






大家好,小编为大家解答python中常用的类的问题。很多人还不知道python 类的用法,现在让我们一起来看看吧!

Source code download: 本文相关源码
此文纯干货,预估阅读时间:10分钟
No.1 一切皆对象
众所周知,Java中强调“一切皆对象”,但是Python中的面向对象比Java更加彻底,因为Python中的类(class)也是对象,函数(function)也是对象,而且Python的代码和模块也都是对象。
- Python中函数和类可以赋值给一个变量
- Python中函数和类可以存放到集合对象中
- Python中函数和类可以作为一个函数的参数传递给函数
- Python中函数和类可以作为返回值
Step.1
# 首先创建一个函数和一个Python3.x的新式类class Demo(object): def init(self): print(“Demo Class”)
# 定义一个函数def function(): print(“function”)
# 在Python无论是函数,还是类,都是对象,他们可以赋值给一个变量class_value = Demo func_value = function
# 并且可以通过变量调用class_value() # Demo Classfunc_value() # function
Step.2
# 将函数和类添加到集合中obj_list = [] obj_list.append(Demo) obj_list.append(function)# 遍历列表for i in obj_list: print(i) # #
Step.3
# 定义一个具体函数def test_func(class_name, func_name): class_name() func_name()
# 将类名和函数名传入形参列表test_func(Demo, function)# Demo Class# function
Step.4
# 定义函数实现返回类和函数def test_func2(): return Demodef test_func3(): return function
# 执行函数test_func2()() # Demo Classtest_func3()() # function
No.2 关键字type、object、class之间的关系
在Python中,object的实例是type,object是顶层类,没有基类;type的实例是type,type的基类是object学python有用吗。Python中的内置类型的基类是object,但是他们都是由type实例化而来,具体的值由内置类型实例化而来。在Python2.x的语法中用户自定义的类没有明确指定基类就默认是没有基类,在Python3.x的语法中,指定基类为object。
# object是谁实例化的?print(type(object)) # # object继承自哪个类?print(object.bases) # ()# type是谁实例化的?print(type(type)) # # type继承自哪个类?print(type.bases) # (,)# 定义一个变量value = 100# 100由谁实例化?print(type(value)) # # int由谁实例化?print(type(int)) # # int继承自哪个类?print(int.bases) # (,)
# Python 2.x的旧式类class OldClass(): pass# Python 3.x的新式类class NewClass(object): pass
No.3 Python的内置类型
在Python中,对象有3个特征属性:
- 在内存中的地址,使用
id()函数进行查看 - 对象的类型
- 对象的默认值
Step.1 None类型
在Python解释器启动时,会创建一个None类型的None对象,并且None对象全局只有一个。
Step.2 数值类型
- ini类型
- float类型
- complex类型
- bool类型
Step.3 迭代类型
在Python中,迭代类型可以使用循环来进行遍历。
Step.4 序列类型
- list
- tuple
- str
- array
- range
- bytes, bytearray, memoryvie(二进制序列)
Step.5 映射类型
- dict
Step.6 集合类型
- set
- frozenset
Step.7 上下文管理类型
- with语句
Step.8 其他类型
- 模块
- class
- 实例
- 函数
- 方法
- 代码
- object对象
- type对象
- ellipsis(省略号)
- notimplemented
NO.4 魔法函数
Python中的魔法函数使用双下划线开始,以双下划线结尾。关于详细介绍请看我的文章——《全面总结Python中的魔法函数》。
No.5 鸭子类型与白鹅类型
鸭子类型是程序设计中的推断风格,在鸭子类型中关注对象如何使用而不是类型本身。鸭子类型像多态一样工作但是没有继承。鸭子类型的概念来自于:“当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子。”
# 定义狗类class Dog(object): def eat(self): print(“dog is eatting…”)# 定义猫类class Cat(object): def eat(self): print(“cat is eatting…”)# 定义鸭子类class Duck(object): def eat(self): print(“duck is eatting…”)# 以上Python中多态的体现# 定义动物列表an_li = []# 将动物添加到列表an_li.append(Dog) an_li.append(Cat) an_li.append(Duck)# 依次调用每个动物的eat()方法for i in an_li: i().eat()# dog is eatting…# cat is eatting…# duck is eatting…
白鹅类型是指只要 cls 是抽象基类,即 cls 的元类是 abc.ABCMeta ,就可以使用 isinstance(obj, cls) 。
No.6 协议、 抽象基类、abc模块和序列之间的继承关系
- 协议:Python中的非正式接口,是允许Python实现多态的方式,协议是非正式的,不具备强制性,由约定和文档定义。
- 接口:泛指实体把自己提供给外界的一种抽象化物(可以为另一实体),用以由内部操作分离出外部沟通方法,使其能被内部修改而不影响外界其他实体与其交互的方式。
我们可以使用猴子补丁来实现协议,那么什么是猴子补丁呢?
