







先思考几个问题:
- 双流join的基本原理是什么?
- 双流join的分类有哪些,具体的实现是什么?
- 双流join产生的问题?回撤的情况以及优化的可能性?
- 多流join数据倾斜与性能优化思路?
- 多流join的可能性?
文章目录
一. 流的join和表的join的区别在哪里
- 左右两边数据是否无穷
- join的结果是否会更新,流join会有回撤的现象
- 流join语义实现的复杂性:双流join左右两边的流速不一致,所以要保存两边的数据到内存中,以保证join语义。
二. 双流Join分类
Join大体分类只有两种:Window Join和Interval Join。
Window Join
又分为:
- Tumbling Window Join
- Sliding Window Join
- Session window Join
Windows类型的join都是利用window的机制,先将数据缓存在Window State中,当窗口触发计算时,执行join操作;
interval join
利用state存储数据再处理,且state中的数据有失效机制,依靠数据触发数据清理;
所以实际开发注意状态的过期时间,免得关联不到数据。
三. interval join 的基本逻辑
看一个例子:
我们知道订单数据(一个订单的概况,没有包含哪些商品明细)和订单明细(哪个商品,这个商品属于哪个订单)数据是一对多(包含)的关系,因为一条订单可能包含多个商品。对于双流(inner)join可以这样考虑:
- 当数据是订单数据到来时,数据的到来均保留到LState中,无论是否关联到明细数据,均留作后续join使用。
- 当数据是明细数据到来时,只要关联到订单数据,数据就可以清除了,否则存储到RState等待join。
- 当同一时段的(左右表)数据都消费且join完时,清空存储状态。
对于flink来说:
不论是INNER JOIN还是OUTER JOIN 都需要对左右两边的流的数据进行保存,JOIN算子会开辟左右两个State进行数据存储,左右两边的数据到来时候,进行如下操作:
