







主要的性能优化:
减少I/O调用
I/O通常发生在毫秒级,而CPU一般发生在亚微米级,任何I/O的代价都很高昂。
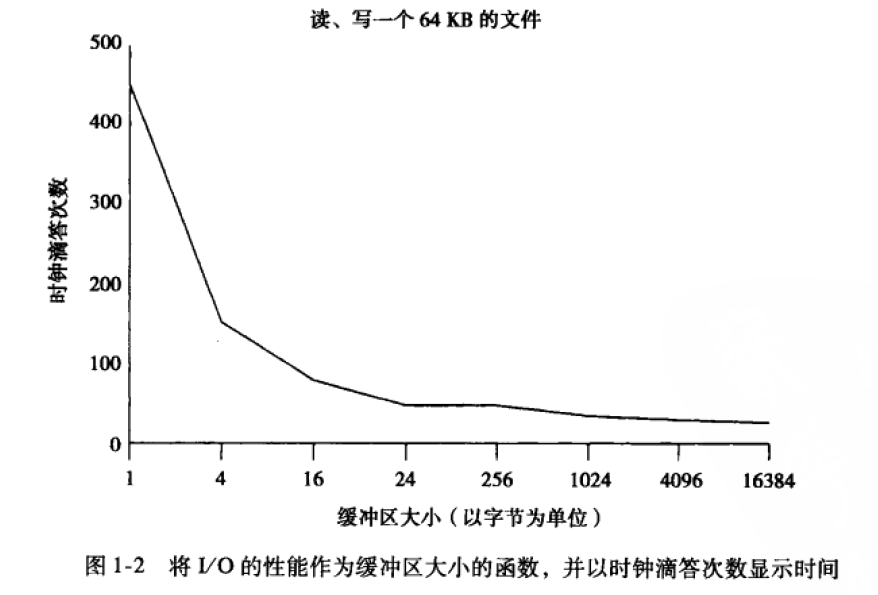
可以通过使用智能缓冲来减小它的影响,ANSI C利用了setvbuf()函数。下面的图可以看到利用1024B的缓存空间就足以消减I/O带来的延迟。函数调用
函数调用会造成大的延迟,虽然compiler已经作了优化,但还是不可消除。为了减小延迟,可以在“多使用宏”、“减少函数递归”两方面入手。
一些名词解释:
- 双向链表(doubly linked list)的每个节点都有一个向前和一个向后的指针。
链表删除节点时的注意事项:
链表被称为动态数据结构,适合于存储数量不确定的数据。缺点是,它的潜在长度是不确定的,一旦数据量很大,对它重复搜索时会变得很麻烦。有两个解决方法:
- 在链表中以某种顺序放置节点
- 将最近访问的节点放到链表头部(当感兴趣的数据集中在一块时有效)
然而这些方法只当链表不太长时管用,否则应当使用其它数据结构,比如散列和二叉树(能够保证近似最优性能并且与所存储数据项的数量无关)
- 链表实现允许无限地调整大小,而数组而要求在开发过程的早期就确定一个最大大小。
- 对于stack和queue,建议在编译时而不是在运行时确定最大大小。
- 使用queue时,如果用数组实现,为了不让数据从内存中全部迁出,可以循环访问数组,这样的数据通常称为循环缓冲区(circular buffer)。
- 如果用链表实现queue的话,在分配和释放节点时,将使可用的内存碎片化。解决这个问题有两个方法:
- 使用自己的函数来分配和返还内存。这个函数将分配一个节点池。
- 创建一个未使用节点的链表。把项目添加到队列中时,就把节点从空闲链表移到队列中,反之移出。

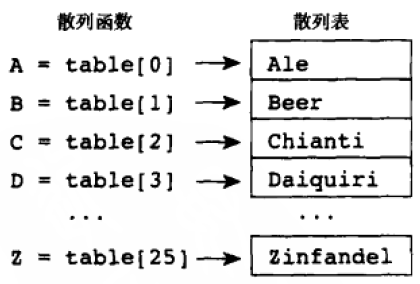
散列表(hash table)
- Hash table可以在存放数量不确定的项目时,提供对数据项的快速、随机访问。
Hash table的简单表示(其中的数字表示hash key):
在上面的例子中,如果有两个单词的首字母相同,则用再散列法(rehashing)或者拉链法(chaining)来区分。前者是对其再分一次,后者是用链表将重复的串联起来。
- 完美散列函数(perfect hash function)是指使元素与hash key之间是一一对映的函数。
- 好的hash function具有两个特点:
- Hash key均匀地分布在整个表中
- 弥补可能出现在输入数据中的聚集
Hash function的目标在于使数据集的冲突率降至最低。函数的形式通常是:
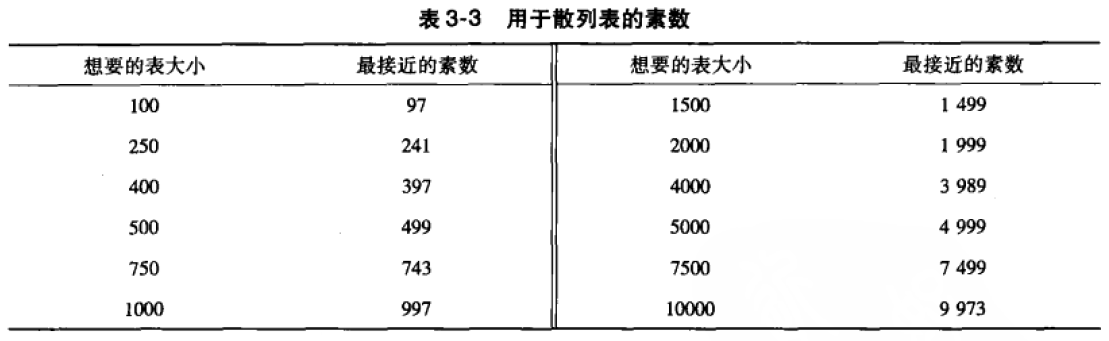
Hash-key = calculated-key % tablesize为了提高离散程度,tablesize应该是一个质数。
- 一个良好的hash function一般满足以下条件:
- 最多含有一个除法运算
- 生成广泛的hash key
- 不依赖于将促使产生聚焦的数据属性
- Hash function占用的时间通常不会很大,性能首要是受到I/O操作和malloc/free的影响。
Hash table出现冲突(相同的hash key)时,有三种方法解决:
- 线性再散列 -> 固定地加一个互质数,找到一个空slot
- 非线性再散列 –> 再散列一次(成功地做法是再用一次rand()),找到一个空slot
- 外部拉链 -> 缺点:要稍微多一点的时间和空间,但这些都微不足道
当负载因子(Nelement/tablesize) > 0.5 时,再散列的方法效率太低,应该用外部拉链的方法
构建hash table时注意以下几点,将使效率提高:

Andrew Binstock, John Rex. 程序员实用算法. 2009.
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









