










二 指令预取
乱序执行可以掩盖寄存器不足以及数据访问带来的部分latency。但是,乱序执行无法缓解取指的latency。因此,取指的latency也是内存墙的瓶颈之一。
2.1 Next-Line Prefetching
Next-Line Prefetching是指令预取最简单的形式,在现代大多数的处理器中都有使用。因为代码在内存中是线性按序存放的,通常超过一半的指令取指都是按序的。其结构如下:
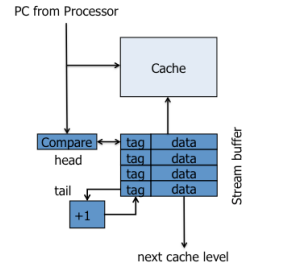
如上图所示,我们可以将预取的指令存入stream buffer,如果处理器访问该PC,就将指令从stream buffer中移入上层cache。
2.2 Fetch-Directed Prefetching
Next-line prefetch通常是高效的,但是只有一半的指令读取是按序的。控制流指令会破坏按序取指,导致取指不连续,因此需要预测未来的控制流,并lookahead。
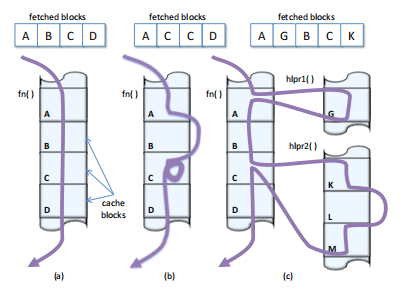
如上图所示,a)为按序取指,b)为进入循环,c)为调用函数,可以看出b、c都不是按序的。
因为分支预测和处理器中的其余流水线都是解耦的,因此可以使用分支预测器其来提前预测后续的控制流。
其结构如下:
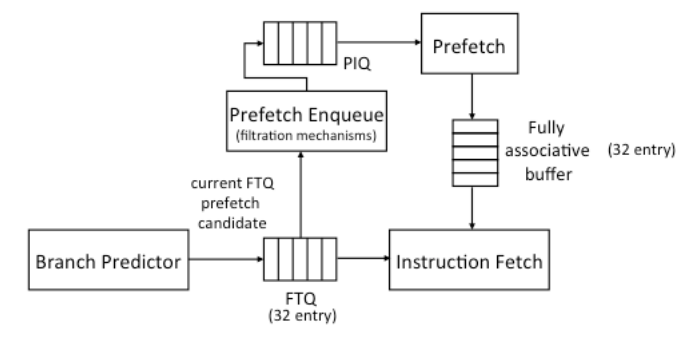
上图中使用FTQ中的地址来从L2 cache中读取指令block,并将它们存于Full associative buffer中;并且会先用预取地址访问L1Cache,只有miss的地址才会存放到PIQ中,进行预取。
我们来看看预测器的效果:
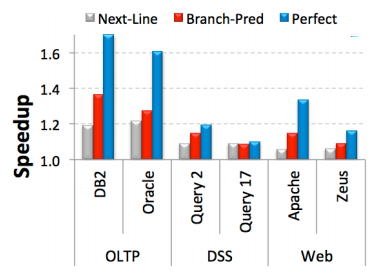
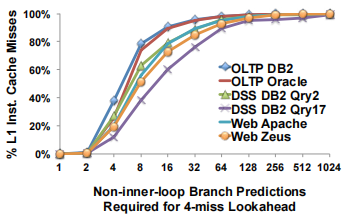
但是FDIP也有着lookahead受限的缺点,此外,超过一半的cache miss需要超过连续16次的分支预测准确才能避免。统计信息如下图所示:
2.3 Discontinuity Prefetching
更大的挑战来自于取指不连续,比如因为函数调用,分支执行和异常。
为了解决这一问题,已经提出了大量的解决方式:1)wrong-path 预取 2)分支历史指导预取 3)执行历史指导预取 4)多stream预测 4)next-trace 预测 5) call graph 预取。
其中一种实现方式如下:
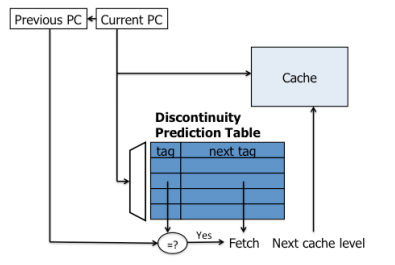
将discontinuity的pc和其上一条sequential的pc存入Discontinuy Prediction Table,如果当前地址索引之后,tag也匹配,那么就预取表格中记录的下一条pc地址(有点类似于BTB)。通过递归访问DPT,就可以起到prefetch lookahead的效果。但是因为只存放了一条映射关系,如果一个PC对应多个分支,那么就无能为力了。
此外还有使用helper thread来识别当前指令流规律,并进行预取的。
2.5 Temporal Instruction Fetch Streaming
TIFS 会记录L1 cache miss的地址,并将连续的miss log存入instruction miss log中。一旦L1 cache miss发生,就会使用它访问indext table,索引到instruction miss log中,然后预取后续的miss 地址。与2.1中的next line类似,将返回的指令存入stream value buffer,后续如果命中SVB,那么就从SVB中返回指令。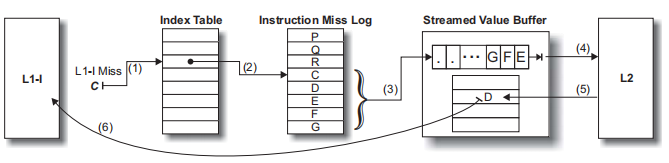
TIFS因为使用了cache block的地址进行索引,而不是pc进行索引,因此它会跳过cache block内部的小循环和小控制流。但是TIFS的lookahead比较大,可以连续的对discontinuty指令进行预取。举例来说,next-line prefetch需要进入函数后,才能对函数后面的指令进行预取。但是TIFS可以在还没进入函数时,根据miss log,就超前预取。
后续又出现了Proactive Instruction Fetch,PIF对TIFS的进行了优化:它记录committed 指令的log,而不是访问cache时miss的地址;并且单独记录终端和异常处理程序中的指令流。
2.6 Return-Address Stack-Directed Instruction Prefetching
Discontinuity Prefetching使用PC的一条映射关系进行预取,TIFS尽管增加了lookahead,但是使用cache block addr进行预取,它们都无法解决cache block内的多重控制流。
为了解决这个问题,提出了RDIP return-address stack-directed instruction prefetching. 该方法基于以下两点:
1) RAS中记录的程序上下文与L1 instruction miss强相关
2)RAS return stack address简洁的记录了程序上下文。
RDIP将预取操作与RAS中记录的上下文signature联系起来。通过在每次call和return时,触发prefetching。
小结:
欢迎关注我的公众号《处理器与AI芯片》


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









