






BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
论文:https://arxiv.org/abs/1810.04805
代码:https://github.com/ google-research/bert
BERT (Bidirectional Encoder Representations from Transformers,基于Transformer的双向编码器表示)
现状:没有一个大型数据集监督任务的迁移网络,应用于下游各种NLP任务。在大量无标签的数据集上做迁移学习,如CV中在ImageNet数据集上训练好模型,再应用到别的任务上。而BERT证明了在大量无标签的数据集上训练的模型,比少量有标签数据集上训练的模型效果更好。
自然语言处理任务包括:
1、句子层面的任务,用于建模句子之间的关系;
2、单词层面的任务,如实体命名的识别;
使用预训练模型做特征表示时有两类策略:
1、基于特征的策略:对于每个下游任务,构造一个与这个任务相关的网络,预训练好的表示作为一个额外的特征,与原始输入一起送入模型中,因为预训练的特征已经有了比较好的表示,所以模型的训练比较容易。如ELMo中使用了RNN作为下游网络。
2、基于微调的策略:把预训练好的模型应用于下游任务时只需要改动一点,模型预训练好的参数会在下游的数据集上再进行微调。如GPT。
缺点:这两种方法在预训练期间共享相同的目标函数,并且使用单向的语言模型(根据上文信息预测下文)来学习通用语言表示。
创新点:
1、提出了一个预训练的BERT模型,它是基于Transformer的双向编码器表示,使用“masked language model"(MLM)来实现预训练的深度双向预测;
2、BERT是第一个基于微调的表示模型,不需要根据特定的任务设计下游网络,网络结构简单且强大,在11个NLP任务上取得了最好的结果。
3、BERT模型是一种预训练模型,能够在大规模无标注数据上进行预训练,然后在有标注数据上进行微调,可以适用于各种任务和语言。
BERT模型的两种主要任务:
