







Java集合类
从上图可以看出,HashMap集合类有一个子类LinkedHashMap,它的基类为AbstractMap。源码如下:
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
...
}HashMap的实现原理(1.7)
Hashmap的数据结构是“链表散列”,即数组+链表。
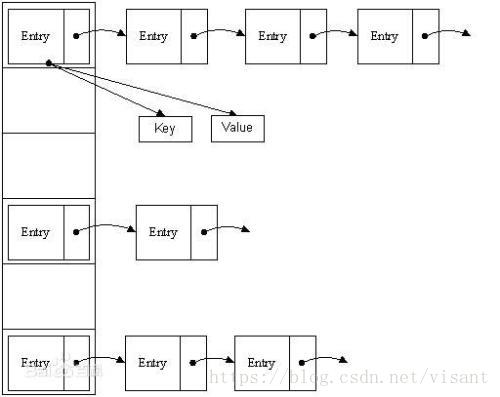
其中,静态内部类Entry的数据结构如下:
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
final int hash;
Entry<K,V> next;
..........
} 数组的数据结构如下:
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry[] table; HashMap的resize过程
在了解HashMap的resize过程之前,需要先知道三个参数:capacity(容量,即table数组长度)、LoadFactory(加载因子)、threshold(最大容量)。
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;根据上述源码,我们可以得知,capacity初始默认大小为16,LoadFactory默认大小为0.75,所以threshold默认大小为16*0.75=12。
那么HashMap什么时候会扩容呢?
当HashMap.size>threshold的时候,就会进行resize操作,resize的时候,就会进行扩容,扩容时capacity=capacity*2。扩容是一个非常消耗性能的过程,需要重新计算数据在新数组中的位置(即rehash),并且将内容复制到新数组中。
HashMap的put过程
当执行put操作的时候,需要先判断是否需要resize,如果需要,则按上面的方式进行resize,否则HashMap会先判断一下要存储内容的key值是否为null,如果为null, 则执行putForNullKey方法,这个方法的作用就是将内容存储到Entry[]数组的第一个位置,如果key不为null,则去计算key的hash值,然后对数组长度取模(进行位移操作),得到要存储位置的下标,再迭代该数组元素上的链表,看该链表上是否有hash值相同并且==和equals都为真,就直接覆盖value的值,如果没有相等的情况,就将该内容存储到链表的表头,最先储存的内容会放在链表的表尾。
HashMap的实现原理(1.8)
相比于1.7,1.8中HashMap的数据结构变成数组+链表+红黑树,数据结构采用的是桶位数组:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
}transient Node<K,V>[] table;1.8的put过程前面一部分和1.7一样,不过当链表长度达到8的时候,如果再在该链表上进行put操作,就会转成红黑数。链表的查找效率O(n),红黑数的查找效率O(lgn)。
面试过程遇到的问题:
什么叫哈希冲突
由于哈希算法被计算的数据是无限的,而计算后的结果范围有限,因此总会存在不同的数据经过计算后得到的值相同,这就是哈希冲突
哈希冲突的解决方法
1)开放地址法(前提是散列表的长度大于等于所要存放的元素)
发生哈希冲突后,按照某一次序找到下一个空闲的单元,把冲突的元素放入。
- 线性探查法
从发生冲突的单元开始探查,依次查看下一个单元是否为空,如果到了最后一个单元还是空,那么再从表首依次判断。如此执行直到碰到了空闲的单元或者已经探查完所有单元。
- 平方探查法
从发生冲突的单元加上1^2,2^2,3^2,...,n^2,直到遇到空闲的单元
- 双散列函数探查法
定义两个散列函数,分别为s1和s2,s1的算法和前面一致,s2取一个1~m-1之间并和m互为素数的数。s2作为步长。
2)链地址法
将哈希值相同的元素构成一个链表,head放在散列表中。一般链表长度超过了8就转为红黑树,长度少于6个就变为链表。
3)再哈希法
同时构造多个不同的哈希函数,Hi = RHi(key) i= 1,2,3 … k;
当H1 = RH1(key) 发生冲突时,再用H2 = RH2(key) 进行计算,直到冲突不再产生,这种方法不易产生聚集,但是增加了计算时间。
4)建立公共溢出区
把哈希表分为公共表和溢出表,如果发生了溢出,溢出的数据全部放在溢出区。
HashMap和HashTable的区别?
1)HashMap是线程不安全的,hashTable是线程安全的,synchronization;
2)hashMap允许null,hashTable不允许;
3)hashMap继承的是AbstractMap类,hashTable继承的是Dicionary类;