猴子补丁就是在运行时修改模块或类,不去修改源代码,从而实现目标协议接口操作,这就是所谓的打猴子补丁。
Tips:猴子补丁的叫法起源于Zope框架,开发人员在修改Zope的Bug时,经常在程序后面追加更新的部分,这些
杂牌军补丁的英文名字叫做guerilla patch,后来写成gorllia,接着就变成了monkey。
猴子补丁的主要作用是:
- 在运行时替换方法、属性
- 在不修改源代码的情况下对程序本身添加之前没有的功能
- 在运行时对象中添加补丁,而不是在磁盘中的源代码上
应用案例:假设写了一个很大的项目,处处使用了json模块来解析json文件,但是后来发现ujson比json性能更高,修改源代码是要修改很多处的,所以只需要在程序入口加入:
import json# pip install ujsonimport ujson def monkey_patch_json(): json.name = ‘ujson’ json.dumps = ujson.dumps json.loads = ujson.loads monkey_patch_json()
Python 的抽象基类有一个重要实用优势:可以使用 register 类方法在终端用户的代码中把某个类 “声明” 为一个抽象基类的 “虚拟” 子 类(为此,被注册的类必腨满足抽象其类对方法名称和签名的要求,最重要的是要满足底 层语义契约;但是,开发那个类时不用了解抽象基类,更不用继承抽象基类 。有时,为了让抽象类识别子类,甚至不用注册。要抑制住创建抽象基类的冲动。滥用抽象基类会造成灾难性后果,表明语言太注重表面形式 。
- 抽象基类不能被实例化(不能创建对象),通常是作为基类供子类继承,子类中重写虚函数,实现具体的接口。
- 判定某个对象的类型
- 强制子类必须实现某些方法
抽象基类的定义与使用
import abc# 定义缓存类class Cache(metaclass=abc.ABCMeta): @abc.abstractmethod def get(self, key): pass @abc.abstractmethod def set(self, key, value): pass# 定义redis缓存类实现Cache类中的get()和set()方法class RedisCache(Cache): def set(self, key): pass def get(self, key, value): pass
值得注意的是:Python 3.0-Python3.3之间,继承抽象基类的语法是class ClassName(metaclass=adc.ABCMeta),其他版本是:class ClassName(abc.ABC)。
- collections.abc模块中各个抽象基类的UML类图

No.7 isinstence和type的区别
class A(object): passclass B(A): passb = B() print(isinstance(b, B)) print(isinstance(b, A)) print(type(b) is B) print(type(b) is A)# True# True# True# False
No.8 类变量和实例变量
- 实例变量只能通过类的实例进行调用
- 修改模板对象创建的对象的属性,模板对象的属性不会改变
- 修改模板对象的属性,由模板对象创建的对象的属性会改变
# 此处的类也是模板对象,Python中一切皆对象class A(object): #类变量 number = 12 def init(self): # 实例变量 self.number_2 = 13# 实例变量只能通过类的实例进行调用print(A.number) # 12print(A().number) # 12print(A().number_2) # 13# 修改模板对象创建的对象的属性,模板对象的属性不会改变a = A() a.number = 18print(a.number) # 18print(A().number) # 12print(A.number) # 12# 修改模板对象的属性,由模板对象创建的对象的属性会改变A.number = 19print(A.number) # 19print(A().number) # 19
No.9 类和实例属性以及方法的查找顺序
- 在Python 2.2之前只有经典类,到Python2.7还会兼容经典类,Python3.x以后只使用新式类,Python之前版本也会兼容新式类
- Python 2.2 及其之前类没有基类,Python新式类需要显式继承自
object,即使不显式继承也会默认继承自object - 经典类在类多重继承的时候是采用从左到右深度优先原则匹配方法的.而新式类是采用C3算法
- 经典类没有MRO和instance.mro()调用的
假定存在以下继承关系:
class D(object): def say_hello(self): passclass E(object): passclass B(D): passclass C(E): passclass A(B, C): pass
采用DFS(深度优先搜索算法)当调用了A的say_hello()方法的时候,系统会去B中查找如果B中也没有找到,那么去D中查找,很显然D中存在这个方法,但是DFS对于以下继承关系就会有缺陷:
class D(object): passclass B(D): passclass C(D): def say_hello(self): passclass A(B, C): pass
在A的实例对象中调用say_hello方法时,系统会先去B中查找,由于B类中没有该方法的定义,所以会去D中查找,D类中也没有,系统就会认为该方法没有定义,其实该方法在C中定义了。所以考虑使用BFS(广度优先搜索算法),那么问题回到第一个继承关系,假定C和D具备重名方法,在调用A的实例的方法时,应该先在B中查找,理应调用D中的方法,但是使用BFS的时候,C类中的方法会覆盖D类中的方法。在Python 2.3以后的版本中,使用C3算法:
# 获取解析顺序的方法类名.mro() 类名.mro inspect.getmro(类名)
使用C3算法后的第二种继承顺序:
class D(object): passclass B(D): passclass C(D): def say_hello(self): passclass A(B, C): passprint(A.mro()) # [, , , , ]
使用C3算法后的第一种继承顺序:
class D(object): passclass E(object): passclass B(D): passclass C(E): passclass A(B, C): passprint(A.mro()) # [, , , , , ]
在这里仅介绍了算法的作用和演变历史,关于深入详细解析,请看我的其他文章——《从Python继承谈起,到C3算法落笔》。
No.10 类方法、实例方法和静态方法
class Demo(object): # 类方法 @classmethod def class_method(cls, number): pass # 静态方法 @staticmethod def static_method(number): pass # 对象方法/实例方法 def object_method(self, number): pass
实例方法只能通过类的实例来调用;静态方法是一个独立的、无状态的函数,紧紧依托于所在类的命名空间上;类方法在为了获取类中维护的数据,比如:
class Home(object): # 房间中人数 __number = 0 @classmethod def add_person_number(cls): cls.number += 1 @classmethod def get_person_number(cls): return cls.number def new(self): Home.add_person_number() # 重写__new__方法,调用object的__new return super().new(self)class Person(Home): def init(self): # 房间人员姓名 self.name = ‘name’ # 创建人员对象时调用Home的__new()方法tom = Person() print(type(tom)) # alice = Person() bob = Person() test = Person() print(Home.get_person_number())
No.11 数据封装和私有属性
Python中使用双下划线+属性名称实现类似于静态语言中的private修饰来实现数据封装。
class User(object): def init(self, number): self.__number = number self.__number_2 = 0 def set_number(self, number): self.__number = number def get_number(self): return self.__number def set_number_2(self, number2): self.__number_2 = number2 # self.__number2 = number2 def get_number_2(self): return self.__number_2 # return self.__number2u = User(25) print(u.get_number()) # 25# 真的类似于Java的反射机制吗?print(u._User__number) # 25# 下面又是啥情况。。。想不明白了T_Tu.set_number_2(18) print(u.get_number_2()) # 18print(u._User__number_2) # Anaconda 3.6.3 第一次是:u._User__number_2 第二次是:18# Anaconda 3.6.5 结果都是 0 # 代码我改成了正确答案,感谢我大哥给我指正错误,我保留了错误痕迹# 变量名称写错了,算是个写博客突发事故,这问题我找了一天,万分感谢我大哥,我太傻B了,犯了低级错误# 留给和我一样的童鞋参考我的错我之处吧!# 正确结果:# 25 25 18 18
