









抓取百度贴吧的某一个帖子的评论内容
前言
本项目实战是用来学习用,没有别的商业用途和恶意请求
先查看贴吧的robots.txt
这是君子协议,如果不允许爬取的,就不去碰,先看君子协议的地址:https://tieba.baidu.com/robots.txt
最后看到,评论内容允许被爬取。

页面结构分析
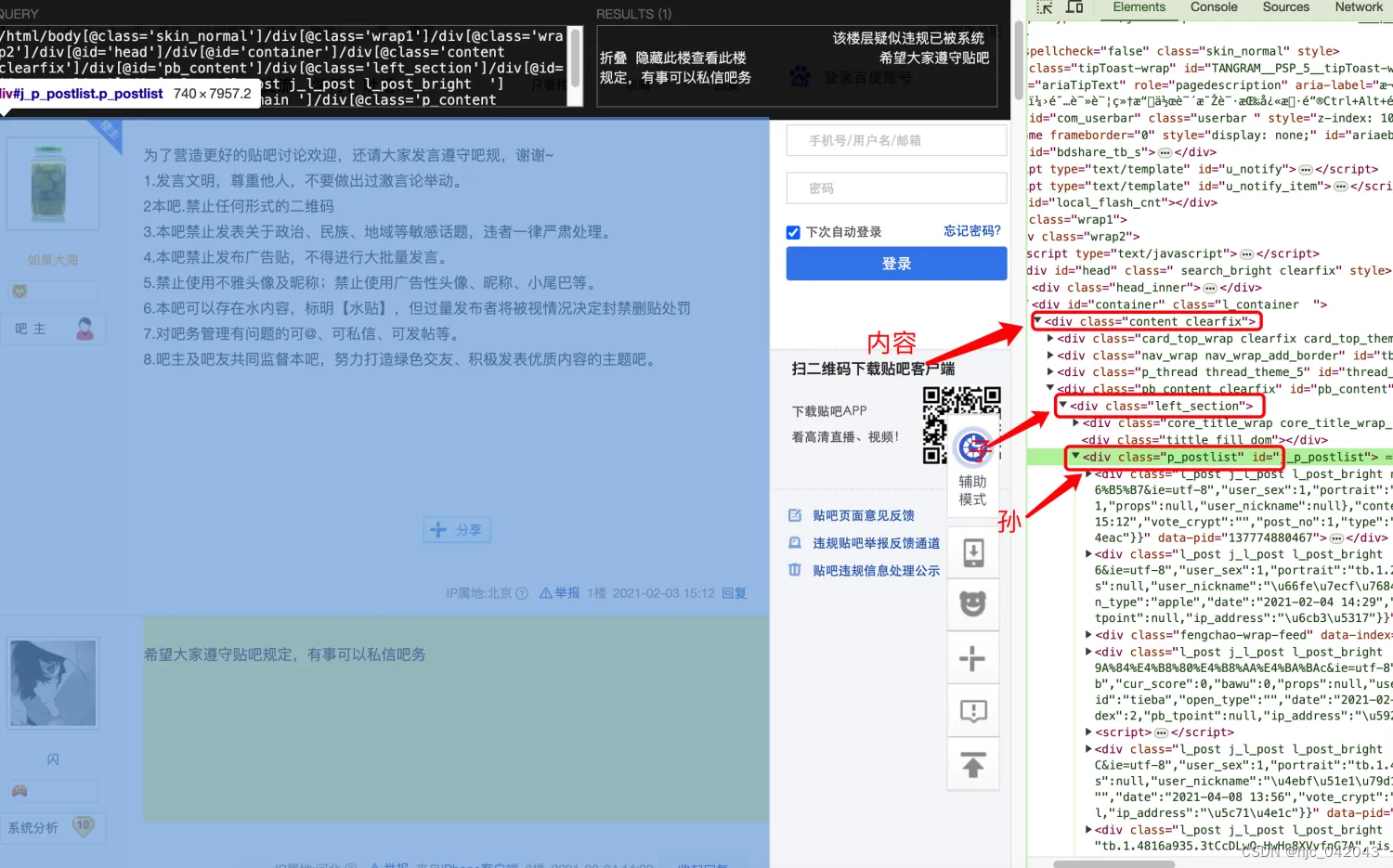
- 抓取的数据结构:
我们要抓取的评论的内容,评论人的头像,用户名,以及评论人的个人主页,评论时间,回复人信息 - 页面结构
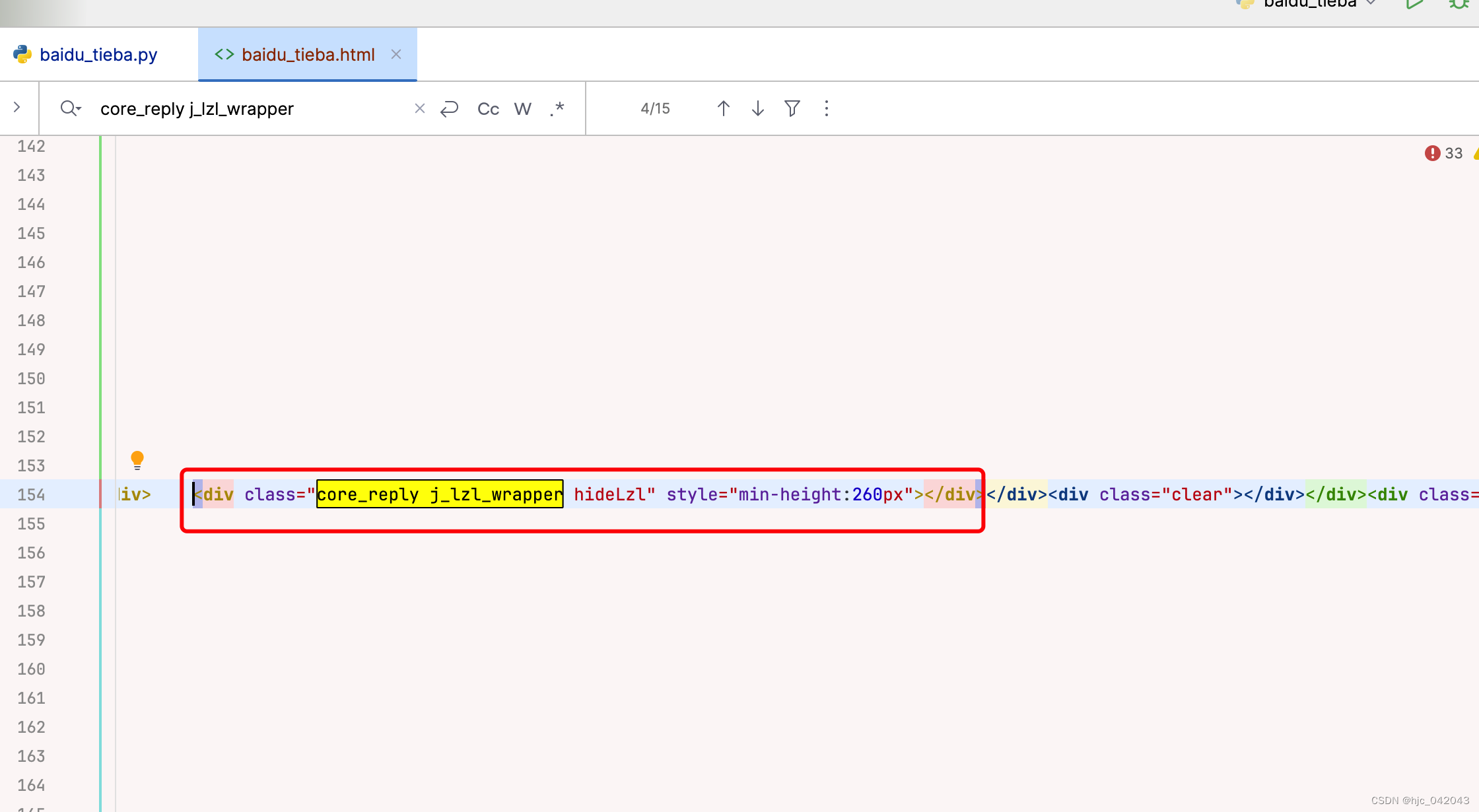
通过 css 选择器,评论是位于一个class="p_postlist"的 div下,而p_postlist 下又有多个class 包含l_post j_l_post l_post_bright内容,可以确定评论就在这些 div 中
评论者头像,用户抓取
通过页面结构分析,头像是位于 class="d_auth"的 div下元素ul 下,url 的 class="p_author
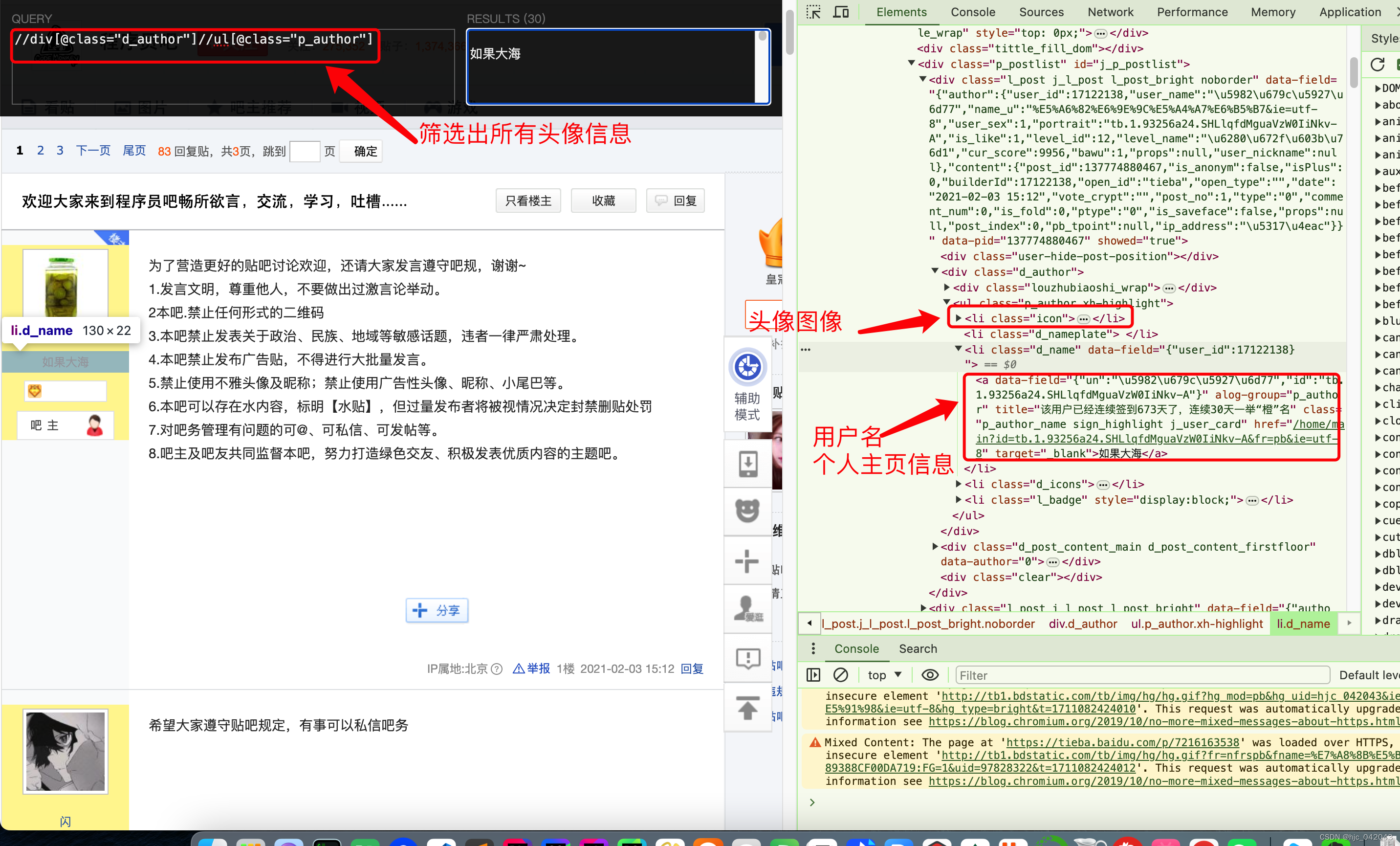
所以取头像,用户名的 xpath代码这么写
#头像地址
//ul[@class="p_author"]//a[contains(@class,"p_author_face")]/img/@src
# 个人主页的链接
//ul[@class="p_author"]//a[contains(@class,"p_author_face")]/@href
