







目录
流量削峰的一些操作思路:排队、答题、分层过滤。这几种方式都是无损(即不会损失用户的发出请求)的实现方案
当然还有些有损的实现方案,关于稳定性的一些办法,比如限流和机器负载保护等一些强制措施也能达到削峰保护的目的
排队
要对流量进行削峰,最容易想到的解决方案就是用消息队列来缓冲瞬时流量,把同步的直接调用转换成异步的间接推送,中间通过一个队列在一端承接瞬时的流量洪峰,在另一端平滑地将消息推送出去。在这里,消息队列就像“水库”一样, 拦蓄上游的洪水,削减进入下游河道的洪峰流量,从而达到减免洪水灾害的目的。
用消息队列来缓冲瞬时流量的方案,如下图所示:

如果流量峰值持续一段时间达到了消息队列的处理上限,例如本机的消息积压达到了存储空间的上限,消息队列同样也会被压垮,这样虽然保护了下游的系统,但是和直接把请求丢弃也没多大的区别。就像遇到洪水爆发时,即使是有水库恐怕也无济于事。
除了消息队列,类似的排队方式还有很多,例如:
- 利用线程池加锁等待也是一种常用的排队方式;
- 先进先出、先进后出等常用的内存排队算法的实现方式;
- 把请求序列化到文件中,然后再顺序地读文件(例如基于 MySQL binlog 的同步机制)来恢复请求等方式。
可以看到,这些方式都有一个共同特征,就是把“一步的操作”变成“两步的操作”,其中增加的一步操作用来起到缓冲的作用。
这样不符合”4要1不要“的原则,增加了路径,但这是对架构做出的妥协
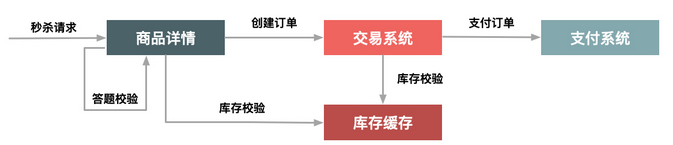
答题
最早期的秒杀只是纯粹地刷新页面和点击购买按钮,它是后来才增加了答题功能的
这主要是为了增加购买的复杂度,从而达到两个目的。
第一个目的是防止部分买家使用秒杀器在参加秒杀时作弊

第二个目的其实就是延缓请求,起到对请求流量进行削峰的作用,从而让系统能够更好地支持瞬时的流量高峰。这个重要的功能就是把峰值的下单请求拉长,从以前的 1s 之内延长到 2s~10s。这样一来,请求峰值基于时间分片了。这个时间的分片对服务端处理并发非常重要,会大大减轻压力。而且,由于请求具有先后顺序,靠后的请求到来时自然也就没有库存了,因此根本到不了最后的下单步骤,所以真正的并发写就非常有限了。这种设计思路目前用得非常普遍,如当年支付宝的“咻一咻”、微信的“摇一摇”都是类似的方式。
秒杀答题的设计思路

如上图所示,整个秒杀答题的逻辑主要分为 3 部分。
- 题库生成模块,这个部分主要就是生成一个个问题和答案,其实题目和答案本身并不需要很复杂,重要的是能够防止由机器来算出结果,即防止秒杀器来答题。
- 题库的推送模块,用于在秒杀答题前,把题目提前推送给详情系统和交易系统。题库的推送主要是为了保证每次用户请求的题目是唯一的,目的也是防止答题作弊。
- 题目的图片生成模块,用于把题目生成为图片格式,并且在图片里增加一些干扰因素。这也同样是为防止机器直接来答题,它要求只有人才能理解题目本身的含义。这里还要注意一点,由于答题时网络比较拥挤,我们应该把题目的图片提前推送到 CDN 上并且要进行预热,不然的话当用户真正请求题目时,图片可能加载比较慢,从而影响答题的体验。
当用户提交的答案和题目对应的答案做比较,如果通过了就继续进行下一步的下单逻辑,否则就失败。我们可以把问题和答案用下面这样的 key 来进行 MD5 加密:
问题 key:userId+itemId+question_Id+time+PK
答案 key:userId+itemId+answer+PK
验证的逻辑如下图所示:
注意,这里面的验证逻辑,除了验证问题的答案以外,还包括用户本身身份的验证,例如是否已经登录、用户的 Cookie 是否完整、用户是否重复频繁提交等。
除了做正确性验证,我们还可以对提交答案的时间做些限制,例如从开始答题到接受答案要超过 1s,因为小于 1s 是人为操作的可能性很小,这样也能防止机器答题的情况。
分层过滤
排队和答题要么是少发请求,要么对发出来的请求进行缓冲,而针对秒杀场景还有一种方法,就是对请求进行分层过滤,从而过滤掉一些无效的请求。
分层过滤其实就是采用“漏斗”式设计来处理请求的,如下图所示。

假如请求分别经过 CDN、前台读系统(如商品详情系统)、后台系统(如交易系统)和数据库这几层,那么:
- 大部分数据和流量在用户浏览器或者 CDN 上获取,这一层可以拦截大部分数据的读取
- 经过第二层(即前台系统)时数据(包括强一致性的数据)尽量得走 Cache,过滤一些无效的请求
- 再到第三层后台系统,主要做数据的二次检验,对系统做好保护和限流,这样数据量和请求就进一步减少
- 最后在数据层完成数据的强一致性校验
这样就像漏斗一样,尽量把数据量和请求量一层一层地过滤和减少了
分层过滤的核心思想是:在不同的层次尽可能地过滤掉无效请求,让“漏斗”最末端的才是有效请求。而要达到这种效果,我们就必须对数据做分层的校验。
分层校验的基本原则是:
- 将动态请求的读数据缓存(Cache)在 Web 端,过滤掉无效的数据读;
- 对读数据不做强一致性校验,减少因为一致性校验产生瓶颈的问题;
- 对写数据进行基于时间的合理分片,过滤掉过期的失效请求;
- 对写请求做限流保护,将超出系统承载能力的请求过滤掉;
- 对写数据进行强一致性校验,只保留最后有效的数据。
分层校验的目的是:在读系统中,尽量减少由于一致性校验带来的系统瓶颈,但是尽量将不影响性能的检查条件提前,如用户是否具有秒杀资格、商品状态是否正常、用户答题是否正确、秒杀是否已经结束、是否非法请求、营销等价物是否充足等;在写数据系统中,主要对写的数据(如“库存”)做一致性检查,最后在数据库层保证数据的最终准确性(如“库存”不能减为负数)。















 1201
1201











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









