









一、DNN的时序预测与缺陷
序列依赖捕获能力有限
传统的全连接DNN(如多层感知机,MLP)在处理时间序列时,难以有效捕获前后序列中的长距离依赖。这是因为DNN本身没有显式设计用来处理顺序信息的机制,序列中的长时依赖容易被“遗忘”。
模型难以捕获复杂的时序关系
时间序列数据常带有非线性、动态变化和多尺度特性,而普通DNN的表达能力和拟合能力有限,需要网络架构的深层设计或者加入其他机制(如注意力机制)才能改善。
对长序列的数据不足和样本效率低
深度学习模型通常需要大量数据来实现良好的泛化性能,尤其是复杂的时序数据。缺乏充分数据时,模型容易出现过拟合或无法有效学习序列的潜在特征。
序列的非平稳性和噪声影响
很多时间序列具有非平稳性(如季节性、趋势性变化)以及噪声干扰,普通DNN难以区分信号与噪声,导致预测性能下降。
训练难度与计算成本高
深度神经网络的训练涉及复杂的参数优化过程,对硬件资源和时间成本要求高。特别是在实时预测场景中,延迟可能成为瓶颈。
泛化能力及迁移学习受限
被训练的模型在特定时间段或环境下表现良好,但面对环境变化、数据漂移时,性能可能迅速下降。迁移学习的效果也有限,需重新训练模型。
缺乏可解释性
深度模型的“黑箱”特性使得其预测过程难以解释,在某些关键应用(如金融、医疗)中,缺乏可解释性限制了其应用拓展。
模型的稳定性和鲁棒性不足
对极端异常值或突发事件的鲁棒性不足,可能导致模型输出不稳定或误判。
二、NLP介绍
自然语言处理(Natural Language Processing,NLP)是人工智能领域的一个分支,专注于使计算机能够理解、分析和生成人类自然语言的文本或语音数据。
NLP致力于构建能够处理自然语言的智能系统,使计算机能够与人类进行自然而流畅的交流,而不仅仅是执行预定义的任务。以下是关于NLP的一些关键概念和应用:
1. 文本分析:NLP技术可用于文本分析,包括文本分类、情感分析、主题建模和实体识别。文本分类涉及将文本分为不同的类别,情感分析用于识别文本中的情感或情感倾向,主题建模用于发现文本数据中的主题,而实体识别则是识别文本中的具体实体,如人名、地名和日期。
2. 语言生成:NLP可以用于生成自然语言文本,包括自动摘要生成、机器翻译和对话系统。这些任务要求计算机生成与人类语言类似的文本,可以帮助自动化生成摘要、翻译文本,或实现自动对话。
3. 机器翻译:NLP技术被广泛用于机器翻译,即将一种语言的文本翻译成另一种语言。这包括基于统计方法或神经网络的机器翻译系统。
4. 对话系统:对话系统(Chatbots)是NLP应用的一部分,它们被用于模拟人类对话。这些系统可以用于在线客服、虚拟助手和智能聊天机器人。
5. 自然语言理解:NLP还包括自然语言理解(Natural Language Understanding,NLU),用于将文本数据转化为计算机可理解的结构化信息。NLU可以帮助计算机理解用户的意图,从而执行相应的操作。
6. 信息检索:NLP技术用于信息检索,帮助用户通过搜索引擎找到相关的文档、网页或信息。关键词提取、文档检索和排名是信息检索的关键组成部分,例如B站很多视频中评论区的AI助理,提取时间线和主要内容。
7. 情感分析:情感分析是NLP中的一个重要任务,用于确定文本中的情感极性,例如正面、负面或中性情感。它在社交媒体监测、市场调研和舆情分析方面具有广泛的应用,例如某件商品的评论提取商品的。
NLP的发展在人工智能领域引发了广泛的兴趣和研究,以改善计算机在处理自然语言方面的能力,使其在文本理解、生成和对话方面取得更大的进展。深度学习技术,特别是循环神经网络(RNN)和变换器(Transformer)架构,已经在NLP任务中取得了显著的成功,推动了自然语言处理的发展。
三、基于DNN的时序预测
3.1、数据操作
import numpy as np
import torch
import torch.nn as nn
# 原始文本
text = "hey how are you"
# 初始化输入和输出序列的列表
input_seq = []