# 用户名的链接
//ul[@class="p_author"]//a[contains(@class,"p_author_name")]/text()
评论内容的抓取
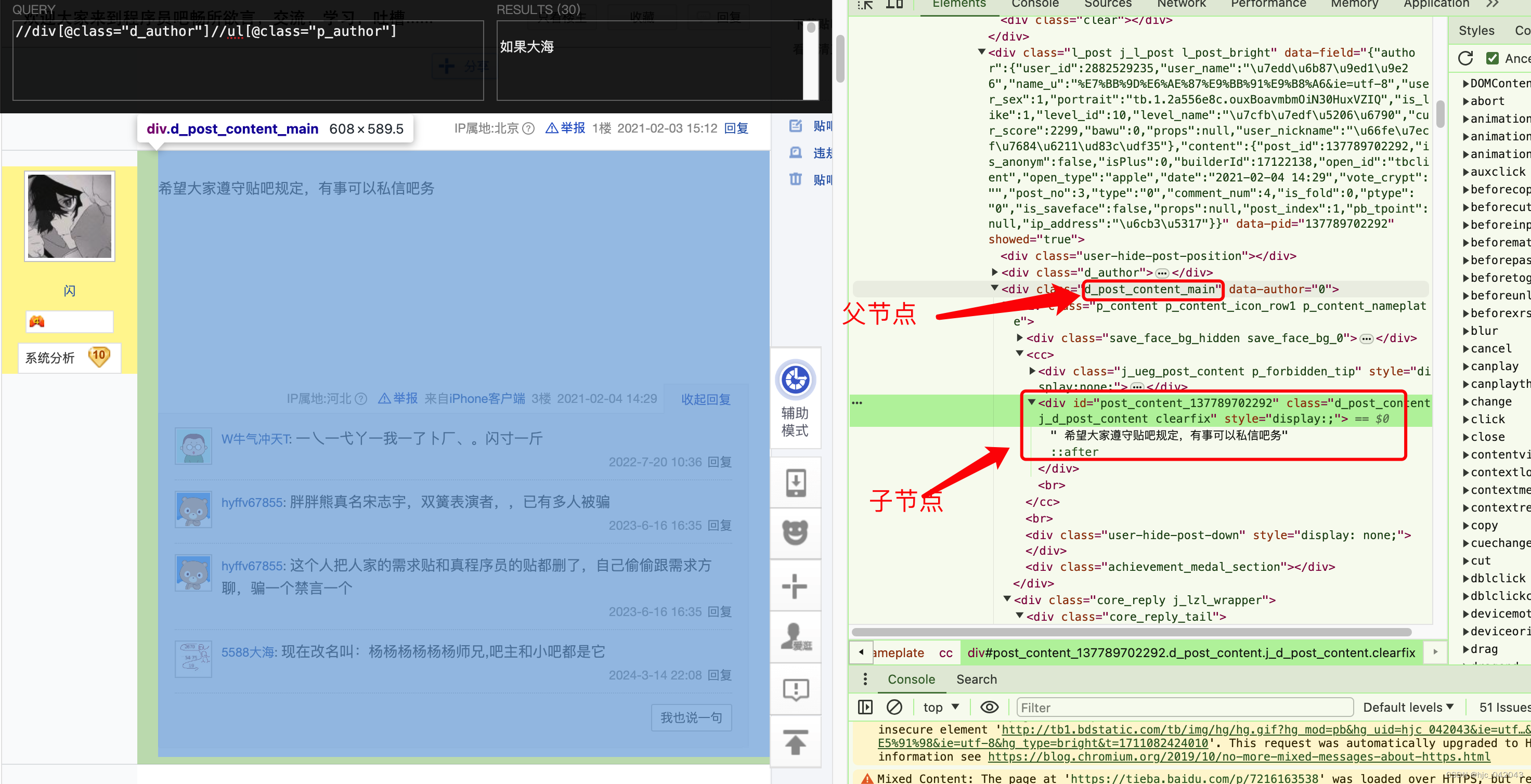
#根据结构,可以去确定内容,子节点的id包含 post_content_就能拿到
//div[contains(@class,"d_post_content_main")]//div[contains(@id,"post_content_")]/text()
评论下回复内容的抓取
根据 xpath 工具看到,都是和评论同一个节点,class="d_post_content_main"的元素下。
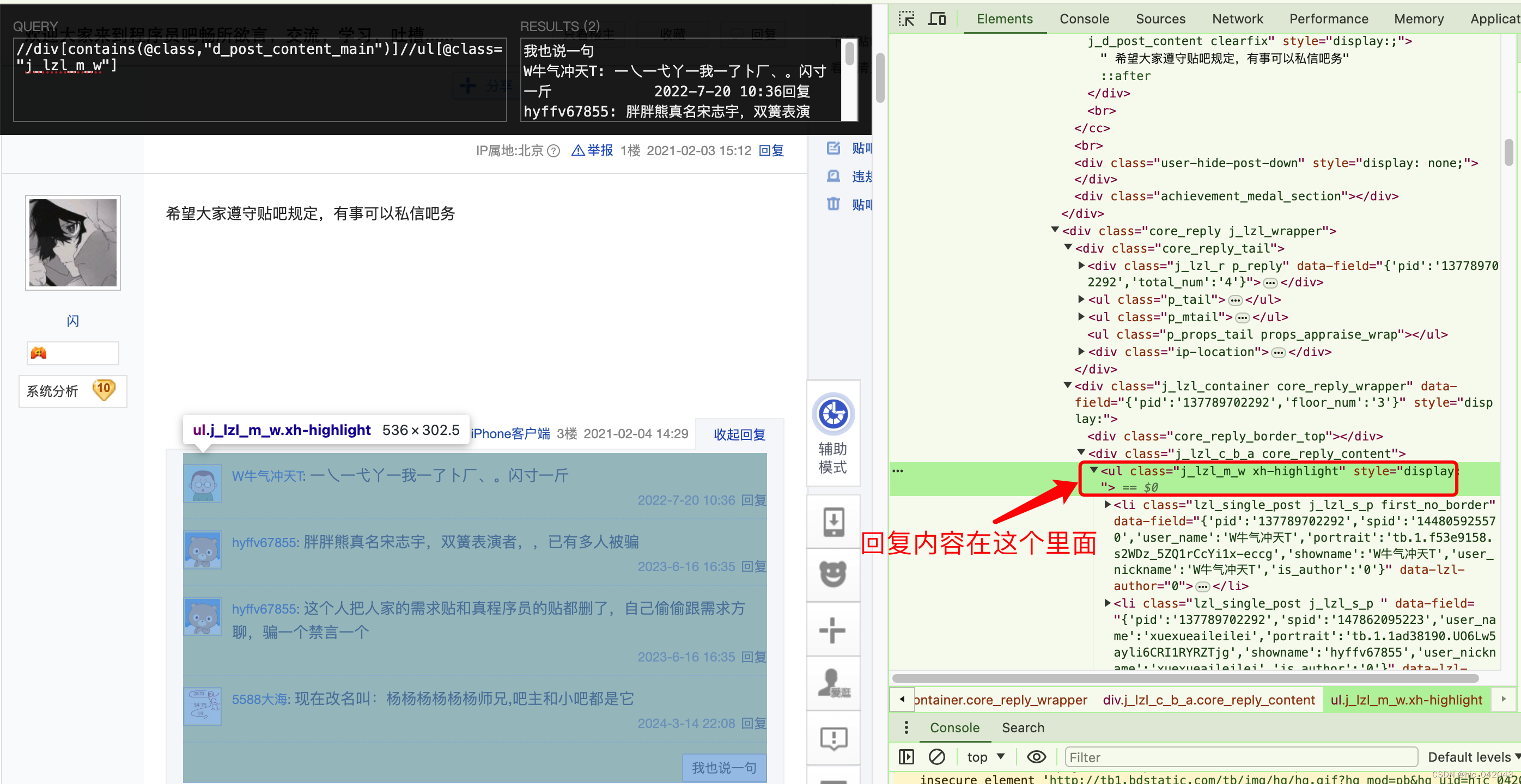
# 评论下的内容
.//div[contains(@class,"d_post_content_main")]//ul[@class="j_lzl_m_w"]
但是在请求的代码中,发现这个 xpath 没有执行,数据没获取到,最后发现是js动态生成的,通过 respons.content的源码发现,这一整个回复的上层 div是空的,这里需要 JS 逆向处理,因为这块涉及到有一定的复杂度,就不再展开,等学完 JS 逆行再来处理。
源码实现
源码链接:https://gitee.com/allen-huang/python/blob/master/crawler/do-request/bbs/baidu_tieba.py
贴吧抓取过程源码实现