No.12 Python的自省机制
自省(introspection)是一种自我检查行为。在计算机编程中,自省是指这种能力:检查某些事物以确定它是什么、它知道什么以及它能做什么。自省向程序员提供了极大的灵活性和控制力。
- dir([obj]):返回传递给它的任何对象的属性名称经过排序的列表(会有一些特殊的属性不包含在内)
- getattr(obj, attr):返回任意对象的任何属性 ,调用这个方法将返回obj中名为attr值的属性的值
- … …
No.13 super函数
Python3.x 和 Python2.x 的一个区别是: Python 3 可以使用直接使用 super().xxx 代替 super(type[, object-or-type]).xxx 。
super()函数用来调用MRO(类方法解析顺序表)的下一个类的方法。
No.14 Mixin继承
在设计上将Mixin类作为功能混入继承自Mixin的类。使用Mixin类实现多重继承应该注意:
- Mixin类必须表示某种功能
- 职责单一,如果要有多个功能,就要设计多个Mixin类
- 不依赖子类实现,Mixin类的存在仅仅是增加了子类的功能特性
- 即使子类没有继承这个Mixin类也可以工作
class Cat(object): def eat(self): print(“I can eat.”) def drink(self): print(“I can drink.”)class CatFlyMixin(object): def fly(self): print(“I can fly.”)class CatJumpMixin(object): def jump(self): print(“I can jump.”)class TomCat(Cat, CatFlyMixin): passclass PersianCat(Cat, CatFlyMixin, CatJumpMixin): passif name == ‘main’: # 汤姆猫没有跳跃功能 tom = TomCat() tom.fly() tom.eat() tom.drink() # 波斯猫混入了跳跃功能 persian = PersianCat() persian.drink() persian.eat() persian.fly() persian.jump()
No.15 上下文管理器with语句与contextlib简化
普通的异常捕获机制:
try: passexcept Exception as err: passelse: passfinally: pass
with简化了异常捕获写法:
class Demo(object): def enter(self): print(“enter…”) return self def exit(self, exc_type, exc_val, exc_tb): print(“exit…”) def echo_hello(self): print(“Hello, Hello…”)with Demo() as d: d.echo_hello()# enter…# Hello, Hello…# exit…
import contextlib# 使用装饰器@contextlib.contextmanagerdef file_open(file_name): # 此处写__enter___函数中定义的代码 print(“enter function code…”) yield {} # 此处写__exit__函数中定义的代码 print(“exit function code…”)with file_open(“json.json”) as f: pass# enter function code…# exit function code…
No.16 序列类型的分类
- 容器序列:list tuple deque
- 扁平序列:str bytes bytearray array.array
- 可变序列:list deque bytearray array
- 不可变序列:str tuple bytes
No.27 +、+=、extend()之间的区别于应用场景
首先看测试用例:
# 创建一个序列类型的对象my_list = [1, 2, 3]# 将现有的序列合并到my_listextend_my_list = my_list + [4, 5] print(extend_my_list) # [1, 2, 3, 4, 5]# 将一个元组合并到这个序列extend_my_list = my_list + (6, 7)# 抛出异常 TypeError: can only concatenate list (not “tuple”) to listprint(extend_my_list)# 使用另一种方式合并extend_my_list += (6, 7) print(extend_my_list) # [1, 2, 3, 4, 5, 6, 7]# 使用extend()函数进行合并extend_my_list.extend((7, 8)) print(extend_my_list) # [1, 2, 3, 4, 5, 6, 7, 7, 8]
由源代码片段可知:
class MutableSequence(Sequence): slots = () “”“All the operations on a read-write sequence. Concrete subclasses must provide new or init, getitem, setitem, delitem, len, and insert(). “”” # extend()方法内部使用for循环来append()元素,它接收一个可迭代序列 def extend(self, values): ‘S.extend(iterable) – extend sequence by appending elements from the iterable’ for v in values: self.append(v) # 调用 += 运算的时候就是调用该函数,这个函数内部调用extend()方法 def iadd(self, values): self.extend(values) return self
No.18 使用bisect维护一个已排序的序列
import bisect my_list = [] bisect.insort(my_list, 2) bisect.insort(my_list, 9) bisect.insort(my_list, 5) bisect.insort(my_list, 5) bisect.insort(my_list, 1)# insort()函数返回接收的元素应该插入到指定序列的索引位置print(my_list) # [1, 2, 5, 5, 9]
No.19 deque类详解
deque是Python中一个双端队列,能在队列两端以 O ( 1 ) O(1) O(1)的效率插入数据,位于collections模块中。
from collections import deque# 定义一个双端队列,长度为3d = deque(maxlen=3)
deque类的源码:
class deque(object): “”" deque([iterable[, maxlen]]) --> deque object 一个类似列表的序列,用于对其端点附近的数据访问进行优化。 “”" def append(self, *args, **kwargs): “”" 在队列右端添加数据 “”" pass def appendleft(self, *args, **kwargs): “”" 在队列左端添加数据 “”" pass def clear(self, *args, **kwargs): “”" 清空所有元素 “”" pass def copy(self, *args, **kwargs): “”" 浅拷贝一个双端队列 “”" pass def count(self, value): “”" 统计指定value值的出现次数 “”" return 0 def extend(self, *args, **kwargs): “”" 使用迭代的方式扩展deque的右端 “”" pass def extendleft(self, *args, **kwargs): “”" 使用迭代的方式扩展deque的左端 “”" pass def index(self, value, start=None, stop=None): doc “”" 返回第一个符合条件的索引的值 “”" return 0 def insert(self, index, p_object): “”" 在指定索引之前插入 “”" pass def pop(self, *args, **kwargs): # real signature unknown “”" 删除并返回右端的一个元素 “”" pass def popleft(self, *args, **kwargs): # real signature unknown “”" 