







 本文讲述了如何为Hadoop Web控制台添加用户名密码验证,从官方配置开始,探讨了使用简单验证的问题,并最终采用Nginx实现BasicAuthentication,以提高访问安全性。
本文讲述了如何为Hadoop Web控制台添加用户名密码验证,从官方配置开始,探讨了使用简单验证的问题,并最终采用Nginx实现BasicAuthentication,以提高访问安全性。
Hadoop HTTP WEB-控制台认证
我们安装完hadoop后,默认情况下我们访问UI界面是没有任何安全验证的。现在我想要的是对Hadoop的Web控制台界面加入一些安全机制,最好是能设置用户名和密码,通过用户名密码的方式来访问我们的Hadoop Web控制台。在做之前,我首先想看看官方有没有类似的这样的功能。下面的文档是官方的 《Hadoop HTTP web-控制台认证》 的说明文档:
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/HttpAuthentication.html
从下面的截图可以看到,有一种方法可以进行设置,那我们就先用这种方式来设置一下,看看效果如何。
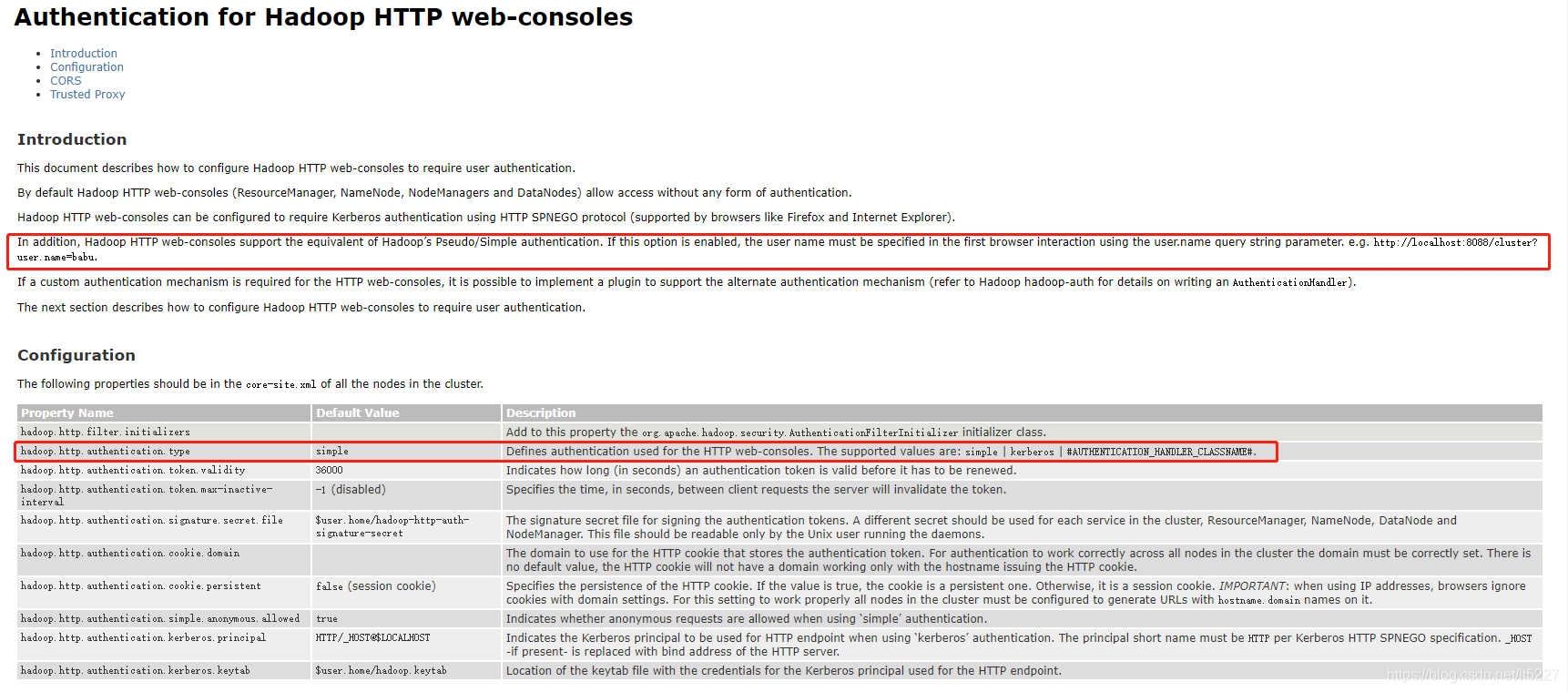
通过上面的文档介绍,以及参考其他博客的方法,我们做下面的配置
Hadoop web页面的授权设定
创建并配置秘钥文件
创建 secret 目录,用于存放密钥文件
mkdir /opt/hadoop/secret