4)hashTable有contains方法,hashMap则是containsValue和containsKey;
5)遍历方式不同,hashMap和hashTable都使用了Iterator,hashTable还使用了Enumeration;
6)hash值不同,hashTable使用的是对象的hashcode,hashMap则是重新计算了hash值;
7)初始化和扩容方式不同,hashMap是16,hashTable是11,扩容时前者是乘2,后者是乘2+1
线程安全和线程不安全
线程安全就是指多个线程对同一个对象进行操作的时候,不会出现问题;线程不安全就是指多个线程对同一个对象进行操作的时候,可能会出现问题。
为什么说HashMap是线程不安全的
1)HashMap 在插入的时候
现在假如 A 线程和 B 线程同时进行插入操作,然后计算出了相同的哈希值对应了相同的数组位置,因为此时该位置还没数据,然后对同一个数组位置,两个线程会同时得到现在的头结点,然后 A 写入新的头结点之后,B 也写入新的头结点,那B的写入操作就会覆盖 A 的写入操作造成 A 的写入操作丢失。
2)HashMap 在扩容的时候
HashMap 有个扩容的操作,这个操作会新生成一个新的容量的数组,然后对原数组的所有键值对重新进行计算和写入新的数组,之后指向新生成的数组。
那么问题来了,当多个线程同时进来,检测到总数量超过门限值的时候就会同时调用 resize 操作,各自生成新的数组并 rehash 后赋给该 map 底层的数组,结果最终只有最后一个线程生成的新数组被赋给该 map 底层,其他线程的均会丢失。
3)HashMap 在删除数据的时候
删除这一块可能会出现两种线程安全问题,第一种是一个线程判断得到了指定的数组位置i并进入了循环,此时,另一个线程也在同样的位置已经删掉了i位置的那个数据了,然后第一个线程那边就没了。但是删除的话,没了倒问题不大。
再看另一种情况,当多个线程同时操作同一个数组位置的时候,也都会先取得现在状态下该位置存储的头结点,然后各自去进行计算操作,之后再把结果写会到该数组位置去,其实写回的时候可能其他的线程已经就把这个位置给修改过了,就会覆盖其他线程的修改。
其他地方还有很多可能会出现线程安全问题,我就不一一列举了,总之 HashMap 是非线程安全的,有并发问题时,建议使用 ConcrrentHashMap。
ConcrrentHashMap
见博客XXXXXXX
fail-fast和fail-server
Iterator的安全失败是基于对底层集合做拷贝,因此,它不受源集合上修改的影响。java.util包下面的所有的集合类都是快速失败的,而java.util.concurrent包下面的所有的类都是安全失败的。快速失败的迭代器会抛出ConcurrentModificationException异常,而安全失败的迭代器永远不会抛出这样的异常。fail-fast机制,是一种错误检测机制。它只能被用来检测错误,因为JDK并不保证fail-fast机制一定会发生。若在多线程环境下使用fail-fast机制的集合,建议使用“java.util.concurrent包下的类”去取代“java.util包下的类”。
HashMap和LinkedHashMap的区别
LinkedHashMap也是一个HashMap,但是内部维持了一个双向链表,可以保持顺序
接口和抽象类的区别
抽象类:
1、抽象类使用abstract修饰;
2、抽象类不能实例化,即不能使用new关键字来实例化对象;
3、含有抽象方法(使用abstract关键字修饰的方法)的类是抽象类,必须使用abstract关键字修饰;
4、抽象类可以含有抽象方法,也可以不包含抽象方法,抽象类中可以有具体的方法;
5、如果一个子类实现了父类(抽象类)的所有抽象方法,那么该子类可以不必是抽象类,否则就是抽象类;
6、抽象类中的抽象方法只有方法体,没有具体实现;
接口:
1、接口使用interface修饰;
2、接口不能被实例化;
3、一个类只能继承一个类,但是可以实现多个接口;
4、接口中方法均为抽象方法;
5、接口中不能包含实例域或静态方法(静态方法必须实现,接口中方法是抽象方法,不能实现);
6、接口中的属性必须用static来修饰;
泛型的作用和如何确定泛型的上下限
泛型是通过类型擦除来实现的,编译器在编译时擦除了所有类型相关的信息,所以在运行时不存在任何类型相关的信息。它提供了编译期的类型安全,确保你只能把正确类型的对象放入 集合中,避免了在运行时出现ClassCastException。
限定通配符对类型进行了限制。有两种限定通配符,一种是<? extends T>它通过确保类型必须是T的子类来设定类型的上界,另一种是<? super T>它通过确保类型必须是T的父类来设定类型的下界。















 2900
2900











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