删除并返回左端的一个元素 “”" pass def remove(self, value): # real signature unknown; restored from doc “”" 删除第一个与value相同的值 “”" pass def reverse(self): # real signature unknown; restored from doc “”" 翻转队列 “”" pass def rotate(self, *args, **kwargs): # real signature unknown “”" 向右旋转deque N步, 如果N是个负数,那么向左旋转N的绝对值步 “”" pass def add(self, *args, **kwargs): # real signature unknown “”" Return self+value. “”" pass def bool(self, *args, **kwargs): # real signature unknown “”" self != 0 “”" pass def contains(self, *args, **kwargs): # real signature unknown “”" Return key in self. “”" pass def copy(self, *args, **kwargs): # real signature unknown “”" Return a shallow copy of a deque. “”" pass def delitem(self, *args, **kwargs): # real signature unknown “”" Delete self[key]. “”" pass def eq(self, *args, **kwargs): # real signature unknown “”" Return self=value. “”" pass def getattribute(self, *args, **kwargs): # real signature unknown “”" Return getattr(self, name). “”" pass def getitem(self, *args, **kwargs): # real signature unknown “”" Return self[key]. “”" pass def ge(self, *args, **kwargs): # real signature unknown “”" Return self>=value. “”" pass def gt(self, *args, **kwargs): # real signature unknown “”" Return self>value. “”" pass def iadd(self, *args, **kwargs): # real signature unknown “”" Implement self+=value. “”" pass def imul(self, *args, *kwargs): # real signature unknown “”" Implement self=value. “”" pass def init(self, iterable=(), maxlen=None): # known case of _collections.deque.init “”" deque([iterable[, maxlen]]) --> deque object A list-like sequence optimized for data accesses near its endpoints. # (copied from class doc) “”" pass def iter(self, *args, **kwargs): # real signature unknown “”" Implement iter(self). “”" pass def len(self, *args, **kwargs): # real signature unknown “”" Return len(self). “”" pass def le(self, *args, **kwargs): # real signature unknown “”" Return self an object providing a view on D’s values" return _OrderedDictValuesView(self) ne = MutableMapping.ne __marker = object() def pop(self, key, default=__marker): ‘’‘od.pop(k[,d]) -> v, remove specified key and return the corresponding value. If key is not found, d is returned if given, otherwise KeyError is raised. ‘’’ if key in self: result = self[key] del self[key] return result if default is self.__marker: raise KeyError(key) return default def setdefault(self, key, default=None): ‘od.setdefault(k[,d]) -> od.get(k,d), also set od[k]=d if k not in od’ if key in self: return self[key] self[key] = default return default @_recursive_repr() def repr(self): ‘od.repr() repr(od)’ if not self: return ‘%s()’ % (self.class.name,) return ‘%s(%r)’ % (self.class.name, list(self.items())) def reduce(self): ‘Return state information for pickling’ inst_dict = vars(self).copy() for k in vars(OrderedDict()): inst_dict.pop(k, None) return self.class, (), inst_dict or None, None, iter(self.items()) def copy(self): ‘od.copy() -> a shallow copy of od’ return self.class(self) @classmethod def fromkeys(cls, iterable, value=None): ‘’‘OD.fromkeys(S[, v]) -> New ordered dictionary with keys from S. If not specified, the value defaults to None. ‘’’ self = cls() for key in iterable: self[key] = value return self def eq(self, other): ‘’‘od.eq(y) od==y. Comparison to another OD is order-sensitive while comparison to a regular mapping is order-insensitive. ‘’’ if isinstance(other, OrderedDict): return dict.eq(self, other) and all(map(_eq, self, other)) return dict.eq(self, other)
deque
list存储数据的时候,内部实现是数组,数组的查找速度是很快的,但是插入和删除数据的速度堪忧。deque双端列表内部实现是双端队列。deuque适用队列和栈,并且是线程安全的。
deque提供append()和pop()函数实现在deque尾部添加和弹出数据,提供appendleft()和popleft()函数实现在deque头部添加和弹出元素。这4个函数的时间复杂度都是 O ( 1 ) O(1) O(1)的,但是list的时间复杂度高达 O ( n ) O(n) O(n)。
创建deque队列
from collections import deque# 创建一个队列长度为20的dequedQ = deque(range(10), maxlen=20) print(dQ)# deque([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=20)
源码