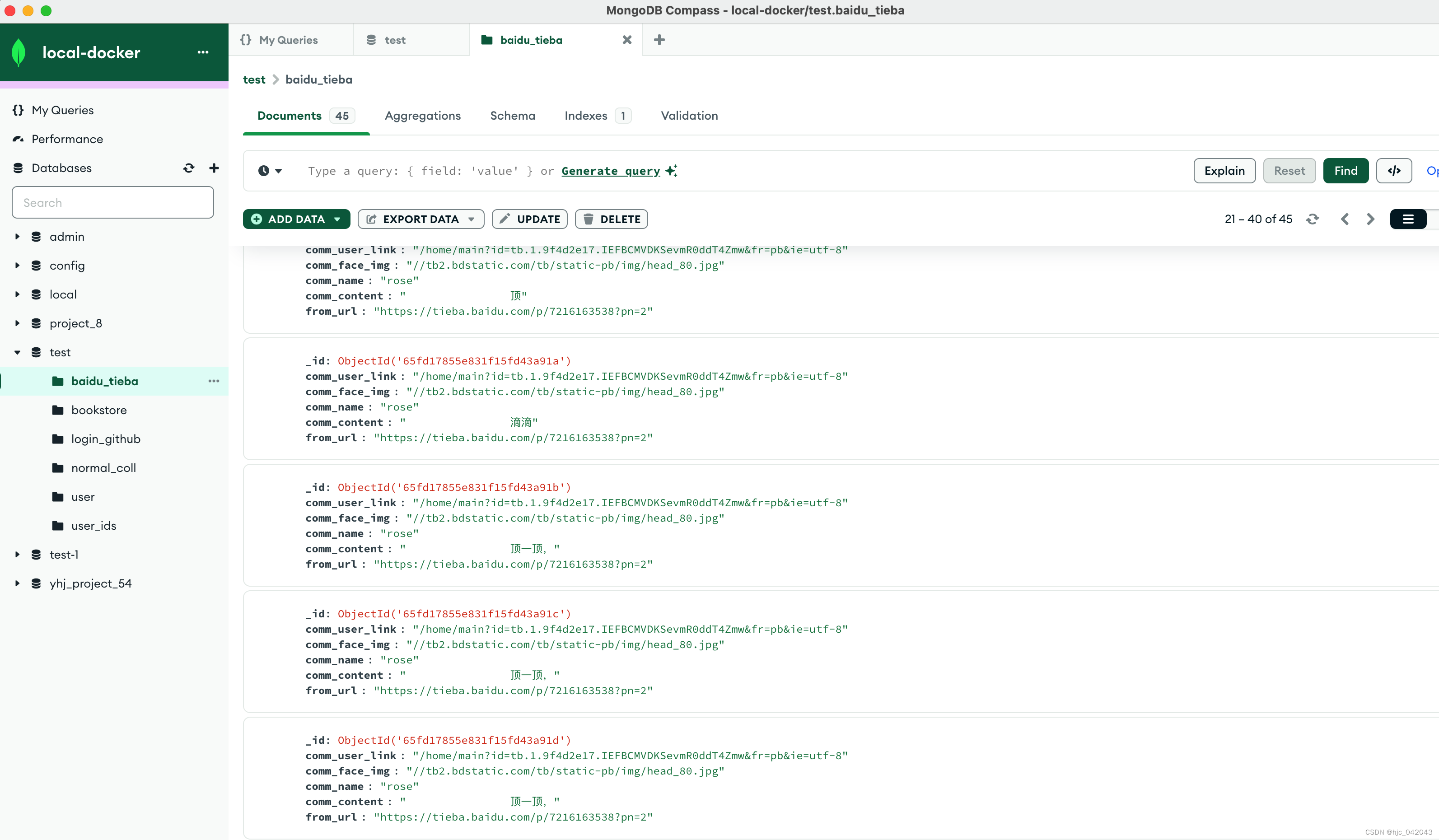
根据xpath结构抓取下来的内容,然后入库到 mongodb 中 去
class BaiduTieba(object):
def __init__(self, url):
self.url = url
self.headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36'
}
pass
def rep_content(self):
"""
获取请求内容
@return:
"""
import requests
resp = requests.get(self.url, headers=self.headers)
if resp.status_code == 200:
return resp.content
else:
return None
pass
def parse_content(self):
"""
解析请求内容
@return:
"""
resp_data = self.rep_content()
# 将请求内容转换成 html 内容,并编码为 utf-8
html_data = etree.HTML(resp_data, parser=etree.HTMLParser(encoding='utf-8'))
# 获取评论的内容
comm_list = html_data.xpath('//div[contains(@class,"l_post j_l_post l_post_bright")]')
insert_list = []
