








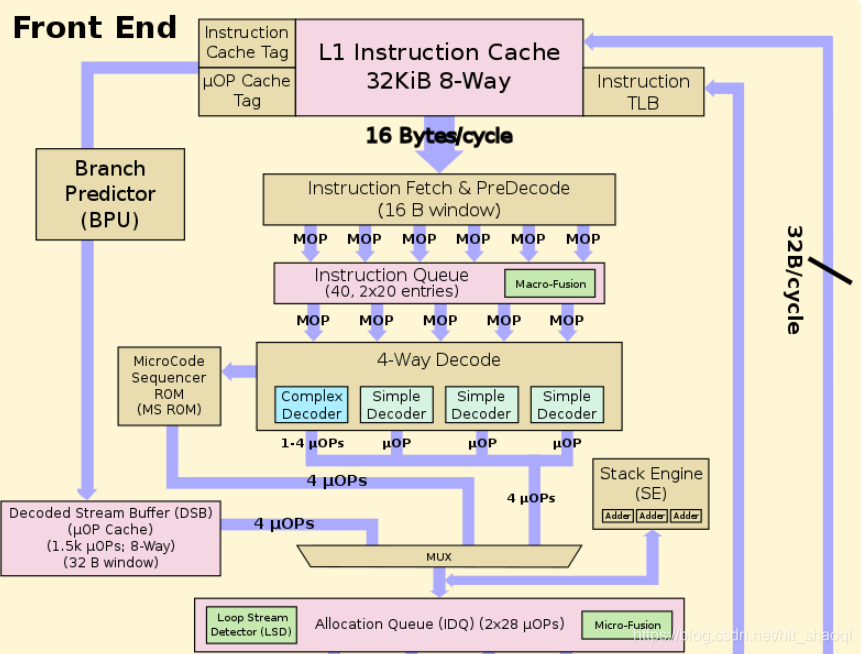
MSROM & Stack Engine
在X86指令中,有一些连复杂解码器都认为复杂的指令。这些指令会被翻译成超过4条uops,它们是从microcode sequencer(MS) ROM 绕道译码的。此时,MSROM每周期会发射超过4条指令,直到microcode sequencer完成了工作。在此期间,译码器停止工作。
x86有这一个专门的stack machine 操作。像push,pop和call,ret这样的指令,是工作在stack pointer(ESP)上的。如果没有这样专门的硬件,这样的指令操作将会被发送到后端的执行单元,使用通用的ALU计算,占用了带宽以及调度器和发射单元的资源。自从Pentium M之后,Intel就采纳了Stack Engine的技术。Stack Engine 有这一组三个专门的累加器,用于实现更新栈的指令(可以每周期进行3次加法)。像push这样的指令翻译成store指令和将ESP-4的指令。此时的减法操作将会被Stack Engine完成。Stack Engine位于decoders的后面,监视uOps指令流。Stack Engine 将会抓住输入的更新栈寄存器的操作。这可以更新栈指针的uops造成的流水线的负担。换句话说,这相对于将这些操作放入流水线并通过执行单元计算,更加简单更加快速。
New uOp cache & x86 tax
译码变长,不连续并且复杂的x86指令是一个复杂的工作。考虑性能和功耗,译码的代价也是非常昂贵的。因此,对流水线来说,最好就是不进行译码了,这恰恰就是Intel向Sandy Bridge中加入的最重要的功能。Sandy Bridge 引入了一个新的new uOp Cache 单元,可能更准确的应该叫做 Decode Stream Buffer(DSB)。micro-op cache的独特在于其不仅可以大幅度的提高性能,也可以大幅的的降低功耗。
表面看来,uOP cache 被定位为一个2级指令cache单元,是1级指令cache单元的子集。其独特之处在于它所存储的是译码之后的指令(uOPs)。尽管它与NetBurst的trace cache的大部分目标相同,二者的实现确实完全不同。考虑到它是如何增强了其余的前端的功能,这点显得尤为真实。两者机制背后的思想都是增加前端的带宽,并降低对译码器的依赖。
Micro-op cache是由32组 8条cacheline 组成。每条cacheline最多保留6条uops,共计1536条uOps。这个Cache是在两个线程之间共享的,并保留了指向micro sequencer ROM的指针。它也是虚拟地址寻址,是L1 指令cache的严格的子集。每条cacheline还包括其包含的uop数量和其长度。
在任何时间,core都是处理来自instruction stream的连续的32byte。同样的,uOP cache也是基于32byte窗口。因此uOP cache可以基于LRU策略存储或者放弃整个窗口。Intel将传统的流水线成为“legacy decode pipeline”。在首次迭代时,所有的指令都是经过“legacy decode pipeline”。一旦整个指令流窗口被译码并且发送到分配队列,窗口的拷贝就被发送到uOP cache。这是与所有其他操作同时发生的,因此这个功能没有增加额外的流水线阶段。后续的迭代,被缓存的已经解码好的指令流就可以直接被发送到分配队列了,省却了取指,预译码,和译码的阶段,节省功耗,增加了吞吐量。这也是一个更短的流水线,latency也被减小了。