class deque(object): “”" deque([iterable[, maxlen]]) --> deque object A list-like sequence optimized for data accesses near its endpoints. “”" def append(self, *args, **kwargs): # real signature unknown “”" Add an element to the right side of the deque. “”" pass def appendleft(self, *args, **kwargs): # real signature unknown “”" Add an element to the left side of the deque. “”" pass def clear(self, *args, **kwargs): # real signature unknown “”" Remove all elements from the deque. “”" pass def copy(self, *args, **kwargs): # real signature unknown “”" Return a shallow copy of a deque. “”" pass def count(self, value): # real signature unknown; restored from doc “”" D.count(value) -> integer – return number of occurrences of value “”" return 0 def extend(self, *args, **kwargs): # real signature unknown “”" Extend the right side of the deque with elements from the iterable “”" pass def extendleft(self, *args, **kwargs): # real signature unknown “”" Extend the left side of the deque with elements from the iterable “”" pass def index(self, value, start=None, stop=None): # real signature unknown; restored from doc “”" D.index(value, [start, [stop]]) -> integer – return first index of value. Raises ValueError if the value is not present. “”" return 0 def insert(self, index, p_object): # real signature unknown; restored from doc “”" D.insert(index, object) – insert object before index “”" pass def pop(self, *args, **kwargs): # real signature unknown “”" Remove and return the rightmost element. “”" pass def popleft(self, *args, **kwargs): # real signature unknown “”" Remove and return the leftmost element. “”" pass def remove(self, value): # real signature unknown; restored from doc “”" D.remove(value) – remove first occurrence of value. “”" pass def reverse(self): # real signature unknown; restored from doc “”" D.reverse() – reverse IN PLACE “”" pass def rotate(self, *args, **kwargs): # real signature unknown “”" Rotate the deque n steps to the right (default n=1). If n is negative, rotates left. “”" pass def add(self, *args, **kwargs): # real signature unknown “”" Return self+value. “”" pass def bool(self, *args, **kwargs): # real signature unknown “”" self != 0 “”" pass def contains(self, *args, **kwargs): # real signature unknown “”" Return key in self. “”" pass def copy(self, *args, **kwargs): # real signature unknown “”" Return a shallow copy of a deque. “”" pass def delitem(self, *args, **kwargs): # real signature unknown “”" Delete self[key]. “”" pass def eq(self, *args, **kwargs): # real signature unknown “”" Return self==value. “”" pass def getattribute(self, *args, **kwargs): # real signature unknown “”" Return getattr(self, name). “”" pass def getitem(self, *args, **kwargs): # real signature unknown “”" Return self[key]. “”" pass def ge(self, *args, **kwargs): # real signature unknown “”" Return self>=value. “”" pass def gt(self, *args, **kwargs): # real signature unknown “”" Return self>value. “”" pass def iadd(self, *args, **kwargs): # real signature unknown “”" Implement self+=value. “”" pass def imul(self, *args, *kwargs): # real signature unknown “”" Implement self=value. “”" pass def init(self, iterable=(), maxlen=None): # known case of _collections.deque.init “”" deque([iterable[, maxlen]]) --> deque object A list-like sequence optimized for data accesses near its endpoints. # (copied from class doc) “”" pass def iter(self, *args, **kwargs): # real signature unknown “”" Implement iter(self). “”" pass def len(self, *args, **kwargs): # real signature unknown “”" Return len(self). “”" pass def le(self, *args, **kwargs): # real signature unknown “”" Return self> Point = namedtuple(‘Point’, [‘x’, ‘y’]) >>> Point.doc # docstring for the new class ‘Point(x, y)’ >>> p = Point(11, y=22) # instantiate with positional args or keywords >>> p[0] + p[1] # indexable like a plain tuple 33 >>> x, y = p # unpack like a regular tuple >>> x, y (11, 22) >>> p.x + p.y # fields also accessible by name 33 >>> d = p._asdict() # convert to a dictionary >>> d[‘x’] 11 >>> Point(**d) # convert from a dictionary Point(x=11, y=22) >>> p._replace(x=100) # replace() is like str.replace() but targets named fields Point(x=100, y=22) “”" # Validate the field names. At the user’s option, either generate an error # message or automatically replace the field name with a valid name. if isinstance(field_names, str): field_names = field_names.replace(‘,’, ’ ‘).split() field_names = list(map(str, field_names)) typename = str(typename) if rename: seen = set() for index, name in enumerate(field_names): if (not