










一、单张调用
1.准备好配置文件 coco.names yolov3.cfg yolov3.weights
将上述文件保存在cfg的目录下,后续可以换成自己训练好的文件
链接:https://pan.baidu.com/s/1GVwE3ORfJ-YwzrHDi73_hQ
提取码:8s83

2、将下面的代码命名为detect.py
# detect.py
import cv2
import numpy as np
import os
import time
def yolo_detect(pathIn='',
pathOut=None,
label_path='./cfg/coco.names',
config_path='./cfg/yolov3.cfg',
weights_path='./cfg/yolov3.weights',
confidence_thre=0.5,
nms_thre=0.3,
jpg_quality=80):
'''
pathIn:原始图片的路径
pathOut:结果图片的路径
label_path:类别标签文件的路径
config_path:模型配置文件的路径
weights_path:模型权重文件的路径
confidence_thre:0-1,置信度(概率/打分)阈值,即保留概率大于这个值的边界框,默认为0.5
nms_thre:非极大值抑制的阈值,默认为0.3
jpg_quality:设定输出图片的质量,范围为0到100,默认为80,越大质量越好
'''
# 加载类别标签文件
LABELS = open(label_path).read().strip().split("\n")
nclass = len(LABELS)
# 为每个类别的边界框随机匹配相应颜色
np.random.seed(42)
COLORS = np.random.randint(0, 255, size=(nclass, 3), dtype='uint8')
# 载入图片并获取其维度
base_path = os.path.basename(pathIn)
img = cv2.imread(pathIn)
(H, W) = img.shape[:2]
# 加载模型配置和权重文件
print('从硬盘加载YOLO......')
net = cv2.dnn.readNetFromDarknet(config_path, weights_path)
# 获取YOLO输出层的名字
ln = net.getLayerNames()
ln = [ln[i[0] - 1] for i in net.getUnconnectedOutLayers()]
# 将图片构建成一个blob,设置图片尺寸,然后执行一次
# YOLO前馈网络计算,最终获取边界框和相应概率
blob = cv2.dnn.blobFromImage(img, 1 / 255.0, (416, 416), swapRB=True, crop=False)
net.setInput(blob)
start = time.time()
layerOutputs = net.forward(ln)
end = time.time()
# 显示预测所花费时间
print('YOLO模型花费 {:.2f} 秒来预测一张图片'.format(end - start))
# 初始化边界框,置信度(概率)以及类别
boxes = []
confidences = []
classIDs = []
# 迭代每个输出层,总共三个
for output in layerOutputs:
# 迭代每个检测
for detection in output:
# 提取类别ID和置信度
scores = detection[5:]
classID = np.argmax(scores)
confidence = scores[classID]
# 只保留置信度大于某值的边界框
if confidence > confidence_thre:
# 将边界框的坐标还原至与原图片相匹配,记住YOLO返回的是
# 边界框的中心坐标以及边界框的宽度和高度
box = detection[0:4] * np.array([W, H, W, H])
(centerX, centerY, width, height) = box.astype("int")
# 计算边界框的左上角位置
x = int(centerX - (width / 2))
y = int(centerY - (height / 2))
# 更新边界框,置信度(概率)以及类别
boxes.append([x, y, int(width), int(height)])
confidences.append(float(confidence))
classIDs.append(classID)
# 使用非极大值抑制方法抑制弱、重叠边界框
idxs = cv2.dnn.NMSBoxes(boxes, confidences, confidence_thre, nms_thre)
# 确保至少一个边界框
if len(idxs) > 0:
# 迭代每个边界框
for i in idxs.flatten():
# 提取边界框的坐标
(x, y) = (boxes[i][0], boxes[i][1])
(w, h) = (boxes[i][2], boxes[i][3])
# 绘制边界框以及在左上角添加类别标签和置信度
color = [int(c) for c in COLORS[classIDs[i]]]
cv2.rectangle(img, (x, y), (x + w, y + h), color, 2)
text = '{}: {:.3f}'.format(LABELS[classIDs[i]], confidences[i])
(text_w, text_h), baseline = cv2.getTextSize(text, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 2)
cv2.rectangle(img, (x, y - text_h - baseline), (x + text_w, y), color, -1)
cv2.putText(img, text, (x, y - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0), 2)
# 输出结果图片
if pathOut is None:
cv2.imwrite('with_box_' + base_path, img, [int(cv2.IMWRITE_JPEG_QUALITY), jpg_quality])
else:
cv2.imwrite(pathOut, img, [int(cv2.IMWRITE_JPEG_QUALITY), jpg_quality])3、调用
# python环境下,导入
from detect import yolo_detect
pathIn = './test/test1.jpg'
pathOut = './resuls/test1.jpg'
# 调用
yolo_detect(pathIn,pathOut)会在result的目录下生成预测的结果

