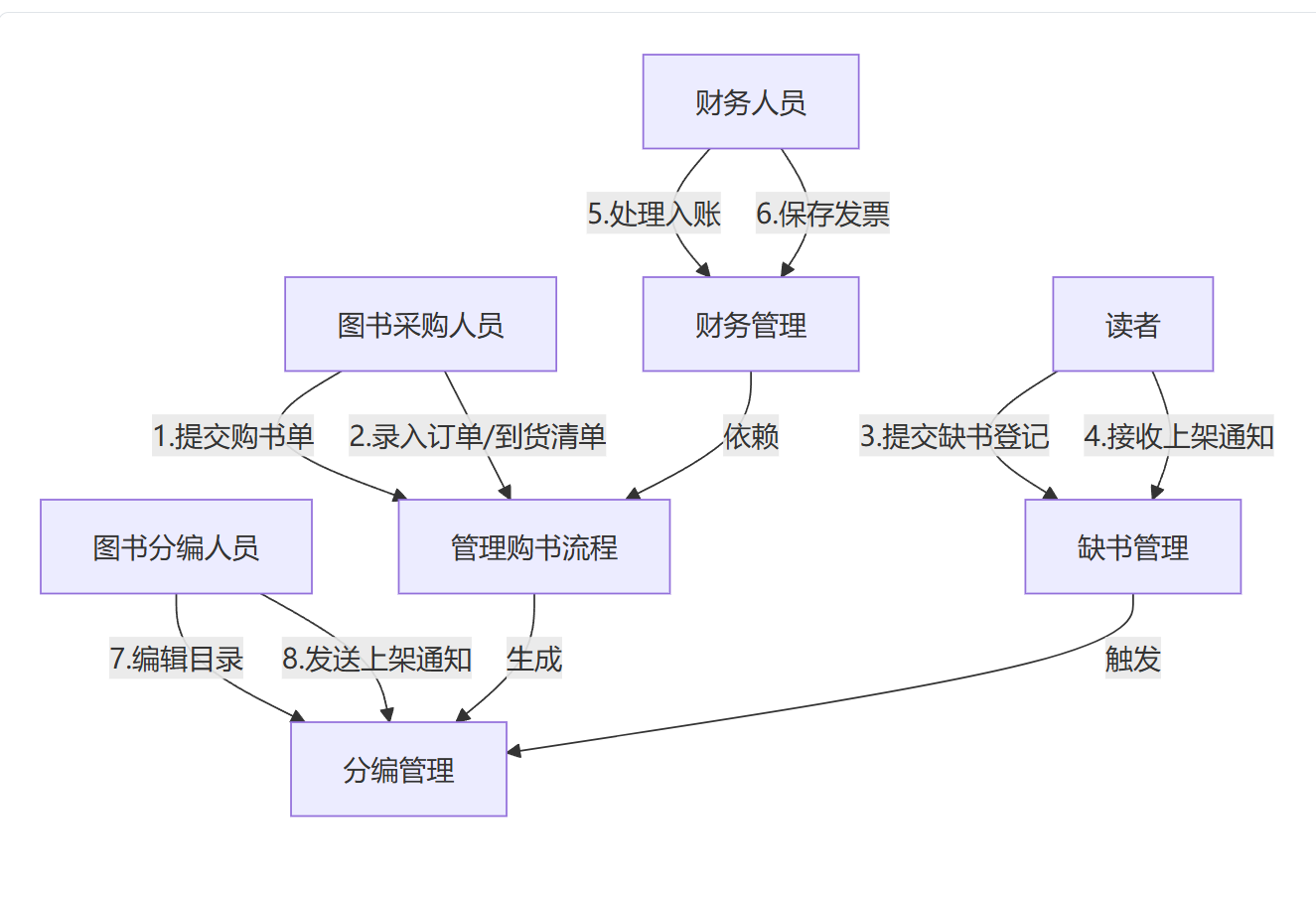
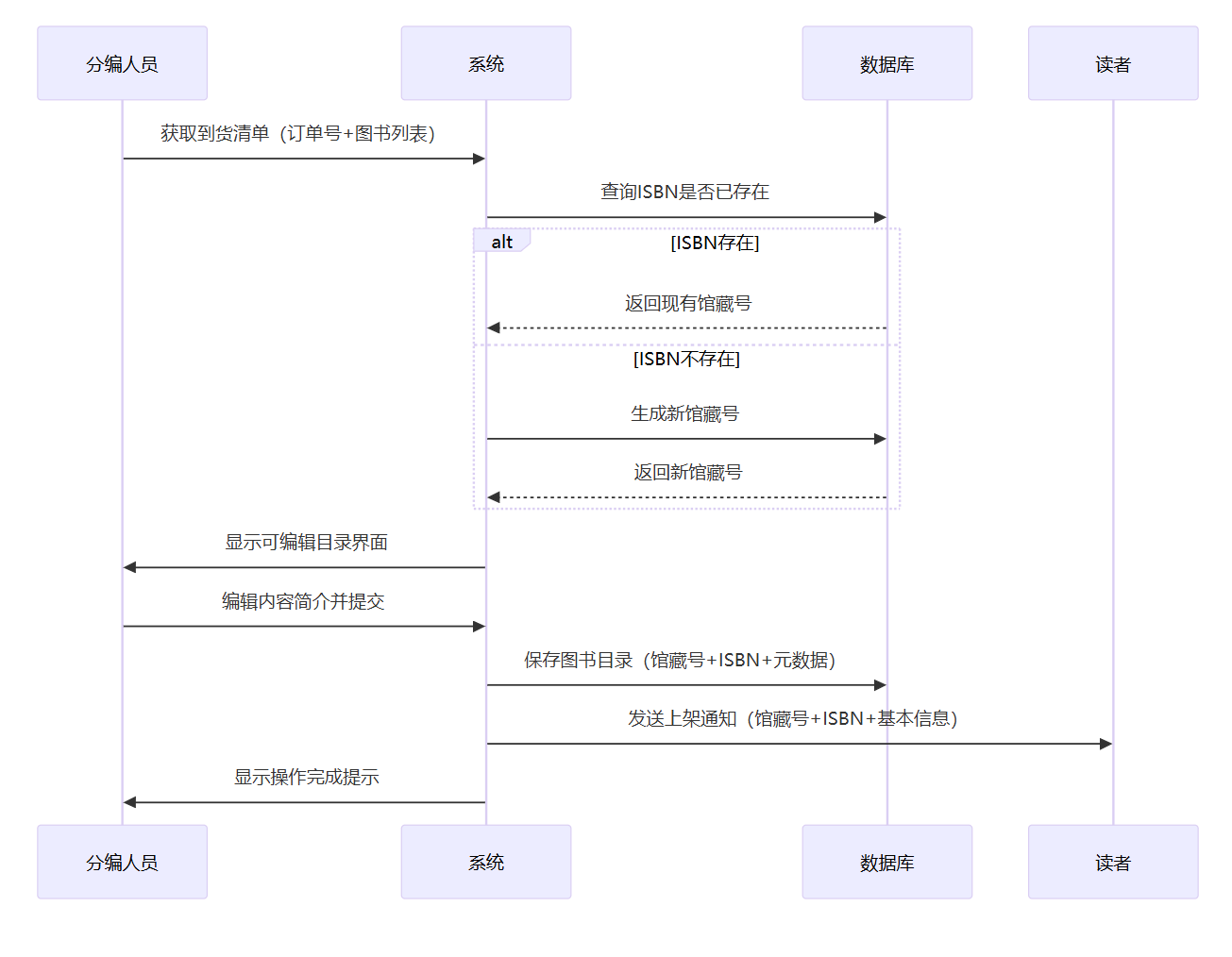
3.(3分)选择该书管理系统中的一个交互,并用顺序图来描述



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