output_seq = []
# 定义滑动窗口大小
windows = 5
# 构建输入和输出序列
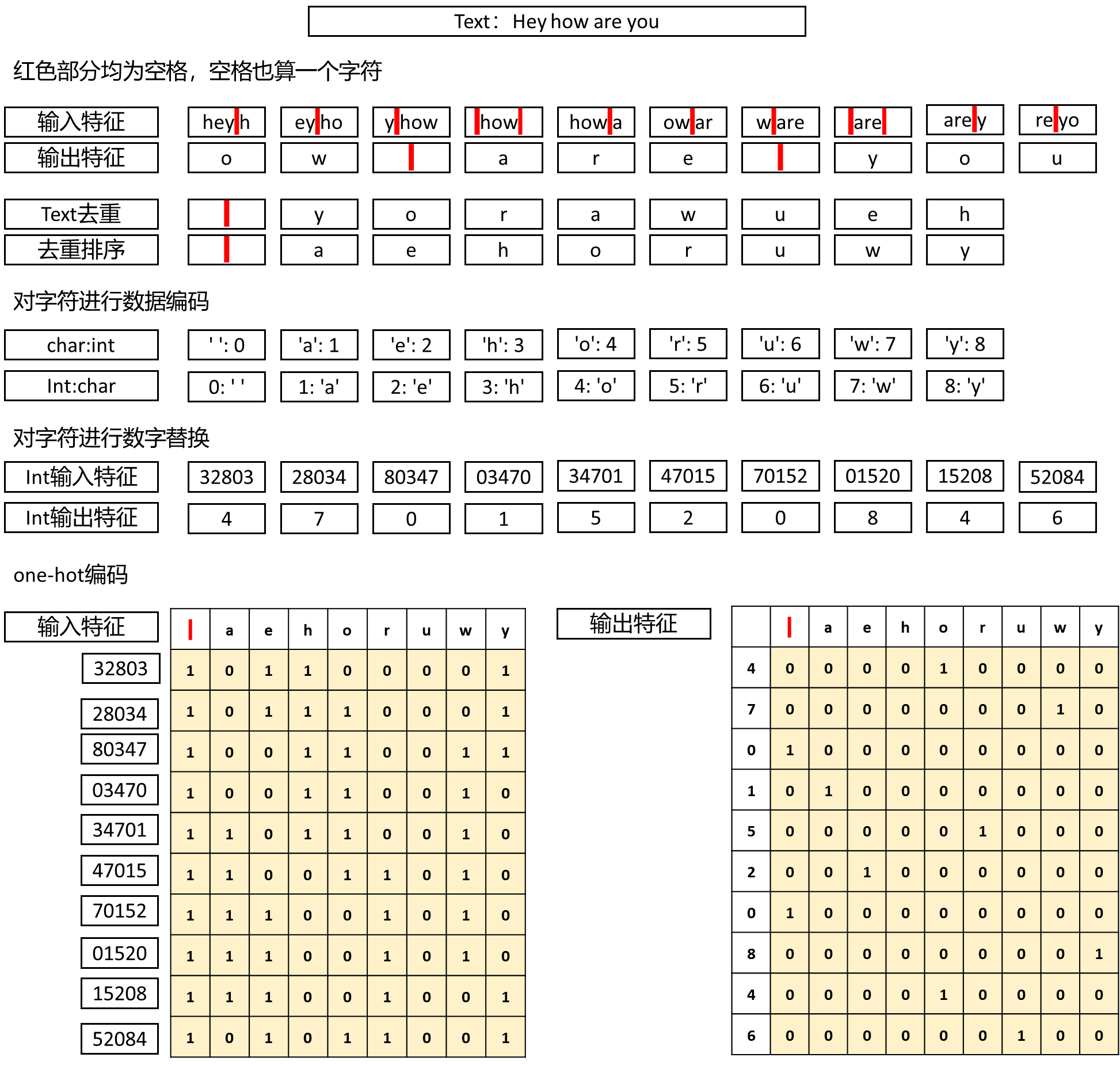
for i in range(0, len(text) - windows, 1):
# 当前窗口内的字符作为输入序列
input_seq.append(text[i:i + windows])
# 紧接着窗口后的字符作为输出(目标)
output_seq.append(text[i + windows])
# 输出所有的输入序列
print(input_seq)
# 输出对应的目标字符序列
print(output_seq)
# 获取文本中的所有唯一字符(集合一般无序)
charts = set(text)
print(charts)
# 将字符集合排序,保持一致的索引顺序
charts = sorted(charts)
print(charts)
# 创建字符到索引的映射字典
char2int = {char: idx for idx, char in enumerate(charts)}
print(char2int)
# 创建索引到字符的映射字典(逆映射)
int2char = {idx: char for idx, char in enumerate(charts)}
print(int2char)
# 将输入字符序列转换为对应的索引列表
input_seq = [[char2int[char] for char in seq] for seq in input_seq]
print(input_seq)
# 将输出目标字符序列转换为索引列表
output_seq = [[char2int[char] for char in seq] for seq in output_seq]
print(output_seq)
# 创建输入的特征矩阵(one-hot编码)
features = np.zeros((len(input_seq), len(charts)), dtype=np.float32)
for i, seq in enumerate(input_seq):
# 对每个字符索引,设置对应位置为1
features[i, seq] = 1
print(features)
# 转换为torch张量
input_seq = torch.tensor(features, dtype=torch.float32)
# 创建输出的标签矩阵(one-hot编码)
features = np.zeros((len(output_seq), len(charts)), dtype=np.float32)
for i, seq in enumerate(output_seq):
features[i, seq] = 1
print(features)
# 转换为torch张量
output_seq = torch.tensor(features, dtype=torch.float32)3.2、构建网络
# 定义神经网络模型
class Model(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
# 第一层全连接线性变换
self.fc1 = nn.Linear(input_size, hidden_size)
# 第二层全连接线性变换
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
# 输入经过第一层+ReLU激活
x = nn.functional.relu(self.fc1(x))
# 输出层
x = self.fc2(x)
return x
# 实例化模型:输入大小为所有字符的个数(one-hot长度)
# 隐藏层大小为32
# 输出大小也是所有字符的个数(预测下一字符的分布)
model = Model(len(charts), 32, len(charts))3.3、损失函数优化器
# 交叉熵损失
cri = nn.CrossEntropyLoss()
