






我这里的错误是在某个时间点GPU利用率 ,显存一下子上去计算矩阵,但是因为gpu算力不够,导致上去一下就崩掉了,生成的程序错误如下:
raise type(e)(node_def, op, message)
tensorflow.python.framework.errors_impl.InternalError: Blas GEMM launch failed : a.shape=(49820, 3), b.shape=(3, 30), m=49820, n=30, k=3
[[node MatMul_6 (defined at python\anaconda3\envs\dev37\lib\site-packages\tensorflow_core\python\framework\ops.py:1748) ]]首先,在cmd中输入下面这行代码查看GPU 利用率、GPU显存利用率、温度、GPU显存具体使用大小。每0.5s记录一次
nvidia-smi --query-gpu=timestamp,index,name,utilization.gpu,utilization.memory,temperature.gpu,memory.used --format=csv -lms 500 > D:\zhangwei\shixian\PINN+FWI\rasht-behesht_etal_2021\log.csv在自己的代码里查看生成的记录日志
解决这个错误,首先我纠结我使用的gpu是集成显卡还是独立显卡,这里赋个链接是集成显卡和独立显卡的区别
【扫盲】关于GPU的那些事_gpu是独显还是集显-CSDN博客
后来在一番验证后发现虽然任务管理器显示有两个显卡,且gpu0对应集显,gpu1对应独显,但是在代码运行时显示的gpu0对应的仍然是独显,可以在代码中输入显示使用设备信息查证,例如我的代码运行会显示