name.isidentifier() or iskeyword(name) or name.startswith('’) or name in seen): field_names[index] = '%d’ % index seen.add(name) for name in [typename] + field_names: if type(name) is not str: raise TypeError(‘Type names and field names must be strings’) if not name.isidentifier(): raise ValueError(‘Type names and field names must be valid ’ ‘identifiers: %r’ % name) if iskeyword(name): raise ValueError(‘Type names and field names cannot be a ’ ‘keyword: %r’ % name) seen = set() for name in field_names: if name.startswith(’’) and not rename: raise ValueError(‘Field names cannot start with an underscore: ’ ‘%r’ % name) if name in seen: raise ValueError(‘Encountered duplicate field name: %r’ % name) seen.add(name) # Fill-in the class template class_definition = _class_template.format( typename = typename, field_names = tuple(field_names), num_fields = len(field_names), arg_list = repr(tuple(field_names)).replace("’", “”)[1:-1], repr_fmt = ', ‘.join(_repr_template.format(name=name) for name in field_names), field_defs = ‘\n’.join(field_template.format(index=index, name=name) for index, name in enumerate(field_names)) ) # Execute the template string in a temporary namespace and support # tracing utilities by setting a value for frame.f_globals[‘name’] namespace = dict(name='namedtuple%s’ % typename) exec(class_definition, namespace) result = namespace[typename] result._source = class_definition if verbose: print(result._source) # For pickling to work, the module variable needs to be set to the frame # where the named tuple is created. Bypass this step in environments where # sys._getframe is not defined (Jython for example) or sys._getframe is not # defined for arguments greater than 0 (IronPython), or where the user has # specified a particular module. if module is None: try: module = _sys._getframe(1).f_globals.get(‘name’, ‘main’) except (AttributeError, ValueError): pass if module is not None: result.module = module return result
ChainMap
用来合并多个字典。
应用案例
from collections import ChainMap cm = ChainMap( {“Apple”: 18}, {“Orange”: 20}, {“Mango”: 22}, {“pineapple”: 24}, ) print(cm)# ChainMap({‘Apple’: 18}, {‘Orange’: 20}, {‘Mango’: 22}, {‘pineapple’: 24})
源码
class ChainMap(MutableMapping): ‘’’ A ChainMap groups multiple dicts (or other mappings) together to create a single, updateable view. The underlying mappings are stored in a list. That list is public and can be accessed or updated using the maps attribute. There is no other state. Lookups search the underlying mappings successively until a key is found. In contrast, writes, updates, and deletions only operate on the first mapping. ‘’’ def init(self, *maps): ‘’‘Initialize a ChainMap by setting maps to the given mappings. If no mappings are provided, a single empty dictionary is used. ‘’’ self.maps = list(maps) or [{}] # always at least one map def missing(self, key): raise KeyError(key) def getitem(self, key): for mapping in self.maps: try: return mapping[key] # can’t use ‘key in mapping’ with defaultdict except KeyError: pass return self.missing(key) # support subclasses that define missing def get(self, key, default=None): return self[key] if key in self else default def len(self): return len(set().union(*self.maps)) # reuses stored hash values if possible def iter(self): return iter(set().union(*self.maps)) def contains(self, key): return any(key in m for m in self.maps) def bool(self): return any(self.maps) @_recursive_repr() def repr(self): return ‘{0.class.name}({1})’.format( self, ', '.join(map(repr, self.maps))) @classmethod def fromkeys(cls, iterable, *args): ‘Create a ChainMap with a single dict created from the iterable.’ return cls(dict.fromkeys(iterable, *args)) def copy(self): ‘New ChainMap or subclass with a new copy of maps[0] and refs to maps[1:]’ return self.class(self.maps[0].copy(), *self.maps[1:]) copy = copy def new_child(self, m=None): # like Django’s Context.push() ‘’‘New ChainMap with a new map followed by all previous maps. If no map is provided, an empty dict is used. ‘’’ if m is None: m = {} return self.class(m, *self.maps) @property def parents(self): # like Django’s Context.pop() ‘New ChainMap from maps[1:].’ return self.class(*self.maps[1:]) def setitem(self, key, value): self.maps[0][key] = value def delitem(self, key): try: del self.maps[0][key] except KeyError: raise KeyError(‘Key not found in the first mapping: {!r}’.format(key)) def popitem(self): ‘Remove and return an item pair from maps[0]. Raise KeyError is maps[0] is empty.’ try: return self.maps[0].popitem() except KeyError: raise KeyError(‘No keys found in the first mapping.’) def pop(self, key, *args): ‘Remove key from maps[0] and return its value. Raise KeyError if key not in maps[0].’ try: return self.maps[0].pop(key, *args) except KeyError: raise KeyError(‘Key not found in the first mapping: {!r}’.format(key)) def clear(self): ‘Clear maps[0], leaving maps[1:] intact.’ self.maps[0].clear()
UserDict
UserDict是MutableMapping和Mapping的子类,它继承了MutableMapping.update和Mapping.get两个重要的方法 。
应用案例
from collections import UserDictclass DictKeyToStr(UserDict): def missing(self, key): if isinstance(key, str): raise KeyError(key) return self[str(key)] def contains(self, key): return str(key) in self.data def setitem(self, key, item): self.data[str(key)] = item # 该函数可以不实现 ‘’’ def get(self, key, default=None): try: return self[key] except KeyError: return default ‘’’
源码
class UserDict(MutableMapping): # Start by filling-out the abstract methods def init(*args, **kwargs): if not args: raise TypeError("deor ‘init’ of ‘UserDict’ object " “needs an argument”) self, *args = args if len(args) > 1: raise TypeError(‘expected at most 1 arguments, got %d’ % len(args)) if args: dict = args[0] elif ‘dict’ in kwargs: dict = kwargs.pop(‘dict’) import warnings warnings.warn(“Passing ‘dict’ as keyword argument is deprecated”, DeprecationWarning, stacklevel=2) else: dict = None self.data = {} if dict is not None: self.update(dict) if len(kwargs): self.update(kwargs) def len(self): return len(self.data) def getitem(self, key): if key in self.data: return self.data[key] if hasattr(self.class, “missing”): return self.class.missing(self, key) raise KeyError(key) def setitem(self, key, item): self.data[key] = item def delitem(self, key): del self.data[key] def iter(self): return iter(self.data) # Modify contains to work correctly when missing is present def contains(self, key): return key in self.data # Now, add the methods in dicts but not in MutableMapping def repr(self): return repr(self.data) def copy(self): if self.class is UserDict: return UserDict(self.data.copy()) import copy data = self.data try: self.data = {} c = copy.copy(self) finally: self.data = data c.update(self) return c @classmethod def fromkeys(cls, iterable, value=None): d = cls() for key in iterable: d[key] = value return d
No.20 Python中的变量与垃圾回收机制
Python与Java的变量本质上不一样,Python的变量本事是个指针。当Python解释器执行number=1的时候,实际上先在内存中创建一个int对象,然后将number指向这个int对象的内存地址,也就是将number“贴”在int对象上,测试用例如下:
number = [1, 2, 3] demo = number demo.append(4) print(number)# [1, 2, 3, 4]
==和is的区别就是前者判断的值是否相等,后者判断的是对象id值是否相等。
class Person(object): passp_0 = Person() p_1 = Person() print(p_0 is p_1) # Falseprint(p_0 == p_1) # Falseprint(id(p_0)) # 2972754016464print(id(p_1)) # 2972754016408li_a = [1, 2, 3, 4] li_b = [1, 2, 3, 4] print(li_a is li_b) # Falseprint(li_a == li_b) # Trueprint(id(li_a)) # 2972770077064print(id(li_b)) # 2972769996680a = 1b = 1print(a is b) # Trueprint(a == b) # Trueprint(id(a)) # 1842179136print(id(b)) # 1842179136
Python有一个优化机制叫intern,像这种经常使用的小整数、小字符串,在运行时就会创建,并且全局唯一。
Python中的del语句并不等同于C++中的delete,Python中的del是将这个对象的指向删除,当这个对象没有任何指向的时候,Python虚拟机才会删除这个对象。
No.21 Python元类编程
property动态属性
class Home(object): def init(self, age): self.__age = age @property def age(self): return self.__ageif name == ‘main’: home = Home(21) print(home.age) # 21
在Python中,为函数添加@property装饰器可以使得函数像变量一样访问。
__getattr__和__getattribute__函数的使用
__getattr__在查找属性的时候,找不到该属性就会调用这个函数。
class Demo(object): def init(self, user, passwd): self.user = user self.password = passwd def getattr(self, item): return 'Not find Attr.'if name == ‘main’: d = Demo(‘Bob’, ‘123456’) print(d.User)
__getattribute__在调用属性之前会调用该方法。
class Demo(object): def init(self, user, passwd): self.user = user self.password = passwd def getattr(self, item): return ‘Not find Attr.’ def getattribute(self, item): print(‘Hello.’)if name == ‘main’: d = Demo(‘Bob’, ‘123456’) print(d.User)# Hello.# None
属性描述符
