







文章目录
一. 问题概述
为了支持国产化,hadoop需要安装3.3.1版本,而客户这边需要安全认证,所以对于hadoop需要做的事是升级到3.3.1版本、支持HA模式、安全认证。本文关注hadoop升级和启动过程中出现的401权限问题。
具体地、安装hadoop3.3.1,当格式化完namenode准备同步元数据到另外一个nn节点时报错,即在另外一个namenode节点执行:
hdfs namenode -bootstrapStandby
报错:
...
ERROR [main] org.apache.hadoop.hdfs.server.namenode.NameNode: Failed to start namenode.
java.io.IOException: java.lang.RuntimeException: org.apache.hadoop.hdfs.server.common.HttpGetFailedException: Image transfer servlet at http://XXXXX/imagetransfer?ge
timage=1&txid=0&storageInfo=-65:271209174:1614287921618:CID-f21dbb8a-8660-4ef6-8045-f80daf067c38&bootstrapstandby=true failed with status code 401
Response message:
Authentication required
at org.apache.hadoop.hdfs.server.namenode.ha.BootstrapStandby.run(BootstrapStandby.java:549)
at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1728)
at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1821)
Caused by: java.lang.RuntimeException: org.apache.hadoop.hdfs.server.common.HttpGetFailedException: Image transfer servlet at http://XXXXX/imagetransfer?getimage=1&t
xid=0&storageInfo=-65:271209174:1614287921618:CID-f21dbb8a-8660-4ef6-8045-f80daf067c38&bootstrapstandby=true failed with status code 401
Response message:
Authentication required
at org.apache.hadoop.hdfs.server.namenode.ha.BootstrapStandby$1.run(BootstrapStandby.java:127)
at org.apache.hadoop.hdfs.server.namenode.ha.BootstrapStandby$1.run(BootstrapStandby.java:121)
at org.apache.hadoop.security.SecurityUtil.doAsLoginUserOrFatal(SecurityUtil.java:485)
at org.apache.hadoop.hdfs.server.namenode.ha.BootstrapStandby.run(BootstrapStandby.java:121)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:76)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:90)
at org.apache.hadoop.hdfs.server.namenode.ha.BootstrapStandby.run(BootstrapStandby.java:544)
... 2 more
...