- LeftEvent到来存储到LState,RightEvent到来的时候存储到RState;
- LeftEvent会去RightState进行JOIN,并发出所有JOIN之后的Event到下游;
- RightEvent会去LeftState进行JOIN,并发出所有JOIN之后的Event到下游。
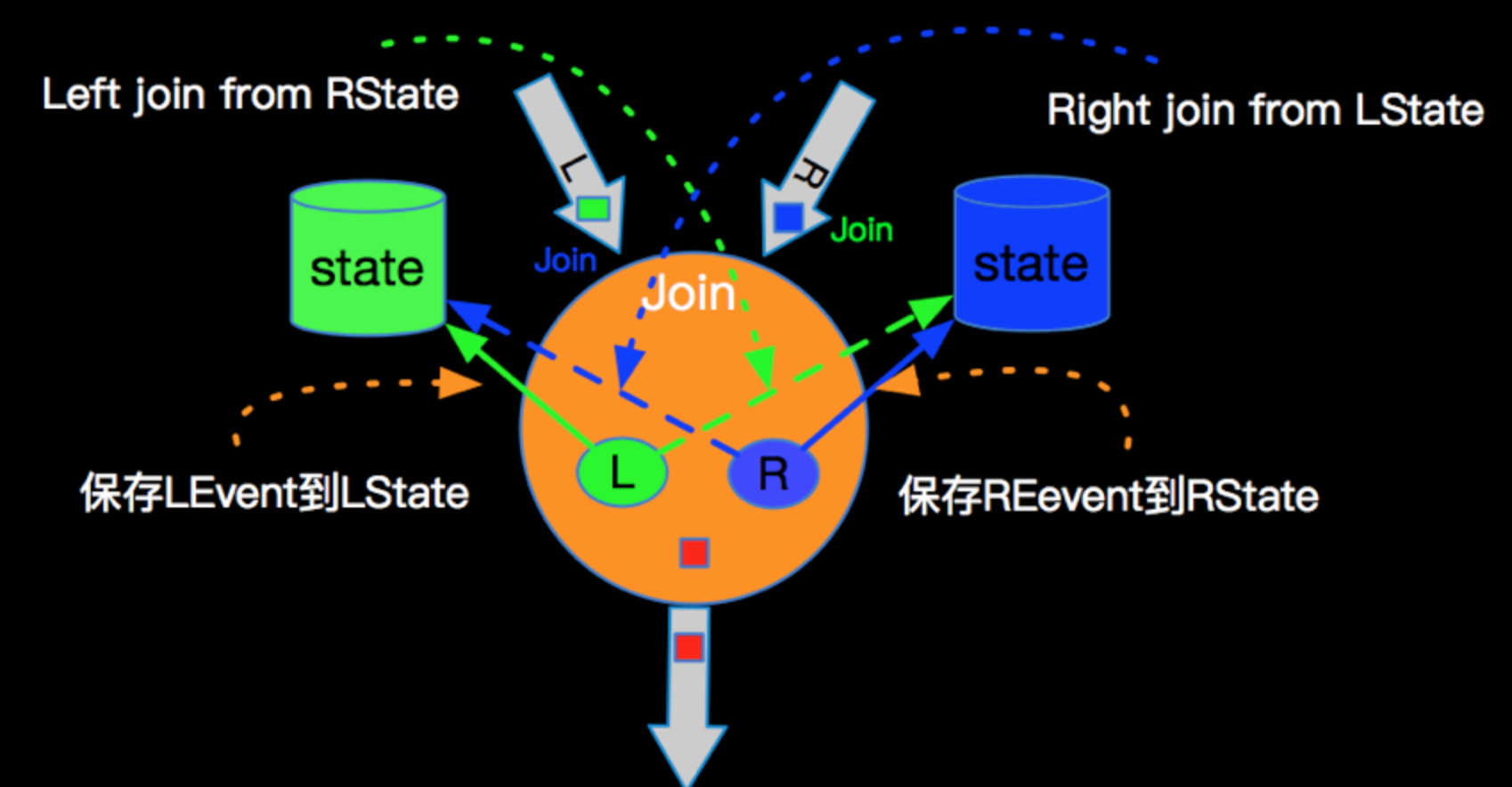
join的结果是数据的笛卡尔积后输出的结果;ing
思考一下:
对于订单的例子,使用flink join之后的相同的订单数据会更新多次,这里涉及到了回撤和幂等操作,那带有相同(join的)id的数据到sink要怎么更新?等会儿讨论。
1. inner join的逻辑
inner join的一个例子,如下图:
- 左右两个流的流入的数据都会一直存储到state里面;
- 数据是按照如图标号的顺序流入,看到右边的流先流入了三个事件,但左边没有事件,先存入RState;
- 当左边4事件流入时,先存储到LState,然后和RState的三个事件join(如图4事件的join result),三行结果流到下游;
- 当右边5事件流入时,先存储到RState,然后和LState进行join(如图5事件的join result),然后输出到下游;
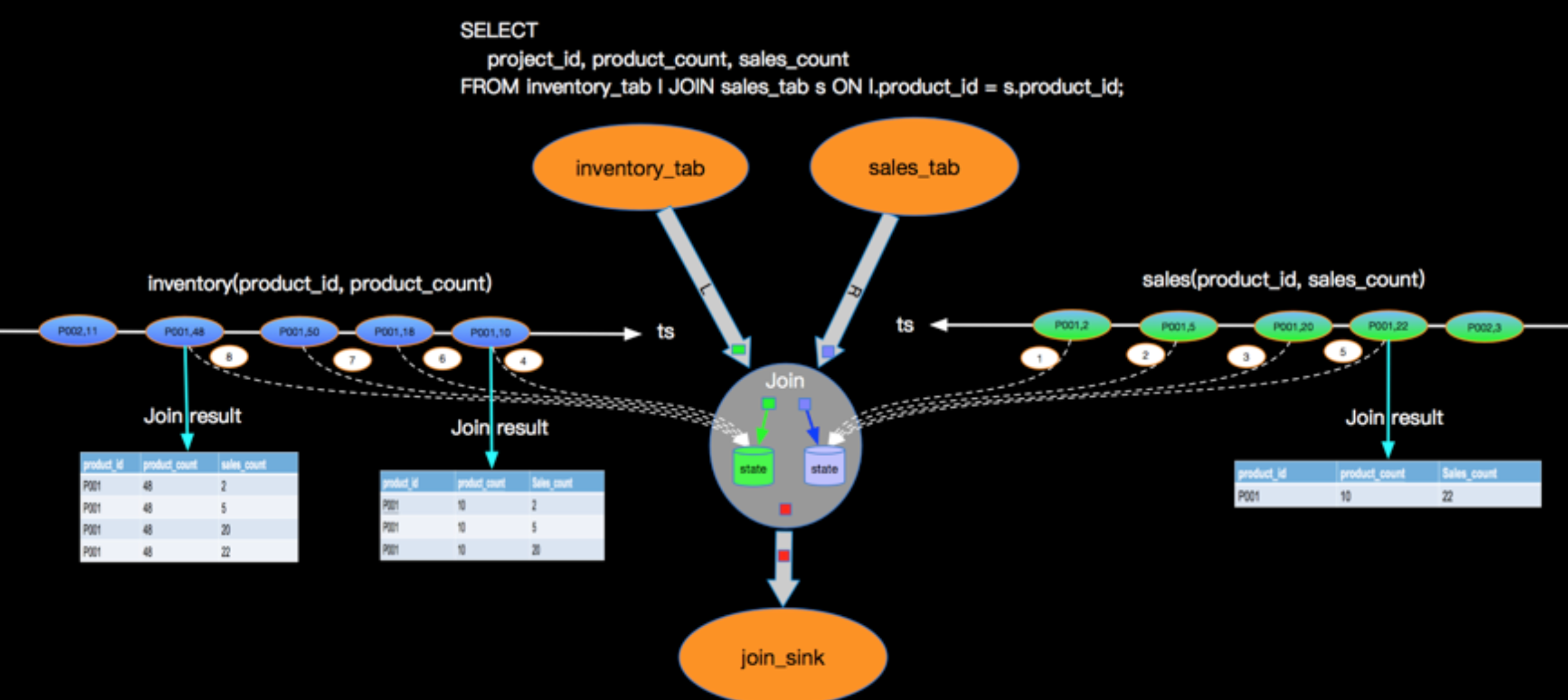
inner join的语义
只有join上数据才会流出到下游
因为保存了两个流所有的事件到state中,所以不管数据是如何乱序,都能保证和传统数据库一样的join语义。
2. left outer join 的逻辑与回撤
首先:和inner join 相比 left join 不管右流是否进行了join,左流的数据都需要流入下游节点。
看一个场景:
查询产品库存和订单数量,库存变化事件流和订单事件流进行LEFT JOIN,JION条件是产品ID,具体如下图:
- 其中数字代表数据的流入顺序:看到左流的数据首先到达了计算任务,不管右流是否有数据,直接输出“+P001,10,null”,其中左流的数据一致维护在state中;
- (左流)事件2接着流入,然后直接输出,(右流)事件3流入,看到LState中有能join上的数据,因为是第一个join(仅有第一条数据会撤回?ing),需要撤回(做一个标记其实是?)左边下发的“+P001,10,null”数据,之后下发join后的数据到下游;
- 后续到来的4,5,6,8等待后续P001的事件是不会产生撤回记录的。
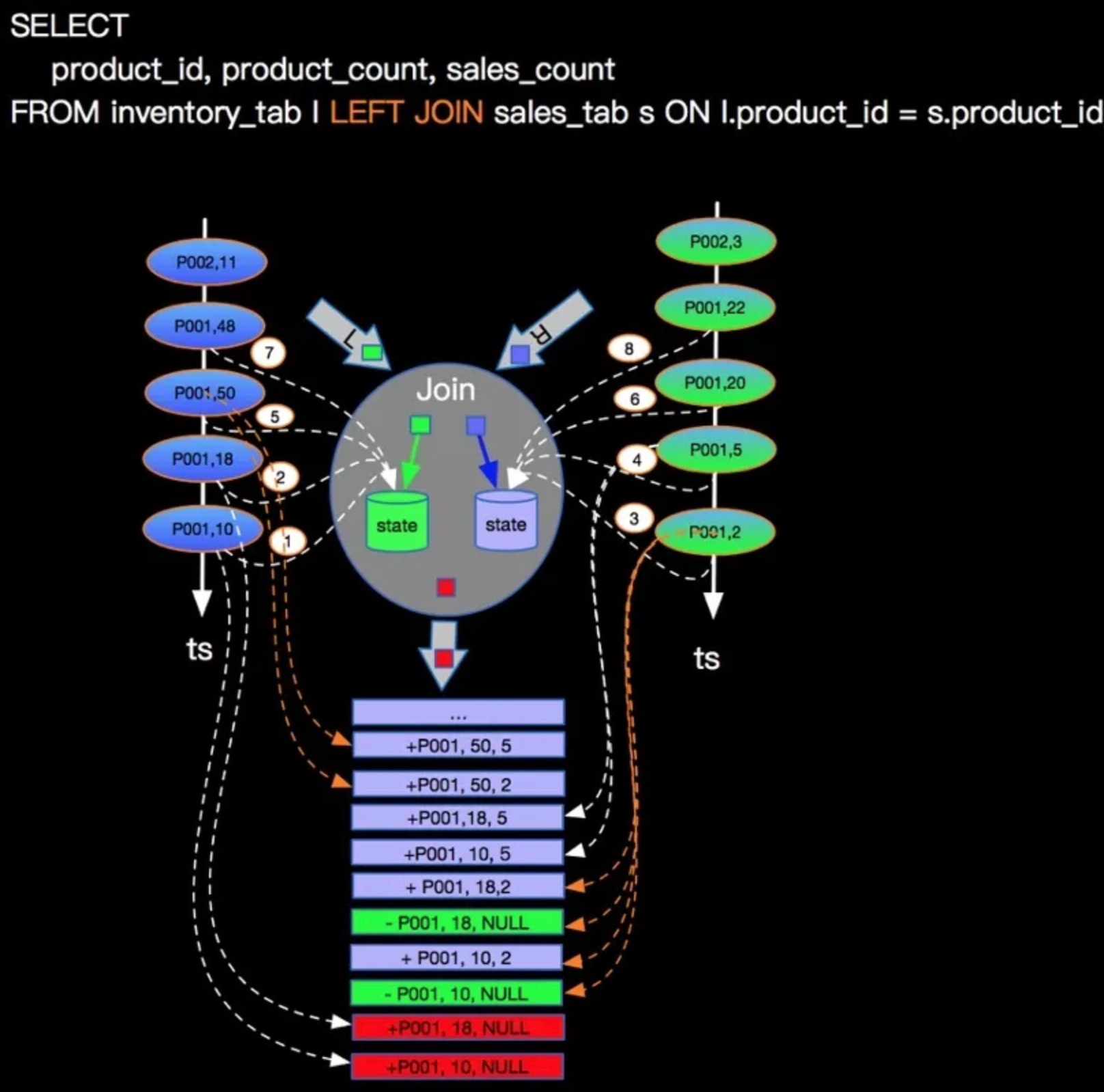
注意:在Apache Flink系统内部事件类型分为正向事件标记为“+”和撤回事件标记为“-”*
四. Interval Join问题讨论
1. state内存过大的问题 ing
对于left 和 inner join有一个问题我们可以思考下:
因为保存了所有事件的state,所以当数据量很大时,是否容易出现OOM,还是有什么机制触发内存的清理。
2. 数据Shuffle怎么保证join实现
分布式流计算所有数据会进行Shuffle,怎么才能保障左右两边流的要JOIN的数据会在相同的节点进行处理呢?
在双流JOIN的场景,我们会利用JOIN中ON的联接key进行partition,确保两个流相同的联接key会在同一个节点处理,这个在flink的源码中有说明。
3. 回撤的优化的一些想法
产生回撤信息最根本的一个原因是不断地向下游多次发送更新结果,因此,为了减少更新的频率并降低并发,可以把更新结果累计一部分之后再发送出去。如上图所示:
第一个场景是一个嵌套 AGG 的场景(例如两次 Count操作),在第一层 Group By 尝试将更新结果发送到下游时候会先做一个 Cache,从而减少向下游发送数据频率。当达到了 Cache 的触发条件时,再把更新结果发送到下游。