# Adam优化器
optim = torch.optim.Adam(model.parameters(), lr=0.001)3.4、训练模型
# 训练模型(迭代1000次)
for epoch in range(1000):
# 前向传播:输入模型,得到输出
output = model(input_seq)
# 计算损失(注意:这里的输出是未经过softmax,满足CrossEntropyLoss输入要求)
loss = cri(output, output_seq)
# 梯度清零
optim.zero_grad()
# 反向传播
loss.backward()
# 参数更新
optim.step()
# 每个epoch输出当前损失值
print(epoch, loss.item())3.5、预测数据
# 测试预测:给定一个新字符序列
input_text = 'hey h'
# 将字符转换为对应索引
input_text = [char2int[char] for char in input_text]
# 创建一个全为0的特征向量(大小等于所有字符数)
features = np.zeros((len(charts)), dtype=np.float32)
# 将序列中的每个字符位置置为1(one-hot)
for seq in input_text:
features[seq] = 1.0
# 转换为Tensor
input_text = torch.tensor(features, dtype=torch.float32)
# 用模型预测
out = model(input_text)
# 获取预测的概率最大的字符的索引
re = int2char[torch.argmax(out).item()]
print(re)3.6、完整代码
import numpy as np
import torch
import torch.nn as nn
# 原始文本
text = "hey how are you"
# 初始化输入和输出序列的列表
input_seq = []
output_seq = []
# 定义滑动窗口大小
windows = 5
# 构建输入和输出序列
for i in range(0, len(text) - windows, 1):
# 当前窗口内的字符作为输入序列
input_seq.append(text[i:i + windows])
# 紧接着窗口后的字符作为输出(目标)
output_seq.append(text[i + windows])
# 输出所有的输入序列
print(input_seq)
# 输出对应的目标字符序列
print(output_seq)
# 获取文本中的所有唯一字符(集合一般无序)
charts = set(text)
print(charts)
# 将字符集合排序,保持一致的索引顺序
charts = sorted(charts)
print(charts)
# 创建字符到索引的映射字典
char2int = {char: idx for idx, char in enumerate(charts)}
print(char2int)
# 创建索引到字符的映射字典(逆映射)
int2char = {idx: char for idx, char in enumerate(charts)}
print(int2char)
# 将输入字符序列转换为对应的索引列表
input_seq = [[char2int[char] for char in seq] for seq in input_seq]
print(input_seq)
# 将输出目标字符序列转换为索引列表
output_seq = [[char2int[char] for char in seq] for seq in output_seq]
print(output_seq)
