






目录
GANs介绍:
GANs网络是由一个生成器(G)和一个判别器(D)组成,两者相互博弈进化。
搭建流程
导入所需要的包 :
import torch
from torch import nn
from tqdm.auto import tqdm #设置一个进度条
from torchvision import transforms
from torchvision.datasets import MNIST #训练数据集
from torchvision.utils import make_grid # 将图像按照网格排列
from torch.utils.data import DataLoader # 数据加载器
import matplotlib.pyplot as plt制作生成器:
生成器最开始生成的是一堆随机的噪声,通过判别网络逐步修正为所需数据。
def get_generator_block(input_dim,output_dim): # 输入维度和输出维度
"""
生成器的一个块
"""
return nn.Sequential(
nn.Linear(input_dim,output_dim),
nn.BatchNorm1d(output_dim),
nn.ReLU(inplace=True)
)
class Generator(nn.Module):
"""
生成器
"""
def __init__(self,z_dim=10,im_dim=784,hidden_dim=128): # z_dim是输入噪声的维度,im_dim是生成图像的维度,hidden_dim是隐藏层的维度
super(Generator,self).__init__()
self.gen = nn.Sequential(
get_generator_block(z_dim,hidden_dim), # 输入噪声维度为z_dim,输出维度为hidden_dim
get_generator_block(hidden_dim,hidden_dim*2), # 输入维度为hidden_dim,输出维度为hidden_dim*2
get_generator_block(hidden_dim*2,hidden_dim*4), # 输入维度为hidden_dim*2,输出维度为hidden_dim*4
get_generator_block(hidden_dim*4,hidden_dim*8), # 输入维度为hidden_dim*4,输出维度为hidden_dim*8
nn.Linear(hidden_dim*8,im_dim), # 输入维度为hidden_dim*8,输出维度为im_dim
nn.Sigmoid() # 生成图像的激活函数为Sigmoid
)
def forward(self,noise):
return self.gen(noise)
def get_gen(self):
return self.gen制作判别器:
主要做的是:将生成模型 G𝐺 生成的虚假样本与真实样本识别出来。
def get_discriminator_block(input_dim,output_dim):
"""
判别器的一个块
"""
return nn.Sequential(
nn.Linear(input_dim,output_dim),
nn.LeakyReLU(0.2,inplace=True)
)
class Discriminator(nn.Module):
"""
判别器
"""
def __init__(self,im_dim=784,hidden_dim=128):
super(Discriminator,self).__init__()
self.disc = nn.Sequential(
get_discriminator_block(im_dim,hidden_dim*4), # 输入维度为im_dim,输出维度为hidden_dim*4
get_discriminator_block(hidden_dim*4,hidden_dim*2), # 输入维度为hidden_dim*4,输出维度为hidden_dim*2
get_discriminator_block(hidden_dim*2,hidden_dim), # 输入维度为hidden_dim*2,输出维度为hidden_dim
nn.Linear(hidden_dim,1), # 输入维度为hidden_dim,输出维度为1
)
def forward(self,image):
return self.disc(image)
def get_disc(self):
return self.disc计算损失:
损失分为生成器的损失和判别器的损失,两者相互博弈都需要计算。
生成器损失:
计算过程:
生成器输出的假样本数据 交给 判别器 进行预测,
将预测的结果 和 真实值 通过 (对数)损失函数 进行比较,
然后进行误差反向传播。
def get_gen_loss(gen,disc,num_images,z_dim,device='cpu'): #gen是生成器,disc是判别器,num_images是生成图像的数量,z_dim是输入噪声的维度,device是设备
"""
计算生成器的损失
"""
# 生成噪声作为生成器的输入
fake_noise = get_noise(num_images,z_dim,device)
fake = gen(fake_noise)
# 计算生成器的损失
disc_fake_pred = disc(fake)
gen_loss = nn.BCEWithLogitsLoss()(disc_fake_pred,torch.ones_like(disc_fake_pred)) #生成器尽量误导判别器打分成1
return gen_loss判别器损失:
判别器的损失函数是由两部分组成的
一部分是真实样本的损失,另一部分是生成样本的损失。
真实样本的损失是指判别器将真实样本判断为真实的损失,生成样本的损失是指判别器将生成样本判断为真实的损失。
为真实数据分布,
为生成样本数据分布。
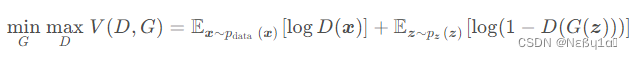
def get_disc_loss(gen,disc,real,num_images,z_dim,device='cpu'):
#gen是生成器,disc是判别器,real是真实的图像,num_images是生成图像的数量,z_dim是输入噪声的维度,device是设备