第二个场景是 Outer Join,前面提到,Outer Join 产生回撤消息是因为左右两边数据的速率不匹配。以 Left Outer Join 为例,可以把左流的数据进行 Cache。左流数据到达时会去右流的状态里面查找,如果能找到可以与之 Join的数据则不作缓存(redis等?);如果找不到相应数据,则对这条 Key 的数据先做缓存,当到达某些触发条件时,再去右流状态中查找一次,如果仍然找不到相应数据,再去向下游发送一条包含 Null 值的 Join 数据,之后右流相应数据到达就会将 Cache 中该 Key 对应的缓存清空,并向下游发送一条回撤消息。
4. sink节点对于回撤现象的处理
对于 Sink 节点,目前 Flink 中有三种 sink 类型,AppendStreamTableSink、RetractStreamTableSink 和 UpsertStreamTableSink。
- AppendStreamTableSink:接收的上游数据是一条 Retract 信息的话会直接报错的,因为它只能描述 Append-Only 语义;
- RetractStreamTableSink:如果上游算子发送一个 Retract 信息过来,它会对消息做 Delete操作,如果上游算子发送的是正常的更新信息,它会对消息做 Insert 操作;
- UpsertStreamTableSink:可以理解为对于RetractStreamTableSink 做了一些性能的优化。如果 Sink 数据源支持幂等操作,或者支持按照某 key 做 Update 操作,UpsertStreamTableSink 会在 SQL 翻译的时候把上游 Upsert Key 传到 Table Sink 里面,然后基于该 Key 去做 Update 操作。这样输出的多条相同key的数据就可以更新为一条。

















 953
953

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











