






一、Llama 4家族全员亮相:中杯、大杯、超大杯登场
Meta在2025年4月6日突然发布Llama 4系列模型,首次采用混合专家(MoE)架构,推出三款产品:
-
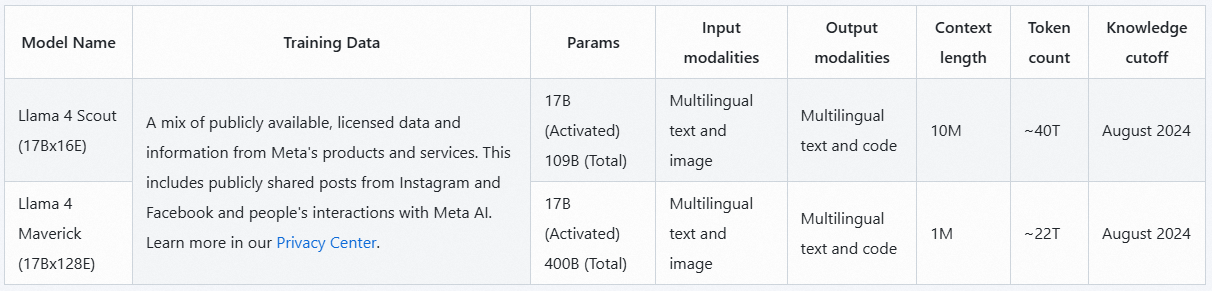
中杯:Llama 4 Scout
- 16位专家模块,170亿激活参数(总参数量1090亿)
- 1000万token上下文窗口(相当于500万字文本),支持单张H100 GPU运行
- 多文档摘要、代码库推理能力超群,击败Gemma 3和Mistral 3.1
-
大杯:Llama 4 Maverick
- 128位专家模块,170亿激活参数(总参数量4000亿)
- 单机H100即可运行,推理成本低至每百万token 0.19美元(GPT-4o的1/23)
- 在编程、数学、创意写作任务中超越GPT-4o和Gemini 2.0 Flash
-
超大杯:Llama 4 Behemoth(预告)
- 2万亿总参数,2880亿激活参数,专攻STEM领域
- 数学基准测试碾压GPT-4.5和Claude 3.7,但训练仍需数万颗GPU

二、四大杀手锏:重新定义AI模型天花板
1. MoE架构革命:用20%算力干100%的活
Llama 4首次引入MoE架构,每个token仅激活部分专家模块。例如Maverick的4000亿参数中,实际调用仅170亿,却能实现单卡运行的惊人效率。这种设计让模型像“智能路由器”,根据任务自动调度专家——写诗找文学专家,解方程找数学专家。
2. 1000万token超长记忆:AI版过目不忘
Scout的1000万token上下文窗口(相当于15000页文本)刷新行业纪录。实测中,它可精准定位百万字文档中的关键信息(“大海捞针”测试准确率98%),还能分析整部《三体》并总结人物关系。Meta通过iRoPE架构实现这一突破:交错注意力层+旋转位置编码,让模型“无限续杯”处理长文本。
3. 原生多模态:Llama终于长眼睛了!
上传图片直接提问“图中哪个工具适合拧螺丝”,Llama 4能圈出扳手;输入鸟类照片,它能识别品种并科普习性。这得益于早期融合技术——文本与图像token在模型底层即统一处理,而非后期拼接。MetaCLIP视觉编码器的升级,更让模型具备像素级定位能力。
4. 价格屠夫:比DeepSeek更狠的性价比
Maverick的推理成本仅GPT-4o的1/23,却能实现同等代码能力。Meta通过三大策略降本:
- FP8精度训练:算力利用率提升至390 TFLOPs/GPU
- 动态参数激活:MoE架构减少无效计算
- 蒸馏技术:从Behemoth模型提炼知识,小模型继承大模型智慧
三、训练黑科技:Meta的AI炼丹术
1. MetaP:超参数预测神器
传统大模型训练需反复试错超参数,而MetaP技术可通过小模型实验预测大模型最优配置,节省90%调参时间。这让Behemoth的训练效率提升10倍。
2. 地狱级数据筛选
后训练阶段,Meta删除50%“简单数据”,专注高难度样本。例如让模型反复练习IMO数学题和LeetCode hard级编程题,并通过持续强化学习(RL)动态过滤低质量提示。
3. 200种语言自由切换
预训练涵盖200种语言(100种超10亿token),多语言能力是Llama 3的10倍。开发者可轻松部署阿拉伯语客服或斯瓦希里语翻译系统。
四、行业冲击波:开源生态再洗牌
-
开源模型首登顶
Maverick以ELO 1417分登顶LMSYS竞技场,成为首个击败DeepSeek V3的开源模型。 -
开发者狂欢
单卡可跑的Scout降低入门门槛,个人开发者也能用消费级GPU部署AI应用。Hugging Face已上线模型下载,并集成至WhatsApp等40国产品。 -
伦理争议
Llama 4宣称“政治立场更平衡”,但用户实测显示其仍倾向自由派观点。Meta同步推出Llama Guard工具,试图监控敏感内容。
五、未来之战:AI进入MoE时代
随着Llama 4的发布,AI竞赛进入新阶段:
- 效率革命:MoE架构让大模型告别“暴力堆参数”
- 多模态标配:文本、图像、视频的深度融合成趋势
- 开源VS闭源:Meta用免费策略蚕食OpenAI市场份额



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











