







标签: 机器学习 LDA
LDA(Latent Dirichlet allocation)
0.引子
贝叶斯思想的源头—逆概问题:
有两个盒子,一个红盒子,一个绿盒子。红盒子中装有2个苹果和6个橘子,绿盒子中装有3个苹果和1个橘子。假设我们随机选择一个盒子,然后从中拿出一个水果。假设有0.6的概率选绿盒子,0.4的概率选红盒子。
问题1.拿到苹果的概率是多少?
问题2.观察到拿到的是苹果,那么从哪个盒子中取出的概率最大?
这就是逆概问题,问题1是正向的求解,而逆概就是逆向的求解。而逆概问题恰恰是生活中常遇到的问题,因为我们已经搜集了大量数据,即已经观察到了现象。我们要根据这些现象,求出各种情况下的概率分布情况。上面的其实就是两层的贝叶斯网络,第一层是选择盒子,第二层选择水果。而我们就是通过第二层的结果来推测第一层节点的概率分布情况。而下面要说的LDA其实就是三层的贝叶斯网络,它是通过第三层的结果来推测第二层节点的概率分布。
1.pLSA
LDA稍微有些复杂,我们先从简单点的pLSA模型说起。
1.1生成文档过程
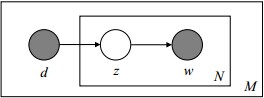
d代表文档,z代表主题(隐含类别),w代表单词。暗色代表可观察随机变量,如d和w。白色为不可观察随机变量即隐含变量,如z。方框代表重复,N即为文章包含的单词个数,M为文章的个数
将m文章的生成过程抽象:
1)以P(di)的概率选中文档di
2)以P(zk∣di)的概率选中主题zk
3)以p(wj∣zk)的概率产生一个单词wj
总结一句话:pLSA生成文档的整个过程便是选定文档的主题,确定主题后通过主题生成词
1.2根据文档反推主题分布
- 反过来,既然文档已经产生,那么如何根据已经产生好的文档反推其主题呢?这个利用看到的文档推断其隐藏的主题(分布)的过程(其实也就是产生文档的逆过程),便是主题建模的目的:自动地发现文档集中的主题(分布)。
- 换言之,人类根据文档生成模型写成了各类文章,然后丢给了计算机,相当于计算机看到的是一篇篇已经写好的文章。现在计算机需要根据一篇篇文章中看到的一系列词归纳出当篇文章的主题,进而得出各个主题各自不同的出现概率:主题分布。即文档d和单词w是可被观察到的,但主题z却是隐藏的。用数学一点的语言表达为:
根据大量已知的文档-词项信息p(w|d),训练出文档-主题p(z|d)和主题-词项p(w|z)
1.3目标函数构建
在确定文档 di 中出现词 wj 出现的条件概率为:
p(wj∣di)=∑k=1Kp(wj∣zk)p(zk∣di)wj 词出现在文档 di 的联合概率为:
p(wj,di)=p(di)p(wj∣di)=p(di)∑k=1Kp(wj∣zk)p(zk∣di)用最大似然估计求解,写出最大似然函数(让已观测数据出现的概率变最大),记 wj 在文章 dj 中出现次数记为 n(di,wj)
似然函数为:
L=∏i=1M∏j=1Np(di,wj)=∏i∏jp(di,wj)n(di,wj)
对数似然为:
l=∑i∑jn(di,wj)logp(di,wj)=∑i∑jn(di,wj)log(p(wj∣di)p(di))=∑i∑jn(di,wj)log((∑k=1Kp(wj∣zk)p(zk∣di))p(di))=∑i∑jn(di,wj)log(∑k=1Kp(wj∣zk)p(zk∣di)p(di))
所以目标函数为
(wj,di)
即为所观察到的数据对,而
zk
为隐含变量
p(wj∣zk)
和
p(zk∣di)
对应两组多项分布,即要求解的参数
面对隐变量EM算法是求解的利器:
1.假定 p(zk∣di) 和 p(wj∣zk) 已知,求隐含变量 zk 的后验概率
2.在 p(di,wj,zk) 已知的前提下,求关于参数 p(zk∣di) 和 p(wj∣zk) 的似然函数期望极大值,得到最优解 p(zk∣di) 和 p(wj∣zk) 带入上一步,从而循环迭代
这里可以直接给出公式(推导过程待后续给出)
E-step:
M-step:
解释
E步:先假设已经知道文章的主题分布和主题的词分布,求得一篇文章中的每个词属于各个主题的概率。
M步:
主题的词分布:
知道了每篇文章每个词的属于各个主题的概率,主题 zk 中词 wj 的概率即为词 wj 在文章 di 中出现的概率乘以在该篇文章中出现的次数,这样给所有文章都加起来,然后在归一化除以 该主题下所有词的概率和。
文章的主题分布:
知道了每篇文章每个词的属于各个主题的概率,那么将该篇文章的所有词属于某个主题的概率乘以该词出现的次数,然后在归一化除以所有的主题和。
LDA
1. 生成文档过程
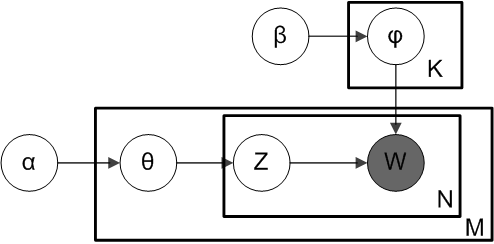
θ和φ分别为参数服从αβ的Dirchlet分布.
