








文章目录
一、需求背景分析
flink sql在维表关联时,会有一个场景:当右表的数据量比较大且有些数据虽然符合join条件,但其实对于下游来说数据可能没用,这样就浪费了flink的计算资源,且拉低了数据处理能力。如果在join前就把维表的数据进一步过滤,然后再join,这样就会使减轻“无用数据”对flink内存的占用,提高计算能力,进而优化数据处理的能力。
有两个思路可以解决这个问题,
一是将维表在join前先过滤不需要的数据,然后再注册为时态表函数,接着join的维表数据就是“下推后的数据”,但目前flink对于时态表函数join时并不完善,场景覆盖的不够全面。
二是在直接修改源码,给维表一个with参数去过滤数据,在join拉取维表数据时,直接过滤。说起来有点抽象,别急,这就是我们接下来要讨论内容。
二、flink-jdbc-connector源码分析与实现
1. 源码分析
1.1.官网解读
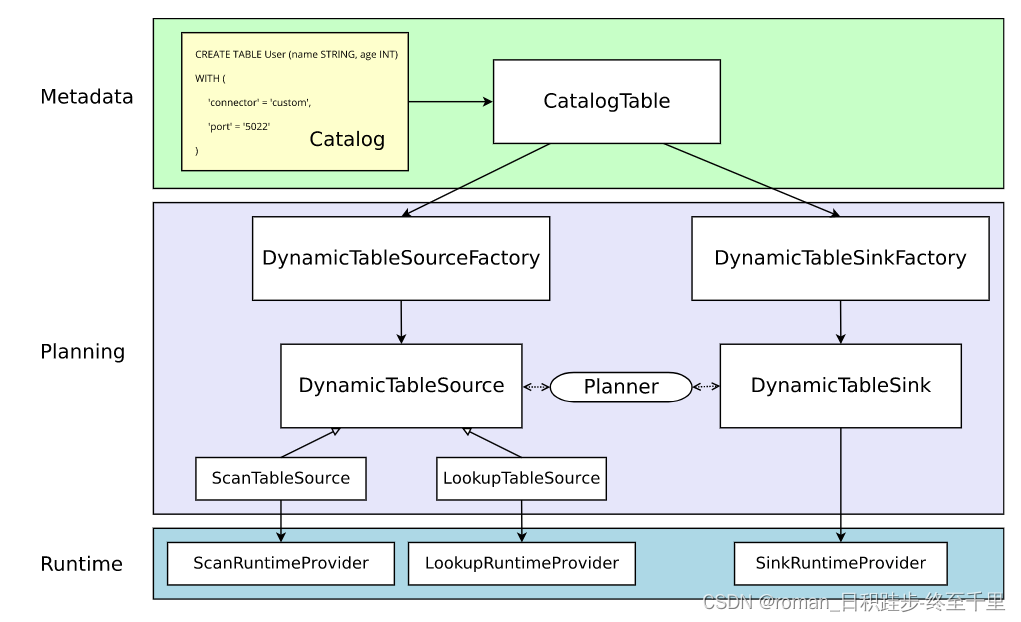
先了解下flink sql在代码层面从一个阶段到其他阶段的翻译过程。
| 阶段 | 解释 |
|---|---|
| 元数据管理 |
执行CREATE TABLE时,会在目标catalog种更新元数据,比如上图黄色的create table语句。语句中with下的参数不会被校验和解释。DDL语句将会被解释成CatalogTable实例。 |
| 生成逻辑计划 | 接下来,当规划和优化一个job下的sql时,CatalogTable实例将会根据sql的语法具体解析为:当读select 语句时,会解析成DynamicTableSource;当读到insert into 语句时,解析成DynamicTableSink。 DynamicTableSource\SinkFactory将会提供具体的解析方法将CatalogTable解析为DynamicTableSource\Sink。具体的,比如说with下的port,Factory会从CatalogTable中校验port是否是连接器支持的参数,然后获取值,并创建参数实例,以便往下个阶段传输。 默认情况下,通过java的SPI机制发现工厂实例,工厂实例要定义一个能被校验的工厂标识符,例如上图:‘connector’ = ‘custom’。 DynamicTableSource\Sink 在运行时将会实际的读写数据。 |
| 运行时 | 当逻辑计划生成时,planner将会获取连接器的实现。运行时核心接口是,InputFormat和SourceFunction,按另一个抽象级别分组为ScanRuntimeProvider、 LookupRuntimeProvider和的子类SinkRuntimeProvider |
通过对官网的解读,
我们知道对于一个flink sql,首先会被维护到catalogTable实例中,catalogTable根据sql类型找到对应的DynamicTable;
这里有一点:create table不会生成DynamicTable,而是select语句会生成DynamicTableSource代表从物理表中拉取数据,insert into语句生成DynamicTableSink代表写入数据到物理表。
在Planning期间,通过with下的connector参数获取对应的工厂,然后通过工厂校验、解析(with下的)参数值(比如’port’=‘5022’)最后封装成参数实例,并传递给runtime的实例;
最后Runtime期间,根据参数实例定义的数据消费规则,开始真正的从物理表中处理(拉取\写入)数据。
1.2 JDBC-connector的解读
通过上面的分析,现在我们通过一个场景分析下,一个job sql是如何在源码中被解析和运行的。
