









转:http://blog.csdn.net/v_july_v/article/details/40738211
从拉普拉斯矩阵说到谱聚类
0 引言
11月1日上午,机器学习班 第7次课,邹讲聚类(PPT),其中的谱聚类引起了自己的兴趣,邹从最基本的概念:单位向量、两个向量的正交、方阵的特征值和特征向量,讲到相似度图、拉普拉斯矩阵,最后讲谱聚类的目标函数和其算法流程。
课后自己又琢磨了番谱聚类跟拉普拉斯矩阵,打算写篇博客记录学习心得, 若有不足或建议,欢迎随时不吝指出,thanks。
1 矩阵基础
在讲谱聚类之前,有必要了解一些矩阵方面的基础知识。
1.0 理解矩阵的12点数学笔记
如果对矩阵的概念已经模糊,推荐国内一人写的《理解矩阵by孟岩》系列,其中,抛出了很多有趣的观点,我之前在阅读的过程中做了些笔记,如下:
“1、简而言之:矩阵是线性空间里的变换的描述,相似矩阵则是对同一个线性变换的不同描述。那,何谓空间?本质而言,“空间是容纳运动的一个对象集合,而变换则规定了对应空间的运动”by孟岩。在线性空间选定基后,向量刻画对象的运动,运动则通过矩阵与向量相乘来施加。然,到底什么是基?坐标系也。
3、前面说了基,坐标系也,形象表述则为角度,看一个问题的角度不同,描述问题得到的结论也不同,但结论不代表问题本身,同理,对于一个线性变换,可以选定一组基,得到一个矩阵描述它,换一组基,得到不同矩阵描述它,矩阵只是描述线性变换非线性变换本身,类比给一个人选取不同角度拍照。
4、前面都是说矩阵描述线性变换,然,矩阵不仅可以用来描述线性变换,更可以用来描述基(坐标系/角度),前者好理解,无非是通过变换的矩阵把线性空间中的一个点给变换到另一个点上去,但你说矩阵用来描述基(把一个坐标系变换到另一个坐标系),这可又是何意呢?实际上,变换点与变换坐标系,异曲同工!
(@坎儿井围脖:矩阵还可以用来描述微分和积分变换。关键看基代表什么,用坐标基就是坐标变换。如果基是小波基或傅里叶基,就可以用来描述小波变换或傅里叶变换)
5、矩阵是线性运动(变换)的描述,矩阵与向量相乘则是实施运动(变换)的过程,同一个变换在不同的坐标系下表现为不同的矩阵,但本质/征值相同,运动是相对的,对象的变换等价于坐标系的变换,如点(1,1)变到(2,3),一者可以让坐标点移动,二者可以让X轴单位度量长度变成原来1/2,让Y轴单位度量长度变成原来1/3,前后两者都可以达到目的。
6、Ma=b,坐标点移动则是向量a经过矩阵M所描述的变换,变成了向量b;变坐标系则是有一个向量,它在坐标系M的度量下结果为a,在坐标系I(I为单位矩阵,主对角为1,其它为0)的度量下结果为b,本质上点运动与变换坐标系两者等价。为何?如(5)所述,同一个变换,不同坐标系下表现不同矩阵,但本质相同。
7、Ib,I在(6)中说为单位坐标系,其实就是我们常说的直角坐标系,如Ma=Ib,在M坐标系里是向量a,在I坐标系里是向量b,本质上就是同一个向量,故此谓矩阵乘法计算无异于身份识别。且慢,什么是向量?放在坐标系中度量,后把度量的结果(向量在各个坐标轴上投影值)按顺序排列在一起,即成向量。
8、b在I坐标系中则是Ib,a在M坐标系中则是Ma,故而矩阵乘法MxN,不过是N在M坐标系中度量得到MN,而M本身在I坐标系中度量出。故Ma=Ib,M坐标系中的a转过来在I坐标系中一量,却成了b。如向量(x,y)在单位长度均为1的直角坐标系中一量,是(1,1),而在X轴单位长度为2.Y轴单位长度为3一量则是(2,3)。
9、何谓逆矩阵? Ma=Ib,之前已明了坐标点变换a-〉b等价于坐标系变换M-〉I,但具体M如何变为I呢,答曰让M乘以M的逆矩阵。以坐标系

1.1 一堆基础概念
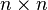 的方形矩阵,其主对角线元素为1,其余元素为0。单位矩阵以
的方形矩阵,其主对角线元素为1,其余元素为0。单位矩阵以
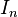 表示;如果阶数可忽略,或可由前后文确定的话,也可简记为
表示;如果阶数可忽略,或可由前后文确定的话,也可简记为
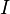 (或者E)。 如下图所示,便是一些单位矩阵:
(或者E)。 如下图所示,便是一些单位矩阵:
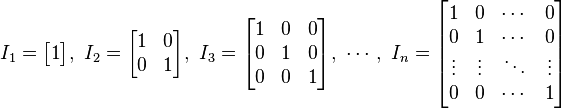
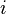
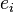
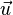 的正规化向量(即单位向量)
的正规化向量(即单位向量)
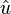 就是平行于