# 创建输入的特征矩阵(one-hot编码)
features = np.zeros((len(input_seq), len(charts)), dtype=np.float32)
for i, seq in enumerate(input_seq):
# 对每个字符索引,设置对应位置为1
features[i, seq] = 1
print(features)
# 转换为torch张量
input_seq = torch.tensor(features, dtype=torch.float32)
# 创建输出的标签矩阵(one-hot编码)
features = np.zeros((len(output_seq), len(charts)), dtype=np.float32)
for i, seq in enumerate(output_seq):
features[i, seq] = 1
print(features)
# 转换为torch张量
output_seq = torch.tensor(features, dtype=torch.float32)
# 定义神经网络模型
class Model(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
# 第一层全连接线性变换
self.fc1 = nn.Linear(input_size, hidden_size)
# 第二层全连接线性变换
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
# 输入经过第一层+ReLU激活
x = nn.functional.relu(self.fc1(x))
# 输出层
x = self.fc2(x)
return x
# 实例化模型:输入大小为所有字符的个数(one-hot长度)
# 隐藏层大小为32
# 输出大小也是所有字符的个数(预测下一字符的分布)
model = Model(len(charts), 32, len(charts))
# 交叉熵损失
cri = nn.CrossEntropyLoss()
# Adam优化器
optim = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练模型(迭代1000次)
for epoch in range(1000):
# 前向传播:输入模型,得到输出
output = model(input_seq)
# 计算损失(注意:这里的输出是未经过softmax,满足CrossEntropyLoss输入要求)
loss = cri(output, output_seq)
# 梯度清零
optim.zero_grad()
# 反向传播
loss.backward()
# 参数更新
optim.step()
# 每个epoch输出当前损失值
print(epoch, loss.item())
# 测试预测:给定一个新字符序列
input_text = 'hey h'
# 将字符转换为对应索引
input_text = [char2int[char] for char in input_text]
# 创建一个全为0的特征向量(大小等于所有字符数)
features = np.zeros((len(charts)), dtype=np.float32)
# 将序列中的每个字符位置置为1(one-hot)
for seq in input_text:
features[seq] = 1.0
# 转换为Tensor
input_text = torch.tensor(features, dtype=torch.float32)
# 用模型预测
out = model(input_text)
# 获取预测的概率最大的字符的索引
re = int2char[torch.argmax(out).item()]
print(re)
















 1163
1163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