1、Masked Language Model(MLM,遮盖语言模型):目的是预测句子中部分单词的原始形式。在训练过程中,BERT模型会随机选择一些单词并用“【MASK】”标记替换它们。模型的任务是预测被替换的单词的原始形式(完形填空)。这种方法可以使模型在理解句子语义的同时学习到词语之间的关系,属于单词层面的任务。
2、Next Sentence Prediction(NSP,下一句预测):目的是预测一个句子是否是另一个句子的下一句。在训练过程中,BERT模型会从从一篇文章中随机采样两个句子,并判断其中一个句子是否是另一个句子的下一句来训练模型。这种方法可以使模型更好地理解上下文之间的关系,属于句子层面的任务。
主要思想:预训练+微调
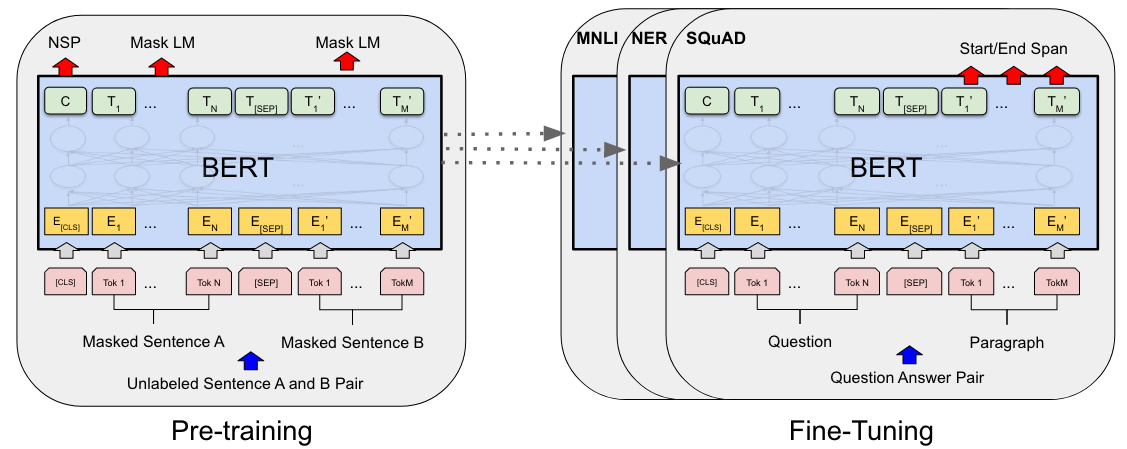
主要思想:在一个大量的无标签的数据集上进行预训练,并将预训练好的参数应用于微调中,微调时使用有标签的数据。除了输出层之外,预训练和微调都使用相同的架构。每个下游任务都会创建一个新的BERT模型,使用之前预训练好的BERT模型作为参数初始化,并根据自己的任务进行参数微调。
BERT模型参数量计算:
BERT模型是标准的Transformer结构,由多头自注意力和前馈神经网络组成。
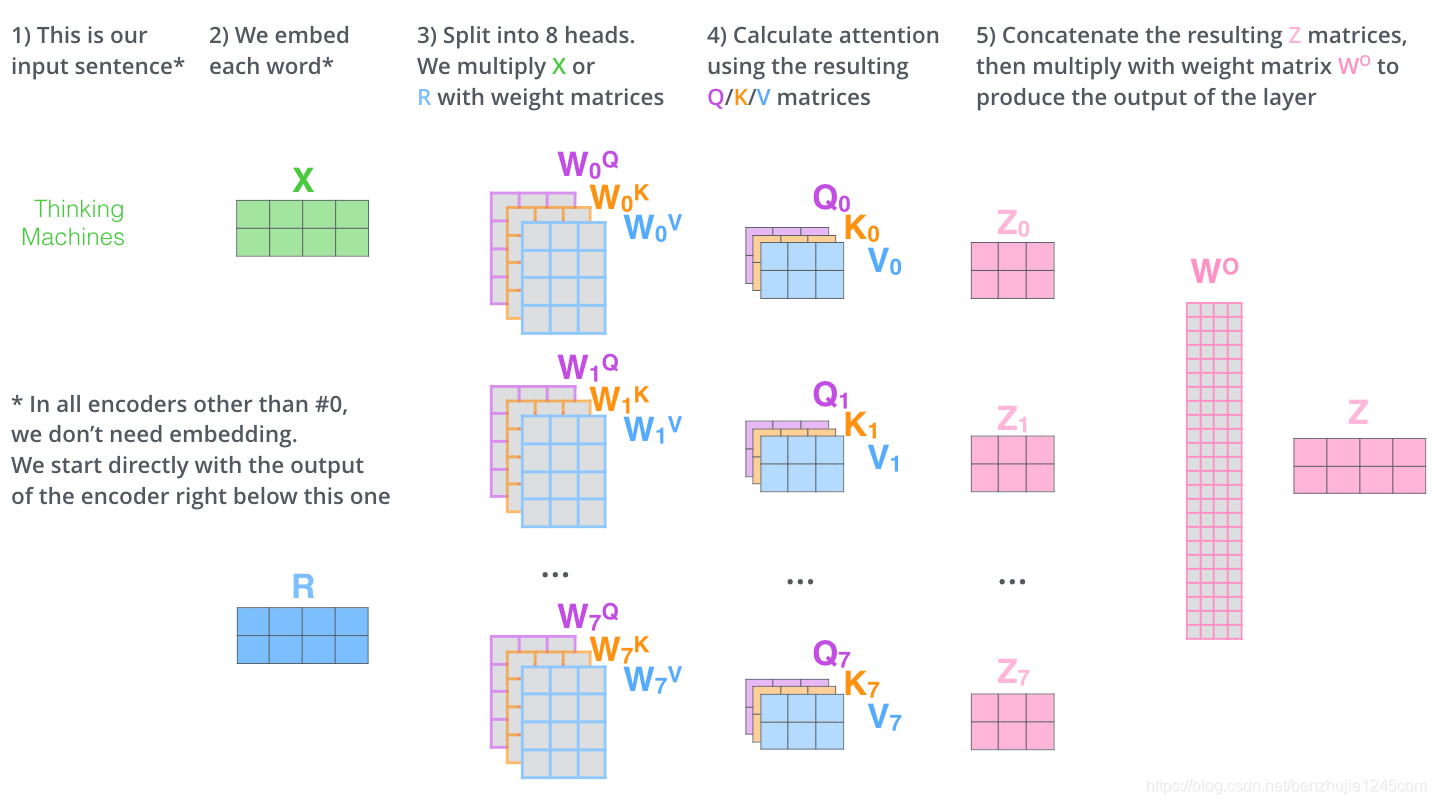
1、在Transformer中,句子首先被划分为token,token是最基本的文本单元,如单词等;之后对每个token进行索引化(Tokenization),将其映射为一个字典大小的索引序列(30K),即离散化处理,此时输入大小 = num_tokens × 30K;
2、词嵌入层(Word Embedding):将每个token编码为一个长度为H的向量,从而将其映射到连续空间中。词嵌入层通常是一个矩阵,矩阵大小 = 字典大小(30K) × embedding_size(H),输出词嵌入向量的大小 = num_tokens × H;