vim /opt/hadoop/secret/hadoop-http-auth-signature-secret

在 hadoop-http-auth-signature-secret 文件当中我写入了 qazwsx$123
配置 core-site.xml
编辑 core-site.xml 文件 vim /opt/hadoop/hadoop-3.3.1/etc/hadoop/core-site.xml,加入下面的配置
<property>
<name>hadoop.http.filter.initializers</name>
<value>org.apache.hadoop.security.AuthenticationFilterInitializer</value>
</property>
<!-- 定义用于HTTP web控制台的身份验证。支持的值是:simple | kerberos | #AUTHENTICATION_HANDLER_CLASSNAME# -->
<property>
<name>hadoop.http.authentication.type</name>
<value>simple</value>
</property>
<!--
签名秘密文件,用于对身份验证令牌进行签名。
对于集群中的每个服务,ResourceManager, NameNode, DataNode和NodeManager,应该使用不同的secret。
这个文件应该只有运行守护进程的Unix用户可以读。
-->
<property>
<name>hadoop.http.authentication.signature.secret.file</name>
<value>/opt/hadoop/secret/hadoop-http-auth-signature-secret</value>
</property>
<!-- 指示在使用“简单”身份验证时是否允许匿名请求。 -->
<property>
<name>hadoop.http.authentication.simple.anonymous.allowed</name>
<value>false</value>
</property>
验证效果
我们重启 hadoop,这里我使用的是单机伪集群,直接运行 stop-dfs.sh 脚本先停止服务,再运行 start-dfs.sh 脚本启动 hadoop 服务,访问我们的web界面看看~。
当我访问web界面,http://127.0.0.1:9870,出现了如下所示的页面:

看起来有效果,按照官方的描述,我们在访问路径后面加user.name参数,值为我们之前设置的值,如:http://127.0.0.1:9870?user.name=qazwsx$123
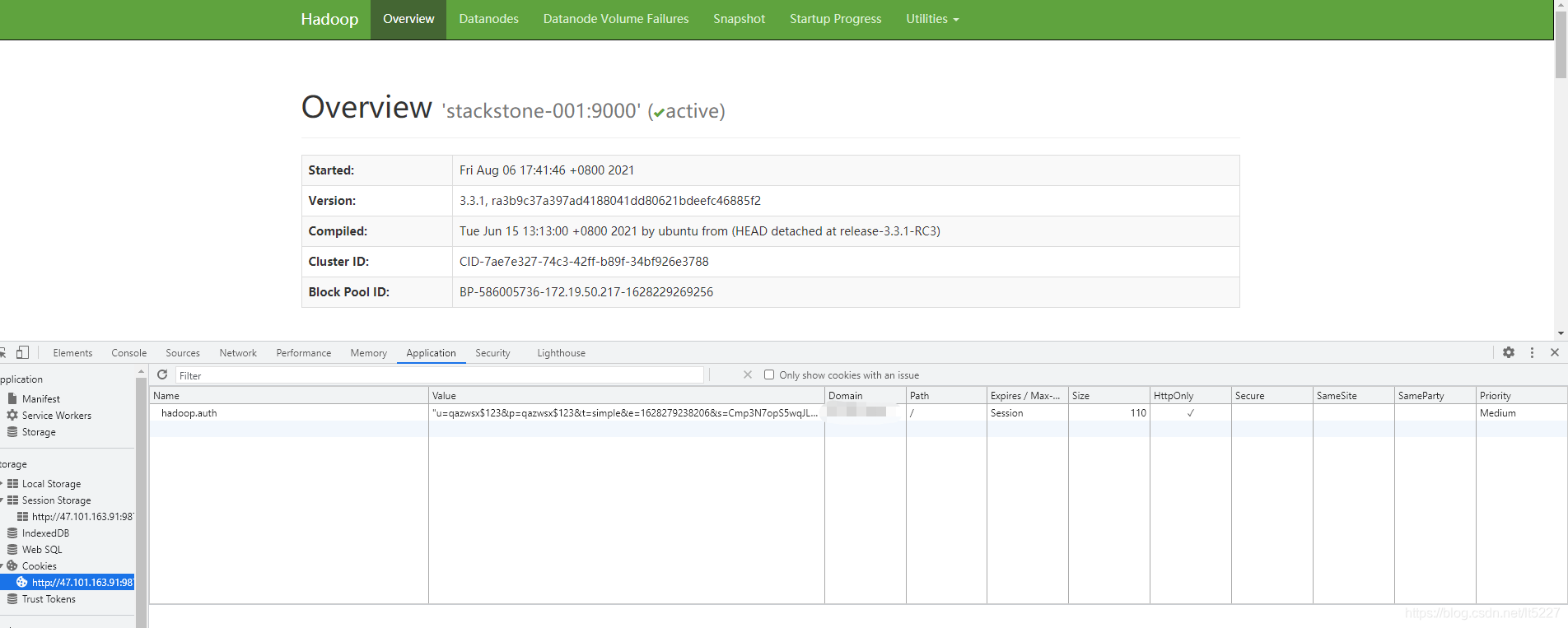
可以看到页面访问成功了~,感觉好像配置好了,可以看到浏览器生成了一个cookie,进一步验证一下是否可行,当我把cookie清除,再次访问。
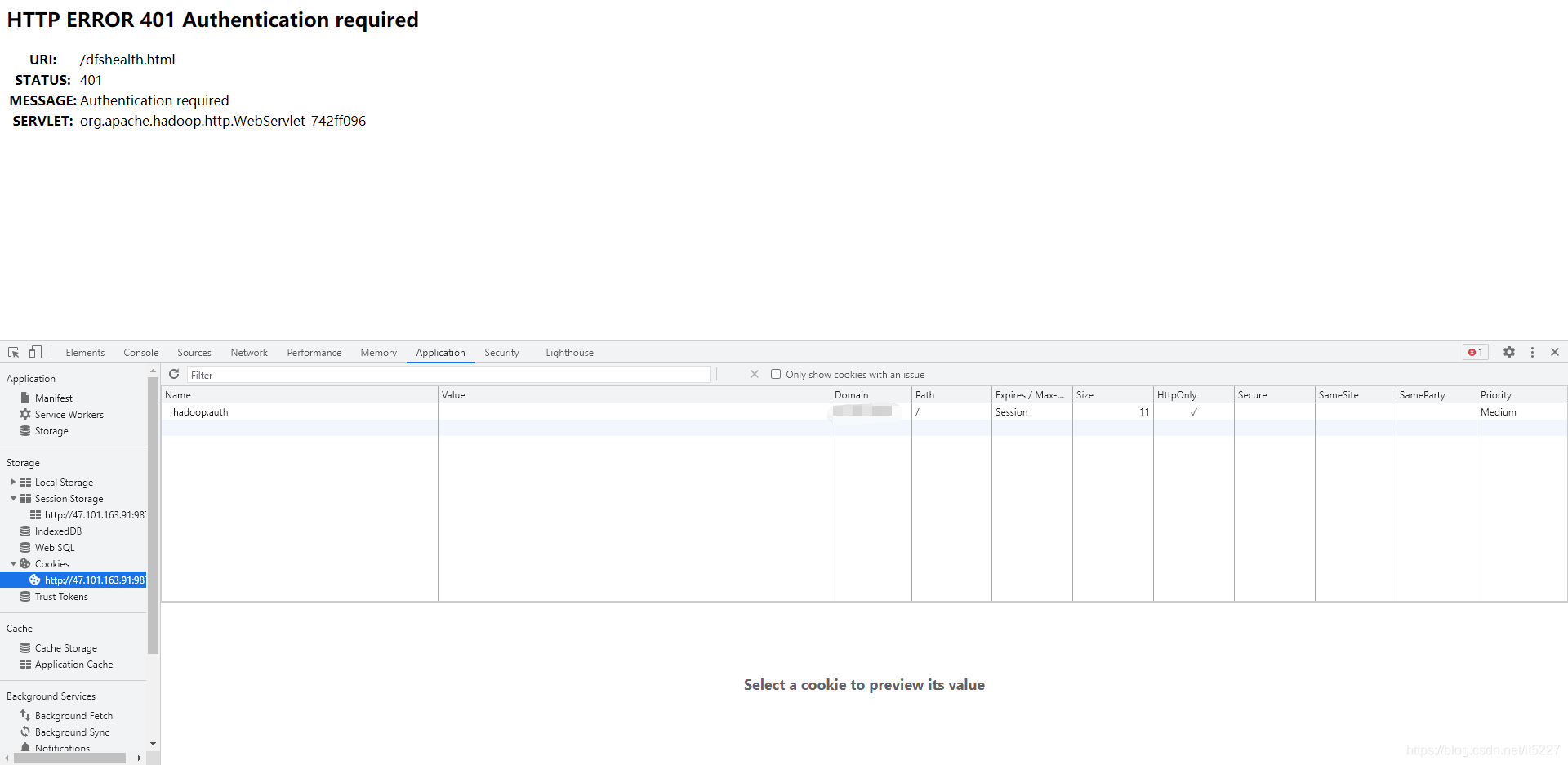
又没访问成功,哪我们再输入其他的user.name值验证一下是否也行呢?