LDA的文章的生成过程如下:
不要被Dirchlet分布吓到,其实都是纸老虎。还是先不上公式,感性的理解下Dirchlet分布。这里的文章-主题分布和主题-词分布都是多项分布,多项分布其实就是骰子(骰子有6个面,多项分布是k个面的骰子。骰子每个面的概率p1=p2=..p6,而多项分布的p1到pk都是不同的)。在pLSA中两个多项分布被认为是固定的参数,就是认为那个骰子的各个面的概率是固定,我们从是从数据中求出这些参数。而在LDA中,我们认为骰子各个面的概率不是固定的,而是由Dirchlet分布确定的,而Dirchlet分布的参数 α 和 β 就是控制那个骰子各个面概率是什么的,当然最后也是从数据中求出这些参数。但是这也根本上体现了频率学派和贝叶斯学派看待参数的区别。关于Dirchlet分布更详细的知识参见 Dirchlet分布
2. LDA过程理解
借助pLSA来理解LDA,LDA其实只是在文档-主题和主题-词的多项分布前加了一个先验的Dirchlet分布,这就比pLSA多了一层概率推断,变成了三层的贝叶斯网络。根据词的生成过程来求一下联合概率
别被公式吓倒,剖析一下:
- 这里的m表示第m篇文章,n表示第n个词。 Nm 表示第m篇文章的词总数。
- 概率里包含向量的形式,其实就是这个向量的每个分量的联合概率如 p(α⃗ )=p(α1,α2,....,αk)
- Φ 是又参数 β⃗ 生成的所有的主题-词的多项式分布, φzm,n→ 是 Φ 中主题编号为 zm,n 的主题-词的多项式分布
- p(zm,n∣ϑm→)p(ϑm→∣α⃗ ) 是又 α⃗ 先产生文章-主题分布 ϑm→ 然后通过该分布采样一个主题编号 zm,n
- p(wm,n∣φzm,n→) 是从选点的主题-词分布中采样一个词。
- 之所以条件概率这样写,就是根据LDA生产过程的贝叶斯网络,网络上有明确的先决条件关系。关于贝叶斯网络的详细讨论见贝叶斯网络
求联合概率这是正向思考的模式。但是中间主题是隐藏的,而且隐藏的层数比pLSA还多了一层,这里面就是环环相扣的未知数!而我们要做到能够预测在一篇文章中一下时刻各个词出现的概率是什么!而要做到这些,就需要利用现有出现的数据(词)来将贝叶斯网络上的各个节点的分布律求出来,然后就能利用刚才的联合概率预测下一刻出现什么词了。(当然我们最后想要的不是预测这篇文章下一刻出现什么词,而是中间隐藏层节点的概率分布律)
想想我们的人生,不应该也是个贝叶斯网络吗,人生的各个节点都是贝叶斯网络上的节点,所有的贝叶斯网络节点的联合概率最终决定了现在的你的样子,而上帝就是控制这些节点概率分布的人。你为什么会是现在的你?下一刻你又将是怎样的你?作为个智者啊,你不会向芸芸众生一样靠着想象去猜测未来自己会怎样,因为你知道未来已来,它隐藏在过去中。你观察到了一个个现象,从这些现象中,你思考出了,你是怎么来的,你为什么会这样存在,产生这样的你的那些中间过程都是什么?这中间过程就是概率图节点的那些概率分布律。知道了这些你就能知道上帝是如何安排你的人生的,概率论是一门窥探上帝密码的武器。
然而或许上帝其实只是控制了最开始的几个参数,中间隐藏节点则是你在不断的成长中形成了自己的性格与能力,这些都是你自己决定的。从这么方面来想,如果真的有命运,那么这些命运也应该是你自己决定的。
3.参数估计(参数学习)
现在来求出那些中间隐藏的贝叶斯网络的节点的概率吧。
还是用最大似然估计,写出似然函数,就是词出现的概率。这里假设了词出现位置是无关的,并且词与词之间是完全独立的,显然是词袋模型。
参数学习采用的是吉布斯采样的方法,当然也可以用变分EM算法。
跟pLSA的EM方法类似,用迭代的方式给词找到它属于的主题的概率。
步骤:
初始化:随机给文本中每个词(word)分布一个主题z,这里word是可重复的。两个相同的词,可能会分配到不同的主题。用term表示不重复的词。
更新:对每个词(word)来说,看一下跟他一样的词(term)都分配给了哪些主题,根据这些在重新计算这个该word属于各个主题的概率。然后通过这些概率分布来抽样,得到一个主题重新分配给该word(必然是概率大的主题被抽中的概率大喽)
更新的公式:
p(zi=k∣z¬i→,w⃗ )=n(t)k,¬i+βt∑Vt=1(n(t)k,¬i+βt)n(k)m,¬i+αk∑Kk=1(nKm+αk)−1