3、使用三个不同的投影矩阵Wk,Wq,Wv = H × dk(64),将向量映射到不同的表示空间中,得到K、Q、V = num_tokens × dk;
4、计算Self-Attention:Q·K^T = num_tokens × num_tokens,Self_Attention = softmax(Q·K^T / 根号dk )·V = num_tokens × dk;
5、多头自注意力拼接:A个head拼接起来,得到 = num_tokens × (dk × A) = num_tokens × H,之后再应用一个线性变换矩阵 = H × H,输出 = num_tokens × H;
6、前馈神经网络:用于对每个注意力子层的输出进行非线性变换和特征提取。使用两个全连接层,输入 = num_tokens × H,隐藏层输出 = num_tokens × 4H,最终输出 = num_tokens × H。
总的超参数量 = 词嵌入矩阵 + ((Wk,Wq,Wv) × A + 线性变换矩阵 + 2个全连接层) × L
= (30K × H) + ((3 × (H × dk)) × A + H^2 + (H × 4H) × 2) × L
= 30K × H + (3 × H × H + H^2 + 8H^2) × L
= 30K × H + 12H^2 × L
BERT_BASE模型:L (num_layers) = 12, H (hidden_size) = 768, A (num_head) = 12
超参数量 = 30K × 768 + 12 × 768^2 × 12 ≈ 1.1亿
BERT_LARGE模型:L (num_layers) = 24, H (hidden_size) = 1024, A (num_head) = 16
超参数量 = 30K × 1024 + 12 × 1024^2 × 24 ≈ 3.4亿
输入输出表示:一个句子/句子对(一个序列)
WordPiece分词法:用词根表示单词,大大减小嵌入层字典的大小。
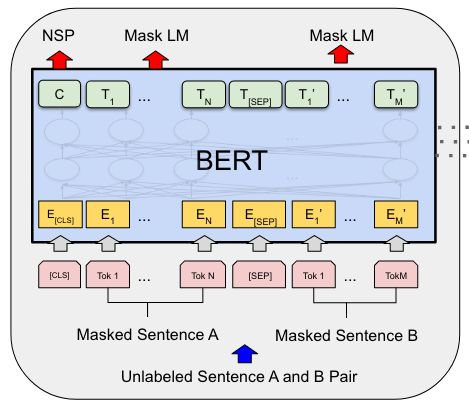