注意32byte的指令流窗口只能扩展到3条cacheline。这意味着每个窗口最多有18条uops被uop cache缓存。这个也就意味着一个32byte的窗口如果产生了超过18条uops,那么就不会被分配到uOP cache中。将会不得不进入“legacy decode pipeline”。然而。这样的场景是非常少见的,大多数的workload都可以从这个特性中受益。
uOP cache有着高于80%的命中率。在取指期间,分支预测器将会读取uOPs cache 的tags。如果命中了cache,会可以每周期发送至多4条uops(可能包含了fused macro-ops)到 Instruction Decode Queue(IDQ), bypass了其他所有本该进行的预译码和译码。在其他周期内,其余的前端完全被clock gated,因此降低了大量的功耗。尽管 legacy decode path工作在16byte取指窗口内,uOP cache没有这样的限制,可以发送最多4uOPs/cycle,对应着超过32byte的窗口。考虑到单个窗口可能包含18条uOPs,可能要花费5个周期才能读完整条已经解码完毕的指令流。尽管如此,uOPs cache可以提供连续的高带宽的指令流。然而,legacy decode pipeline,被限制在16byte 取指窗口内,如果平均指令长度超过4byte,那么将会是一个严重的瓶颈(无法达到4uop,无法使后端满负荷工作)。
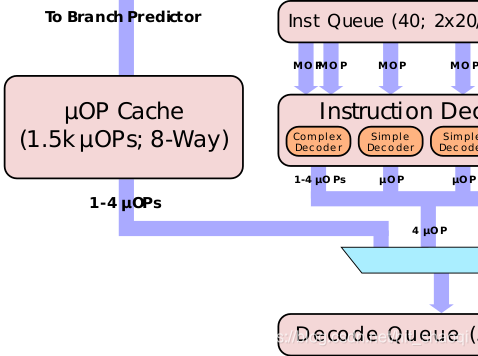
有趣的是uOPs cache只工作在满窗口下,也就是整个32B的窗口的所有uOPs都被cache了。如果只是任何单部分的命中,那么仍然需要通过“legacy decode pipeline”,仿佛没有被cache过。不处理部分命中的选择根植于特性效率。如果只是部分命中,输出部分译码过的指令,那么其余的指令还需要经过“legacy decode pipeline”。这样的机制不仅会增加复杂性,而且并不清楚可以获益多少。
如前所述,uOPs cache根植于原始的NetBurst trace cache,尤其是考虑到它们相同的目标。但是它们也仅仅是目标相同。Sandy Bridge 中的micro-op cache 是一个轻量级的,有效地uOPs传递机制,可以在任何可能的时候都超过legacy pipeline的性能。这与trace cache不同,trace cache试图有效地去取代整个前端,在trace cache不能处理的workload的情况下,表现较差,取指和译码都比较缓慢。考虑到trace cache代价巨大而且复杂(有着专门的 trace BTB单元),并且在上下文切换时,需要进行flush,而有着副作用。uOP cache则没有这个缺点。trace cache也有着大量不必要的重复。比如NetBurst的trace cache多大12K uops,与 8KB-16KB的L1 cache的命中率接近。然而1.5K uOPs的命中率接近6KB 指令cache。这意味着存储效率要提高了超过4倍。
欢迎关注我的公众号《处理器与AI芯片》


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