for comm in comm_list:
# 取左侧头像的图片链接
author_face = comm.xpath('.//ul[@class="p_author"]//a[contains(@class,"p_author_face")]')[0]
comm_user_link = author_face.xpath('./@href')[0]
comm_face_img = author_face.xpath('./img/@src')[0]
# 取左侧头像的用户名
comm_name = comm.xpath('.//ul[@class="p_author"]//a[contains(@class,"p_author_name")]/text()')[0]
# 取右侧的评论内容
comm_content = comm.xpath(
'.//div[contains(@class,"d_post_content_main")]//div[contains(@id,"post_content_")]/text()')[0]
# todo 取右侧的评论时间,这个需要使用 JS 逆向来取一开始以为是 xpath有问题,但在 chrom 浏览器插件上测试是可以的,
# todo 在 response.content 上发现这是通过JS来动态取的,所以需要学完 JS 逆向再来处理
# comm_time = comm.xpath(
# './/div[contains(@class,"core_reply_tail")]//ul[@class="p_tail"]/li[2]/span/text()')[0]
comm_dict = {
"comm_user_link": comm_user_link,
"comm_face_img": comm_face_img,
"comm_name": comm_name,
"comm_content": comm_content,
"from_url": self.url,
# "comm_time": comm_time
}
# todo 取右侧的回复内容,这个需要使用 JS 逆向来取,先不做处理,等学完 JS 逆向再来处理
# reply_list = []
# reply_container = comm.xpath('.//div[contains(@class,"d_post_content_main")]//ul[@class="j_lzl_m_w"]')
# for reply in reply_container:
# # 取回复人头像的链接
# reply_face = reply.xpath(
# './li[contains(@class,"lzl_single_post")]/a[@class="j_user_card lzl_p_p"]')
# reply_user_link = reply_face.xpath('./@href')
# reply_user_img = reply_face.xpath('./img/@src')
# # 取回复人的名字,回复内容,回复时间
# reply_con = reply.xpath(
# './li[contains(@class,"lzl_single_post")]/div[contains(@class,"lzl_cnt")]')