先看一个job下的sql:sql的逻辑是clickhouse join clickhouse 后将数据输出到flink的控制台
CREATE TABLE `in_table` (
`id` BIGINT NOT NULL,
`name` String NOT NULL,
`cloud_wise_proc_time` AS `proctime`()
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:clickhouse://xxx/gaogao?socket_timeout=900000',
'username' = 'default',
'table-name' = 'user'
);
CREATE TABLE `in_table_1` (
`id` BIGINT NOT NULL,
`age` BIGINT NOT NULL,
_cw_insert_time TIMESTAMP(3)
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:clickhouse://xxx/gaogao?socket_timeout=900000',
'username' = 'default',
'table-name' = 'info',
'lookup.cache.max-rows' = '100000',
'lookup.cache.ttl' = '10MINUTE'
);
create table out_table(
`id` BIGINT,
`age` BIGINT,
_cw_insert_time TIMESTAMP(3)
) with (
'connector' = 'print');
insert into out_table
select a.id,b.age,b._cw_insert_time
from in_table as a left join in_table_1 FOR SYSTEM_TIME AS OF a.cloud_wise_proc_time as b on a.id=b.id;
下图展示了在维表关联时维表侧(in_table_1)拉取数据的源码逻辑:
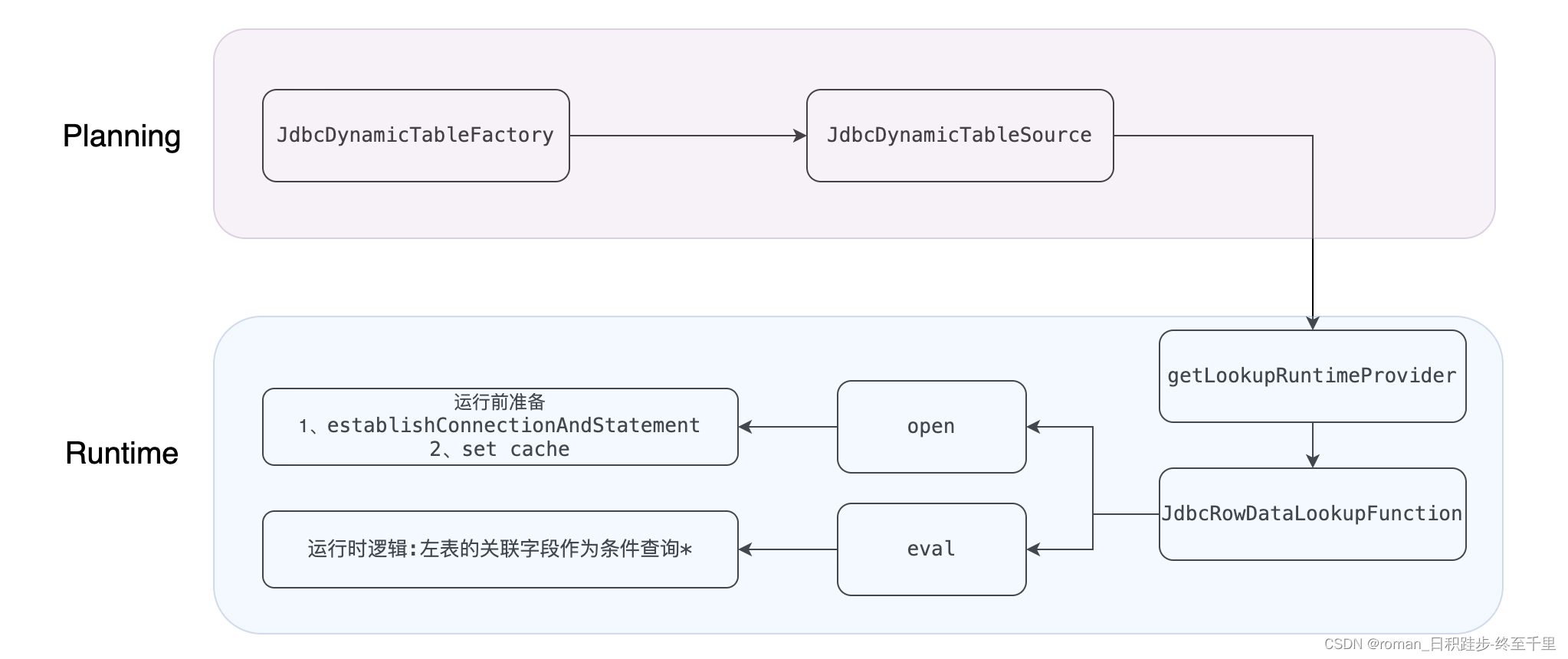
Planning时,
JdbcDynamicTableFactory拿到(in_table_1)CatalogTable实例的参数值(如下),
'connector' = 'jdbc',
'url' = 'jdbc:clickhouse://xxx:18100/gaogao?socket_timeout=900000',
'username' = 'default',
'table-name' = 'info',
'lookup.cache.max-rows' = '100000',
'lookup.cache.ttl' = '10MINUTE'
进行检查和解析,如必要的连接参数(url、username、password、driver、table-name)用于连接clickhouse的那张表;可选的配置(例查询缓存、分区查询),用于拉取数据时的策略,比如单次查询最多拉取10000条数据到缓存中,缓存每10分钟过期一次,以免没有及时查到更新后的数据。
然后生成参数实例,并将参数传递到runtime阶段。
runtime时,
JdbcRowDataLookupFunction主要有两个逻辑,一个是通过planning传递的必要参数,去建立JDBC连接,二是根据查询条件去查询并获取数据。
关键来了:
查询条件是维表关联的关联字段,而值来源于左表。具体的说,当左表通过物理表来查询到一条数据时,这条数据中关联字段对应的数据作为右表查询时的查询条件!!!