每个序列的第一个token是一个特殊的分类token([CLS]),由于自注意力的全局视野,该token可以聚合句子中所有其他token的信息,即句子层面的信息。
当输入是一个句子对时,有两种区分方式:
1、在每个句子后面使用一个特殊的token([SEP])将它们分开;
2、向每个token中添加一个可学习嵌入层,指示它属于句子A还是句子B。
Bert中的Embedding嵌入:
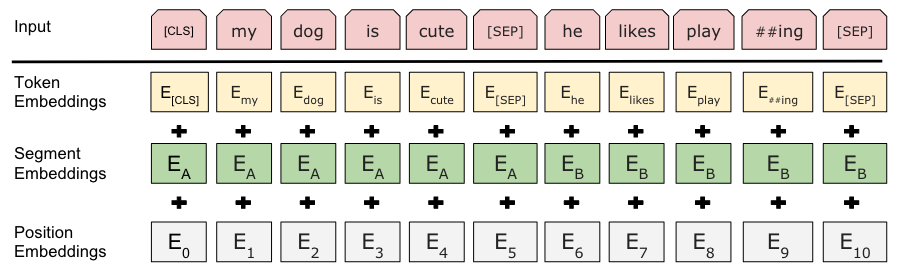
Embedding = Token Embeddings + Segment Embeddings + Position Embeddings
它们都是可学习的表示。
预训练任务:
1、Masked Language Model (MLM, 完形填空)
在预训练阶段:对于输入的次元序列,如果一个词元是由WordPiece生成的,则会以15%的概率被随机替换为[mask],[CLS]和[SEP]不会被替换。
在微调阶段:对于15%被选中的词元,以80%的概率替换为[mask],以10%的概率替换为一个随机的token,以10%的概率保持不变。在计算损失函数时,只有真正被替换成了[MASK]标记的tokens会被用来计算损失值,而没有被标记的tokens则不会参与损失函数的计算。

这样做的好处是Transformer编码器不知道要求预测哪些单词或哪些单词已被随机替换,因此它被迫保留了每个输入token的上下文分布表示。此外,由于随机替换仅发生在所有token的1.5%(15%中的10%),因此不会损害模型的语言理解能力。
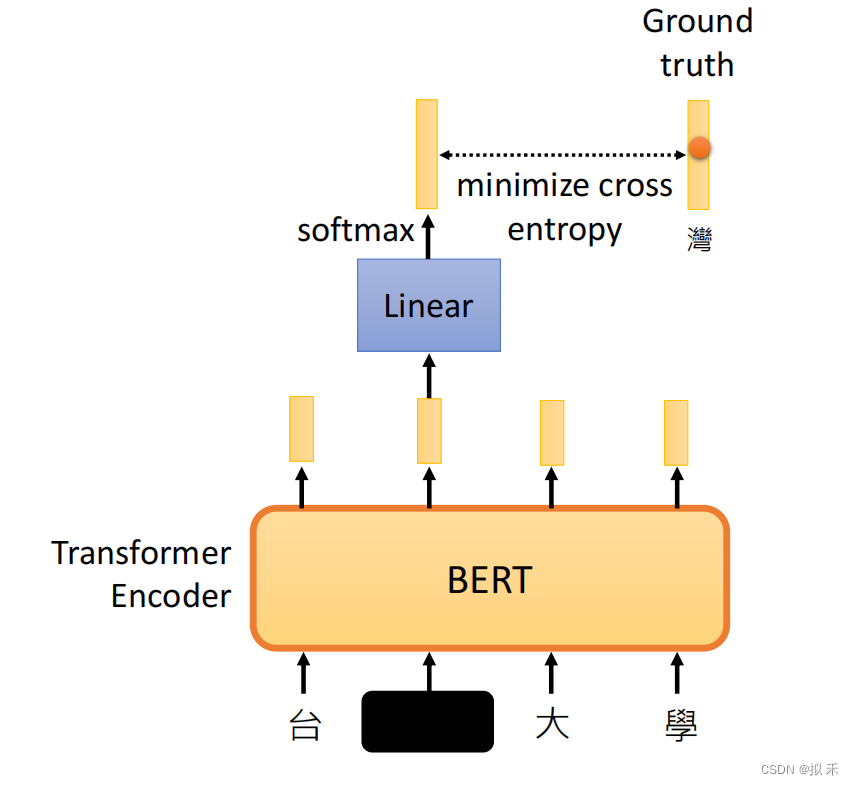
在计算损失函数时,需要使用一个掩码(Mask)向量来标识哪些token是被mask的,哪些token是没有被mask的。具体来说,将掩码向量中被mask的token设置为1,没有被mask的token设置为0。在计算损失函数时,可以将掩码向量与预测的token和实际的token相乘,这样就可以将没有被mask的token的损失值置为0,只计算被Mask的token的损失值。