log的基本信息就是:
通过
http://XXXXX/imagetransfer?xxx同步镜像到另外一个namenode时,报401权限错误。
这个问题我们也可以大概了解是因为设置了web console的simple认证,而通过的url没有添加 user.name=xxx 导致报401。
那既然这样,我们就不执行这个命令去同步元数据,直接SCP将数据拷贝到目标节点。
scp -P 36000 -r namenode/* root@ip:/data/appData/hadoop/namenode/
启动两个namenode节点发现报错暂时消失。。。
然而问题很快就又出现了,我停掉namenode然后再启动,发现又报了如下错:
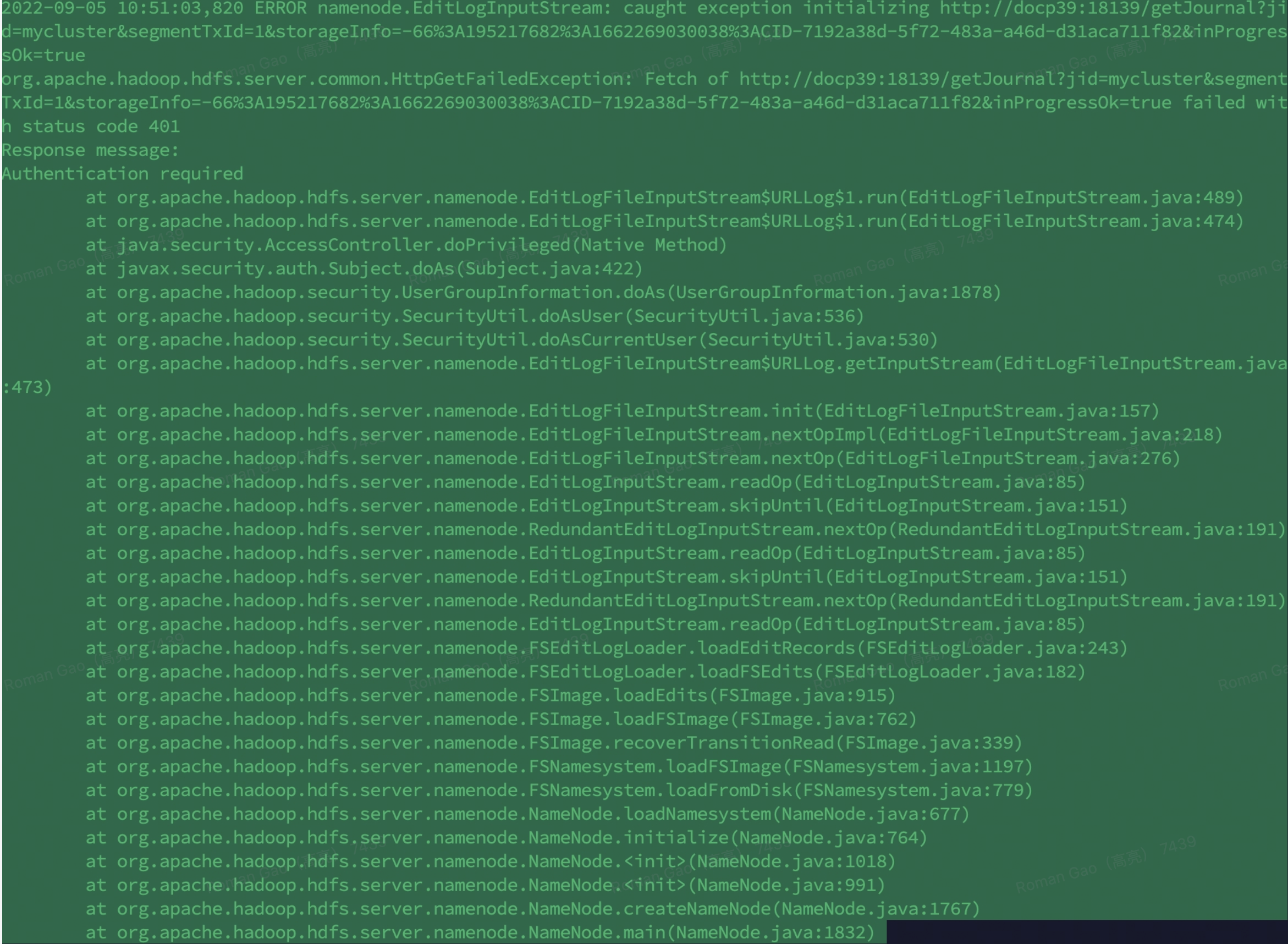
根据堆栈信息可以大概了解到,namenode启动时找journalnode去同步数据报权限的错误,类似的也是通过http请求去同步数据。。。
是官方的bug吗?!
此时可以猜测:hadoop升级到3.3.1后,有关web的请求都需要手动添加认证(user.name=xxx)!!! 直接访问web端还好,可以自己手动添加,但是hadoop内部通讯手动添加认证,实在是无能为力。。。
二. 解决思路
1. 理解hadoop web请求鉴权的逻辑,修改源码 ing
通过观察源码,大概了解到,当hadoop进行web请求时,hadoop会有一个filter进行拦截,然后进行鉴权的检查。
对于我们配置的simple认证,鉴权的方式如下:
public class PseudoAuthenticationHandler implements AuthenticationHandler {
。。。
@Override
public AuthenticationToken authenticate(HttpServletRequest request, HttpServletResponse response)
throws IOException, AuthenticationException {
AuthenticationToken token;
String userName = getUserName(request);
if (userName == null) {
if (getAcceptAnonymous()) {
token = AuthenticationToken.ANONYMOUS;
} else {
response.setStatus(HttpServletResponse.SC_FORBIDDEN);
response.setHeader(WWW_AUTHENTICATE, PSEUDO_AUTH);
token = null;
}
} else {
token = new AuthenticationToken(userName, userName, getType());
}
return token;
}
具体逻辑放到专门一篇来分析ing。
具体实现见,最新文章
【修改源码】修复hadoop 3.3.1 内部通讯权限问题:failed with status code 401 Response message: Authentication required
2. 放弃hadoop官方的安全认证,使用tegine代理
思路大概是:通过自定义端口,当访问此端口时,进行认证,认证通过后再跳转hadoop页面。而对于hadoop内部通讯,其实此时已经没有了认证。
具体实现见:
Hadoop Web 控制台安全认证——使用用户名 + 密码登陆设置方法 (Hadoop HTTP web-控制台认证 )
3. 通过Kerberos认证
大数据常用的认证方式,但自建比较麻烦。
目前做一套Kerberos的认证,需要将hadoop、zookeeper、flink 、kafka等组件都进行配置,而且有一些坑,虽然推荐,但是感觉费力不讨好,使得服务运维成本变高。
4. 降低版本到2.x

















 6182
6182











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