这一次我访问了 http://127.0.0.1:9870?user.name=aaaa,这里的值和我之前设置的 hadoop-http-auth-signature-secret 里面的值不一样,按其他博客说的和我的理解,这时候应该页面访问不了才对,但是这次也居然访问成功了!
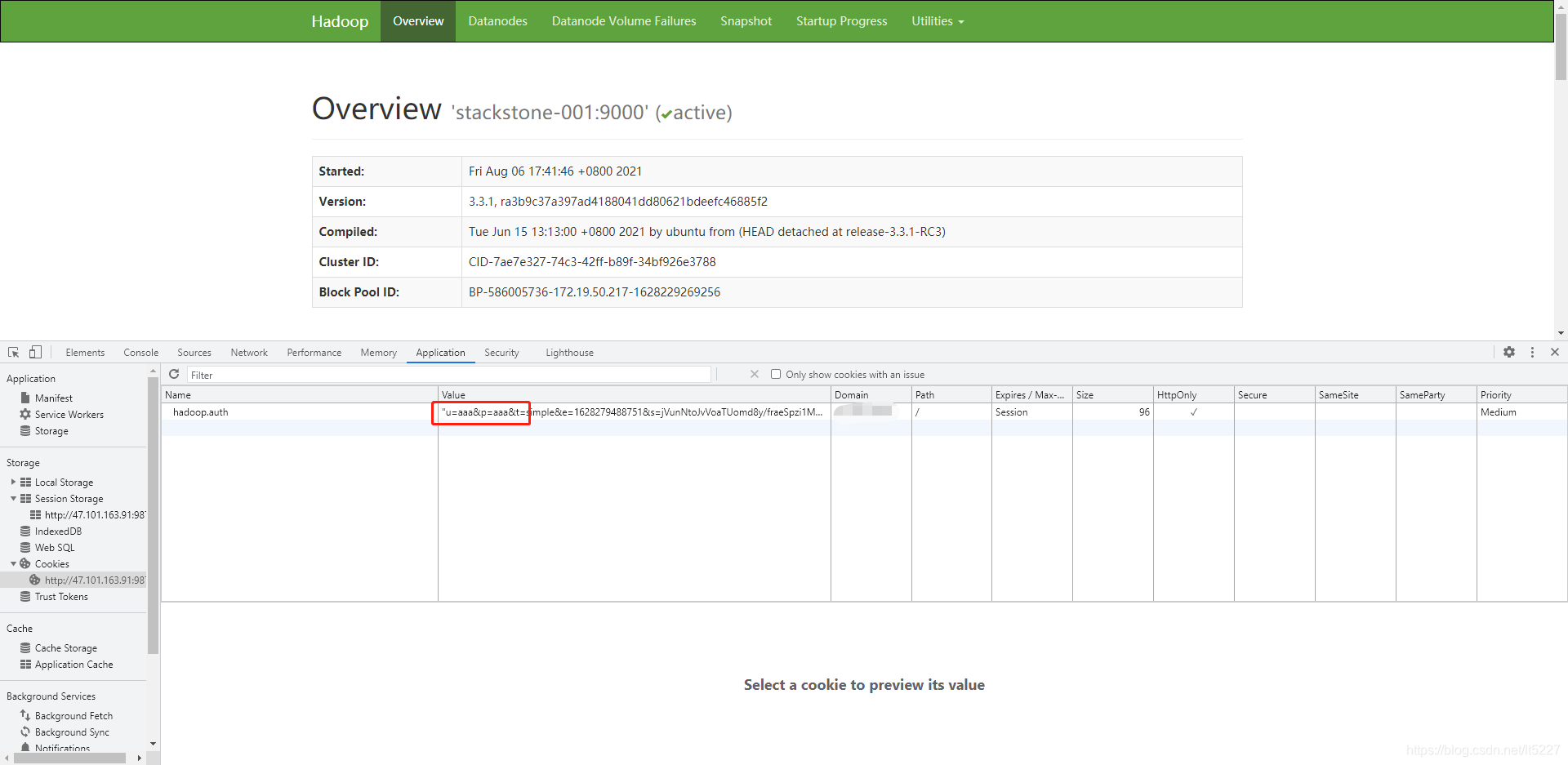
可以看到,这里我输入的是aaa,但是也通过了验证,哪这和我想要的需求不一样啊,这样的话不是每个人直接随便写几个字符都可以查看该页面了!我之后又反复检测多次,更换浏览器尝试,发现根本不行,索性我就放弃了这种配置方法。按照官方所说还有 Kerberos 方法进行安全设置,这里大家可以参考阅读这篇博客:https://www.cnblogs.com/yinzhengjie2020/p/13506913.html
我是觉得 Kerberos 方式太繁琐了索性也没有尝试,当然我也不想修改 Hadoop 的代码来完成这项需求,没办法只能寻找别的替代方案了。这里我就想能不能先把9870端口给先关了,通过反向代理来映射到对该端口地址的访问,通过Nginx来设置Basic Authentication 方式设置用户名密码来进行安全的校验。
通过Nginx 设置对 Hadoop 的 HTTP Basic Authentication 安全访问机制
安装 httpd 或 安装 httpd-tools