2024-09-04 11:50:46.609184: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1618] Found device 0 with properties:
name: NVIDIA GeForce RTX 3060 Laptop GPU major: 8 minor: 6 memoryClockRate(GHz): 1.425说明我的代码是在独显上运行的。
其次,我考虑了batch-size大小的原因,我的batch-size大小为40000,代码输入为40000*2000,我调小batch-size为5000*500,发现还是计算不出来,我觉得应该不是这个的原因。但是cpu加载数据的时间明显变短,说明改变size是对加载数据有调节的。
raise type(e)(node_def, op, message)
tensorflow.python.framework.errors_impl.InternalError: Blas GEMM launch failed : a.shape=(11820, 3), b.shape=(3, 30), m=11820, n=30, k=3
[[node MatMul_6 (defined at python\anaconda3\envs\dev37\lib\site-packages\tensorflow_core\python\framework\ops.py:1748) ]]然后,考虑tensorflow版本兼容问题,我用的是tensorflow=1.15对应cuda=10.0、cudnn=7.4版本都是对的,兼容问题排除。
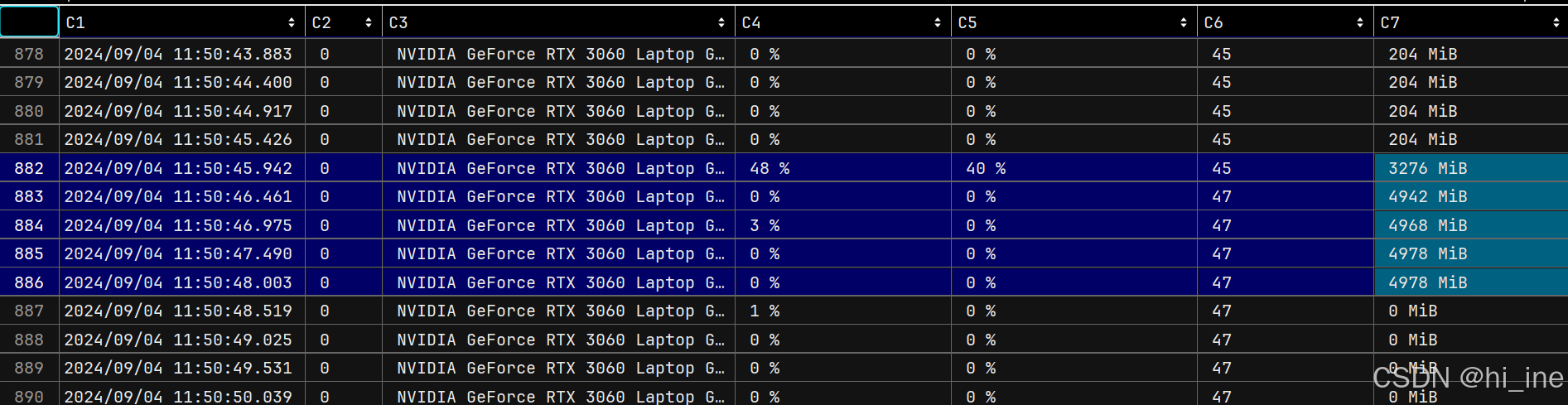
然后,考虑是否因为驱动不是最新版导致,更新驱动,我的驱动是