zi=k 表示编号为i的词( wi )主题编号为k, z¬i→ 除来 wi 的之外的其他词的主题编号向量。 n(t)k,¬i 表示term为t的word属于主题k的个数(除了 wi 外)。 n(k)m,¬i 表示编号为m的文章( Dm )中主题k出现的次数(除了 wi 外)
可以看到 wi 属于k的概率就是文章中主题k出现的次数*跟他一样词(term)分配到主题k的次数归一化。
算出 wi 属于每个主题的概率,然后在按概率抽样,得到的主题在重新赋值给 wi 的主题归属。
当然更新不止更新一次,迭代更新的次数要视情况而定,人工指定。计算词分布和主题分布
有了每个文章中的每个词属于哪个主题,剩下就是计算主题-词分布和文章-主题分布了。即贝叶斯网络中 Θ 和 Φ 两个分布。公式为:
ϑm,k=nkm+αk∑Kk=1(nkm+αk)
φk,t=ntk+βt∑Vt=1(ntk+βt)
以上m表示文档编号,term数量为V,term编号为t,主题数目为K,主题编号为k重点来了
4.1 其本质就是看到了各个词在不同文章中出现,然后根据各个词的出现规律来猜测文章的主题分布及主题的词分布。但是现在词属于哪个主题还没有呢(被隐藏了),那么就先给每个词指定主题,每个词有了主题,那么算这两个分布就用3中的公式一下就算出来了。而指定主题的方法就是吉布斯采样,这个采样的方式很奇妙,与EM一样都是先随机的先为每个词映射到主题,然后迭代的更新这个映射。
4.2.着重看看对更新公式的理解,从更新公式上可以看出,更新利用到的信息就是数一数跟当前更新词相同的词被分配到了哪个主题上,当然还要看看当前更新词所在文章包含的主题次数。其实就是把初始化那点差异在拉大,开始肯定不同词分配到某个主题与相同词分配到的主题间差异不是很大,现在更是给相同的词往相同的主题上拉,这个过程自然就会让不同的词“拉”往不同的主题。当然同一篇文章里的词被拉到一个主题的肯能行也是在增大的。这样就实现了我们最开始想要的结果。
4.公式证明
上面都是直接说了公式,下面来一下公式的证明,这里就用到了Dirchlet分布。不懂请先移步Dirchlet分布
- 使用最大似然估计,第一步先写出似然函数,观察到的变量是w,要求的隐变量是
Φ
和
Θ
:
第m篇文章第n个词w被观察到为t的概率:
p(wm,n=t∣ϑm→,Φ)=∑k=1Kp(wm,n=t∣φk→)p(zm,n=k∣ϑm→)(1)
就是全概率公式。将文章先选个主题,再从主题中选词。这样给每个主题加起来。
似然函数,所有文章所有词都相乘:
p(W∣Θ,Φ)=∏m=1Mp(wm→∣ϑm→,Φ)=∏m=1M∏n=1Nmp(wm,n∣ϑm→,Φ)(2)
将式(1)带入式(2)即可。让上式取得最大值。
值得注意的一点是 ϑm→ 和 Φ 是隐变量,控制他们的已知变量是 α⃗ 和 β⃗ 推导吉布斯采样的更新公式
p(zi=k∣z¬i→,w⃗ )=
p(w⃗ ,zi,z¬i→)p(w⃗ ,z¬i→)=p(w⃗ ,z⃗ )p(w⃗ ,z¬i→)=p(w⃗ ∣z⃗ )p(z⃗ )p(w⃗ ,z¬i→)=p(w⃗ ∣z⃗ )p(z⃗ )p(w⃗ ∣z¬i→)p(z¬i→)
=p(w⃗ ∣z⃗ )p(w⃗ ∣z¬i→)∗p(z⃗ )p(z¬i→)=p(w⃗ ∣z⃗ )p(w¬i→∣z¬i→)∗p(wi)∗p(z⃗ )p(z¬i→)
下一步先求一下 p(w⃗ ∣z⃗ ) 和 p(z⃗ )
其中
ntz
表示词t被观察分配给主题z的次数,
nz→={ntz}Vt=1
p(w⃗ ∣z⃗ ,β⃗ )
是多项分布,而
p(Φ,β⃗ )
是Dirchlet分布,相乘还是Dirchlet分布。
φz,k
就多项分布的时候各个词的概率,也是Dirchlet分布中那个概率。
这里 nkm 是主题k被分配给文章m的次数, nm→={nkm}Kk=1
在回到更新公式:
这里用到了 Γ(x+1)=xΓ(x) 公式
3. 计算词分布和主题分布
完全套用Dirchlet分布的公式即可,参见 Dirchlet分布。















 998
998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









