







本文主要介绍体系结构仿真中使用的工具:
- Gem5
Gem5支持功能级别的仿真和周期精确的cycle-accurate级别的仿真。
功能级别类似于验证或者算法中的c model,不对时序建模。
周期精确的仿真则是基于event-driven的原理,进行cycle-accurate级别的建模。
Gem5支持SE模式和FS 模式,分别为system-call emulation和full system。FS模式的仿真是基于操作系统,需要boot之后进行仿真。
- Spec 2006/2017
Spec2006和 2017 是程序标准测试benchmark,类似于我们平时写的程序,不过是挑选的各种能够衡量CPU性能的程序,比如gcc,h264,科学计算等。
目前还没有找到开源的,需要购买,买来之后拿到的ISO需要编译,产生可执行文件。
可执行文件可以在真实的CPU上运行,得到真实CPU的性能。
因为可以在gem5上运行可执行文件,因此我们可以将编译好的可执行文件在gem5上运行。通过更改不同的配置,比如ROB的深度等,得到不同的ipc,这样可以对CPU 微架构进行调优。
Spec2017分为两类benchmark,整型和浮点。每一类指令中又分别分成speed和rate两类,speed主要侧重衡量CPU执行指令的时间长短,rate则主要衡量CPU 的吞吐率。
论文上说speed模式会开启多线程,因此运行浮点benchmark时,会因为多线程的引入而导致cache miss增加。此外一个不同点也是rate会运行多份copy 数据。因此个人理解,可能会存在一种情况,架构A 支持4线程,但是缓存小,架构B只支持2线程,但是缓存大,导致架构A speed比架构B 快,但是架构B rate的性能更好。
Spec2017的指令个数:
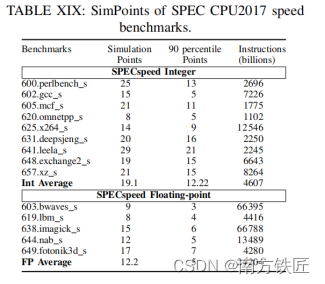
用gem5仿真billion数量级的指令还是十分缓慢的。
- Simpoint
为了解决gem5仿真大型指令十分缓慢的问题,gem5引入了checkpoint机制,checkpoint类似于上下文切换时保存的上下文,也类似于微架构中遇到分支指令时,保存的checkpoint,可以理解成是在一个时刻CPU运行的快照,会保存架构寄存器和缓存memory的状态。
如果每间隔1000MB指令保存一个checkpoint,那么假设我们仿真10000M的指令,可以同时提交10个task,分别从0M,1000M,2000M,3000M ..开始进行仿真,仿真启动时加载checkpoint,就可以同时进行仿真了,提高了仿真的并行度。
但是如果要仿真100 Billion条指令,这时有1000个task需要执行,那么还是不理想,于是就有了simpoint工具。
Simpoint工具是基于k-means的思想,首先使用gem5生成simpoint文件,simpoint文件是Simpoint工具定义的bbv格式的数据,根据其论文的描述,会记录微架构关键的统计信息。
向 Simpoint 指定聚类的个数之后,simpoint会分析程序的特征,比如一个100M的指令大量的反复执行,那么它在gem5产生的simpoint文件中,会产生大量相同的统计信息,这时我们可以给它比较高的权重,通过将程序段进行归类,我们可以从100 Billion条指令中抽取具有代表性的指令。
这里simpoint工具只会生成各段指令的起始位置和权重。Simpoint的论文里介绍会选取最靠近簇心的程序段作为代表程序段。
我们看一下它的论文里分析的gzip指令,还是挺有规律的。这里要说的是它在聚类时也使用了降维的方法,将100,000维降低到了15维之后进行聚类。
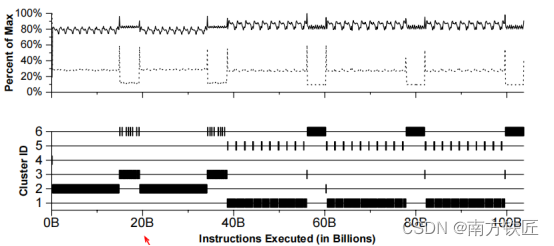
最终,我们知道了各个程序段的权重,使用gem5运行比较有代表性的指令片段,得到的不同程序段的统计信息进行加权计算就可以得到最终的统计信息了,这样比完整的运行一个benchmark快速了很多。
除了论文以外几个比较有帮助的文章:
——————欢迎关注我的公众号《处理器与AI芯片》














 258
258











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