2、Next Sentence Prediction (NSP, 下一句预测)
在预训练阶段,对于输入的句子A和B,有50%的概率句子B在句子A之后(正例),50%的概率句子B是从其他地方随机采样得到的(负例)。
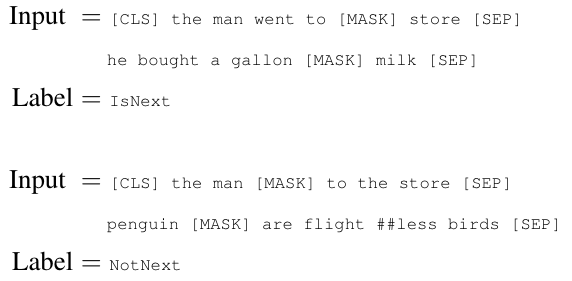
预训练数据集:BooksCorpus(8亿字),和英语基维百科(25亿字)。
在BERT中,编码器看不到解码器,应用于下游任务时,只需要将[CLS]拿出来做分类,或者将需要的特征拿出来经过一个Softmax输出层得到对应的输出即可。
微调任务:
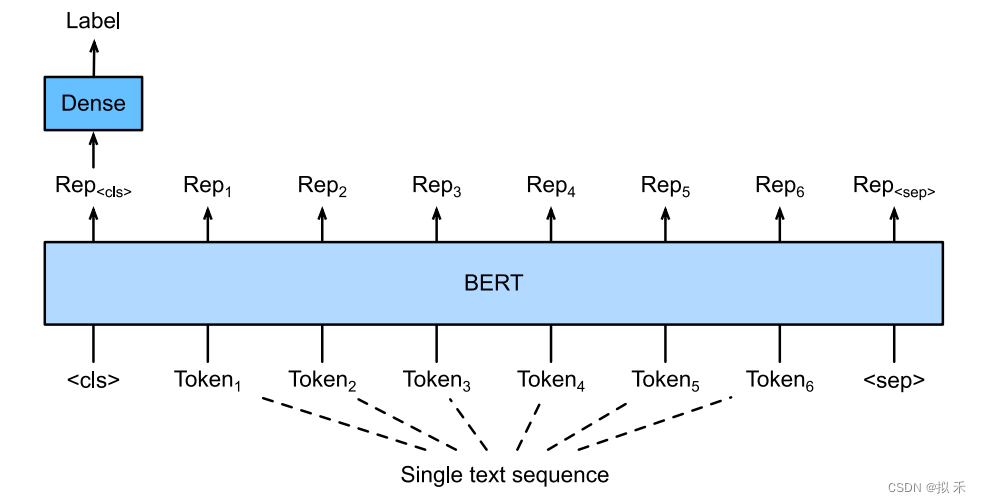
1、Single Text Classifification(单文本分类)
2、Text Pair Classifification(文本对分类)
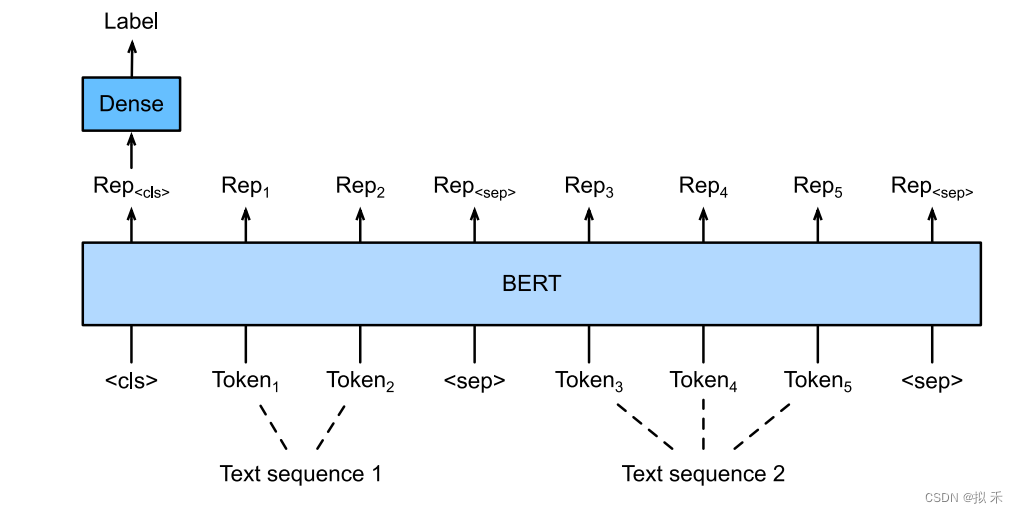
上面的两种情况要求模型输入需要附加一个起始Token,记为[CLS],对应最终的Hidden State(即Transformer的输出)可以用来表征整个句子,用于下游的分类任务。就是将[CLS]对应的向量输入到全连接层进行分类。
3、Text Tagging
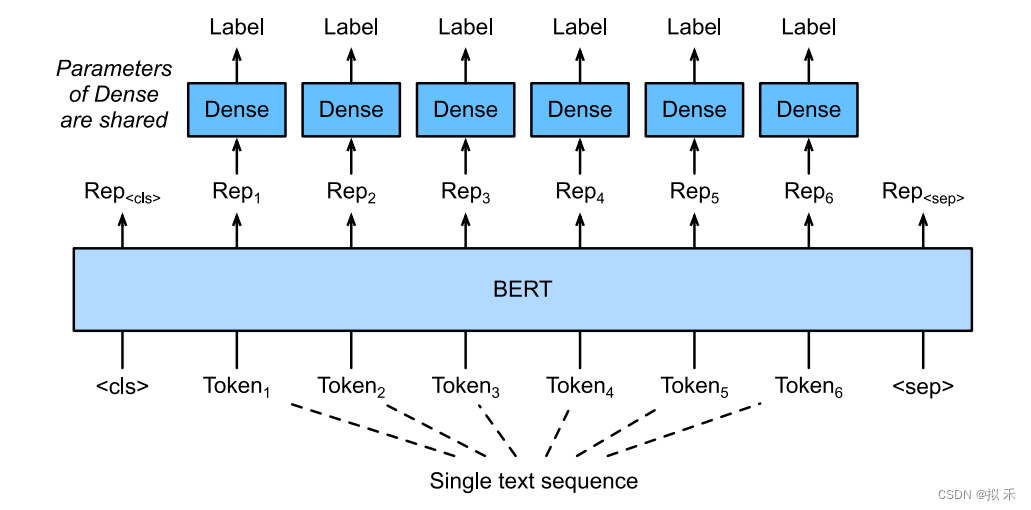
为了识别一个词元是不是命名实体,例如人名、机构、位置,可以将非特殊词元放进全连接层进行分类。
4、Question Answering
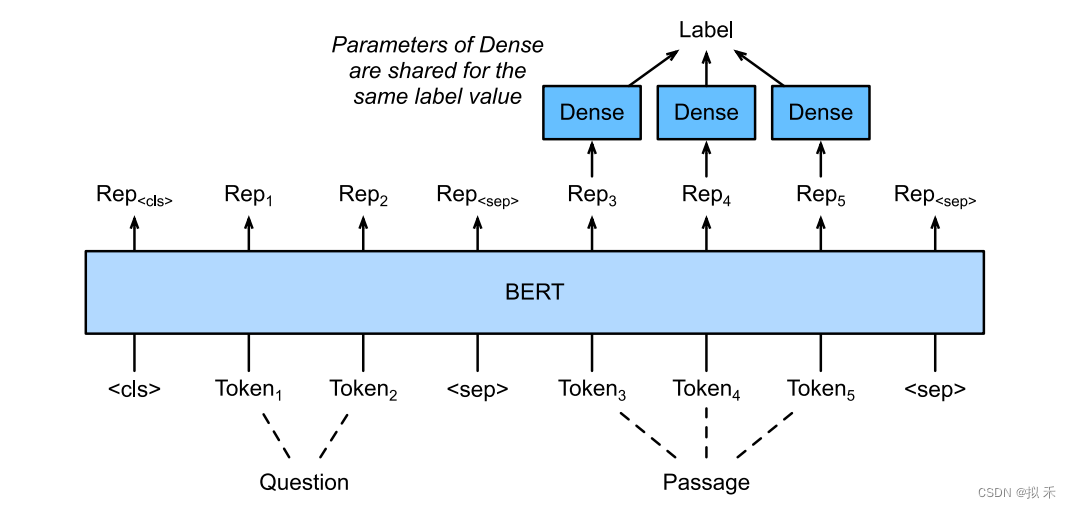
给定一个问题,和描述文字,找出一个片段作为回答,对片段中的每个词元预测它是不是回答的开头或结束,然后返回两个整数分别表示开始和结束是给定描述文字第几个词,所以开始和结束(包括自身)中间的部分就是答案。
代码分析:
embedding = Token embedding + Position embedding + Segment embedding