就是平行于
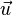 的单位向量,记作:
的单位向量,记作:
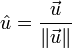
这里
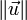 是
是
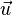 的范数(长度)。
的范数(长度)。
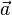 = [a1, a2,…, an]和
= [a1, a2,…, an]和
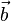 = [b1, b2,…, bn]的点积定义为:
= [b1, b2,…, bn]的点积定义为:
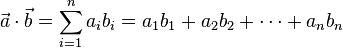
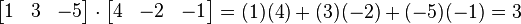
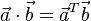
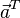
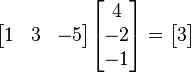
除了上面的代数定义外,点积还有另外一种定义:几何定义。在欧几里得空间中,点积可以直观地定义为:
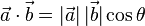
这里|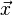
表示
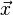
和
都是单位向量(长度为1),它们的点积就是它们的夹角的余弦。
正交是垂直这一直观概念的推广,若内积空间中两向量的内积(即点积)为0,则称它们是正交的,相当于这两向量垂直,换言之,如果能够定义向量间的夹角,则正交可以直观的理解为垂直。而正交矩阵(orthogonal matrix)是一个元素为实数,而且行与列皆为正交的单位向量的方块矩阵(方块矩阵,或简称方阵,是行数及列数皆相同的矩阵。)
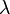
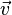
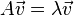 ,则
,则
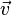
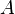 的一个
特征向量,
的一个
特征向量,
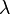 沿其
对
做了手脚,使得向量
变长或变短了,但
本身的方向不变。
沿其
对
做了手脚,使得向量
变长或变短了,但
本身的方向不变。
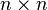 的对角线元素之和,也是其
的对角线元素之和,也是其
2 拉普拉斯矩阵
2.1 Laplacian matrix的定义
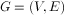 ,其拉普拉斯矩阵被定义为:
,其拉普拉斯矩阵被定义为:
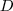 为图的度矩阵,
为图的度矩阵,
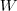 为图的邻接矩阵。
为图的邻接矩阵。
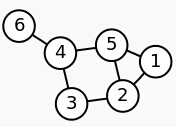 :
:

把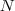


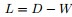 ,可得拉普拉斯矩阵
,可得拉普拉斯矩阵
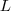 为:
为:

2.2 拉普拉斯矩阵的性质
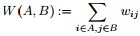
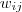 定义为节点
定义为节点
 到节点
到节点
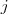 的权值,如果两个节点不是相连的,权值为零。
的权值,如果两个节点不是相连的,权值为零。
②与某结点邻接的所有边的权值和定义为该顶点的度d,多个d 形成一个度矩阵
(对角阵)
具有如下性质:
,即
。证明:
和非零向量
满足
为
是其对应的特征值)。
- 且对于任何一个属于实向量