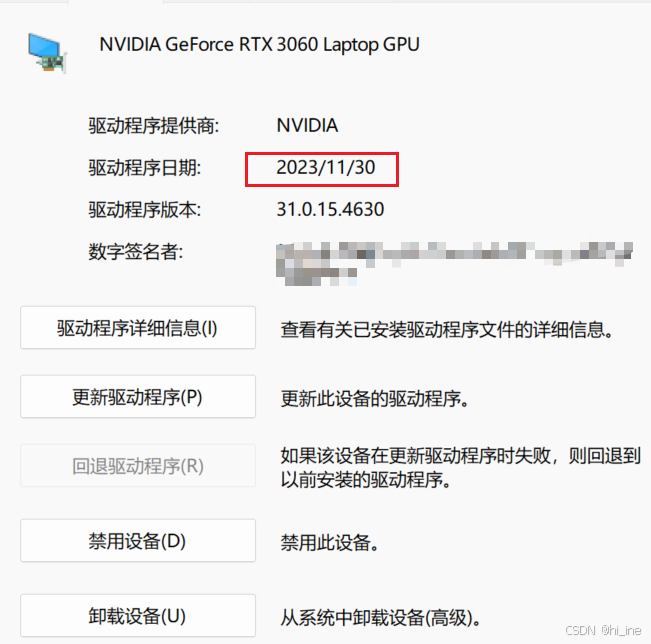
我到官网去手动搜索驱动,看到最新的驱动是

且
 支持我的显卡,所以下载安装,安装步骤参考:
支持我的显卡,所以下载安装,安装步骤参考:
【Windows】安装NVIDIA驱动 / 更新驱动_windows 更新nvidia驱动-CSDN博客
直至安装完毕,重启电脑,再在设备管理器中查看驱动版本,发现已经更新到安装版本
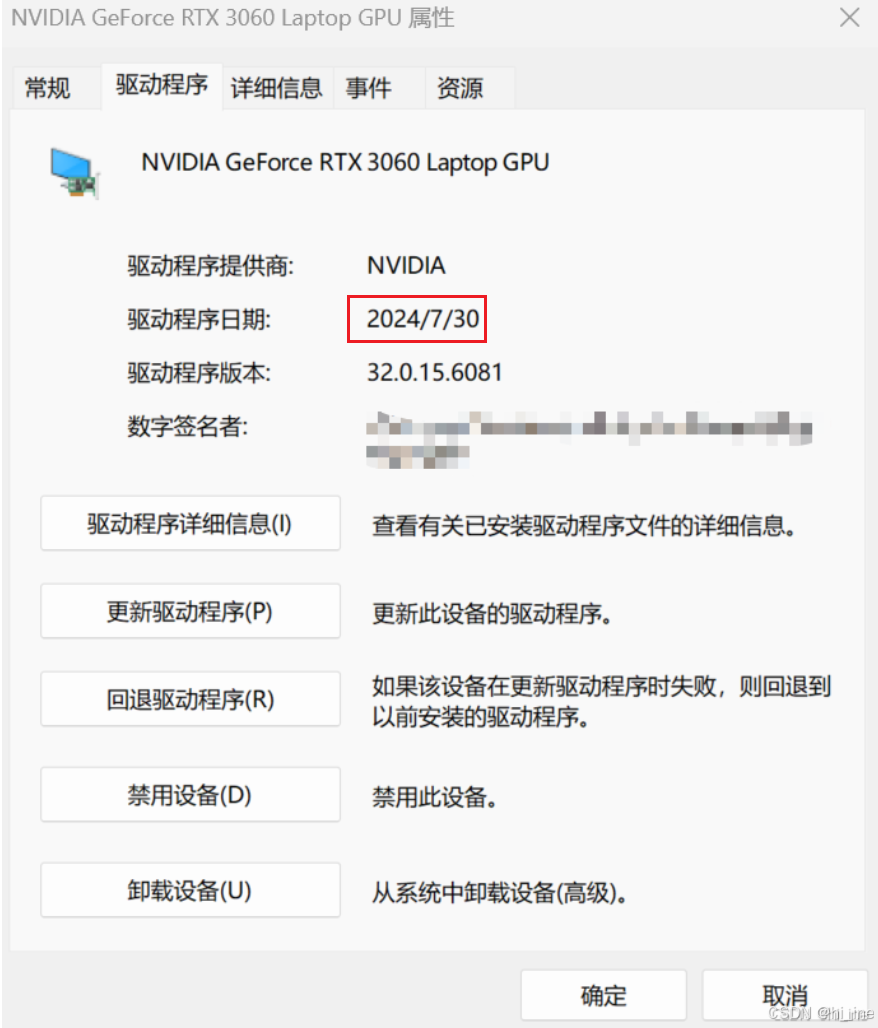
更新驱动之后还是出现错误,且还是会出现在某一时间点显存和利用率都爆了的情况。
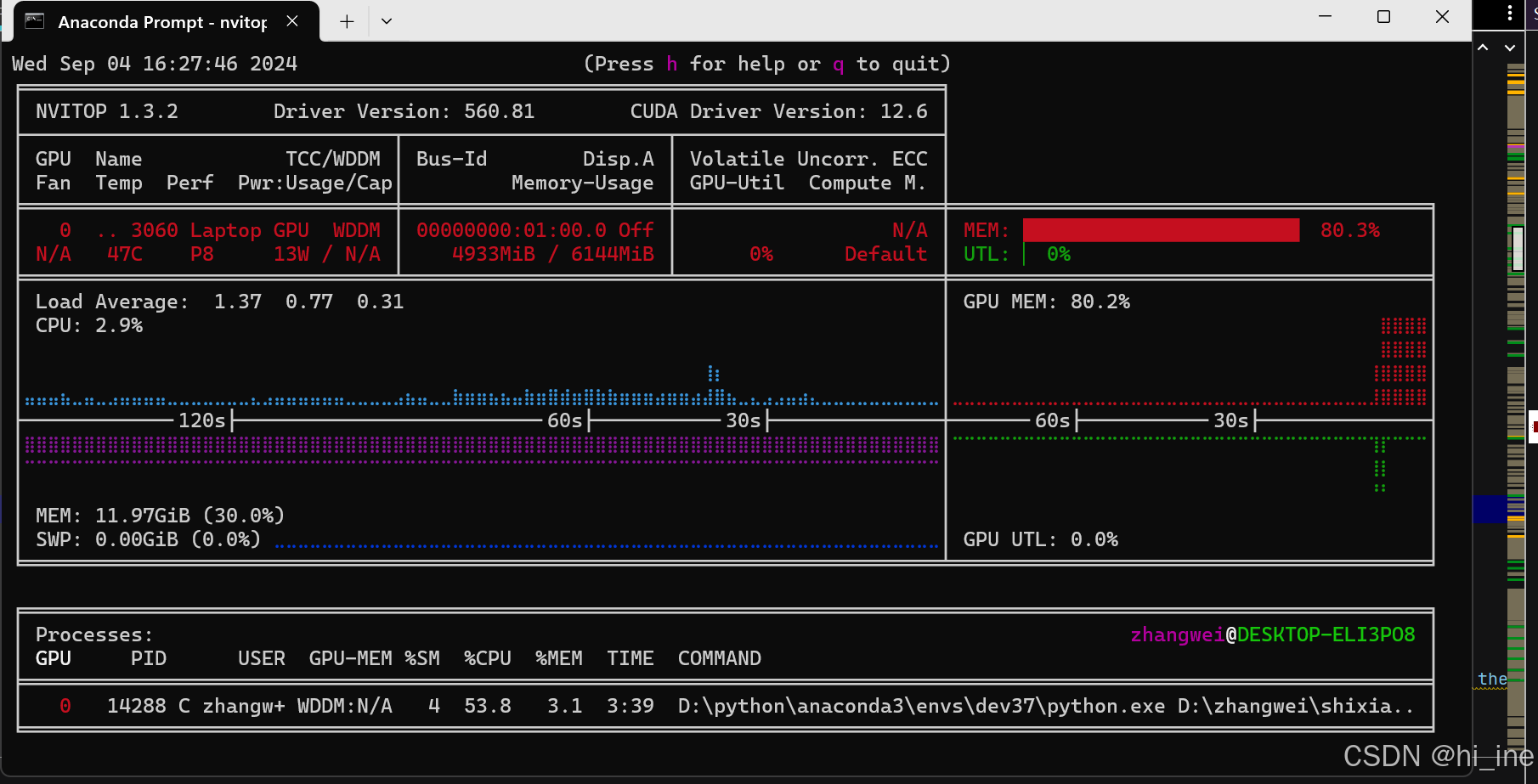
至此,应该只有两种可能,要么是代码中gpu并行没有处理好;要么是模型太大了,因为batchsize已经减小且输入的数据量也不算太多。
代码中gpu并行没有处理好
针对tensorflow1.x,动态配置gpu显存,参考这篇文章:
TensorFlow1.x/2.x配置动态显存方法_tensorflow2 动态分配显存-CSDN博客
速度确实提升很多,但是问题还是没有解决,那么就是只有模型太大的可能了,这个问题使用云服解决。
更新:云服上我已经使用了gpu显存48g仍然显示该错误,我的模型感觉用不了那么大的显存,等有时间试一下显存80g的,我看到有人说将tensorflow1.x升级到2.x也可能解决该问题,因为1.x很多功能没开发出来,对于现在新的gpu有种力不从心的感觉,下边更新如何从tensorflow1.x更新到2.x。
参考另一篇文章:
将 TensorFlow 1.X 的代码转换为 TensorFlow 2.0_tf.contrib.tpu.runconfig在tf2-CSDN博客


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