class BERTEmbedding(nn.Module):
"""
BERT Embedding which is consisted with under features
1. TokenEmbedding : normal embedding matrix
2. PositionalEmbedding : adding positional information using sin, cos
2. SegmentEmbedding : adding sentence segment info, (sent_A:1, sent_B:2)
sum of all these features are output of BERTEmbedding
"""
def __init__(self, vocab_size, embed_size, dropout=0.1):
"""
:param vocab_size: total vocab size
:param embed_size: embedding size of token embedding
:param dropout: dropout rate
"""
super().__init__()
self.token = TokenEmbedding(vocab_size=vocab_size, embed_size=embed_size)
self.position = PositionalEmbedding(d_model=self.token.embedding_dim)
self.segment = SegmentEmbedding(embed_size=self.token.embedding_dim)
self.dropout = nn.Dropout(p=dropout)
self.embed_size = embed_size
def forward(self, sequence, segment_label):
x = self.token(sequence) + self.position(sequence) + self.segment(segment_label)
return self.dropout(x)Token embedding:
class TokenEmbedding(nn.Embedding):
def __init__(self, vocab_size, embed_size=512):
super().__init__(vocab_size, embed_size, padding_idx=0)Positional embedding:
class PositionalEmbedding(nn.Module):
def __init__(self, d_model, max_len=512):
super().__init__()
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model).float()
pe.require_grad = False
position = torch.arange(0, max_len).float().unsqueeze(1)
div_term = (torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model)).float().exp()
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
return self.pe[:, :x.size(1)]Segment embedding:
class SegmentEmbedding(nn.Embedding):
def __init__(self, embed_size=512):
super().__init__(3, embed_size, padding_idx=0)BERT model:
class BERT(nn.Module):
"""
BERT model : Bidirectional Encoder Representations from Transformers.