在一个类中实现__get__()、__set__()和__delete__()都是属性描述符。
数据属性描述符
import numbersclass IntField(object): def init(self): self.v = 0 def get(self, instance, owner): return self.v def set(self, instance, value): if(not isinstance(value, numbers.Integral)): raise ValueError(“Int value need.”) self.v = value def delete(self, instance): pass
非数据属性描述符
在Python的新式类中,对象属性的访问都会调用__getattribute__()方法,它允许我们在访问对象时自定义访问行为,值得注意的是小心无限递归的发生。__getattriubte__()是所有方法和属性查找的入口,当调用该方法之后会根据一定规则在__dict__中查找相应的属性值或者是对象,如果没有找到就会调用__getattr__()方法,与之对应的__setattr__()和__delattr__()方法分别用来自定义某个属性的赋值行为和用于处理删除属性的行为。描述符的概念在Python 2.2中引进,__get__()、__set__()、__delete__()分别定义取出、设置、删除描述符的值的行为。
- 值得注意的是,只要实现这三种方法中的任何一个都是描述符。
- 仅实现
__get__()方法的叫做非数据描述符,只有在初始化之后才能被读取。 - 同时实现
__get__()和__set__()方法的叫做数据描述符,属性是可读写的。
属性访问的优先规则
对象的属性一般是在__dict__中存储,在Python中,__getattribute__()实现了属性访问的相关规则。
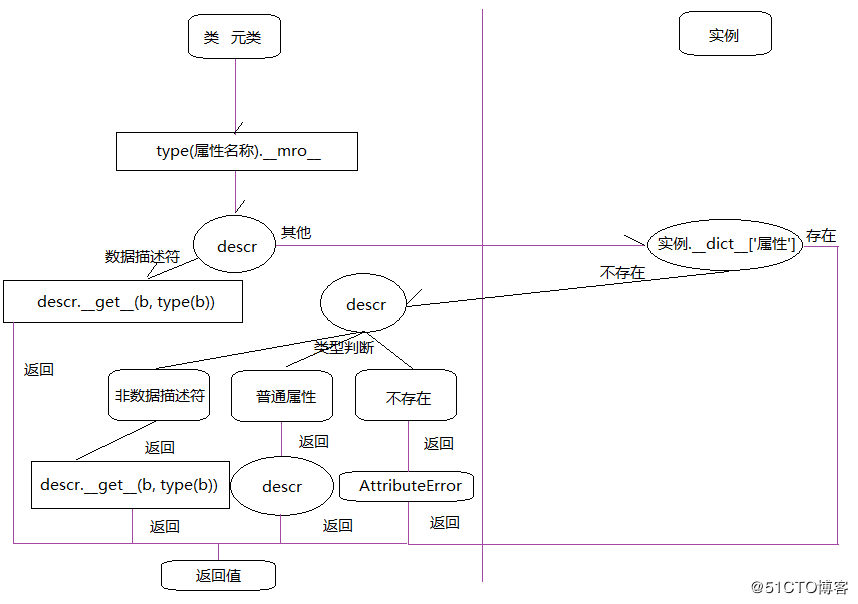
假定存在实例obj,属性number在obj中的查找过程是这样的:
- 搜索基类列表
type(b).__mro__,直到找到该属性,并赋值给descr。 - 判断
descr的类型,如果是数据描述符则调用descr.__get__(b, type(b)),并将结果返回。 - 如果是其他的(非数据描述符、普通属性、没找到的类型)则查找实例
obj的实例属性,也就是obj.__dict__。 - 如果在
obj.__dict__没有找到相关属性,就会重新回到descr的判断上。 - 如果再次判断
descr类型为非数据描述符,就会调用descr.__get__(b, type(b)),并将结果返回,结束执行。 - 如果
descr是普通属性,直接就返回结果。 - 如果第二次没有找到,为空,就会触发
AttributeError异常,并且结束查找。
用流程图表示:
__new__()和__init__()的区别
__new__()函数用来控制对象的生成过程,在对象上生成之前调用。__init__()函数用来对对象进行完善,在对象生成之后调用。- 如果
__new__()函数不返回对象,就不会调用__init__()函数。
自定义元类
在Python中一切皆对象,类用来描述如何生成对象,在Python中类也是对象,原因是它具备创建对象的能力。当Python解释器执行到class语句的时候,就会创建这个所谓类的对象。既然类是个对象,那么就可以动态的创建类。这里我们用到type()函数,下面是此函数的构造函数源码:
def init(cls, what, bases=None, dict=None): # known special case of type.init “”" type(object_or_name, bases, dict) type(object) -> the object’s type type(name, bases, dict) -> a new type # (copied from class doc) “”" pass
由此可知,type()接收一个类的额描述返回一个类。
def bar(): print(“Hello…”) user = type(‘User’, (object, ), { ‘name’: ‘Bob’, ‘age’: 20, ‘bar’: bar, }) user.bar() # Hello…print(user.name, user.age) # Bob 20
元类用来创建类,因为累也是对象。type()之所以可以创建类是由于tyep()就是个元类,Python中所有的类都由它创建。在Python中,我们可以通过一个对象的__class__属性来确定这个对象由哪个类产生,当Python创建一个类的对象的时候,Python将在这个类中查找其__metaclass__属性。如果找到了,就用它创建对象,如果没有找到,就去父类中查找,如果还是没有,就去模块中查找,一路下来还没有找到的话,就用type()创建。创建元类可以使用下面的写法:
class MetaClass(type): def new(cls, *args, **kwargs): return super().new(cls, *args, **kwargs)class User(metaclass=MetaClass): pass
使用元类创建API
元类的主要用途就是创建API,比如Python中的ORM框架。
Python领袖 Tim Peters :
“元类就是深度的魔法,99%的用户应该根本不必为此操心。如果你想搞清楚究竟是否需要用到元类,那么你就不需要它。那些实际用到元类的人都非常清楚地知道他们需要做什么,而且根本不需要解释为什么要用元类。”
No.22 迭代器和生成器
当容器中的元素很多的时候,不可能全部读取到内存,那么就需要一种算法来推算下一个元素,这样就不必创建很大的容器,生成器就是这个作用。
Python中的生成器使用yield返回值,每次调用yield会暂停,因此生成器不会一下子全部执行完成,是当需要结果时才进行计算,当函数执行到yield的时候,会返回值并且保存当前的执行状态,也就是函数被挂起了。我们可以使用next()函数和send()函数恢复生成器,将列表推导式的[]换成()就会变成一个生成器:
my_iter = (x for x in range(10))for i in my_iter: print(i)
值得注意的是,我们一般不会使用next()方法来获取元素,而是使用for循环。当使用while循环时,需要捕获StopIteration异常的产生。
Python虚拟机中有一个栈帧的调用栈,栈帧保存了指定的代码的信息和上下文,每一个栈帧都有自己的数据栈和块栈,由于这些栈帧保存在堆内存中,使得解释器有中断和恢复栈帧的能力:
import inspect frame = Nonedef foo(): global frame frame = inspect.currentframe()def bar(): foo() bar() print(frame.f_code.co_name) # fooprint(frame.f_back.f_code.co_name) # bar
这也是生成器存在的基础。只要我们在任何地方获取生成器对象,都可以开始或暂停生成器,因为栈帧是独立于调用者而存在的,这也是协程的理论基础。
迭代器是一种不同于for循环的访问集合内元素的一种方式,一般用来遍历数据,迭代器提供了一种惰性访问数据的方式。
可以使用for循环的有以下几种类型:
- 集合数据类型
- 生成器,包括生成器和带有
yield的生成器函数
这些可以直接被for循环调用的对象叫做可迭代对象,可以使用isinstance()判断一个对象是否为可Iterable对象。集合数据类型如list、dict、str等是Iterable但不是Iterator,可以通过iter()函数获得一个Iterator对象。send()和next()的区别就在于send()可传递参数给yield()表达式,这时候传递的参数就会作为yield表达式的值,而yield的参数是返回给调用者的值,也就是说send可以强行修改上一个yield表达式值。
-END-
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、机器学习、自动化测试带你从零基础系统性的学好Python!
👉[CSDN大礼包:《python安装工具&全套学习资料》免费分享](安全链接,放心点击)
👉Python学习大礼包👈
👉Python学习路线汇总👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取哈)
👉Python必备开发工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉Python实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉Python书籍和视频合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
👉Python面试刷题👈

👉Python副业兼职路线👈

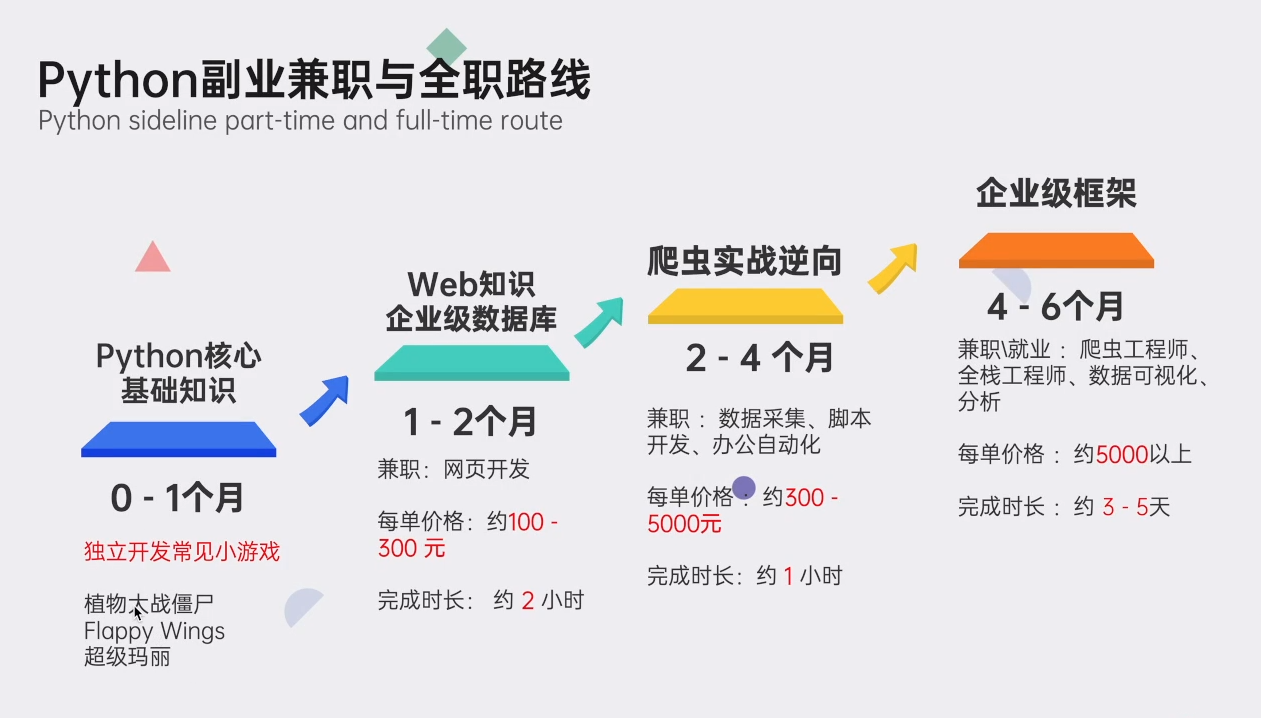
这份完整版的Python全套学习资料已经上传CSDN,朋友们如果需要可以点击链接免费领取或者保存图片到wx扫描二v码免费领取 【保证100%免费】
👉[CSDN大礼包:《python安装工具&全套学习资料》免费分享](安全链接,放心点击)














 3537
3537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