"""
计算判别器的损失
"""
# 生成噪声作为生成器的输入
fake_noise = get_noise(num_images,z_dim,device)
fake = gen(fake_noise)
# 计算判别器的损失
disc_fake_pred = disc(fake.detach())
disc_real_pred = disc(real)
# 计算判别器的损失
disc_loss = nn.BCEWithLogitsLoss()(disc_real_pred,torch.ones_like(disc_real_pred)) + nn.BCEWithLogitsLoss()(disc_fake_pred,torch.zeros_like(disc_fake_pred))
return disc_loss配置参数:
#定义训练参数
n_epochs = 200 #训练的轮数
z_dim = 64 #生成器的输入维度
display_step = 500 #打印结果的步数
batch_size = 128 #每次训练的样本数
lr = 0.0001 #学习率
#定义数据加载
dataloader = DataLoader(
MNIST('', download=True, transform=transforms.ToTensor()), #加载MNIST数据集
batch_size=batch_size, #每个batch的大小
shuffle=True #是否打乱数据
)
# 定义生成器和判别器
gen = Generator(z_dim)
gen_opt = torch.optim.Adam(gen.parameters(),lr=lr) # 生成器优化器
disc = Discriminator() # 判别器
disc_opt = torch.optim.Adam(disc.parameters(),lr=lr) # 判别器优化器输出张量图片:
# 定义一个函数,用于显示张量图像
def show_tensor_images(image_tensor,num_images=25,size=(1,28,28)):
# 将张量转换为numpy数组,并将其展平为一维数组
images = image_tensor.detach().cpu().view(-1,*size) #维度为:(batch_size,channel,height,width)
# 使用make_grid函数创建一个图像网格
image_grid = make_grid(images[:num_images],nrow=4) # 参数nrow表示每行显示的图像数量,images[:num_images]表示只显示前num_images个图像
# 使用matplotlib库显示图像网格
plt.imshow(image_grid.permute(1,2,0).squeeze())
plt.show()训练:
重置损失:
在GAN的训练过程中,每迭代一次,生成器和判别器的权重就会更新一次。这意味着每次迭代后,生成器和判别器的损失应该基于更新后的权重重新计算。因此,每进行一次迭代,就需要重置一次损失。
此外,这段代码中每迭代
display_step次就会打印一次生成器和判别器的损失。如果在打印损失之前没有重置损失,那么损失值将会包含之前display_step次迭代的所有梯度下降步骤,这可能导致打印出的损失值偏高,失去参考意义。因此,重置损失函数是必要的,可以确保每次打印的损失值都是最近
display_step次迭代计算的平均值。
"""
训练
"""
# 当前的步骤数
cur_step = 0
# 生成器的平均损失
mean_generator_loss = 0
# 判别器的平均损失
mean_discriminator_loss = 0
# 结果
result = None
# 标签
label = None
for epoch in tqdm(range(n_epochs)):
for real, _ in dataloader:
cur_batch_size = len(real)
real = real.view(cur_batch_size, -1)
# 计算判别器的损失
disc_opt.zero_grad() # 判别器梯度清零
disc_loss = get_disc_loss(gen,disc,real,cur_batch_size,z_dim)
disc_loss.backward(retain_graph=True) # 保留图,以便在反向传播中使用
disc_opt.step()
# 计算生成器的损失
gen_opt.zero_grad() # 生成器梯度清零
gen_loss = get_gen_loss(gen,disc,cur_batch_size,z_dim)
gen_loss.backward() # 生成器损失反向传播
gen_opt.step()
# 打印损失
# 计算生成器损失
mean_generator_loss += gen_loss.item() / display_step
# 计算判别器损失
mean_discriminator_loss += disc_loss.item() / display_step
# 如果当前步数%显示步数等于0,并且当前步数大于0
if cur_step % display_step == 0 and cur_step > 0:
print(
f'Step {cur_step}: Generator Loss: {mean_generator_loss}, ' +
f'Discriminator Loss: {mean_discriminator_loss}')
# 生成随机噪声
fake_noise = get_noise(batch_size, z_dim)
# 使用生成器生成假图片
fake = gen(fake_noise)
# 将假图片放入判别器
result = fake
label = real
# 重置损失
mean_generator_loss = 0
mean_discriminator_loss = 0
cur_step += 1
# 显示张量图像
show_tensor_images(result)
# 显示张量图像
show_tensor_images(label)输出结果:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