,有以下式子成立
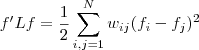 ,
,
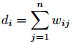 ,
,
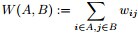 。
。
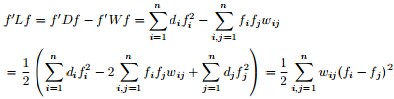
3 谱聚类
- cut/Ratio Cut
- Normalized Cut
- 不基于图,而是转换成SVD能解的问题
3.1 相关定义
- 无向图
- 与某结点邻接的所有边的权值和定义为该顶点的度d,多个d 形成一个度矩阵
- 邻接矩阵其中,
- 相似度矩阵的定义。相似度矩阵由权值矩阵得到,实践中一般用高斯核函数(也称径向基函数核)计算相似度,距离越大,代表其相似度越小。
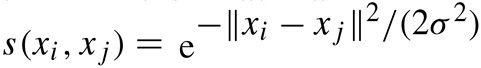
- 子图A的指示向量如下:
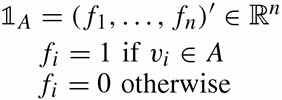
3.2 目标函数
 为图的几个子集(它们没有交集) ,为了让分割的
Cut 值最小,谱聚类便是要最小化下述目标函数:
为图的几个子集(它们没有交集) ,为了让分割的
Cut 值最小,谱聚类便是要最小化下述目标函数:
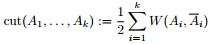
其中k表示分成k个组,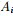
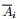
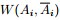
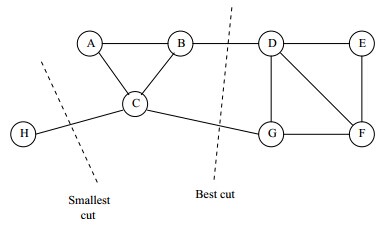
为了让被切断边的权值之和最小,便是要让上述目标函数最小化。但很多时候,最小化cut 通常会导致不好的分割。以分成2类为例,这个式子通常会将图分成了一个点和其余的n-1个点。如下图所示,很明显,最小化的smallest cut不是最好的cut,反而把{A、B、C、H}分为一边,{D、E、F、G}分为一边很可能就是最好的cut:
为了让每个类都有合理的大小,目标函数尽量让A1,A2...Ak 足够大。改进后的目标函数为:
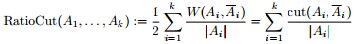
其中|A|表示A组中包含的顶点数目。
或:
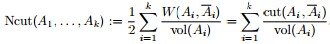
其中,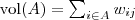
3.3 最小化RatioCut 与最小化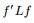 等价
等价
下面,咱们来重点研究下RatioCut 函数。
目标函数:
定义向量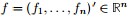
根据之前得到的拉普拉斯矩阵矩阵的性质,已知
现在把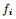
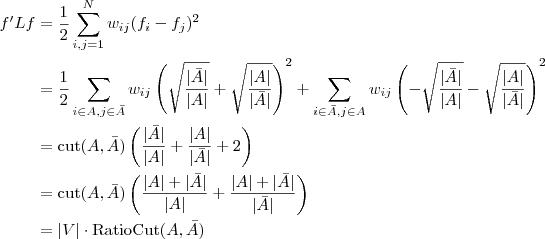
是的,我们竟然从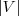
同时,因单位向量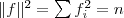
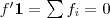
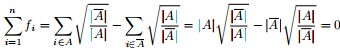
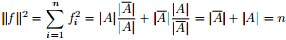
最终我们新的目标函数可以由之前的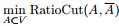
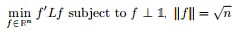
其中,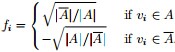
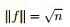
继续推导前,再次提醒特征向量和特征值的定义:
- 若数字
和非零向量
满足
为
是其对应的特征值。
假定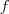
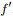
但到了这关键的最后一步,咱们却遇到了一个比较棘手的问题,即由之前得到的拉普拉斯矩阵的性质“
因此,怎么办呢?根据论文“A Tutorial on Spectral Clustering”中所说的Rayleigh-Ritz 理论,我们可以取第2小的特征值,以及对应的特征向量