要使用 Nginx 服务首先当然要在我们的服务器上安装 Nginx 了,在此之前我们首先要安装 httpd,因为需要htpasswd命令来生成 用户名/密码
可以直接单独安装 htpasswd 安装命令:
yum install httpd-tools -y
安装 httpd 我这里直接通过yum方式进行安装的:yum -y install httpd
这里简单提一下:
启动 httpd 命令:service httpd restart
httpd 的默认安装目录在:/etc/httpd/
关于其配置可以自行查看 /etc/httpd/httpd.conf 文件
如果启动成功后,访问服务器的80端口会出现apache的welcome界面。
安装 Nginx
这里不在赘述Nginx的安装步骤,大家可以直接参考博客:CentOS 安装 Nginx 服务
通过htpasswd命令生成用户名及对应密码数据库文件
运行下面的命令创建密钥文件
# 设置用户名,密码 生成 db文件
htpasswd -c /usr/local/nginx/passwd.db username password
# 查看生成的db文件内容
cat /usr/nginx/conf/htpasswd.users
配置Nginx代理并设置访问身份验证
编辑 nginx.conf 文件,命令如下:
vim /usr/local/nginx/conf/nginx.conf
增加下面的配置信息:
server {
listen 50070;
server_name localhost;
location / {
auth_basic "hadoop001"; # 虚拟主机认证命名
auth_basic_user_file /usr/local/nginx/passwd.db; # 虚拟主机用户名密码认证数据库
proxy_pass http://127.0.0.1:9870; # hadoop 访问
}
}
由于Hadoop3.0.0以上版本访问WebUI默认端口从50070 改为了 9870,所以这里直接通过 50070 来代理到本机的 9870 端口,这时候我们访问一下服务器的50070端口页面
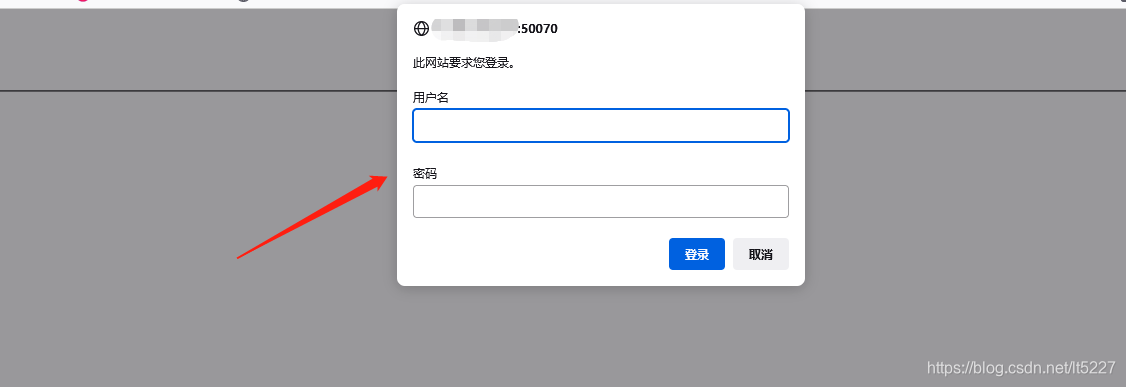
可以看到此时页面提示我们输入用户名和密码,我们把之前设置的用户名密码写上,点击登陆。
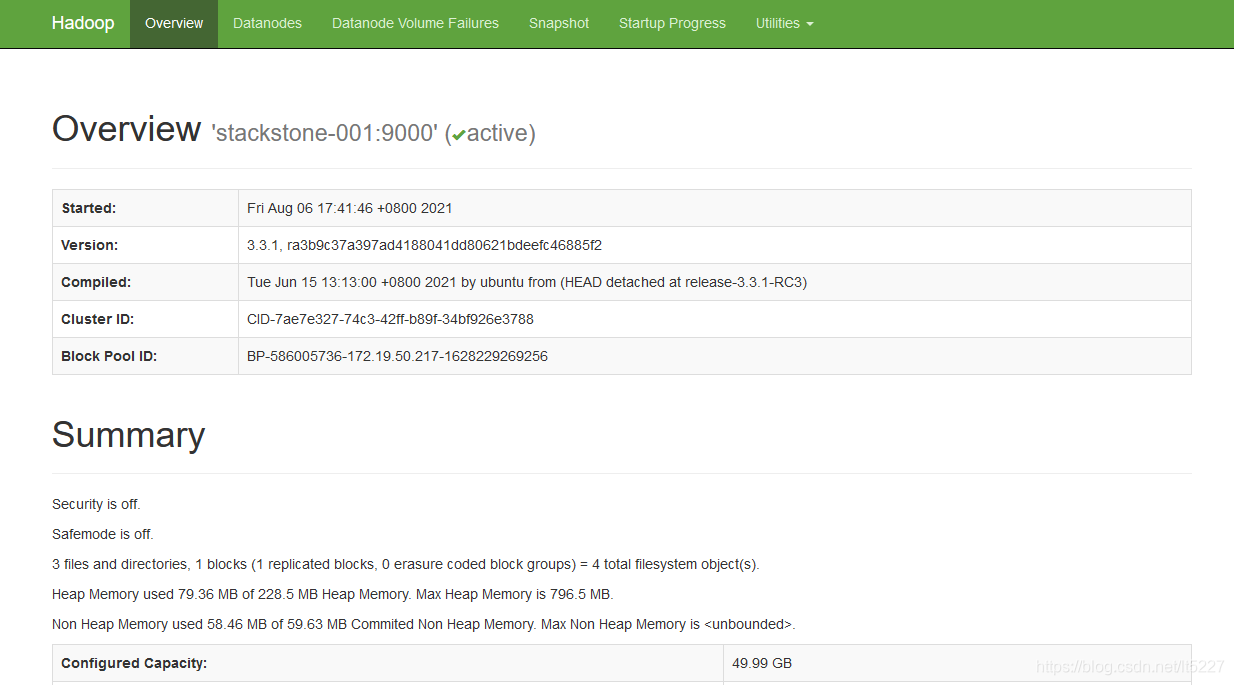
成功进入了我们的UI页面,大功告成,最开始的哪些配置就可以去掉了!
参考文档:
Nginx设置身份验证 https://www.bbsmax.com/A/n2d9bZvVzD/


















 868
868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