二、批量测试:
import cv2
import numpy as np
import os
import time
print('从硬盘加载YOLO......')
label_path = './cfg/coco.names'
config_path = './cfg/yolov3.cfg'
weights_path = './cfg/yolov3.weights'
net = cv2.dnn.readNetFromDarknet(config_path, weights_path)
# 创建保存结果的目录
if not os.path.exists('results'):
os.mkdir('results')
def NMSBoxes_fix(boxes, confidences, confidence_thre, nms_thre, class_id):
class_id_set = set(class_id) # 总共有几类
result = [] # 用来存储结果的
for cls in class_id_set: # 遍历每个类别
cls_boxes = [] # 用来保存每个类别的 边框
cls_confidences = [] # 用来保存每个类别边框的分数
indices = [i for i, c in enumerate(class_id) if c == cls] # 某一类在原始输入的所有索引
for i in indices:
cls_boxes.append(boxes[i]) # 把属于该类的框框和分数找出来
cls_confidences.append(confidences[i])
idxs = cv2.dnn.NMSBoxes(cls_boxes, cls_confidences, confidence_thre, nms_thre) # 对每类进行 NMS 操作
for i in idxs: # 找出原始输入的索引,并把经过 NMS 操作后保留下来的框框的索引保存下来到一个列表中
result.append([indices[i[0]]]) #
return np.array(result) # opencv 原始的 NMS 输出是一个 np.array 的数据,所以我们也将其转化成指定格式
def yolo_detect(pathIn='',
label_path=label_path,
net=net,
confidence_thre=0.5,
nms_thre=0.3,
jpg_quality=80):
'''
pathIn:原始图片的路径
pathOut:结果图片的路径
label_path:类别标签文件的路径
config_path:模型配置文件的路径
weights_path:模型权重文件的路径
confidence_thre:0-1,置信度(概率/打分)阈值,即保留概率大于这个值的边界框,默认为0.5
nms_thre:非极大值抑制的阈值,默认为0.3
jpg_quality:设定输出图片的质量,范围为0到100,默认为80,越大质量越好
'''
# 加载类别标签文件
LABELS = open(label_path).read().strip().split("\n")
nclass = len(LABELS)
# 为每个类别的边界框随机匹配相应颜色
np.random.seed(42)
COLORS = np.random.randint(0, 255, size=(nclass, 3), dtype='uint8')
# 载入图片并获取其维度
base_path = os.path.basename(pathIn)
img = cv2.imread(pathIn)
(H, W) = img.shape[:2]
# 加载模型配置和权重文件
# 获取YOLO输出层的名字
ln = net.getLayerNames()
ln = [ln[i[0] - 1] for i in net.getUnconnectedOutLayers()]
# 将图片构建成一个blob,设置图片尺寸,然后执行一次
# YOLO前馈网络计算,最终获取边界框和相应概率
blob = cv2.dnn.blobFromImage(img, 1 / 255.0, (416, 416), swapRB=True, crop=False)
net.setInput(blob)
start = time.time()
layerOutputs = net.forward(ln)
end = time.time()
# 显示预测所花费时间
print('YOLO模型花费 {:.2f} 秒来预测一张图片'.format(end - start))
# 初始化边界框,置信度(概率)以及类别
boxes = []
confidences = []
classIDs = []
# 迭代每个输出层,总共三个
for output in layerOutputs:
# 迭代每个检测
for detection in output:
# 提取类别ID和置信度
scores = detection[5:]
classID = np.argmax(scores)
confidence = scores[classID]
# 只保留置信度大于某值的边界框
if confidence > confidence_thre:
# 将边界框的坐标还原至与原图片相匹配,记住YOLO返回的是
# 边界框的中心坐标以及边界框的宽度和高度
box = detection[0:4] * np.array([W, H, W, H])
(centerX, centerY, width, height) = box.astype("int")
# 计算边界框的左上角位置
x = int(centerX - (width / 2))
y = int(centerY - (height / 2))
# 更新边界框,置信度(概率)以及类别
boxes.append([x, y, int(width), int(height)])
confidences.append(float(confidence))
classIDs.append(classID)
# 使用非极大值抑制方法抑制弱、重叠边界框
# idxs = cv2.dnn.NMSBoxes(boxes, confidences, confidence_thre, nms_thre)
# 自己修正过的 非极大值抑制方法
idxs = NMSBoxes_fix(boxes, confidences, confidence_thre, nms_thre, classIDs)
# 确保至少一个边界框
if len(idxs) > 0:
# 迭代每个边界框
for i in idxs.flatten():
# 提取边界框的坐标
(x, y) = (boxes[i][0], boxes[i][1])
(w, h) = (boxes[i][2], boxes[i][3])
# 绘制边界框以及在左上角添加类别标签和置信度
color = [int(c) for c in COLORS[classIDs[i]]]
cv2.rectangle(img, (x, y), (x + w, y + h), color, 2)
text = '{}: {:.3f}'.format(LABELS[classIDs[i]], confidences[i])
(text_w, text_h), baseline = cv2.getTextSize(text, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 2)
cv2.rectangle(img, (x, y - text_h - baseline), (x + text_w, y), color, -1)
cv2.putText(img, text, (x, y - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0), 2)
# 输出结果图片
if not os.path.exists('results'):
os.mkdir('results')
cv2.imwrite(os.path.join('results', base_path), img, [int(cv2.IMWRITE_JPEG_QUALITY), jpg_quality])
if __name__ == "__main__":
'''
实现对test目录下图片进行推理预测,并将结果保存在results下
'''
dir = 'test'
for pic in os.listdir(dir):
pic_path = os.path.join(dir, pic)
yolo_detect(pic_path, jpg_quality=100)1) 将上述代码保存为 detect_batch.py (官网的cv2.dnn.NMSBOXES有问题,上述使用修正的nms)
2) 将待测试的图片放到test的目录下,
3) python detect_batch.py
4) 最后会在results的目录下生成批量测试的结果
Bug:
应用自己训练的模型,可能出现了bug:
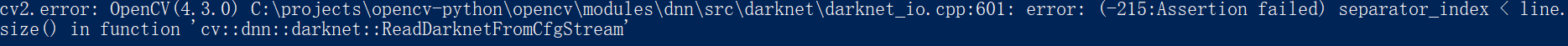
解决方法:
1)pip install -U opencv-python
(网上说4.2版本低,升级opencv即可,亲测了升级到4.3还是报错)
2)将yolov3.cfg的train训练模式 修改成 test测试模型,去掉前面的注释。















 4149
4149











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