里的元素是连续的任意实数,所以可以根据
是大于0,还是小于0对应到离散情况下的
,决定
是取
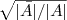 ,还是取
,还是取
 。而如果能求取
的前K个特征向量,进行K-means聚类,得到K个簇,便从二聚类扩展到了K 聚类的问题。
。而如果能求取
的前K个特征向量,进行K-means聚类,得到K个簇,便从二聚类扩展到了K 聚类的问题。
就这样,因为离散求解
3.4 谱聚类算法过程
综上可得谱聚类的算法过程如下:
- 根据数据构造一个Graph,Graph的每一个节点对应一个数据点,将各个点连接起来(随后将那些已经被连接起来但并不怎么相似的点,通过cut/RatioCut/NCut 的方式剪开),并且边的权重用于表示数据之间的相似度。把这个Graph用邻接矩阵的形式表示出来,记为
- 把
。
- 求出
的前
个特征值(前
,以及对应的特征向量
。
- 把这
的矩阵,将其中每一行看作
或许你已经看出来,谱聚类的基本思想便是利用样本数据之间的相似矩阵(拉普拉斯矩阵)进行特征分解( 通过Laplacian Eigenmap 的降维方式降维),然后将得到的特征向量进行 K-means聚类。
此外,谱聚类和传统的聚类方法(例如 K-means)相比,谱聚类只需要数据之间的相似度矩阵就可以了,而不必像K-means那样要求数据必须是 N 维欧氏空间中的向量。
4 参考文献与推荐阅读
- 孟岩之理解矩阵系列:http://blog.csdn.net/myan/article/details/1865397;
- 理解矩阵的12点数学笔记:http://www.51weixue.com/thread-476-1-1.html;
- 一堆wikipedia,比如特征向量:https://zh.wikipedia.org/wiki/%E7%89%B9%E5%BE%81%E5%90%91%E9%87%8F;
- wikipedia上关于拉普拉斯矩阵的介绍:http://en.wikipedia.org/wiki/Laplacian_matrix;
- 邹博之聚类PPT:http://pan.baidu.com/s/1i3gOYJr;
- 关于谱聚类的一篇非常不错的英文文献,“A Tutorial on Spectral Clustering”:http://engr.case.edu/ray_soumya/mlrg/Luxburg07_tutorial_spectral_clustering.pdf;
- 知乎上关于矩阵和特征值的两个讨论:http://www.zhihu.com/question/21082351,http://www.zhihu.com/question/21874816;
- 谱聚类:http://www.cnblogs.com/fengyan/archive/2012/06/21/2553999.html;
- 谱聚类算法:http://www.cnblogs.com/sparkwen/p/3155850.html;
- 漫谈 Clustering 系列:http://blog.pluskid.org/?page_id=78;
- 《Mining of Massive Datasets》第10章:http://infolab.stanford.edu/~ullman/mmds/book.pdf;
- Tydsh: Spectral Clustering:①http://blog.sina.com.cn/s/blog_53a8a4710100g2rt.html,②http://blog.sina.com.cn/s/blog_53a8a4710100g2rv.html,③http://blog.sina.com.cn/s/blog_53a8a4710100g2ry.html,④http://blog.sina.com.cn/s/blog_53a8a4710100g2rz.html;
- H. Zha, C. Ding, M. Gu, X. He, and H.D. Simon. Spectral relaxation for K-means clustering. Advances in Neural Information Processing Systems 14 (NIPS 2001). pp. 1057-1064, Vancouver, Canada. Dec. 2001;
- 机器学习中谱聚类方法的研究:http://lamda.nju.edu.cn/conf/MLA07/files/YuJ.pdf;
- 谱聚类的算法实现:http://liuzhiqiangruc.iteye.com/blog/2117144。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