# reply_name = reply_con.xpath('./a[contains(@class,"j_user_card")]/text()')
# reply_content = reply_con.xpath('./span[contains(@class,"lzl_content_main")]/text()')
# reply_time = reply_con.xpath(
# './div[contains("class="lzl_content_reply")]//span[class="lzl_time"]/text()')
#
# reply_dict = {
# "reply_user_link": reply_user_link,
# "reply_user_img": reply_user_img,
# "reply_name": reply_name,
# "reply_content": reply_content,
# "reply_time": reply_time
# }
# reply_list.append(reply_dict)
#
# comm_dict["reply_list"] = reply_list
insert_list.append(comm_dict)
return insert_list
pass
def insert_data(self, curr_page):
insert_list = self.parse_content()
if insert_list:
res = MongoPool().test.baidu_tieba.insert_many(insert_list)
if res.inserted_ids:
print(f"第{curr_page}页的数据插入成功")
else:
print("插入失败")
else:
pass
多进程的实现
- 将爬取数据的处理封装成一个执行函数
def main(curr_page):
url = "https://tieba.baidu.com/p/7216163538?pn={}".format(curr_page)
# 创建一个百度贴吧对象
baidu_tieba = BaiduTieba(url)
# 调用对象的方法插入到 mongodb中
baidu_tieba.insert_data(curr_page)
pass
- 这里是进程池来处理,爬取3页内容
if __name__ == '__main__':
TOTAL_PAGE = 3
pool = multiprocessing.Pool()
pages = range(1, TOTAL_PAGE + 1)
# 回调 main函数,pages是迭代器,作为回调函数的参数,这和map函数的用法一样
pool.map(main, pages)
# 关闭进程池
pool.close()
# 等待进程池中的进程执行完毕
pool.join()
效果图
















 805
805











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