当获取到这条消息之后,那谓词下推要实现的逻辑点就引刃而解了,即将谓词下推逻辑放到eval的查询sql中!!!
2. 源码改造
按照planning到runtime的顺序改造:
2.1. planning
添加with参数,即谓词下推参数
JdbcDynamicTableFactory{
...
private static final ConfigOption<String> PRE_FILTER_CONDITION =
ConfigOptions.key("lookup.data.filter")
.stringType()
.defaultValue("")
.withDescription("filter data before dimension table join.");
/**
* 用于可选参数的存储,和检查。
* @return
*/
@Override
public Set<ConfigOption<?>> optionalOptions() {
Set<ConfigOption<?>> optionalOptions = new HashSet<>();
。。。
optionalOptions.add(PRE_FILTER_CONDITION);
return optionalOptions;
}
2.2 Runtime
public class JdbcLookupFunction extends TableFunction<Row> {
。。。
public JdbcLookupFunction(
JdbcOptions options,
JdbcLookupOptions lookupOptions,
String[] fieldNames,
TypeInformation[] fieldTypes,
String[] keyNames) {
。。。
//嵌入下推条件
this.query =
FieldNamedPreparedStatementImpl.parseNamedStatement(
options.getDialect()
.getSelectFromStatement(
options.getTableName(), fieldNames, keyNames, lookupOptions.getPreFilterCondition()), new HashMap<>());
@Internal
public interface JdbcDialect extends Serializable {
。。。
/**
* 维表join查询sql语句
* " SELECT `user_id`, `age` FROM `w` WHERE `user_id` = ? and `age`>3"
*
* @param tableName 表名
* @param selectFields 查询字段
* @param conditionFields 关联字段
* @param preFilterCondition 预过滤条件:一定程度减小查询缓存 例如:age>3,进一步过滤user_id等于某值的数据
* @return
*/
default String getSelectFromStatement(
String tableName, String[] selectFields, String[] conditionFields, String preFilterCondition) {
String selectExpressions =
Arrays.stream(selectFields)
.map(this::quoteIdentifier)
.collect(Collectors.joining(", "));
String fieldExpressions =
Arrays.stream(conditionFields)
.map(f -> format("%s = :%s", quoteIdentifier(f), f))
.collect(Collectors.joining(" AND "));
return "SELECT "
+ selectExpressions
+ " FROM "
+ quoteIdentifier(tableName)
+ (conditionFields.length > 0 ? " WHERE " + fieldExpressions : "")
+ (StringUtils.isNotBlank(preFilterCondition) ? " AND " + preFilterCondition : "");
}
3. SQL验证
CREATE TABLE `in_table` (
`id` BIGINT NOT NULL,
`name` String NOT NULL,
`cloud_wise_proc_time` AS `proctime`()
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:clickhouse://xxx/gaogao?socket_timeout=900000',
'username' = 'default',
'table-name' = 'user'
);
CREATE TABLE `in_table_1` (
`id` BIGINT NOT NULL,
`age` BIGINT NOT NULL,
_cw_insert_time TIMESTAMP(3)
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:clickhouse://xxx/gaogao?socket_timeout=900000',
'username' = 'default',
'table-name' = 'info',
'lookup.cache.max-rows' = '100000',
'lookup.cache.ttl' = '10MINUTE'
'lookup.data.filter'='toInt32(toYYYYMMDD(_partition_day))=20220707',
);
create table out_table(
`id` BIGINT,
`age` BIGINT,
_cw_insert_time TIMESTAMP(3)
) with (
'connector' = 'print');
insert into out_table
select a.id,b.age,b._cw_insert_time
from in_table as a left join in_table_1 FOR SYSTEM_TIME AS OF a.cloud_wise_proc_time as b on a.id=b.id;
此时flink job 在join前,in_table_1会只拉取_partition_day=20220707的数据,实现谓词下推。
参考:
https://nightlies.apache.org/flink/flink-docs-release-1.12/zh/dev/table/sourceSinks.html
















 2642
2642











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