"""
def __init__(self, vocab_size, hidden=768, n_layers=12, attn_heads=12, dropout=0.1):
"""
:param vocab_size: vocab_size of total words
:param hidden: BERT model hidden size
:param n_layers: numbers of Transformer blocks(layers)
:param attn_heads: number of attention heads
:param dropout: dropout rate
"""
super().__init__()
self.hidden = hidden
self.n_layers = n_layers
self.attn_heads = attn_heads
# paper noted they used 4*hidden_size for ff_network_hidden_size
self.feed_forward_hidden = hidden * 4
# embedding for BERT, sum of positional, segment, token embeddings
self.embedding = BERTEmbedding(vocab_size=vocab_size, embed_size=hidden)
# multi-layers transformer blocks, deep network
self.transformer_blocks = nn.ModuleList(
[TransformerBlock(hidden, attn_heads, hidden * 4, dropout) for _ in range(n_layers)])
def forward(self, x, segment_info):
# attention masking for padded token
# torch.ByteTensor([batch_size, 1, seq_len, seq_len)
mask = (x > 0).unsqueeze(1).repeat(1, x.size(1), 1).unsqueeze(1)
# embedding the indexed sequence to sequence of vectors
x = self.embedding(x, segment_info)
# running over multiple transformer blocks
for transformer in self.transformer_blocks:
x = transformer.forward(x, mask)
return x注意,这里的mask是大小为[batch_size, 1, seq_len, seq_len],由0和1表示的矩阵,在Transformer计算Attention矩阵时将对应0的位置替换为无穷小量。
class Attention(nn.Module):
"""
Compute 'Scaled Dot Product Attention
"""
def forward(self, query, key, value, mask=None, dropout=None):
scores = torch.matmul(query, key.transpose(-2, -1)) \
/ math.sqrt(query.size(-1))
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn训练任务:(NSP和MLM任务)
class BERTLM(nn.Module):
"""
BERT Language Model
Next Sentence Prediction Model + Masked Language Model
"""
def __init__(self, bert: BERT, vocab_size):
"""
:param bert: BERT model which should be trained
:param vocab_size: total vocab size for masked_lm
"""
super().__init__()
self.bert = bert
self.next_sentence = NextSentencePrediction(self.bert.hidden)
self.mask_lm = MaskedLanguageModel(self.bert.hidden, vocab_size)
def forward(self, x, segment_label):
x = self.bert(x, segment_label)
return self.next_sentence(x), self.mask_lm(x)
class NextSentencePrediction(nn.Module):
"""
2-class classification model : is_next, is_not_next
使用[cls]做分类
"""
def __init__(self, hidden):
"""
:param hidden: BERT model output size
"""
super().__init__()
self.linear = nn.Linear(hidden, 2)
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, x):
return self.softmax(self.linear(x[:, 0]))
class MaskedLanguageModel(nn.Module):
"""
predicting origin token from masked input sequence
n-class classification problem, n-class = vocab_size
"""
def __init__(self, hidden, vocab_size):
"""
:param hidden: output size of BERT model
:param vocab_size: total vocab size
"""
super().__init__()
self.linear = nn.Linear(hidden, vocab_size)
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, x):
return self.softmax(self.linear(x))LOSS计算:
self.criterion = nn.NLLLoss(ignore_index=0)NLLloss是CrossEntropyLoss的简化版,即不经过softmax和log。
CrossEntropyLoss:
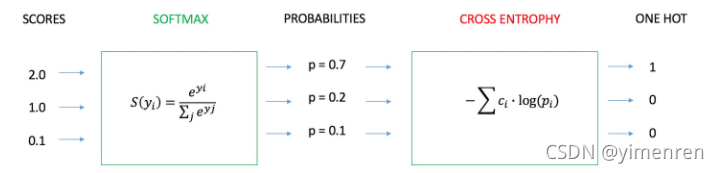
![]()
for i, data in data_iter:
# 0. batch_data will be sent into the device(GPU or cpu)
data = {key: value.to(self.device) for key, value in data.items()}
# 1. forward the next_sentence_prediction and masked_lm model
next_sent_output, mask_lm_output = self.model.forward(data["bert_input"], data["segment_label"])
# 2-1. NLL(negative log likelihood) loss of is_next classification result
next_loss = self.criterion(next_sent_output, data["is_next"])
# 2-2. NLLLoss of predicting masked token word
mask_loss = self.criterion(mask_lm_output.transpose(1, 2), data["bert_label"])
# 2-3. Adding next_loss and mask_loss : 3.4 Pre-training Procedure
loss = next_loss + mask_loss
# 3. backward and optimization only in train
if train:
self.optim.zero_grad()
loss.backward()
self.optim.step()
# next sentence prediction accuracy
correct = next_sent_output.argmax(dim=-1).eq(data["is_next"]).sum().item()
avg_loss += loss.item()
total_correct += correct
total_element += data["is_next"].nelement()
post_fix = {
"epoch": epoch,
"iter": i,
"avg_loss": avg_loss / (i + 1),
"avg_acc": total_correct / total_element * 100,
"loss": loss.item()
}















 159
159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









